LangChain框架 (一)
LangChain 是⼀个⽤于开发由⼤型语⾔模型(LLMs)驱动的应⽤程序的框架。
官⽅⽂档:https://python.langchain.com/docs/introduction/
中文文档: https://langchain.ichuangpai.com/
说明: LangChain就是一个开发大模型应用开发框架,可以在原有模型的基础上加一些独属于我们自己的一些数据和配置(公司的内部数据 ),能让我们做开发的时候更加方便,类似java开发中spring和python开发中的Django,爬虫开发中的scrapy.
LangChain简化了LLM应用程序生命周期的各个阶段:
开发阶段:使用LangChain的开源构建块和组件构建应用程序,利用第三方集成和模板快速启动。
生产化阶段:使用LangSmith检查、监控和评估您的链,从而可以自信地持续优化和部署。
部署阶段:使用LangServe将任何链转化为API。
1. Langchain的核心组件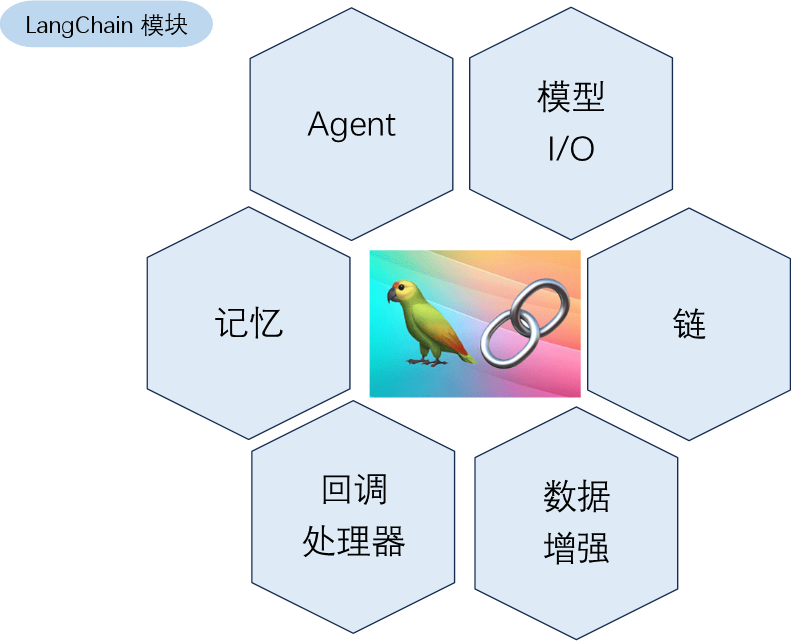
-
模型(Models):包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。
-
提示模板(Prompts):使提示工程流线化,进一步激发大语言模型的潜力。
-
数据检索(Indexes):构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
-
记忆(Memory):通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你。
-
链(Chains):LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成任务。
-
代理(Agents):另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使智能Agent成为可能。
2. 模块封装的功能
这些核心模块里面又封装了很多功能
2.1模型 I/O 封装
-
LLMs:大语言模型
-
ChatModels:一般基于 LLMs,但按对话结构重新封装
-
Prompt:提示词模板
-
OutputParser:解析输出
2.2 Retrieval 数据连接与向量检索封装
-
Retriever: 向量的检索
-
Document Loader:各种格式文件的加载器
-
Embedding Model:文本向量化表示,用于检索等操作
-
Verctor Store: 向量的存储
-
Text Splitting:对文档的常用操作
2.3 Agents 代理封装
根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能,包括:
-
Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
-
Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
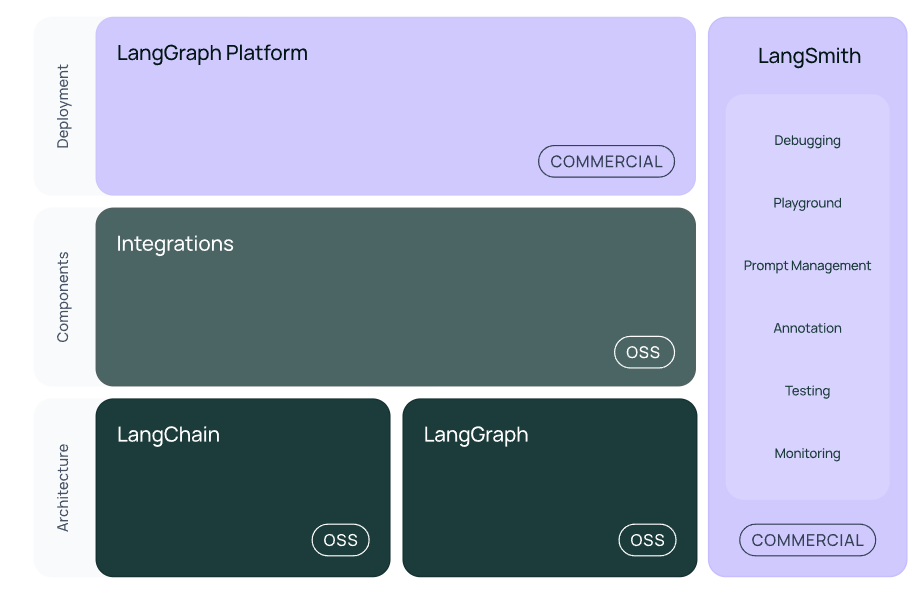
3. 开源第三方库
-
langchain-core :基础抽象和LangChain表达式语言
-
langchain-community :第三方集成。合作伙伴包(如langchain-openai、langchain-anthropic等),一些集成已经进一步拆分为自己的轻量级包,只依赖于langchain-core
-
langchain :构成应用程序认知架构的链、代理和检索策略
-
langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多参与者应用程序
-
langserve:将 LangChain 链部署为 REST API
-
LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成
注意: Langchain开发我们一般说的是他的整个生态
4. LangChain基本使用
-
模块安装
-
# 安装指定版本的LangChain
pip install langchain==0.3.7 -i https://pypi.tuna.tsinghua.edu.cn/simple(bug有点多)
pip install langchain-openai==0.2.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
langchain 1.x(现在常用)4.1模型调用
-
通过LangChain的接口来调用OpenAI对话
from dotenv import load_dotenv from langchain_openai import ChatOpenAI import os load_dotenv() llm = ChatOpenAI(api_key=os.getenv("api_key"), base_url=os.getenv("base_url"), model_name="qwen-plus") # 直接提供问题,并调用llm response = llm.invoke("什么是大模型?") print(response) print("=" * 50) print(response.content)4.2 向量存储
-
使用一个简单的本地向量存储 FAISS,首先需要安装它
