RAG-SQL Router实战:让AI智能判断文档与数据库查询,小白也能轻松搭建收藏版
本文介绍RAG-SQL Router系统,解决AI问答时判断信息来源(文档或数据库)的困境。通过LlamaIndex框架和OpenAI模型,实现智能路由决策,支持非结构化和结构化数据查询。提供完整代码和实战步骤,帮助开发者快速搭建智能问答系统。此外,结合Cleanlab Codex提升输出可靠性,适用于企业知识库、客服系统和数据分析助手等场景。
你有没有遇到过这样的困境:用户问你一个问题,你得先判断是该去文档库里翻翻,还是该查查数据库?更头疼的是,如果判断错了,给出的答案要么不准确,要么干脆答非所问。
今天我想和你聊聊一个实战项目——RAG-SQL Router。这不是什么高深莫测的理论,而是一个能真正解决问题的智能系统。更重要的是,我会把完整的实现思路和代码都分享给你,让你也能动手搭建一个。
一、为什么需要这样一个系统?
先说说实际场景。假设你在做一个企业内部的智能问答助手:
场景1:非结构化数据查询
- “公司最新的休假政策是什么?”
- “产品功能文档里关于API鉴权的部分怎么说的?”
这类问题的答案藏在PDF、Word文档、Wiki页面里——典型的非结构化数据,最适合用RAG(检索增强生成)来处理。
场景2:结构化数据查询
- “去年第四季度销售额最高的三个地区是哪些?”
- “目前有多少活跃用户?”
这些问题需要的是精确的数字,答案在数据库里——需要Text-to-SQL来解决。
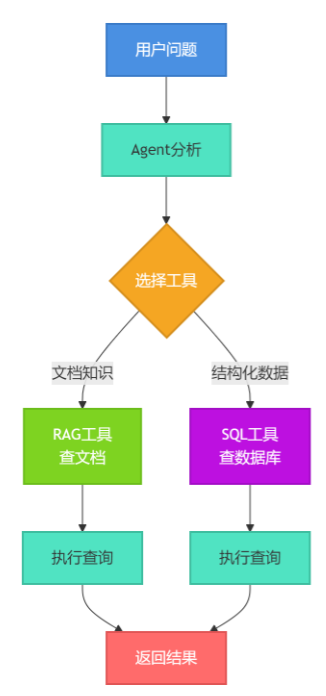
问题来了:当用户随便问一个问题,系统怎么知道该用哪种方式回答?
这就是RAG-SQL Router要解决的核心问题:让AI自己判断该走哪条路。
二、系统架构:Agent如何做决策?
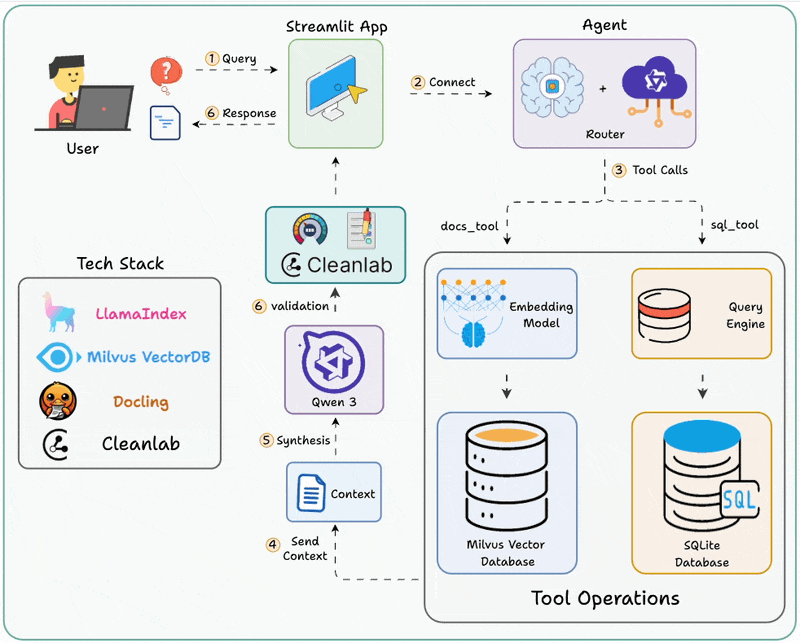
整个系统的核心是一个路由Agent,它的工作流程是这样的:
智能体根据用户问题分析意图后,自主选择文档检索或数据库查询工具来获取信息并返回结果。
关键组件解析
- Router Agent(路由智能体)
这是整个系统的大脑。它基于LlamaIndex的Workflow框架构建,能够:
- 理解用户问题的语义
- 判断问题类型(文档检索还是数据查询)
- 选择合适的工具
- 甚至可以同时调用多个工具
- RAG工具(向量检索引擎)
负责处理非结构化数据:
- 使用LlamaCloud作为向量数据库
- 支持PDF、Word等文档格式
- 通过语义相似度检索相关内容
- SQL工具(自然语言转SQL引擎)
负责处理结构化数据:
- 将自然语言转换为SQL查询
- 执行数据库查询
- 返回结构化结果
- Cleanlab Codex(质量保障层)
这是个亮点!很多人做Agent,但没人关心输出是否靠谱。Cleanlab Codex提供:
- 自动检测不准确或无用的回答
- 为每个回答提供可信度评分
- 实时验证查询和响应
- 允许专家直接改进回答,无需改代码
三、动手实现:完整代码解析
让我带你一步步搭建这个系统。我会用最实际的代码,而不是空谈理论。
第一步:环境准备
# 创建项目目录mkdir rag-sql-routercd rag-sql-router# 创建虚拟环境python -m venv venvsource venv/bin/activate # Windows用: venv/Scripts/activate# 安装依赖pip install llama-index llama-index-llms-openai / llama-index-embeddings-openai / llama-index-indices-managed-llama-cloud / sqlalchemy streamlit nest-asyncio
第二步:配置API密钥
