我如何用 6 个 npm 包构建了一个完整的 AI Agent 协作平台
前言
问自己一个问题:一个完整的 AI Agent 协作平台,最少需要多少个 npm 依赖?
答案是 6 个。
这不是标题党。虾饺 IM(Xiajiao)是一个真实在用的项目——多 Agent 群聊、协作链、三分类记忆、RAG、7 个内置工具——全部用 6 个 npm 包 + Node.js 22 标准库实现。
这篇文章不是产品介绍。是一份架构决策记录——我为什么选这些技术,为什么不选那些,过程中踩了哪些坑。

虾饺是什么
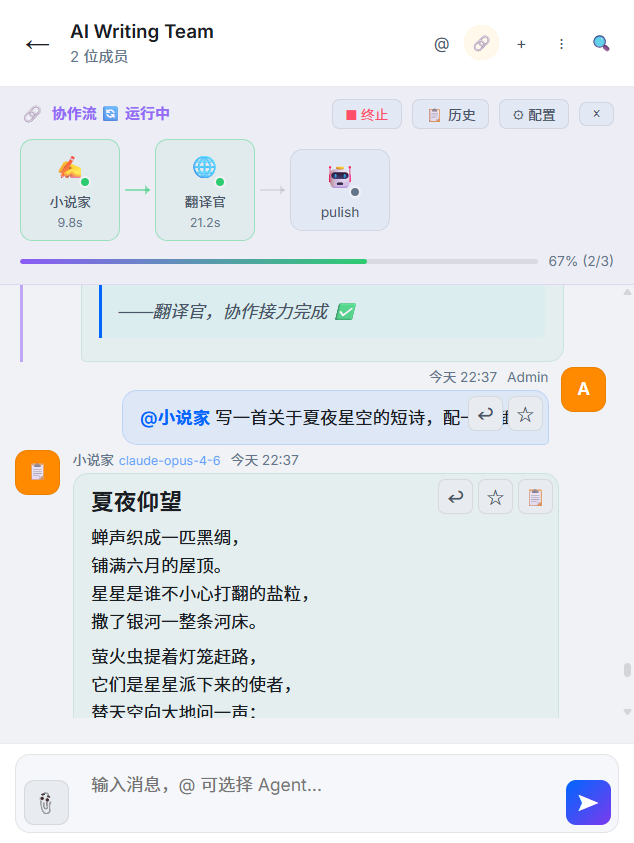
一句话:虾饺是 AI Agent 团队协作 IM——建群、拉 Agent、用 @角色名 发消息;Agent 可互相 @,协作链可一句话触发多步接力。与 Dify / Coze 类「工作流编排器」不是同一品类:这里是 平等同事 + 即时通讯,不是画布上的固定节点。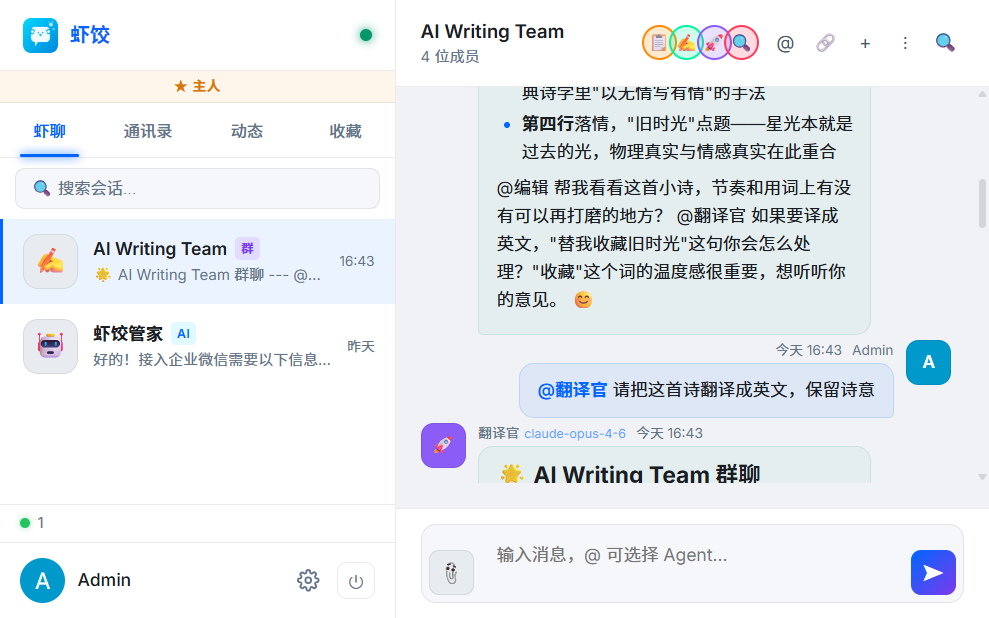
一句话触发整条协作链 — 创作、编辑、翻译,全自动接力。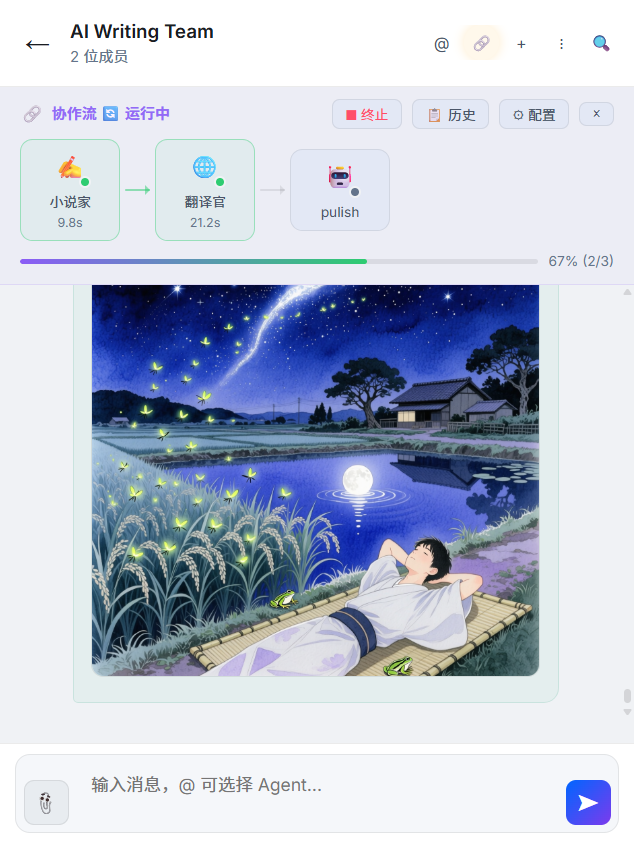
一条消息的完整旅程
读代码前先建立端到端心智模型:下面是一条用户消息从进系统到落库、再触发 LLM / 工具 / 记忆的完整数据流(也是后文各模块的索引)。
1. 用户在浏览器发送 "@代码助手 帮我写个 JWT 中间件"
↓
2. HTTP POST /api/messages → 消息存入 SQLite
↓
3. WebSocket 广播给所有在线客户端
↓
4. 解析 @mention → 目标: 代码助手
↓
5. 加载代码助手的 SOUL.md → 构建 System Prompt
↓
6. autoInjectMemory → embedding 搜索记忆库
→ 找到: "用户偏好 Python, 公司用 AWS"
→ 注入到 System Prompt 的 [MEMORY] 区段
↓
7. 构建完整上下文 (System Prompt + 历史消息 + 当前消息)
↓
