论文精读:拆解顶会论文 COLA:当大模型玩起角色扮演与对抗博弈,Agent 工作流的威力有多大?
在这个大语言模型(LLM)狂飙的时代,遇到复杂的文本分析任务——比如识别网络喷子的“阴阳怪气”、挖掘网友隐藏的真实立场,我们是不是只能靠砸钱、雇人打标签、苦哈哈地去“微调”模型?
清华大学的一篇论文《Stance Detection with Collaborative Role-Infused LLM-Based Agents》给出了一个极其优雅且反直觉的答案:完全不需要额外训练!
本篇文章将用最通俗易懂的大白话,带你硬核拆解这篇让人拍案叫绝的论文。我们将看到,作者如何仅仅通过精妙的 Prompt(提示词)工程,就搭建出了一个由“领域专家”、“正反方辩手”和“最高法官”组成的 AI 专家辩论团(COLA 框架),并且在“零样本”考试中吊打了那些靠死记硬背训练出来的传统模型。
更重要的是,透过这篇论文,我们可以窥见当前 AI 发展的一个核心本质:真正的智能或许已经存在于大模型的脑海中。我们不需要总是教它做题,而是可以通过类似 GAN(生成式对抗网络)的博弈思维和多角色协同的工作流(Agentic Workflow),去激发和组织这些潜能。这是不是强化学习的一种新方式呢?
文章下载地址:
https://arxiv.org/pdf/2310.10467
背景与想法
1. 核心任务:什么是“立场检测”?
这篇论文研究的核心任务叫 “立场检测” (Stance Detection) 。 简单来说,就是让电脑自动阅读一段文字,然后判断作者对某个特定的人、事物或话题,是抱着什么态度。通常分为三种:支持 (Favor)、反对 (Against) 还是 中立 (Neutral) 。
举个例子: 假设目标是“某款手机”,有人发帖说:“这手机电池太不耐用了,简直是电子垃圾。” 那么这句话的立场就是“反对”。
想象一下,每天微博、推特(X)、各种论坛上有海量的信息产生。如果靠人去一条条读,几辈子也读不完。立场检测就像是给电脑装上了一个高效的“态度雷达”,让它能瞬间读懂千万网友的心思。
论文里提到了几个非常实际的用途,听起来都挺厉害的:
互联网和社交媒体大调查:立场检测对于分析网络和社交媒体上的内容至关重要 。它可以帮助研究人员深入了解互联网平台上的海量内容 。比如,我们可以用它来一键分析大家对某个社会现象是支持多还是反对多。
发现网络争议点:有科学家利用这种技术,通过生成带有大家立场的推文总结,来自动发现社交媒体上大家正在激烈争论的话题 。这就像是一个“网络热点矛盾探测器”。
预测或分析重大社会事件:论文里提到了一个特别有意思的真实案例。在英国脱欧(Brexit)全民公投之前,有研究人员用立场检测技术去分析推特上的网友态度,结果发现,支持脱欧的阵营在网络上的影响力其实更大 。这就等于用网友的发帖看清了社会的风向!
当然,论文的作者们也非常清醒。他们在文章最后提到,这种技术如果落入坏人手里,也有可能被滥用,比如被某些机构用来揪出并在网络上打压那些持有不同意见的人 。这说明技术本身是一把双刃剑。
总而言之,立场检测就是帮我们从海量且混乱的网络文字中,迅速摸清“民意”和“风向”的神器。
2. 存在的问题:这事儿难在哪里?
