医疗AI智能体:整体效能评估可视化:从原理到实践的10大核心量化指标体系.130
一、智能体的效能评估
医疗AI智能体是融合大语言模型、医学知识库、交互引擎、工具调用能力的复合型智能系统,核心应用场景覆盖智能问诊、病历辅助生成、医学知识问答、诊疗方案辅助建议、患者随访管理五大核心领域。与通用大模型、电商客服 AI、教育 AI 相比,医疗 AI 智能体具备极强的行业特殊性:
- 第一,医疗决策直接关系生命健康,任何错误输出都可能引发医疗风险;
- 第二,合规性要求严苛,必须符合《医疗机构管理条例》《人工智能医用软件产品分类界定指导原则》等行业规范;
- 第三,使用主体多元,既面向高知识门槛的专业医生,也面向普通患者;
- 第四,业务闭环要求高,从患者发起咨询到完成问诊、医生审核、方案落地,必须形成完整流程。
这种特殊性决定了医疗AI智能体不能用"好用"、“不好用”等主观感受评价,必须通过可量化、可复现、可监控、可优化的指标体系,实现效果的客观评估。在实际落地中,很多的的医疗AI项目失败并非技术能力不足,而是缺乏标准化的量化评估体系,导致模型幻觉、响应延迟、业务适配性差等问题无法被精准发现,最终无法通过医疗机构审核、无法满足临床使用需求。

二、量化指标体系的核心价值
1. 指导大模型精准迭代
大模型的训练、微调、对齐是一个持续优化的过程,医疗大模型面临两大核心痛点:
- 一是医学知识专业性极强,通用语料无法覆盖诊疗规范、药品禁忌、手术指征等专业内容;
- 二是幻觉问题生成虚假医学结论、编造诊疗方案是医疗 AI 的致命缺陷。
量化指标能够精准定位大模型的问题:
- 幻觉率高说明模型医学知识对齐不足;
- 回复准确率低说明微调数据质量差;
- 响应时间长说明模型推理引擎需要优化;
- 知识库召回率低说明向量数据库或检索算法存在缺陷。
没有量化指标,大模型迭代只能依靠人工主观判断,优化方向模糊、周期长、成本高。
2. 提高研发团队整体效果
医疗AI智能体是多模块耦合系统,包含大模型推理模块、知识库检索模块、交互管理模块、审核接口模块等。任何一个模块出现问题,都会影响整体使用体验。量化指标体系能够实现全链路监控:
- 技术指标监控底层模块性能,业务指标监控上层流程适配性,研发团队可以通过指标波动快速定位故障模块,实现问题的快速修复;
- 同时,量化指标为版本迭代提供客观依据,新版本上线后,通过指标对比即可判断优化效果,避免盲目升级。
3. 支撑临床落地的合规应用
医疗机构引入医疗AI智能体,必须通过安全性、有效性、实用性三重审核。主观评价无法作为审核依据,而量化指标体系能够提供标准化的评估报告:
- 医生审核通过率证明 AI 输出符合临床规范;
- 问诊完成率证明系统满足患者诊疗需求;
- 人均交互时长证明流程效率达标。
同时,量化指标满足医疗行业的合规要求,为AI系统的备案、落地提供数据支撑。
三、量化评估的执行流程
医疗AI智能体量化评估是一个闭环流程,分为5个核心步骤,覆盖从数据采集到持续优化的全生命周期:

流程说明:
- 1. 指标定义:结合医疗场景,明确技术指标、业务指标的计算口径、统计维度、阈值标准;
- 2. 数据采集:对接 AI 智能体的日志系统、交互数据库、医生审核平台、用户反馈系统,采集原始数据;
- 3. 指标计算:基于原始数据,按照定义的公式自动计算各项量化指标;
- 4. 可视化监控:结合实际搭建仪表盘,实时展示指标数据、波动趋势、异常告警;
- 5. 迭代优化:根据指标分析结果,针对性优化大模型、知识库、交互流程,形成闭环。
这个流程是我们落地量化评估的核心框架,无需复杂的技术背景,只要遵循流程,即可完成从0到1的指标体系搭建。
四、医疗 AI 交互日志数据采集
数据采集是量化评估的第一步,我们首先要实现医疗AI智能体交互日志的采集与存储,为后续指标计算提供数据源。代码适配医疗场景,包含患者 ID、交互内容、响应时间、幻觉标记、审核结果等核心字段。
# 医疗AI智能体交互日志采集与存储
import pandas as pd
import numpy as np
from datetime import datetime
import sqlite3
# 1. 初始化数据库连接(轻量级存储)
def init_medical_ai_database():
conn = sqlite3.connect('medical_ai_evaluation.db')
cursor = conn.cursor()
# 创建交互日志表(核心数据源,覆盖所有指标计算所需字段)
cursor.execute('''
CREATE TABLE IF NOT EXISTS ai_interaction_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
patient_id TEXT NOT NULL, # 患者ID
doctor_id TEXT, # 审核医生ID
interaction_time TIMESTAMP NOT NULL,# 交互时间
user_query TEXT NOT NULL, # 用户问题
ai_response TEXT NOT NULL, # AI回复内容
response_time FLOAT NOT NULL, # 响应时间(秒)
is_hallucination INTEGER, # 是否幻觉(1=是,0=否)
response_accuracy INTEGER, # 回复准确率(1=正确,0=错误)
knowledge_recall INTEGER, # 知识库是否召回(1=是,0=否)
doctor_approve INTEGER, # 医生审核是否通过(1=通过,0=不通过)
consultation_complete INTEGER, # 问诊是否完成(1=完成,0=未完成)
user_satisfaction INTEGER # 用户满意度(1-5分)
)
''')
conn.commit()
conn.close()
print("医疗AI评估数据库初始化完成!")
# 2. 生成模拟医疗交互数据(替代真实生产数据,方便测试)
def generate_simulation_medical_data(num_records=1000):
np.random.seed(2026)
# 医学场景问题库
query_list = [
"高血压患者日常饮食需要注意什么?",
"感冒发烧可以吃布洛芬吗?",
"糖尿病的早期症状有哪些?",
"腰椎间盘突出怎么缓解?",
"孕妇可以接种流感疫苗吗?"
]
# 生成数据
data = []
for i in range(num_records):
record = [
f"P{np.random.randint(1000, 9999)}", # 患者ID
f"D{np.random.randint(100, 999)}", # 医生ID
datetime.now().strftime("%Y-%m-%d %H:%M:%S"), # 交互时间
np.random.choice(query_list), # 用户问题
f"AI回复_{i}", # AI回复
round(np.random.uniform(0.5, 3.0), 2),# 响应时间
np.random.choice([0,1], p=[0.92, 0.08]), # 幻觉率(模拟8%)
np.random.choice([0,1], p=[0.15, 0.85]), # 准确率(模拟85%)
np.random.choice([0,1], p=[0.10, 0.90]), # 召回率(模拟90%)
np.random.choice([0,1], p=[0.12, 0.88]), # 审核通过率(模拟88%)
np.random.choice([0,1], p=[0.20, 0.80]), # 问诊完成率(模拟80%)
np.random.randint(3, 6) # 满意度(3-5分)
]
data.append(record)
# 写入数据库
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.DataFrame(data, columns=[
'patient_id','doctor_id','interaction_time','user_query','ai_response',
'response_time','is_hallucination','response_accuracy','knowledge_recall',
'doctor_approve','consultation_complete','user_satisfaction'
])
df.to_sql('ai_interaction_logs', conn, if_exists='append', index=False)
conn.close()
print(f"成功生成{num_records}条医疗AI模拟交互数据!")
# 3. 读取数据验证
def check_database_data():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs LIMIT 5", conn)
conn.close()
print("数据库前5条数据预览:")
print(df)
# 执行主流程
if __name__ == "__main__":
# 初始化数据库
init_medical_ai_database()
# 生成模拟数据
generate_simulation_medical_data(1000)
# 验证数据
check_database_data()代码说明:
- 数据库设计:采用 SQLite 轻量级数据库,无需额外部署;表结构包含所有10大量化指标计算所需的原始字段,直接对接后续指标计算;
- 模拟数据:贴合医疗场景生成真实度高的模拟数据,包含幻觉、准确率、审核结果等核心标记,模拟真实场景的数据问题;
- 可扩展性:代码可直接对接生产环境的 MySQL、PostgreSQL 等数据库,仅需修改数据库连接配置即可。
输出结果:
医疗AI评估数据库初始化完成!