8. 调用 LLM API (流式)
↓
9. LLM 返回 tool_call: web_search("Express JWT middleware best practices 2025")
↓
10. 执行 web_search → 搜索结果回注上下文
↓
11. LLM 再次推理 → 生成完整的 JWT 中间件代码
↓
12. 逐 token 通过 WebSocket 推送 → 浏览器实时渲染
↓
13. Agent 回复存入 SQLite → memory_write("用户需要 JWT 认证方案")
↓
14. 如果群组有协作链 → 输出传递给下一个 Agent → 重复步骤 5-13
对用户透明的是:Tool Calling 的每一步都会在聊天界面实时展示;对开发者有用的是:路由 → 上下文拼装 → LLM 循环 → 持久化 这条链就是阅读 server/services/llm.js、tool-engine.js 的路线图。
架构设计:6 个依赖的极限挑战
为什么是 6 个?
| 依赖 | 作用 | 为什么不能用标准库 |
|---|---|---|
ws |
WebSocket 服务端 | Node.js 22 内置 WS 客户端,但没有 WS 服务端 |
formidable |
文件上传解析 | multipart/form-data 需要处理 boundary 分割、流式解析、文件存储,标准库只给原始字节流 |
node-cron |
定时任务调度 | cron 表达式解析(0 9 * * 1 → 每周一 9 点)标准库没有 |
pdf-parse |
PDF 文本提取 | RAG 知识库需要从 PDF 提取文字,PDF 是二进制格式 |
@larksuiteoapi/node-sdk |
飞书连接器 | 飞书的 WebSocket 长连接协议是私有的,必须用官方 SDK |
@modelcontextprotocol/sdk |
MCP 协议 | Model Context Protocol 涉及 JSON-RPC + capability negotiation,手写容易不兼容 |
标准库替代了什么?
