【网安毕设项目】基于机器学习的网络入侵检测系统设计与实现
全套资料包含:源码+开发文档+部署教程视频+万字LW,有需要可以私信博主,伸手党勿扰
一、课题研究背景与意义
随着互联网技术的发展,网络已经成为社会运行的重要基础设施。大量的信息通过网络进行传输与交换。然而网络规模不断扩大,网络攻击事件也在持续增加,例如拒绝服务攻击(DoS)、端口扫描、暴力破解攻击以及Web攻击等。这些攻击会导致系统瘫痪、数据泄露以及服务中断,对企业和个人造成严重损失。
传统的网络安全防护主要依赖防火墙、访问控制和特征库检测等技术。这些方法在面对已知攻击时具有一定效果,但对于未知攻击或复杂攻击模式往往难以有效识别。此外,传统特征库需要人工不断更新,维护成本较高。
近年来,机器学习技术在网络安全领域得到了广泛应用。机器学习可以通过对大量网络流量数据进行训练,自动学习攻击行为的特征模式,从而实现对异常流量和攻击行为的自动检测。与传统方法相比,基于机器学习的入侵检测系统具有更好的自适应能力和检测效率。
因此,设计并实现一个基于机器学习算法的网络入侵检测系统具有重要意义。本课题将利用机器学习算法对网络流量数据进行分析,实现对多种网络攻击行为的识别,并通过图形化界面展示检测结果,从而提高系统的可用性和实用性。
二、国内外研究现状
网络入侵检测系统(Intrusion Detection System,IDS)是网络安全领域的重要研究方向。根据检测方式不同,IDS主要可以分为基于特征的检测方法和基于异常的检测方法。
早期的入侵检测系统主要采用基于特征匹配的方法,例如 Snort 和 Suricata 等系统。这类系统通过预定义攻击特征库来识别攻击行为,检测速度较快,但对未知攻击的识别能力较弱。
随着数据分析技术的发展,越来越多研究开始引入机器学习方法进行入侵检测。例如,研究人员利用 Random Forest、Support Vector Machine、K-Nearest Neighbors 等算法对网络流量数据进行分类。这些方法可以通过训练数据自动学习攻击特征,从而提高检测准确率。
近年来,深度学习技术也被应用于网络入侵检测。例如使用 Convolutional Neural Network 和 Long Short-Term Memory 模型对网络流量进行分析。这些方法能够提取更复杂的特征,但通常需要较高的计算资源。
在数据集方面,常用的网络入侵检测数据集包括 KDD Cup 1999 Dataset、NSL-KDD Dataset 以及 CICIDS2017 Dataset。其中 CICIDS2017 数据集包含多种真实网络攻击类型,被广泛用于入侵检测研究。
综合来看,基于机器学习的入侵检测方法在检测准确率和泛化能力方面具有明显优势,因此成为当前研究的热点方向。
三、研究目标与研究内容
本课题的主要目标是设计并实现一个基于机器学习算法的网络入侵检测系统。系统能够对网络流量数据进行分析,并识别多种常见的网络攻击行为。
本研究主要包括以下几个方面的内容:
- 数据预处理模块设计
- 对网络流量数据进行清洗和处理,包括数据合并、缺失值处理、特征选择以及数据标准化等步骤,为机器学习模型训练提供高质量数据。
- 入侵检测模型构建
- 采用机器学习算法建立入侵检测模型。通过对训练数据进行学习,使模型能够区分正常网络流量与异常攻击流量。
- 模型训练与评估
