奇点算力讲解:大模型推理中,GPU显存为什么这么重要?
在大模型领域,很多人一提到推理,第一反应就是“算力不够”。
但从真实工程实践看,推理阶段真正经常卡住系统的,未必是GPU算力,而往往是GPU显存。
尤其在长上下文、高并发、流式输出逐渐成为常态之后,显存容量、显存带宽以及KV Cache管理能力,正在成为影响推理效率和部署成本的关键因素。
这篇文章就用更直白的方式,聊清楚一个问题:
为什么大模型推理越来越依赖GPU显存?
一、大模型推理,为什么不只是“算得多”?
当前主流大模型大多采用自回归生成机制,也就是一个Token接一个Token往后生成。
这意味着,每生成一个新Token,模型都要参考前面已经生成的历史内容。
如果每一步都把前面的内容重新完整计算一遍,就会出现大量重复计算。上下文越长,重复计算越多,整体开销也会迅速放大。
所以,大模型推理并不是简单的“算一次”,而是一个持续依赖历史信息的过程。
问题也正出在这里:
历史越长,系统负担越重。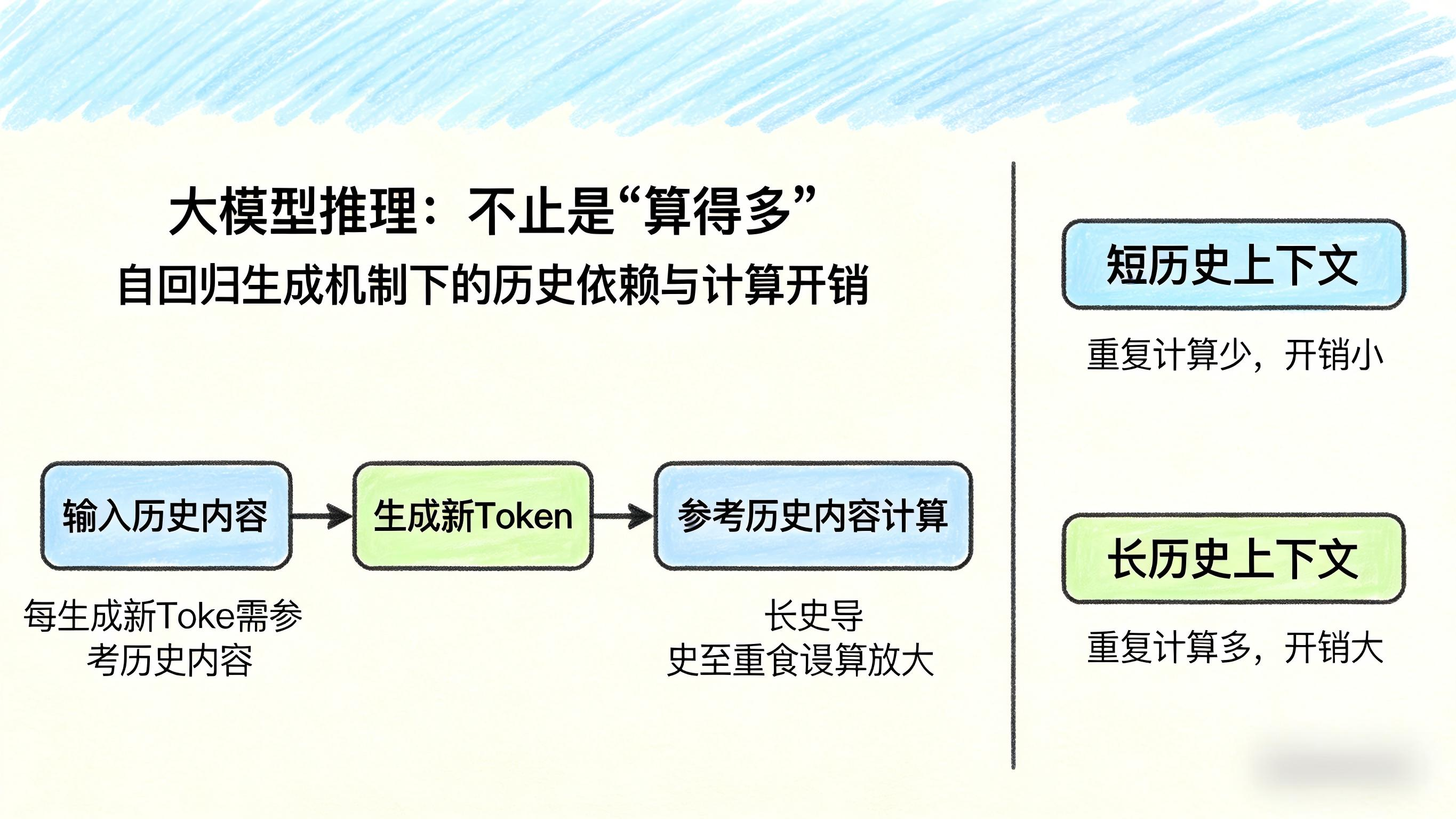
二、KV Cache为什么重要?