你可能会想,这听起来很简单啊,找找有没有“支持”、“讨厌”这种词不就行了?但在真实的互联网和社交媒体上,这非常难。论文指出了两个主要挑战 :
挑战一:需要懂很多“梗”和背景知识 (Multi-aspect knowledge) 。 网友说话经常带各种梗、专业词汇或者特殊的缩写 。论文里举了个真实的例子:有人发推特说“不再要共和党人了!#ByeByeGOP”,如果你不知道标签“#ByeByeGOP”是对共和党表达不满,或者不知道“特朗普”是共和党人,你就无法判断这句话对“特朗普”的立场其实是“反对” 。
挑战二:需要复杂的逻辑推理 (Advanced reasoning) 。 人们在网上表达立场时,经常“阴阳怪气”说反话(讽刺),或者拐弯抹角地表达 。不直接表达立场,而是通过对相关事件的态度来暗示,这就需要电脑有很强的推理能力 。
3. 以前的方法为什么不够好?
以前,科学家为了解决这个问题,需要找人手动给成千上万句话打标签(也就是做标注),然后用这些数据去教(训练)AI 模型 。这非常费时、费力,而且换个新话题又要重新教一遍 。
最近,像 ChatGPT 这样的大语言模型 (LLMs) 非常火,它们本身就很聪明 。但是,直接把一段话扔给它们,问它们“这句话是什么立场?”,它们往往也会被复杂的语境绕晕,表现得不如那些专门花力气训练出来的老模型 。
4. 论文的绝妙点子:AI 专家辩论团
既然直接问大模型效果不好,清华大学的作者们想出了一个绝妙的办法:不要让 AI 直接猜,而是让 AI 玩“角色扮演”!
他们设计了一个名叫 COLA 的框架系统 。这个系统就像是组建了一个由 AI 扮演的“专家辩论团”,让不同的 AI 角色分工合作,从不同角度分析文字,互相辩论,最后得出一个最靠谱的结论 。而且,这个方法完全不需要额外去辛苦标注数据训练模型,直接拿现成的大模型套用这个框架就行,非常方便(也就是论文里说的零样本 zero-shot) 。
技术路径拆解
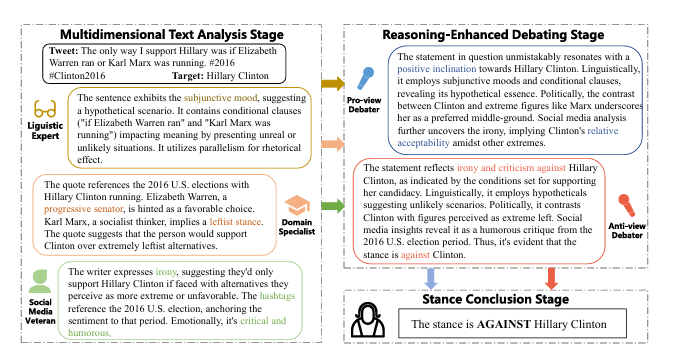
你可以把这个系统想象成一出精彩的“法庭推理剧”。为了搞清楚网友到底是什么态度,AI 们分成了三个阶段来破案 :
第一步:多维度文本分析(专家会诊)
前面我们说过,网友说话可能带梗、带情绪,背景很复杂 。为了看懂这些,系统请来了三位“AI 专家”分别对这段话进行“会诊” :
语言学专家 (Linguistic Expert):专门死磕语法和修辞 。比如这句话用了什么时态?是不是用了虚拟语气?有没有用“正话反说”(讽刺)等修辞手法?
领域专家 (Domain Specialist):专门科普背景知识 。这段话里提到的人物是谁?是哪个党派的?发生了什么大事件?这些人和事与我们要讨论的目标有什么直接关系?
社交媒体老手 (Social Media Veteran):专门解读网络语境 。比如这句话里的特殊标签(Hashtags)是什么意思?有没有用网络黑话?说话人的情绪是愤怒、幽默还是悲伤?
经过这三位专家的拆解,原本干瘪难懂的一句话,它的骨架、背景和情绪就被扒得一清二楚了,这就生成了一份详细的“分析报告” 。
第二步:增强推理的辩论(法庭辩论)
有了专家的分析报告,接下来就是精彩的辩论环节。为了防止 AI 瞎猜,系统安排了几个“辩手”(Debaters)。
假设我们要判断立场是支持、反对还是中立,系统就会派出几位对应的辩手 。
每个辩手都要从第一步的“专家报告”里找证据,拼命去证明自己代表的立场是对的 。
比如,“反方辩手”可能会说:“你们看,社交老手说这个词带有讽刺意味,领域专家又说这两人是政敌,所以综合来看,作者肯定是反对的态度!