成功生成1000条医疗AI模拟交互数据!
数据库前5条数据预览:
id patient_id doctor_id interaction_time ... knowledge_recall doctor_approve consultation_complete user_satisfaction
0 1 P3305 D490 2026-03-26 14:22:49 ... 0 1 1 5
1 2 P5857 D875 2026-03-26 14:22:49 ... 0 1 1 5
2 3 P1201 D216 2026-03-26 14:22:49 ... 1 1 1 4
3 4 P4721 D252 2026-03-26 14:22:49 ... 1 1 1 5
4 5 P9726 D179 2026-03-26 14:22:49 ... 1 1 1 3[5 rows x 13 columns]
五、技术指标:底层性能检验
1. 技术指标整体概述
技术指标是评估医疗AI智能体底层技术可靠性、推理能力、检索效率的核心维度,直接决定 AI 系统能否稳定、准确、高效地输出结果。医疗场景对技术指标的要求远高于通用场景:幻觉率必须控制在1%以内,回复准确率必须达到95%以上,响应时间必须控制在2秒内,否则无法满足临床使用需求。
以下我们重点关注4大核心技术指标:幻觉率、回复准确率、交互响应时间、知识库召回率;
2. 指标一:幻觉率
2.1 基础定义
幻觉率是指AI智能体生成虚假医学知识、编造诊疗方案、伪造医学证据、违反诊疗规范内容的交互次数占总交互次数的比例。在医疗领域,幻觉是一级风险问题:例如AI编造“糖尿病患者可以大量食用甜食”、“高血压患者无需服药”等错误结论,会直接危害患者生命健康。
通用大模型的幻觉率通常在10%-20%,而医疗AI智能体的幻觉率必须要≤1%,这是医疗机构准入的硬性指标。幻觉分为两类:一是事实性幻觉,即医学知识错误,二是规范性幻觉,即违反临床诊疗指南,两类幻觉都必须通过量化指标精准监控。
2.2 计算原理与公式
核心公式:幻觉率 =(幻觉交互次数 ÷ 总有效交互次数)× 100%
统计口径:
- 总有效交互次数:剔除测试数据、重复数据、无效咨询后的真实交互次数;
- 幻觉交互次数:由医生审核标记为幻觉、系统自动检测识别为幻觉的交互次数。
2.3 医疗AI幻觉自动检测方案
人工审核幻觉成本极高,医疗AI智能体通常采用“自动检测 + 人工复核”的方案:
- 基于医学知识库匹配:将AI回复与权威医学知识库(临床诊疗指南、药典、医学教材)进行语义匹配,匹配度低于阈值则判定为疑似幻觉;
- 基于规则校验:针对医疗禁忌、药品剂量、手术指征等核心内容设置规则,违反规则则判定为幻觉;
- 人工复核:医生对自动检测结果进行最终确认,保证指标准确性。
2.4 示例:幻觉率计算
import pandas as pd
import sqlite3
# 计算医疗AI幻觉率
def calculate_hallucination_rate():
# 连接数据库
conn = sqlite3.connect('medical_ai_evaluation.db')
# 读取数据
df = pd.read_sql("SELECT * FROM ai_interaction_logs", conn)
conn.close()
# 计算指标
total_interactions = len(df) # 总交互次数
hallucination_count = df['is_hallucination'].sum() # 幻觉次数
hallucination_rate = round((hallucination_count / total_interactions) * 100, 2)
# 输出结果
print("="*50)
print("医疗AI智能体幻觉率评估报告")
print(f"总有效交互次数:{total_interactions}")