为了解决重复计算问题,工程上引入了KV Cache。
在Transformer注意力机制中,每次计算都会生成三组核心信息:
- Q(Query):当前Token的查询
- K(Key):历史Token的特征
- V(Value):历史Token的内容表示
如果没有KV Cache,那么模型每生成一个新Token,都要把历史Token对应的K和V重新算一遍。
而有了KV Cache之后,历史K和V会被提前缓存下来,后续只需要计算当前Token的Q,再直接读取历史缓存进行匹配即可。
这样做有两个直接好处:
- 减少重复计算
- 提升推理速度
但同时也带来了新的问题:
这些缓存下来的K和V,要占用GPU显存。
也就是说,KV Cache越大,显存压力越大。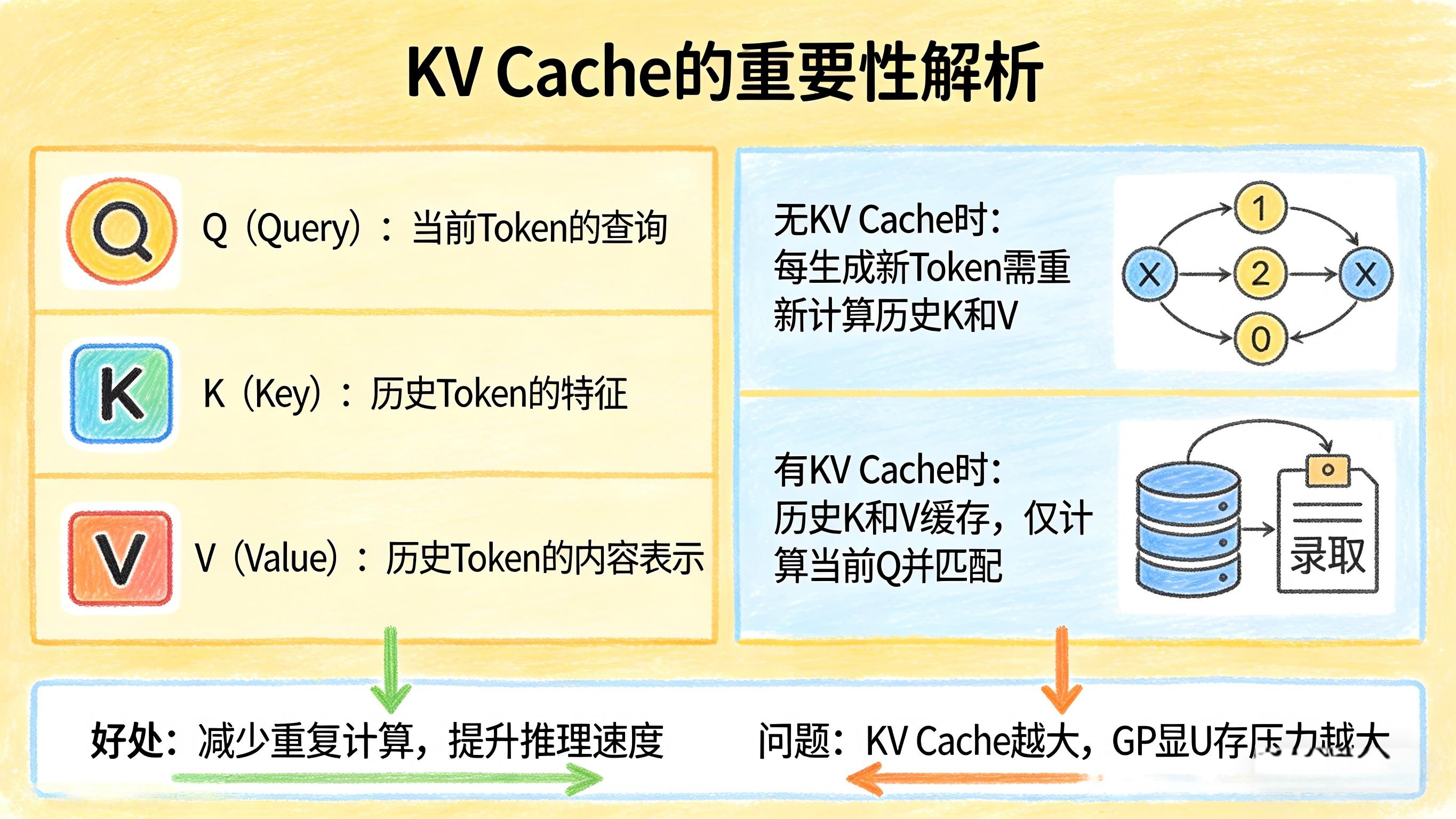
三、为什么说推理分成“拼算力”和“拼显存”两个阶段?
从工程实现看,大模型推理通常分成两个阶段:
1. Prefill阶段:更吃算力
Prefill阶段负责一次性处理用户输入的全部提示词。
模型会完整计算所有输入Token的Q、K、V,并生成初始KV Cache。
这一阶段的特点很明显:
- 计算量大
- GPU核心负载高
- 主要瓶颈在算力
所以,Prefill更像传统意义上的计算密集型任务。
2. Decode阶段:更吃显存
Decode阶段开始逐Token输出答案。