- 使用训练集对模型进行训练,并通过测试集对模型性能进行评估。主要评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及 F1-score 等。
- 系统功能实现
- 基于 Python 编程语言设计图形化界面,实现数据预处理、模型训练、模型评估以及结果展示等功能。
- 系统测试与优化
- 对系统进行测试,分析模型检测效果,并通过参数优化等方法提升系统性能。
四、研究方法与技术路线
本课题采用机器学习方法进行网络入侵检测。整体技术路线如下:
首先,收集并整理网络流量数据。本研究选用 CICIDS2017 数据集作为实验数据来源。该数据集包含正常流量和多种攻击类型,例如 DoS 攻击、端口扫描、暴力破解攻击等。
其次,对原始数据进行预处理。数据预处理过程包括数据清洗、特征选择、缺失值处理以及标签编码等步骤。预处理后的数据将被划分为训练集和测试集。
然后,利用机器学习算法建立分类模型。本系统采用随机森林算法作为主要分类模型。随机森林算法通过构建多个决策树并进行集成学习,可以有效提高分类准确率并降低过拟合风险。
在模型训练完成后,通过测试集对模型性能进行评估。系统将输出分类报告,包括各类攻击的精确率、召回率以及 F1-score 等指标。
最后,基于 Python 图形界面框架 PyQt5 开发用户界面,实现数据处理、模型训练和检测结果展示等功能。
整体技术流程如下:
数据集准备
→ 数据预处理
→ 特征选择
→ 模型训练
→ 模型评估
→ 系统界面展示
五、研究内容的可行性分析
本课题具有较好的可行性,主要体现在以下几个方面。
首先,在数据资源方面,CICIDS2017 数据集公开可用,包含多种攻击类型,能够满足实验需求。
其次,在技术实现方面,Python 语言拥有丰富的数据分析和机器学习库,例如 Pandas、NumPy 和 Scikit-learn 等,这些工具可以有效支持机器学习模型的开发与实现。
此外,图形界面开发可以使用 PyQt5 框架。该框架功能完善,文档丰富,能够实现良好的用户交互界面。
最后,本课题的研究方法和实现过程较为成熟,已有大量相关研究作为参考,因此整体研究具有较高可行性。
六、研究计划与进度安排
本课题计划按照以下阶段进行:
第一阶段(第1—2周)
查阅相关文献,了解网络入侵检测和机器学习算法的研究现状,明确研究方向。
第二阶段(第3—5周)
收集并整理数据集,对数据进行预处理,包括数据清洗、特征选择以及数据划分。
第三阶段(第6—8周)
构建机器学习模型,完成模型训练与性能评估。
第四阶段(第9—10周)
设计并实现系统图形界面,整合数据处理和模型训练功能。
第五阶段(第11—12周)
进行系统测试和优化,并完成论文撰写。
七、预期成果
本课题预计完成以下成果:
- 设计并实现一个基于机器学习的网络入侵检测系统。
- 实现网络流量数据的自动预处理和特征提取。
- 构建入侵检测模型,并对多种网络攻击进行识别。
- 开发图形化用户界面,实现系统操作与检测结果展示。
- 完成毕业论文,分析系统设计过程与实验结果。
核心实现部分:
1、项目简介:
本系统基于机器学习算法,实现对网络流量数据的入侵检测。系统以 CICIDS2017 Dataset 为数据基础,通过数据预处理、模型训练、模型评估以及离线检测,实现对多种网络攻击行为的自动识别。
系统采用 Python 语言开发,结合:
- PyQt5(界面)
- Scikit-learn(机器学习随机森林算法)
