Diffusion 扩散模型知识体系梳理(二)
Diffusion 扩散模型知识体系 Part 2
博客笔记逻辑示意图:
1. 关于扩散模型的直觉理解
见《Diffusion 扩散模型知识体系梳理(一)》
2. 从 DDPM 的角度看离散 Diffusion
见《Diffusion 扩散模型知识体系梳理(一)》
3. 从 Score-based 的角度再看 Diffusion
3.1. 如何对目标与环境建模?
- 好的,上来让我们放下先前所有对扩散模型所谓正向加噪/逆向去噪的理解,从另一个角度来审视生成模型这个课题。
- 从本质上讲,我们认为大自然中万物数据 x \mathbf{x} x 都会存在一种分布关系 p ( x ) p(\mathbf{x}) p(x),这是我们无法进行精确量化的,所以生成模型则会基于我们能够获取到的数据集 { x 1 , x 2 , ⋯ , x n } \{\mathbf{x}_1,\mathbf{x}_2,\cdots,\mathbf{x}_n\} {x1,x2,⋯,xn},去尝试用网络拟合这样的分布 p θ ( x ) p_{\theta}(\mathbf{x}) pθ(x)。然后,我们知道任何一种概率分布都需要满足归一性与非负性,所以在此处,我们可以为 p θ ( x ) p_\theta(\mathbf{x}) pθ(x) 构建一种模型的形态 p θ ( x ) = e − f θ ( x ) Z θ , where ∫ p θ ( x ) d x = 1 , Z θ = ∫ e − f θ ( x ) d x p_\theta(\mathbf{x}) = \frac{e^{-f_\theta(\mathbf{x})}}{Z_\theta} ,\,\text{where}\;\int{p_\theta(\textbf{x})\,d\textbf{x}} = 1,\;Z_\theta = \int e^{-f_\theta(\textbf{x})}\,d\textbf{x} pθ(x)=Zθe−fθ(x),where∫pθ(x)dx=1,Zθ=∫e−fθ(x)dx 此处的 f θ f_\theta fθ 可以称之为非归一化概率模型,或者能量模型(Energy-Based Model)。
3.2. 如何确定网络学习的目标 ?
- 所以此时我们会关注到,如果我们希望 p θ p_\theta pθ 尽可能准确,可以通过最大化似然的方式来描述,同时出于指数幂次连乘变连加的考虑,加上对数作为目标方向(Maximize the log-likelihood): max θ ∑ i = 1 N log p θ ( x i ) \max_{\theta}\sum^N_{i=1}\log p_\theta(x_i) θmaxi=1∑Nlogpθ(xi)
- 然而,上面的式子要求 p θ ( x ) p_\theta(\mathbf{x}) pθ(x) 是一个经过归一化的概率密度函数。这是我们不希望看到的,因为为了计算 p θ ( x ) p_\theta(\mathbf{x}) pθ(x),我们必须求出归一化常数 Z θ Z_\theta Zθ ,但是对于任何一般的函数 f θ ( x ) f_\theta(\mathbf{x}) fθ(x) 来说,这通常是一个难以计算的量(前人只能通过 VAE 自回归或者 MCMC 采样近似估计等方式处理)。所以我们进行下面的这种定义,可以巧妙地用对数的性质消去常数 Z θ Z_\theta Zθ,这就是 Hyvärinen [4] 提出的 Score Matching 的核心思想: s θ ( x ) = ∇ x log p θ ( x ) = − ∇ x f θ ( x ) − ∇ x log Z θ ⏟ = 0 = − ∇ x f θ ( x ) \mathbf{s}_\theta(\mathbf{x}) = \nabla_{\mathbf{x}} \log p_\theta(\mathbf{x}) = -\nabla_{\mathbf{x}} f_\theta(\mathbf{x}) - \underbrace{\nabla_{\mathbf{x}} \log Z_\theta}_{=0} = -\nabla_{\mathbf{x}} f_\theta(\mathbf{x}) sθ(x)=∇xlogpθ(x)=−∇xfθ(x)−=0 ∇xlogZθ=−∇xfθ(x)
3.3. 如何构建损失函数 ?