这个阶段单次计算量不算特别大,但每一步都要频繁读取前面已经存下来的大量KV Cache。
所以它真正依赖的,不只是算力,而是:
- 显存容量
- 显存带宽
- 缓存读取效率
也正因为如此,很多推理场景里GPU看起来没满载,但吞吐量就是提不上去。
原因不一定是“算不动”,而往往是“显存读不过来”。
一句话总结就是:
Prefill拼算力,Decode拼显存。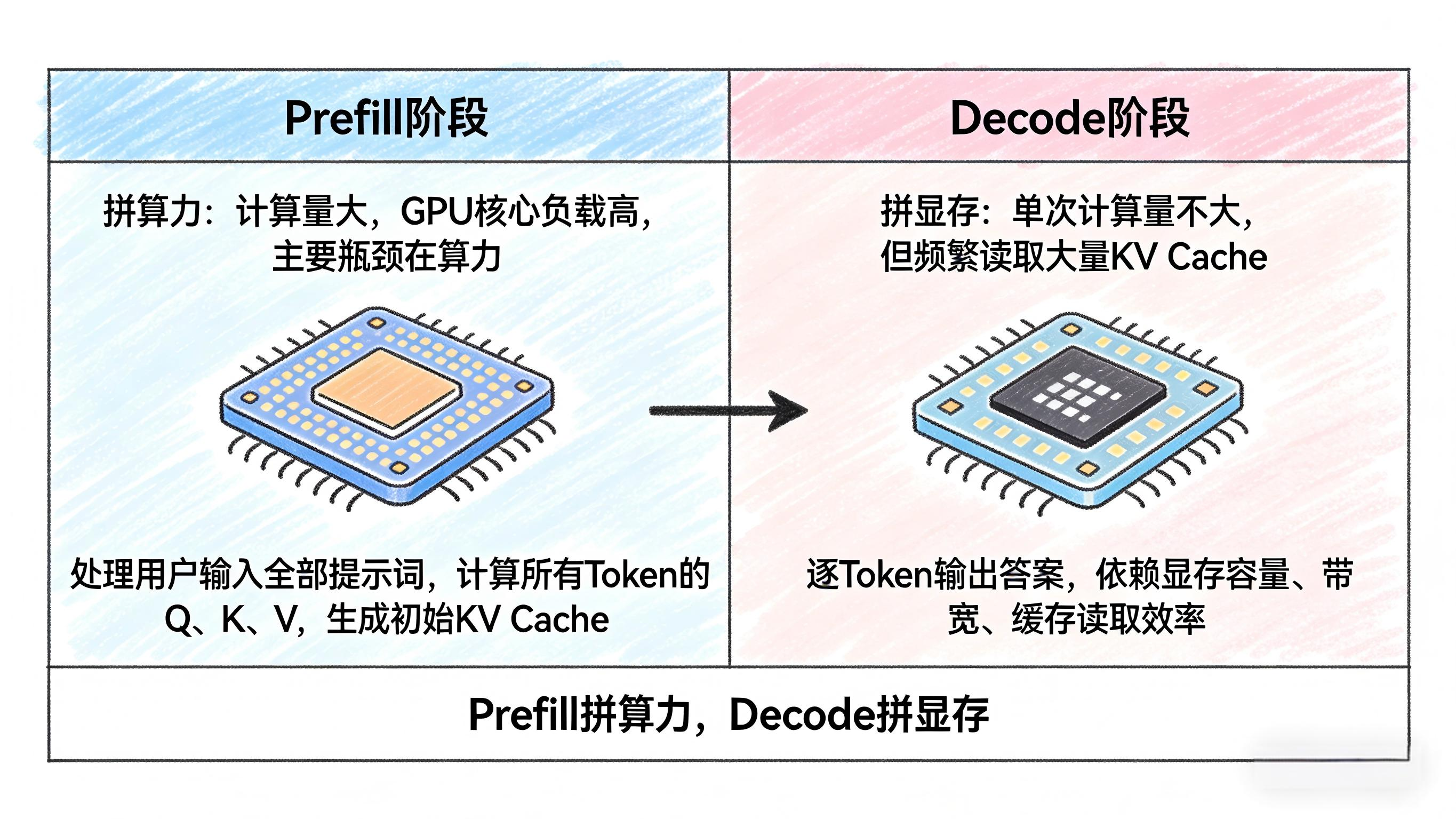
四、显存为什么会很快被吃满?
很多人以为显存主要消耗在模型参数上。
但在真实部署中,模型权重只是基础占用,真正会随着业务负载快速膨胀的,是KV Cache。
显存压力通常来自三部分叠加:
- 模型参数量
- 上下文长度