- Pandas(数据处理)
构建完整可运行的桌面应用程序。
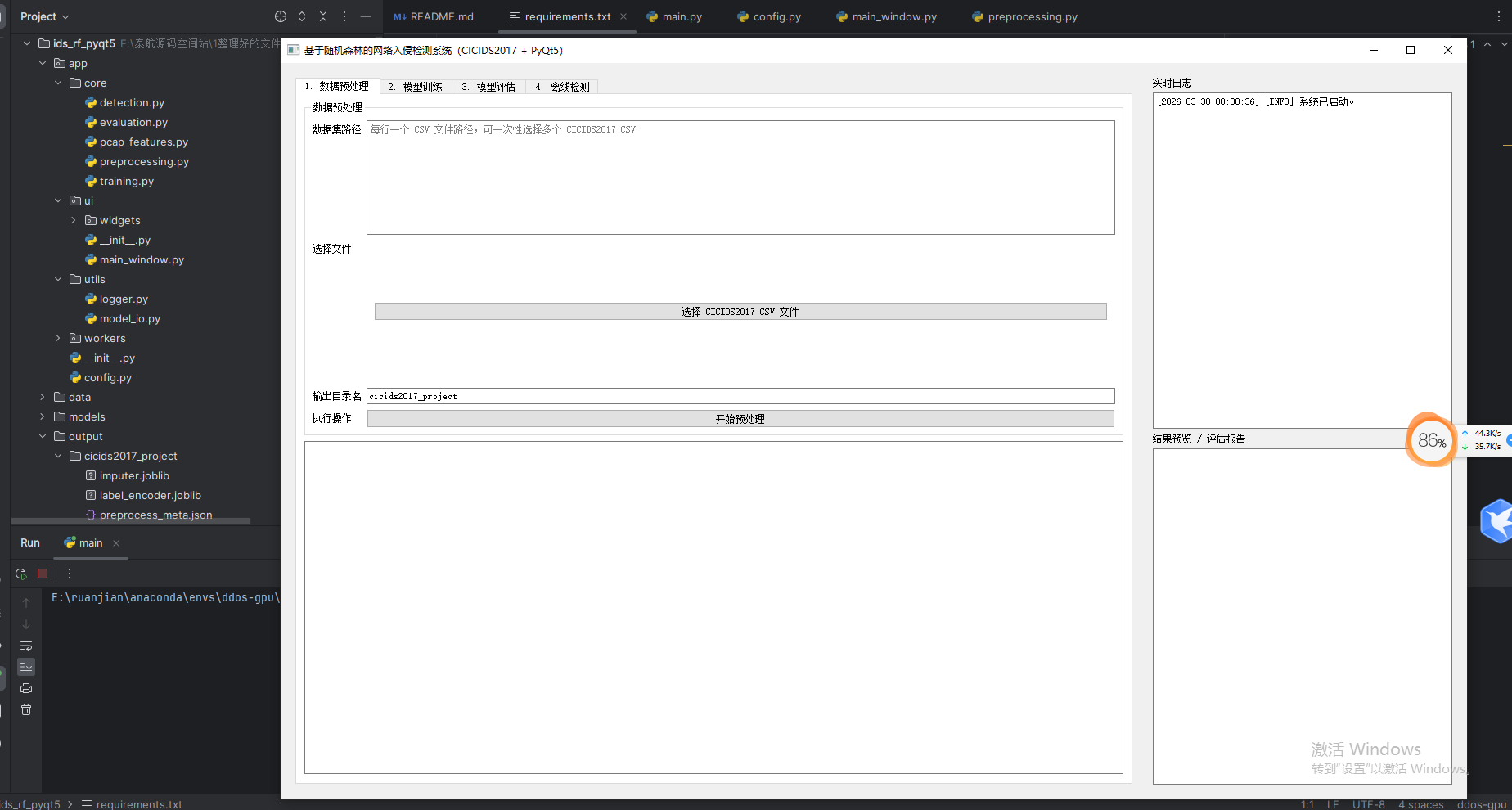
2、系统功能主要包含以下四大功能模块:
- 数据预处理
- 模型训练
- 模型评估
- 离线检测
界面如下:
3、软件开发环境

赖安装:pip install pyqt5 pandas numpy scikit-learn joblib
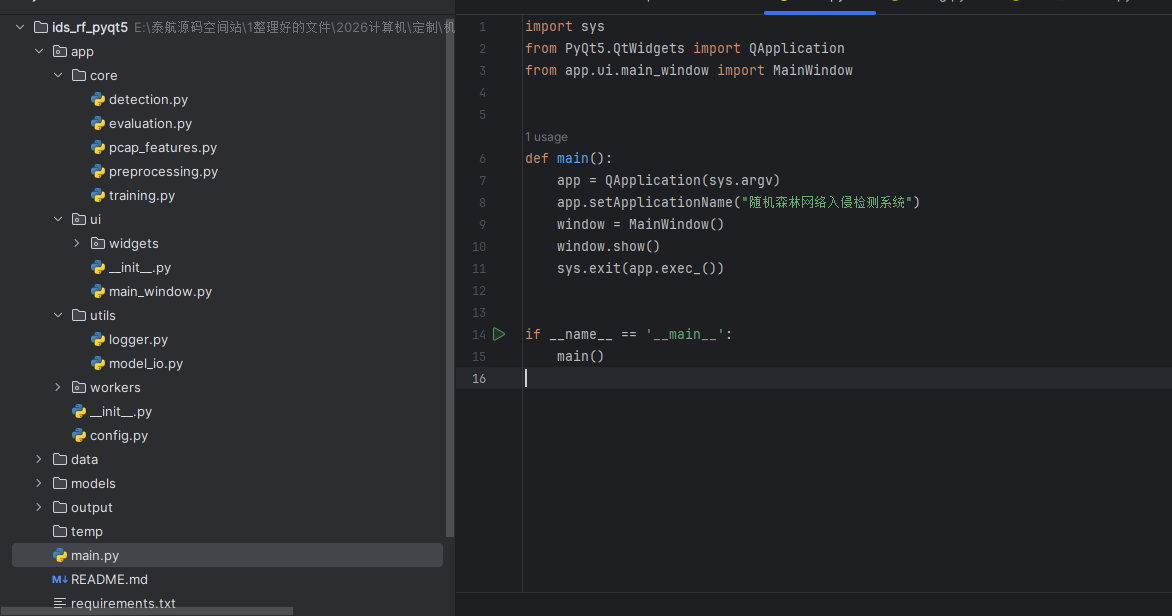
4、系统总体架构:
UI界面层 (PyQt5)
↓
业务逻辑层 (Worker线程)
↓
数据处理层 (Preprocessing / Model)
↓
文件存储层 (CSV / JSON / joblib)
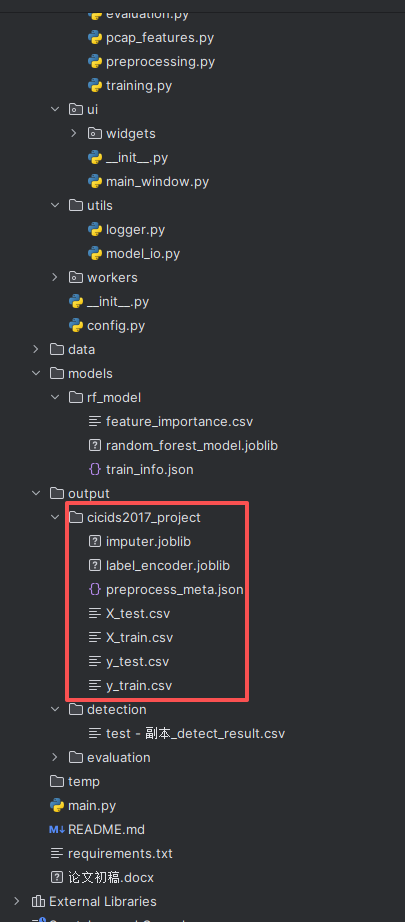
项目目录结构:
5、核心代码目录介绍
5.1 数据预处理模块 (文件:preprocessing.py)
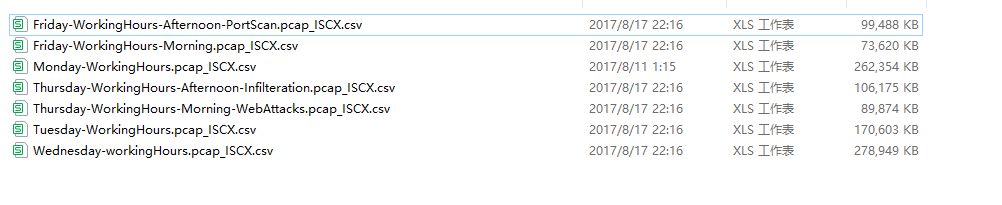
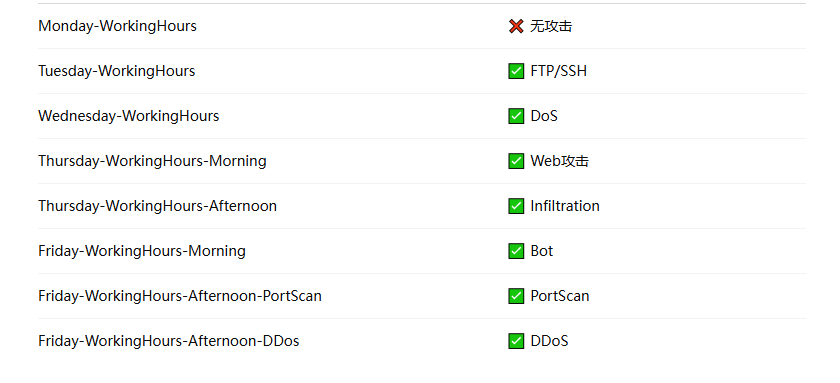
数据预处理流程: 选择CSV → 读取数据 → 清洗 → 特征提取 → 保存
采用的数据集是cicids2017
功能:
- 多CSV读取
- 数据清洗
- 特征选择
- 数据划分
- 数据保存
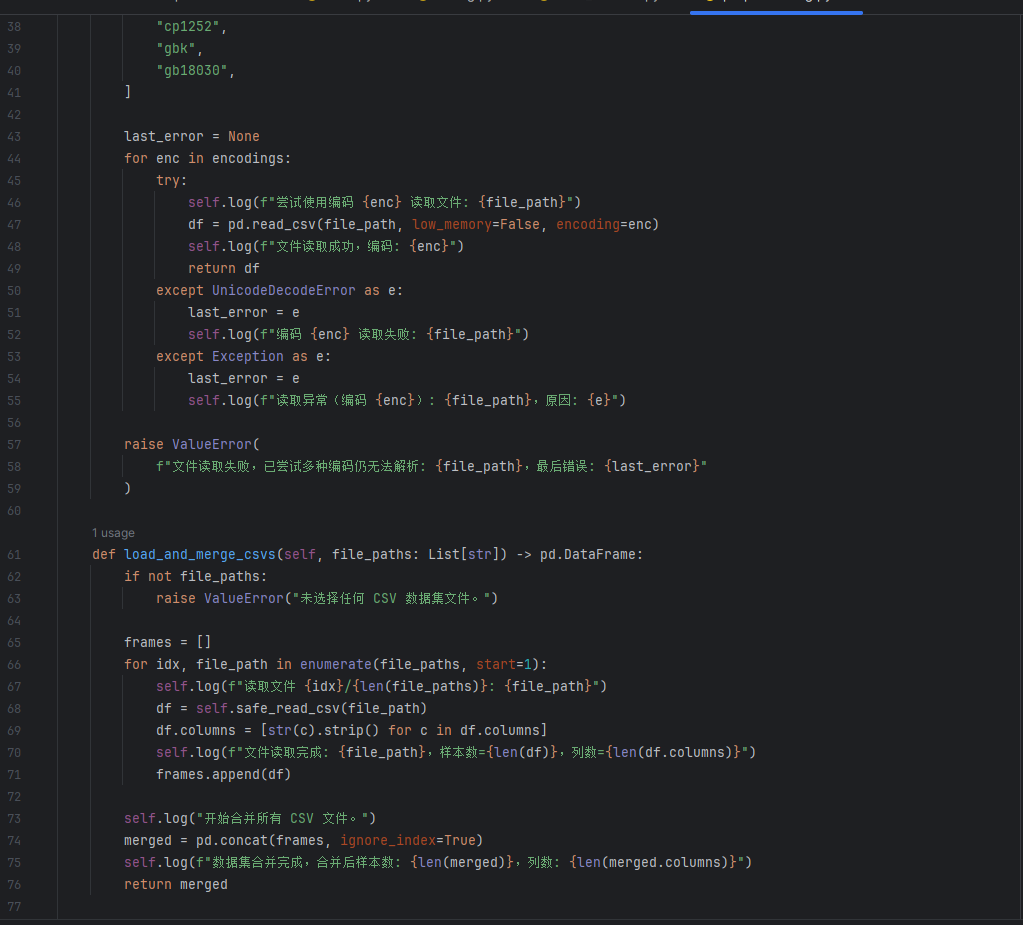
5.2模型训练模块(training.py):
加载meta → 读取数据 → 训练模型 → 保存模型
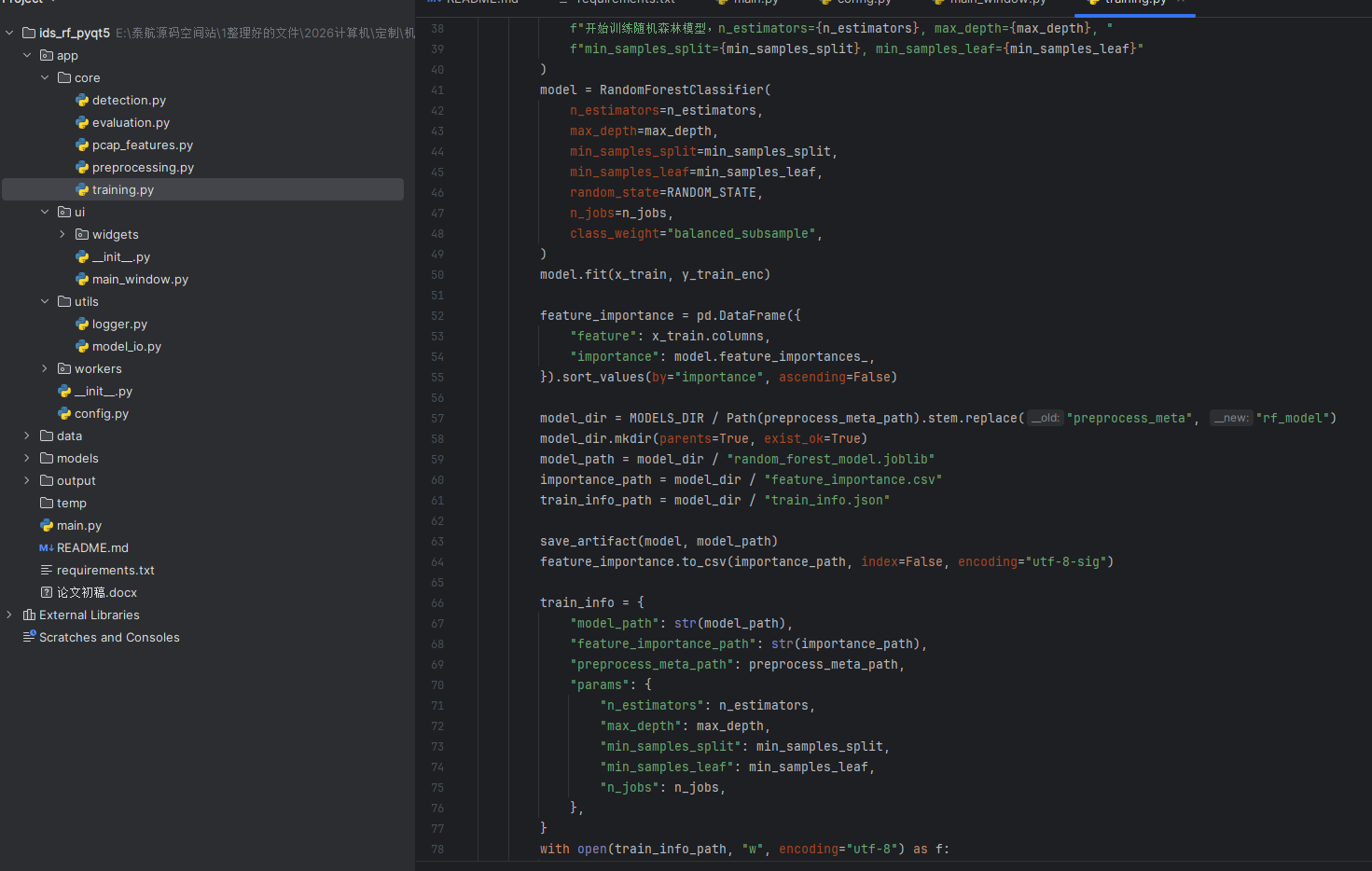
训练完输出:

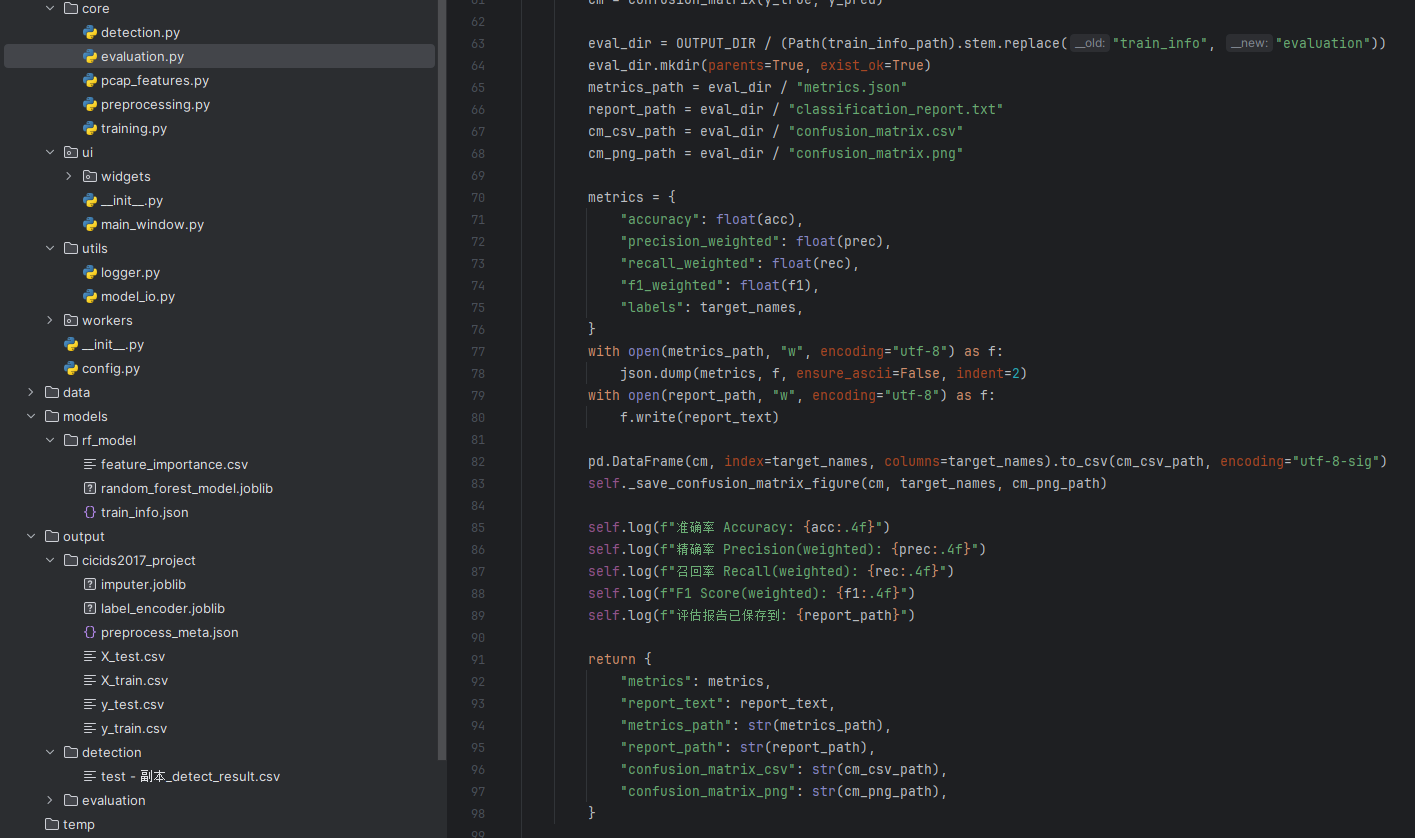
5.3模型评估模块(evaluation.py)
加载模型 → 测试集预测 → 输出报告
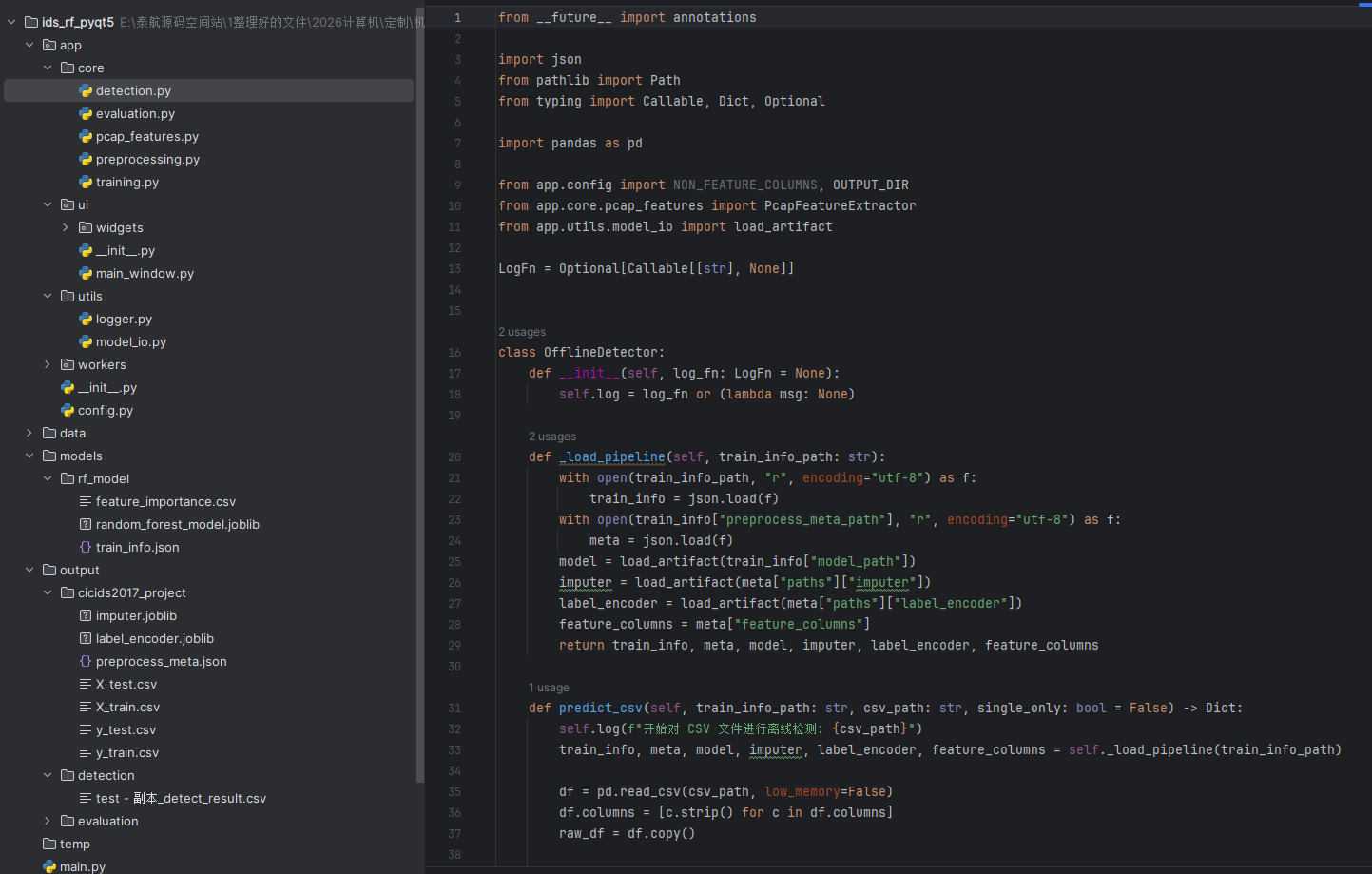
5.4算法检测模块(detection.py)
流程:加载模型 → 输入数据 → 输出预测
功能:
- 加载模型
- 读取输入数据
- 输出预测结果
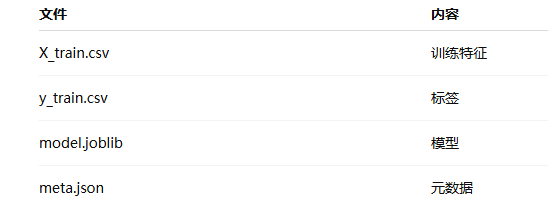
5.5系统输出文件说明:
项目实现原理:
一、项目整体实现原理
这个项目本质上是一个基于监督学习的多分类网络入侵检测系统(随机森林)。
它的核心思想是:
先用带标签的网络流量数据训练一个分类模型,让模型学会“正常流量”和“不同攻击流量”的统计特征;之后再把新的网络流量输入模型,由模型自动判断它属于哪一种类型。
整个系统可以理解为由四个主要部分组成:
- 数据预处理
- 模型训练
- 模型评估
- 检测与结果展示
如果从程序运行流程来看,就是:
原始CSV数据 → 数据清洗与特征处理 → 划分训练集/测试集 → 训练随机森林模型 → 评估模型性能 → 加载模型进行入侵检测 → 在PyQt界面中显示结果
二、系统的核心思想
2.1 为什么能用机器学习做入侵检测
网络流量虽然看起来复杂,但每一条流量记录都可以抽象成一组特征,比如:
- 流持续时间
- 前向包数量
- 后向包数量
- 包长度均值
- 每秒字节数
- 每秒包数
- 标志位数量
这些特征本质上描述了网络连接行为。不同攻击类型通常会表现出不同的统计规律。
例如:
- PortScan:短时间内大量连接多个端口
- DoS Hulk:流量密集,请求数量巨大
- FTP-Patator / SSH-Patator:暴力尝试登录,连接模式重复
- Web Attack:请求结构异常,但整体规模较小
机器学习模型并不“理解攻击”,它只是通过训练数据学习这些特征与标签之间的对应关系。
所以这个系统的原理不是手工写规则,而是:
让模型从历史数据中自动学习“什么样的特征组合更像哪一种攻击”。
2.2 为什么选监督学习
项目使用的是 CICIDS2017 数据集,这个数据集本身带有标签,例如:
- BENIGN
- Bot
- DoS Hulk
- PortScan
- FTP-Patator
- SSH-Patator
- Web Attack - XSS
因为训练数据已经告诉模型“这条数据是什么类型”,所以最合适的方法就是监督学习。
监督学习的特点是:
- 输入:一组特征
- 输出:一个明确类别
- 目标:学会从特征到类别的映射关系
系统本质上就是在做一个多分类问题。
三、数据层实现原理
这一部分是整个系统最基础的部分。因为机器学习模型的效果很大程度上取决于数据质量。
3.1 数据来源原理
系统使用的是 CICIDS2017 数据集的 CSV 文件。
每个 CSV 文件本质上是一张表:
- 每一行是一条网络流量记录
- 每一列是一个流量特征
- 最后一列通常是
Label
也就是说,原始输入并不是抓包文件本身,而是从流量中提取出来的统计特征表。
程序并不是直接分析原始网络协议内容,而是分析这些已经结构化后的数值特征。
3.2 多文件合并原理
因为 CICIDS2017 按天、按攻击类型分成多个文件,所以系统预处理时会先把多个 CSV 合并成一个总数据集。
实现原理很简单:
- 依次读取每个 CSV
- 统一列名格式
- 存入列表
- 使用
pd.concat()纵向拼接
这样做的目的有两个:
- 让模型一次看到更多攻击类型
- 让训练集和测试集具有更全面的数据分布
如果只读取 Monday 文件,系统只会看到正常流量,模型就会学成“永远预测 BENIGN”。
所以多文件合并的本质作用是:
构造一个包含正常样本和多种攻击样本的完整训练数据集。
3.3 多编码读取原理
CICIDS2017 某些 CSV 文件编码并不统一,有的能用 UTF-8 读,有的需要 latin-1 或 cp1252。
所以你的 safe_read_csv() 函数不是只用一种编码,而是采用“依次尝试”的方式:
- 先尝试
utf-8 - 如果失败,再试
utf-8-sig - 再试
latin-1 - 再试
cp1252 - 必要时再试
gbk/gb18030
这个机制的本质是一个容错式文件读取策略。
它避免因为单个文件编码不同导致整个预处理流程中断。
3.4 数据清洗原理
原始数据中可能存在很多不适合直接训练的问题,比如:
- 重复样本
- 空标签
- 列名中带空格
- 无穷值
- 非法字符
- 缺失值
如果这些问题不处理,后面的训练可能会报错,或者模型效果变差。
3.4.1 列名清理
程序会对列名做 strip(),去掉前后空格。
这样可以避免 " Label" 和 "Label" 被当成两个不同字段。
3.4.2 删除重复列和重复样本
重复列会影响特征读取,重复样本会让模型记住重复数据,降低泛化能力。
所以程序会:
- 删除重复列
- 删除重复行
3.4.3 无穷值替换