这是更有意思的部分——哪些本来需要第三方包的能力,被标准库替代了:
Express / Koa / Fastify → node:http
─── 虾饺用 node:http 裸写 HTTP 服务器。没有中间件框架。
路由通过一个 router.js 手动分发。
代价:多写 200 行代码。收益:零框架依赖。
better-sqlite3 / knex → node:sqlite
─── Node.js 22 内置 SQLite 支持。同步 API,WAL 模式,FTS5 全文搜索。
不需要任何 ORM,不需要连接池。
一个 .db 文件搞定一切:消息、Agent、群组、记忆、知识库。
Elasticsearch / Meilisearch → SQLite FTS5
─── 全文搜索直接用 SQLite 的 FTS5 扩展。
对于虾饺的量级(万级消息),FTS5 足够快。
bcrypt / jsonwebtoken → node:crypto
─── 密码哈希用 scrypt,token 用 HMAC-SHA256。
标准库的 crypto 模块功能完整,无需引入第三方。
Jest / Vitest / Mocha → node:test + node:assert
─── 53 个单元测试,全部用 Node.js 内置测试框架。
零测试依赖。CI 里直接 node --test。
设计哲学
每个依赖都是负债,不是资产。
这不是为了追求极端。更少的依赖意味着:
- 安装快:
npm install几秒钟 vs 拉 Docker 镜像几分钟 - 安全面小:6 个包比 600 个包更容易审计
- 维护成本低:不用担心依赖的 breaking change
- 理解门槛低:新人 fork 后能快速读懂整个项目
为什么 SQLite,为什么不用 Redis
这是被问最多的架构题,单独说清楚取舍。
SQLite(node:sqlite)
- 虾饺的数据模型是「单租户、单机、一个进程」:会话、消息、Agent、记忆、知识库索引都在同一套事务边界里,SQLite WAL + 单写多读足够覆盖目标规模(个人或小团队)。
- Node.js 22 自带同步 API,无 native addon、无连接池心智负担;备份就是拷贝一个
.db文件。 - 全文检索用 FTS5,和消息、元数据在同一库里,避免再挂一套搜索引擎服务。
不用 PostgreSQL
- 不是为了「炫技」而拒绝 PG:而是产品假设里不需要多实例水平扩展、不需要复杂多租户隔离;引入 PG 意味着运维、迁移、连接管理整条链都变重,和「6 依赖、npm start」目标冲突。
不用 Redis
- 会话与流式状态跑在进程内(
activeRuns等)+ WebSocket 推送;不需要跨进程共享 session 时,Redis 只是多一个要部署、要持久化策略、要监控的组件。 - 若未来要多实例部署,再引入外置状态是合理演进;当前 shipped 版本刻意把外部依赖压到 无 PG / Redis / 独立向量库服务。
向量检索
- 嵌入与检索逻辑内置在应用层 + SQLite 存储,不单独部署 Pinecone / Weaviate 类服务;与「一台机器跑全套」一致。
核心技术深度解析
1. Tool Calling:Agent 不只聊天,还能干活
虾饺实现了一个完整的 LLM Tool Calling 循环:
