Diffusion 扩散模型知识体系梳理(一)
Diffusion 扩散模型知识体系 Part 1
博客笔记逻辑示意图:
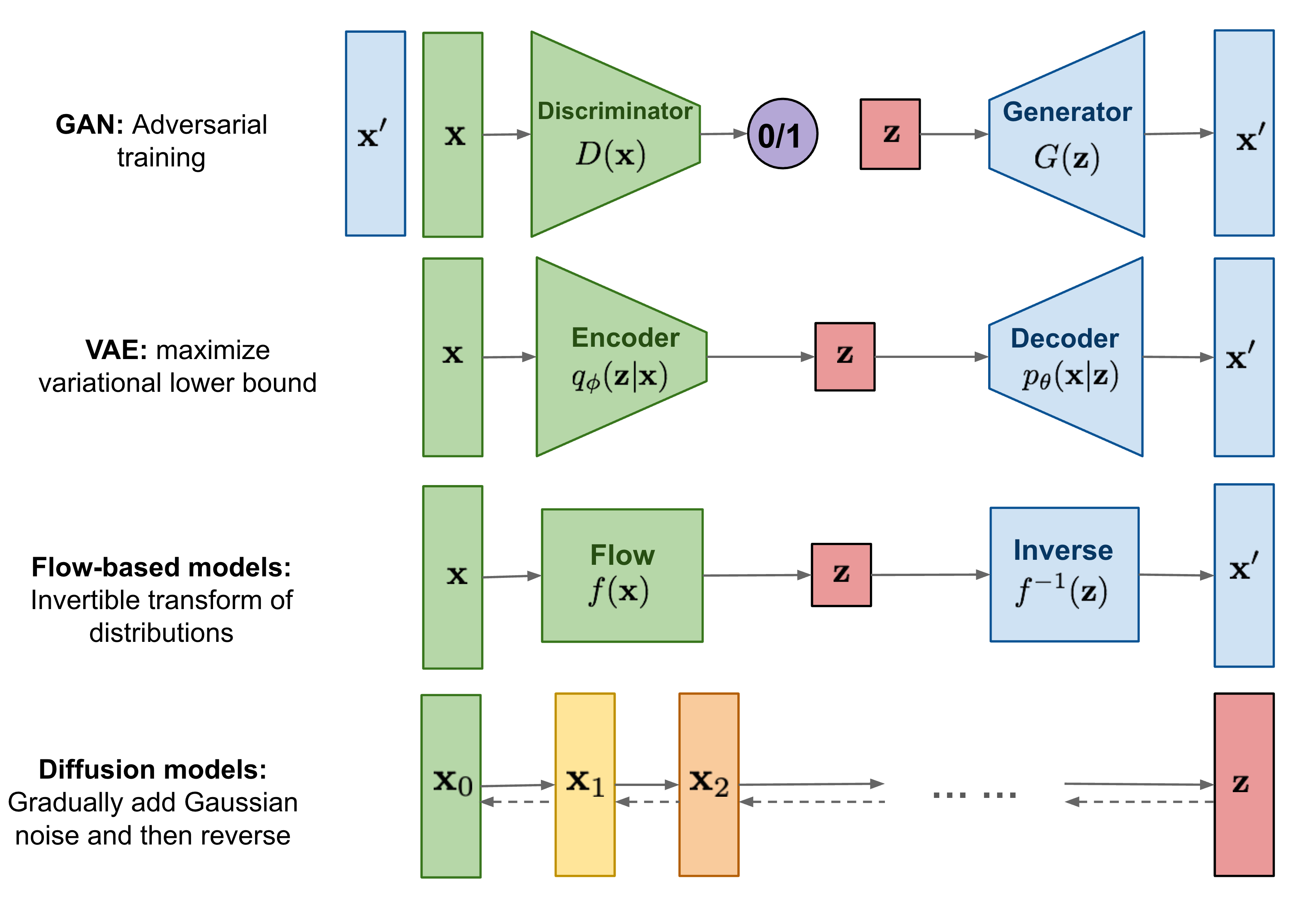
1. 关于扩散模型的直觉理解
- 首先要构建关于生成式模型的一种直觉,生成式模型可以主要分为这样的五个大类别:
- 自回归模型:按顺序生成每个 token,基于前面的所有内容
- 变分自编码器:VAE 的思路,主要通过对隐空间中的编码学习来实现
- 对抗生成:生成器和判别器对抗训练
- 流模型:“通过可逆变换将简单分布映射到数据分布”
- 扩散模型:当下的 SOTA,也是今天讨论的重点
- 关于扩散模型的特征嘛,可以这样直观理解,我想要生成一张图片,但是我手里只有随机分布的纯噪声,那么我能做的就是使用类似去噪的手法,经过若干次迭代,将这个纯噪声演化为目标的图像。所以直观上想,我的模型就是通过网络预测+数学推导,来拟合这样一个去噪的过程。所以相应的,我们就可以定义前向加噪与逆向去噪的过程。前者是人为确定好的过程,每一步通过添加一定的高斯噪声,将完整的图片变成纯噪声。而加噪过程中每一步所采样的噪声,则成为了去噪网络训练时的监督信号(label)。扩散模型的概念最早由 Sohl-Dickstein et al. [1] 提出。
- Diffusion 早期的加噪过程是充满了复杂的概率估计的,不利于工程化实现,直到2020年的 DDPM [2],Denoising Diffusion Probabilistic Models 的出现,通过简化 ELBO 损失函数,将预测目标从预测复杂的后验分布,简化成了预测噪声( ϵ \epsilon ϵ-prediction),并在实验中验证了这种简化目标的有效性。此外,DDPM 采用了线性调度的加噪节奏(后来被 Nichol & Dhariwal [3] 提出的 cosine schedule 等改进方案替代)。
2. 从 DDPM 的角度看离散 Diffusion
2.1. 线性调度加噪公式
- 在 DDPM 的算法理论中,模型的加噪过程是一种 β \beta β 线性调度的加噪过程,也即满足如下过程: x t = α t x t − 1 + β t ϵ t x t = α ˉ t x 0 + 1 − α ˉ t ϵ where x 0 → x 1 → ⋯ → x T ( 纯噪声 ) , ϵ ∼ N ( 0 , I ) α ˉ t = ∏ s = 1 t α s 、 α t + β t = 1 ∀ t , α t + 1 ≤ α t , β t + 1 ≥ β t \begin{aligned} x_{t} &= \sqrt{\alpha_t}\,x_{t-1} +\sqrt{\beta_t} \,\epsilon_t \\ x_{t} &= \sqrt{\bar{\alpha}_t}\,x_0 +\sqrt{1-\bar{\alpha}_t} \,\epsilon \\ \text{where} \;&x_0 \rightarrow x_1 \rightarrow\cdots \rightarrow x_T \,(纯噪声),\;\epsilon \sim \mathcal{N}(0,I) \\ \bar{\alpha}_t &= \prod^{t}_{s=1} \alpha_s\,、\alpha_t+\beta_t = 1 \\ \forall\,t ,\; & \alpha_{t+1} \leq \alpha_t,\;\beta_{t+1} \geq \beta_t \end{aligned} xtxtwhereαˉt∀t,=αtxt−1+βtϵt=αˉtx0+1−αˉtϵx0→x1→⋯→xT(纯噪声),ϵ∼N(0,I)=s=1∏tαs、αt+βt=1αt+1≤αt,βt+1≥βt
- 其中需要注意的是,每一步添加的噪声 ϵ 1 ⋯ ϵ t ∼ N ( 0 , I ) \epsilon_1\cdots\epsilon_t \sim \mathcal{N}(0,I) ϵ1⋯ϵt∼N(0,I),可以经过数学推导,对于任意的样本 x 0 x_0 x0,都可以经过无限次的单位高斯噪声加噪,变成最后的纯高斯噪声,所以上述过程可以认为能够在有限步内实现(当 α ˉ t \sqrt{\bar{\alpha}_t} αˉt 趋近于零,可以认为当前的状态全部为噪声)。另外,之所以对 α \alpha α 与 β \beta β 进行归一化,可以让每一步的 x t x_t xt 都符合不同参数的高斯分布。
2.2. 去噪过程的概率本质