- 并发请求数
模型越大,基础显存越高;
上下文越长,缓存越大;
并发越多,需要同时维护的缓存就越多。
所以,大模型推理里的显存压力,本质上不是一个静态数字,而是会随着场景变化不断放大的。
这也是为什么很多模型“单跑能跑”,一旦上线真实业务流量,就会暴露显存瓶颈。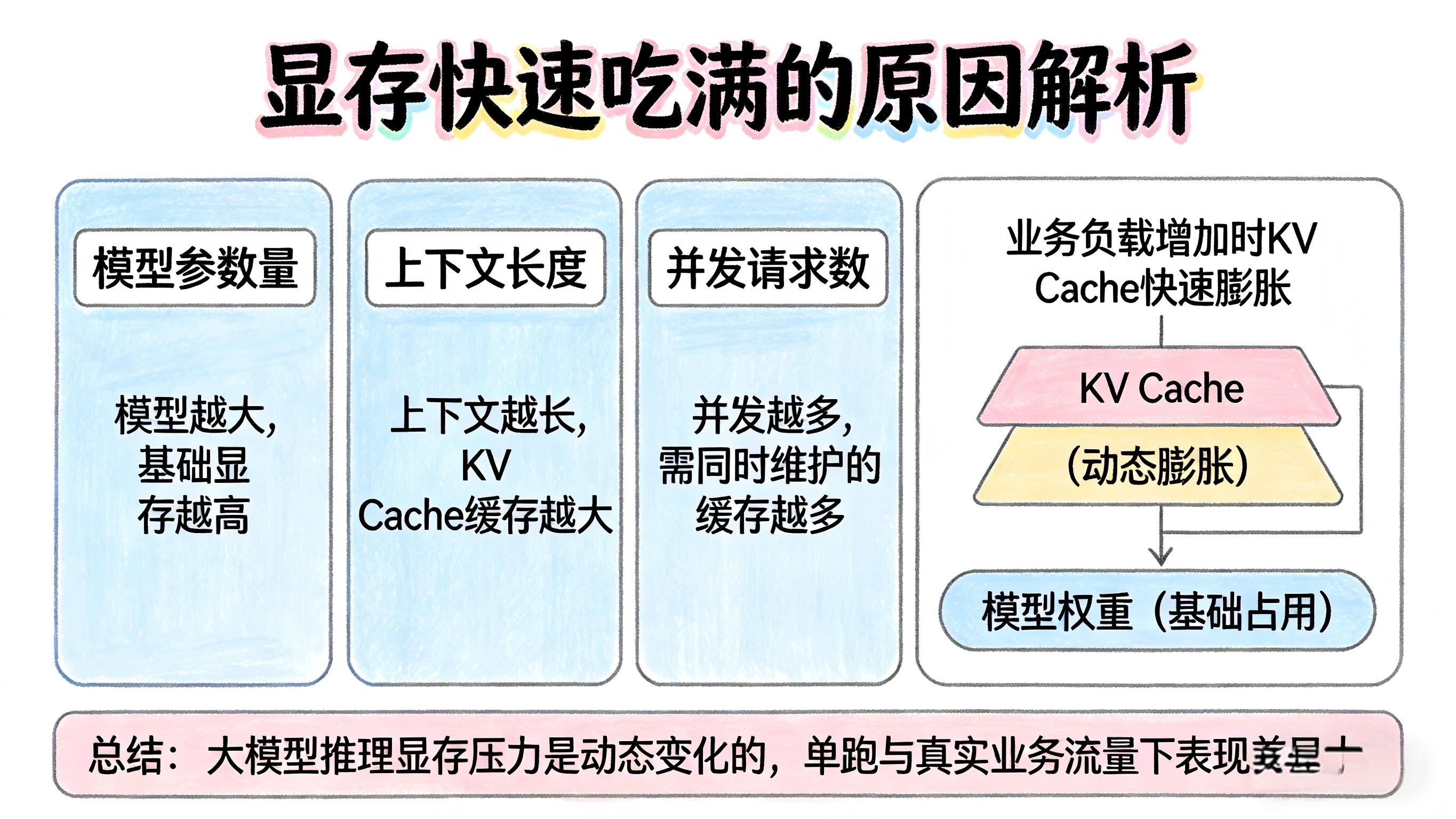
五、为什么这些年优化都围着KV Cache转?
因为KV Cache直接影响推理系统的几个核心指标:
- 吞吐量
- 并发能力
- 上下文长度
- 部署成本
- GPU利用率
所以,近年来很多推理优化,本质上都在回答同一个问题:
如何用更少的显存,保存尽可能有效的历史信息?
