边打电话边用电脑:基于双 Agent 并行架构的多模态协同系统实践
摘要: 针对“语音对话”与“UI 操作”并发场景中传统单 Agent 架构存在的实时性冲突与上下文污染问题,本文提出并实现了一种基于双 Agent 异步并行协同的架构。结合 VAD 语音端点检测、流式 LLM、Playwright 及 Browser-use,实现了一个能在低空飞行计划申报场景中“边对话边填表”的自动化系统。
一、背景与痛点:单智能体在多任务并发中的局限性
在构建复杂的现实世界 AI 助理时,我们常常需要 Agent 具备多模态并发处理能力。以“在线机票预订”或“政务表单填报”为例,Agent 需要一边通过电话向用户询问核心字段(如姓名、日期、设备信息),一边在网页端进行 DOM 解析与表单输入。
如果采用传统的单 Agent 架构串行处理,会面临以下致命挑战:
- 进程阻塞与低实时性:当大模型正在消耗计算资源处理页面截图、规划浏览器点击路径时,音频采集与语音处理链路被迫挂起,导致用户遇到极大的交互延迟,甚至出现对话假死。
- 上下文污染极易产生幻觉:将用户的口语化多轮对话记录,与极其庞大且带有噪音的网页 DOM 树或多模态日志混合在同一个 Prompt 上下文中,会导致大模型注意力严重分散,进而频发指令错误。
因此,本实验的核心破局思路为:通过职责解耦,构建双 Agent 异步通信架构。
二、双 Agent 异步并行架构设计
整个系统被拆分为两个独立运行的智能体,分别在独立的线程/进程事件循环中运行,通过基于内存的线程安全队列(queue.Queue)进行全双工消息传递。在这里插入图片描述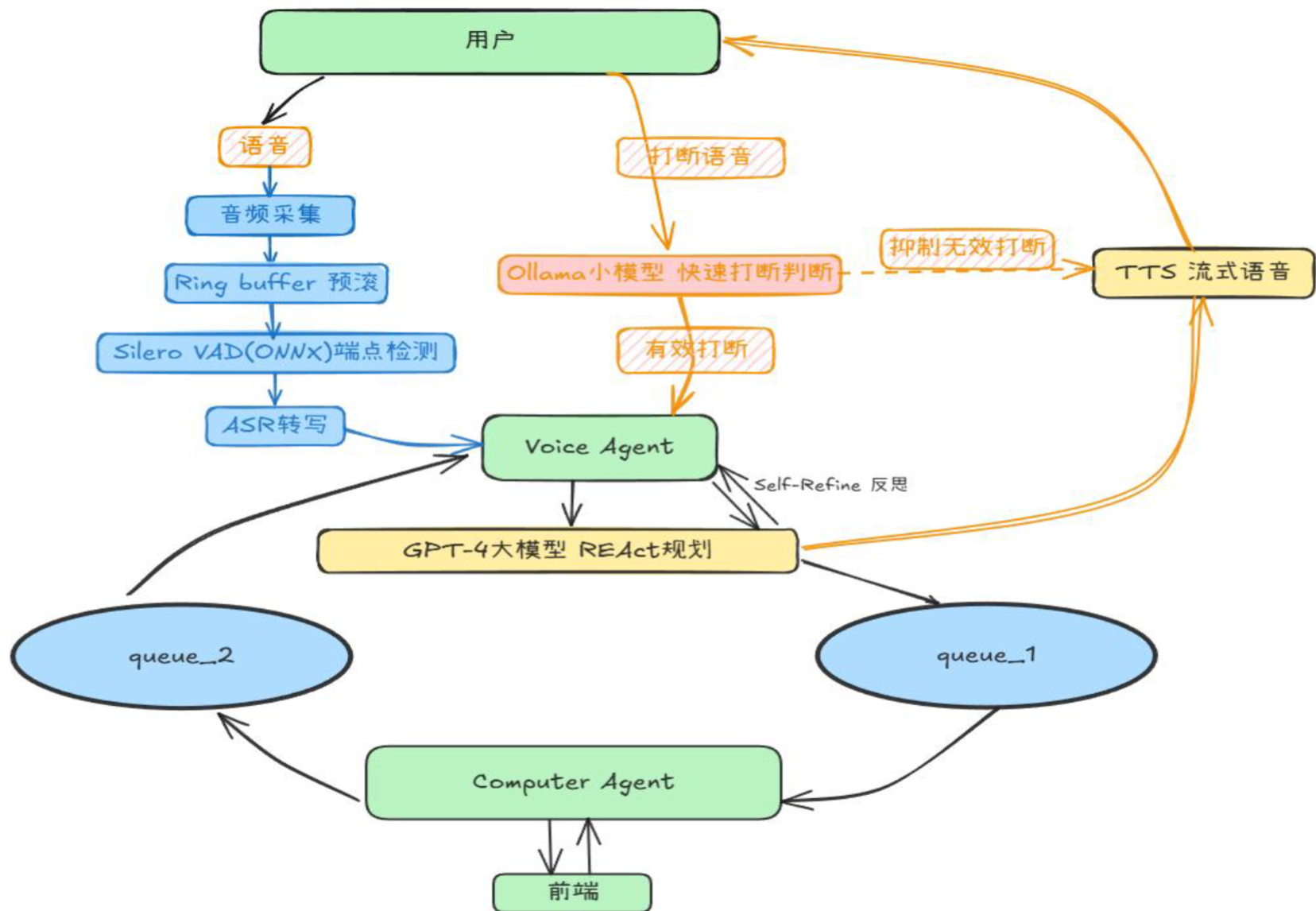
┌─────────────────────────────────────────────────────────┐
│ User Input │
│ Speech ───────────────► Hearing │
└──────────────┬──────────────────────┬───────────────────┘
│ Audio Stream │ Audio Playback
┌───────▼───────────────────────▼───────┐
│ Voice Agent │
│ VAD ─► STT ─► LLM (gpt-4o) ─► TTS │
│ Function Calling Router │
└───────┬───────────────────────▲───────┘
│ q1_queue (Task Link) │ q2_queue (Callback Link)
┌───────▼───────────────────────┴───────┐
│ Computer Agent │
│ Playwright + browser-use + Vision LLM │
│ JS Injection ─► Fallback GUI Action │
└───────────────────────────────────────┘
1. 角色定义
- Voice Agent (语音交互系统):全权负责低延迟的语音交互。包含基于 Silero VAD 的端点检测、Whisper STT 识别、基于 gpt-4o 的意图理解与提取,以及对接 TTS 的音频输出。
- Computer Agent (浏览器测控系统):全权负责网页状态机维护、DOM 解析与元素操作。它无需处理任何语音流,只消费来自 Voice Agent 的标准化数据字典。
2. 跨 Agent 通信协议
采用非阻塞的消息总线机制:
- 下行任务 (Task Link):Voice Agent 提取出表单字段后,调用内置工具将信息封装为 JSON 投递至
q1_queue。 - 上行回调 (Callback Link):Computer Agent 执行完毕(或遇到超时/找不到元素等失败情况),将执行状态或当前页面状态打上
[FROM_COMPUTER_AGENT]的标签投递至q2_queue,Voice Agent 的拦截线程会实时监听此队列,并以最高优先级将消息插回对话上下文。
三、Voice Agent 的核心工程实现
语音链路的核心指标是低延迟响应和合理的打断机制。
3.1 基于流式的 VAD 与打断校验
为了实现极速响应,项目采用了 ONNX 引擎驱动的 Silero VAD(16kHz,32ms 帧)对麦克风持续进行 VAD(Voice Activity Detection)。
当用户在 AI 语音播报期间插话时,为了避免“咳嗽声”、“嗯啊”等无意义声音触发全局打断,系统引入了边缘端打断校验机制:借助本地部署的轻量级模型(deepseek-v3-qwen2.5)作为“安检员”。
def _is_valid_interrupt(self, text: str) -> bool:
# 请求本地小模型判定是否为有效打断意图,设置 3 秒硬超时
response = self.small_llm_client.chat.completions.create(
model=config.SMALL_LLM_MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=10,
timeout=3
)
return "interrupt" in response.choices[0].message.content.strip().lower()
3.2 意图状态机与 Function Calling
Voice Agent 核心被塑约为一个“四步状态机”:
- 场景观察:向 Computer Agent 发起当前可填字段探测。
- 信息采集:根据拿到的缺失字段清单,自然地向用户发问。
- 指令下发:将口语化内容(如“明年八月二十六号的飞机”)规范化加工后,通过 Tool Call 发给电脑系统。
- 提交确认:表单完备后发起最终提交。
为防止 LLM 连续工具调用产生“工具风暴(Tool Storm)”,我们在处理完工具结果后会强制禁止当次会话的级联调用 self._trigger_large_llm(allow_tool_calls=False)。
3.3 句频级的流式 TTS 缓冲策略
直接将短碎片的 Token 推送到 TTS 会带来严重的断顿感。我们在生成器中间抽象了一层缓冲队列,利用句末标点(., ?, ! 等)切分完整语义块,以此保证播报语气的连贯性。
四、Computer Agent 的核心工程实现
UI 控制模块需要在准确率与执行速度上做权衡。项目中实现了渐进式操作降级策略。
4.1 Fast-Path:基于 DOM 查询的 JavaScript 盲注
因为表单多为结构化标准控件,使用视觉大模型识别坐标再点击往往过于耗时和繁琐。优先采用 JS 注入查找 <label> 并直填 <input>:
// 基于可见 Label 文本动态路由目标 input 并触发双向绑定事件
const labels = Array.from(document.querySelectorAll('label'));
for (const lab of labels) {
const txt = (lab.textContent || '').replace(/\s/g, '');
if (txt.includes(targetLabelText)) {
// ... 寻找关联 input 逻辑 ...
