通过安全特异性神经元理解并增强LLM安全机制
1 摘要
问题:目前对LLM的安全机制的理解十分有限
贡献:
- 提出了一种特异性安全神经元的检测方法
- 揭示了安全神经元在LLM神经网络中的分布特点
- 提出了针对安全神经元的安全对齐方法SN-Tune,极大地提升了指令微调模型的安全性
- 提出了隔离安全神经元的微调方法RSN-Tune,在下游任务微调过程中,保持LLM安全机制的完整性
2 背景
2.1 原有的LLM安全对齐方法
- 改进训练算法,核心围绕人类反馈强化学习(RLHF) 及其改进展开
- 精修训练数据,构建高质量、多样化的安全训练数据,让模型更充分地学习安全行为
- 在原有LLM外新增独立的安全检测,阻断模块
这三类方法均缺少LLM安全机制的底层理解,将LLM作为黑盒训练,从整体模型参数层面做优化,未针对 LLM 中负责安全的核心组件精准调优,对齐训练成本高,效果差,且全参数微调容易破坏LLM原有功能
2.2 神经元的定义
LLM中神经元指的是参数矩阵中的一行或者一列
3 安全神经元检测方法
3.1 基本原理
在安全任务中某个神经元的重要性衡量方式:
神经元去除(将该神经元对应的行或者列参数置为0)后对神经元所在层输出的影响
去除前该网络层输出为a,去除后网络层输出为a’,则**(a-a’)^2**越大,神经元重要性越高
设定一个阈值,当神经元重要性超过阈值时,标记为重要神经元
每一次对LLM的有害查询都能得到一个重要神经元集合,所有查询的安全神经元集合交集即为安全神经元集合
因此随着查询数量增多,取交集得到的安全神经元越少,实验表明,200次查询足以可靠识别安全神经元
3.2 并行神经元检测方法
由于3.1检测过程需要逐个去除神经元,串行特性使得检测速度较慢,因此提出并行神经元检测方法以适用于巨量参数的LLM
3.2.1 前馈网络并行化
前馈网络计算过程如图:
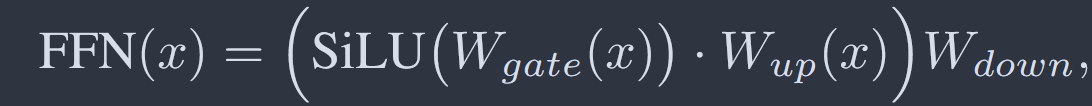
由于Wup,Wdown矩阵的线性特点,将第k列置为0时,最终结果第k列也置为0,因此可以通过将原结果乘以mask[k]列向量实现,mask[k]第k行为1,其余行为0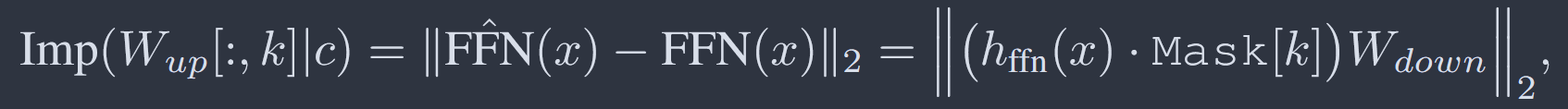
将mask[i],i=1,2…k,拼接为Mask矩阵即可一次性计算所有神经元重要性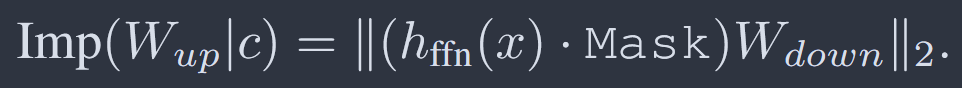
Wdown的计算方式与Wup类似
3.2.2 自注意力层并行化
自注意力层计算公式如图: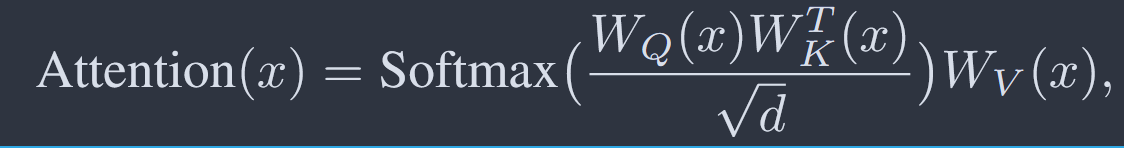
Wv矩阵具有线性性,因此计算方式与3.2.1方法相似
Wq和Wk矩阵由于经过Softmax激活函数,因此具有非线性性