常见思路包括:
1. MQA
多个注意力头共享同一组K/V,减少缓存占用。
2. GQA
在共享和效果之间做折中,分组共享K/V,进一步优化显存效率。
3. 缓存压缩与分页管理
通过更高效的缓存组织方式,降低显存碎片和冗余占用。
4. 量化与混合精度
不仅压缩模型权重,也压缩缓存占用,降低整体显存压力。
从表面看,这些方案是在优化模型结构或框架;
从本质看,核心目标都一样:
省显存、提吞吐、降成本。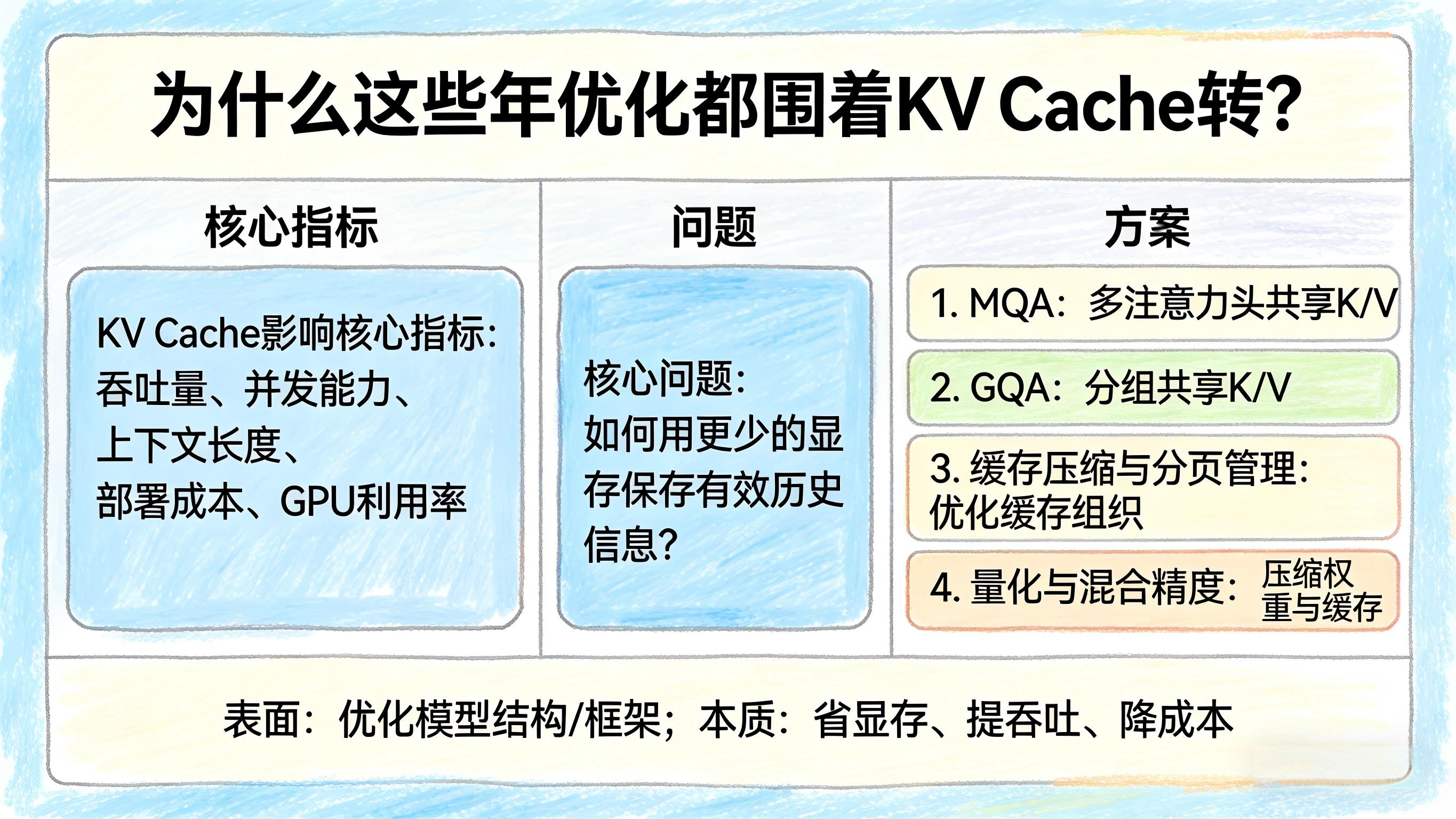
六、为什么显存已经成了推理时代的关键资源?