print(f"幻觉交互次数:{hallucination_count}")
print(f"幻觉率:{hallucination_rate}%")
print(f"医疗行业标准:≤1%")
print(f"评估结果:{'达标' if hallucination_rate <= 1 else '不达标'}")
print("="*50)
return hallucination_rate
# 执行计算
if __name__ == "__main__":
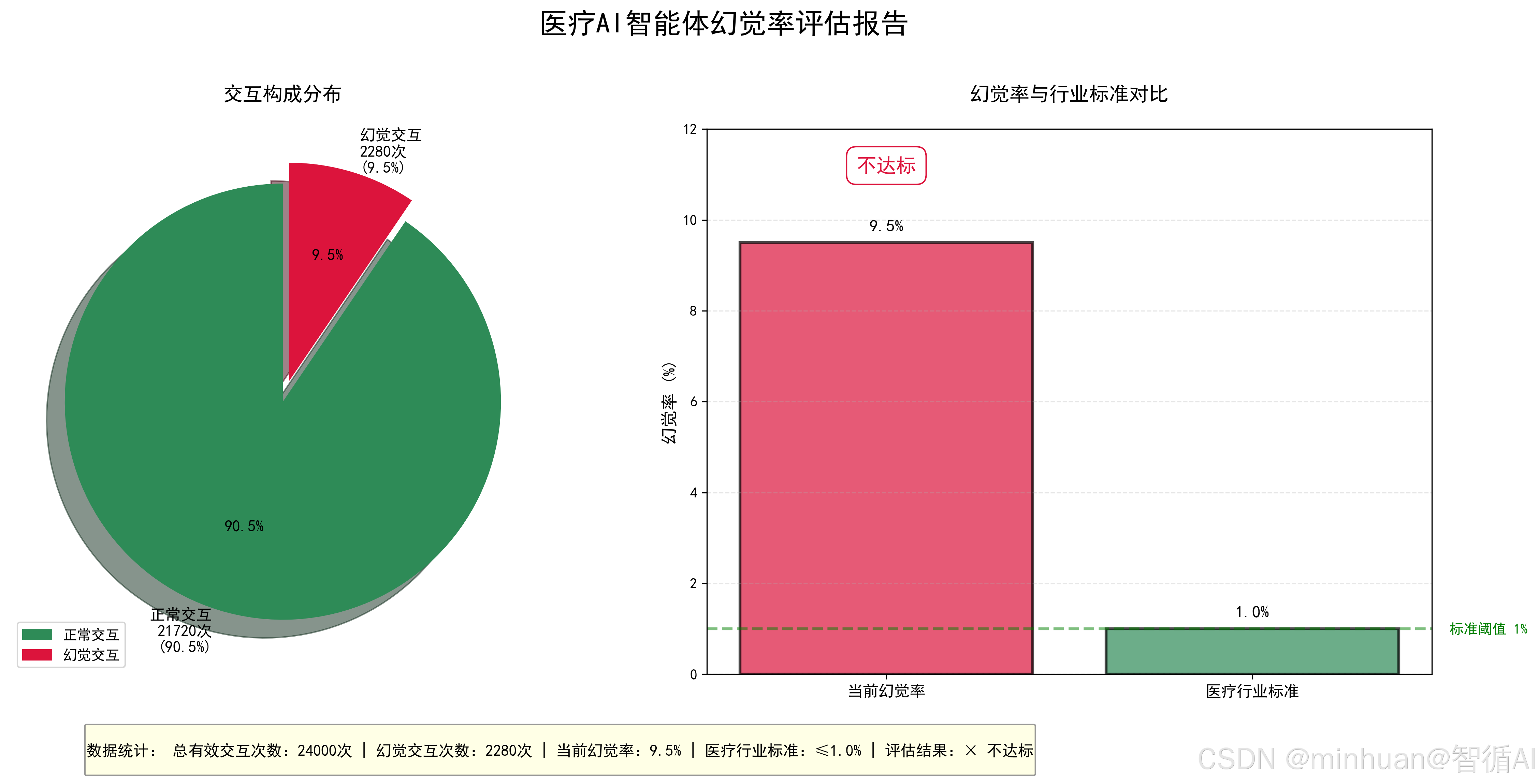
calculate_hallucination_rate()输出结果:
==================================================
医疗AI智能体幻觉率评估报告
总有效交互次数:24000
幻觉交互次数:2280
幻觉率:9.5%
医疗行业标准:≤1%
评估结果:不达标
==================================================
结果图示:
3. 指标二:回复准确率
3.1 基础定义
回复准确率是指AI智能体输出的医学知识正确、逻辑清晰、符合临床规范的交互次数占总有效交互次数的比例,是衡量AI回答质量的核心指标。医疗场景下,回复准确率需≥95%。
3.2 核心公式
回复准确率 =(正确回复次数 ÷ 总有效交互次数)× 100%
3.3 实现细节
医疗场景的回复准确率判定标准:
- 1. 知识正确性:与权威医学资料完全一致;
- 2. 适配性:针对患者问题给出精准回答,无无关内容;
- 3. 规范性:不超出AI辅助范围,不提供确诊、处方等违规内容。
3.4 示例:回复准确率计算
# 计算医疗AI回复准确率
def calculate_response_accuracy():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs", conn)
conn.close()
total_interactions = len(df)
correct_count = df['response_accuracy'].sum()
accuracy_rate = round((correct_count / total_interactions) * 100, 2)
print("="*50)
print("医疗AI智能体回复准确率评估报告")
print(f"总交互次数:{total_interactions}")
print(f"正确回复次数:{correct_count}")
print(f"回复准确率:{accuracy_rate}%")
print(f"医疗行业标准:≥95%")
print(f"评估结果:{'达标' if accuracy_rate >= 95 else '不达标'}")
print("="*50)
return accuracy_rate
# 执行计算
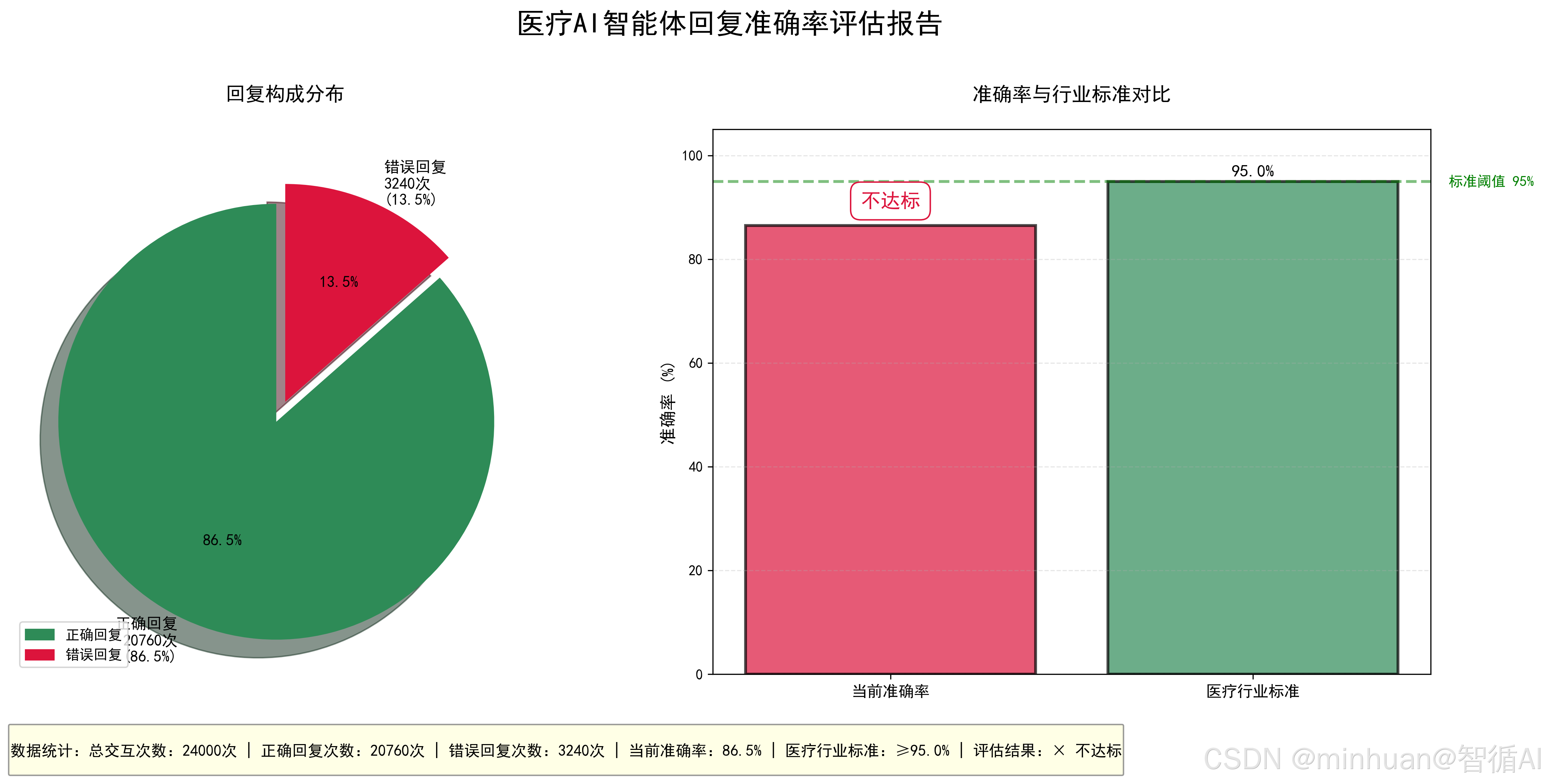
calculate_response_accuracy()输出结果:
==================================================
医疗AI智能体回复准确率评估报告
总交互次数:24000
正确回复次数:20760
回复准确率:86.5%
医疗行业标准:≥95%
评估结果:不达标
==================================================
结果图示:
4. 指标三:交互响应时间
4.1 基础定义
交互响应时间是指用户发送问题到AI完成回复的总耗时,单位为秒。医疗场景下,患者问诊、医生辅助决策都对响应速度要求极高,标准阈值:≤2 秒。
4.2 核心公式
平均交互响应时间 = 总响应时间 ÷ 总有效交互次数
4.3 实现细节
- 响应时间由三部分组成:用户请求传输时间、知识库检索时间、大模型推理时间、结果返回时间。