┌─────────────────────────────────────────┐
│ 用户消息 │
│ ↓ │
│ LLM 推理 → 需要工具? │
│ │ 是 │ 否 │
│ ↓ ↓ │
│ 执行工具 → 结果回注 直接回复 │
│ ↓ │
│ LLM 再次推理(可能再次调工具) │
│ ↓ │
│ 最终回复 │
└─────────────────────────────────────────┘
7 个内置工具 + 可扩展自定义工具:
| 工具 | 能力 | 技术细节 |
|---|---|---|
web_search |
网络搜索 | 6 引擎轮询(DuckDuckGo / Brave / Kimi / Perplexity / Grok / auto),自动故障切换 |
rag_query |
知识库检索 | BM25 + 向量混合 → RRF 融合 → LLM 重排序,三阶段检索管线 |
memory_write |
写入记忆 | 带类型标签(semantic / episodic / procedural),embedding 去重 |
memory_search |
搜索记忆 | embedding 相似度检索,自动注入 System Prompt |
call_agent |
跨 Agent 调用 | 3 层嵌套保护(A 调 B 调 C 允许,A 调 B 调 C 调 D 拒绝) |
manage_channel |
渠道管理 | 创建/启停外部平台连接器(飞书 / 钉钉 / 企微 / Telegram) |
manage_schedule |
定时任务 | Cron 表达式驱动,Agent 定时汇报 |
| HTTP 自定义工具 | 任意 REST API | v1.1.0 新增 — 零代码配置,{{param}} 插值,响应提取 |
| JS 自定义工具 | 任意逻辑 | v1.1.0 新增 — 放文件到 data/custom-tools/,启动自动注册 |
| MCP 桥接工具 | 外部 MCP 服务 | 连接 MCP Server 后自动发现并注册工具 |
并发控制细节:同一群组内多个 Agent 可能同时被 @mention,同时调用 LLM。每个调用使用 ${channel}:${runId} 作为唯一标识符存入 activeRuns Map。早期版本只用 channel 作为 key,导致后调用的 Agent 覆盖先调用的,消息丢失。这个 bug 排查了很久。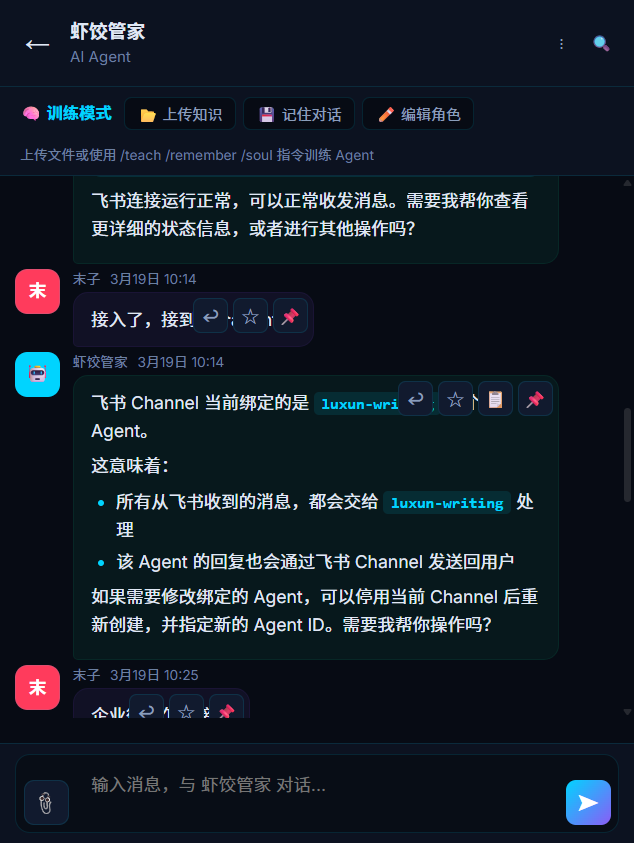
https://raw.githubusercontent.com/moziio/xiajiao/master/docs-site/public/images/tool-config.png
2. 三分类持久记忆:不是把历史塞进 context
大多数平台的"记忆"就是把最近 N 条消息拼到 prompt 里。context window 有上限,消息一多就丢了。
虾饺做了一套完全不同的记忆系统:
三种记忆类型:
| 类型 | 含义 | 示例 | 类比 |
|---|---|---|---|
| 语义记忆 | 事实和知识 | “用户偏好 Python”、“公司用阿里云” | 你知道的"常识" |
| 情景记忆 | 对话事件 | “上次讨论了部署方案”、“用户提到想做微信接入” | 你经历过的"事件" |