- 下面让我们来分析去噪过程,也就是推导训练目标的关键。不过在此之前,让我们从贝叶斯理论的角度还分析一下,加噪和去噪过程,本质上是在构造些什么。首先,我们发现加噪过程可以本质上描述为一种条件概率分布: q ( x t ∣ x t − 1 ) ∼ N ( x t ; α t x t − 1 , β t I ) q\,(\,x_t\,|\,x_{t-1}\,)\sim\mathcal{N}(\,x_t\,;\,\sqrt{\alpha_t}\,x_{t-1}\,,\,\beta_t\,I\,) q(xt∣xt−1)∼N(xt;αtxt−1,βtI)
- 同理我们可以将加噪过程整体理解为在已知 x 0 x_0 x0 样本的条件下的总体分布: q ( x 1 : T ∣ x 0 ) = ∏ i = 1 T q ( x t ∣ x t − 1 ) q\,(\,x_{1:T}\,|\,x_0\,) = \prod_{i=1}^T q\,(\,x_t\,|\,x_{t-1}\,) q(x1:T∣x0)=i=1∏Tq(xt∣xt−1)
- 所以我们在去噪过程中,想要获得的就是一种后验的分布 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt),也就是在已知高噪声的图像时,得到下一步低噪声图像的分布。由于这里的分布我们在不知道 x 0 x_0 x0 的时候是无法准确量化的,所以选择使用模型 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt) 来近似, x 0 x_0 x0 可以理解为这个训练过程中的 label。
2.3. 结合贝叶斯公式推导
-
下面让我们来 结合贝叶斯公式进行展开推导: q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(x_{t-1}|x_t,x_0) = q(x_t|x_{t-1},x_0)\dfrac{q(x_{t-1}|x_0)}{q(x_t|x_0)} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0) 其中我们有后三者均为满足一定递推条件的高斯分布: q ( x t ∣ x t − 1 , x 0 ) ∼ N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q ( x t ∣ x 0 ) ∼ N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q ( x t − 1 ∣ x 0 ) ∼ N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) \begin{aligned} q(x_t|x_{t-1},x_0) &\sim \mathcal{N}(x_t;\sqrt{\alpha_t}\,x_{t-1},(1-\alpha_t)I) \\ q(x_t|x_0) &\sim \mathcal{N}(x_t;\sqrt{\bar{\alpha}_t}\,x_0,(1-\bar{\alpha}_t)I) \\ q(x_{t-1}|x_0) &\sim \mathcal{N}(x_{t-1};\sqrt{\bar{\alpha}_{t-1}}\,x_0,(1-\bar{\alpha}_{t-1})I) \end{aligned} q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∼N(xt;αtxt−1,(1−αt)I)∼N(xt;αˉtx0,(1−αˉt)I)∼N(xt−1;αˉt−1x0,(1−αˉt−1)I) 将这三个高斯分布的指数形式进行展开: q ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 1 − α t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{aligned} q(x_{t-1}|x_t,x_0) &\propto \exp\left(-\frac{1}{2}\left( \frac{(x_t - \sqrt{\alpha_t} x_{t-1})^2}{1-\alpha_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1-\bar{\alpha}_t} \right)\right) \\ &= \exp\left(-\frac{1}{2}\left( \left( \frac{\alpha_t}{\beta_t} + \frac{1}{1-\bar{\alpha}_{t-1}} \right) x_{t-1}^2 - \left( \frac{2\sqrt{\alpha_t}}{\beta_t} x_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}} x_0 \right) x_{t-1} + C(x_t, x_0) \right)\right) \end{aligned} q(xt−1∣xt,x0)∝exp(−21(1−αt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