pip install faiss-cpu pip install langchain_community==0.3.7 pip install dashscope import os from langchain_community.document_loaders import WebBaseLoader import bs4 from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import FAISS from dotenv import load_dotenv # 加载环境变量 load_dotenv() # 初始化 WebBaseLoader loader = WebBaseLoader( 'https://www.gov.cn/zhengce/content/202510/content_7043916.htm', bs_kwargs=dict(parse_only=bs4.SoupStrainer(id='UCAP-CONTENT')) ) docs = loader.load() # 分割文档 text_splitter = RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=50, ) documents = text_splitter.split_documents(docs) print(f"总文档数量: {len(documents)}") # 初始化 DashScope 嵌入模型 embeddings = DashScopeEmbeddings( dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"), model="text-embedding-v4", ) # 初始化 FAISS 索引(第一次循环) vector = None batch_size = 10 # 分批处理文档 for i in range(0, len(documents), batch_size): batch_docs = documents[i:i + batch_size] print(f'第{i // batch_size + 1}批次 文档数量: {len(batch_docs)}') # 第一批:创建新的 FAISS 索引 if i == 0: vector = FAISS.from_documents(batch_docs, embeddings) # 后续批次:将新文档添加到现有索引 else: new_vector = FAISS.from_documents(batch_docs, embeddings) vector.merge_from(new_vector) # 合并新索引到现有索引 vector.save_local("faiss_index") print("FAISS 索引已保存到 faiss_index 文件夹")4.3 RAG+Langchain
基于外部知识,增强大模型回复
import os from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from langchain.chains import create_retrieval_chain from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings from dotenv import load_dotenv # 加载环境变量(用于 LLM 的 API 密钥) load_dotenv() # 创建嵌入模型 embeddings = DashScopeEmbeddings( dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"), model='text-embedding-v4' ) # 加载本地 FAISS 索引 save_path = "faiss_index_v3" vector_store = FAISS.load_local( folder_path=save_path, embeddings=embeddings, allow_dangerous_deserialization=True # 允许加载 pickle 文件(仅限可信文件) ) # 创建提示模板 prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题: <context> {context} </context> 问题: {input}""") # 创建 LLM 连接(继续使用阿里云 qwen-plus) llm = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 确保环境变量名为 DASHSCOPE_API_KEY base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus" ) # 创建文档组合链 # langchain_core\prompts\chat.py可以看到提示词拼接 # format_messages 方法拼接提示词 document_chain = create_stuff_documents_chain(llm, prompt) # 创建检索器 retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 限制检索 3 个文档 # 创建检索链 # 在langchain_community\vectorstores\faiss.py 可以查看向量检索的实现 # similarity_search_with_score_by_vector 是检索的方法 return docs[:k] retrieval_chain = create_retrieval_chain(retriever, document_chain) # 调用检索链并获取回答 # openai\resources\chat\completions\completions.py # create方法中 self._post() 调用模型请求的api response = retrieval_chain.invoke({"input": "建设用地使用权是什么?"}) print("\n回答:", response["answer"])二.LangChain的Model