创建 .env 文件:
OPENAI_API_KEY=your_openai_keyLLAMA_CLOUD_API_KEY=your_llamacloud_keyLLAMA_CLOUD_ORG_ID=your_org_idLLAMA_CLOUD_PROJECT_NAME=your_projectLLAMA_CLOUD_INDEX_NAME=your_index
第三步:搭建SQL查询引擎
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, insertfrom llama_index.core.query_engine import NLSQLTableQueryEnginefrom llama_index.core import SQLDatabase# 创建示例数据库engine = create_engine("sqlite:///:memory:")metadata = MetaData()# 定义城市统计表city_stats = Table( 'city_stats', metadata, Column('city', String, primary_key=True), Column('population', Integer), Column('country', String),)metadata.create_all(engine)# 插入示例数据rows = [ {"city": "Toronto", "population": 2930000, "country": "Canada"}, {"city": "Tokyo", "population": 13960000, "country": "Japan"}, {"city": "Berlin", "population": 3645000, "country": "Germany"},]with engine.connect() as conn: for row in rows: conn.execute(insert(city_stats).values(row)) conn.commit()# 创建SQL数据库对象sql_database = SQLDatabase(engine, include_tables=["city_stats"])# 创建自然语言SQL查询引擎sql_query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=["city_stats"],)
这段代码做了什么?
-
创建了一个内存SQLite数据库(适合演示,生产环境换成MySQL/PostgreSQL)
-
定义了城市统计表,包含城市名、人口、国家字段
-
插入了一些示例数据
-
用
NLSQLTableQueryEngine包装数据库,它能把"人口最多的城市"这样的问题转成SQL
第四步:搭建RAG检索引擎
from llama_index.indices.managed.llama_cloud import LlamaCloudIndeximport os# 连接到LlamaCloud索引rag_index = LlamaCloudIndex( name=os.getenv("LLAMA_CLOUD_INDEX_NAME"), project_name=os.getenv("LLAMA_CLOUD_PROJECT_NAME"), organization_id=os.getenv("LLAMA_CLOUD_ORG_ID"), api_key=os.getenv("LLAMA_CLOUD_API_KEY"),)# 创建查询引擎rag_query_engine = rag_index.as_query_engine()
LlamaCloud是什么?
