大模型应用开发Dify 安装、使用(小白超详细所用功能2026)
一、Dify 是什么?
Dify 是一款开源的大模型应用开发 / 运营平台(LLMOps),零代码 / 低代码快速搭建企业级 AI 应用,支持对话机器人、RAG 知识库、工作流、智能 Agent 等场景,开箱即用。
核心优势
- 全场景覆盖:支持对话助手、RAG 检索增强、多模态、工作流、智能体
- 兼容几乎所有大模型:OpenAI、DeepSeek、通义千问、文心一言、Gemini、本地模型等
- 可视化搭建:无需写代码,拖拽配置即可完成应用开发
- 自带知识库:支持文档上传、自动切片、向量检索
- 可私有化部署:数据完全可控,适合企业 / 个人本地使用
- 免费开源:MIT 协议,可商用、可二次开发

二、dify安装
2.1、系统要求

2.2、安装要求(Docker)
Dify依赖Docker环境运行,若尚未安装Docker请参考:
Windows 下 Docker Desktop 安装教程及常用命令(2026 最新)-CSDN博客
Linux 下 Docker 安装教程(2026)-CSDN博客
2.3、源码下载
langgenius/dify: Production-ready platform for agentic workflow development.
https://github.com/langgenius/dify.git
源码结构:
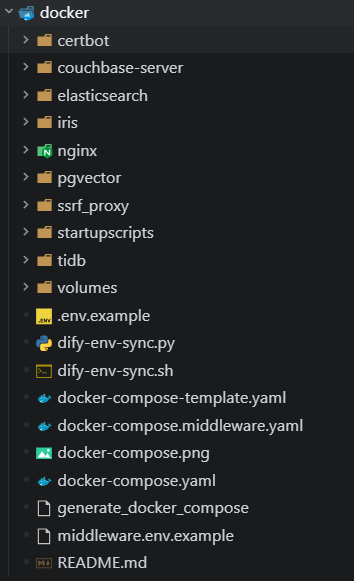
启动 Dify 服务器的最简单方法是运行我们的 docker-compose.yml 文件。在运行安装命令之前,请确保您的机器上安装了 Docker 和 Docker Compose:
https://github.com/langgenius/dify.git #下载源码
cd docker #进入docker相关目录
cp .env.example .env #复制.env.example并重命名为.env,但win下得手动
docker compose up -d #执行docker命令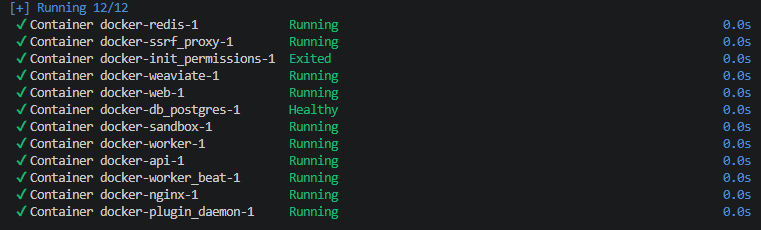
运行后,你可以在 http://localhost/install 时访问浏览器中的Dify仪表盘,开始初始化过程。
2.4、常见错误
2.4.1、换源问题
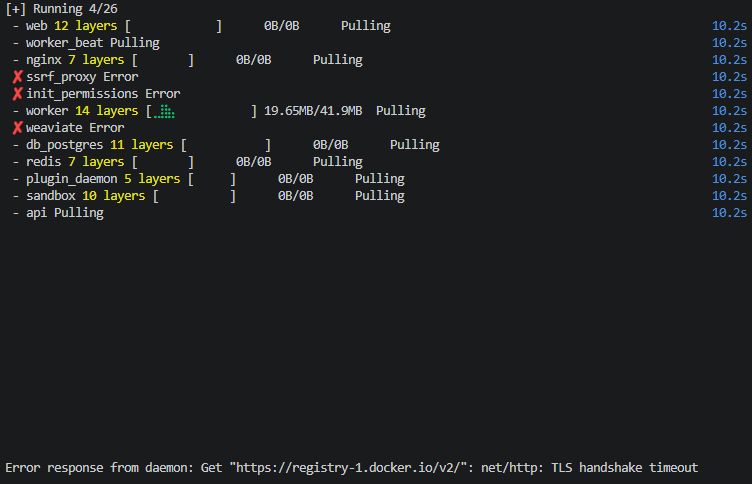
这是 Docker Hub 访问超时的问题,在中国大陆非常常见。需要配置 Docker 镜像加速器 来解决。
- 添加国内镜像(Settings → Docker Engine):
-
{ "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": false, "registry-mirrors": [ "https://docker.1panelproxy.com", "https://docker.m.daocloud.io", "https://docker.registry.cyou", "https://docker.jsdelivr.fyi", "https://docker.m.daocloud.io", "https://docker.nju.edu.cn", "https://docker.mirrors.sjtug.sjtu.edu.cn", "https://docker.mirrors.ustc.edu.cn", "https://docker.rainbond.cc", "https://dockerhub.icu", "https://docker-cf.registry.cyou", "https://dockercf.jsdelivr.fyi", "https://dockertest.jsdelivr.fyi", "https://dockerproxy.com", "https://mirror.baidubce.com", "https://mirror.iscas.ac.cn", "https://mirror.aliyuncs.com", "https://hub-mirror.c.163.com", "https://your_preferred_mirror", "https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com" ] }
2.4.2、目录共享权限问题
Error response from daemon: user declined directory sharing E:\PROJECT\dify-main\docker\volumes\db\data
这是一个 Docker Desktop 的目录共享权限问题。Docker 尝试挂载 E:\PROJECT\dify-main\docker\volumes\db\data 目录作为卷,但权限被拒绝了。
解决方法
方法一:通过 Docker Desktop 设置
1. 打开 Docker Desktop
2. 点击右上角的 设置图标(齿轮)
3. 进入 Resources → File Sharing
4. 添加以下路径之一:
- E:\PROJECT\dify-main (推荐,允许整个项目)
- 或 E:\ (允许整个 E 盘)
5. 点击 Apply & Restart
方法二:重置文件共享权限
如果上述方法不起作用,可以尝试:
1. 在 Docker Desktop 设置中,先移除 E:\ 相关的共享路径
2. 点击 Apply
3. 重新添加 E:\PROJECT\dify-main
4. 再次 Apply & Restart
2.4.3、Skipped: optional depende...
! Container docker-db_postgres-1 Skipped: optional depende...
解决办法:
1.打开docker文件夹下的docker-compose.yml
2.修改db_postgres: --> volumes:内容,将原内容修改为:
- postgres_data:/var/lib/postgresql/data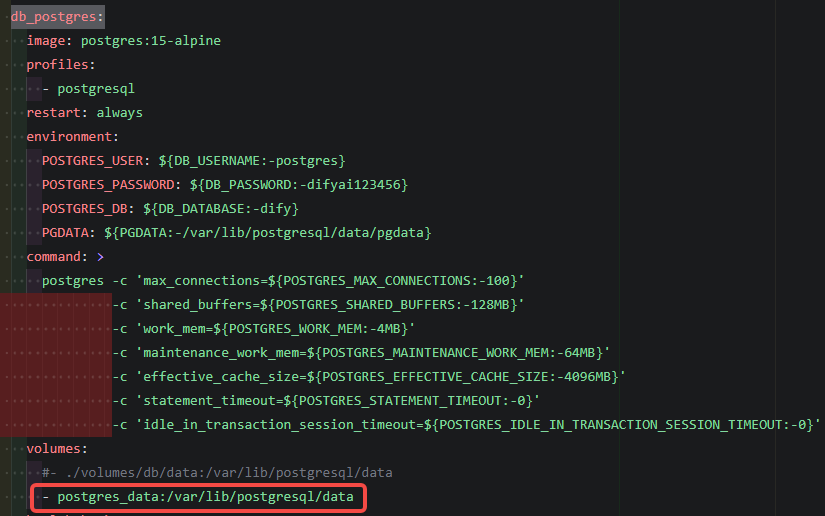
3.找到最后volumes:,添加卷内容:
postgres_data: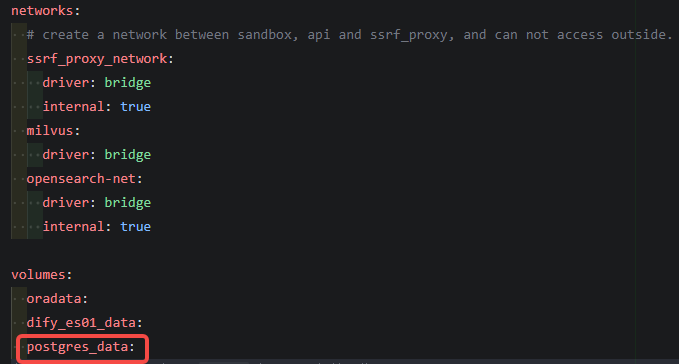
4. 停止所有容器
docker compose down5. 重新启动
docker compose up -d6. 查看状态
docker compose ps2.5、配置登录
docker compose up -d命令执行完后,在本地浏览器访问 http://localhost/install,进入Dify初始化配置界面:
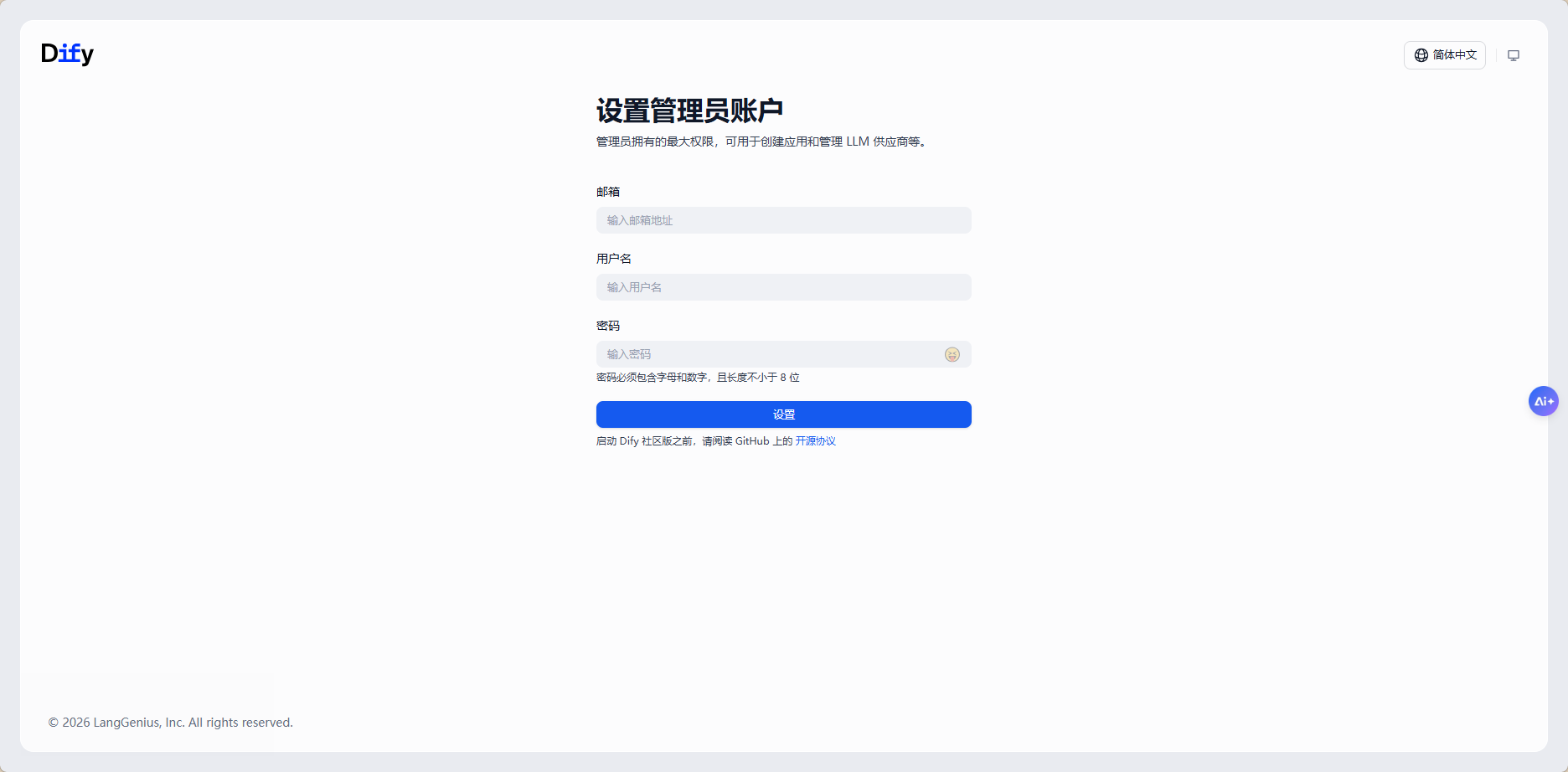
登录后进入工作台:
三、Ollama
Dify原生支持Ollama、Xinference等主流推理框架,按需选择即可,这边我使用Ollama。如果没安装可参考下方链接:
参考链接:
ollama安装、部署模型、命令、环境变量(ubuntu + windows)_ubuntu ollama安装教程-CSDN博客
四、Dify使用Ollama
安装完Dify后需要将Dify和Ollama关联,让Dify通过Docker能访问Ollama 的服务。
在Dify项目-->docker-->.env文件,在末尾加上下面的配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定 Ollama 的 API地址(根据部署环境调整IP)
OLLAMA_API_BASE_URL=host.docker.internal:11434工作台--->点击头像--->设置
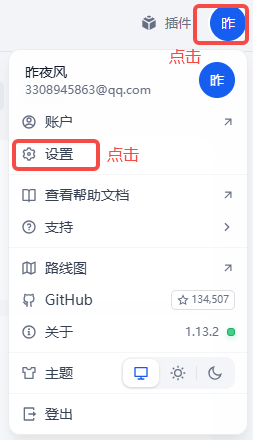
模型供应商--->Ollama--->安装
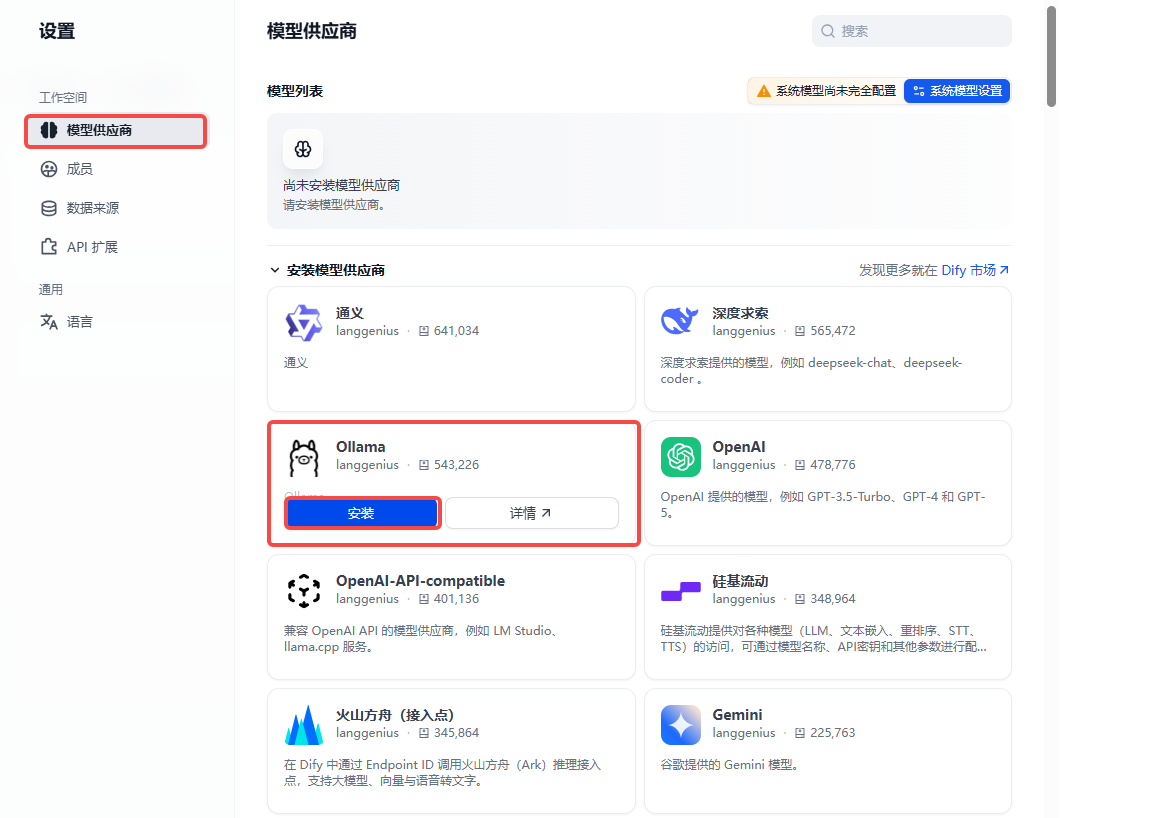
待配置--->Ollama--->添加模型
填写相关信息:
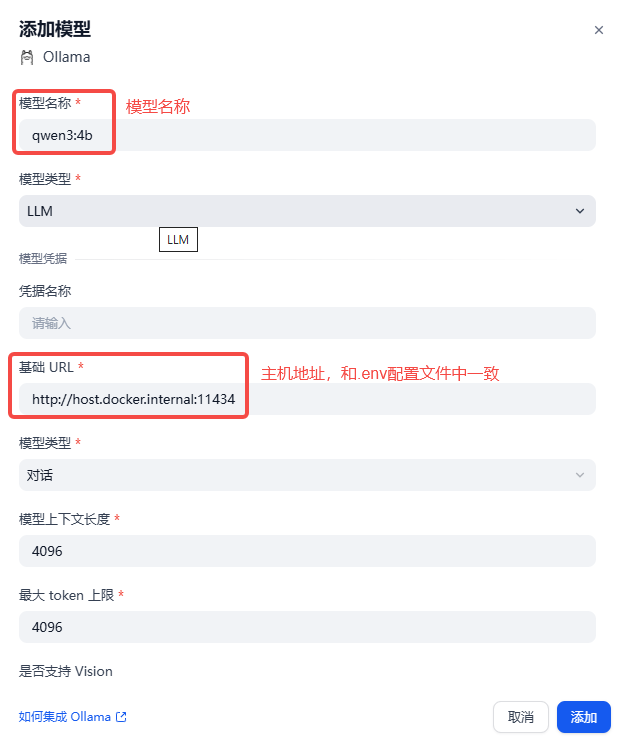
添加完:

五、Dify应用
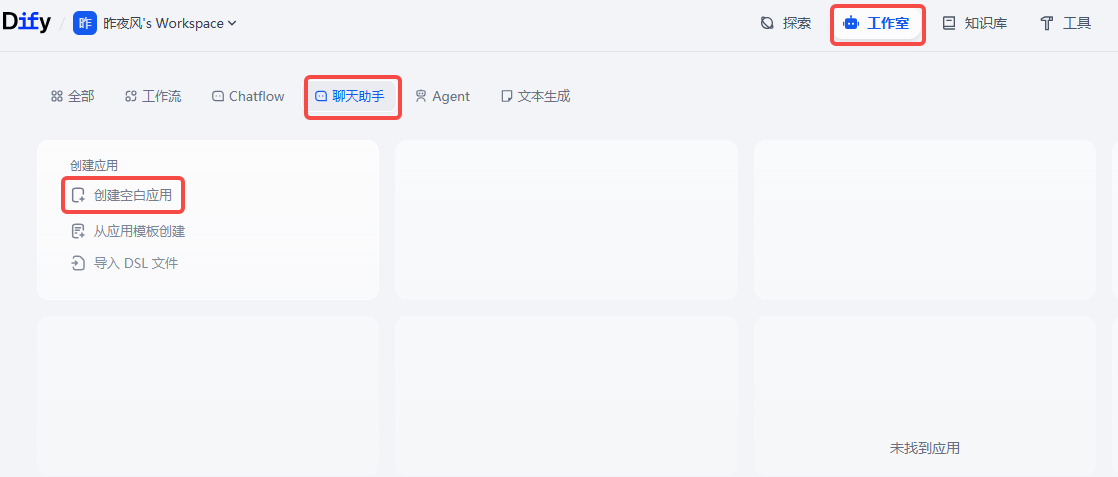
5.1、聊天助手
工作室--->聊天助手--->创建空白应用
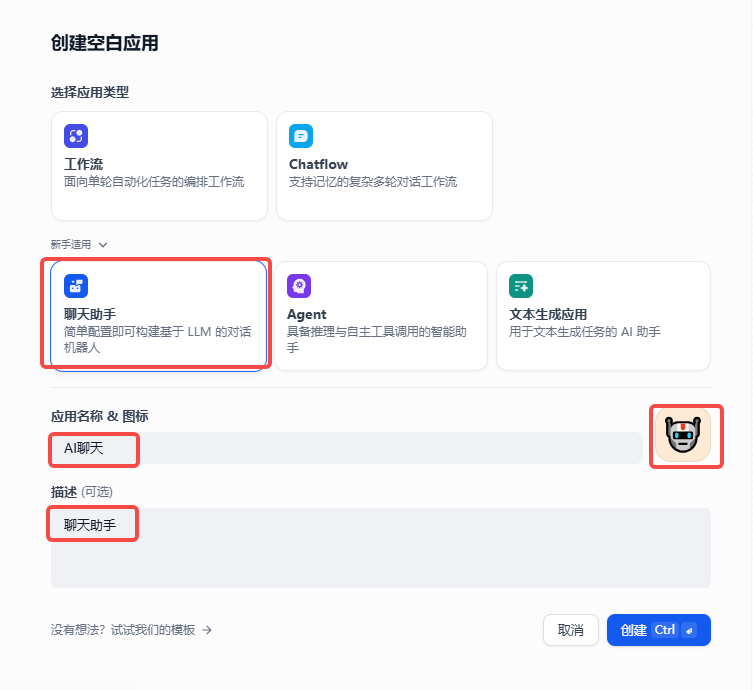
聊天助手--->应用名称--->图标--->描述
原始聊天助手:
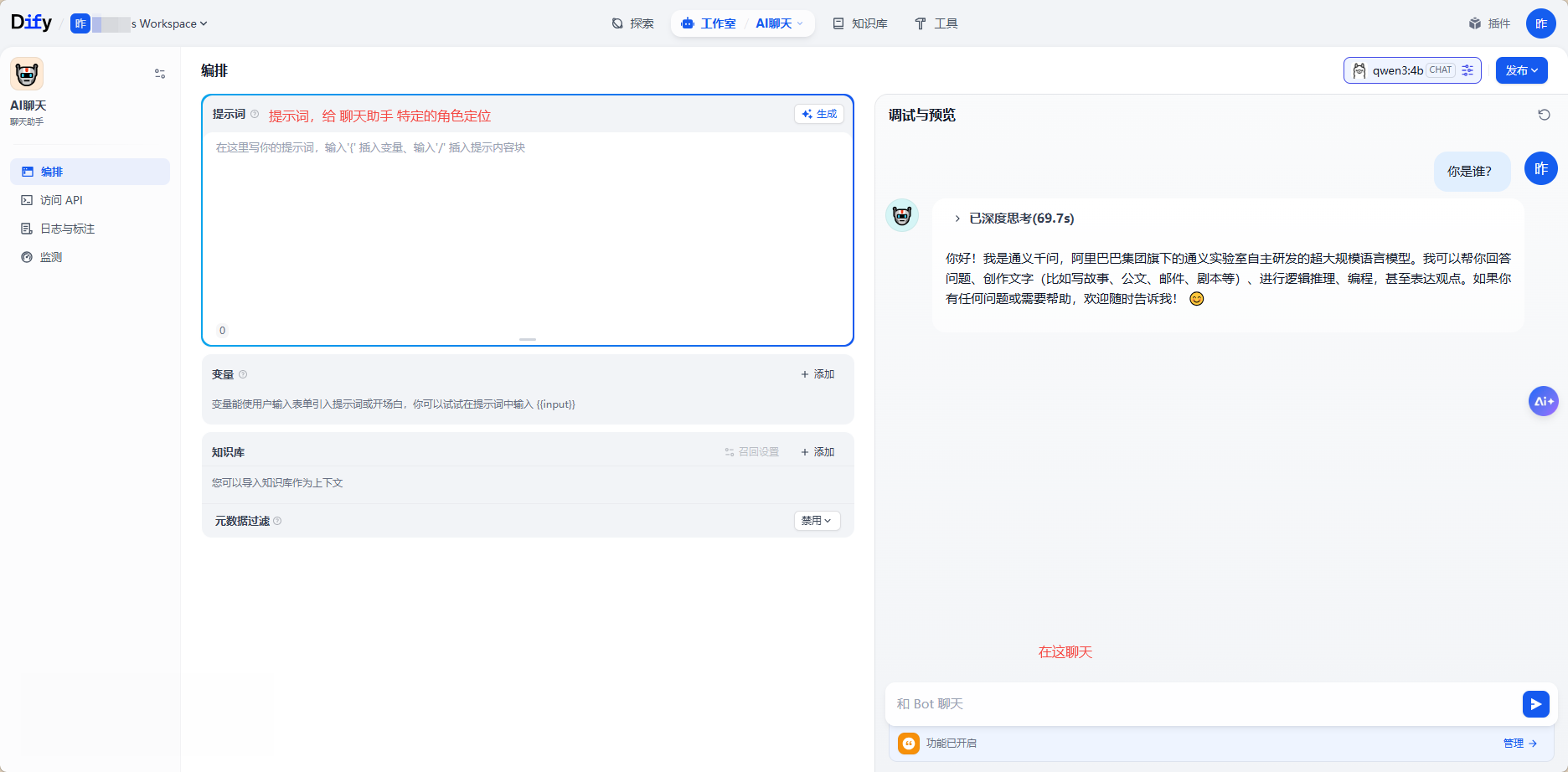
添加提示词和变量聊天助手:
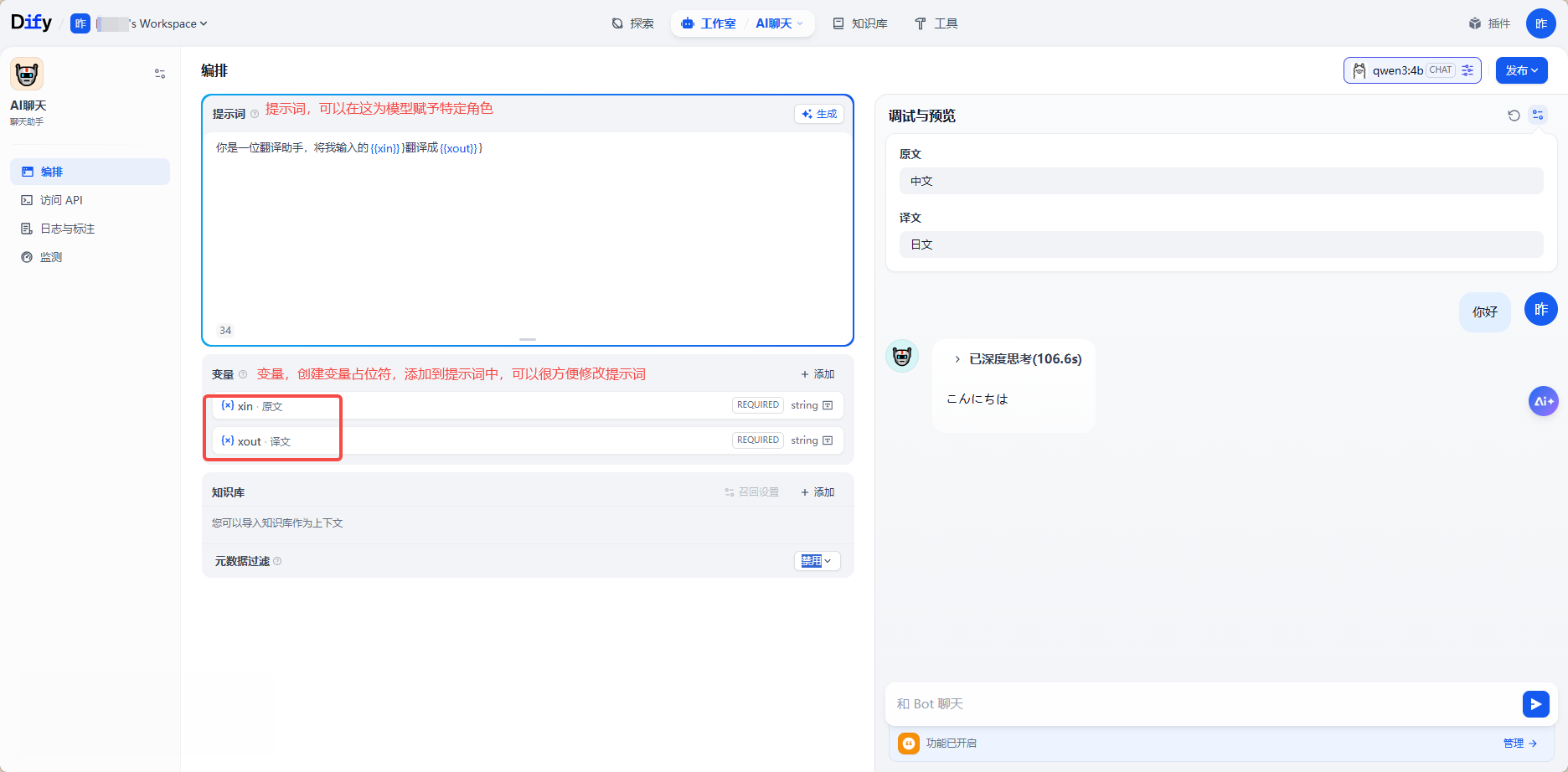
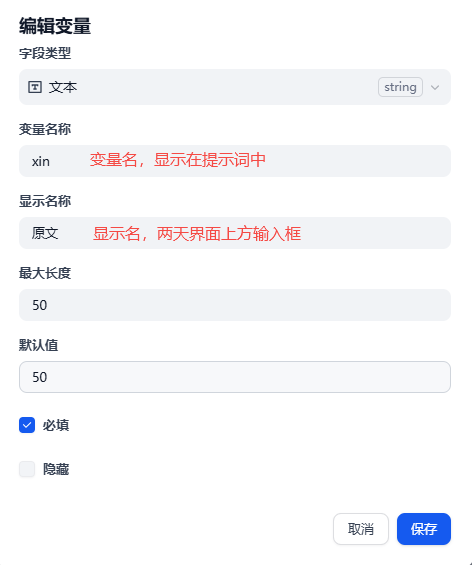
5.1.1、提示词(Prompt)的作用
提示词 = 给 AI 的 “角色设定 + 行为规则 + 回答要求”你可以把它理解成:你给 AI 写的一份工作说明书。
它的核心作用:
-
定义 AI 身份
- 让 AI 知道自己是谁:客服、老师、顾问、翻译、代码助手、医生助手等
- 例子:
你是一名专业的电商客服,语气友好、简洁、耐心
-
规定回答规则
- 不能说什么
- 必须怎么回答
- 回答长度、格式、语气
- 例子:
只回答与产品相关的问题,不要闲聊,回答不超过3句话
-
绑定业务逻辑
- 让 AI 按你的业务要求回答,而不是自由发挥
- 例子:
如果用户问价格,统一回复:官方统一售价99元
-
控制对话风格
- 正式 / 幽默 / 简洁 / 详细 / 专业 / 口语化
简单总结:
没有提示词 = AI 乱回答有提示词 = AI 按你的要求乖乖回答
5.1.2、变量(Variable)的作用
变量 = 可以动态替换的 “占位符”你可以把它理解成:AI 回答里的 “可填空内容”。
它的核心作用:
-
让提示词可以动态变化不用每次都改提示词,直接传值进去就行。
-
把外部数据传给 AI
- 用户信息
- 商品信息
- 订单信息
- 知识库内容
- 接口返回的数据
-
实现个性化回答同一个提示词,不同变量 → 不同回答。
Dify 里变量的写法:
{{变量名}}
例子:
提示词里写:
你是客服,用户名字是 {{username}},商品是 {{product_name}},价格是 {{price}}。
运行时变量传入:
- username = 小明
- product_name = 无线耳机
- price = 199
AI 看到的就是:
你是客服,用户名字是 小明,商品是 无线耳机,价格是 199。
简单总结:
变量 = 让 AI 能 “读取外部数据” 的通道没有变量 = AI 只能瞎编有变量 = AI 能使用真实业务数据
5.1.3、提示词 + 变量 一起怎么用?(最关键)
它们是搭档关系:
公式:
提示词(规则) + 变量(数据) = 智能回答
真实场景例子(电商客服)
提示词:
你是电商智能助手。
用户姓名:{{user_name}}
当前咨询商品:{{goods_name}}
商品价格:{{goods_price}}
库存:{{stock}}
规则:
1. 只回答商品相关问题
2. 语气友好简洁
3. 库存为0时告诉用户无货
变量自动传入:
- user_name: 张三
- goods_name: iPhone 15
- goods_price: 5999
- stock: 有货
AI 就能:
- 叫出用户名字
- 报真实价格
- 查真实库存
- 按你的规则回答
5.2、知识库
知识库--->创建知识库
动物灭绝表举例:

导入已有文本--->上传--->下一步
设置:
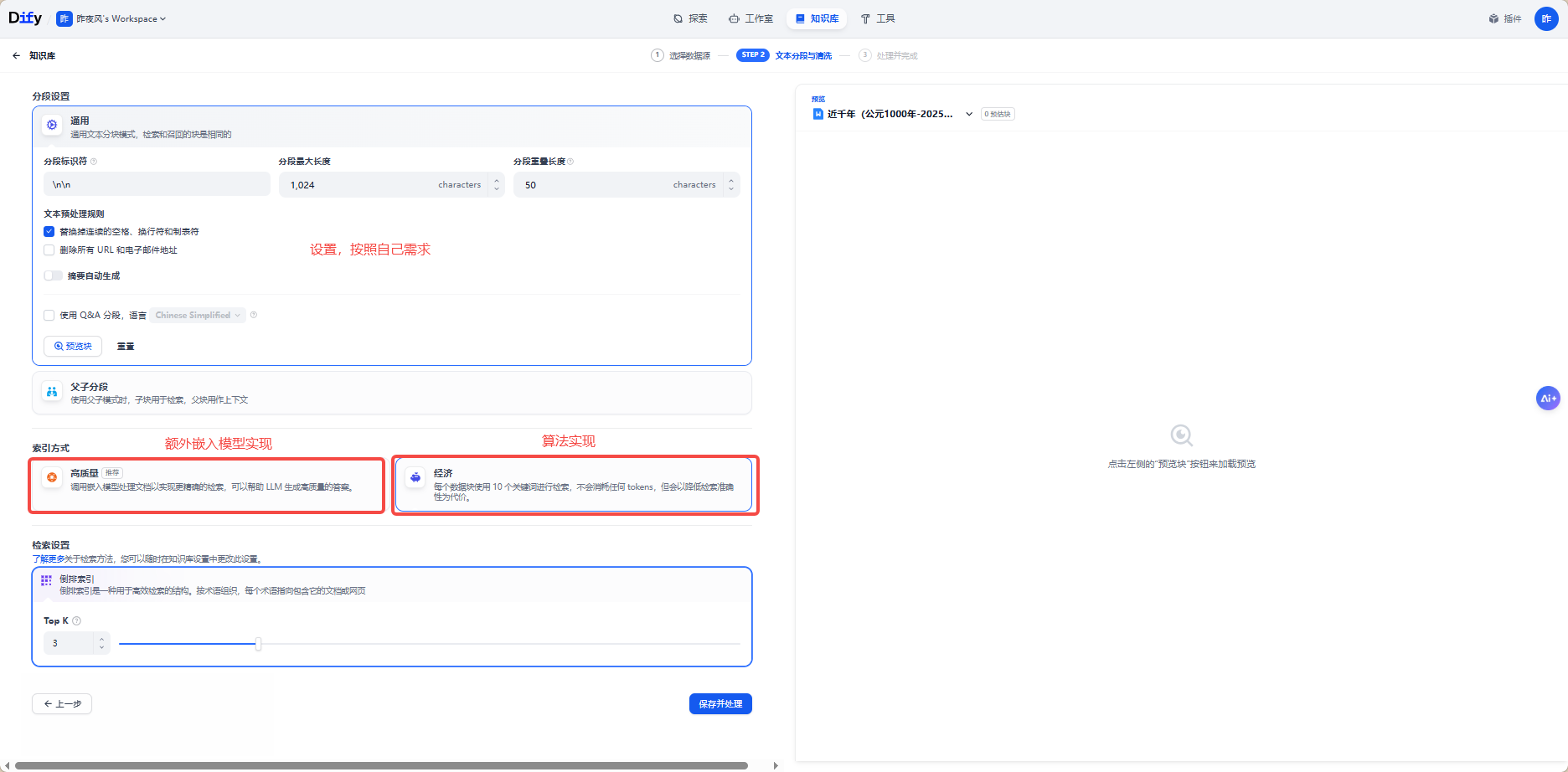
保存--->前往文档
文档中已经启用知识库:
只是空间中也已经创建:
聊天界面--->知识库--->添加
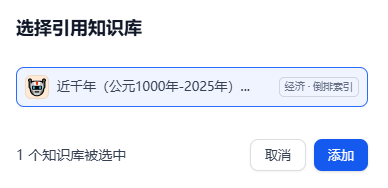
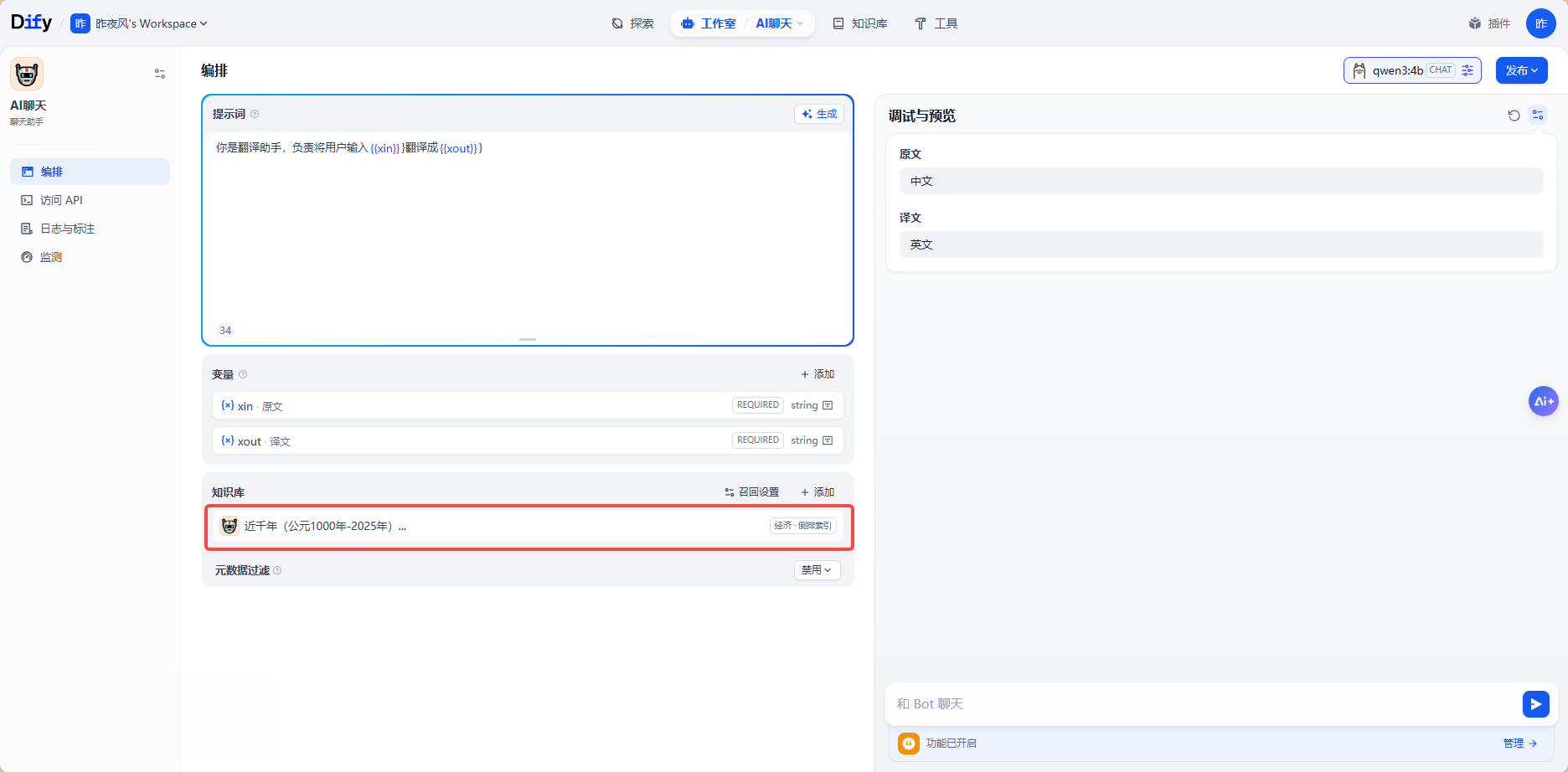
5.2.1、知识库介绍
在 Dify 中,知识库(Knowledge Base) 是基于 RAG(检索增强生成) 技术的核心模块,专门用来解决大模型 “知识过时、不懂专业内容、容易瞎编(幻觉)” 三大痛点。简单说:提示词定规矩,变量传数据,知识库给 “真知识”。
5.2.1.1、知识库的核心作用
把你的私有 / 专业 / 最新文档,变成 AI 能精准引用的 “外部大脑”,让回答基于事实、来源可查、绝不瞎编。
5.2.1.2、详细作用拆解