这一步非常绝妙,它逼着大语言模型去建立“文字特征”和“最终立场”之间的逻辑推理链条,而不是只看表面意思 。
第三步:立场总结(法官宣判)
辩手们吵完之后,最后会有一位“法官”(总结者 / Judger Agent)出场 。
这位法官会先看一眼网友发的原始文字 。然后,法官会仔细听取所有辩手提供的证据和逻辑链条 。最后,法官综合所有的信息,一锤定音,得出最终结论:这句话的立场到底是支持、反对,还是中立 。
论文里给出了一个非常经典的真实案例(就在论文的图2里),完美展示了这三步是怎么运作的:
网友发帖: "The only way I support Hillary was if Elizabeth Warren ran or Karl Marx was running. #2016 #Clinton2016"(大意:我支持希拉里的唯一可能,就是伊丽莎白·沃伦或者卡尔·马克思出来竞选。)
我们的目标(Target): 判断这人对 Hillary Clinton(希拉里) 是什么态度 ?
如果你直接让以前的 AI 看这句话,它可能会看到“support Hillary(支持希拉里)”这几个字,就傻乎乎地判定为“支持”。但这显然不对。我们来看看 COLA 系统的三个步骤是怎么一层层扒开这句话的伪装的:
第一步:专家会诊(把句子拆碎了揉碎了看)
语言学专家出场: 他推了推眼镜说,这句话用的是“虚拟语气”和“条件从句”(if...) 。这说明作者描述的是一个假设的、不太可能发生的场景 。
领域专家出场: 他翻开资料库说,这是在聊 2016 年的美国大选 。沃伦是个进步派参议员,而马克思是社会主义思想家(代表极左翼) 。这人想表达的是,只有面对这些极端的左翼候选人时,他才会勉强选希拉里 。
社交媒体老手出场: 他敏锐地指出,这其实是在“讽刺”!作者带了 #2016 的标签 。整体的情绪是非常带有批判性和幽默感的 。
第二步:法庭辩论(正反方抢夺逻辑高地)
拿到三位专家的报告后,辩手开始吵架了。
正方辩手(支持希拉里): 虽然有点牵强,但他还是努力找角度。他说:“你们看,相比于马克思那种极端的历史人物,作者把希拉里当成了更容易让人接受的中间派,所以这其实是对她的一种肯定!”
反方辩手(反对希拉里): 毫不留情地反驳:“瞎说!作者用‘虚拟语气’加上‘讽刺’,明明是在表达对希拉里的批评 。他的意思是除非遇到最离谱的情况,否则绝不选希拉里,这是一个幽默的讽刺,立场绝对是反对!
所谓的“正方辩手”和“反方辩手”,依然是咱们熟悉的那个老熟人——同一个大语言模型(比如 GPT-3.5)!
那它是怎么做到“精神分裂”出正反双方的呢?答案是:强制角色扮演(分配不同的剧本)。
系统并不是让 AI 自由发挥去猜,而是像举办一场辩论赛一样,强行给 AI “抽签”分配立场 。
作者在论文里公布了给辩手设定的提示词,我把它翻译成大白话,大概是这样的流程:
1. 发放参考资料:这是原贴的内容,以及语言学专家、领域专家、社交媒体老手刚才写好的三份分析报告 。 2. 强制分配阵营:现在,你必须坚信这句话对【讨论目标】的态度是【填入:支持 / 反对 / 中立】的 。 3. 布置硬性任务:请从刚才那三位专家的分析报告中,挑出最能支撑你这个立场的 3 条证据,并据此展开你的辩论发言 !