简单说,它是一个托管的向量数据库服务:
- 你上传文档(PDF、DOCX等)
- 它自动切分、向量化、建索引
- 你只需要调用API查询
当然,你也可以用Qdrant、Pinecone、Weaviate等替代。
第五步:将查询引擎包装成工具
from llama_index.core.tools import QueryEngineTool# SQL工具sql_tool = QueryEngineTool.from_defaults( query_engine=sql_query_engine, name="sql_query_engine", description=( "用于查询城市统计数据,包括人口、国家等信息。" "适合回答关于数字、排名、统计类的问题。" ),)# RAG工具rag_tool = QueryEngineTool.from_defaults( query_engine=rag_query_engine, name="document_search_engine", description=( "用于搜索文档内容,适合回答关于政策、流程、" "说明等需要从文档中查找信息的问题。" ),)
为什么要包装成工具?
这里的description非常关键!Agent会读这些描述来判断该用哪个工具。所以描述要:
- 清晰明确:说清楚工具能做什么
- 区分明显:让Agent能轻松分辨使用场景
- 举例说明:提示适用的问题类型
第六步:构建Router Workflow
这是整个系统最核心的部分:
from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step,)from llama_index.llms.openai import OpenAIfrom typing import List, Any# 定义事件类型class PrepEvent(Event): """准备阶段完成事件""" passclass ToolCallEvent(Event): """工具调用事件""" tool_calls: List[Any]# 定义Router Workflowclass RouterWorkflow(Workflow): def __init__(self, tools: List[QueryEngineTool], kwargs): super().__init__(kwargs) self.tools = {tool.metadata.name: tool for tool in tools} self.llm = OpenAI(model="gpt-4") @step async def prepare_chat(self, ev: StartEvent) -> PrepEvent: """准备对话消息""" # 获取用户查询 user_msg = ev.query # 构建系统提示 system_prompt = self._build_system_prompt() # 存储到上下文 self.query = user_msg self.messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_msg} ] return PrepEvent() @step async def handle_llm_call(self, ev: PrepEvent) -> ToolCallEvent | StopEvent: """调用LLM决策""" # 准备工具定义给LLM tools_def = [ { "type": "function", "function": { "name": name, "description": tool.metadata.description, "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "用户查询" } }, "required": ["query"] } } } for name, tool in self.tools.items() ] # 调用LLM response = await self.llm.achat( messages=self.messages, tools=tools_def ) # 检查是否有工具调用 if response.message.tool_calls: return ToolCallEvent(tool_calls=response.message.tool_calls) else: # 没有工具调用,直接返回答案 return StopEvent(result=response.message.content) @step async def handle_tool_calls(self, ev: ToolCallEvent) -> StopEvent: """执行工具调用""" results = [] for tool_call in ev.tool_calls: tool_name = tool_call.function.name tool_args = eval(tool_call.function.arguments) # 执行工具 tool = self.tools[tool_name] result = await tool.aquery(tool_args["query"]) results.append({ "tool": tool_name, "result": str(result) }) # 组合结果 final_answer = self._combine_results(results) return StopEvent(result=final_answer) def _build_system_prompt(self) -> str: """构建系统提示""" return """你是一个智能助手,能够访问以下工具:1. SQL查询引擎:用于查询结构化数据2. 文档搜索引擎:用于搜索文档内容根据用户问题,选择合适的工具。如果需要,可以同时使用多个工具。""" def _combine_results(self, results: List[dict]) -> str: """组合多个工具的结果""" if len(results) == 1: return results[0]["result"] combined = "根据查询结果:/n/n" for i, res in enumerate(results, 1): combined += f"{i}. 从{res['tool']}得到: {res['result']}/n" return combined
这个Workflow是怎么工作的?