1. 解决 LLM 三大致命问题
- 信息过时(时效性):模型训练数据截止到过去(如 GPT-4 截止到 2023 年 10 月),无法知道最新政策、价格、新闻。知识库可随时上传 / 更新,新内容立即可用。
- 不懂你的业务(专业性):模型不知道你公司的产品手册、内部规范、售后政策、项目细节。知识库 = 给 AI 灌入你的 “私域知识”。
- 编造事实(幻觉):模型不懂就会瞎编。知识库强制 AI 只基于检索到的原文回答,不知道就说不知道,彻底杜绝幻觉。Dify
2. 自动处理海量文档(一站式 RAG)
- 支持格式:PDF、Word (DOCX)、TXT、Markdown、CSV、Excel、HTML、JSON 等
- 自动处理:上传后自动 提取文本 → 清洗 → 智能分段(Chunk)→ 向量化(Embedding)
- 外部同步:可直接抓取 网页、Notion、在线文档,无需手动下载
3. 精准语义检索(不是简单关键词)
Dify 提供两种核心索引模式:
- 高质量模式(推荐)
- 用 AI 嵌入模型将文字转为语义向量
- 支持:向量搜索(语义匹配)、全文搜索、混合搜索
- 效果:用户问 “手机耐摔吗”,能召回 “产品采用康宁大猩猩玻璃,抗跌落等级...”
- 经济模式
- 仅关键词倒排索引,不消耗 Token,但只能精准匹配关键词
4. 与提示词 / 变量联动(黄金组合)
提示词(规则) + 变量(动态数据) + 知识库(事实依据) = 专业可控回答
5.3、文本生成应用
工作室--->文本生成--->创建空白应用
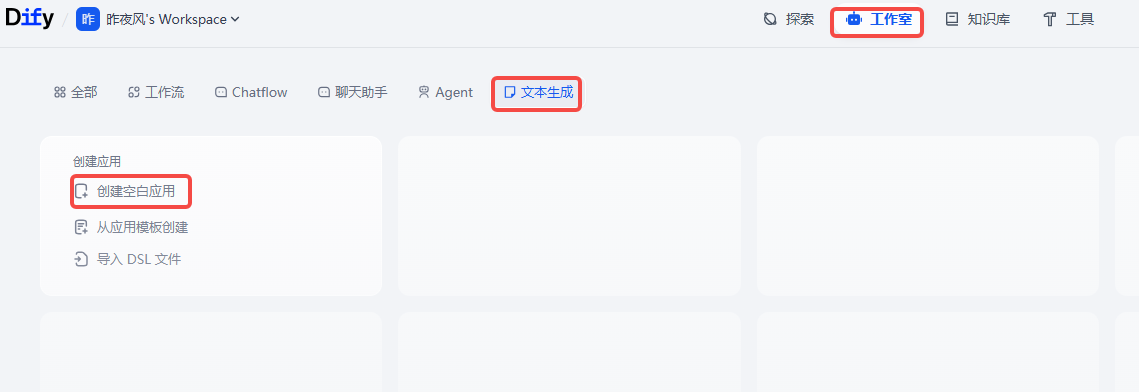
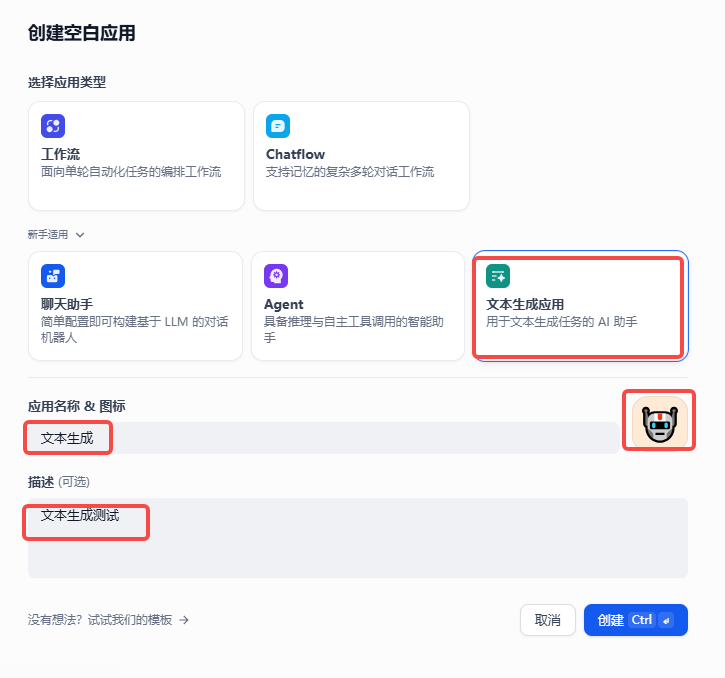
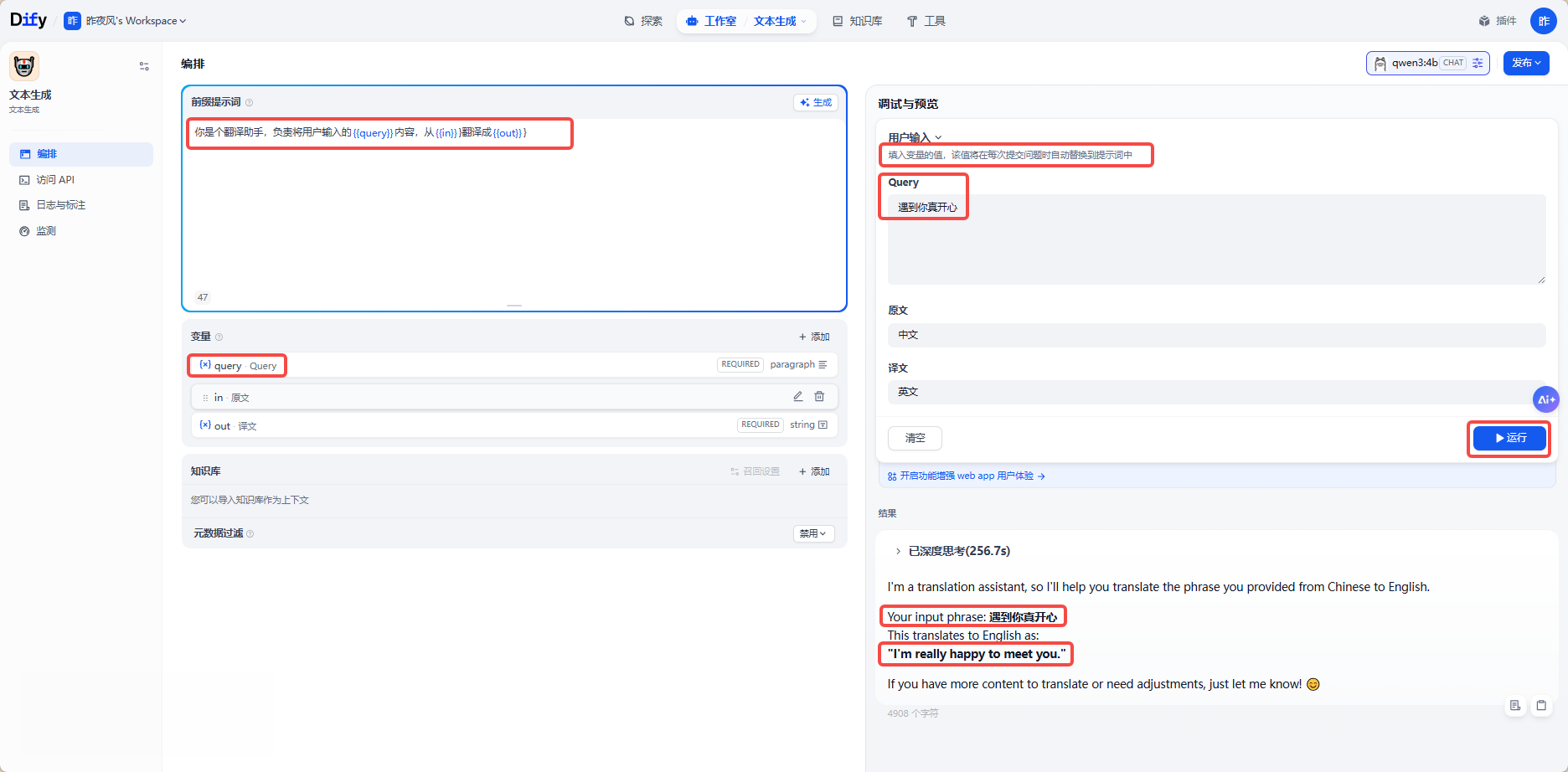
5.3、文本生成介绍
Dify 文本生成(Text Generator) 是一种一次性、单向、无对话记忆的 AI 文本自动化工具,核心作用是:按固定规则与模板,快速 / 批量生成标准化、高质量、可落地的文本内容。它和聊天助手的区别:聊天是多轮对话,文本生成是 “一次输入、一次输出”。
5.3.1、核心定位与本质
- 定位:AI 自动化文本生产流水线
- 本质:提示词模板 + 变量 + 知识库 → 结构化 / 标准化输出
- 特点:
- 单向执行:无多轮对话、无历史记忆
- 任务独立:每次请求都是全新任务
- 强规则:严格按预设格式、风格、长度生成Dify
5.3.2、文本生成的 6 大核心作用
1. 高效批量内容生产(最核心价值)
- 单条 / 批量双模式:支持单次生成,也可上传 CSV 批量生成Dify
- 场景:
- 电商:5 分钟生成 100 篇商品 SEO 文案
- 自媒体:批量生成公众号 / 小红书 / 短视频脚本
- 跨境:多语言产品描述、广告文案本地化
- 效率:比人工快 10–100 倍,一致性强、无重复
2. 结构化 / 标准化文本自动生成
- 按固定格式输出:
- 报告、周报、简历、合同条款
- 新闻通稿、活动通知、邮件模板
- 技术文档、API 说明、测试用例
- 优势:格式统一、术语规范、零排版错误
3. 专业文本加工(提炼 / 翻译 / 润色)
- 摘要总结:长文→要点、论文→核心、视频→字幕稿
- 多语言翻译:专业 / 商务 / 技术文档精准翻译
- 文本润色:口语→书面、病句修正、风格统一
- 信息提取:从杂乱文本抽关键词、数据、联系人、法规条款
4. 绑定知识库,杜绝 “幻觉”(RAG 加持)
- 可关联私有知识库(产品手册、行业规范、内部数据)
- 强制 AI 只依据知识库内容生成,不瞎编
- 示例:生成 “基于 2026 年 Q1 财报的分析报告”,数据完全真实
5. 低代码搭建行业专用工具
- 可视化配置:无需代码,拖拽 + 写提示词即可
- 自定义变量:产品名、受众、风格、字数、语气等
- 可发布为:独立 Web 应用 + API 接口,嵌入企业系统Dify
6. 企业级可控、可审计、可复用
- 风格 / 语气 / 长度 / 禁忌词完全可控Dify
- 生成记录可追溯、可导出、可重复使用
- 适合金融、法律、医疗等强合规场景
5.3.3、典型应用场景
- 电商文案生成器
- 变量:产品名、卖点、受众、风格、字数
- 输出:标题 + 详情 + SEO 关键词 + 小红书文案
- 周报 / 月报自动生成
- 变量:本周工作、问题、计划、数据
- 输出:结构完整、格式规范的工作汇报
- 技术文档生成
- 绑定 API / 代码知识库
- 自动生成:接口文档、使用说明、常见问题
- 法律 / 合规文书生成
- 变量:甲方、乙方、金额、条款
- 输出:合同、告知函、免责声明(合规可控)
- 教育 / 培训内容生成
- 生成:题库、教案、知识点总结、学习指南
5.4、Agent
工作室--->Agent--->创建空白应用
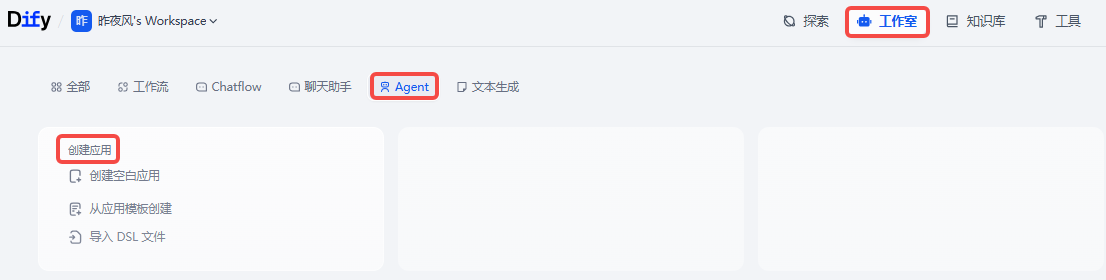
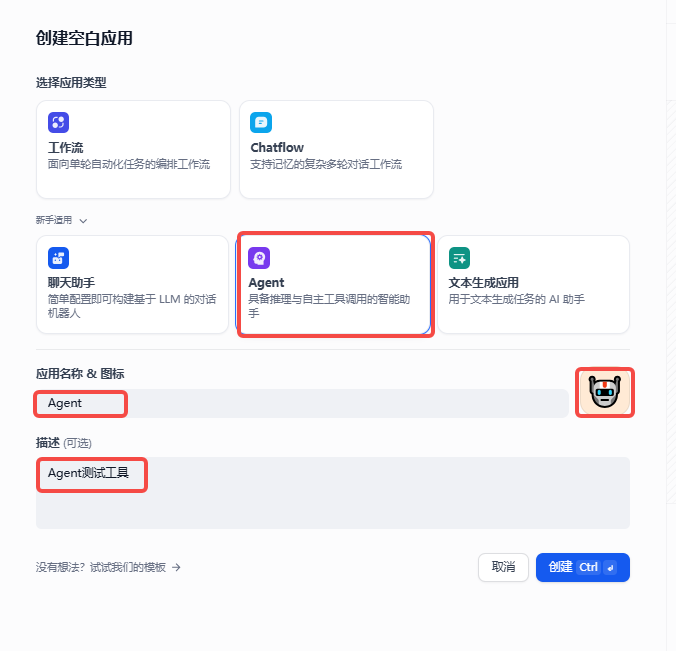
相比前面的聊天助手来说多了一个工具的功能,添加工具。
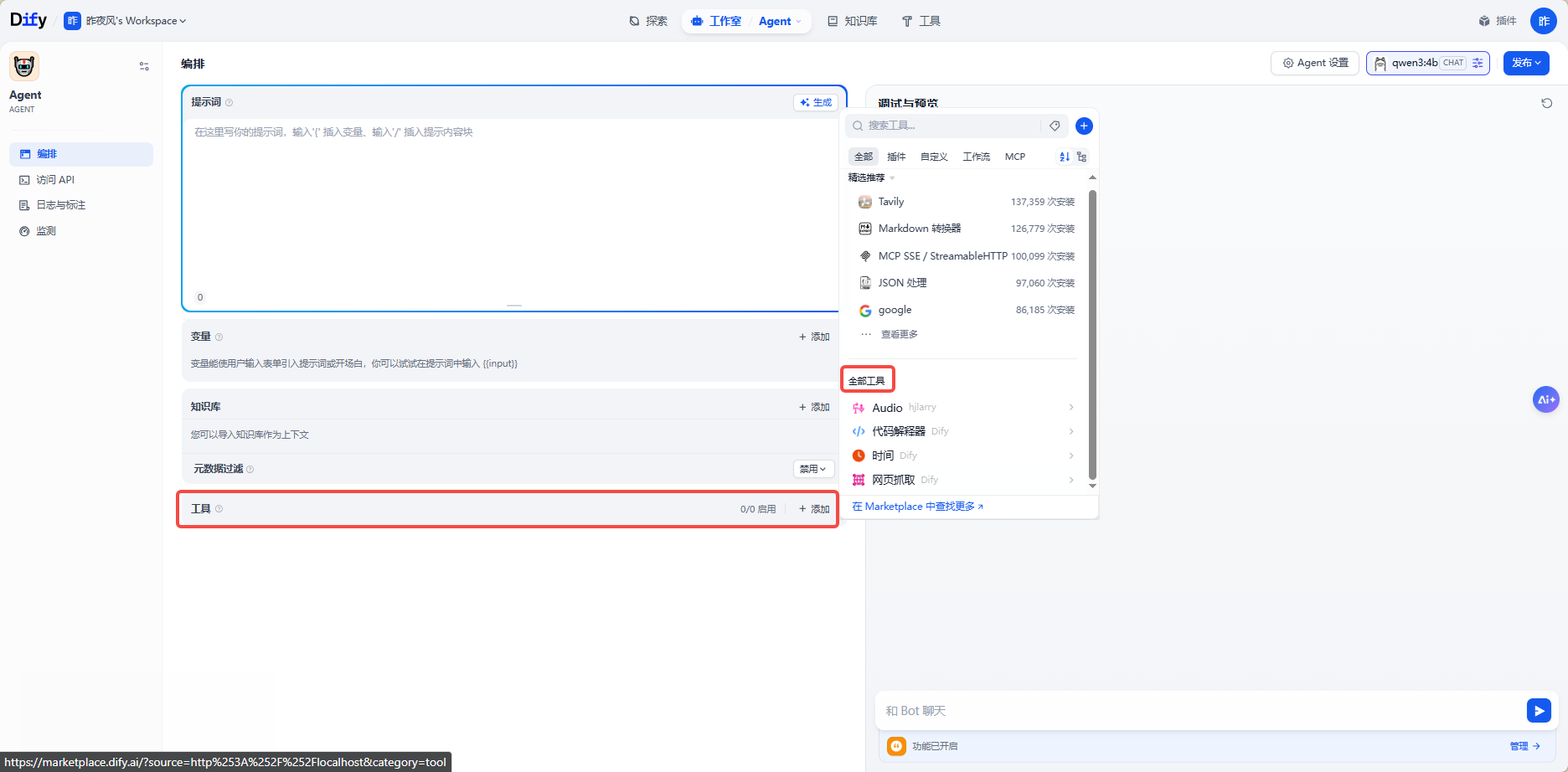
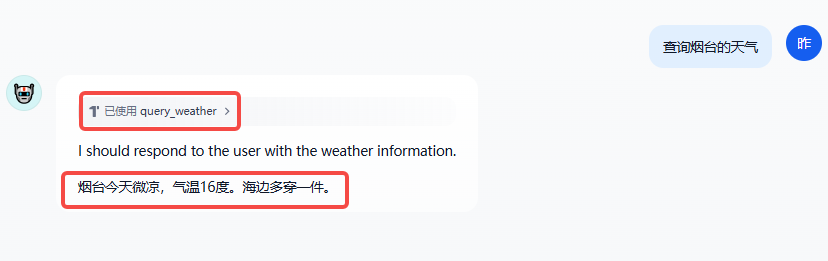
拿时间工具举例:

可以看到模型调用工具并按照要求返回了时间。
5.4.1、Agent介绍
Dify Agent(智能体) 是 Dify 中最高级、最强大的能力模块,核心作用是:让 AI 从 “被动应答” 变成 “自主思考、主动行动、完成复杂任务” 的智能助手。简单说:聊天助手是 “问答机器人”,文本生成是 “文案机器”,而 Agent 是有 “大脑 + 手脚” 的 “AI 员工”。
5.4.1.1、核心本质:AI 的 “大脑 + 手脚”
- 大脑(自主推理):基于 LLM 进行思考、规划、决策、反思。
- 手脚(工具调用):自主调用联网搜索、数据库、API、代码、知识库等外部工具Dify。
- 循环执行:通过 Thought(思考)→ Action(行动)→ Observation(观察) 循环,多步骤迭代完成任务。
5.4.1.2、Agent 的 5 大核心作用
1. 自主拆解与执行复杂任务(最核心)
- 能把用户模糊的复杂指令(如 “写一份行业分析报告”),自动拆解为:
- 确定行业与关键词
- 联网搜索最新数据