Wq矩阵第k列置为0时,输出变化量为Wq第k列向量与Wk第k行向量的乘积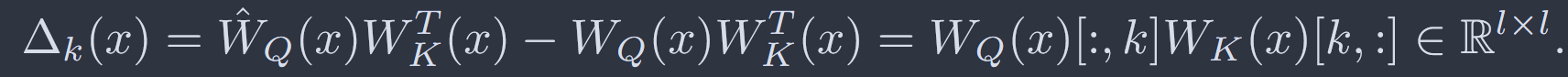
由此构造三维张量▲x,第k行为Wq第k列向量与Wk第k行向量的乘积得到的二维军阵,按照下面公式即可一次性计算所有Wq神经元重要性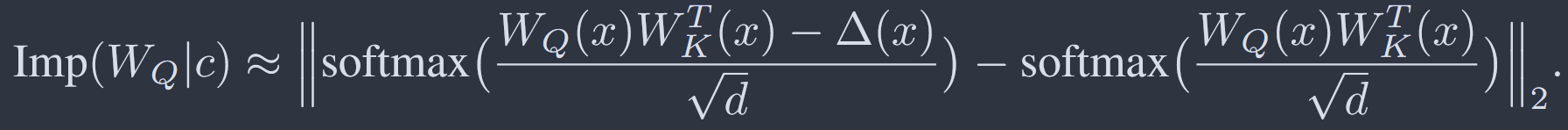
Wk计算方式与Wq类似
3.3 实验验证
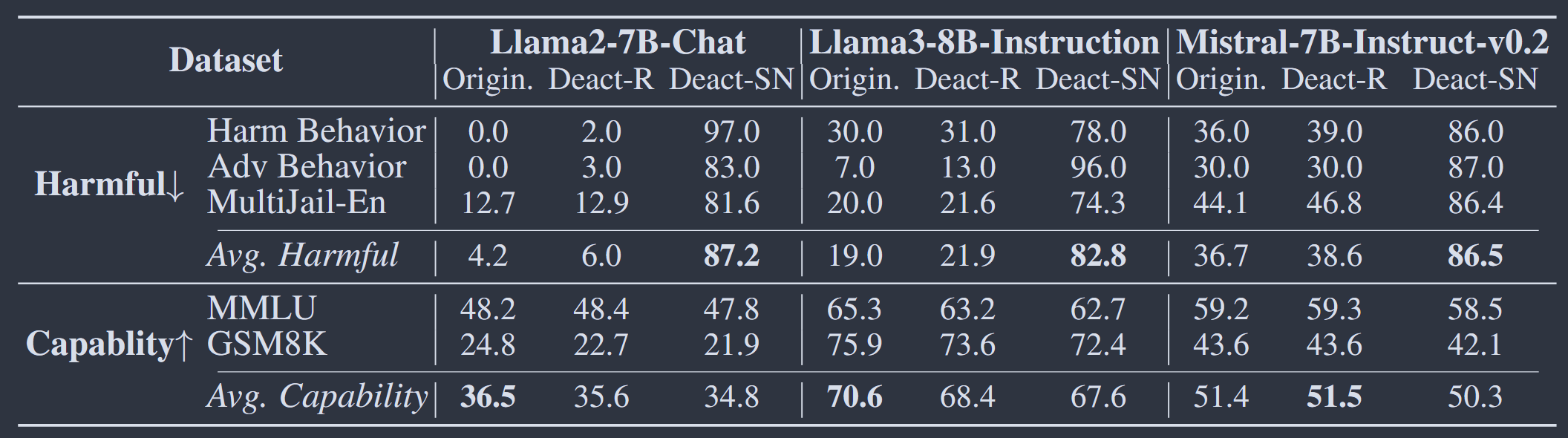
实验采用三种针对安全性进行调优的开源模型,Llama2-7B-Chat、Llama3-8B-Instruction、Mistral-7B-Instruct-v0.2。测试其原始状态(Origin)、随机失活其中0.5%神经元(Deact-R)、失活0.5%安全神经元(Deact-SN)时在各个数据集上的攻击成功率(Harmful)和通用能力(Capability)