- 很好,那在知道了模型拟合的目标之后,就该要去定义相应的损失函数了。由上文可知,我们为了避开无法计算的 Z θ Z_\theta Zθ,采用 Fisher Divergence 作为模型预测的 Loss Function: J ( θ ) = E p data ( x ) [ 1 2 ∣ ∣ s θ ( x ) − ∇ x log p data ( x ) ) ∣ ∣ 2 2 ] \mathcal{J}(\theta) = \mathbb{E}_{p_{\text{data}}(\textbf{x})}[\,\frac{1}{2}||s_\theta(\textbf{x})-\nabla_{\textbf{x}}\log p_{\text{data}}(\textbf{x}))||^2_2\,] J(θ)=Epdata(x)[21∣∣sθ(x)−∇xlogpdata(x))∣∣22]
- 可是问题是,此时我们还是无法知道我们需要的真实数据分布,但是经过一段巧妙地数学推导(见 Appendix A)上述损失函数可以转化为等价的显式得分匹配 (Explicit Score Matching) 目标: J ( θ ) = E p data ( x ) [ 1 2 ∣ ∣ s θ ( x ) ∣ ∣ 2 + tr ( ∇ x s θ ( x ) ) ] \mathcal{J}(\theta) = \mathbb{E}_{p_{\text{data}}(\textbf{x})}[\,\frac{1}{2}||s_\theta(\textbf{x})||^2+\text{tr}(\nabla_{\textbf{x}}s_\theta(\textbf{x}))\,] J(θ)=Epdata(x)[21∣∣sθ(x)∣∣2+tr(∇xsθ(x))]
- 这一绝妙的转化使得损失函数不再依赖于真实数据分布的解析形式。在理论上,我们可以直接通过在训练集上采样 x \textbf{x} x 来近似该期望。但是,由于计算高维雅可比矩阵的迹 tr ( ∇ x s θ ( x ) ) \text{tr}(\nabla_{\textbf{x}}s_\theta(\textbf{x})) tr(∇xsθ(x)) 存在难以承受的计算开销,该方法很难直接应用于高维数据(如图像)。实际工程上,通常有两种解决办法,分别是 Pascal Vincent [5] 提出的 Denoising Score Matching (DSM, 去噪得分匹配,严格推导见 Appendix B),另一条是 Yang Song et al. [6] 提出的 Sliced Score Matching (SSM, 切片得分匹配,其核心思想是用随机投影向量将高维散度降为一维方向导数,从而避免计算完整的雅可比矩阵,此处不展开)。
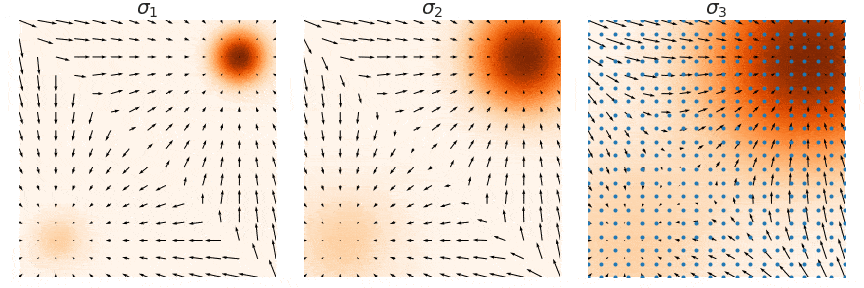
3.4. 如何进行采样推理?