网络流量特征里可能出现:
np.inf-np.inf"Infinity"
这些值通常来自“除以 0”或者异常流量。
随机森林和缺失值填补器不能直接处理这类值,所以系统先统一把它们替换为 NaN。
3.4.4 标签清洗
标签列必须保证:
- 不能为空
- 不为全空格
- 格式一致
因为标签是监督学习的“标准答案”,标签脏了,训练就没有意义。
四、特征工程实现原理
4.1 什么是特征
特征就是用来描述网络流量行为的数值属性。
例如:
- Flow Duration
- Total Fwd Packets
- Total Backward Packets
- Packet Length Mean
- Flow Bytes/s
- Flow Packets/s
这些特征相当于把网络行为转换成机器可读的数字。
4.2 特征选择原理
系统中有两种特征选择方式。
第一种:优先使用预设特征
如果配置文件里定义的 PREFERRED_FEATURES 在当前数据中存在,就优先使用这些字段。
这样做的好处是:
- 不同训练批次特征一致
- 便于和后续检测模块保持统一
- 便于模型复现
第二种:自动从数值列中筛选
如果预设特征不完整,程序就自动遍历所有字段:
- 排除明显不是特征的列,比如标签列、Flow ID、IP、时间戳等
- 尝试把每一列转成数值
- 如果某列可以转成数值并且有有效值,就保留为可训练特征
这个逻辑的核心思想是:
模型只能吃数值,所以只把“真正有统计意义的数值字段”送去训练。
4.3 为什么要数值化
机器学习模型不能直接处理随意的字符串。
所以每个候选特征都要经过:
pd.to_numeric(errors="coerce")
其原理是:
- 能转成数字的就保留
- 转不了的变成
NaN
这是一种比较稳妥的特征转换方式,可以最大限度保留可用信息。
五、训练数据构建原理
5.1 X 和 y 的构造
在监督学习里,数据会被拆成两部分:
X:特征矩阵y:目标标签
对于系统:
X是所有选中的流量特征列y是Label列
也就是说:
X = 网络流量的数值特征 y = 该流量属于哪一类
模型训练的目标就是学会从 X 到 y 的映射。
5.2 为什么要划分训练集和测试集
如果所有数据都拿去训练,再用同一批数据做测试,结果会虚高。
因为模型可能只是“记住了”这些样本,而不是真的学会了规律。
所以必须分成:
- 训练集:给模型学习
- 测试集:用来检验模型是否真的有泛化能力
程序使用的是大约 7:3 划分。
5.3 分层抽样原理
用的是:
train_test_split(..., stratify=y)
这表示分层抽样。
它的作用是让训练集和测试集都尽量保持原始数据中的类别比例。
例如,如果整体数据中:
- BENIGN 占 80%
- DoS Hulk 占 10%
- PortScan 占 5%
- Bot 占 5%
那么训练集和测试集也会尽量维持类似比例。
这样做的意义非常大,因为如果不分层抽样,小类别可能在测试集中几乎消失,评估就会失真。
六、缺失值处理原理
6.1 为什么会有缺失值
在数值转换和无穷值替换之后,很多位置会变成 NaN。
而大多数机器学习模型不能直接处理缺失值。
所以系统必须做“缺失值填补”。
6.2 为什么选择中位数填补
程序里用的是:
SimpleImputer(strategy="median")
即用每列的中位数填补缺失值。
选择中位数而不是均值的原因是:
- 网络流量数据通常偏态严重