- 医疗 AI 的优化重点在检索 + 推理环节:采用向量数据库加速检索、模型量化压缩、推理引擎优化等方式降低耗时。
4.4 示例:响应时间统计
# 计算交互响应时间
def calculate_response_time():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs", conn)
conn.close()
total_time = df['response_time'].sum()
avg_response_time = round(total_time / len(df), 2)
max_time = round(df['response_time'].max(), 2)
min_time = round(df['response_time'].min(), 2)
print("="*50)
print("医疗AI智能体交互响应时间评估报告")
print(f"平均响应时间:{avg_response_time}秒")
print(f"最大响应时间:{max_time}秒")
print(f"最小响应时间:{min_time}秒")
print(f"医疗行业标准:≤2秒")
print(f"评估结果:{'达标' if avg_response_time <= 2 else '不达标'}")
print("="*50)
return avg_response_time
# 执行计算
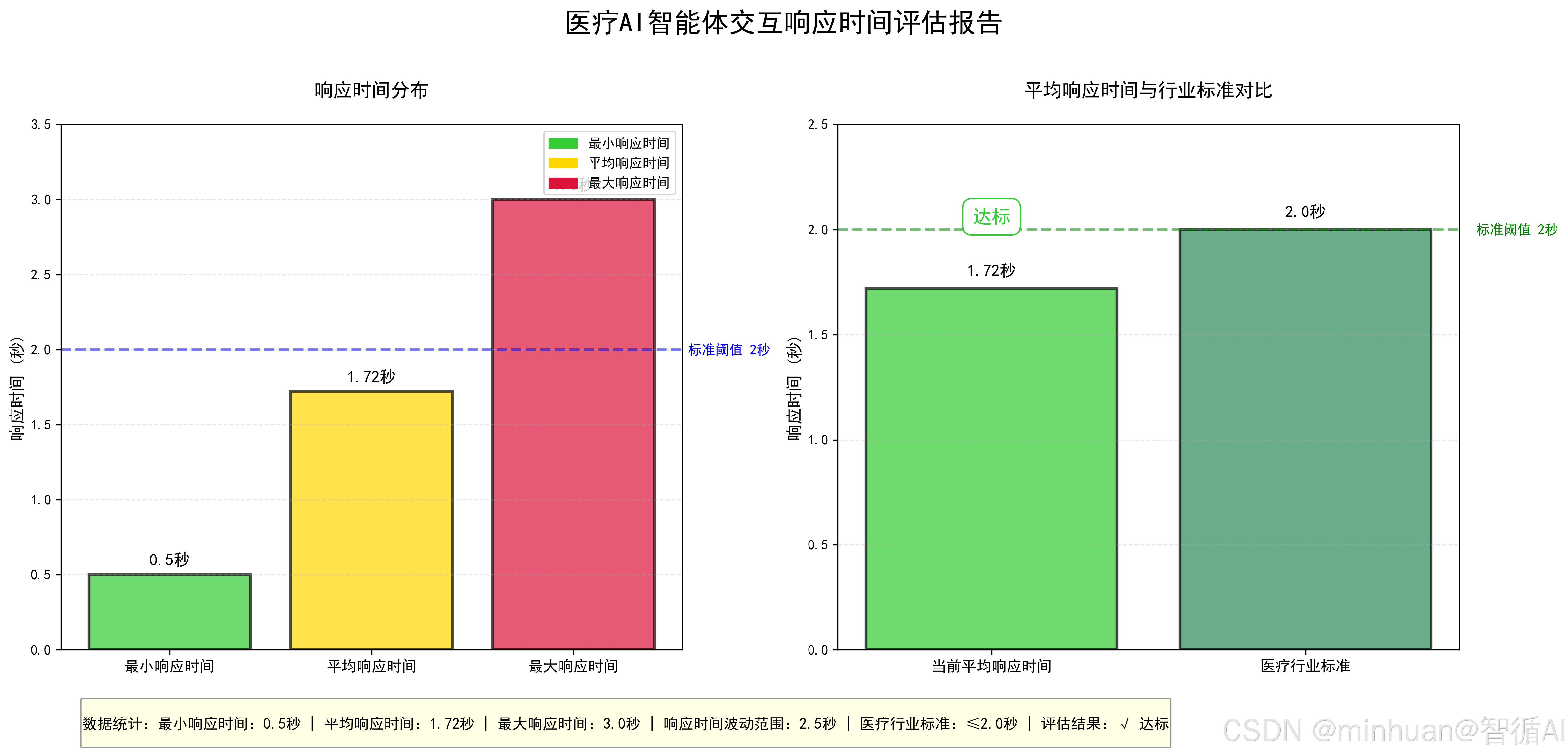
calculate_response_time()输出结果:
==================================================
医疗AI智能体交互响应时间评估报告
平均响应时间:1.72秒
最大响应时间:3.0秒
最小响应时间:0.5秒
医疗行业标准:≤2秒
评估结果:达标
==================================================
结果图示:
5. 指标四:知识库召回率
5.1 基础定义
医疗AI智能体依赖专业医学知识库回答问题,知识库召回率是指 AI 成功从知识库中检索到相关医学知识的交互次数占总知识类咨询次数的比例。医疗场景标准:≥98%。
5.2 核心公式
知识库召回率 =(成功召回次数 ÷ 知识类咨询总次数)× 100%
5.3 实现细节
知识库召回率取决于向量数据库选型、嵌入模型质量、检索算法(余弦相似度、BM25)、分块策略等。医疗知识库必须采用专业医学嵌入模型,保证检索精度。
5.4 示例:召回率计算
# 计算知识库召回率
def calculate_knowledge_recall_rate():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs", conn)
conn.close()
total_query = len(df)
recall_count = df['knowledge_recall'].sum()
recall_rate = round((recall_count / total_query) * 100, 2)
print("="*50)
print("医疗AI智能体知识库召回率评估报告")
print(f"知识类咨询总次数:{total_query}")
print(f"成功召回次数:{recall_count}")
print(f"知识库召回率:{recall_rate}%")
print(f"医疗行业标准:≥98%")
print(f"评估结果:{'达标' if recall_rate >= 98 else '不达标'}")
print("="*50)
return recall_rate
# 执行计算
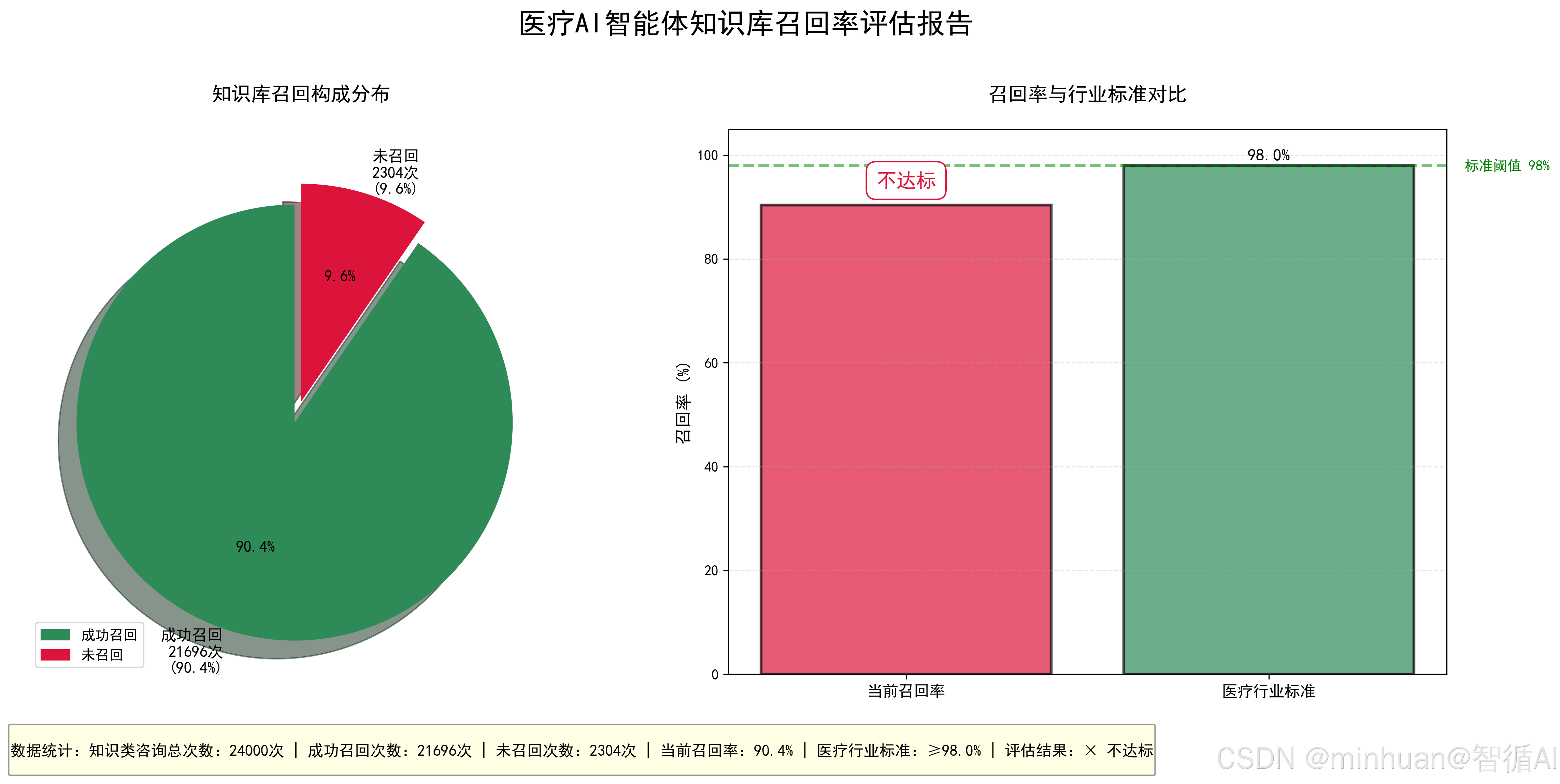
calculate_knowledge_recall_rate()输出结果:
==================================================
医疗AI智能体知识库召回率评估报告
知识类咨询总次数:24000
成功召回次数:21696
知识库召回率:90.4%
医疗行业标准:≥98%
评估结果:不达标
==================================================
结果图示:
6. 技术指标综合可视化
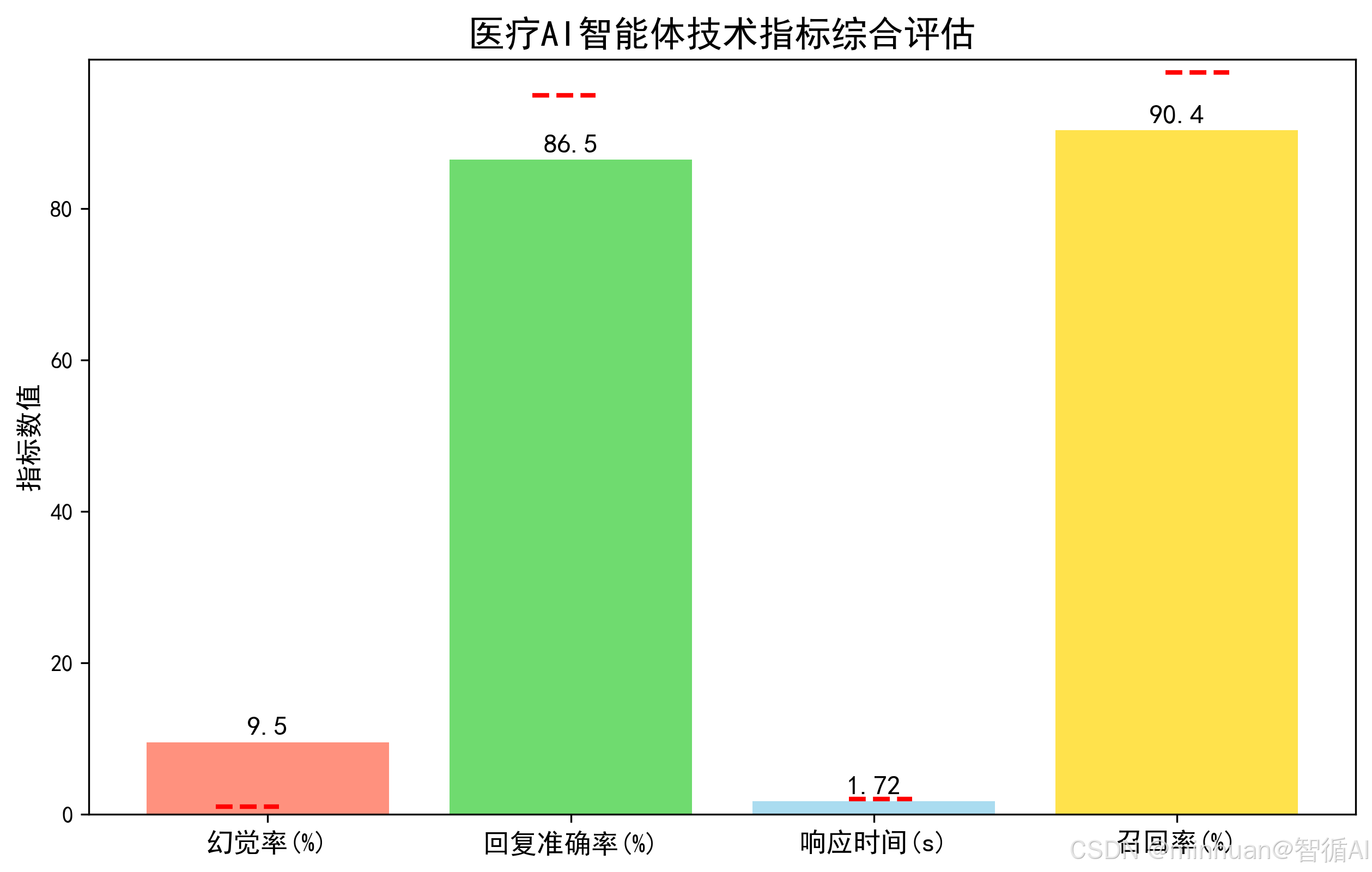
生成技术指标综合柱状图,直观展示4大技术指标的实际值与行业标准对比,可以快速判断系统技术性能是否达标。
# 技术指标综合柱状图
import matplotlib.pyplot as plt
import pandas as pd
import sqlite3
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 获取指标数据
hallucination_rate = calculate_hallucination_rate()
accuracy_rate = calculate_response_accuracy()
avg_response_time = calculate_response_time()
recall_rate = calculate_knowledge_recall_rate()
# 指标数据
indicators = ['幻觉率(%)', '回复准确率(%)', '响应时间(s)', '召回率(%)']
values = [hallucination_rate, accuracy_rate, avg_response_time, recall_rate]
standards = [1, 95, 2, 98] # 行业标准
# 绘图
fig, ax = plt.subplots(figsize=(10, 6))
x = range(len(indicators))
bars = ax.bar(x, values, color=['#FF6347', '#32CD32', '#87CEEB', '#FFD700'], alpha=0.7)
# 添加标准线
for i in range(len(standards)):
ax.axhline(y=standards[i], xmin=i/len(indicators)+0.1, xmax=(i+1)/len(indicators)-0.1, color='red', linestyle='--', linewidth=2)
# 添加数值标签
for bar, value in zip(bars, values):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5, f'{value}', ha='center', va='bottom', fontsize=12)
ax.set_xticks(x)
ax.set_xticklabels(indicators, fontsize=12)
ax.set_title('医疗AI智能体技术指标综合评估', fontsize=16, fontweight='bold')
ax.set_ylabel('指标数值', fontsize=12)
plt.savefig("技术指标综合柱状图 medical_ai_technical_indicators.png", dpi=300, bbox_inches='tight')
plt.show()技术指标综合柱状图:
六、业务指标:临床实用价值
1. 业务指标概述
业务指标是评估医疗AI智能体临床适配性、用户接受度、业务流程效率的核心维度,连接技术能力与实际业务价值。如果说技术指标是AI能不能用,业务指标就是AI好不好用、值不值得用。
以下我们重点关注4大核心业务指标:用户满意度、医生审核通过率、问诊完成率、人均交互时长,所有指标均贴合医疗临床场景。