你看懂这个操作了吗?系统会把这个剧本在后台运行好几次:
-
第一次,系统在剧本的空白处填上“支持”。这时候,GPT 就变成了正方辩手,它只能绞尽脑汁从专家的报告里找“支持”的蛛丝马迹。
-
第二次,系统在空白处填上“反对”。同一个 GPT 摇身一变就成了反方辩手,开始拼命找“反对”的论点 。
这就像大学里的辩论赛,哪怕你心里觉得这个辩题很扯,但既然你抽到了反方,你也得疯狂翻资料,给自己的阵营找理由。这样做的好处是,能够逼着大语言模型进行发散性思维,把一句话里正反两面的暗示全给挖出来
第三步:法官宣判(一锤定音)
在论文里,作者把给法官的剧本(Prompt)完全公开了,它实际上是一段填空题,大意是这样的:
任务说明: 请判断下面这句话对【目标(比如:希拉里)】的态度是支持、反对,还是中立。 案发现场(原句): 【这里填入网友发的那句话】
请参考以下各方辩手的证词来做决定: 正方辩手的理由: 【系统会自动填入第二步里支持方的辩论词】 反方辩手的理由: 【系统会自动填入第二步里反方的辩论词】 中立方辩手的理由: 【系统会自动填入第二步里中立方的辩论词】
请从以下选项中做出选择: A: 反对 (Against) B: 支持 (Favor) C: 中立 (Neutral)
强制要求:只能回答上面最准确的一个选项,除了选项什么都别说!
法官(总结者): 听完两边的话,结合原句一看。反方辩手的逻辑明显更符合人类的真实表达习惯。
最终判定: 这句话对希拉里的立场是 反对(AGAINST) !
法官要综合所有辩手的发言来下结论。为了防止法官(也是大模型扮演的)瞎猜,作者在最后一步加了一个小魔法:
法官在输出结果时,系统要求它必须提供一个结构化的数据(JSON 格式),里面强制包含两部分:
-
最终判定:比如“反对”。
-
判决理由:一段不超过 100 个单词的简短解释 。
嘲讽希拉里的帖子为例,法官不仅判了“反对”,还写出了这样一段堪比真人的判决词:
“作者使用了贬义语言(对应语言专家的发现),提到了班加西事件的负面背景(对应领域专家的发现),还使用了 #NoHillary2016 的标签(对应社交老手的发现),所有这些都清楚地表明了反对希拉里当选的立场。”
有了这段有理有据的解释,我们就再也不怕 AI 是一本正经地胡说八道了,这就叫**“高可解释性”** !
到这里,这篇论文的精髓——怎么分身当专家、怎么左右互搏去辩论、怎么不用训练直接上考场、以及怎么给自己找理由,你就已经完全掌握了!论文最后还提到,这套“分析-辩论-总结”的万能模板,不仅能测立场,还能跨界去干点别的活儿(比如测情感) 。
你看,这就是这篇论文最牛的地方。它没有让 AI 直接去猜结果,而是逼着 AI 先懂语法、懂背景、懂阴阳怪气,然后再自己跟自己辩论一下,最后才下结论。这样就能完美避开字面意思的陷阱,像人类一样精准get到网友的“潜台词”。
到这个时候你肯定想问这个模型到底是如何训练的呢?:
这个问题问得特别好!这正是这篇论文最“反常识”、也最厉害的一个卖点:
COLA 系统根本就没有经过传统的“训练”!
这听起来是不是有点不可思议?为了让你彻底明白,我们来对比一下“传统 AI”和这篇论文里的“COLA”是怎么干活的:
1. 传统 AI:题海战术(需要大量训练)
以前如果要造一个“立场检测”的 AI,科学家需要像教小学生一样:
-
先找来几万条甚至几十万条网友的评论 。
-
雇人把这些评论一条一条地打上标签(这条是支持,那条是反对)。
-
把这些做好的“练习册”喂给 AI 模型,让它反复背诵、调整大脑里的参数(这就叫训练/微调)。
-
痛点: 太花时间、太费钱了!而且如果你本来训练它识别“特朗普”的立场,明天你想让它识别大家对“某款新能源车”的立场,对不起,你得重新找数据、重新教一遍 。
2. 这篇论文的魔法:不训练,直接发“剧本”(零样本 Zero-shot)
这篇论文的作者们说:既然现在的大语言模型(比如 ChatGPT)已经读过人类几乎所有的书,是个全知全能的“大学霸”了,我们干嘛还要让它从头做小学生练习册呢?