- 读取内部知识库资料
- 整理信息、分析数据
- 生成结构化报告
- 无需人工干预,AI 自己决定先做什么、后做什么。
2. 主动调用外部工具,突破 LLM 限制
Agent 是唯一能动态、自主调用工具的模块Dify:
- 内置工具:联网搜索(Google/Bing)、代码解释器、文本处理、思维导图、图片生成等Dify。
- 自定义工具:接入企业内部 API、数据库、ERP、钉钉 / 企业微信、第三方服务Dify。
- 场景:
- 查天气 → 自动调用天气 API
- 算数据 → 自动执行 Python 代码
- 查订单 → 自动查询企业数据库
- 写代码 → 自动调用 GitHub / 代码解释器
3. 动态决策与反思(自我修正)
- 多策略思考:
- ReAct:边想边做,思考链完全可见(适合调试、强解释性)
- Function Calling:原生工具调用,高效稳定(推荐 GPT-4o / Claude 3.5)
- Plan-and-Execute:先定完整计划,再一步步执行(适合长任务)
- 自我反思:每一步执行后判断 “是否完成目标?是否需要补充信息?是否出错?”,自动修正路线。
4. 长记忆与上下文管理
- 短期记忆:记住当前对话的所有历史与中间结果。
- 长期记忆:跨会话保存用户偏好、历史任务、专属知识。
- 工作记忆:在多步骤任务中,临时存储关键数据(如报告大纲、搜索结果)。
5. 低代码可视化编排(强大易用)
- 在 Dify Workflow 中以 Agent 节点 形式存在,拖拽即可使用Dify。
- 可与提示词、变量、知识库、条件判断、代码节点等自由组合。
- 一键发布为 Web App / API / 插件,嵌入企业系统Dify。
5.4.1.3、典型应用场景
- 智能研究助理
- 指令:“分析 2026 年 AI 大模型市场趋势,给出报告”
- Agent 自动:联网搜索 → 查研报 → 读行业文档 → 分析数据 → 生成报告Dify
- 自动化客服专家
- 用户:“我的订单 #123 为什么没发货?帮我催单并退款”
- Agent 自动:查订单库 → 联系物流 API → 生成工单 → 发起退款 → 回复用户
- 代码 / 数据分析助手
- 指令:“分析这份 CSV 销售数据,找出异常并生成可视化图表”
- Agent 自动:读取数据 → 清洗 → 写 Python 代码 → 计算 → 生成图表与结论Dify
5.5、Chatflow
工作室--->Chatflow--->创建空白应用
这是一整套流程,ChatFlow 就是一个对话流程,对话流程通过一个个节点,引导用户按照我们既定的方向提问,并给出答案。
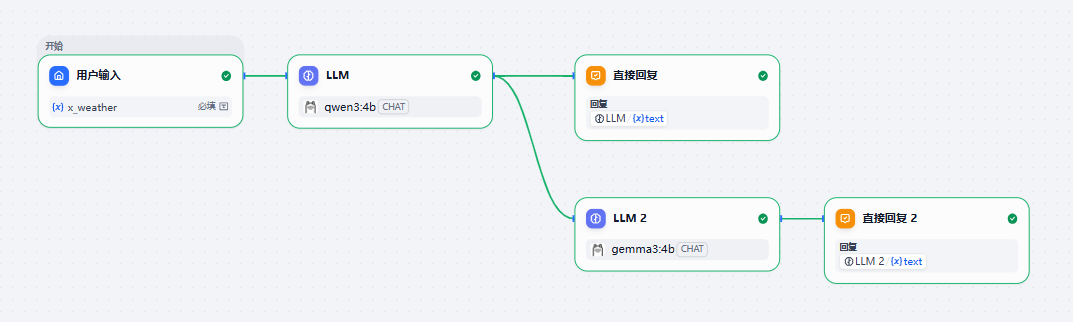
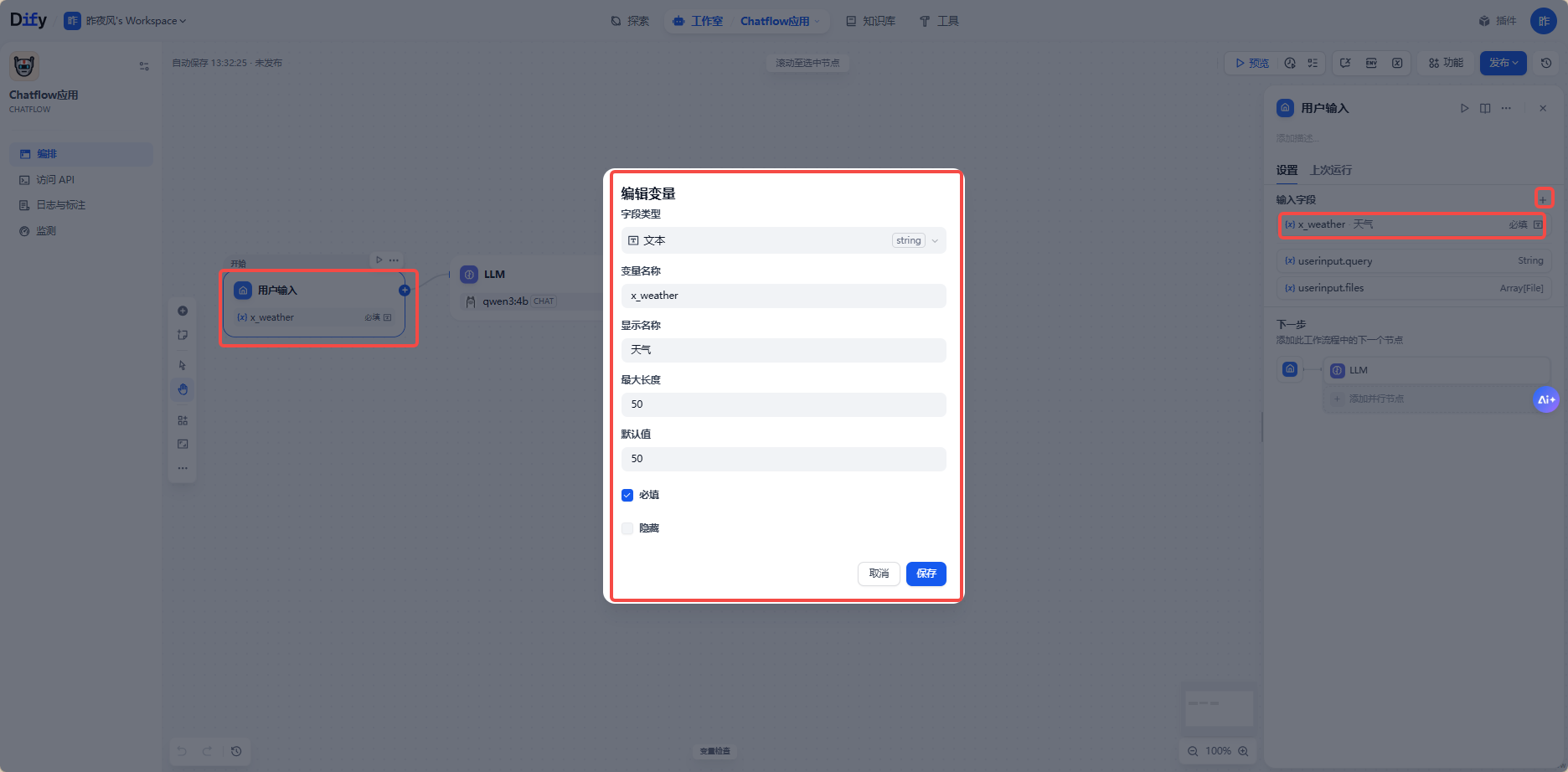
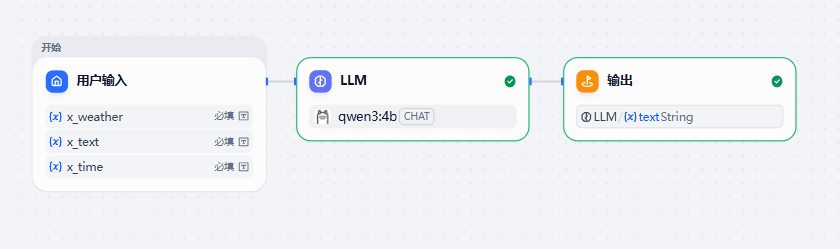
用户输入(用户节点)
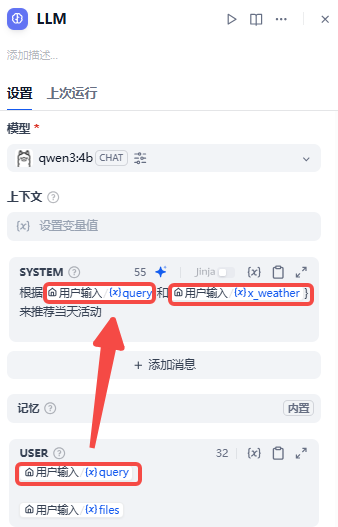
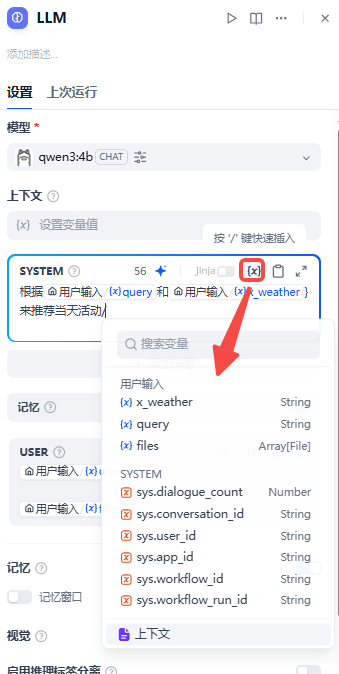
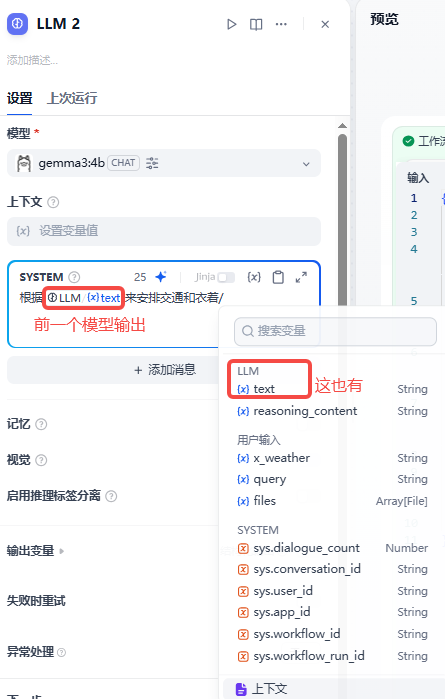
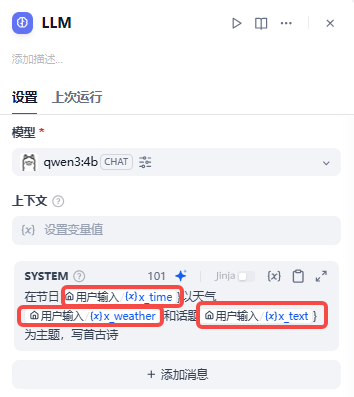
LLM(大模型节点)
里面有很多变量,可以自定义,也有默认的
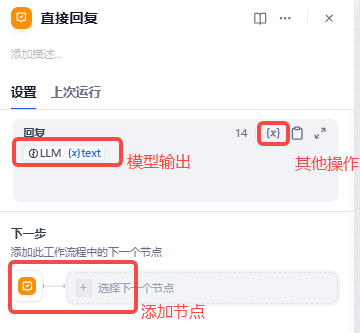
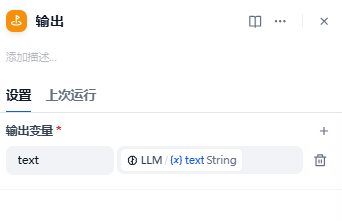
直接回复(回复节点)
模型输出,还可以往后添加节点,或者插入命令进行其他操作
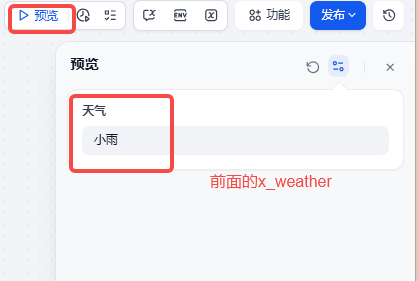
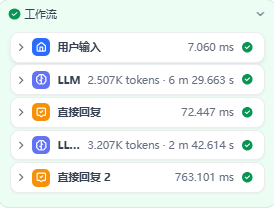
运行效果
可以清楚看到流程,根据要求回答出来了,两个回答输出


此外还可以添加其他的,例如:知识库、Agent、大模型、工具、等等
5.5.1、Chatflow介绍
Dify Chatflow(对话流) 是 Dify 中专为多轮对话设计的可视化工作流引擎,核心作用是:让你像画流程图一样,精确控制 AI 聊天的每一步逻辑、分支与行为,把简单的 “问答机器人” 变成能处理复杂业务的智能对话系统。简单说:普通聊天是 “黑盒”,Chatflow 是 “白盒”—— 你完全掌控 AI 怎么想、怎么做、怎么回。
5.5.1.1、核心定位:对话的 “总导演”
- 本质:带记忆的可视化对话编排器
- 对比:
- 普通聊天助手:简单输入→输出,逻辑不可控、无分支
- Chatflow:全流程可视化、可拆解、可调试、可分支的对话蓝图
- 核心能力:多轮记忆 + 节点编排 + 条件分支 + 工具调用 + 流式输出
5.5.1.2、Chatflow 的 6 大核心作用
1. 可视化编排复杂对话逻辑(最核心价值)
- 拖拽式设计:无需代码,通过节点(LLM、知识库、IF/ELSE、工具等)连线设计流程
- 精确控制:
- 先意图识别→再知识库检索→最后LLM 生成
- 找不到答案时→自动转接人工
- 敏感问题→触发风控、拒绝回答
- 优势:逻辑透明、可调试、可复用
2. 多轮对话与上下文记忆(区别于普通 Workflow)
- 内置对话记忆(Memory):自动保存历史消息,跨轮次保持连贯
- 会话变量:可自定义变量(如用户信息、订单号、进度),全程可读写Dify
- 示例:
- 用户:“我要查订单”→Chatflow 记住 “查单” 意图
- 接着问:“怎么退货”→AI 结合上下文直接回应,无需重复说明
3. 意图识别与动态路由(智能分流)
- 问题分类器节点:自动判断用户意图(咨询、投诉、查单、技术问题)
- 条件分支(IF/ELSE):
- IF 问题简单→直接知识库回答
- IF 问题复杂→转 LLM 深度解答
- IF 涉及隐私→触发人工审核
- 价值:千人千面,不同问题走不同流程,效率提升 50%+
4. 混合检索与工具调用(增强能力)
- 多数据源并行检索:
- 同时查私有知识库 + 联网搜索 + 企业数据库
- 整合信息后生成唯一答案,杜绝幻觉
- 工具节点:
- 调用HTTP API(查天气、查订单、发邮件)
- 执行Python 代码(计算、数据分析)
- 连接第三方服务(企业微信、钉钉、ERP)
5. 引导式对话与信息收集(主动交互)