-
prepare_chat: 接收用户问题,准备系统提示和对话消息
-
handle_llm_call: 调用LLM,让它决定用哪个工具(或多个工具)
-
handle_tool_calls: 实际执行工具调用,获取结果
-
如果有多个结果,组合起来返回
关键点在于:
- Event驱动:每个step返回一个Event,触发下一个step
- 异步执行:所有step都是async,支持并发
- 灵活路由:LLM可以选择0个、1个或多个工具
第七步:创建Streamlit界面
import streamlit as stimport asyncio# 页面配置st.set_page_config(page_title="RAG-SQL Router", page_icon="🤖")st.title(" 智能路由问答系统")st.markdown("问我任何问题,我会自动选择最佳方式回答!")# 初始化工具和workflowif "workflow" not in st.session_state: # 创建工具 tools = [sql_tool, rag_tool] # 初始化workflow st.session_state.workflow = RouterWorkflow( tools=tools, timeout=60.0 )# 聊天历史if "messages" not in st.session_state: st.session_state.messages = []# 显示历史消息for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"])# 用户输入if prompt := st.chat_input("在这里输入你的问题..."): # 显示用户消息 st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) # 调用workflow获取答案 with st.chat_message("assistant"): with st.spinner("思考中..."): # 运行workflow result = asyncio.run( st.session_state.workflow.run(query=prompt) ) # 显示答案 st.markdown(result) # 保存助手回答 st.session_state.messages.append({"role": "assistant", "content": result})# 侧边栏:显示可用工具with st.sidebar: st.subheader("🔧 可用工具") st.write("1. SQL查询引擎") st.caption("查询城市统计数据") st.write("2. 文档搜索引擎") st.caption("搜索文档内容") if st.button("清空对话"): st.session_state.messages = [] st.rerun()
第八步:运行系统
streamlit run app.py
打开浏览器,访问 http://localhost:8501,试试这些问题:
SQL类问题:
- “哪个城市人口最多?”
- “有多少个欧洲城市?”
RAG类问题:
- “文档里提到的政策要点是什么?”
- “关于API使用的说明在哪里?”
混合问题:
- “东京的人口是多少?同时告诉我文档里关于东京的介绍。”
四、加入Cleanlab Codex:让输出更可靠
前面的系统已经能工作了,但有个问题:怎么知道AI的回答靠不靠谱?
这就是Cleanlab Codex的价值。它能:
- 自动检测问题回答
- 答非所问
- 信息不完整
- 事实错误
- 提供可信度评分
- 每个回答都有0-1的分数
- 分数低于阈值触发告警
- 支持专家反馈
- SME(领域专家)可以直接标注
- 系统自动学习改进
集成代码示例:
from cleanlab_codex import CleanlabCodex# 初始化Codexcodex = CleanlabCodex(api_key=os.getenv("CLEANLAB_API_KEY"))# 在workflow中使用@stepasync def validate_response(self, ev: StopEvent) -> StopEvent: """验证响应质量""" # 获取原始回答 response = ev.result # 验证质量 validation = codex.validate( query=self.query, response=response, context=self.retrieved_context ) # 添加可信度评分 confidence = validation.trustworthiness_score if confidence < 0.7: response += f"/n/n 可信度: {confidence:.2%} (建议人工确认)" else: response += f"/n/n 可信度: {confidence:.2%}" return StopEvent(result=response)
五、实际应用场景
这套系统不是玩具,我们来看看能解决什么实际问题:
场景1:企业知识库
问题: 公司有大量文档(员工手册、产品文档、流程规范)和业务数据(销售、用户、财务)。员工经常不知道去哪找信息。
解决方案:
- RAG工具索引所有文档
- SQL工具连接业务数据库
- 员工直接问问题,系统自动路由
效果:
- 减少80%的重复咨询
- 提升员工自助查询效率
- 数据和文档统一入口
场景2:客户服务系统
问题: 客服需要回答产品使用问题(文档)和订单状态(数据库)。
解决方案:
- RAG工具索引产品文档、FAQ
- SQL工具连接订单系统
- 客服输入问题,系统提供参考答案
效果:
- 新客服上手快
- 答案标准化
- 响应时间缩短50%
场景3:数据分析助手
问题: 业务人员不会写SQL,但需要经常查数据。
解决方案:
- SQL工具连接数据仓库
- RAG工具提供分析方法论文档
- 自然语言查询,自动生成SQL
效果:
- 降低对数据团队的依赖
- 提升数据驱动决策效率
- 减少重复分析工作
六、关键经验和坑
搭建这个系统时,我踩过不少坑,分享几个关键经验:
1. 工具描述要精准
坑: 最开始我的SQL工具描述是"用于查询数据"——太模糊了!结果Agent经常选错。
解决: 改成"用于查询城市统计数据,包括人口、国家等信息。适合回答关于数字、排名、统计类的问题。"——具体、清晰、有例子。
2. 处理好并发调用
坑: 用户问"东京人口多少?文档里怎么说的?"——需要同时调用两个工具,但结果怎么组合?
