【AI Engineering 】别再迷信换模型了!从Prompt到Harness,AI Agent真正的工程范式变迁
Hello 大家好,我是蜂蜜 🍯。
世界变化太快,我正在努力跟上。
最近不管是写代码还是刷技术圈,大家都在疯狂卷 AI Agent。但不知道你们有没有遇到这种让人极其崩溃的场景:咱们这些打工人(牛马)辛辛苦苦花大半年搭了个 Agent,本地 Demo 跑得那叫一个丝滑漂亮,简直要改变世界了。结果一放到真实的业务场景里去跑复杂的 CRUD,或者去跑长链路的数据处理?直接翻车 💥。
任务失败、结果神鬼莫测、动不动就死循环……根本没法交付给用户。
这时候,我们的第一反应往往是:“是不是模型太笨了?” 于是咬咬牙换了更贵的模型,或者疯狂去改 Prompt 加粗大写 “你是一个资深专家”,再或者疯狂往上下文里塞文档。结果呢?依然不靠谱。
问题到底出在哪?最近刷到一位博主的硬核拆解,加上这阵子研究前沿架构的感悟,我发现:咱们的坐标系建错了。
今天就带大家重新建构这个坐标系,聊聊 AI 工程的“三次范式跃迁”:Prompt(提示)、Context(上下文)与 Harness(缰绳/马具/脚手架)。
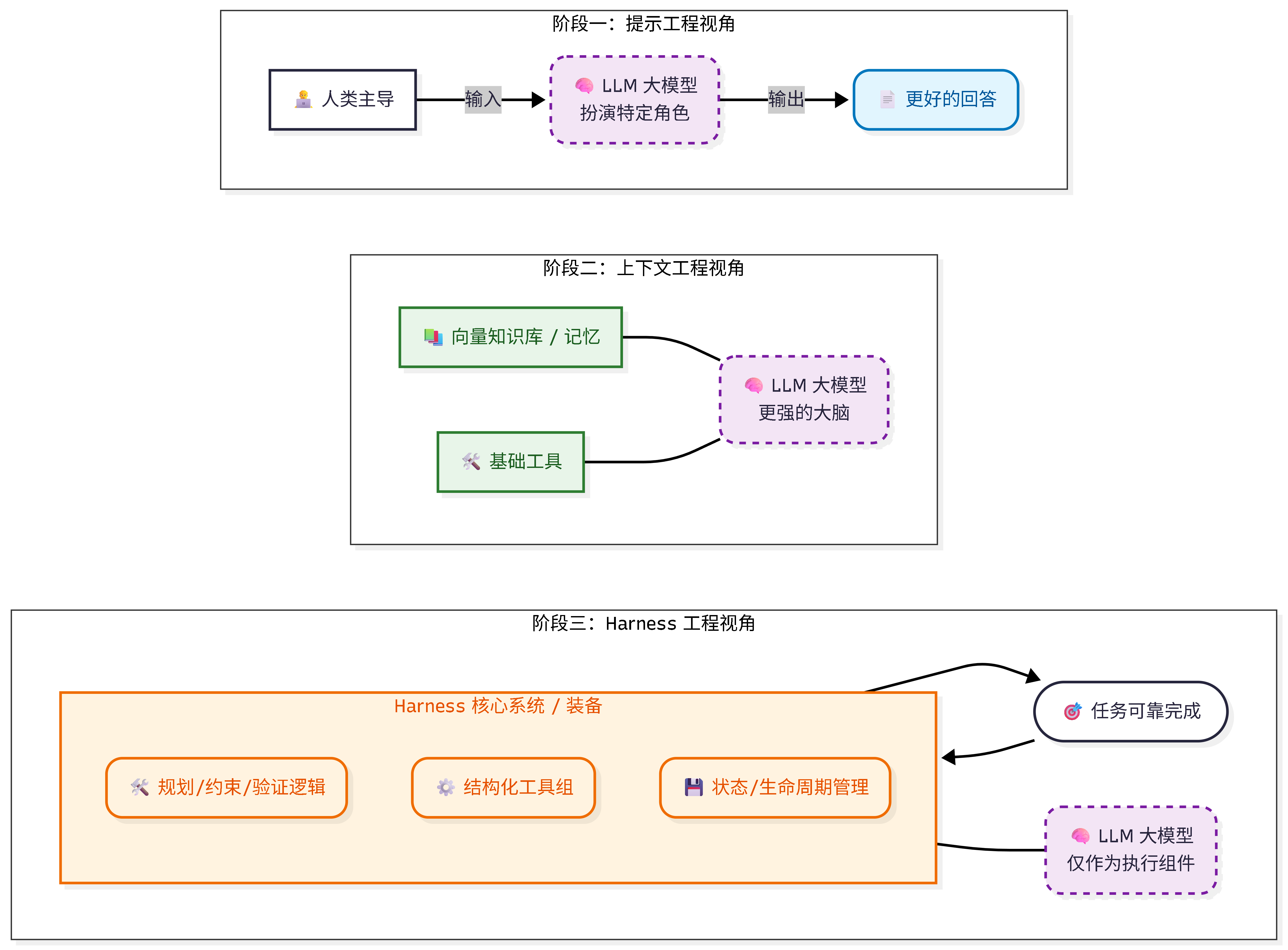
🚀 跃迁一:提示工程(Prompt Engineering)—— 追求更好的回答
这是大家最熟悉的阶段。半年前,满世界都在教你写 Prompt。 在这个阶段,解决的核心问题是:如何让大模型给出更精准、更符合预期的回答?
我们用 角色设定(“你是一个拥有 20 年经验的 Java 架构师”)、思维链(CoT,“请一步步思考”)、少样本示例(Few-shot)来引导它。 定位: 此时的大模型就像个高级“副驾驶(Co-pilot)”,人在主导方向盘,AI 负责在旁边出主意。
🧠 跃迁二:上下文工程(Context Engineering)—— 追求更强的大脑
当 Agent 开始执行多步任务时,单次 Prompt 显然不够用了。我们开始管记忆、管工具、管超长对话。