- 某些异常流量会导致极端值很多
- 均值容易受异常值影响
- 中位数更稳健
所以中位数填补更适合这种网络流量场景。
6.3 为什么训练集和测试集要用同一个填补器
系统先在训练集上 fit,再对测试集 transform。
这一步不能反过来,也不能训练集一个填补规则、测试集另一个规则。
原因是:
测试集必须模拟“真实未来数据”,不能参与训练阶段统计。
所以必须由训练集生成填补规则,再把这个规则应用到测试集和后续检测数据。
七、标签编码原理
7.1 为什么要编码标签
标签原本是字符串,比如:
- BENIGN
- PortScan
- Bot
模型内部更适合处理整数类别,因此需要把这些标签编码成数字,例如:
- BENIGN → 0
- Bot → 1
- DoS Hulk → 2
这就是 LabelEncoder 的作用。
7.2 标签编码的本质
标签编码不是改变类别含义,而是建立一套类别到整数的映射表。
这个映射表会保存下来,后面预测结果出来后再反向解码回原始标签。
所以:
- 训练时:字符串标签 → 整数
- 预测后:整数类别 → 字符串标签
这一步保证了模型训练和用户展示可以兼顾。
八、随机森林模型实现原理
这一部分是整个项目最核心的算法原理。
8.1 随机森林是什么
随机森林本质上是由很多棵决策树组成的集成模型。
它的工作方式是:
- 从训练数据中随机采样
- 训练很多棵不同的决策树
- 对新样本预测时,让所有树分别投票
- 最终选择票数最多的类别作为结果
所以它不是单一模型,而是“多棵树共同决策”。
8.2 为什么适合这个项目
随机森林适合网络入侵检测,主要因为:
1. 适合表格型数据
数据不是图像,也不是文本,而是结构化的数值表。
随机森林对这种数据非常友好。
2. 抗过拟合能力较强
单棵决策树容易过拟合,但随机森林通过多树集成降低了这种风险。
3. 对特征尺度不敏感
不像 SVM 或 KNN 那样特别依赖标准化,随机森林对原始数值尺度更宽容。
4. 能处理高维特征
CICIDS2017 有很多特征列,随机森林在这类问题上表现通常比较稳定。
8.3 决策树在内部是怎么工作的
每一棵树本质上都在不断问类似这样的问题:
- Flow Duration 是否大于某个值?
- Packet Length Mean 是否小于某个值?
- Flow Bytes/s 是否超过某个阈值?
通过不断划分样本,把不同类别逐步分开。
最终每个叶子节点会倾向于某一类。
所以决策树本质上是在学“阈值规则”。
8.4 随机森林为什么比单棵树更好
如果只训练一棵树,它可能非常依赖某些偶然特征,泛化能力差。
随机森林通过两层随机性降低了这个问题:
第一层随机性:Bootstrap 采样
每棵树只看训练集的一部分样本。
第二层随机性:随机选特征
每次分裂时,不是看所有特征,而是只从部分特征中选最优划分。
这两层随机性让每棵树都不一样,最后通过投票综合起来,鲁棒性更强。
8.5 class_weight 的原理
数据不平衡很严重,小类别很少,大类别很多。
如果不处理,模型会偏向大类。
加入:
class_weight="balanced"
后,模型在训练时会自动给小类别更高权重。
这意味着:
- 误判小类别的代价更大
- 模型会更重视小类样本
它的本质是:
通过修改损失贡献,让模型不要只讨好大类别。
九、模型评估原理
9.1 为什么不能只看 accuracy