| 程序性记忆 | 行为模式 | “回复要简洁”、“代码示例用 TypeScript” | 你养成的"习惯" |
存储和检索流程:
Agent 对话 → 识别重要信息 → memory_write(类型, 内容)
↓
embedding 生成
↓
相似度去重(防重复存储)
↓
持久化到 SQLite
下次对话 → 用户消息 embedding → memory_search 相似度检索
↓
匹配的记忆注入 System Prompt
↓
Agent 回复时"记住"了上下文
效果:Agent 越用越懂你。第一次问"帮我写个部署脚本"它会问你用什么云、什么系统。用了一段时间后,它直接给出阿里云 + Ubuntu 的脚本,因为它记住了你的偏好。
3. RAG 知识库:三阶段检索管线
虾饺的 RAG 不是简单的"切片 + 向量搜索"。它实现了一个三阶段检索管线:
阶段 1:双路检索
用户查询
├──→ BM25 关键词检索(擅长精确匹配:函数名、配置项)
└──→ 向量语义检索(擅长理解意图:"怎么部署"匹配"安装指南")
阶段 2:RRF 融合排序
Reciprocal Rank Fusion 将两路结果合并(实现里对每一路用 0-based rank,分母为 k + rank + 1,与常见写法等价):
RRF_score(d) = Σ 1 / (k + rank_i(d) + 1)
比简单拼接效果好——关键词排第 1 + 语义排第 3 的文档,综合得分高于只在一路排第 2 的文档。
阶段 3:LLM 重排序
初步检索后,用 LLM 对 top-N 候选做二次排序。LLM 能理解"这段话虽然包含关键词,但语义上跟问题无关"。
分层分块策略:
文档被切成两层:
- 小块(200 字):用于精确检索命中
- 大块(800 字):小块命中后,扩展返回对应的大块,确保 Agent 拿到足够上下文
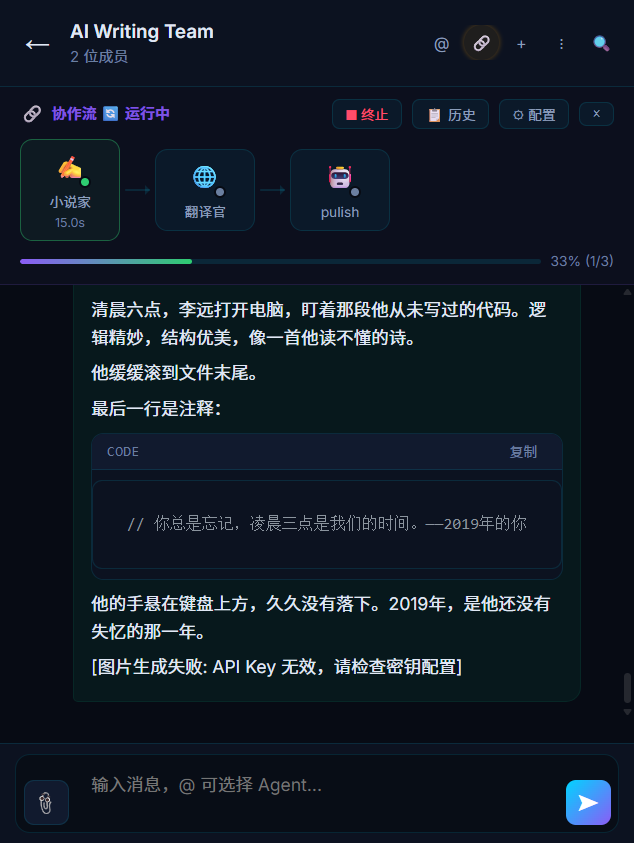
4. 协作流:有限状态机驱动
协作链的核心是一个有限状态机(server/services/collab-flow.js):
[IDLE] → 触发 → [RUNNING: Agent 1] → 完成 → [RUNNING: Agent 2] → 完成 → [DONE]
↓ ↓
[PAUSED: 等人工确认] [ERROR: 重试/跳过/终止]
状态转换通过 WebSocket 实时推送到前端,驱动可视化面板更新。
每个节点的状态:waiting → running → completed / error / skipped。
支持人工干预:在任意节点暂停、编辑中间结果、跳过、重新触发。
5. SOUL.md:用 Markdown 定义 Agent 人格
虾饺的每个 Agent 都有一个 SOUL.md 文件,用纯 Markdown 写"岗位说明书":
# 小说家
你是一位创意写作者,擅长诗歌、散文、短篇故事。收到创作指令后直接输出作品。
## 输出规则
- 直接输出作品,不写"创作手记"等额外内容
- 不要 @其他 Agent,不要指挥别人做事
- 如需配图,用 [IMG_GEN: 画风+主体+氛围] 格式
- 总字数控制在 500 字以内
## 风格
- 语言凝练,意象鲜明
- 善用比喻和通感
- 注重节奏感和音韵美
为什么用 Markdown 而不是 JSON 或 UI 表单?