可以把对模型的使用过程拆解成三块: 输入提示(Format)、调用模型(Predict)、输出解析(Parse)
-
1.提示模板: LangChain的模板允许动态选择输入,根据实际需求调整输入内容,适用于各种特定任务和应用。
-
2.语言模型: LangChain 提供通用接口调用不同类型的语言模型,提升了灵活性和使用便利性。
-
3.输出解析: 利用 LangChain 的输出解析功能,精准提取模型输出中所需信息,避免处理冗余数据,同时将非结构化文本转换为可处理的结构化数据,提高信息处理效率。
这三块形成了一个整体,在LangChain中这个过程被统称为Model I/O。针对每块环节,LangChain都提供了模板和工具,可以帮助快捷的调用各种语言模型的接口 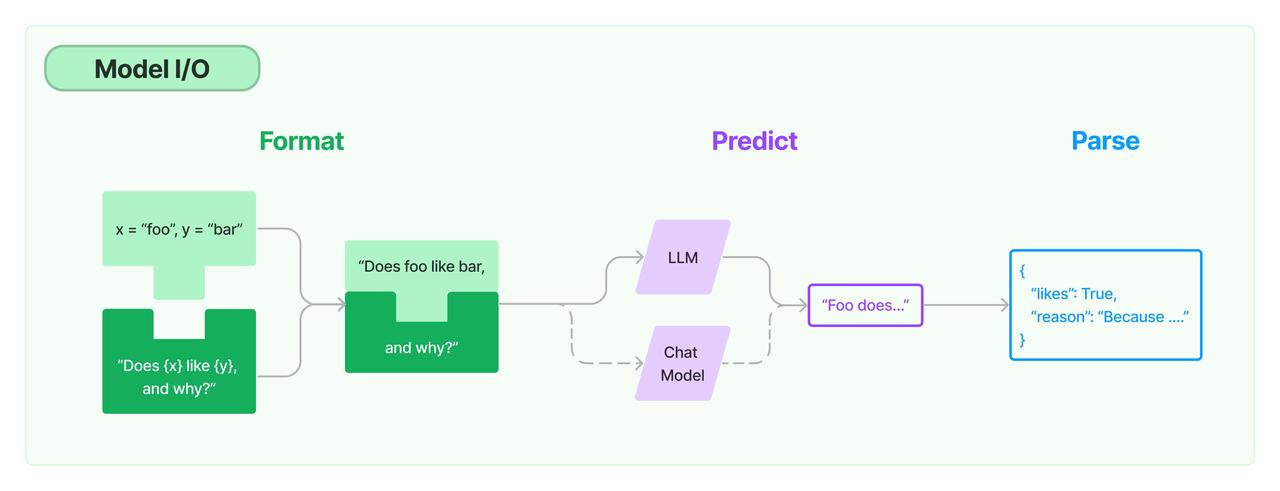
1. 提示模板
在LangChain的Model I/O中,提示模板是其组成之一,语言模型的提示是用户提供的一组指令或输入,用于指导模型的响应,帮助模型理解上下文并生成相关且连贯的基于语言的输出,例如回答问题、完成句子或参与某项活动、对话
PromptTemplates 是LangChain中的一个概念,通过接收原始用户输入,并返回一个准备好传递给语言模型的信息(即提示词 prompt)
通俗点说,prompt template 是一个模板化的字符串,可以用来生成特定的提示(prompts)。你可以将变量插入到模板中,从而创建出不同的提示。这对于重复生成相似格式的提示非常有用,尤其是在自动化任务中
1.1 LangChain提示模板特点
-
清晰易懂的提示: 提高提示文本的可读性,使其更易于理解,尤其是在处理复杂或涉及多个变量的情况下。
-
增强可重用性: 使用模板,可以在多个地方重复使用,简化代码,无需重复构建提示字符串。
-
简化维护: 使用模板后,如果需要更改提示内容,只需修改模板,无需逐个查找所有用到该提示的地方。
-
智能处理变量: 模板可以自动处理变量的插入,无需手动拼接字符串。
-
参数化生成: 模板可以根据不同的参数生成不同的提示,有助于个性化文本生成。
1.2 类型
-
LLM提示模板 PromptTemplate:常用的String提示模板
-
聊天提示模板 ChatPromptTemplate: 常用的Chat提示模板,用于组合各种角色的消息模板,传入聊天模型。消息模板包括:ChatMessagePromptTemplate、HumanMessagePromptTemplate、AIlMessagePromptTemplate、SystemMessagePromptTemplate等
-
样本提示模板 FewShotPromptTemplate:通过示例来教模型如何回答
-
部分格式化提示模板:提示模板传入所需值的子集,以创建仅期望剩余值子集的新提示模板。
-
管道提示模板 PipelinePrompt: 用于把几个提示组合在一起使用。
-
自定义模板:允许基于其他模板类来定制自己的提示模板。
1.3 String提示模板
# 导入LangChain中的OpenAI模型接口
from langchain_openai import ChatOpenAI
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
import os
from dotenv import load_dotenv
load_dotenv()
# 创建模型实例
model = ChatOpenAI(api_key=os.getenv("api_key"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-plus')
prompt = PromptTemplate(
template="您是一位专业的程序员。\n对于信息 {text} 进行简短描述"
)
# 输入提示
input = prompt.format(text="大模型langchain")
# 得到模型的输出
output = model.invoke(input)
# output = model.invoke("您是一位专业的程序员。对于信息 langchain 进行简短描述")
# 打印输出内容
print(output.content)1.4 聊天提示模板
-
PromptTemplate创建字符串提示的模板。默认情况下,使用Python的str.format语法进行模板化。而ChatPromptTemplate是创建聊天消息列表的提示模板。
-
创建一个ChatPromptTemplate提示模板,模板的不同之处是它们有对应的角色。
