多模态数据标注平台LabelStudio——部署与智能标注体验
0. 前言
由于最近个人兴趣原因,需要调研下数据标注平台。看了这些平台:
- https://github.com/cvat-ai/cvat
- https://roboflow.com/
- https://github.com/HumanSignal/label-studio
- https://platform.ultralytics.com/
从丰富性与二次开发角度对比,最终决定使用Label Studio进行一次实践,也趁此机会了解下关于数据标注与AI智能标注的相关知识。
1. label-studio简介
如Label Studio的仓库地址(https://github.com/HumanSignal/label-studio )所述,Label Studio是一个使用Python+TypeScript多模态数据标注平台,开源协议为Apache-2.0,非常适合二次开发或商用。
Label Studio也支持多种部署方式,如需快速体验,推荐使用docker一键部署:
docker run -it -p 8080:8080 -v $(pwd)/mydata:/label-studio/data heartexlabs/label-studio:latest
之后访问对应的web服务,如:http://192.168.1.101:8080
2. 功能体验
label-studio支持系统内置的模板和自定义模板标注。
2.1 图像标注
上传数据集,并设置标签;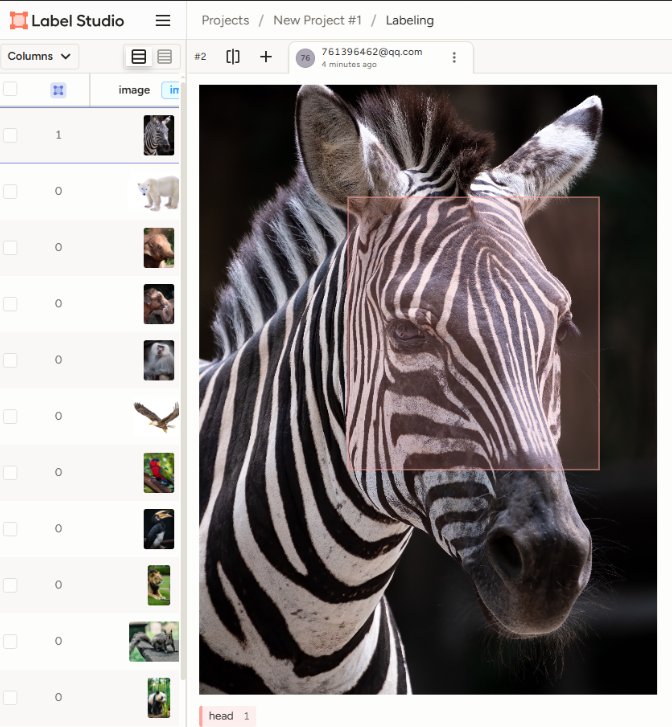
我上面设置的是标注名为head,在上传的数据集中自己拖拽出一个head的矩形区域即可。