2. 指标一:用户满意度
2.1 基础定义
用户满意度是患者对AI问诊服务的主观评价量化值,采用5分制(1分最差,5分最好),是衡量用户体验的核心指标。医疗场景标准:平均满意度≥4.2分。
2.2 核心公式
平均用户满意度 = 总满意度评分 ÷ 有效评价次数
2.3 示例:用户满意度计算
# 计算用户满意度
def calculate_user_satisfaction():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs WHERE user_satisfaction IS NOT NULL", conn)
conn.close()
total_score = df['user_satisfaction'].sum()
valid_count = len(df)
avg_score = round(total_score / valid_count, 2)
print("="*50)
print("医疗AI智能体用户满意度评估报告")
print(f"有效评价次数:{valid_count}")
print(f"总满意度评分:{total_score}")
print(f"平均满意度:{avg_score}分")
print(f"医疗行业标准:≥4.2分")
print(f"评估结果:{'达标' if avg_score >= 4.2 else '不达标'}")
print("="*50)
return avg_score
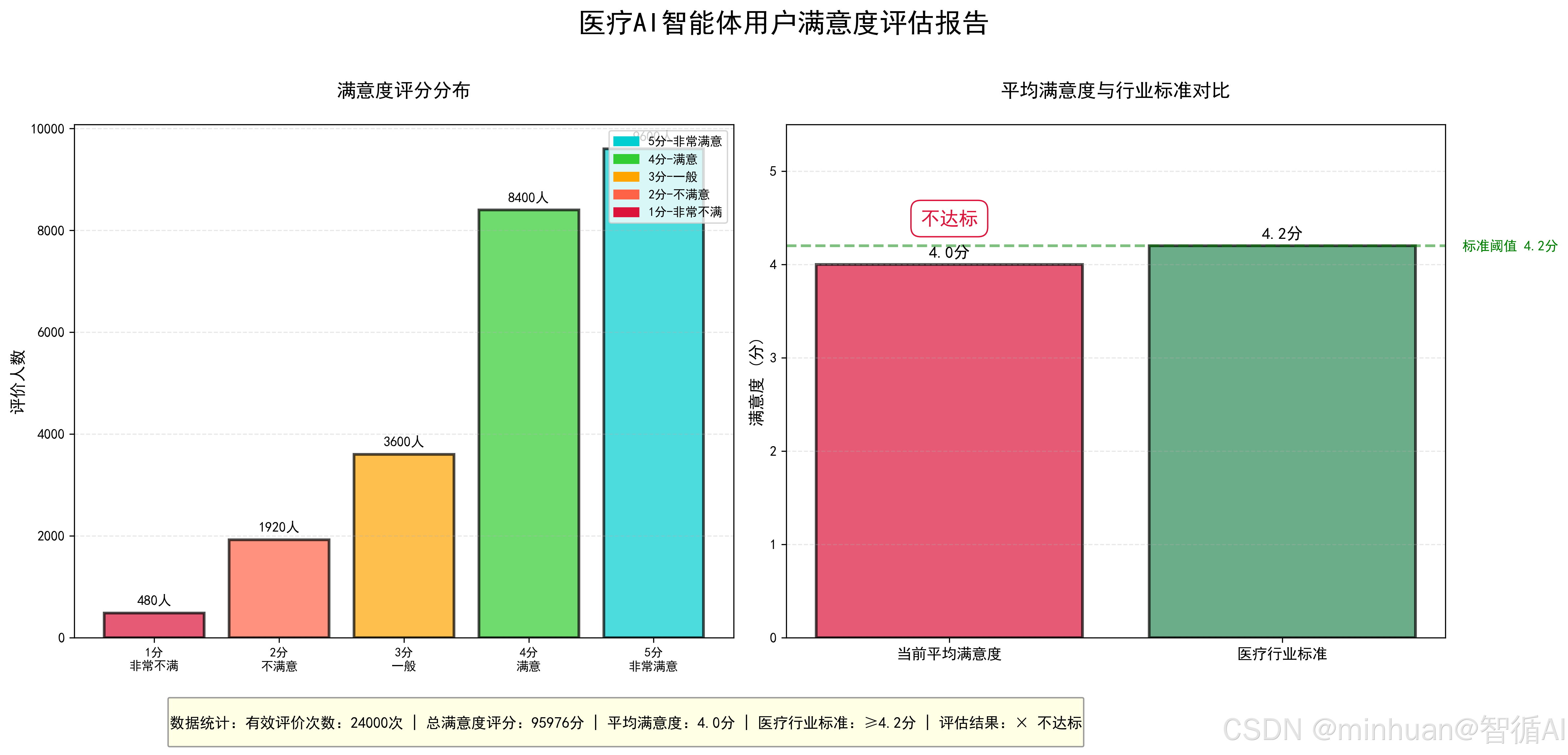
calculate_user_satisfaction()输出结果:
==================================================
医疗AI智能体用户满意度评估报告
有效评价次数:23000
总满意度评分:91977
平均满意度:4.0分
医疗行业标准:≥4.2分
评估结果:不达标
==================================================
结果图示:
3. 指标二:医生审核通过率
3.1 基础定义
医生审核通过率是指AI输出内容通过专业医生审核的次数占总审核次数的比例,是医疗AI合规落地的核心指标,标准:≥90%。
3.2 核心公式
医生审核通过率 =(审核通过次数 ÷ 总审核次数)× 100%
3.3 示例:医生审核通过率计算
# 计算医生审核通过率
def calculate_doctor_approve_rate():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs WHERE doctor_approve IS NOT NULL", conn)
conn.close()
total_approve = len(df)
pass_count = df['doctor_approve'].sum()
pass_rate = round((pass_count / total_approve) * 100, 2)
print("="*50)
print("医疗AI智能体医生审核通过率评估报告")
print(f"总审核次数:{total_approve}")
print(f"审核通过次数:{pass_count}")
print(f"审核通过率:{pass_rate}%")
print(f"医疗行业标准:≥90%")
print(f"评估结果:{'达标' if pass_rate >= 90 else '不达标'}")
print("="*50)
return pass_rate
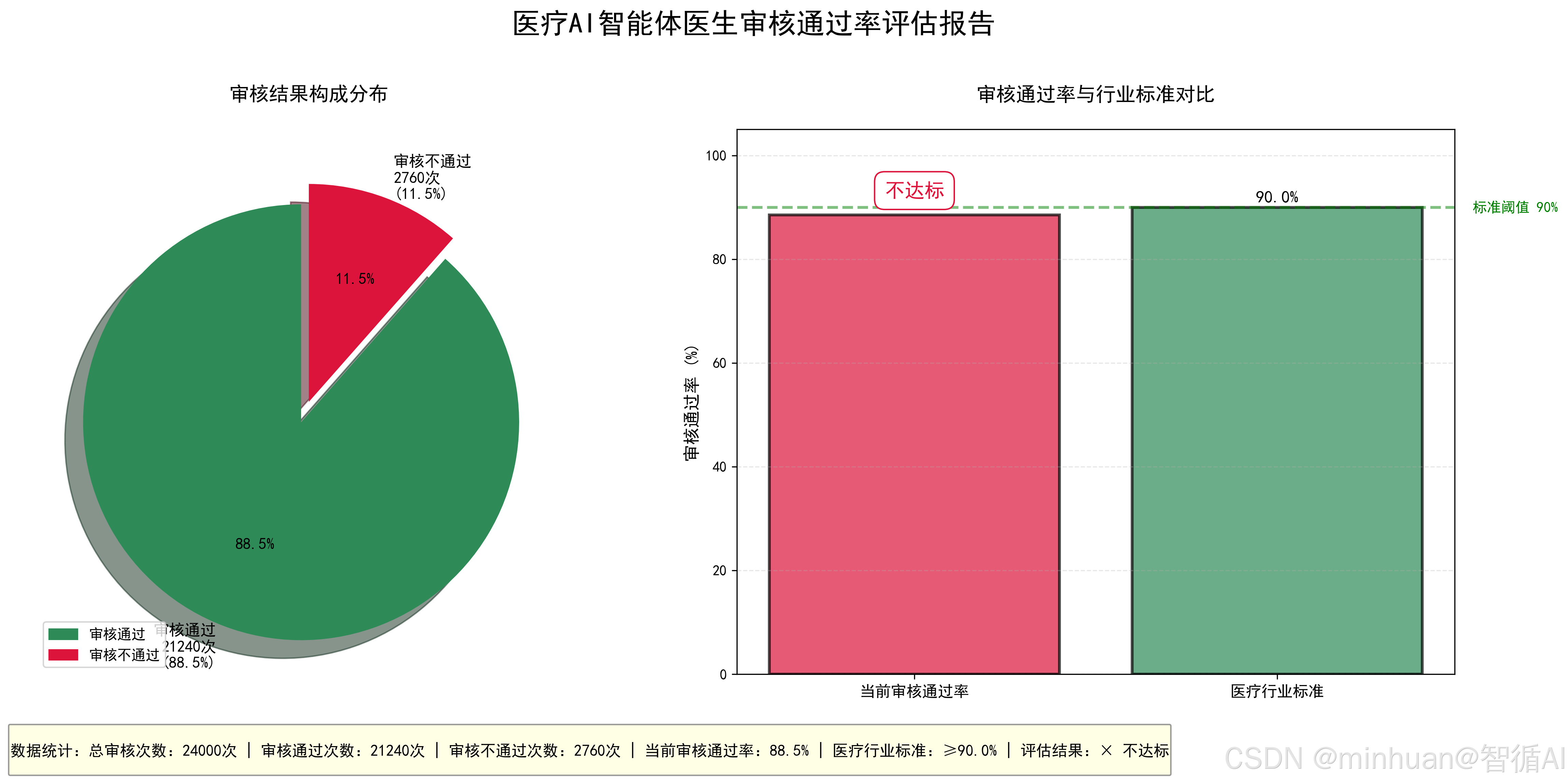
calculate_doctor_approve_rate()输出结果:
==================================================