- 假设我的模型已经训练好了,分析一下,我们本质上获得的是一个向量场,时刻告诉我们概率密度增加最快的方向是哪里,你可以把它想象成高维势能面上的重力线,它永远指向“更像真实数据”的高密度区域。当我们一直沿着 ∇ x log p ( x ) \nabla_{\textbf{x}} \log{p(\textbf{x})} ∇xlogp(x) 的方向移动时,最终会确定性地停留在某一个概率密度的峰值(mode),但是这往往并非想要寻找的真实数据分布,所以我们需要在每一步的过程中都添加一项布朗运动。而这个靠近的过程迭代,是基于朗之万动力学(Langevin Dynamics) 所构造的,公式如下: x i + 1 ← x i + ϵ 2 ⋅ ∇ x log p ( x ) + ϵ ⋅ z i , where i = 1 ∼ k , z i ∼ N ( 0 , I ) x_{i+1} \leftarrow x_i + \frac{\epsilon}{2}·\nabla_{\textbf{x}} \log{p(\textbf{x})}+\sqrt{\epsilon}·z_i,\,\text{where}\;i=1 \sim k,\,z_i \sim \mathcal{N}(0,I) xi+1←xi+2ϵ⋅∇xlogp(x)+ϵ⋅zi,wherei=1∼k,zi∼N(0,I)
- 当然,理想很丰满,现实很骨感,实验发现,如果拿着上面的公式去生成,大概率会得到一堆充满噪点的无意义色块,原因在于真实的物理世界数据(比如人脸图片)在高维空间中满足流形假设 (Manifold Hypothesis)。真实数据只占据高维空间中极其狭窄、低维的流形“薄膜”,而薄膜之外的广袤空间里,真实数据的概率 p ( x ) ≈ 0 p(\textbf{x}) \approx 0 p(x)≈0。这会导致两个问题:
- 梯度消失或未定义:在纯噪声区域,网络根本没见过这些数据, s θ ( x ) \textbf{s}_\theta(\textbf{x}) sθ(x) 的预测是完全瞎猜的,或者梯度为 0。
- 孤岛效应: 即使网络预测准了,不同模式(比如“猫”的流形和“狗”的流形)之间是被概率为 0 的大块区域隔开的。朗之万动力学的噪声无法跨越这片区域,导致采样极易卡死在一个局部流形里出不来。
3.5. 如何解决流形分布的问题?
- 研究者们 [7] 提出的方案,是利用噪声对数据点进行扰动,并在这些带噪的数据点上训练基于分数的模型。当噪声的幅度足够大时,它能够填充数据低密度的区域,从而提高估计得分的准确性。至于噪声的分布方差,由于数据集的差异性过大,所以选取从小到大的一组方差序列 { σ 1 , σ 2 , ⋯ , σ L } \{\sigma_1,\sigma_2,\cdots,\sigma_L\} {σ1,σ2,⋯,σL},通过与原始数据分布进行卷积: p σ i ( x ) = ∫ p ( y ) N ( x ; y , σ i 2 I ) d y p_{\sigma_i}(\mathbf{x}) = \int p(\mathbf{y})\,\mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 \mathbf{I})\,d\mathbf{y} pσi(x)=∫p(y)N(x;y,σi2I)dy 其中 N ( x ; y , σ i 2 I ) \mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 \mathbf{I}) N(x;y,σi2I) 是一个以 y \mathbf{y} y 为均值、 σ i 2 \sigma_i^2 σi2 为方差的高斯分布核。它代表了加在数据上的噪声。至于卷积操作,在代码中只需要从训练集中抽取一个样本 y \textbf{y} y,再加上相应强度的噪声即可 y + σ i z ∼ p σ i ( x ) \textbf{y}+\sigma_i \textbf{z} \sim p_{\sigma_i}(\textbf{x}) y+σiz∼pσi(x)。
- 自然我们也需要重构一下前面设定的模型训练目标和训练损失函数。我们定义了噪声条件评分模型 Noise Conditional Score-Based Model,也即 s θ ( x , i ) s_\theta(\textbf{x},i) sθ(x,i)。而损失函数同样沿用 Fisher Divergence 的思路,公式定义如下: J ( θ ) = ∑ i = 1 N λ ( i ) E p σ i ( x ) [ 1 2 ∣ ∣ s θ ( x , i ) − ∇ x log p σ i ( x ) ) ∣ ∣ 2 2 ] \mathcal{J}(\theta) = \sum^N_{i=1}\lambda(i)\,\mathbb{E}_{p_{\sigma_i}(\textbf{x})}[\,\frac{1}{2}||s_\theta(\textbf{x},i)-\nabla_{\textbf{x}}\log p_{\sigma_i}(\textbf{x}))||^2_2\,] J(θ)=i=1∑Nλ(i)Epσi(x)[21∣∣sθ(x,i)−∇xlogpσi(x))∣∣22] 其中加权系数 λ ( i ) ∝ σ i 2 \lambda(i) \propto \sigma_i^2 λ(i)∝σi2,这么做的目的是为了平衡不同噪声尺度下的损失函数,可以从下面这个维度来理解。