结果里 accuracy 很高,但某些小类别 precision 很低。
这说明仅看总体准确率是不够的。
因为在极度不平衡数据中,即使模型几乎全预测大类,accuracy 也可能很好看。
9.2 precision、recall、f1-score 的含义
Precision(精确率)
表示模型判成某类的样本中,有多少是真正属于这一类。
比如 Bot 的 precision 很低,说明模型经常把别的类错判成 Bot。
Recall(召回率)
表示真正属于某类的样本中,有多少被模型找出来了。
比如 recall 高,说明漏检少。
F1-score
是 precision 和 recall 的综合指标。
它更适合评价类别不平衡场景。
9.3 分类报告实现原理
系统通过 classification_report() 统计每个类别:
- support:该类真实样本数
- precision
- recall
- f1-score
这本质上是对预测结果和真实标签逐类做对比统计。
十、检测模块实现原理
10.1 检测时为什么要和训练时保持一致
检测模块并不是直接把新数据丢给模型,而是必须严格重复训练时的数据处理流程,包括:
- 选择同样的特征列
- 用同一个 imputer 填补缺失值
- 保证列顺序一致
原因是:
模型学到的是固定特征空间下的规律,如果检测时输入格式变了,预测就会失真。
所以训练阶段保存的这些对象都很重要:
feature_columnsimputer.jobliblabel_encoder.joblibmodel.joblib
10.2 检测流程本质
检测流程可以概括为:
读取新数据 → 按训练时同样方式做特征对齐 → 用已保存的缺失值填补器处理 → 输入模型预测 → 把数字类别还原成字符串标签 → 在界面展示
本质上,这是把“训练阶段学到的规则”应用到新样本上。
十一、PyQt 界面实现原理
这个项目除了模型,还做成了桌面程序。其实现原理不是算法层面的,而是界面与业务逻辑的组织方式。
11.1 为什么要做图形界面
如果只写脚本,程序虽然能跑,但使用不方便。
做成 PyQt 桌面程序后,用户可以通过按钮完成:
- 选择 CSV
- 开始预处理
- 训练模型
- 查看结果
- 执行检测
这提升了项目的工程完整性和可演示性。
11.2 界面与业务分离原理
界面层负责:
- 接收用户操作
- 显示日志和结果
核心层负责:
- 数据处理
- 模型训练
- 预测
这种分离有好处:
- 结构清晰
- 易于维护
- 后期好扩展
11.3 为什么要用 Worker + QThread
机器学习训练和数据预处理通常比较耗时。
如果这些任务直接在主线程里执行,PyQt 界面会卡死。
所以系统采用:
Worker对象负责具体任务QThread负责在线程中运行 Worker
原理就是把耗时任务放到后台线程运行,让主线程继续负责界面刷新。
这样界面就不会“未响应”。
11.4 信号与槽机制原理
PyQt 使用信号-槽机制进行通信。
例如后台线程在预处理过程中会不断发送日志信号,主界面收到信号后把日志显示出来。
这样做的优点是:
- 线程间通信安全
- 主界面和后台逻辑解耦
- 用户能实时看到运行进度
十二、文件存储实现原理
12.1 为什么要把中间结果保存到文件
预处理、训练、检测不是一次性流程。
为了让系统具备工程实用性,需要把关键结果落盘保存,这样下次可以直接加载。
保存的内容包括:
- 训练特征
X_train.csv - 测试特征