训练时代,大家更关注TFLOPS、Tensor Core和训练速度;
但到了推理时代,判断一张GPU是否真正“好用”,越来越要看这些指标:
- 显存有多大
- 显存带宽有多高
- 缓存管理效率怎么样
- 多卡通信是否高效
因为在推理场景里:
算力决定能不能算,显存决定能不能高效持续地算。
特别是在长上下文、多轮对话和高并发推理场景下,显存早已不是辅助配置,而是核心资源。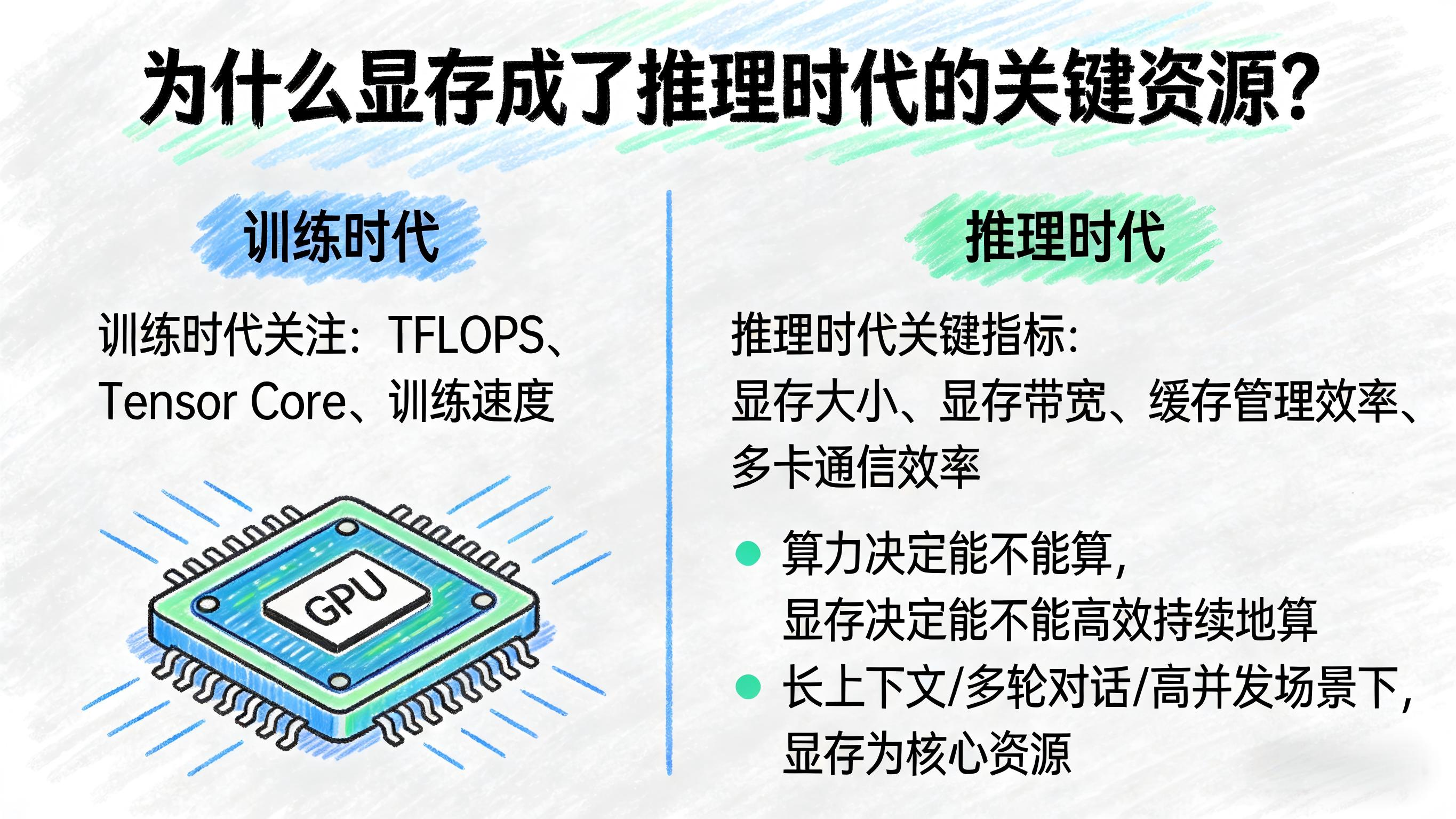
七、结语
大模型推理表面上是在拼GPU算力,
但从真实工程落地看,行业已经越来越进入更细分的阶段:
- Prefill看算力
- Decode看显存
KV Cache让推理避免了大量重复计算,是性能提升的关键;
但与此同时,也把越来越大的系统压力转移到了GPU显存上。
所以今天讨论推理优化,不能只盯着模型算得快不快,更要看:
- 显存占用是否可控
- 显存带宽是否足够
- 缓存管理是否高效
- 并发能力是否能真正落地
说到底:
大模型推理,表面拼计算,深层其实越来越在拼显存。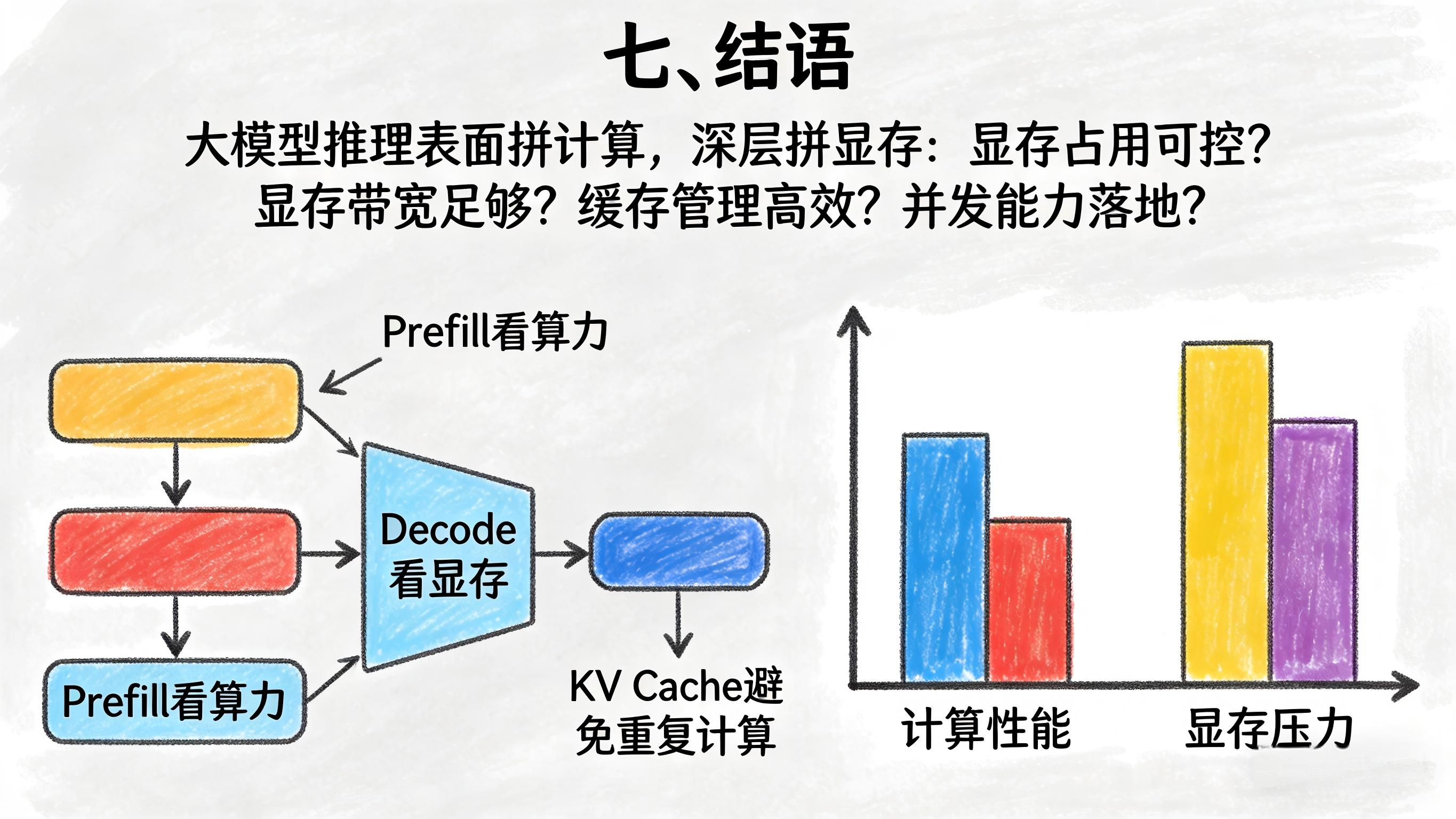

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)