假设添加噪声之后的 x \textbf{x} x 是满足高斯分布的,那么有: p ( x ∣ y ) = N ( x ; y , σ i 2 I ) = 1 ( 2 π σ i 2 ) d / 2 exp ( − ∥ x − y ∥ 2 2 2 σ i 2 ) p(\mathbf{x}|\mathbf{y}) = \mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 \mathbf{I}) = \frac{1}{(2\pi \sigma_i^2)^{d/2}} \exp \left( -\frac{\| \mathbf{x} - \mathbf{y} \|_2^2}{2\sigma_i^2} \right) p(x∣y)=N(x;y,σi2I)=(2πσi2)d/21exp(−2σi2∥x−y∥22) 取对数后: log p ( x ∣ y ) = − d 2 log ( 2 π σ i 2 ) ⏟ 常数 C − ∥ x − y ∥ 2 2 2 σ i 2 \log p(\mathbf{x}|\mathbf{y}) = \underbrace{-\frac{d}{2} \log(2\pi \sigma_i^2)}_{\text{常数 } C} - \frac{\| \mathbf{x} - \mathbf{y} \|_2^2}{2\sigma_i^2} logp(x∣y)=常数 C −2dlog(2πσi2)−2σi2∥x−y∥22 利用链式法则,注意到 ∇ x ∥ x − y ∥ 2 2 = 2 ( x − y ) \nabla_{\mathbf{x}} \| \mathbf{x} - \mathbf{y} \|_2^2 = 2(\mathbf{x} - \mathbf{y}) ∇x∥x−y∥22=2(x−y): ∇ x log p ( x ∣ y ) = 0 − 1 2 σ i 2 ⋅ ∇ x ( x − y ) T ( x − y ) = − 1 2 σ i 2 ⋅ 2 ( x − y ) = − x − y σ i 2 \begin{aligned}\nabla_{\mathbf{x}} \log p(\mathbf{x}|\mathbf{y}) &= 0 - \frac{1}{2\sigma_i^2} \cdot \nabla_{\mathbf{x}} (\mathbf{x} - \mathbf{y})^T (\mathbf{x} - \mathbf{y}) \\ &= -\frac{1}{2\sigma_i^2} \cdot 2(\mathbf{x} - \mathbf{y}) = -\frac{\mathbf{x} - \mathbf{y}}{\sigma_i^2} \end{aligned} ∇xlogp(x∣y)=0−2σi21⋅∇x(x−y)T(x−y)=−2σi21⋅2(x−y)=−σi2x−y 因为我们知道 x = y + σ i z \mathbf{x} = \mathbf{y} + \sigma_i \mathbf{z} x=y+σiz(其中 z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(0, \mathbf{I}) z∼N(0,I)),代入上式即可知道条件 score 的 L2 范数期望 E [ ∥ ∇ x log p ( x ∣ y ) ∥ 2 ] = d σ i 2 \mathbb{E}[\|\nabla_\mathbf{x} \log p(\mathbf{x}|\mathbf{y})\|^2] = \frac{d}{\sigma_i^2} E[∥∇xlogp(x∣y)∥2]=σi2d( d d d 为数据维度),所以 λ ( i ) ∝ σ i 2 \lambda(i) \propto \sigma_i^2 λ(i)∝σi2 的选取恰好能抵消这个量级差异,使得不同噪声尺度下的损失贡献大致均衡: ∇ x log p ( x ∣ y ) = − ( y + σ i z ) − y σ i 2 = − σ i z σ i 2 = − z σ i \nabla_{\mathbf{x}} \log p(\mathbf{x}|\mathbf{y}) = -\frac{(\mathbf{y} + \sigma_i \mathbf{z}) - \mathbf{y}}{\sigma_i^2} = -\frac{\sigma_i \mathbf{z}}{\sigma_i^2} = -\frac{\mathbf{z}}{\sigma_i} ∇xlogp(x∣y)=−σi2(y+σiz)−y=−σi2σiz=−σiz 