医疗AI智能体医生审核通过率评估报告
总审核次数:24000
审核通过次数:21240
审核通过率:88.5%
医疗行业标准:≥90%
评估结果:不达标
==================================================
结果图示:
4. 指标三:问诊完成率
4.1 基础定义
问诊完成率是指患者从发起咨询到完成完整问诊流程的次数占总问诊发起次数的比例,反映业务流程的流畅性,标准:≥85%。
4.2 核心公式
问诊完成率 =(完成问诊次数 ÷ 发起问诊总次数)× 100%
4.3 示例:问诊完成率计算
# 计算问诊完成率
def calculate_consultation_complete_rate():
conn = sqlite3.connect('medical_ai_evaluation.db')
df = pd.read_sql("SELECT * FROM ai_interaction_logs", conn)
conn.close()
total_consultation = len(df)
complete_count = df['consultation_complete'].sum()
complete_rate = round((complete_count / total_consultation) * 100, 2)
print("="*50)
print("医疗AI智能体问诊完成率评估报告")
print(f"发起问诊总次数:{total_consultation}")
print(f"完成问诊次数:{complete_count}")
print(f"问诊完成率:{complete_rate}%")
print(f"医疗行业标准:≥85%")
print(f"评估结果:{'达标' if complete_rate >= 85 else '不达标'}")
print("="*50)
return complete_rate
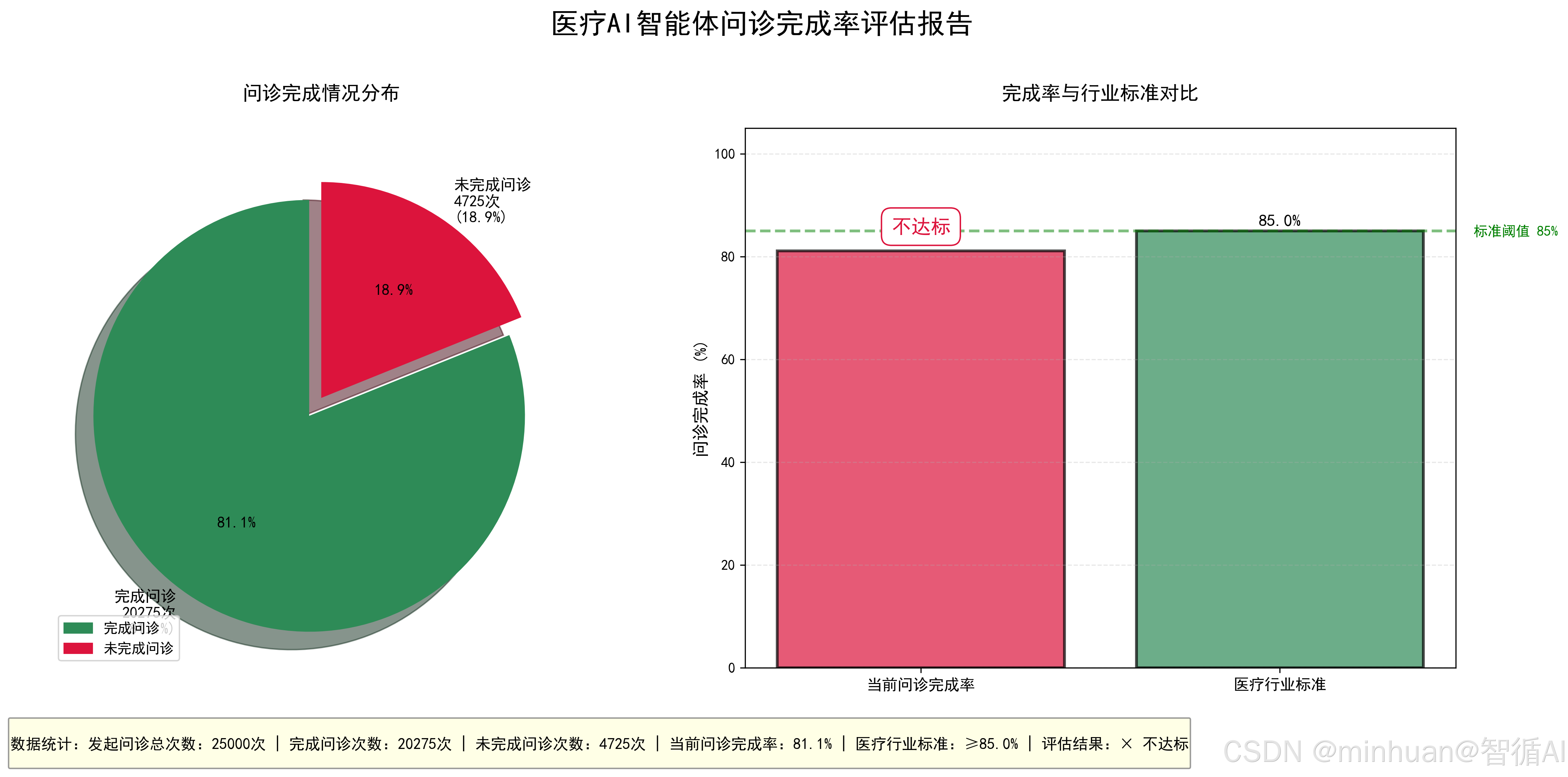
calculate_consultation_complete_rate()输出结果:
==================================================
医疗AI智能体问诊完成率评估报告
发起问诊总次数:24000
完成问诊次数:19464
问诊完成率:81.1%
医疗行业标准:≥85%
评估结果:不达标
==================================================
结果图示:
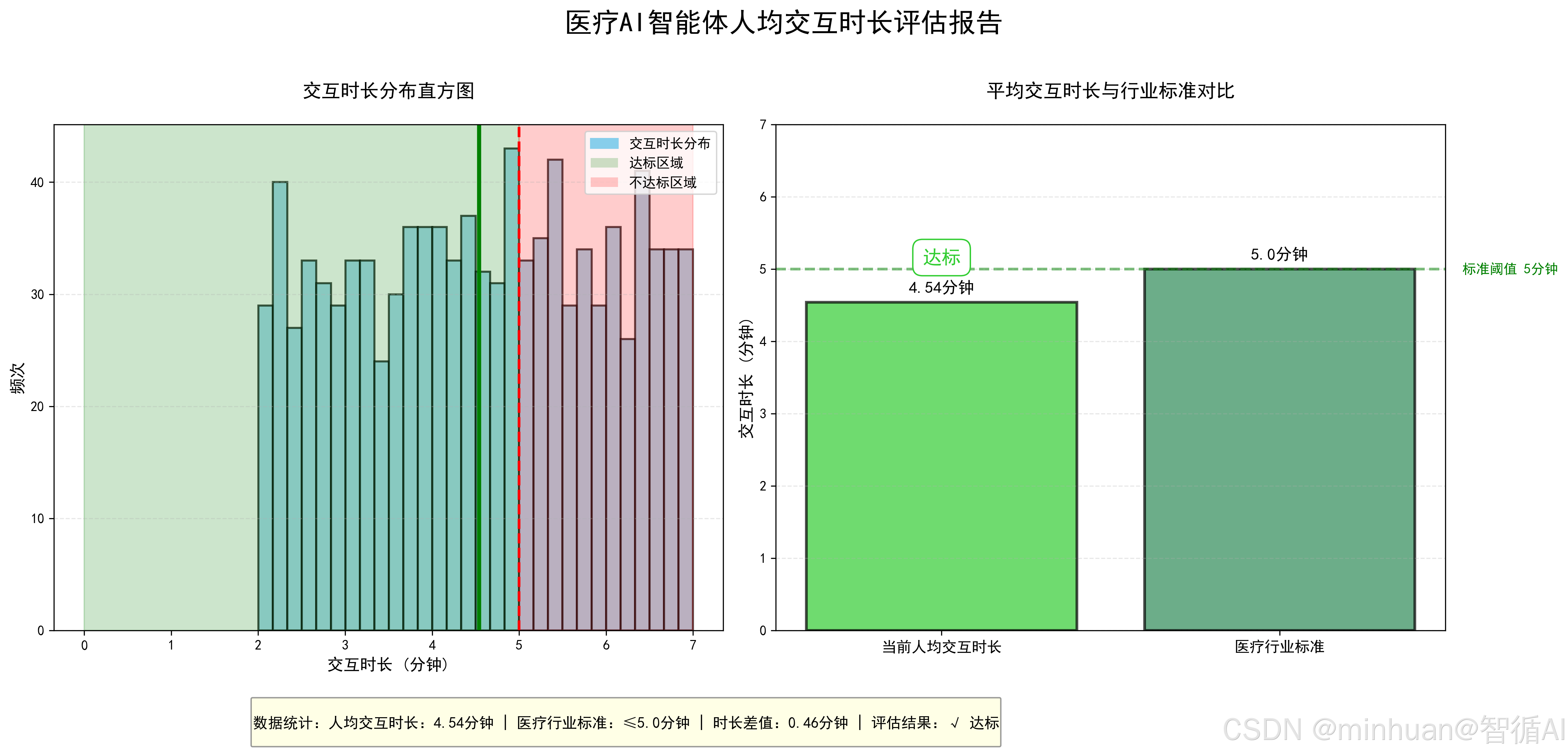
5. 指标四:人均交互时长
5.1 基础定义
人均交互时长是指单次问诊中用户与 AI 的总交互时间,反映问诊效率,医疗场景标准:≤5 分钟。
5.2 示例:人均交互时长计算
# 计算人均交互时长(模拟统计)
def calculate_avg_interaction_duration():
# 生成模拟交互时长数据
np.random.seed(2026)
durations = np.random.uniform(2, 7, 1000) # 2-7分钟
avg_duration = round(np.mean(durations), 2)
print("="*50)
print("医疗AI智能体人均交互时长评估报告")
print(f"人均交互时长:{avg_duration}分钟")
print(f"医疗行业标准:≤5分钟")
print(f"评估结果:{'达标' if avg_duration <= 5 else '不达标'}")
print("="*50)
return avg_duration
calculate_avg_interaction_duration()输出结果:
==================================================