-
此时,我们不妨定义想要化简的后验分布的高斯分布形式为: q ( x t − 1 ∣ x t , x 0 ) ∼ N ( x t − 1 ; μ ~ t , β ~ t I ) ∝ exp ( − 1 2 σ 2 ( x t − 1 − μ ) 2 ) q(x_{t-1}|x_t,x_0) \sim \mathcal{N}(x_{t-1};\widetilde{\mu}_t,\widetilde{\beta}_t\,I) \propto \exp\,(-\frac{1}{2\sigma^2}(x_{t-1}-\mu)^2) q(xt−1∣xt,x0)∼N(xt−1;μ t,β tI)∝exp(−2σ21(xt−1−μ)2) 将两式子进行对照化简可得: μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 , β ~ t = β t ( 1 − α ˉ t − 1 ) 1 − α ˉ t → 代入前向过程递推公式,替换掉 x 0 而使用噪声 ϵ t 表示 μ θ ( x t , t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) \begin{aligned} &\tilde{\mu}_t = \frac{\sqrt{\alpha_t} (1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} x_0 ,\; \tilde{\beta}_t = \frac{\beta_t (1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} \\ &\rightarrow \; 代入前向过程递推公式,替换掉\,x_0\,而使用噪声\,\epsilon_t\,表示 \\ &\mu_\theta(x_t,t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta(x_t ,t) \right) \end{aligned} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0,β~t=1−αˉtβt(1−αˉt−1)→代入前向过程递推公式,替换掉x0而使用噪声ϵt表示μθ(xt,t)=αt1(xt−1−αˉt1−αtϵθ(xt,t))
-
于是我们得到的最后的化简结论: q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) ⏟ 均值 μ ~ t , β t ( 1 − α ˉ t − 1 ) 1 − α ˉ t ⏟ 方差 β ~ t ) \boxed{ q(x_{t-1} | x_t, x_0) = \mathcal{N}\left(x_{t-1}; \underbrace{\frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_t\right)}_{\text{均值}\tilde{\mu}_t}, \underbrace{\frac{\beta_t(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}}_{\text{方差}\tilde{\beta}_t} \right) } q(xt−1∣xt,x0)=N xt−1;均值μ~t αt1(xt−1−αˉt1−αtϵt),方差β~t 1−αˉtβt(1−αˉt−1)
-
很好,那么当我们冷静一下想想,计算得到这个分布的意义是什么?是因为它提示了我们如何进行去噪过程,也就是只要我确切地知道从 x 0 x_0 x0 到第 t t t 个时间步所添加的噪声 ϵ \epsilon ϵ 就可以得到下一个时刻的含噪状态 x t − 1 x_{t-1} xt−1,一步一步,直到最后输出 x 0 x_0 x0。不错,所以归根到底,经过数学的推算,我们的模型要预测的目标,已经从整个条件分布,变成了当前状态 x t x_t xt 相对于 x 0 x_0 x0 的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)。