input.value = value;
input.dispatchEvent(new Event('input', {bubbles: true}));
input.dispatchEvent(new Event('change', {bubbles: true})); // 核心:触发 React/Vue 响应式拦截
break;
}
}
4.2 Slow-Path:基于 Browser-use 的多模态 Fallback
如果 JS 直接操作失败(例如遇到动态下拉组件联级的复杂渲染),则任务自动回退(Fallback)至调用 Browser-use 核心组件,利用大模型做多模态理解与 Action 规划。为了减少主 Agent 的 Context 压力,针对此过程中的冗长 Agent History,独立开辟了一条摘要清洗链路进行数据瘦身再上报。
五、并发控制与时序同步
系统后台集成了错综复杂的并发流,核心的协调机制包括:
threading.Event:用于interrupt_event跨线程实现零 CPU 轮询开销的打断通知。threading.RLock:在修改由于异步回调产生的 Conversation History 时加锁,防止多线程竞争导致上下文数据脏读写。- 动态协程隔离:Computer Agent 本身的 Playwright 组件依赖
asyncio,为避免阻塞主线程,其单独运行在run_coroutine_threadsafe所挂载的后台异步事件循环中。
六、全链路执行拓扑图
将各模块拼装后,一个完整的多模态响应周期流向如下:
User Speech
│
▼
[Silero VAD] (16kHz, Edge detection)
│ Audio PCM
▼
[STT Service] (Whisper-1)
│ Transcribed Text
▼
[Intent Analysis] (Local SLM + Valid Interrupt Check)
│
▼
[Global LLM Route] (gpt-4o) ─────────┐
│ │
├──► 1. Text Generation └──► 2. Tool Calling (Function Call)
│ │ │
│ ▼ ▼
│ [TTS Queue (Streaming)] [q1_queue Task Send]
│ │ │
▼ ▼ ▼
[Audio Playback / User] [Computer Agent Async Loop]
│
├──► Fast-Path: JS Execute
└──► Slow-Path: Browser-use Agent
│
▼
[q2_queue Status Callback]
│
▼
[Voice Agent Background Watcher] ◄───────────┘
(Force triggers LLM to handle DOM block/exceptions)
七、环境配置与运行指南
对于想要在本地复现这套“双 Agent 并行架构”的开发者,以下是完整的环境依赖与启动链路:
1. 基础环境与依赖注入
本项目基于 Python >= 3.13 开发,建议使用虚环境进行隔离。核心依赖库涵盖了多模态浏览器测控与本地音频流处理。
# 安装基础依赖
pip install -r requirements.txt
# 初始化 Playwright 浏览器内核
playwright install
2. 核心私有化模型准备
- 端侧 VAD 模型:音频处理极其依赖轻量级的端侧实时推理,需提前下载 Silero VAD 的
silero_vad.onnx模型,并严格放置于项目根目录的models/文件夹下。 - 环境变量 (
.env):系统强依赖多模态大语言模型、 STT/TTS 以及小模型(用于打断校验),请自行在根目录下配置:
OPENAI_API_KEY=sk-xxxxxx
OPENAI_BASE_URL=https://api.openai.com/v1
# 本地部署的小模型 endpoint (如 Ollama 提供的 deepseek-v3-qwen2.5)
SMALL_LLM_URL=http://localhost:11434/v1
3. 系统启动事件序列
双 Agent 的通信与启停依托于统一的主进程协调,标准启动顺序如下:
-
唤醒后台控制中枢:
在终端执行守护程序入口文件(如main.py或local_server.py),这会同步挂载 Python 的多线程池与asyncio事件循环,并初始化q1_queue和q2_queue两条通信总线。python main.py -
挂载前端交互台:
本项目的前端与测试表单已解耦至Frontend目录下。直接在浏览器中打开Frontend/index.html(或test_simple_date.html),并务必允许网页获取麦克风权限。 -
发起协同指令:
触发录音并直接用自然语言对着麦克风发布任务(例如:“帮我填一下这个无人机飞行计划表,我的名字是…”),此时你将观察到后台日志中两个 Agent 相互配合与接力的完整拓扑流。
八、总结与性能对比
传统的“串行”工作流通常等于 提问时间 + 思考时间 + 推理/截图耗时 + GUI 执行时间。
通过本方案的异步解耦,我们在日志审计中可以明显观察到时间线的极度折叠现象。当 Computer Agent 正在进行几十秒的长超时阻塞推理和点选时,Voice Agent 一侧仍保持了极高的活跃度(甚至主动加入“您稍等,系统正在尝试跳过该广告…”之类的安抚语句),在真实测试集对比下单次流程平均耗时缩短了近 35-40%,有效消除了“系统假死感”。
未来演进:
接下来我们将考虑在此架构中集成更强健的任务编排(Orchestrator Agent),从“双节点异步”演进到真正的“多节点总线路由框架”,以拓展到客户端接管等泛在桌面自动化(RPA)场景。
(附:核心依赖及版本建议:Python >= 3.13, browser-use >= 0.7.0, playwright >= 1.54.0, Silero VAD ONNX runtime)# 边打电话边用电脑:基于双 Agent 并行架构的多模态协同系统实践
有问题欢迎联系作者

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)