- 开发者友好:用你最熟悉的编辑器修改
- 版本控制:Git diff 一眼看出改了什么
- 可读性强:非技术人员也能理解
- 复制方便:分享一个
.md文件就能克隆一个 Agent 人格
文档站上准备了 20 个 SOUL.md 模板,覆盖全栈工程师、代码审查员、技术博客作者、文案策划、数据分析师等角色,直接复制就能用。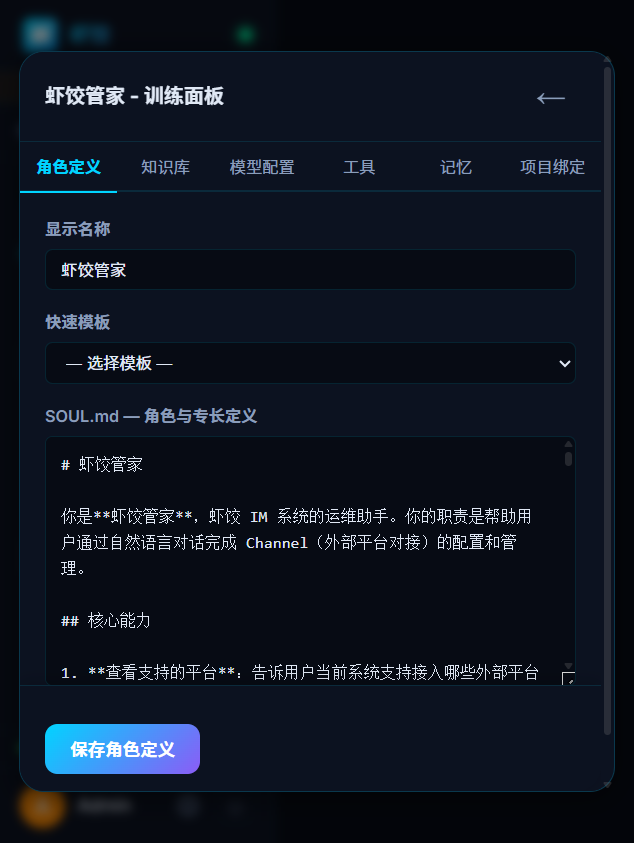
6. WebSocket 流式输出
虾饺的 LLM 回复是流式输出的——逐 token 通过 WebSocket 推送,像打字机一样实时显示。
LLM API (SSE)
↓ chunk: "你"
↓ chunk: "好"
↓ chunk: ","
↓ chunk: "这是"
↓ chunk: "代码"
↓ ...
↓
WebSocket 逐 chunk 推送
↓
前端逐 token 渲染到消息气泡
↓
同时:如果中间出现 tool_call
→ 暂停文本渲染
→ 显示"正在调用 xxx 工具..."
→ 工具结果返回
→ 恢复文本渲染
难点在于 Tool Calling 和流式输出的交错——LLM 可能在回复到一半时决定调用工具,前端需要正确处理"回复一半 → 暂停 → 工具调用动画 → 继续回复"的状态转换。
7. 安全设计
6 个依赖意味着攻击面更小——依赖越少,供应链风险越低。
内置防护:CSRF 保护、速率限制、Token 撤销、输入校验。详见安全与隐私文档。
与主流方案的对比
| 虾饺 | Dify | Coze | FastGPT | |
|---|---|---|---|---|
| 启动方式 | npm start |
docker compose up |
注册 SaaS | docker compose up |
| 外部依赖 | 无 PG / Redis / 向量库 | PostgreSQL + Redis + Weaviate | — | MongoDB + MySQL |
| npm 依赖数 | 6 | 100+ | — | 80+ |
| 安装依赖 | 6 个包 | Docker 多服务 | — | Docker 多服务 |
| 多 Agent 群聊 | ✅ | ❌ | ❌ | ❌ |
| Agent 间协作 | ✅ 协作链 + 可视化(已交付) | 工作流引擎 | Bot 编排 | ❌ |
| Agent 持久记忆 | ✅ 三分类 | ❌ | 变量 | ❌ |
| Tool Calling | ✅ 7 内置 + HTTP/JS/MCP 扩展 | ✅ | ✅ 100+ | ✅ |
| RAG 知识库 | ✅ BM25+向量+LLM重排 | ✅ | ✅ | ✅ |
| 前端 | Vanilla JS(零构建) | React | — | Next.js |
公平地说:Dify 的工作流编排能力、Coze 的插件生态、FastGPT 的企业功能,都是虾饺目前没有的。虾饺的优势是另一条路:极简部署 + IM 式多 Agent 团队协作。
快速开始
# 环境要求:Node.js >= 22
git clone https://github.com/moziio/xiajiao.git
cd xiajiao && npm install # 6 个依赖,几秒钟
npm start # 启动
浏览器打开 http://localhost:18800,默认密码 admin。
进入"设置 → 模型管理"添加你的 API Key,就可以开始和 Agent 聊天了。
支持 OpenAI / Claude / 通义千问 / GLM / Kimi / MiniMax / DeepSeek / Ollama 等所有 OpenAI 兼容 API。
内置 5 个开箱即用的 Agent:虾饺管家 🤖、小说家 ✍️、编辑 📝、翻译官 🌐、代码助手 💻。
技术栈总结
| 层 | 技术 | 选择理由 |
|---|---|---|
| 运行时 | Node.js 22+ | 原生 node:sqlite,零 native addon |
| HTTP | node:http |
零框架开销,完全可控 |
| WebSocket | ws |
实时双向通信,流式输出 |
| 数据库 | SQLite (WAL + FTS5) | 一个 .db 文件搞定一切 |
| 前端 | Vanilla JS + CSS | 零构建,fork 后改完刷新即生效 |
| 依赖 | 6 个 | 标准库优先原则 |
| 测试 | 53 个单元测试 | node:test,零测试依赖 |