但是这里面需要注意的一点是,我们之所以可以用条件分布来估计边缘分布,主要是因为在期望意义上,优化 “模型与条件分布评分的距离”等价于优化“模型与边缘分布评分的距离” ,数学表达式如下: E p σ i ( x , y ) [ ∥ s θ ( x , i ) − ∇ x log p ( x ∣ y ) ∥ 2 2 ] = E p σ i ( x ) [ ∥ s θ ( x , i ) − ∇ x log p σ i ( x ) ∥ 2 2 ] + C \mathbb{E}_{p_{\sigma_i}(\mathbf{x}, \mathbf{y})} \left[ \| \mathbf{s}_\theta(\mathbf{x}, i) - \nabla_{\mathbf{x}} \log p(\mathbf{x}|\mathbf{y}) \|_2^2 \right] = \mathbb{E}_{p_{\sigma_i}(\mathbf{x})} \left[ \| \mathbf{s}_\theta(\mathbf{x}, i) - \nabla_{\mathbf{x}} \log p_{\sigma_i}(\mathbf{x}) \|_2^2 \right] + C Epσi(x,y)[∥sθ(x,i)−∇xlogp(x∣y)∥22]=Epσi(x)[∥sθ(x,i)−∇xlogpσi(x)∥22]+C
3.6. 退火朗之万动力学采样
- 针对于前文构造的噪声条件评分模型,我们也应该相应的为之调整一下采样的模式,称之为退火朗之万动力学采样 Annealed Langevin Dynamics。在此所谓的退火,就表示模型会先在较大层面的噪声中确定宏观的轮廓和区域,随后随着噪声的波动越来越小,逐渐锁定迭代到最优的位置。
- 第一步,先从纯噪声中随机初始化一个起始点 x L 0 ∼ N ( 0 , σ L 2 I ) \mathbf{x}_L^0 \sim \mathcal{N}(0, \sigma_L^2 \mathbf{I}) xL0∼N(0,σL2I),此时的 x \mathbf{x} x 看起来就是完全的随机白噪声。
- 第二步,我们考虑从大噪声到小噪声, i = L , L − 1 , … , 1 i = L, L-1, \dots, 1 i=L,L−1,…,1,利用当前噪声尺度计算采样的步长 α i = ϵ ⋅ σ i 2 / σ L 2 \alpha_i = \epsilon \cdot \sigma_i^2 / \sigma_L^2 αi=ϵ⋅σi2/σL2。
- 第三步,对于时间步 t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T 运行下面迭代公式: x t = x t − 1 + α i 2 s θ ( x t − 1 , i ) + α i z t \mathbf{x}_t = \mathbf{x}_{t-1} + \frac{\alpha_i}{2} \mathbf{s}_\theta(\mathbf{x}_{t-1}, i) + \sqrt{\alpha_i} \mathbf{z}_t xt=xt−1+2αisθ(xt−1,i)+αizt
Appendix
Appendix A:Score Matching 到显式目标的严格推导
-
下面我们的目标是证明: J Fisher ( θ ) = E p ( x ) [ 1 2 ∥ s θ ( x ) − ∇ x log p ( x ) ∥ 2 ] ⟺ J ESM ( θ ) = E p ( x ) [ 1 2 ∥ s θ ( x ) ∥ 2 + ∇ ⋅ s θ ( x ) ] \mathcal{J}_{\text{Fisher}}(\theta)=\mathbb{E}_{p(\mathbf{x})}\left[\frac12\|s_\theta(\mathbf{x})-\nabla_{\mathbf{x}}\log p(\mathbf{x})\|^2\right] \; \Longleftrightarrow \; \mathcal{J}_{\text{ESM}}(\theta)=\mathbb{E}_{p(\mathbf{x})}\left[\frac12\|s_\theta(\mathbf{x})\|^2+\nabla\cdot s_\theta(\mathbf{x})\right] JFisher(θ)=Ep(x)[21∥sθ(x)−∇xlogp(x)∥2]⟺JESM(θ)=Ep(x)[21∥sθ(x)∥2+∇⋅sθ(x)]二者只差与 θ \theta θ 无关的常数项。为避免符号冗余,以下记 p ( x ) ≡ p data ( x ) p(\mathbf{x})\equiv p_{\text{data}}(\mathbf{x}) p(x)≡pdata(x), s θ ( x ) ≡ s θ ( x ) \mathbf{s}_\theta(\mathbf{x})\equiv s_\theta(\mathbf{x}) sθ(x)≡sθ(x)。
