具身智能中的传感器技术9——感知技术概述3
·
环境感知:
摘要:
具身智能与自动驾驶在环境感知技术上存在显著差异。自动驾驶关注远距离目标(如卡车、车道线),而具身智能聚焦近距离物体(如杯子、剪刀),需精确感知物体的位置和可操作性。核心传感器包括:
- RGB-D相机:提供高精度深度信息(毫米级),支持手眼协调,是VLA大模型的关键输入;
- 激光雷达:用于导航和避障,需超大视场角(360°×90°)以应对复杂环境;
- 事件相机:通过异步触发捕捉高速运动,解决传统相机的动态模糊问题;
- 麦克风阵列:实现声源定位和波束成形,增强人机交互与异常检测能力。
这些技术共同构建机器人的多模态感知系统,使其适应精细操作与动态场景需求。

虽然具身智能与自动驾驶共享了大部分感知技术栈(如 SLAM、目标检测),但应用场景的差异决定了两者关注点截然不同:自动驾驶关注**“百米外的卡车和车道线”(为了活着),具身智能关注“半米内的杯子和剪刀”**(为了干活)。
环境感知 (Exteroception) —— 机器人的“眼睛”与“耳朵”
这一系统负责构建机器人对外部世界的 3D 语义理解。它不仅要回答“前面有什么”,还要回答“它离我的手有多远”、“我能不能捏住它”。
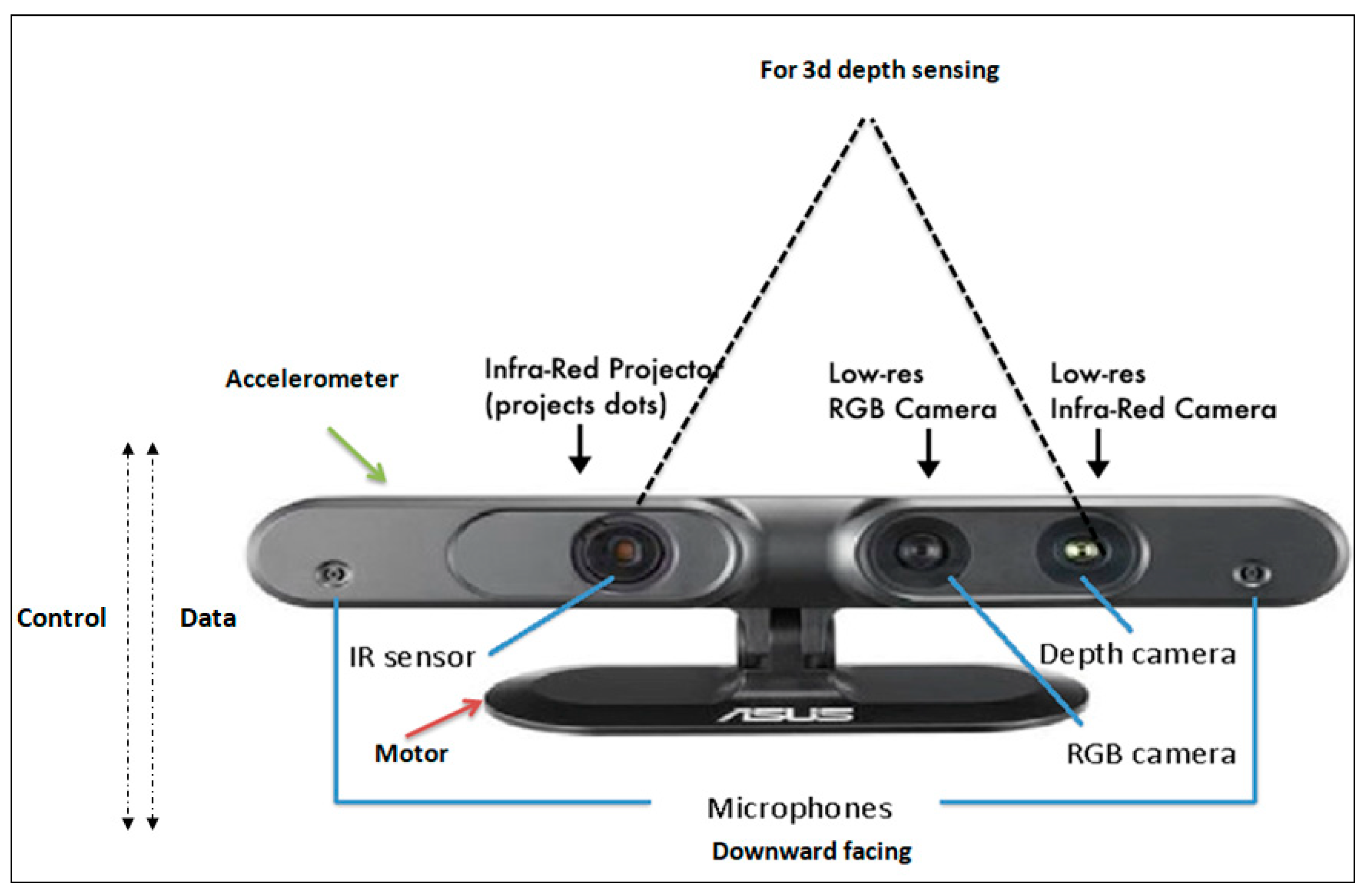
1. RGB-D 相机 (深度相机) —— 机器人的“立体视觉”