解决:
- Workflow支持并发step
- 在
_combine_results里做好结果聚合 - 让LLM再做一次总结
3. 数据库连接要健壮
坑: SQLite内存数据库重启就没了,生产环境不能用。
解决:
# 生产环境用持久化数据库engine = create_engine( "postgresql://user:pass@host:5432/db", pool_pre_ping=True, # 检查连接有效性 pool_size=10, # 连接池)
4. Token消耗要控制
坑: 每次查询都把全部上下文传给LLM,token消耗巨大。
解决:
- 只传必要的上下文
- 使用更便宜的模型做路由(gpt-3.5-turbo)
- 缓存常见问题的答案
5. 错误处理要完善
坑: SQL语法错误、网络超时、API限流都会导致系统崩溃。
解决:
try: result = await tool.aquery(query)except SQLAlchemyError as e: result = f"数据库查询失败: {str(e)}"except TimeoutError: result = "查询超时,请稍后重试"except Exception as e: result = f"系统错误: {str(e)}" # 记录日志 logger.error(f"Tool error: {e}", exc_info=True)
七、性能优化建议
如果你要把这套系统用到生产环境,这些优化必不可少:
1. 缓存机制
from functools import lru_cacheimport hashlib@lru_cache(maxsize=1000)def cached_query(query_hash: str): """缓存查询结果""" # 实际查询逻辑 pass# 使用时query_hash = hashlib.md5(query.encode()).hexdigest()result = cached_query(query_hash)
2. 批量查询
对于相似查询,批量处理:
async def batch_query(queries: List[str]): """批量执行查询""" tasks = [workflow.run(query=q) for q in queries] return await asyncio.gather(*tasks)
3. 监控和日志
import loggingfrom datetime import datetimelogging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('rag_sql_router.log'), logging.StreamHandler() ])logger = logging.getLogger(__name__)# 在关键位置记录logger.info(f"Query received: {query}")logger.info(f"Tool selected: {tool_name}")logger.info(f"Response time: {elapsed:.2f}s")
4. 限流保护
from functools import wrapsimport timedef rate_limit(max_calls: int, time_window: int): """限流装饰器""" calls = [] def decorator(func): @wraps(func) async def wrapper(*args, kwargs): now = time.time() # 清理过期记录 calls[:] = [c for c in calls if c > now - time_window] if len(calls) >= max_calls: raise Exception("请求过于频繁,请稍后再试") calls.append(now) return await func(*args, kwargs) return wrapper return decorator@rate_limit(max_calls=10, time_window=60)async def handle_query(query: str): """处理查询,每分钟最多10次""" pass
八、总结
看到这里,你大概已经能感受到:RAG-SQL Router 这东西看起来像“多加了一个路由层”,但真正解决的是落地时最容易被忽视的一件事——把“该去哪儿找答案”这一步交给系统,而不是交给用户。
很多企业内部问答做不起来,并不是因为模型不够强,而是因为入口不够统一:同一句话问出来,有时候是制度条款,有时候是数据口径,有时候还夹杂着流程步骤。人能凭经验判断“先查文档还是先查库”,但系统如果没有这个判断能力,就会变成两种尴尬:
- 只做RAG:回答得像“引用资料”,听起来挺像那么回事,但数字经不起核对;
- 只做Text-to-SQL:能查到数,但对“为什么这么算”“规则写在哪”完全没有解释能力。
Router 的价值,就是让这两套能力不再互相拖后腿,而是互相补位:需要确定性的时候走SQL,需要背景解释的时候走RAG,复杂一点的问题就两条路一起跑,最后再把结果合到一张桌子上给你。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献189条内容
已为社区贡献189条内容

所有评论(0)