- 参数提取器:自动从对话中抽取关键信息(姓名、手机号、地址)
- 追问引导:信息不全时,AI 主动追问补全(如 “请提供你的订单号”)
- 表单式交互:边聊边填,自然完成复杂业务(如办卡、报修、下单)
6. 流式输出与多模态回复(优质体验)
- Answer 节点:支持流式响应(边思考边输出,无等待卡顿)
- 多格式输出:文本、图片、文件、表格、卡片式回复
- 中间步骤回复:可在流程任意节点输出消息(如 “正在为您查询订单,请稍候”)Dify
5.5.1.3、实战场景
- 智能客服机器人
- 流程:用户提问 → 意图分类 → 知识库检索 → 找到→直接答 / 没找到→转人工 / 复杂→调用 API
- 能力:查订单、退货、改地址、催发货全流程自动处理
- 医疗 / 法律问诊助手
- 流程:症状询问 → 信息收集 → 知识库匹配 → 初步诊断 → 建议就医
- 优势:多轮引导、上下文连贯、依据专业知识库、无幻觉
- 销售 / 营销顾问
- 流程:需求了解 → 产品推荐 → 参数对比 → 报价 → 下单引导
- 价值:主动式销售、个性化推荐、全程留痕
5.6、工作流
看着和Chatflow非常像,但工作流最重要的是自动化执行而不是对话。
工作室 ---> 工作流 ---> 创建空白应用
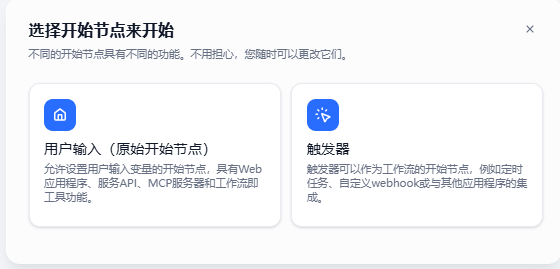
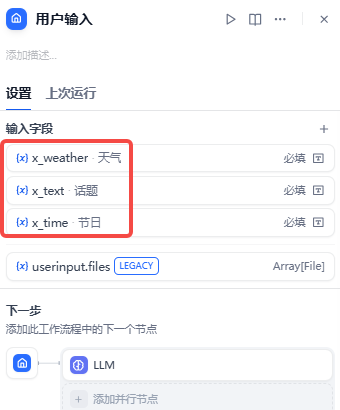
用户输入节点允许你定义从最终用户收集哪些内容作为应用程序的输入。使用此节点启动的应用程序按需运行,可以通过直接用户交互或 API 调用启动。你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
触发器是一种开始节点,能够使工作流定时运行或当外部系统(例如 GitHub、Gmail 或你自己的内部系统)的特定事件发生时自动运行,而不是只能通过用户交互或 API 调用才能启动。基于以上特性,触发器可用于自动执行重复任务,或将工作流与第三方系统集成以实现自动化数据同步与处理。一个工作流可同时拥有多个并行的触发器。你也可以在同一画布上构建多个独立的、以不同触发器作为起点的工作流。
选择用户输入,选择一个节点
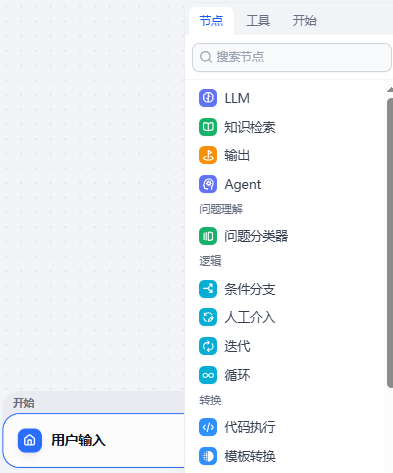
创建的流程
5.6.1、工作流介绍
是否发现了,全流程和Chatflow非常像,可以说几乎一样,但是相较于Chatflow,没有了聊天窗口,多了触发器,更适合自动化。
工作流 = 自动化执行的 “流水线”,用来做不需要聊天、不需要交互、一次性跑完的复杂任务。
它不跟人聊天,只干活。
5.6.1.1、工作流到底是什么?
你可以把它理解为:把一堆步骤串起来,让 AI 自动从头到尾跑完,不用人管。
步骤可以是:
- 读取文件
- 调用 LLM
- 调用 API
- 条件判断(if/else)
- 执行 Python 代码
- 查知识库
- 生成文本、邮件、报告、总结
- 写入数据库、发送通知
你画流程图 → 点运行 → AI 自动跑完所有步骤 → 输出最终结果。
5.6.1.2、工作流最核心的 5 个作用
① 自动化复杂任务(最核心)
不需要人参与,不需要对话,直接从头到尾跑完。例如:
- 上传一篇文档 → 自动总结 → 自动提取关键词 → 自动生成简报
- 爬取网页 → 清洗内容 → 生成报告 → 发邮件
② 可视化编排,不用写代码
拖拽节点就能实现:
- 分支判断
- 循环
- 变量传递
- 多 LLM 调用
- 多工具调用
完全可视化、可调试、可复用。
③ 后台批量处理
适合:
- 批量总结文章
- 批量生成文案
- 批量清洗数据
- 批量提取信息
- 批量翻译
一次跑 100 条、1000 条都没问题。
④ 连接外部系统(API、数据库、工具)
工作流可以:
- 调用外部 API
- 执行 Python
- 查询数据库
- 发送 HTTP 请求
- 连接企业系统
让 AI 变成你业务的自动化工人。
⑤ 稳定、可复用、可上线成 API
配置好一次,就能:
- 手动运行
- 定时运行
- 通过 API 调用
- 集成到你的系统里
5.6.1.3、工作流真实使用场景
- 自动周报生成
- 自动研报分析
- 批量商品描述生成
- 自动爬取网页 → 总结 → 发邮件
- 数据清洗、格式转换、信息提取
- 自动化审核、自动化判断
- 定时任务:每天自动跑、自动汇总
5.7、五个功能的联系和区别
区别:
1. 文本生成(Text Generator)
作用:一次性输出内容,无交互、无记忆。
- 只做:写文案、总结、翻译、扩写、结构化输出
- 特点:
- 无对话
- 无历史
- 一次请求一次结果
- 适合:批量文案、报告、摘要
2. 聊天助手(Chat Assistant,简易版)
作用:简单多轮对话,黑盒模式,不能画流程。
- 你给提示词 → AI 回答
- 有上下文记忆
- 不能画流程图、不能分支、不能判断 if/else
- 适合:简单客服、日常问答、个人助手
3. 工作流(Workflow)
作用:后台自动化流水线,不跟人聊天。
- 拖拽节点:LLM、知识库、API、代码、条件判断
- 从头到尾自动跑完
- 无聊天、无记忆、不交互
- 适合:
- 批量处理
- 自动总结
- 数据清洗
- 定时任务
4. Chatflow(对话流)
作用:带聊天功能的工作流 = 可控制对话逻辑
- 有记忆、有多轮对话
- 可画分支、可判断、可查知识库、可调 API
- 你完全掌控对话路径
- 适合:
- 智能客服
- 业务办理(报修、办卡、查单、退货)
- 多轮引导式交互
5. Agent(智能体)
作用:拥有自主思考能力的超级大脑
- 会自己规划步骤
- 会自己调用工具
- 会反思、会修正
- 能处理复杂、开放、不确定的任务
- 适合:
- 写报告
- 数据分析
- 复杂查询
- 自主完成任务
联系:
工作流 / Chatflow 是 “流程框架”,Agent 是里面的 “超级大脑”(超级节点)。
1. 工作流 和 Chatflow 都是流程编排工具
- Workflow:后台任务
- Chatflow:对话任务
它们都可以:
- 加 LLM
- 加知识库
- 加变量
- 加判断
- 加 API
- 加 Agent!
2. Agent 可以被嵌入到 工作流 / Chatflow 里
Chatflow、Workflow 里面都能插入 Agent 节点!