结果表明,随机失活少量神经元对LLM安全机制有轻微破坏,而失活极少量的安全神经元攻击成功率大幅提升,安全机制严重破坏,说明LLM安全机制很大程度依赖于少量安全神经元
随机失活少量神经元和安全神经元后,LLM通用能力均略微下降,说明安全神经元也承担一定LLM通用能力
4 安全神经元分布特点
4.1 安全神经元占比不足1%
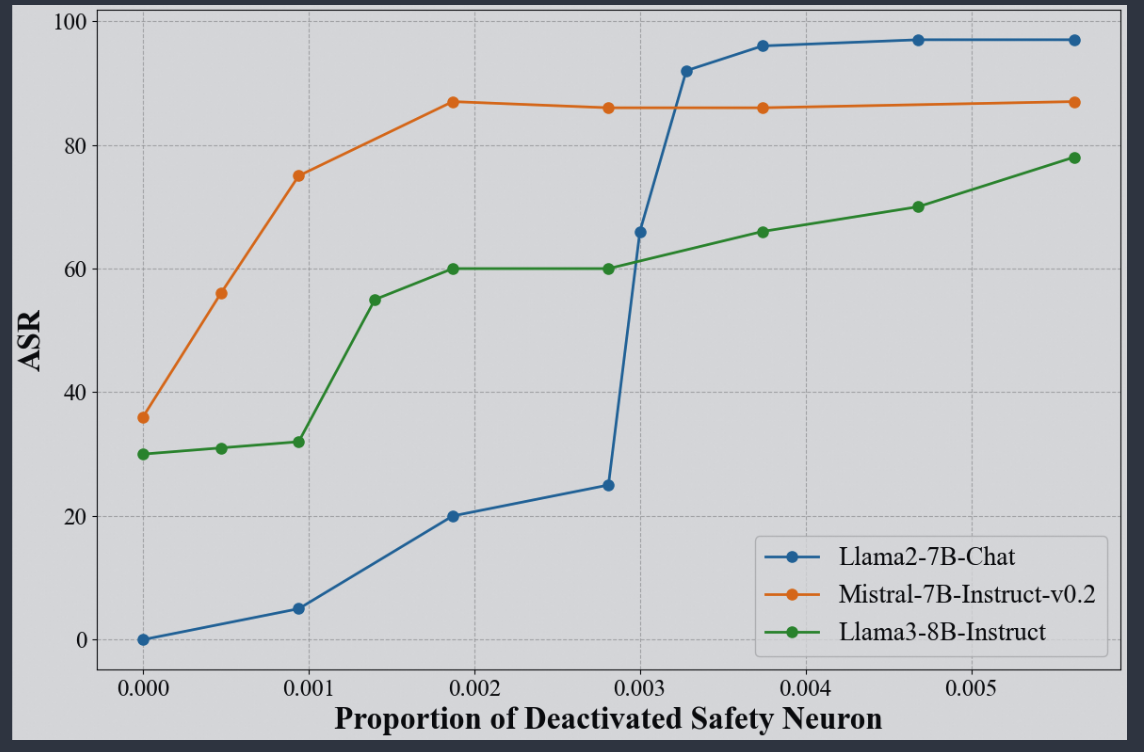
当失活0.4%安全神经元时,三种LLM的攻击成功率均达到峰值
4.2 安全神经元集中于前几层网络
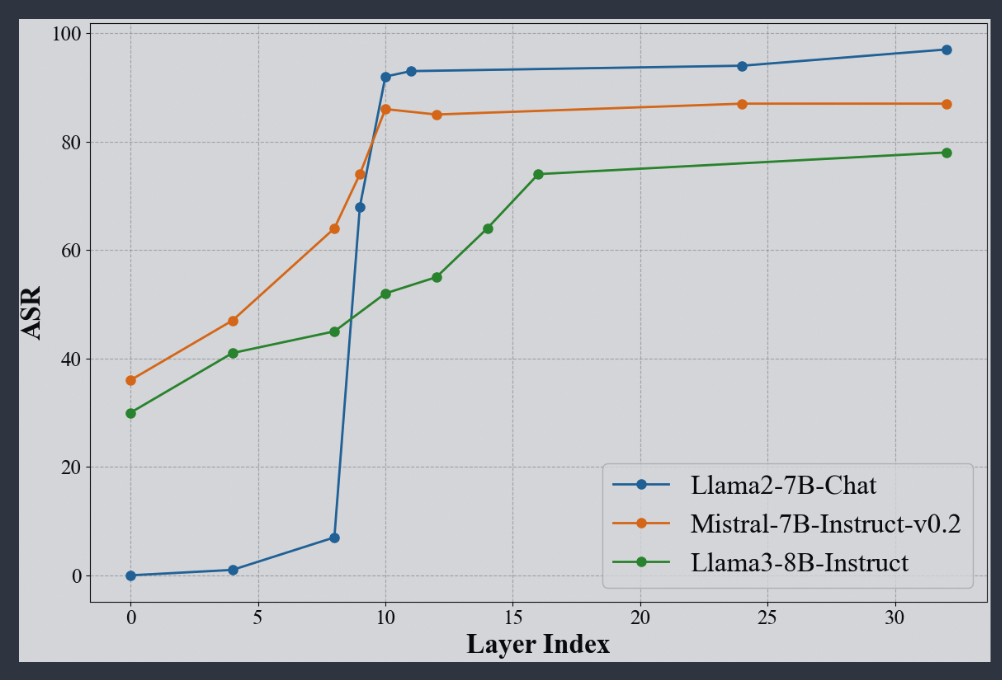
上图是从前向后逐层失活安全神经元时LLM的攻击成功率变化,可以看到失活前10层网络的安全神经元时,LLM攻击成功率达到峰值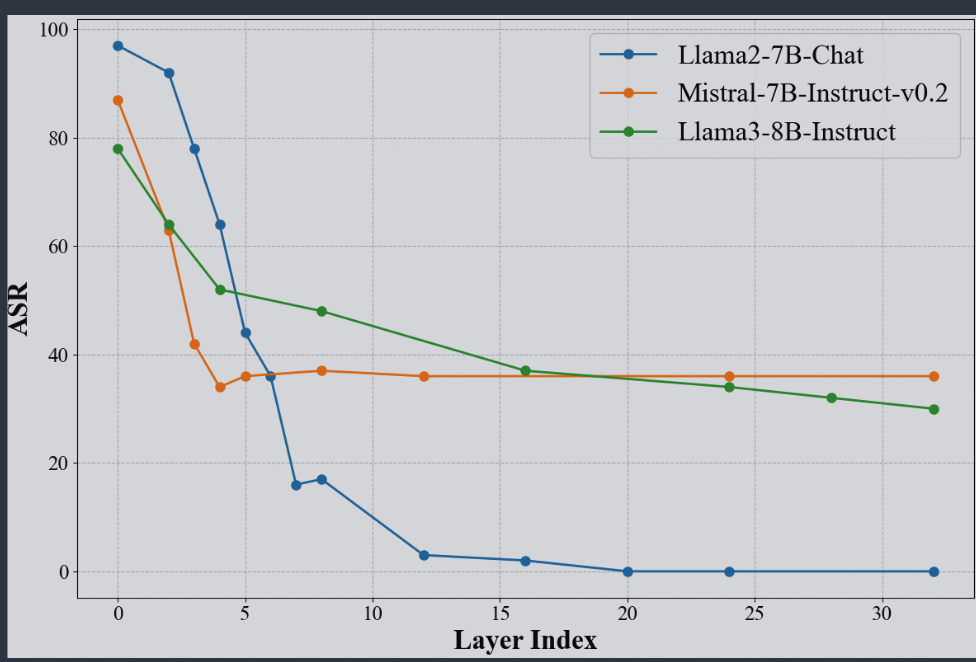