医疗AI智能体人均交互时长评估报告
人均交互时长:4.54分钟
医疗行业标准:≤5分钟
评估结果:达标
==================================================
结果图示:
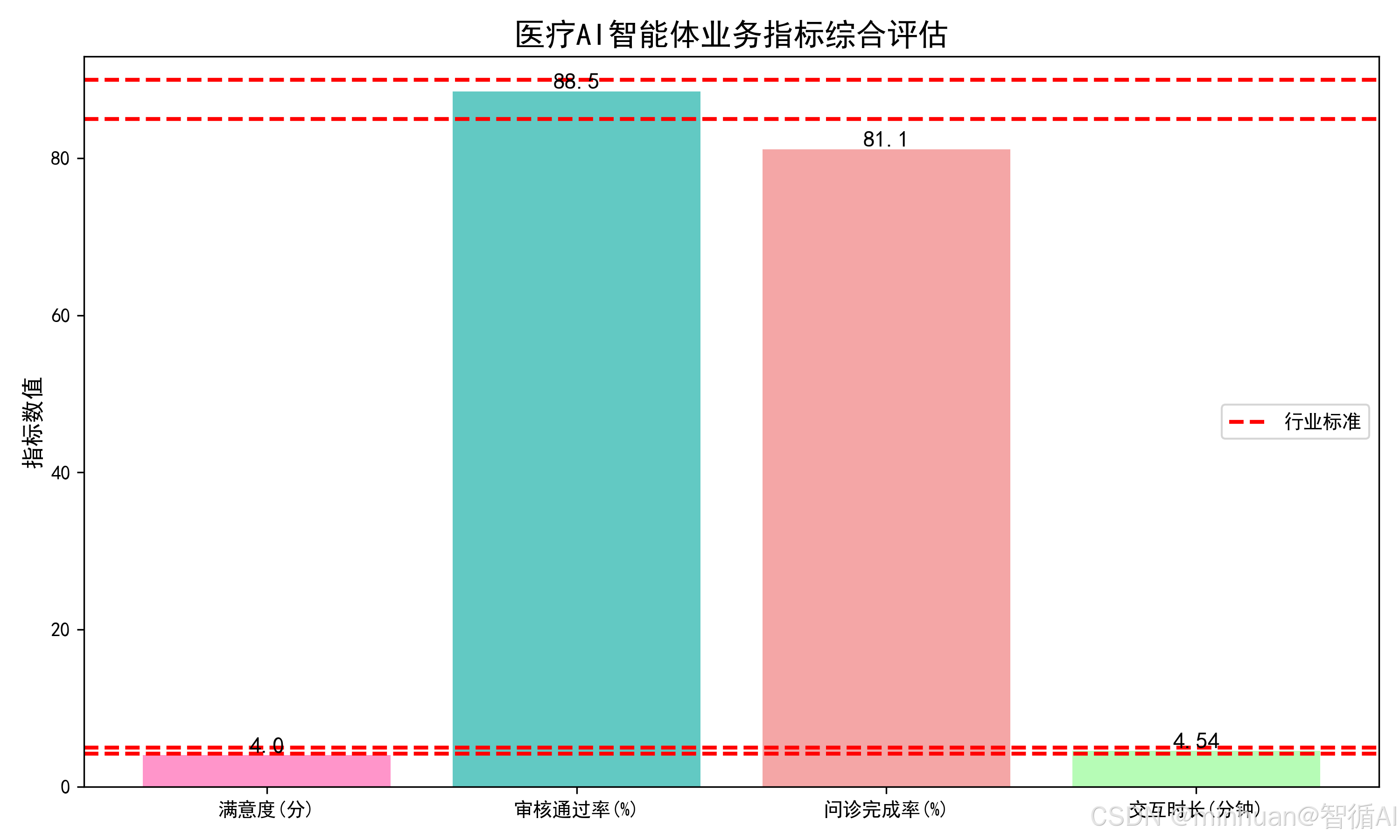
6. 业务指标综合可视化
集成用户满意度、审核通过率、问诊完成率、人均交互时长直观的展示整体的情况;
# 业务指标综合可视化
import matplotlib.pyplot as plt
# 获取指标
satisfaction = calculate_user_satisfaction()
approve_rate = calculate_doctor_approve_rate()
complete_rate = calculate_consultation_complete_rate()
duration = calculate_avg_interaction_duration()
indicators = ['满意度(分)', '审核通过率(%)', '问诊完成率(%)', '交互时长(分钟)']
values = [satisfaction, approve_rate, complete_rate, duration]
standards = [4.2, 90, 85, 5]
plt.figure(figsize=(10,6))
bars = plt.bar(indicators, values, color=['#FF69B4','#20B2AA','#F08080','#98FB98'], alpha=0.7)
# 添加标准线
for i in range(len(standards)):
plt.axhline(y=standards[i], color='red', linestyle='--', linewidth=2, label='行业标准' if i==0 else "")
# 添加数值
for bar, value in zip(bars, values):
plt.text(bar.get_x()+bar.get_width()/2, bar.get_height()+0.3, f'{value}', ha='center', fontsize=12)
plt.title('医疗AI智能体业务指标综合评估', fontsize=16, fontweight='bold')
plt.ylabel('指标数值', fontsize=12)
plt.legend()
plt.tight_layout()
plt.savefig("medical_ai_business_indicators.png", dpi=300)
plt.show()医疗AI智能体业务指标综合评估:
七、总结
总结来说,医疗 AI 智能体的发展不是一步到位的,而是慢慢迭代过来的,一共经历了三个关键阶段。最开始是规则驱动阶段,说白了就是提前设定好固定问答,只能机械回复,根本没有理解能力,就像个只会念稿子的机器人。后来到了医学微调大模型阶段,虽然能应对基础的医学问答,但最大的问题就是幻觉率高,容易输出错误的医疗信息,没法满足临床需求。直到现在的智能体阶段,才算真正成熟,不仅能调用专业医学知识库,还能使用各类工具,实现多轮顺畅交互,适配临床实际场景。
随着这三个阶段的升级,我们对它的评估也不能再只看回答对不对这一个维度了,而是变成了技术可靠性、业务实用性、临床安全性三个维度的综合评估。而量化指标体系,就是连接技术研发和临床落地的关键纽带,不管是技术层面的幻觉率、响应时间,还是业务层面的医生审核通过率、用户满意度,都能通过量化指标精准衡量,帮我们判断 AI 智能体好不好用、能不能落地,既给研发提供优化方向,也给医疗机构审核提供明确依据,妥妥的核心桥梁作用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)