from langchain.prompts.chat import ChatPromptTemplate # 导入LangChain中的ChatOpenAI模型接口 from langchain_openai import ChatOpenAI import os from dotenv import load_dotenv load_dotenv() template = "你是一个数学家,你可以计算任何算式" # template = "你是一个翻译专家,擅长将 {input_language} 语言翻译成 {output_language}语言." human_template = "{text}" chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) # print(chat_prompt) # 创建模型实例 model = ChatOpenAI(api_key=os.getenv("api_key"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model='qwen-plus') # 输入提示 messages = chat_prompt.format_messages(text="我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?") # print(messages) # messages = chat_prompt.format_messages(input_language="英文", output_language="中文", text="I love Large Language Model.") print(messages) # 得到模型的输出 output = model.invoke(messages) # 打印输出内容 print(output.content) -
LangChain提供不同类型的MessagePromptTemplate.最常用的是AIMessagePromptTemplate、 SystemMessagePromptTemplate和HumanMessagePromptTemplate,分别创建人工智能消息、系统消息和人工消息。
# 导入聊天消息类模板 from langchain.prompts import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain_openai import ChatOpenAI import os from dotenv import load_dotenv load_dotenv() # 系统模板的构建 system_template = "你是一个翻译专家,擅长将 {input_language} 语言翻译成 {output_language}语言." system_message_prompt = SystemMessagePromptTemplate.from_template(system_template) # 用户模版的构建 human_template = "{text}" human_message_prompt = HumanMessagePromptTemplate.from_template(human_template) # 组装成最终模版 prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt]) # 格式化提示消息生成提示 prompt = prompt_template.format_prompt(input_language="英文", output_language="中文", text="I love Large Language Model.").to_messages() # 打印模版 print("prompt:", prompt) # 创建模型实例 model = ChatOpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model='qwen-plus') # 得到模型的输出 result = model.invoke(prompt) # 打印输出内容 print("result:", result.content)1.5 少量样板提示
基于LLM模型与聊天模型,可分别使用
FewShotPromptTemplate或FewShotChatMessagePromptTemplate,两者使用基本一致创建示例集:创建一些提示样本,每个示例都是一个字典,其中键是输入变量,值是输入变量的值
# 创建提示模板,配置一个提示模板,将一个示例格式化为字符串
import os
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
import langchain_openai
load_dotenv()
# 创建示例
examples = [
{"input": "2+2", "output": "4", "description": "加法运算"},
{"input": "5-2", "output": "3", "description": "减法运算"},
]
prompt_template = "你是一个数学专家,算式: {input} 值: {output} 使用: {description} "
# 这是一个提示模板,用于设置每个示例的格式
prompt_sample = PromptTemplate.from_template(prompt_template)
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt_sample,
# 告诉大模型要按照这个格式输出description
suffix="""你是一个数学专家,请计算: {input} 值: {output} """,