-
首先展开平方项: J Fisher ( θ ) = E p [ 1 2 ∥ s θ ∥ 2 − s θ ⊤ ∇ log p + 1 2 ∥ ∇ log p ∥ 2 ] . \mathcal{J}_{\text{Fisher}}(\theta) =\mathbb{E}_p\!\left[\frac12\|\mathbf{s}_\theta\|^2-\mathbf{s}_\theta^\top\nabla\log p+\frac12\|\nabla\log p\|^2\right]. JFisher(θ)=Ep[21∥sθ∥2−sθ⊤∇logp+21∥∇logp∥2]. 其中最后一项 C p ≜ 1 2 E p ∥ ∇ log p ∥ 2 C_p\triangleq \frac12\mathbb{E}_p\|\nabla\log p\|^2 Cp≜21Ep∥∇logp∥2与模型参数 θ \theta θ 无关,可视作常数。关键在交叉项: I ( θ ) = E p [ s θ ⊤ ∇ log p ] = ∫ s θ ( x ) ⊤ ∇ p ( x ) d x . I(\theta)=\mathbb{E}_p\left[\mathbf{s}_\theta^\top\nabla\log p\right] =\int \mathbf{s}_\theta(\mathbf{x})^\top\nabla p(\mathbf{x})\,d\mathbf{x}. I(θ)=Ep[sθ⊤∇logp]=∫sθ(x)⊤∇p(x)dx.
-
利用散度恒等式我们可以得到: ∇ ⋅ ( p s θ ) = s θ ⊤ ∇ p + p ∇ ⋅ s θ ⟹ s θ ⊤ ∇ p = ∇ ⋅ ( p s θ ) − p ∇ ⋅ s θ . \nabla\cdot\big(p\mathbf{s}_\theta\big)=\mathbf{s}_\theta^\top\nabla p+p\,\nabla\cdot\mathbf{s}_\theta \; \Longrightarrow \; \mathbf{s}_\theta^\top\nabla p=\nabla\cdot\big(p\mathbf{s}_\theta\big)-p\,\nabla\cdot\mathbf{s}_\theta. ∇⋅(psθ)=sθ⊤∇p+p∇⋅sθ⟹sθ⊤∇p=∇⋅(psθ)−p∇⋅sθ.代回积分得: I ( θ ) = ∫ ∇ ⋅ ( p s θ ) d x − ∫ p ∇ ⋅ s θ d x . I(\theta)=\int \nabla\cdot\big(p\mathbf{s}_\theta\big)\,d\mathbf{x}-\int p\,\nabla\cdot\mathbf{s}_\theta\,d\mathbf{x}. I(θ)=∫∇⋅(psθ)dx−∫p∇⋅sθdx.若满足常见边界条件(如 p ( x ) s θ ( x ) p(\mathbf{x})\mathbf{s}_\theta(\mathbf{x}) p(x)sθ(x) 在无穷远处衰减足够快),由散度定理有 ∫ ∇ ⋅ ( p s θ ) d x = 0 , \int \nabla\cdot\big(p\mathbf{s}_\theta\big)\,d\mathbf{x}=0, ∫∇⋅(psθ)dx=0,因此 I ( θ ) = − E p [ ∇ ⋅ s θ ( x ) ] . I(\theta)=-\mathbb{E}_p\left[\nabla\cdot\mathbf{s}_\theta(\mathbf{x})\right]. I(θ)=−Ep[∇⋅sθ(x)]. 所以我们最终得到: J Fisher ( θ ) = E p [ 1 2 ∥ s θ ∥ 2 + ∇ ⋅ s θ ] + C p . \mathcal{J}_{\text{Fisher}}(\theta) =\mathbb{E}_p\left[\frac12\|\mathbf{s}_\theta\|^2+\nabla\cdot\mathbf{s}_\theta\right]+C_p. JFisher(θ)=Ep[21∥sθ∥2+∇⋅sθ]+Cp.忽略常数 C p C_p Cp 即得显式得分匹配目标: J ESM ( θ ) = E p [ 1 2 ∥ s θ ( x ) ∥ 2 + tr ( ∇ x s θ ( x ) ) ] . \boxed{\mathcal{J}_{\text{ESM}}(\theta)=\mathbb{E}_p\left[\frac12\|\mathbf{s}_\theta(\mathbf{x})\|^2+\operatorname{tr}(\nabla_{\mathbf{x}}\mathbf{s}_\theta(\mathbf{x}))\right]}. JESM(θ)=Ep[21∥sθ(x)∥2+tr(∇xsθ(x))].解释:该式不再显式依赖未知的 ∇ log p \nabla\log p ∇logp,但代价是需要计算散度(Jacobian 迹),这正是高维场景下 ESM 难以直接工程化的根源。