所以,作者采用了一种叫 “零样本”(Zero-shot) 的方法 。他们没有给模型喂任何带标签的数据,也没有去修改模型本身的代码和参数 。
他们是怎么做的呢?答案是:写剧本(写提示词 Prompt Engineering) 。
作者直接接入了现成的大语言模型(在主要实验里,他们用的是 OpenAI 的 GPT-3.5 Turbo)。然后,他们利用系统的“指令功能”,给大模型发送了精心设计好的提示词(Prompts),让模型来玩角色扮演 。
论文里把这些“剧本”都公开了,比如:
-
给“语言学专家”的剧本:“你是一个语言学家。请准确简明地解释句子中的语言元素以及这些元素如何影响含义,包括语法结构、时态、虚拟语气、修辞手法等。除了这个什么都别做。”
-
给“社交媒体老手”的剧本:“你是一个重度社交媒体用户,非常熟悉网上的表达方式。请分析下面这句话的内容、情绪基调和暗示意义等。
-
给“辩手”的剧本:“请从刚才专家的分析中,找出最能支持你这个立场的 3 条证据,并为你的观点进行辩论。”
总结一下它的“训练”秘诀:
它没有训练,而是通过“现成的大脑(GPT-3.5) + 绝妙的剧本(提示词)” 。你只要把这些剧本和网友的话一起发给 API 接口,大模型就会乖乖地按照设定的角色把活儿干了 。这不仅省去了收集数据和训练的麻烦,而且因为没改模型,任何人拿过来直接就能用,超级方便(高可用性)
这种用“提示词”代替“训练”的方法,是现在人工智能领域最流行的玩法之一。
最终效果如何?
这绝对是整篇论文最让人激动的部分!我们前面说到,这个 COLA 系统是个“免训练”的学霸,直接拿来就用。那么,它在真正的考场上表现到底怎么样呢?
作者们为了证明这个系统不是花架子,找了三个非常权威的“题库”(数据集:SEM16、P-Stance、VAST)来进行考试 。
考试结果简直可以用“成绩爆炸”来形容。我们可以把它的战绩总结为以下几个超强亮点:
1. 碾压同级别的“裸考”选手(零样本测试第一名)
在 AI 界,不给看复习资料直接上考场叫“零样本”(Zero-shot)测试。
在所有不用额外数据训练的模型里,COLA 系统的成绩全面超越了之前最强的先进模型 。
尤其是在遇到“气候变化”(CC)和“堕胎合法化”(LA)这种比较抽象、复杂的社会话题时,COLA 的成绩比之前的最高分分别暴涨了 16.9% 和 26.6% 。这说明它处理复杂问题的能力极强。
2. 越级打怪,干翻了“死记硬背”的选手
这是论文里最让人震惊的一个结果。
有一些传统的 AI 模型,是拿着专门的题库“死记硬背”辛苦训练出来的(领域内模型) 。
结果,COLA 这个完全没看过题库的“裸考”选手,成绩竟然和那些辛苦训练的模型打成了平手,甚至在很多题目上超越了它们 !
比如在 P-Stance(专门测试政治人物立场的题库)中,COLA 的表现始终优于所有经过全面训练的传统基准模型 。这就好比一个天赋异禀加上懂解题技巧(辩论框架)的学生,考赢了题海战术的书呆子。
3. 团队协作完爆“个人英雄主义”(对比直接问 GPT)
你可能会好奇,既然是用大语言模型,那我直接把原话发给 ChatGPT,问它“这句话什么立场”,不就行了吗?