上图是从后向前逐层失活安全神经元时LLM的攻击成功率变化,可以看到失活10-30层神经元时LLM的安全机制基本未被破坏
4.3 安全神经元主要位于自注意力层
先前研究表明,前馈层主要负责信息提取,自注意力层主要负责信息理解,而安全机制侧重于理解潜在威胁,以识别其有害性质,而无需大量获取新知识,因此安全神经元主要位于自注意力层符合逻辑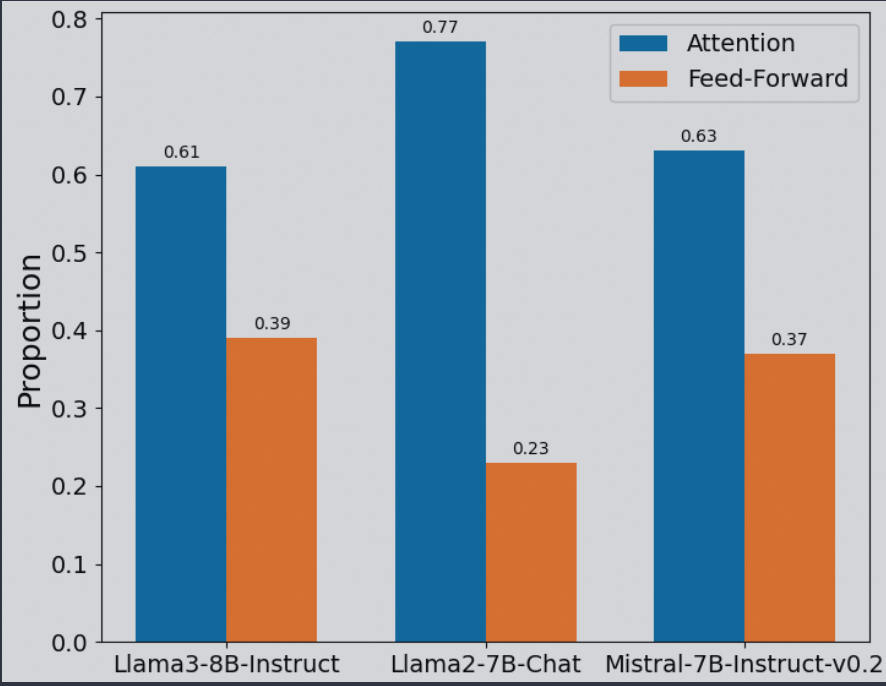
尽管注意力层参数不到前馈层参数的一半,安全神经元超过60%集中于注意力层
4.3 不同语言间安全神经元交集较少
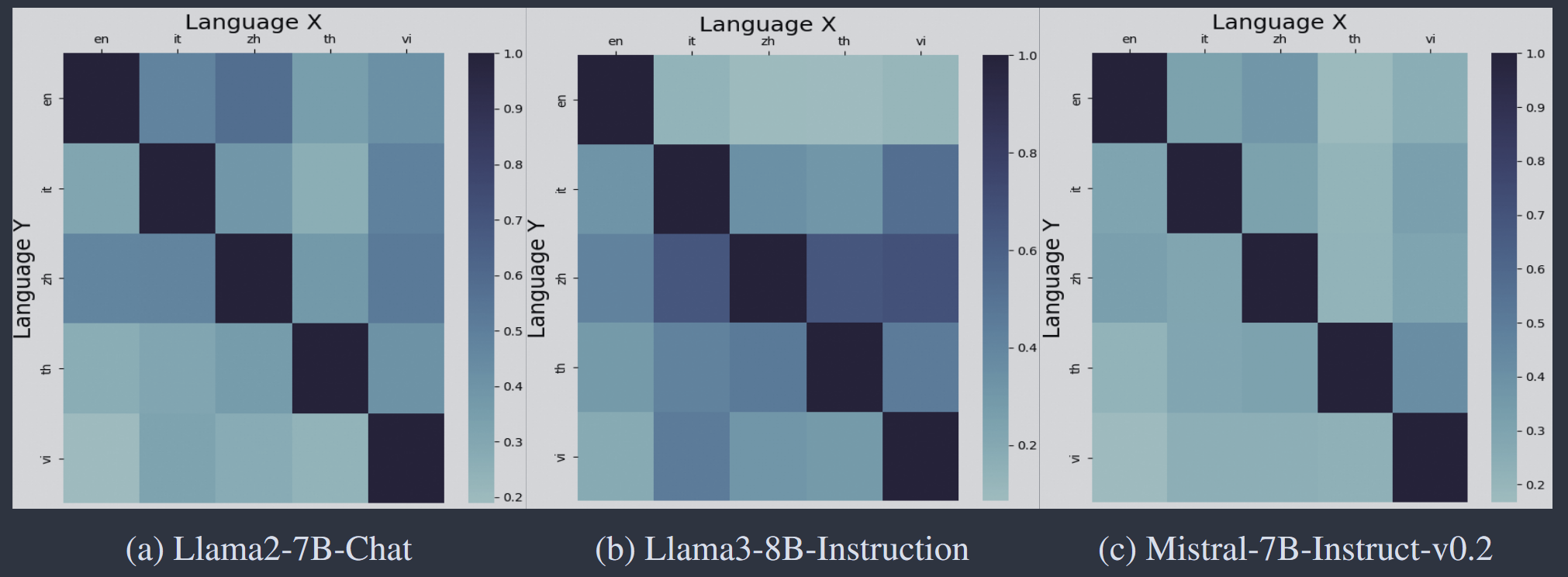
不同语言间安全神经元的交集通常低于30%
这意味着即使LLM专门针对英语安全对齐,应用到其他语言时仍可能存在风险。因此安全对齐的训练语料需要包含多种语言
5 SN-Tune
原理:安全对齐时,仅调整安全神经元参数,其余神经元梯度设置为0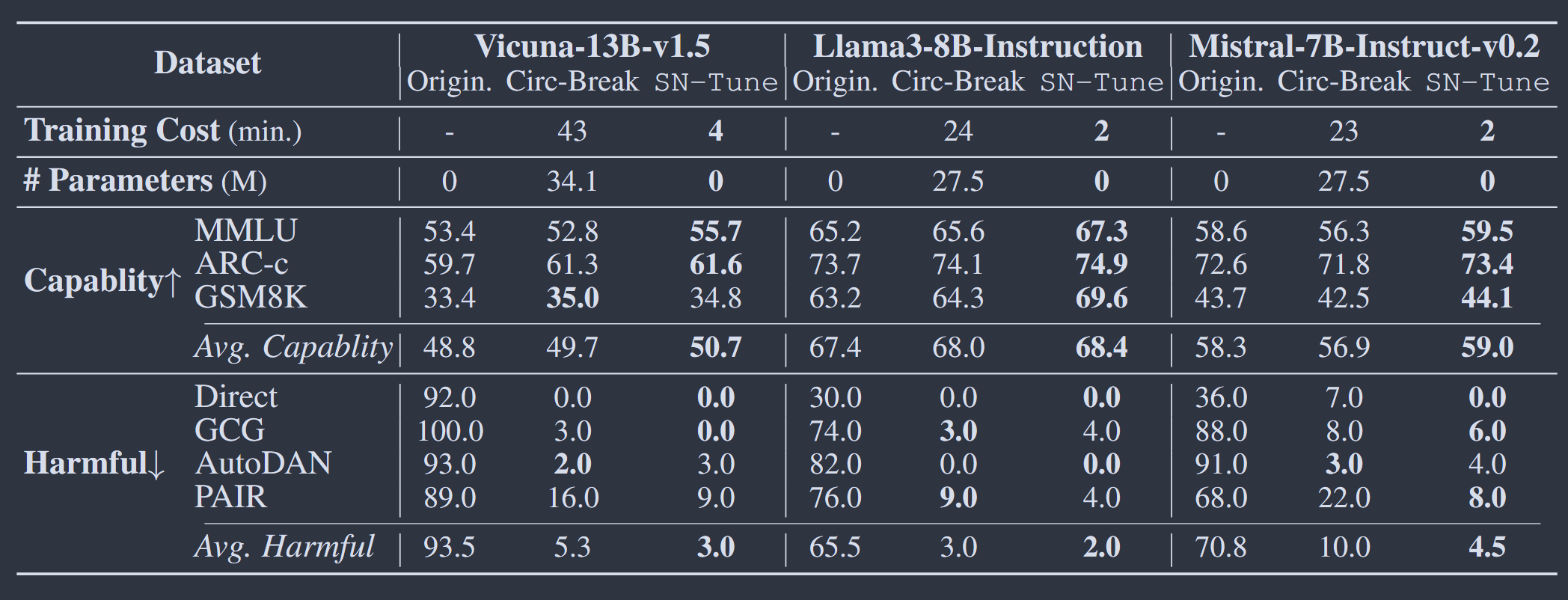