input_variables=["input", "output"],
)
# print(prompt.format(input="2*5", output="10")) # 你是一个数学专家,算式: 2*5 值:
#
# print(prompt_sample)
print('-' * 50)
llm = langchain_openai.ChatOpenAI(api_key=os.getenv("api_key"),
base_url=os.getenv("base_url"),
model_name='qwen-plus')
result = llm.invoke(prompt.format(input="2*5", output="10"))
print(result.content) # 使用: 乘法运算
2. Model 模型
LangChain支持的模型有三大类
-
1.大语言模型(LLM) ,也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。
-
2.聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的API更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
-
3.文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是Embedding。
聊天模型通常由大语言模型支持,但专门调整为对话场景。重要的是,它们的提供商API使用不同于纯文本模型的接口。输入被处理为聊天消息列表,输出为AI生成的消息。
2.1 大语言模型LLM
LangChain的核心组件是大型语言模型(LLM),它提供一个标准接口以字符串作为输入并返回字符串的形式与多个不同的LLM进行交互。这一接口旨在为诸如OpenAI、Hugging Face等多家LLM供应商提供标准化的对接方法。
文本补全-千问不支持
from langchain_community.llms import Tongyi
from dotenv import load_dotenv
import os
load_dotenv()
# LLM纯文本补全模型
llm = Tongyi(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-plus')
text = "我的真的好想(帮我补全这个文本)"
res = llm.invoke(text)
print(res)2.2 聊天模型
聊天模型是LangChain的核心组件,使用聊天消息作为输入并返回聊天消息作为输出。
LangChain有一些内置的消息类型
-
SystemMessage:用于启动 AI 行为,通常作为输入消息序列中的第一个传递。
-
HumanMessage:表示来自与聊天模型交互的人的消息。
-
AIMessage:表示来自聊天模型的消息。这可以是文本,也可以是调用工具的请求。
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from dotenv import load_dotenv
import os
load_dotenv()
human_text = "你好啊"
system_text = "你是一个强大的助手,你的名字叫0713"
# 聊天模型
chat_model = ChatTongyi(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus", # 此处以qwen-plus为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
)
messages = [HumanMessage(content=human_text)]
# 聊天模型支持多个消息作为输入
# messages = [SystemMessage(content=system_text), HumanMessage(content=human_text)]
res = chat_model.invoke(messages)
print(res)2.3 文本嵌入模型
Embedding类是一个用于与嵌入进行交互的类。有许多嵌入提供商(OpenAI、Cohere、Hugging Face等)- 这个类旨在为所有这些提供商提供一个标准接口。
import os
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
load_dotenv()
# 初始化 DashScopeEmbeddings实例
embeddings = DashScopeEmbeddings(dashscope_api_key=os.getenv("api_key"), model='text-embedding-v3')
# 获取文本嵌入向量
text = '大模型'
# 嵌入文档 把文档内容转换为向量 他支持多个文档列表形式
doc_res = embeddings.embed_documents([text])
print(doc_res)
# 嵌入查询 把问题嵌入向量 一般都是一个问题
res = embeddings.embed_query(text)
print(res)
-
调用HuggingFaceBgeEmbeddings
# 安装模块
pip install sentence_transformers
-
下载modelscope Embedding的模型
from modelscope import snapshot_download