这是具身智能最不可或缺的核心传感器,地位远高于自动驾驶中的单目/双目相机。
- 技术原理 (Depth 的来源):
- 结构光 (Structured Light): 发射特定的红外散斑图案,根据图案变形计算距离。精度极高(毫米级),适合近距离精细操作(如穿针引线、抓药丸),代表作:Realsense D435, Orbbec Astra。
- ToF (Time of Flight): 发射光脉冲并测量反射回来的时间。抗强光能力强,适合中远距离感知,代表作:Azure Kinect。
- 主动双目 (Active Stereo): 双摄 + 红外投影辅助。兼顾了室外强光和室内弱纹理场景。
- 关键差异 (vs 自动驾驶):
- 近距盲区小: 车载相机看清 1米外就行,机器人必须看清 10cm - 50cm 的工作台面。
- 稠密点云: 机器人需要物体表面的高致密深度信息来计算抓取点(Grasp Pose),而不是像车那样只看个大概轮廓。
- 具身智能价值:
- 手眼协调 (Hand-Eye Coordination): 它是 VLA 大模型最重要的输入源。RGB 图告诉 AI “这是苹果”,Depth 图告诉控制算法“苹果中心坐标是 (0.3m, 0.1m, 0.5m)”。
2. 激光雷达 (LiDAR) —— 机器人的“空间扫描仪”
虽然在视觉大模型(VLM)兴起的当下,雷达地位略有下降,但在**导航(Navigation)**层面依然是“定海神针”。
- 技术形态:
- 单线/2D 雷达: 仅扫描一个平面,用于构建 2D 栅格地图。成本低,扫地机器人标配。
- 3D 半固态/机械雷达: 扫描三维空间。人形机器人通常使用轻量化的小型 3D 雷达(如 Livox Mid-360, Unitree 4D LiDAR)。
- 关键差异 (vs 自动驾驶):
- 视场角 (FOV) 极大: 车载雷达主要看前方 120°,机器人雷达通常需要 360° x 90° 的超大覆盖范围,因为机器人需要时刻提防脚下的台阶和头顶的吊灯。
- 测距要求低: 机器人主要在室内或园区活动,探测 30-50米 足够,不需要车载的 200米+。
- 具身智能价值:
- SLAM 建图: 在陌生环境中快速构建高精度的 3D 点云地图,解决“我在哪”的问题。
- 全向避障: 弥补视觉在暗光或无纹理墙面下的失效风险。
3. 事件相机 (Event Camera / DVS) —— 机器人的“动态视网膜”
这是一种颠覆传统的仿生视觉传感器,它不按“帧”拍照片,而是记录像素亮度的“变化事件”。
- 技术原理:
- 异步触发: 当某个像素点的亮度变化超过阈值时,才输出一个信号 (x, y, t, polarity)。画面静止时,它没有任何输出(数据量极低);物体高速运动时,它能以微秒级的时间分辨率捕捉轨迹。
- 核心作用:
- 极速运动捕捉: 能够捕捉子弹飞行、高速旋转扇叶或乒乓球轨迹,完全没有普通相机的“运动模糊(Motion Blur)”。