论文的测试给出了残酷的真相:如果你直接问大模型,它的表现非常糟糕,特别是在处理抽象概念时 。
比如在测试“无神论”(A)这个话题时,直接用 GPT-3.5 只能拿到可怜的 9.1% 的分数 。
但是,当你用 COLA 的框架,把同一个 GPT-3.5 拆分成“专家”和“辩手”让它自己走流程时,它的成绩出现了巨大的飞跃 。这完美证明了:怎么提问、怎么设计流程,比单纯依赖大模型本身的智商更重要。
4. 缺了谁都不行(消融实验证明不带水分)
为了证明系统里设计的“语言专家”、“领域专家”、“社交老手”和“辩论环节”不是在凑字数,作者还做了一个“拔网线”测试(学术上叫消融实验)
他们尝试把三位专家挨个开除,发现只要少了一个,成绩就会下滑 。
他们又尝试取消“法庭辩论”环节,让法官直接看报告判决,结果成绩遭遇了滑铁卢,尤其是在判断复杂话题时,分数狂跌(比如在 LA 目标上绝对分数下降了 31.2%) 。这说明,“让 AI 自己跟自己辩论”这一步,是提升逻辑推理能力的核心大招 。
总结:
这篇论文的最终效果简直可以用“拿了全班第一,还顺便踢馆了隔壁班”来形容!
作者用三个非常有名的考试题库(SEM16、P-Stance、VAST)对 COLA 系统进行了全面测试 。结果可以说是大获全胜,主要体现在以下几个极其惊艳的方面:
一、 (零样本测试领先):
在所有不需要额外训练的“零样本”模型中,COLA 在几乎所有指标上都全面超越了目前最强的先进模型 。
特别是在面对“气候变化”(CC)和“堕胎合法化”(LA)这种非常复杂的社会话题时,COLA 的成绩比之前的最高分暴涨了 16.9% 和 26.6%
二、 对比微调模型:
有很多传统的 AI 模型是拿着特定话题的题库“死记硬背”辛苦训练出来的 。而 COLA 这个完全没看过题库的“裸考”选手,成绩竟然和那些辛苦训练的模型打成了平手 。
在 P-Stance(专门测试政治人物立场的题库)中,COLA 的表现甚至一直优于所有经过全面训练的传统基准模型 。
三、 对比直接问大模型:
如果你不搞这套专家辩论的流程,直接把原话发给大语言模型(GPT-3.5),它的表现其实非常糟糕 。比如在测试对“无神论”(A)这个话题的态度时,直接用 GPT-3.5 只能拿到可怜的 9.1%的分数,而用了 COLA 框架后,分数飙升到了 70.8% 。这完美证明了:怎么给大模型分配任务,比大模型本身的聪明程度更关键!
四、消融实验:
作者为了证明系统里没有“混日子”的组件,特意做了测试,发现只要拿掉任何一个“专家”,或者取消“辩论环节”,成绩就会明显下滑 。尤其是取消“辩论环节”后,面对复杂话题的分数出现了狂跌(比如在 LA 目标上绝对分数下降了 31.2%) 。这说明“让 AI 互相辩论”正是它拥有强大逻辑推理能力的核心大招 。
五、 通用性:作者还把这套“分析-辩论-总结”的框架拿去干别的活儿,比如“基于方面的情感分析”(判断对特定细节的情感)和“说服预测”(判断对话中某人是否被说服) 。结果发现,COLA 在这些新任务上同样表现得极其出色,成绩不仅堪比那些专门靠数据训练出来的模型,而且大大超越了直接使用 GPT-3.5 的效果 。
总而言之,COLA 系统的最终效果完美证明了:不用苦哈哈地去训练模型,只要把大模型当成员工,给它们分配合理的角色、制定清晰的讨论流程,它们就能爆发出惊人的智慧和极高的准确率!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)