意义是:
- 流程负责:路径、顺序、什么时候调用 AI
- Agent 负责:复杂思考、工具调用、自主解决问题
六、工具
6.1、官方工具
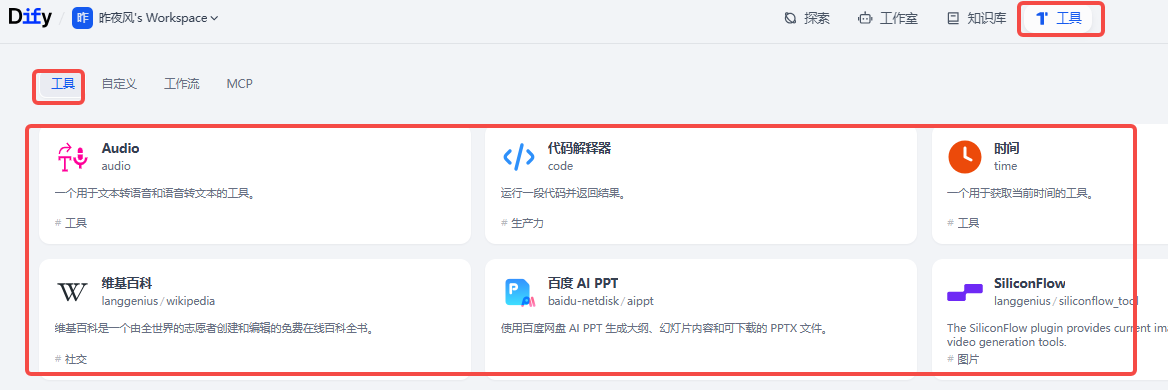
下载:
我们可以在顶部工具进入
其中有官方工具,也有官方支持的各厂商工具
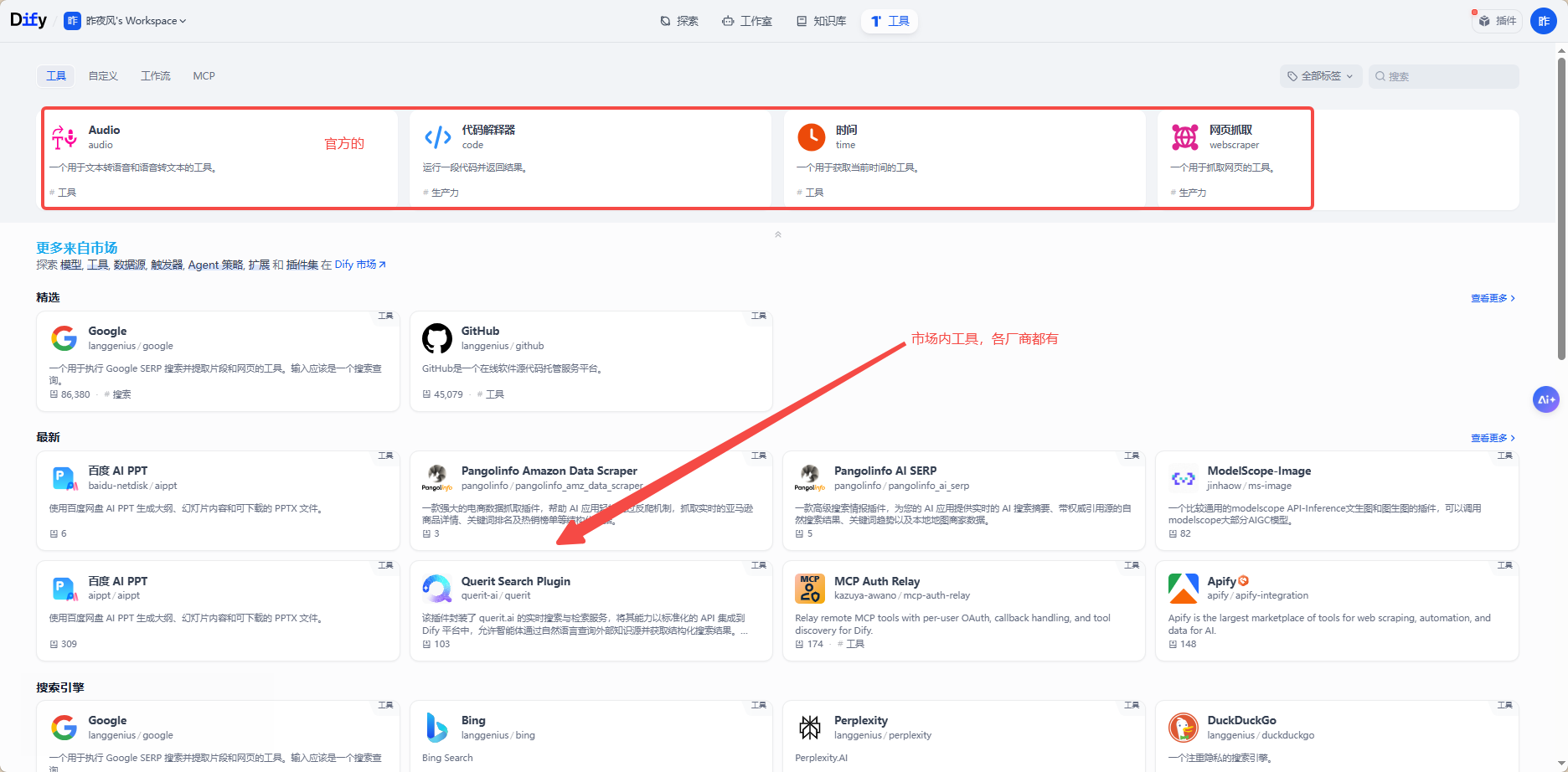
拿维基百科举例,点击安装
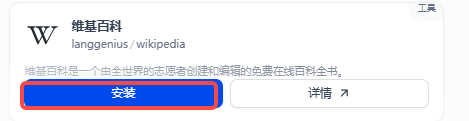
右上角插件查看下载进度,你下载的插件都在这

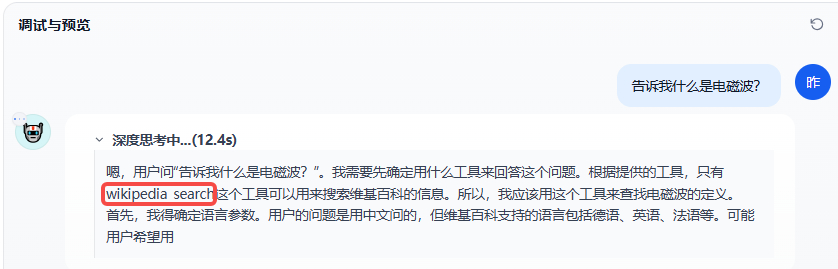
Agent调用:
回到Agent添加调用
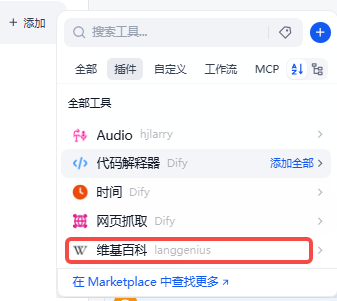
点击添加

看到已经使用维基百科工具了
6.2、创建自定义工具:
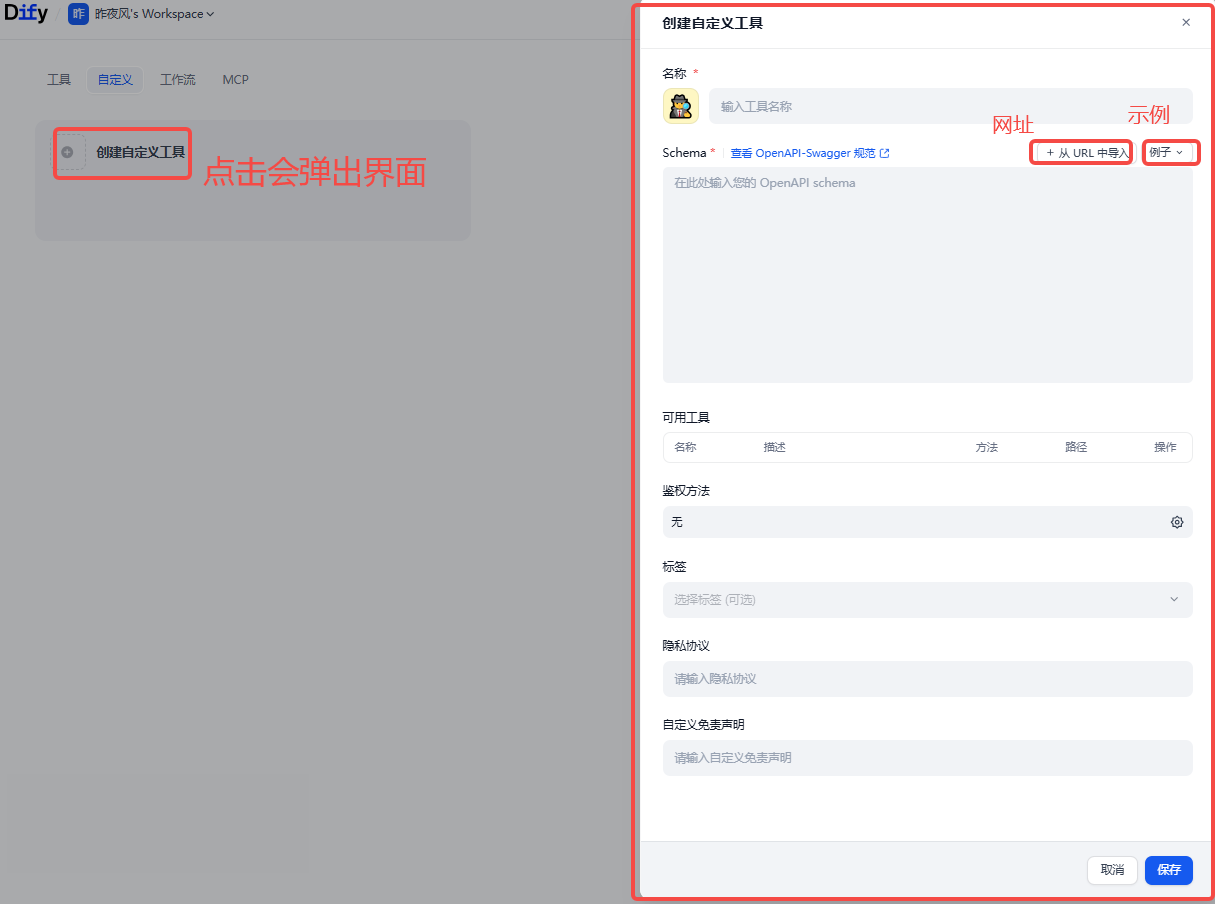
创建:
拿天气举例子:(免费的,也可以其他的)
Free Weather API - WeatherAPI.com
自定义工具的示例可以看下:
{
"openapi": "3.1.0",
"info": {
"title": "Get weather data",
"description": "Retrieves current weather data for a location.",
"version": "v1.0.0"
},
"servers": [
{
"url": "https://weather.example.com"
}
],
"paths": {
"/location": {
"get": {
"description": "Get temperature for a specific location",
"operationId": "GetCurrentWeather",
"parameters": [
{
"name": "location",
"in": "query",
"description": "The city and state to retrieve the weather for",
"required": true,
"schema": {
"type": "string"
}
}
],
"deprecated": false
}
}
},
"components": {
"schemas": {}
}
}
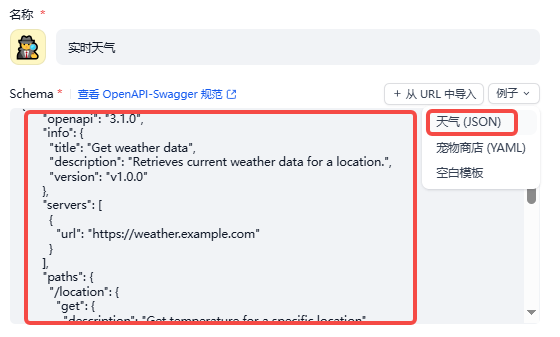
weatherapi结构可如下:
{
"openapi": "3.1.0",
"info": {
"title": "WeatherAPI 实时天气",
"description": "基于 WeatherAPI.com 获取指定城市的实时天气、温度、天气状况",
"version": "v1.0.0"
},
"servers": [
{
"url": "https://api.weatherapi.com"
}
],
"paths": {
"/v1/current.json": {