至于我的 label 是什么相信显而易见,就是我在加噪过程中采样的那个噪声 ϵ \epsilon ϵ(满足 x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_{t} = \sqrt{\bar{\alpha}_t}\, x_0 +\sqrt{1-\bar{\alpha}_t} \,\epsilon xt=αˉtx0+1−αˉtϵ,其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0,I) ϵ∼N(0,I) )。所以,相应的损失函数也很好构造了: L DDPM simple = ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 L DDPM simple = E x 0 , ϵ [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] \begin{aligned} \mathcal{L}^{\text{simple}}_{\text{DDPM}} &= ||\epsilon - \epsilon_\theta(x_t,t)||^2 \\ \mathcal{L}^{\text{simple}}_{\text{DDPM}} &= \mathbb{E}_{x_0,\epsilon}\left[\|\epsilon - \epsilon_\theta(x_t, t)\|^2\right] \end{aligned} LDDPMsimpleLDDPMsimple=∣∣ϵ−ϵθ(xt,t)∣∣2=Ex0,ϵ[∥ϵ−ϵθ(xt,t)∥2] 于是我们用这个思路进行梯度下降更新参数即可。
-
一点补充,有没有看到上面的损失函数中有一个”simple”,其实这是 DDPM 算法的一个超级赞的数学原理推导。由最大似然的理论可知,如果我们想要我们模型最终的分布 p θ ( x 0 ) p_\theta(x_0) pθ(x0) 能够尽可能准确,可以理解为最小化 L \mathcal{L} L,也即表示模型实际的输出在真实数据分布 q ( x 0 ) q(x_0) q(x0) 下的期望: L = E q ( x 0 ) [ − log p θ ( x 0 ) ] \mathcal{L} = \mathbb{E}_{q(x_0)}[\,-\log p_\theta(x_0)\,] L=Eq(x0)[−logpθ(x0)] 经过严格的数学推导,可以将上述负对数似然(NLL)的损失函数,逐步化简得到 MSE,与咱们前文中利用贝叶斯推导出的结果出奇的一致。 NLL → ≤ VLB/ELBO → = KL散度 → ∝ MSE → ϵ − prediction \text{NLL}\xrightarrow{\leq} \text{VLB/ELBO} \xrightarrow{=} \text{KL散度} \xrightarrow{\propto} \text{MSE} \rightarrow \epsilon-\text{prediction} NLL≤VLB/ELBO=KL散度∝MSE→ϵ−prediction 其中 KL 散度退化为 MSE 的关键在于:当 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0) 和 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt) 都是高斯分布且方差被固定为 β ~ t \tilde{\beta}_t β~t 时,两个高斯之间的 KL 散度只剩下均值差的平方项,也就是 ∥ μ ~ t − μ θ ∥ 2 \|\tilde{\mu}_t - \mu_\theta\|^2 ∥μ~t−μθ∥2,自然退化为 MSE。这种一致性可以认为来自于我们对于高斯分布的假设,高斯分布取对数得到的表达式中会包含 MSE 的均方差。
3. 后续
后续完整内容请关注 “Diffusion 扩散生成模型” 后续文章。欢迎评论区批评指正
References
[1] Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. ICML 2015.
[2] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020.
[3] Nichol, A. Q., & Dhariwal, P. (2021). Improved Denoising Diffusion Probabilistic Models. ICML 2021.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)