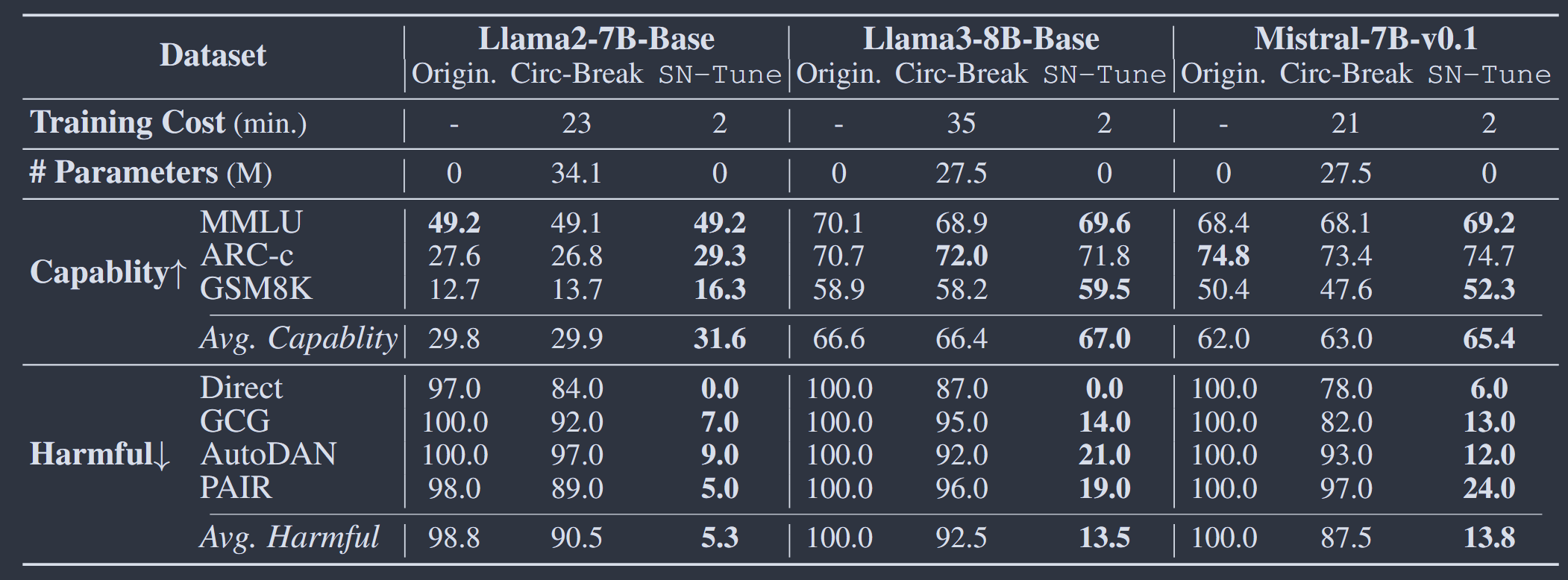
无论是指令微调模型,还是base模型。SN-Tune通过仅针对安全神经元训练均大幅提高了模型抗攻击能力,保持了LLM原本的通用能力甚至略微提升。此外,SN-Tune 所需的训练成本更低
6 RSN-Tune
原理:微调过程冻结安全神经元测试,降低特定任务微调对LLM安全机制的破坏
Before:微调前经过安全对齐的模型
Origin:微调后模型
SN-Tune:先SN-Tune后微调模型
阅读原文:Understanding and Enhancing Safety Mechanisms of LLMs via Safety-Specific Neuron

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)