"get": {
"operationId": "GetCurrentWeather",
"summary": "获取实时天气",
"description": "获取城市实时天气",
"parameters": [
{
"name": "key",
"in": "query",
"description": "WeatherAPI 密钥,别忘了换成你的key!!!",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "q",
"in": "query",
"description": "城市名,如:beijing, shanghai, guangzhou, london",
"required": true,
"schema": {
"type": "string"
}
}
]
}
}
}
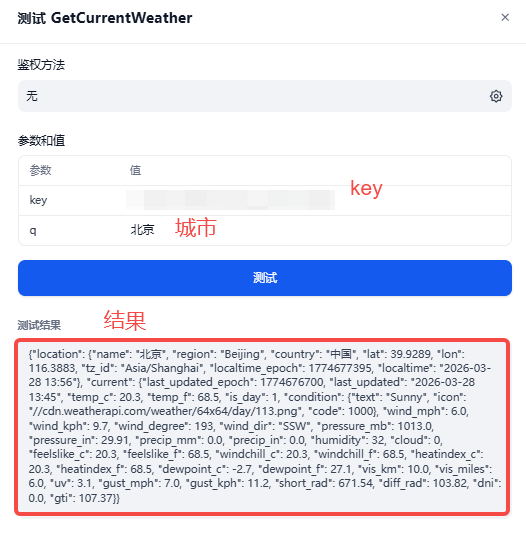
}点击测试,输入你的key和要查询城市,会出现结果:
保存后就有工具了:
Agent调用:
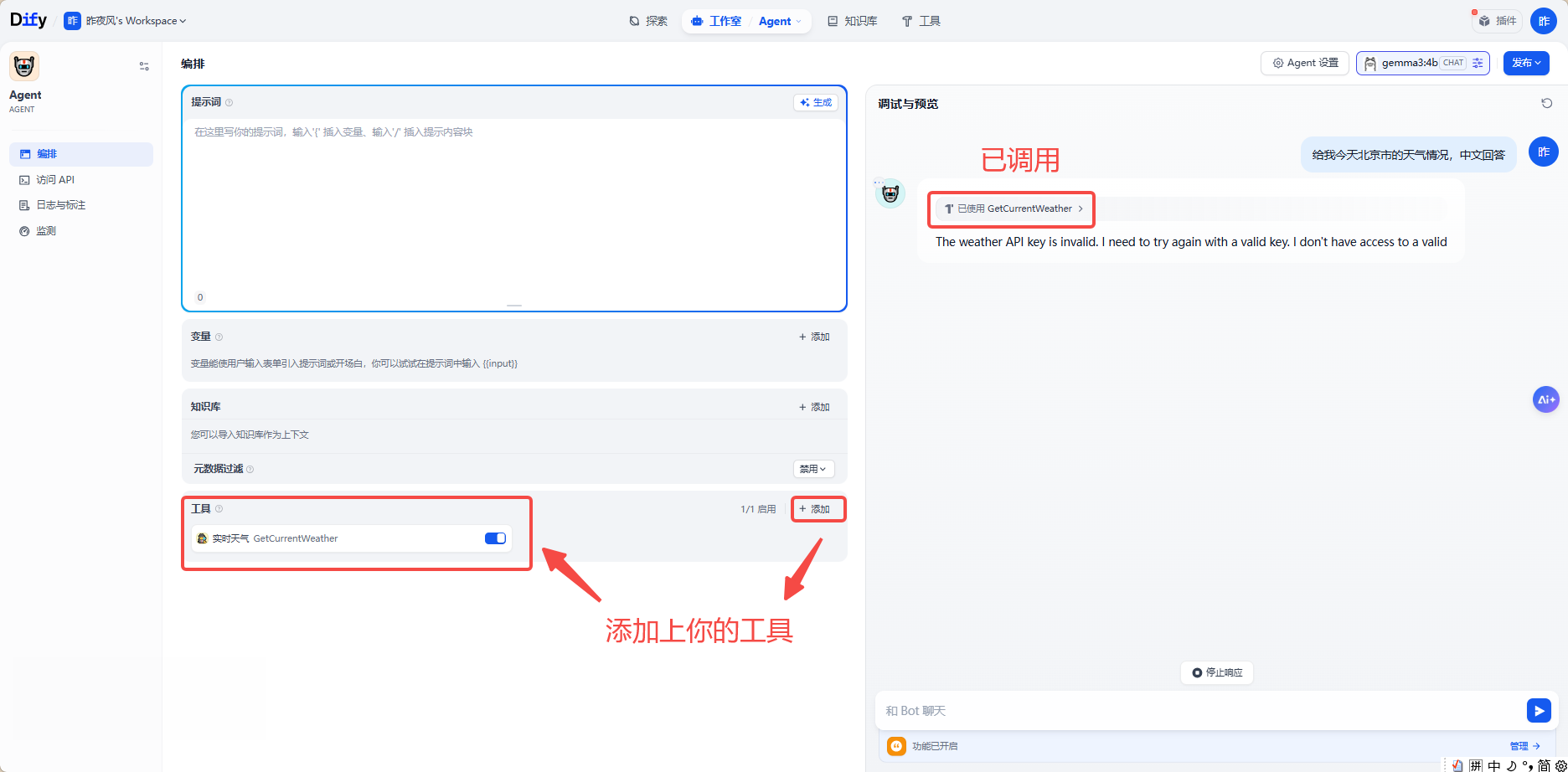
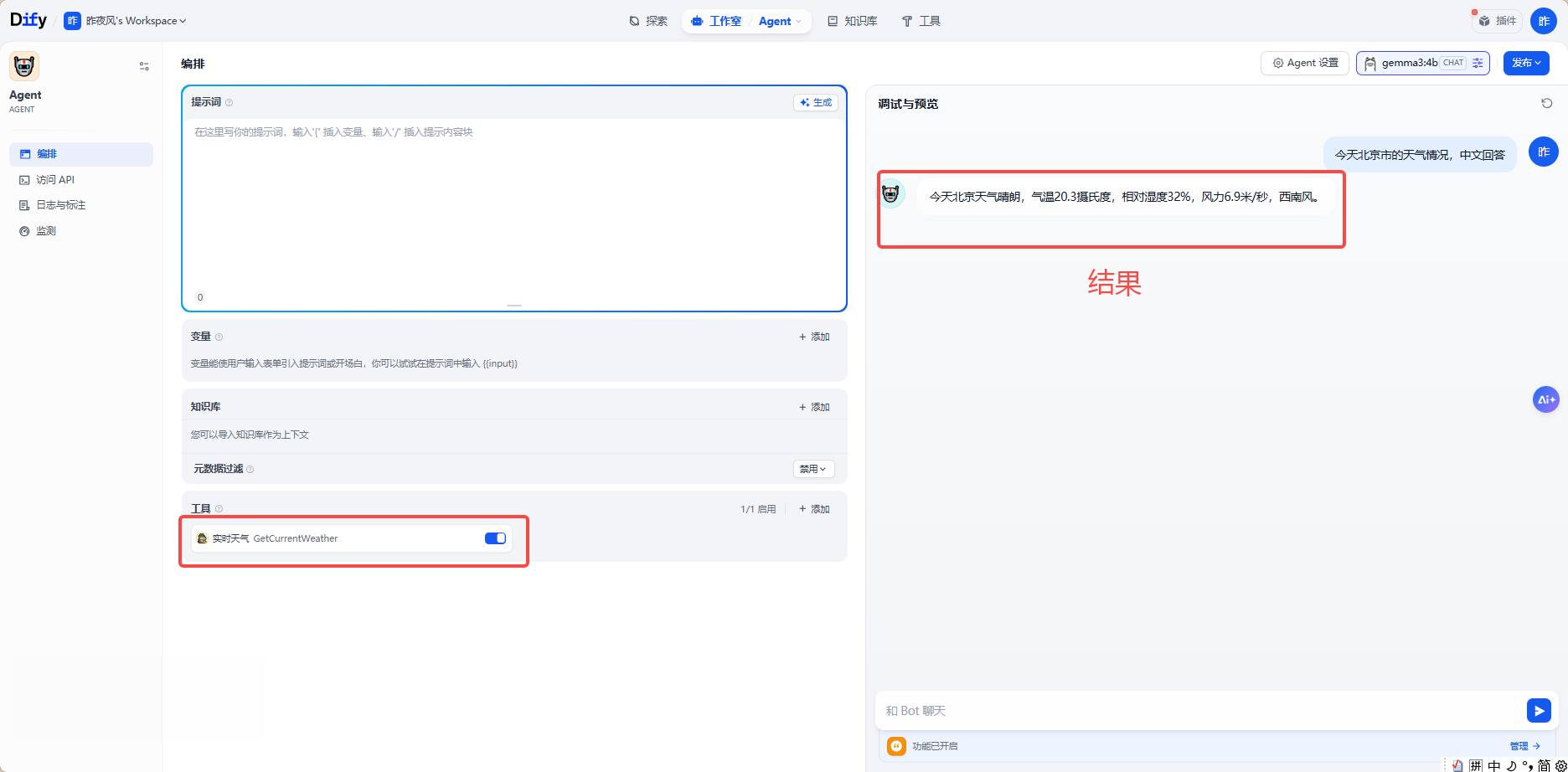
6.3、工作流
创建:
需要你将工作室的工作流 发布成工具,拿前面的例子举例
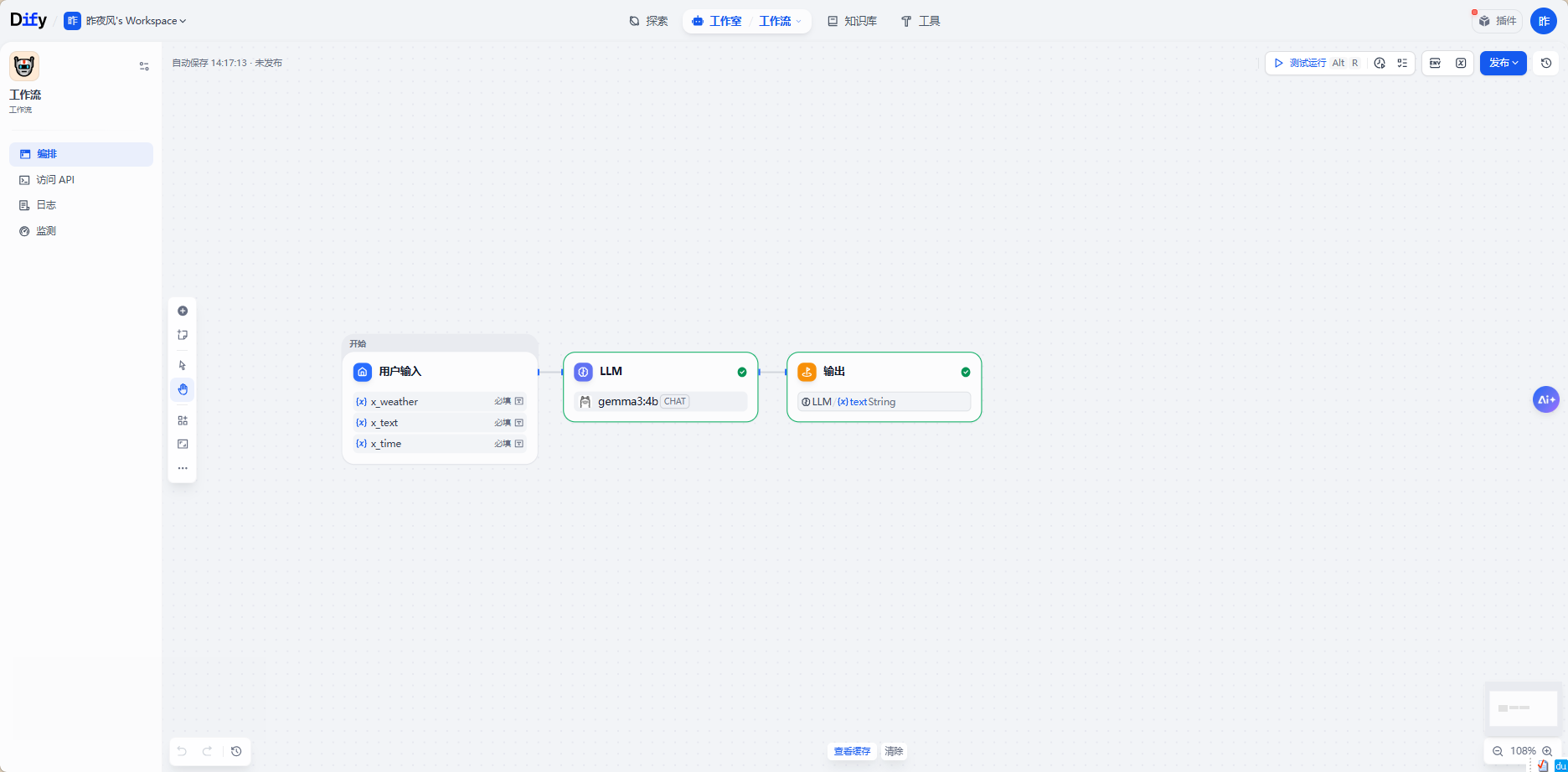
发布 ---> 发布更新 ---> 发布为工具
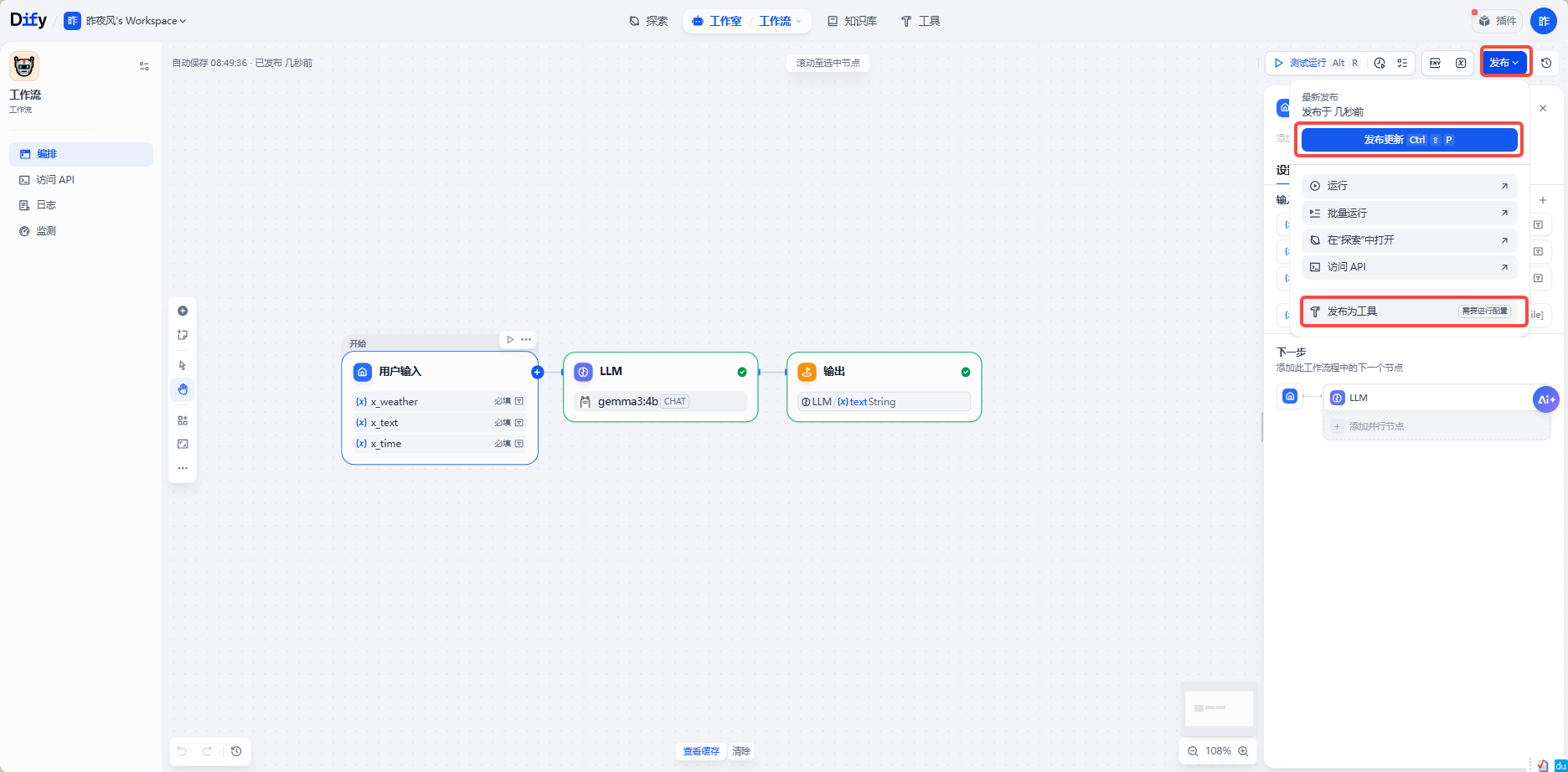
会出现如下界面
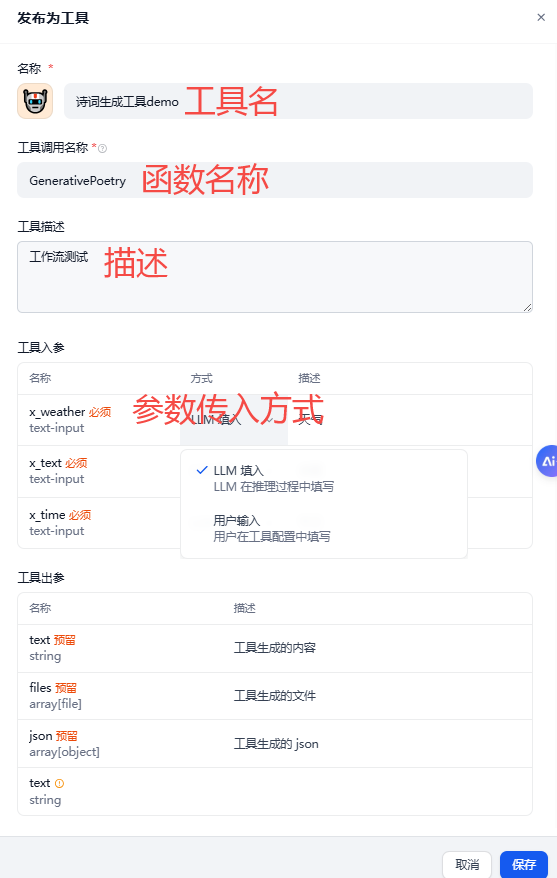
工具--->工作流下已经有了

Agent调用:
回到Agent添加调用
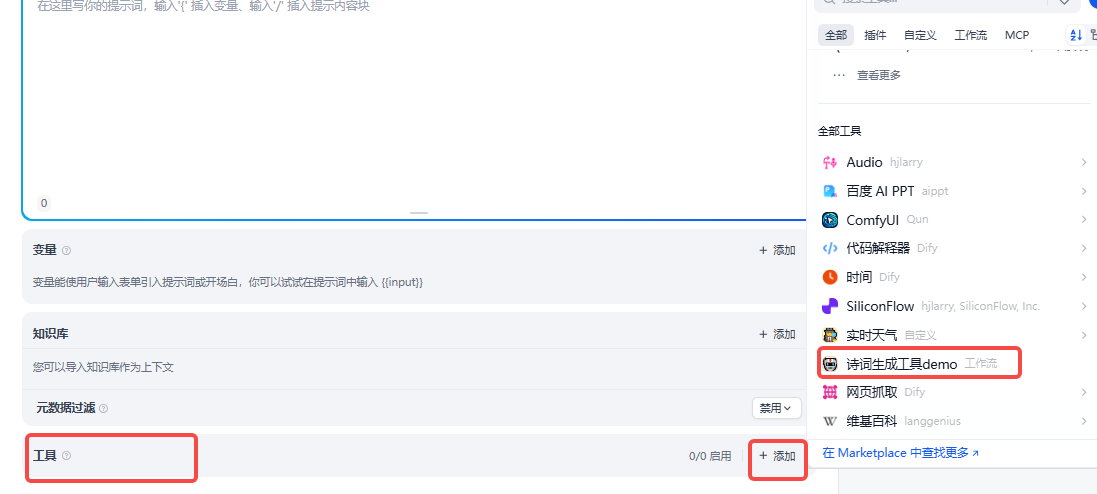
我前面填的是用户输入,必须提前输入,点击
![]()
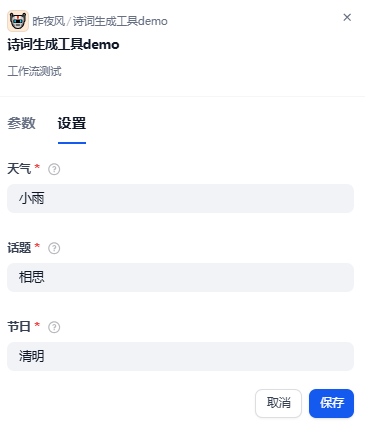


6.4、MCP
mcp服务器的搭建请参考:MCP服务器搭建-CSDN博客
创建:
工具--->MCP--->添加
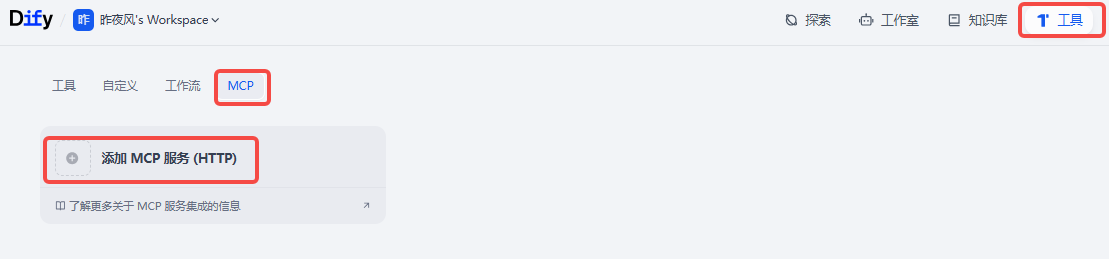
设置MCP服务器:
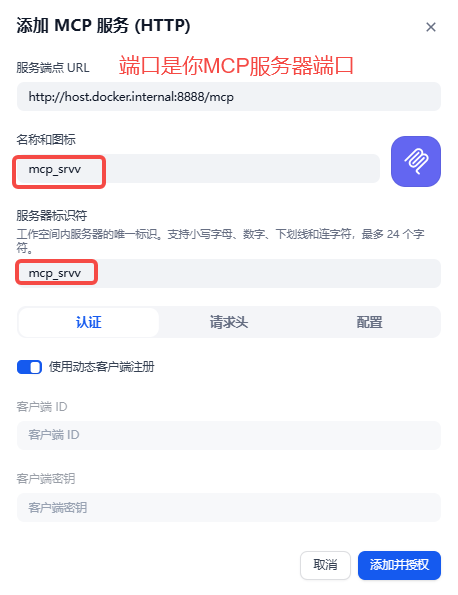
添加授权完就能看到MCP工具了,也能看到函数方法:
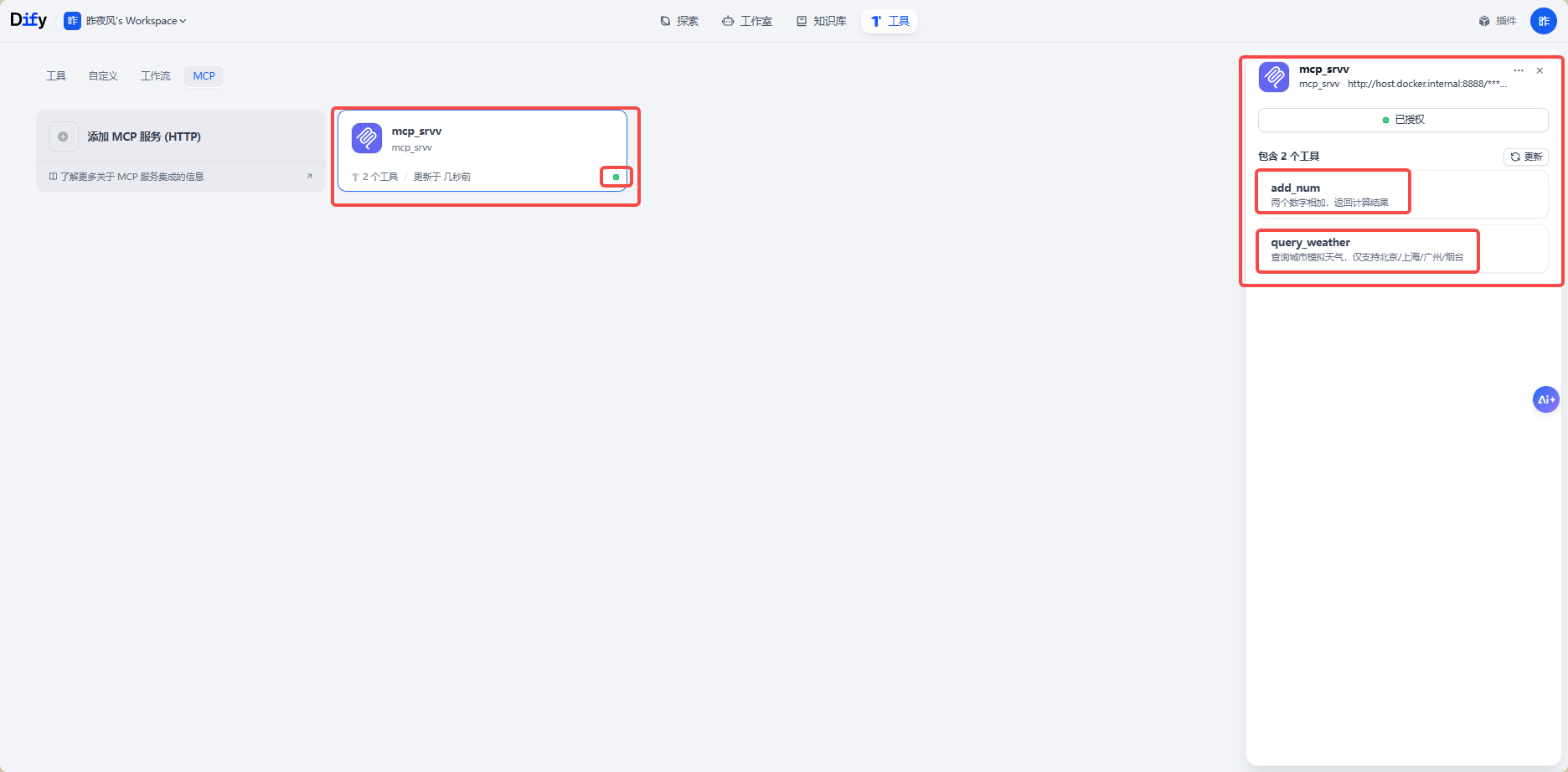
Agent调用:
Agent--->工具--->添加--->mcp_srvv
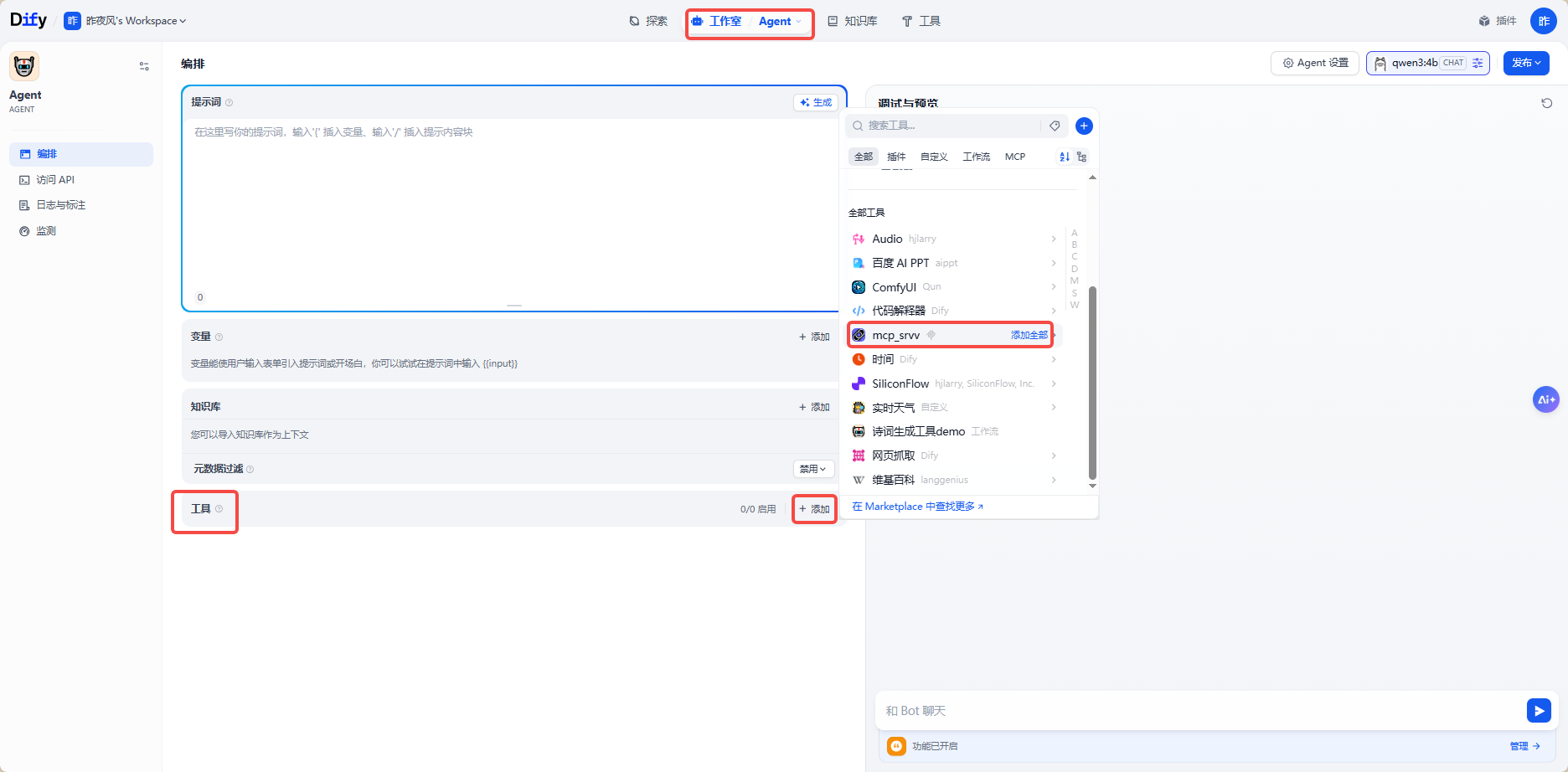

调用成功
七、外部使用dify
是不是很好奇,在dify中实现了工具,MCP,Agent,如果我别的项目要用怎么办?总不能一直在dify中使用吧?
官方已经提供了相应方式:
别忘了点【发布更新】
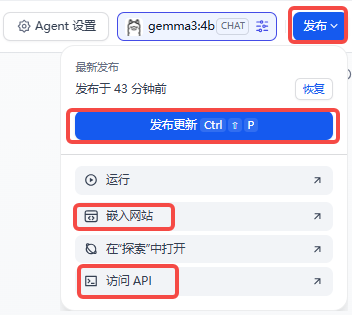
常用两种:
1、HTTP API 调用
拿Agent举例:
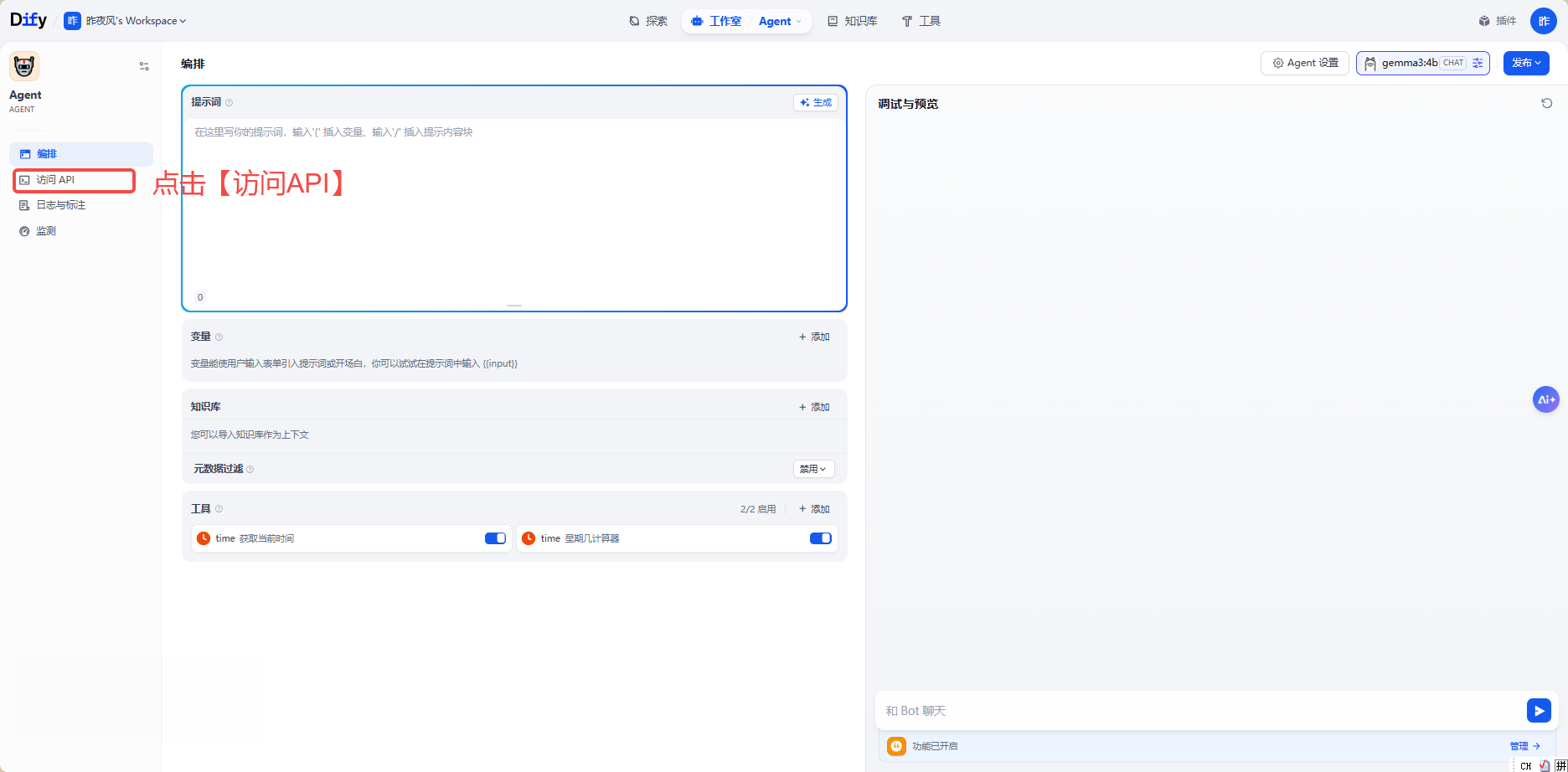
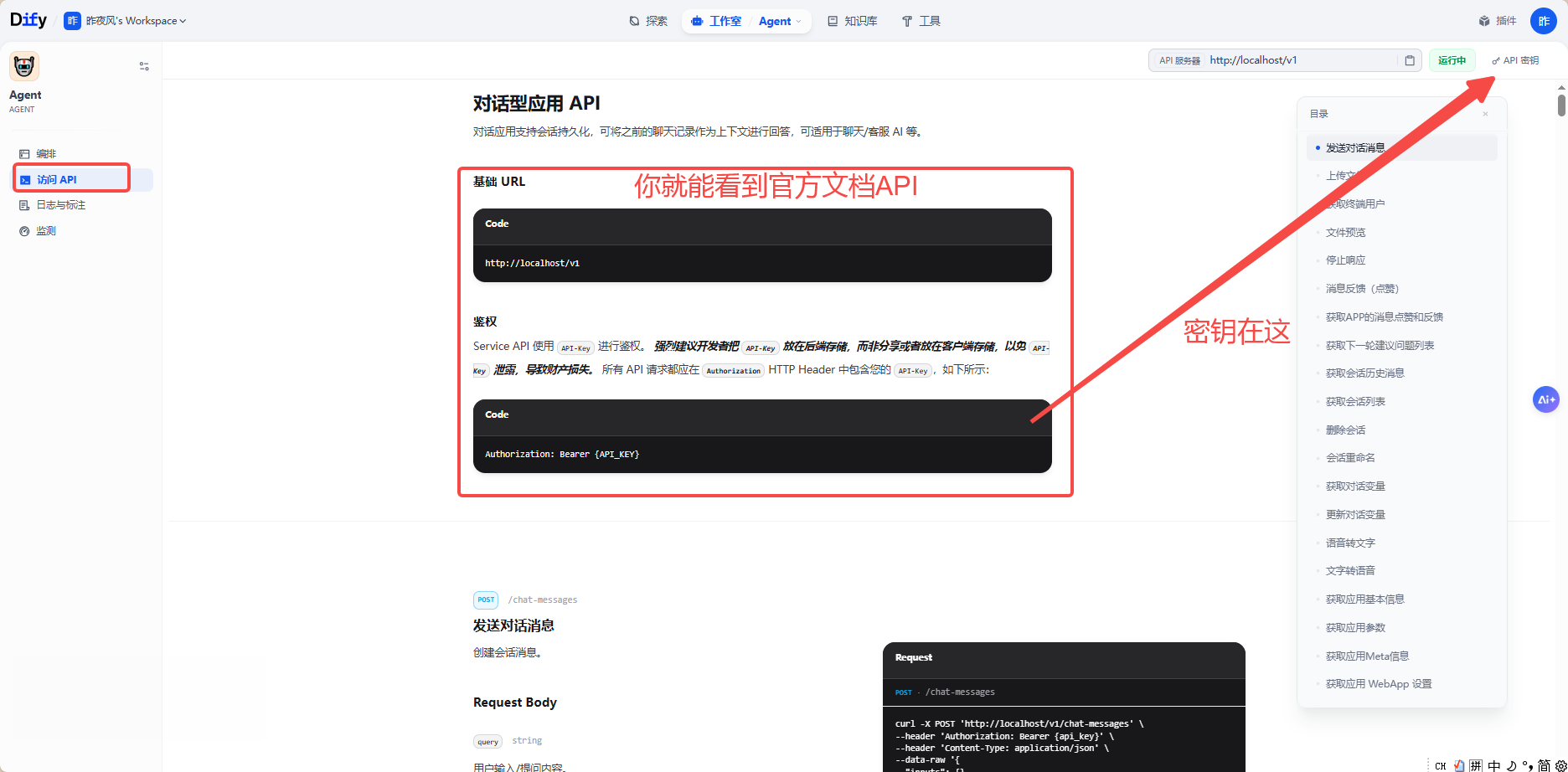
点击【API密钥】

会生成【API密钥】
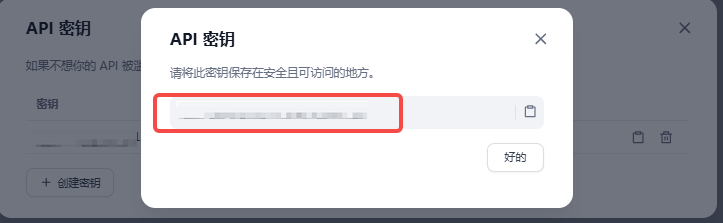
下面是一段python使用requests通过HTTP访问dify内Agent的示例,可以自己使用修改:
import requests
import json
# ====================== 你只需要改这里 ======================
API_KEY = "app-xxxxxxxxxxxxxxxxxx"
DIFY_URL = "http://localhost/v1"
QUERY = "现在什么时间?"
# ==========================================================
url = f"{DIFY_URL}/chat-messages"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
# 关键:Agent 必须用 streaming 模式
data = {
"inputs": {},
"query": QUERY,
"response_mode": "streaming", # 这里改了!
"user": "test_user",
}
# 发送流式请求
response = requests.post(url, headers=headers, json=data, stream=True)
# 读取流式返回
print("=== Agent 思考过程 & 最终答案 ===")
for line in response.iter_lines():
if line:
line = line.decode("utf-8")
if line.startswith("data:"):
json_str = line[5:].strip()
try:
json_data = json.loads(json_str)
if "answer" in json_data:
print(json_data["answer"], end="", flush=True)
except:
continue
print("\n")
结果:调用了Agent内工具
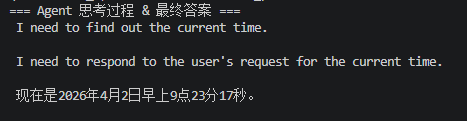

注意:
- 每个工具都有自己APIKEY,代表调用不同工具
例如:每个 Dify 应用(Agent / 聊天助手 / Chatflow)基础url都是/v1/chat-messages
HTTP调用他们的区别就是各自APIKEY
2、前端嵌入式使用
写在结尾:我也是刚了解Dify,如果有什么错误或遗漏,可以指正出来,欢迎大家交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 38
38 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)