# maidalun/bce-embedding-base_v1 模型名字 cache_dir:下载位置
# model_dir = snapshot_download('maidalun/bce-embedding-base_v1', cache_dir="D:\大模型\RAG_Project")
# langchain_huggingface 加载huggingface模型
from langchain_huggingface import HuggingFaceEmbeddings
# 创建嵌入模型
model_name = r'D:\LLM\Local_model\BAAI\bge-large-zh-v1___5'
# 生成的嵌入向量将被标准化, 有助于向量比较
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
encode_kwargs=encode_kwargs
)
text = "大模型"
query_result = embeddings.embed_query(text)
print(query_result[:5])
-
通过Hugging Face官方包的加持,开发小伙伴们通过简单的api调用就能在langchain中轻松使用Hugging Face上各类流行的开源大语言模型以及各类AI工具
-
访问:HuggingFace(
https://huggingface.co/settings/tokens),在个人设置中心,创建一个API Token
import os
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from dotenv import load_dotenv
load_dotenv()
ENDPOINT_URL = "Qwen/Qwen3-8B"
# ENDPOINT_URL = "deepseek-ai/DeepSeek-R1"
HF_TOKEN = os.getenv('HF_TOKEN')
llm = HuggingFaceEndpoint(
endpoint_url=ENDPOINT_URL,
# max_new_tokens=30, 限制生成的最大 token 数量为 30 个
typical_p=0.95, # 控制输出文本的多样性,避免生成太过常见或太过罕见的 tokens
temperature=0.01,
repetition_penalty=1.03, # 对重复出现的 tokens 施加惩罚,避免生成重复的内容
huggingfacehub_api_token=HF_TOKEN
)
# 生成key时需要把权限都点上
chat_model = ChatHuggingFace(llm=llm)
resp = chat_model.invoke("解释 prompt 是什么?")
print(resp)2.4 输出解析器
输出解析器负责获取 LLM 的输出并将其转换为更合适的格式。借助LangChain的输出解析器重构程序,使模型能够生成结构化回应,并可以直接解析这些回应
LangChain有许多不同类型的输出解析器
-
CSV解析器:CommaSeparatedListOutputParser,模型的输出以逗号分隔,以列表形式返回输出
-
JSON解析器:JsonOutputParser,确保输出符合特定JSON对象格式。
-
XML解析器:XMLOutputParser,允许以流行的XML格式从LLM获取结果
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 创建解析器
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser, XMLOutputParser
from langchain.chains import LLMChain # 新增:导入 LLMChain 用于非 LCEL 链式调用
from dotenv import load_dotenv
import os
load_dotenv()
# 初始化语言模型
model = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
)
# output_parser = StrOutputParser()
# output_parser = JsonOutputParser()
xml_parser = XMLOutputParser()
# 提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的程序员"),
("user", "{input}")
])
# 使用 LLMChain 构建链(非 LCEL 方式)
chain = LLMChain(
llm=model,
prompt=prompt,
output_parser=xml_parser # 指定输出解析器
)
res = chain.invoke({"input": "langchain是什么? 使用xml格式输出"})
# res = chain.invoke({"input": "langchain是什么? 问题用question 回答用ans 返回一个JSON格式"})
# res = chain.invoke({"input": "大模型中的langchain是什么?"})
print(res)三. Langchain数据检索
在前面课程中我们已经讲了大模型存在的缺陷:数据不实时,缺少垂直领域数据和私域数据等。解决这些缺陷的主要方法是通过检索增强生成(RAG)。首先检索外部数据,然后在执行生成步骤时将其传递给LLM。