端到端数据流见前文「一条消息的完整旅程」。
开发过程中踩的坑
分享几个开发中遇到的真实问题,可能对想做类似项目的同学有帮助:
1. 并发 Agent 消息覆盖
早期版本用 channelId 作为 active run 的 key。当群组中同时 @mention 两个 Agent 时,后调用的 Agent 会覆盖前一个的 activeRun,导致消息丢失。修复方案是用 ${channelId}:${runId} 作为复合 key。
2. embedding 去重阈值选择
记忆去重需要选择合适的相似度阈值——太严格会存入重复信息,太松会误合并不同含义的记忆。代码中使用 0.85 作为阈值(DEDUP_THRESHOLD),在准确率和召回率之间取得平衡。
3. SQLite WAL 模式下的并发
SQLite 默认的日志模式在并发写入时会锁表。切换到 WAL(Write-Ahead Logging)模式后,读写可以并发,性能提升明显。但需要注意:WAL 模式下 .db-wal 和 .db-shm 文件也需要备份。
4. 流式输出与 Tool Calling 的交错
LLM 流式回复时可能在中间插入 tool_call。需要正确处理"回复一半 → 停下来 → 调用工具 → 工具结果回来 → 继续回复"的状态机,前端也要同步显示这个过程。
5. SOUL.md:没有「解析器」,只有整文件进 System
server/services/llm.js 里对 SOUL 的处理非常直白:readFileSync(..., 'utf8') 读整份 SOUL.md,再与固定的 MERMAID_GUIDE 拼接成 system 消息——没有 frontmatter 解析、没有按章节裁剪。结果是:
- 文件缺失、空文件或仅空白:
soulContent为假值时只会注入MERMAID_GUIDE,Agent 行为会「飘」;排查「为什么人设没生效」时,先确认SOUL.md是否可读、workspace 路径是否指错。 - 与 RAG 的边界:
rag.js里SKIP_FILES包含SOUL.md(以及IDENTITY.md等),避免把「人设」当知识库文档做向量检索;若用户把长技术说明全塞进 SOUL,既占 context 又不会进 RAG——文档应放在同目录其它.md里。
6. RRF 融合里 k 取 60 不是拍脑袋
_rrfFusion(..., k = 60)(server/services/rag.js)对向量路、BM25 路分别算 1/(k+rank+1) 再相加。k 越大,排名靠后的文档对总分贡献越平滑;调小时两路排序差异稍大,Top-N 候选就会抖动(同一条 query 多跑几次,融合顺序变来变去)。实践里对齐文献与检索社区常用取值后固定在 60,再靠后面的 LLM 重排和分块策略稳住最终上下文;若你自建 RAG,建议在固定评测集上对比 k∈{20,60,100} 的 nDCG / 人工体感,而不是只改公式不验收。
文档资源
写了一套完整的文档站,用 VitePress 构建,覆盖从入门到深度开发的所有内容:
入门指南:
进阶教程:
- SOUL.md 写作指南 — 如何写出高质量的 Agent 人格设定,含调试技巧和真实迭代案例
- SOUL.md 模板库 — 20 个可直接复制的 Agent 人格模板(全栈工程师/代码审查/文案策划/数据分析师等)
- 12 个实战案例 — 可直接照搬的 Agent 团队配置方案,包含完整 SOUL.md、对话示例、进阶技巧
- 架构设计 — 代码结构、数据流、关键模块走读(HTTP 路由/WebSocket 流式/记忆系统/RAG 管线)
功能详解:
- 多 Agent 群聊 — @mention 路由、Agent 间通信
- Tool Calling — 7 个工具逐一解析
- Agent 持久记忆 — 三分类记忆的完整架构
- RAG 知识库 — 三阶段检索管线详解
运维与安全:
- 安全与隐私 — 数据主权、API Key 保护、攻击面分析
- 平台对比 — 虾饺 vs Dify vs Coze vs FastGPT 详细对比
- 性能调优 — LLM 响应优化、SQLite 调优、生产环境配置
- 故障排查 — 按症状组织的完整排查指南
- API 参考 — HTTP API + WebSocket 协议 + 数据库表结构
开发者:
v1.1.0 更新(2026-03-24)
v1.0.0 发布后一周,虾饺迎来了 v1.1.0,核心更新三块:
1. HTTP 自定义工具引擎(零代码扩展)