X_test.csv - 训练标签
y_train.csv - 测试标签
y_test.csv - 缺失值填补器
imputer.joblib - 标签编码器
label_encoder.joblib - 元信息
preprocess_meta.json - 模型文件
model.joblib
12.2 meta 文件的作用
preprocess_meta.json 相当于整个系统的“配置快照”。
它记录了:
- 用了哪些特征列
- 标签列名是什么
- 有哪些类别
- 训练集和测试集大小
- 数据文件路径
后续训练、评估、检测都依赖这个 meta 文件定位资源。
所以它相当于把预处理阶段的环境固定下来。
十三、为什么结果会出现“大类好、小类差”
这其实是项目原理中非常关键的一点。
13.1 数据不平衡的本质影响
你的结果中:
- BENIGN 样本几十万
- DoS Hulk、PortScan 也很多
- 但 Bot、Web Attack、SQL Injection 非常少
模型在训练时会更容易学会大类规律,因为大类样本多、统计模式更明显。
而小类样本太少,模型很难学到稳定边界。
所以会出现:
- 大类指标很好
- 小类 precision 很差
- macro avg 偏低
13.2 为什么会出现 recall 高但 precision 低
比如某类 recall 高,说明真正属于这一类的大多数都被抓到了。
但 precision 低说明模型把大量别的类也误报成这一类。
这通常意味着:
模型学到了“这类的大致轮廓”,但边界不够精确。
这种情况在小样本、相似攻击类别中很常见。
十四、这个项目的本质优点和局限
14.1 优点
1. 流程完整
从数据预处理到训练、评估、检测全链路完整。
2. 工程可运行
不是停留在算法实验,而是真正做成了 GUI 程序。
3. 模型稳定
随机森林对结构化表格数据效果较稳,适合毕业设计实现。
4. 易扩展
后续可以替换模型、增加图表、增加实时检测。
14.2 局限
1. 严重依赖数据质量
如果数据标签有问题,模型会直接学偏。
2. 对类别不平衡敏感
小类样本太少时性能不稳定。
3. 当前偏向离线检测
目前主要基于 CSV 特征输入,不是直接实时抓包分析。
4. 对未知攻击的泛化有限
虽然比规则系统灵活,但仍依赖训练数据覆盖范围。
十五、用一句话概括这个项目的实现原理
可以这样总结:
本项目通过对网络流量特征数据进行清洗、数值化、缺失值填补和标签编码,构建结构化训练样本;再利用随机森林算法学习不同流量类型的统计特征模式;最后将训练好的模型集成到 PyQt 图形界面中,实现网络入侵数据的预处理、训练、评估和检测一体化功能。
十六、如果用于论文或答辩,建议这样讲
你可以直接这么介绍:
该系统的实现原理可以分为数据层、模型层和界面层三个部分。数据层负责将原始网络流量 CSV 转换为可训练的结构化数据;模型层采用随机森林算法完成多分类学习,通过训练样本建立特征与攻击类型之间的映射关系;界面层基于 PyQt5 实现用户交互,并通过多线程机制保证训练和预处理过程中的界面响应性。最终系统能够实现从数据导入到模型训练再到攻击检测的完整流程。
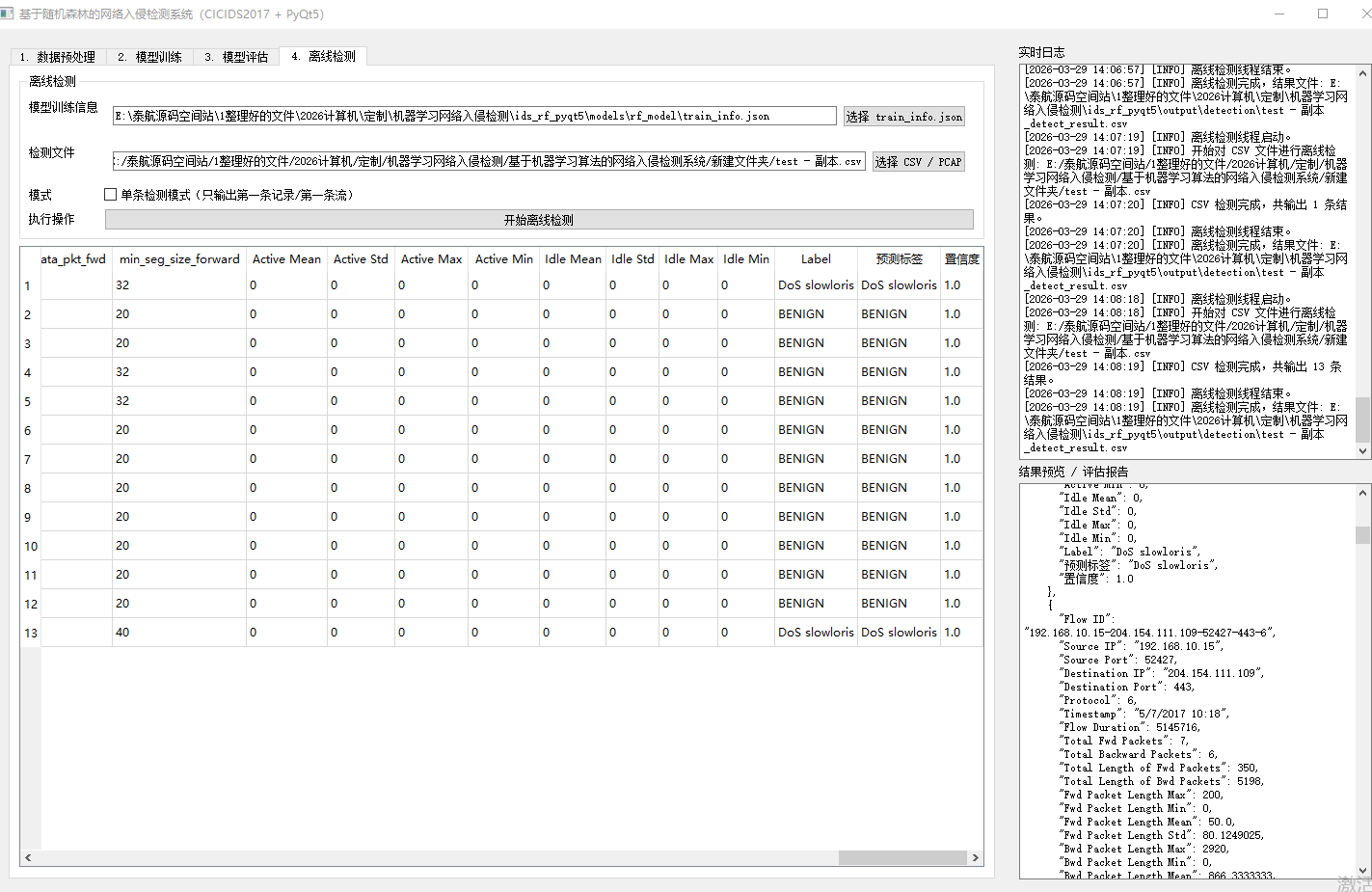
最终程序实现效果如下:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)