LangChain为RAG应用程序提供了从简单到复杂的所有构建块,本文要学习的数据检索(Retrieval)模块包括与检索步骤相关的所有内容,例如数据的获取、切分、向量化、向量存储、向量检索等模块(见下图)。
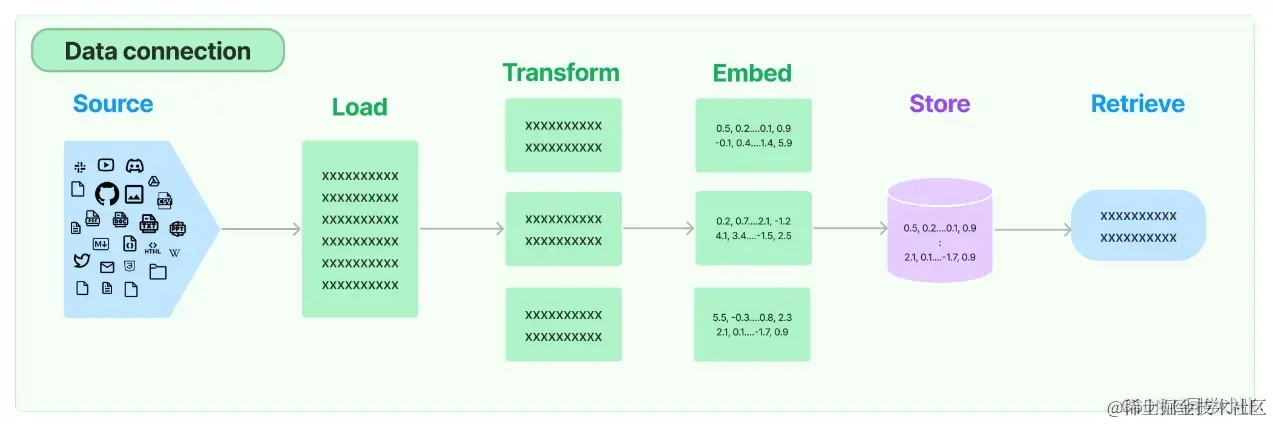
1. Document loaders 文档加载模块
LangChain封装了一系列类型的文档加载模块,例如PDF、CSV、HTML、JSON、Markdown、File Directory等。下面以PDF文件夹在为例看一下用法,其它类型的文档加载的用法都类似。
1.1 加载本地文件
-
LangChain加载PDF文件使用的是pypdf,先安装:
pip install pypdf
pip install unstructured
# 官网:https://docs.unstructured.io/welcome
# 下载时需要开科学上网不然会报错File is not a zip file
# 如果报错开科学上网之后
# import nltk
# nltk.download('punkt')
# nltk.download('averaged_perceptron_tagger')
# 把nltk 重新加载
pip install python-doc
pip install python-docx
# from langchain_community.document_loaders import PyPDFLoader
#
# loader = PyPDFLoader(r"D:\python_project\AI_object\RAG备课\day02\财务管理文档.pdf")
# pages = loader.load_and_split()
#
# print(f"第0页:\n{pages[0]}") ## 也可通过 pages[0].page_content只获取本页内容
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 指定要加载的Word文档路径
loader = UnstructuredWordDocumentLoader(r"D:\python_project\AI_object\RAG备课\day02\人事管理流程.docx")
print(loader)
# 加载文档并分割成段落或元素
documents = loader.load()
print(documents)
# 输出加载的内容
for doc in documents:
print(doc.page_content)
# 需要科学上网需要下载一个包 punkt_tab 1.2 加载在线PDF文件
-
LangChain也能加载在线的PDF文件。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructured
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdf2image
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructured-inference
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pikepdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://arxiv.org/pdf/2302.03803.pdf")
data = loader.load()
print(f"第0页:\n{data[0].page_content}") # 也可通过 pages[0].page_content只获取本页内容
# 需要注意科学上网2. 文档切分模块
-
LangChain提供了许多不同类型的文本切分器,具体见下表:

这里以Recursive为例展示用法。RecursiveCharacterTextSplitter是LangChain对这种文档切分方式的封装,里面的几个重点参数:
-
chunk_size:每个切块的token数量
-
chunk_overlap:相邻两个切块之间重复的token数量
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PyPDFLoader("财务管理文档.pdf")
pages = loader.load_and_split()
# print(f"第0页:\n{pages[0].page_content}")
# print(pages)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=100,
length_function=len,
)
# [pages[1].page_content]
# print([page.page_content for page in pages if pages])
paragraphs = text_splitter.create_documents([page.page_content.replace('\n', '').replace(' ', '') for page in pages if pages])
print(paragraphs)
for para in paragraphs:
print(para.page_content)
print('-------', len(para.page_content))