2.2 视频/音频标注
音视频标注也是类似的,加载了资源文件后,根据任务的类型框出对应需要标注的区域。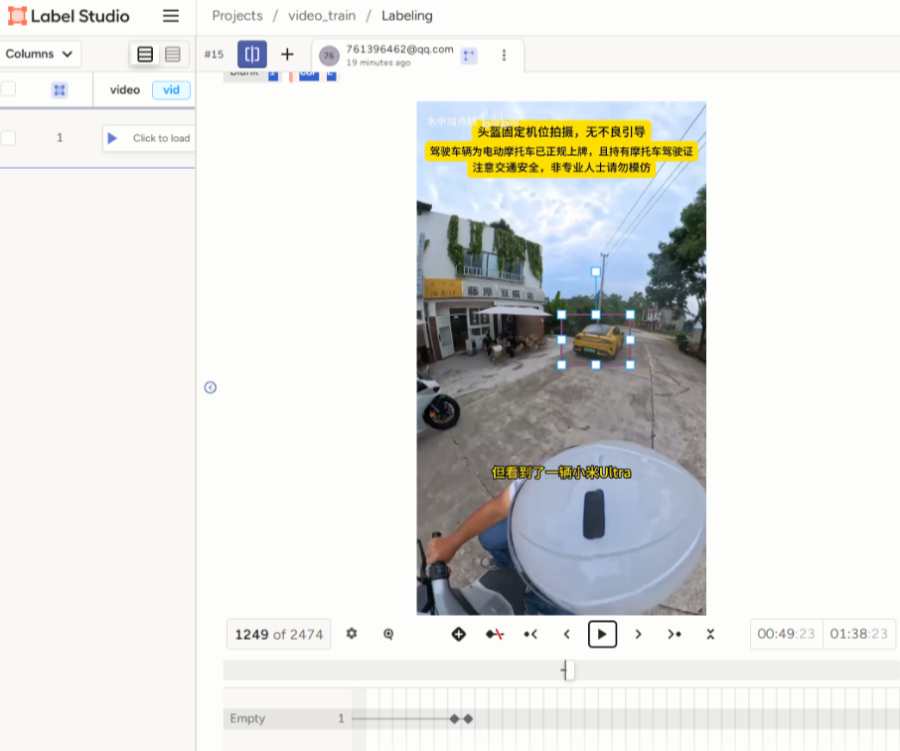
2.3 文本标注
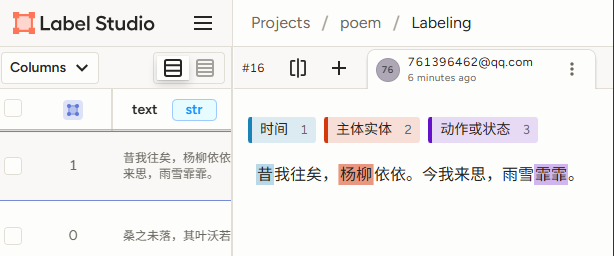
提前设置好文本标签,就可以对导入的文本进行标注了。
2.4 数据的导入/导出
数据支持本地上传,与外部数据源导入。与之前笔者调研的RAGFlow类似的,LabelStudio也分为开源社区版和企业版,企业版的LabelStudio具有更强大的功能。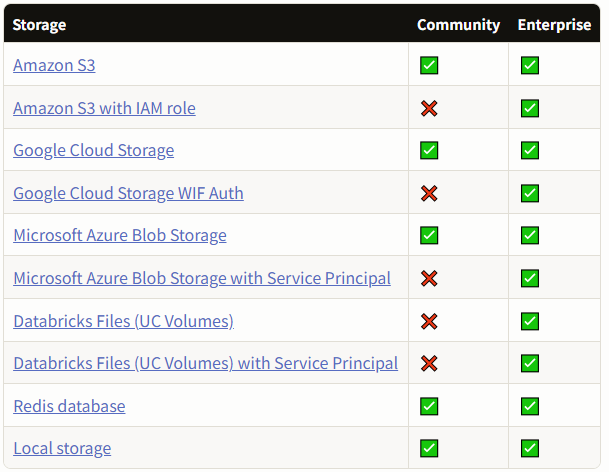
现导出支持的数据格式有:
- ASR_MANIFEST
- Brush labels to NumPy and PNG
- COCO
- CoNLL2003
- CSV
- JSON
- JSON_MIN
- Pascal VOC XML
- spaCy
- TSV
- YOLO
如果遇到暂不支持的数据格式,LabelStudio官方也提供了对应的源码以方便我们进行扩展开发。详见:label_studio_sdk-converter
3.AI智能标注-ML Backend
在LabelStudio中也支持使用ML Backend集成机器学习框架来实现数据集的预标注和自动标注,从而提高数据标注的效率。
整合了ML Backend之后的数据标注任务流程图如上所示。
3.1 ML Backend部署
Label Studio中的ML backend是一个WEB服务,在这个服务中定义了一些关于机器学习(machine learn)的流程和代码。通过让ML Backend与Label Studio连接后,从而实现自动化的标注。