- 高动态范围 (HDR): 在隧道出口或强光直射下,普通相机会过曝“瞎掉”,事件相机依然能看清轮廓。
- 具身智能价值:
- 高动态交互: 比如机器人打乒乓球、接住飞来的物体,或者在极度颠簸中保持视觉锁定。这是传统 RGB 相机(30fps/60fps)无法做到的。
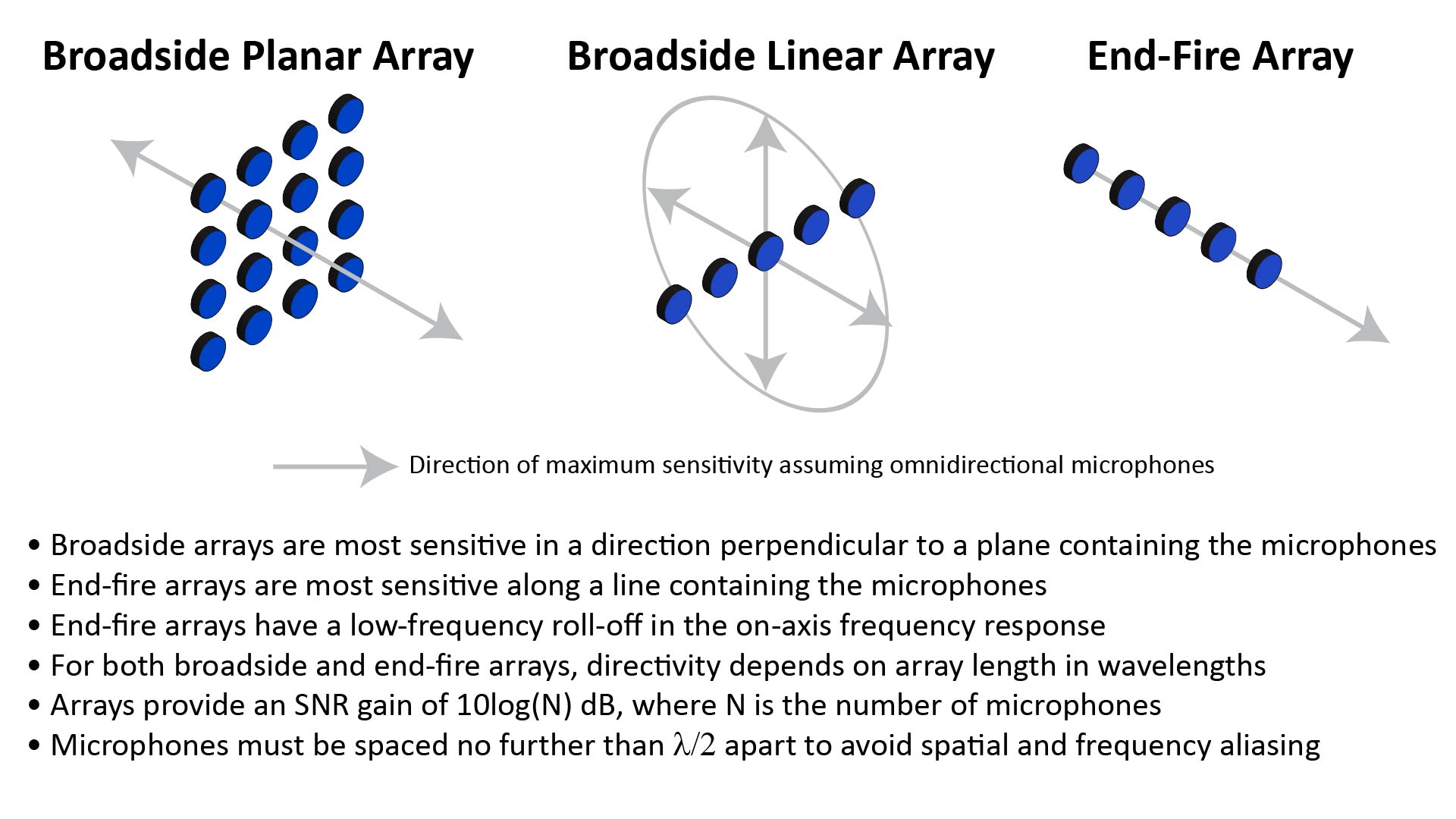

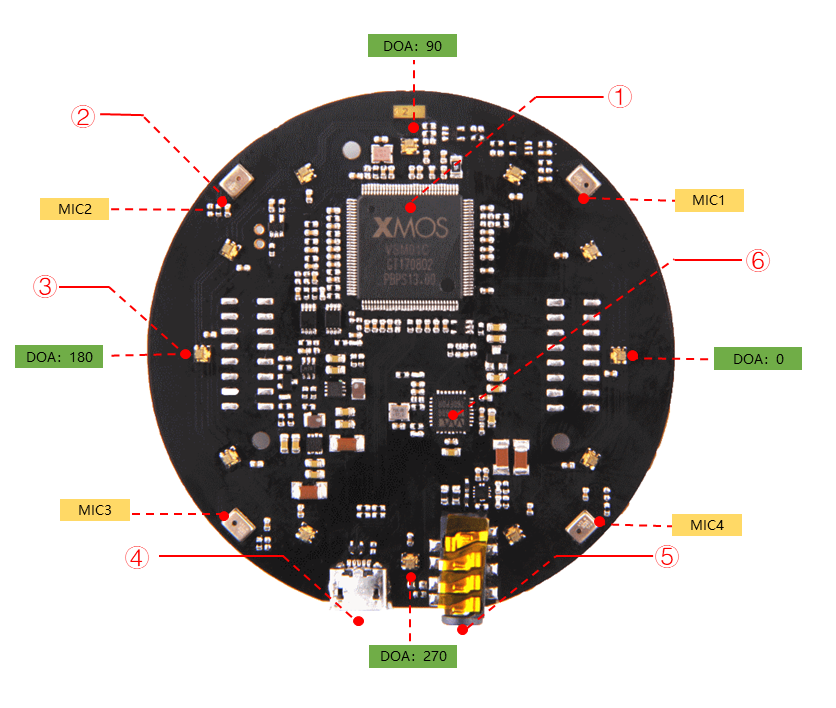
4. 麦克风阵列 (Mic Array) —— 机器人的“听觉中枢”
听觉不仅是交互的入口,也是感知的补充。
- 技术形态:
- 环形/线性阵列: 通常在机器人头顶布置 4-8 个麦克风。
- 核心算法:
- 声源定位 (SSL): 利用声音到达不同麦克风的时间差(TDOA),计算出声源的角度(Azimuth)和俯仰角(Elevation)。精度可达 ±5°。
- 波束成形 (Beamforming): 像手电筒一样,定向增强某个方向的声音(如主人的说话声),抑制其他方向的噪音(如电视声、电机转动声)。
- 具身智能价值:
- 自然交互: 当你喊“嘿,机器人”,它能利用声源定位立刻转头面向你,这是建立人机信任感的第一步。
- 异常检测: 听到玻璃破碎声、婴儿哭声或重物倒地声,触发安防警报。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)