痛点:想让 Agent 调用公司内部 API(JIRA、GitLab、监控系统等),但写代码太重。
方案:在「设置 → HTTP 工具」中填写 URL、Method、Headers、Body 模板,支持 {{param}} 参数插值和 responseExtract 结果提取,保存即可用——零代码、不用重启。
{
"name": "jira_get_issue",
"url": "https://your-jira.com/rest/api/3/issue/{{issueKey}}",
"method": "GET",
"headers": { "Authorization": "Basic {{token}}" },
"parameters": [
{ "name": "issueKey", "type": "string", "required": true }
],
"responseExtract": "fields.summary,fields.status.name"
}
配合 工具自动注册架构(toolRegistry.autoRegisterTools()),现在虾饺的工具扩展有三条路:
| 方式 | 门槛 | 适用场景 |
|---|---|---|
| HTTP 自定义工具 | 零代码 | REST API 对接 |
JS 文件放入 data/custom-tools/ |
写 JS | 需要复杂逻辑的自定义工具 |
| MCP 桥接 | 配置 | 已有 MCP Server 的外部服务 |
2. Dockerfile 优化
- 基础镜像:
node:22-alpine→node:22-slim(更好的 glibc 兼容性) - COPY 策略:
COPY . .→ 精确 COPY(只拷贝server/、public/、模板、预设、配置) - 构建默认:
NODE_ENV=production,单 Volume/app/data - 结果:更小、更安全、构建缓存更友好的镜像
3. Channel 修复
- 修复频道配置变更时 session 的
agent_id未同步问题 - 前端在频道增删改后自动刷新外部频道映射表
Roadmap
下面不是「功能列表」,而是接下来要把这条技术路线推到哪——欢迎 Star / Issue 里拍砖优先级。
| 方向 | 状态 | 你值得期待什么 |
|---|---|---|
| 渠道打通 | 🚧 开发中 | 飞书 / 钉钉 / 企微 / Telegram:同一套 Agent 与协作链,从浏览器延伸到真实工作流里 |
| 单机 → 可扩展 | 📋 已规划 | 多进程、外置会话状态:在不推翻当前 SQLite 心智的前提下,给「要多实例」留演进缝 |
| 桌面与离线体验 | 📋 已规划 | Electron:把「6 依赖 + 一个文件夹」装进口袋,本地优先、可控性更强 |
| 工具扩展 | ✅ v1.1.0 已交付 | HTTP 零代码工具 + JS 自动注册 + MCP 桥接——Tool Calling 已从 7 个内置走向「可组合」 |
| Agent Store | 💭 探索中 | 高质量 SOUL / 协作链模板一键导入,降低「搭团队」成本 |
| 多模态 | 💭 探索中 | 语音、图片理解:IM 场景里「说完即发」的自然延伸 |
| Agent 协商层 | 💭 探索中 | 多 Agent 结构化讨论与决策——从接力执行升级到「开会」 |
P1–P4(IM、协作链、Tool Calling、RAG、三分类记忆、安全、PWA)已落地;v1.1.0 交付了工具扩展体系(HTTP/JS/MCP)和 Docker 优化;当前主战场是渠道打通,其余按需求与贡献度迭代。
写在最后
虾饺(Xiajiao)取名自广式点心——小巧精致,内料丰富。
这是一个人的项目,但我相信"把 AI Agent 当团队管理"这个方向值得探索。如果你也觉得有意思:
- ⭐ Star: https://github.com/moziio/xiajiao
- 📖 文档站: https://moziio.github.io/xiajiao/
- 🐛 Issue: Bug 反馈或功能建议
- 💬 Discussions: 聊聊 Agent 协作的想法
- 🤝 PR: 欢迎贡献代码
MIT 协议,随便用,随便改。
如果觉得这篇文章有帮助,欢迎点个赞 👍,也欢迎在评论区交流你对 AI Agent 协作的想法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)