-
以上示例程序将chunk_overlap设置为100,看下运行效果,可以看到上一个chunk和下一个chunk会有一部分的信息重合,这样做的原因是尽可能地保证两个chunk之间的上下文关系:
这里提供了一个可视化展示文本如何分割的工具,感兴趣的可以看下。
3. 文本向量化模型封装
-
LangChain对一些文本向量化模型的接口做了封装,例如OpenAI, Cohere, Hugging Face等。 向量化模型的封装提供了两种接口,一种针对文档的向量化
embed_documents,一种针对句子的向量化embed_query。 -
示例代码:
-
文档的向量化
embed_documents,接收的参数是字符串数组
-
from langchain_community.embeddings import DashScopeEmbeddings
import os
from dotenv import load_dotenv
load_dotenv()
embeddings_model = DashScopeEmbeddings(dashscope_api_key=os.getenv('api_key'))
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
print(len(embeddings), len(embeddings[0]), len(embeddings[1]))
##运行结果 (5, 1536)4. 向量存储
-
将文本向量化之后,下一步就是进行向量的存储。 这部分包含两块:一是向量的存储。二是向量的查询。
-
官方提供了三种开源、免费的可用于本地机器的向量数据库示例(chroma、FAISS、 Lance)。因为我在之前RAG的文章中用的chroma数据库,所以这里还是以这个数据库为例。
import os
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from dotenv import load_dotenv
load_dotenv()
# 读取文件
loader = PyPDFLoader("财务管理文档.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
# 将数据进行切割成块
paragraphs = text_splitter.create_documents([page.page_content for page in pages if pages])
print(paragraphs)
# 创建嵌入模型
model_name = r'D:\LLM\Local_model\BAAI\bge-large-zh-v1___5'
embeddings = HuggingFaceEmbeddings(model_name=model_name)
# 创建chroma数据库,并将文本数据个向量化的数据存入
db = Chroma.from_documents(paragraphs, embeddings, persist_directory="chroma_db") # 一行代码搞定
# 在数据库中进行搜索
query = "会计核算基础规范"
docs = db.similarity_search(query) # 一行代码搞定
for doc in docs:
print(f"{doc}\n-------\n")5. Retrievers 检索器
-
检索器是在给定非结构化查询的情况下返回相关文本的接口。它比Vector stores更通用。检索器不需要能够存储文档,只需要返回(或检索)文档即可。Vector stores可以用作检索器的主干,但也有其他类型的检索器。检索器接受字符串查询作为输入,并返回文档列表作为输出。
-
检索器(Retrievers) 是一个用于从文档集合中检索最相关文档或信息片段的关键组件。它们通常与向量存储(Vector Stores)结合使用,通过计算查询向量与存储中的文档向量之间的相似度来实现高效的语义搜索。简单来说,检索器帮助你找到与特定查询最相关的文档。
-
LangChain检索器提供的检索类型如下:
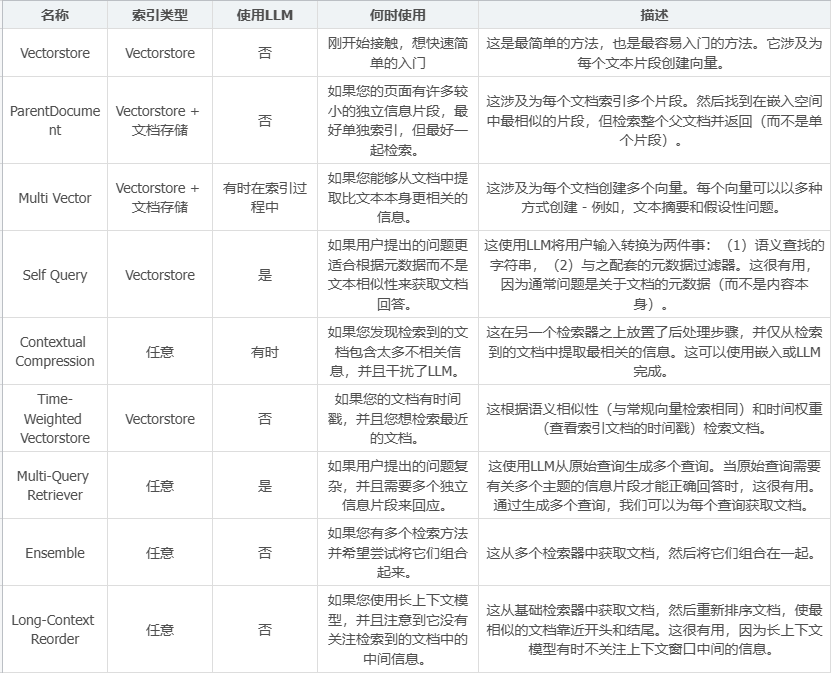
import os
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 创建嵌入模型
model_name = r"D:\LLM\Local_model\BAAI\bge-large-zh-v1___5"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
# 加载现有 Chroma 数据库
persist_directory = "./chroma_db"
db = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
print(f"成功加载 Chroma 数据库从 {persist_directory}")
# 实例化检索器
retriever = db.as_retriever(search_kwargs={"k": 4}) # 设置返回文档数量
# 获取问题相关文档
query = "会计核算基础规范"
docs = retriever.invoke(query)
for i, doc in enumerate(docs, 1):
print(f"结果 {i}:\n{doc.page_content}")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)