Appendix B:DSM 等价性与 DDPM 的噪声预测目标
-
记加噪核 q σ ( x ~ ∣ x ) = N ( x ~ ; x , σ 2 I ) , q σ ( x ~ ) = ∫ q σ ( x ~ ∣ x ) p ( x ) d x . q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})=\mathcal{N}(\tilde{\mathbf{x}};\mathbf{x},\sigma^2\mathbf{I}), \qquad q_\sigma(\tilde{\mathbf{x}})=\int q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})p(\mathbf{x})d\mathbf{x}. qσ(x~∣x)=N(x~;x,σ2I),qσ(x~)=∫qσ(x~∣x)p(x)dx. DSM 目标是 J DSM ( θ ) = E p ( x ) q σ ( x ~ ∣ x ) [ 1 2 ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 ] . \mathcal{J}_{\text{DSM}}(\theta) = \mathbb{E}_{p(\mathbf{x})q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})} \left[ \frac12\left\|s_\theta(\tilde{\mathbf{x}})-\nabla_{\tilde{\mathbf{x}}}\log q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})\right\|^2 \right]. JDSM(θ)=Ep(x)qσ(x~∣x)[21∥sθ(x~)−∇x~logqσ(x~∣x)∥2].
-
假设 u ( x ~ , x ) ≜ ∇ x ~ log q σ ( x ~ ∣ x ) , u ˉ ( x ~ ) ≜ E [ u ( x ~ , x ) ∣ x ~ ] . \mathbf{u}(\tilde{\mathbf{x}},\mathbf{x})\triangleq \nabla_{\tilde{\mathbf{x}}}\log q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x}), \qquad \bar{\mathbf{u}}(\tilde{\mathbf{x}})\triangleq\mathbb{E}[\mathbf{u}(\tilde{\mathbf{x}},\mathbf{x})\mid\tilde{\mathbf{x}}]. u(x~,x)≜∇x~logqσ(x~∣x),uˉ(x~)≜E[u(x~,x)∣x~].对平方项做条件方差分解: E ∥ s θ − u ∥ 2 = E ∥ s θ − u ˉ ∥ 2 + E ∥ u − u ˉ ∥ 2 . \mathbb{E}\|s_\theta-\mathbf{u}\|^2 =\mathbb{E}\|s_\theta-\bar{\mathbf{u}}\|^2+\mathbb{E}\|\mathbf{u}-\bar{\mathbf{u}}\|^2. E∥sθ−u∥2=E∥sθ−uˉ∥2+E∥u−uˉ∥2. 第二项与 θ \theta θ 无关,因此最优解由第一项决定。所以此时只需证明 u ˉ ( x ~ ) = ∇ x ~ log q σ ( x ~ ) . \bar{\mathbf{u}}(\tilde{\mathbf{x}})=\nabla_{\tilde{\mathbf{x}}}\log q_\sigma(\tilde{\mathbf{x}}). uˉ(x~)=∇x~logqσ(x~). 由 Bayes 与求导交换可得下式,两边除以 q σ ( x ~ ) q_\sigma(\tilde{\mathbf{x}}) qσ(x~) 即得结论。: ∇ x ~ q σ ( x ~ ) = ∫ ∇ x ~ q σ ( x ~ ∣ x ) p ( x ) d x = ∫ q σ ( x ~ ∣ x ) u ( x ~ , x ) p ( x ) d x , \nabla_{\tilde{\mathbf{x}}}q_\sigma(\tilde{\mathbf{x}}) =\int \nabla_{\tilde{\mathbf{x}}}q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})p(\mathbf{x})d\mathbf{x} =\int q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x})\mathbf{u}(\tilde{\mathbf{x}},\mathbf{x})p(\mathbf{x})d\mathbf{x}, ∇x~qσ(x~)=∫∇x~qσ(x~∣x)p(x)dx=∫qσ(x~∣x)u(x~,x)p(x)dx,