LabelStudio官方也提供了一些关于ML Backend的示例,地址为:https://github.com/HumanSignal/label-studio-ml-backend?tab=readme-ov-file#models ,通过对这些示例的修改,可快速实现一个符合自己场景的AI标注工作流。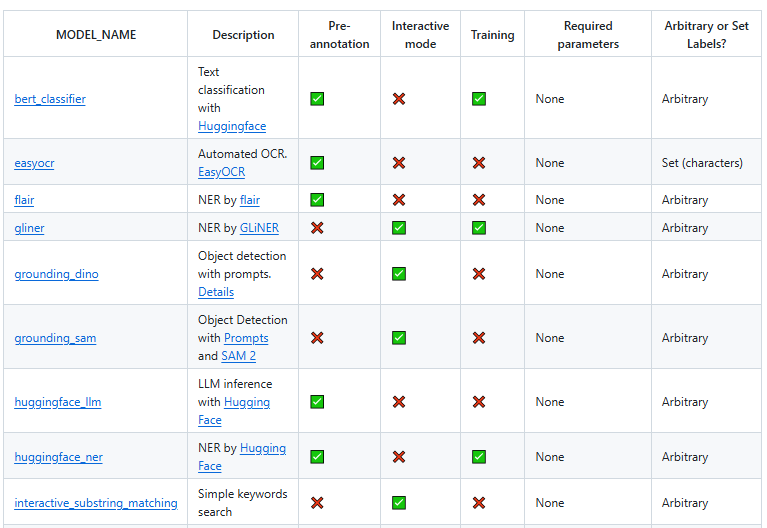
这里以SAM模型为例,演示一下:
git clone https://github.com/HumanSignal/label-studio-ml-backend.git
cd label-studio-ml-backend/label_studio_ml/examples/segment_anything_model
其docker-compose.yml中的内容如下:
version: "3.8"
services:
segment_anything_model:
container_name: segment_anything_model
image: heartexlabs/label-studio-ml-backend:sam-master
init: true
build:
context: .
shm_size: '4gb'
args:
TEST_ENV: ${TEST_ENV}
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
# Add this to pass through 1 GPU
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]
environment:
# specify these parameters if you want to use basic auth for the model server
- BASIC_AUTH_USER=
- BASIC_AUTH_PASS=
# Change this to your model name: MobileSAM or SAM
- SAM_CHOICE=MobileSAM
- LOG_LEVEL=DEBUG
# Enable this to use the GPU
# - NVIDIA_VISIBLE_DEVICES=all
# specify the number of workers and threads for the model server
- WORKERS=1
- THREADS=8
# specify the model directory (likely you don't need to change this)
- MODEL_DIR=/data/models
# Specify the Label Studio URL and API key to access
# uploaded, local storage and cloud storage files.
# Do not use 'localhost' as it does not work within Docker containers.
# Use prefix 'http://' or 'https://' for the URL always.
# Determine the actual IP using 'ifconfig' (Linux/Mac) or 'ipconfig' (Windows).
- LABEL_STUDIO_HOST=
- LABEL_STUDIO_ACCESS_TOKEN=
ports:
- 9090:9090
volumes:
- "./data/server:/data"
在docker-compose.yml的目录下执行命令,启动ML Backend:
docker-compose up
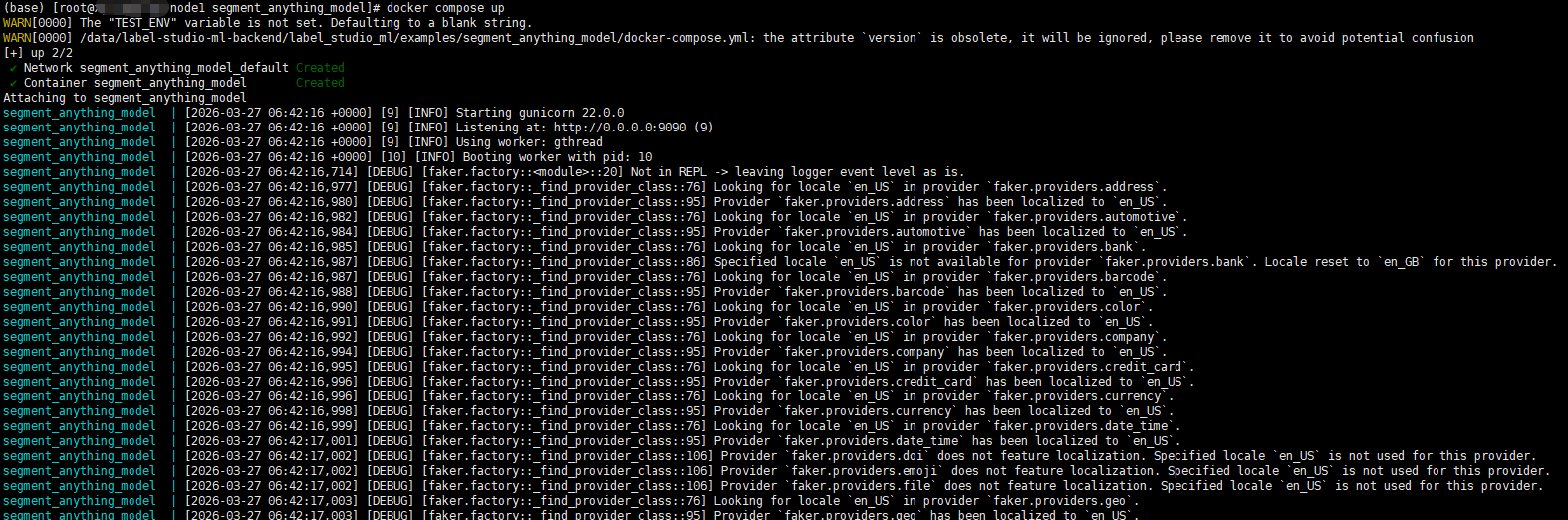
运行后,它会占用9090端口。
curl localhost:9090
{"model_class":"SamMLBackend","status":"UP"}
3.2 ML Backend整合
在前面完成了LabelStudio与ML Backend的部署,并都已启动成功。接下来就可以进行对接测试了。
在LabelStudio中打开某个项目,找到设置中的Model,在Connect Model中填入相关的ML Backend的信息。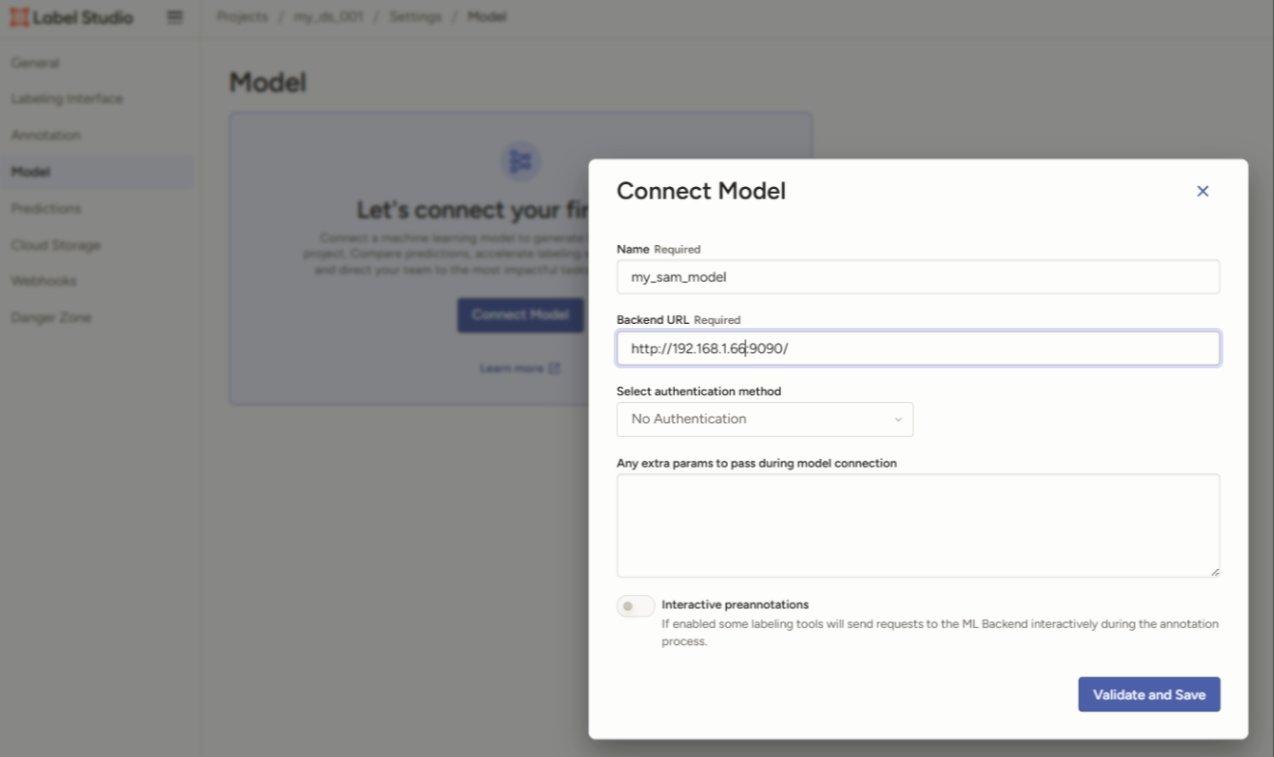
保存之后,再次进入到数据标注界面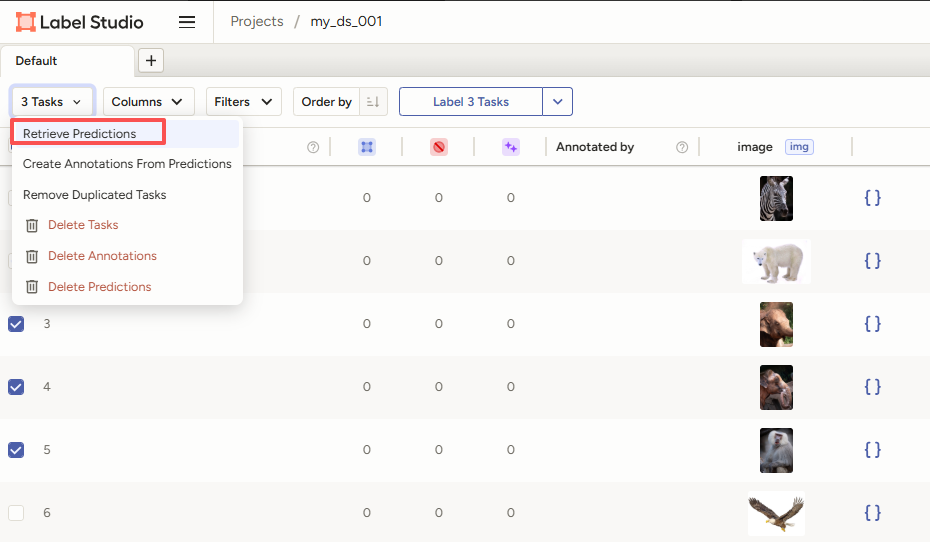
这时选择task之后,再点击Retrieve Predictions就可以对任务进行预标注了。
更多关于ML Backend可参考:https://labelstud.io/guide/ml_create ,笔者在这里不再详细展开。
另外,我们还可以使用LabelStudio的ML Backend完成数据集的训练集成,从而实现数据集的一条龙服务。笔者这里暂不详细展开,后面有机会再持续补充。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)