-
所以 DSM 实际优化的是
E q σ ( x ~ ) [ 1 2 ∥ s θ ( x ~ ) − ∇ log q σ ( x ~ ) ∥ 2 ] + const . \mathbb{E}_{q_\sigma(\tilde{\mathbf{x}})}\left[\frac12\|s_\theta(\tilde{\mathbf{x}})-\nabla\log q_\sigma(\tilde{\mathbf{x}})\|^2\right]+\text{const}. Eqσ(x~)[21∥sθ(x~)−∇logqσ(x~)∥2]+const. -
对高斯核有解析 target: ∇ x ~ log q σ ( x ~ ∣ x ) = − x ~ − x σ 2 . \nabla_{\tilde{\mathbf{x}}}\log q_\sigma(\tilde{\mathbf{x}}\mid\mathbf{x}) =- \frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma^2}. ∇x~logqσ(x~∣x)=−σ2x~−x.令 x ~ = x + σ z \tilde{\mathbf{x}}=\mathbf{x}+\sigma\mathbf{z} x~=x+σz( z ∼ N ( 0 , I ) \mathbf{z}\sim\mathcal{N}(0,\mathbf{I}) z∼N(0,I)),则 J DSM ( θ ) = E p ( x ) , z [ 1 2 ∥ s θ ( x + σ z ) + z σ ∥ 2 ] . \mathcal{J}_{\text{DSM}}(\theta)= \mathbb{E}_{p(\mathbf{x}),\mathbf{z}} \left[\frac12\left\|s_\theta(\mathbf{x}+\sigma\mathbf{z})+\frac{\mathbf{z}}{\sigma}\right\|^2\right]. JDSM(θ)=Ep(x),z[21 sθ(x+σz)+σz 2].
-
DDPM 的 ϵ \epsilon ϵ-prediction 与之对应关系: x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ ∇ x t log q ( x t ∣ x 0 ) = − ϵ 1 − α ˉ t . \mathbf{x}_t=\sqrt{\bar\alpha_t}\,\mathbf{x}_0+\sqrt{1-\bar\alpha_t}\,\boldsymbol\epsilon \Rightarrow \nabla_{\mathbf{x}_t}\log q(\mathbf{x}_t\mid\mathbf{x}_0) =- \frac{\boldsymbol\epsilon}{\sqrt{1-\bar\alpha_t}}. xt=αˉtx0+1−αˉtϵ⇒∇xtlogq(xt∣x0)=−1−αˉtϵ.因此常见参数化 s θ ( x t , t ) = − ϵ θ ( x t , t ) 1 − α ˉ t s_\theta(\mathbf{x}_t,t)=-\frac{\epsilon_\theta(\mathbf{x}_t,t)}{\sqrt{1-\bar\alpha_t}} sθ(xt,t)=−1−αˉtϵθ(xt,t)正是 DSM 形式在离散时间上的实现。
Reference
[4] Hyvärinen, A. (2005). Estimation of Non-Normalized Statistical Models by Score Matching. JMLR, 6, 695–709.
[5] Vincent, P. (2011). A Connection Between Score Matching and Denoising Autoencoders. Neural Computation, 23(7), 1661–1674.
[6] Song, Y., Garg, S., Shi, J., & Ermon, S. (2020). Sliced Score Matching: A Scalable Approach to Density and Score Estimation. UAI 2020.
[7] Song, Y., & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. NeurIPS 2019.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)