在这个阶段,RAG(检索增强生成) 成为了绝对的“核心王者”。不管在哪个公司,想要让 AI 懂你的业务,就得把企业知识库、历史的 SQL 查询记录、Python 脚本规范统统向量化。核心问题变成了:怎么往有限的上下文窗口里,塞入最高质量、最相关的信息?
注意: 前两个阶段的思路,本质上都是 “以大模型为中心”。我们所做的一切,都是为了伺候好这个大脑。
💡 蜂蜜的脱水干货: 别被花哨的术语绕晕!咱拉一张全景图对比一下,前两步咱们都在拼命“卷”大脑(模型本身),而到了第三步 Harness 工程,视角完全变了——它关心的不再是模型聪不聪明,而是怎么给大脑配上好用的手脚和规矩。
⚙️ 跃迁三:Harness Engineering(马具工程)—— 追求更高的交付质量!
就在最近,OpenAI 的官方博客和 LangChain 的深度拆解里,都在高频提及一个新词:Harness Engineering。
千万别以为这又是什么割韭菜的新概念,这是一次真正的范式转变!
我上一篇文章里专门拆解过 OpenAI 那个 “3个人5个月撸出100万行代码” 的神级实验。当时我为了好理解,管它叫 “缰绳工程” ——因为你得勒紧缰绳,AI 这匹烈马才不会乱跑。
但随着研究的深入,我发现“缰绳”其实只是马具的一部分。
Harness 这个词,原意是完整的 “马具” 。驾驭一匹日行千里的烈马,光靠一条 缰绳(Prompt) 引导方向是不够的,你还得有受力的马鞍、踩得稳的脚蹬、控制速度的辔头,这一整套装备缺一不可。
Harness 的视角是“以任务的可靠完成为中心”。 在这个系统里,大模型只是一个组件(引擎),而不是全部。围绕 Agent 构建的那套精密“装备”,决定了你的系统到底是玩具还是工业品。比如像 OpenClaw 这种优秀的开源框架设计,其底层的 Gateway、Agent Engine 划分,本质上就是在构建一套强大的 Harness。
根据前沿实践,这套“马具”包含七个极其核心的修炼方向,咱们快速过一遍:
🛠️ Harness 架构全景: 这七个维度不是孤立的。规划是司令部,工具和约束是前线战壕,反馈与验证是督军。只有这几套装备咬合在一起,Agent 才能在复杂的业务环境里“跑得稳”。
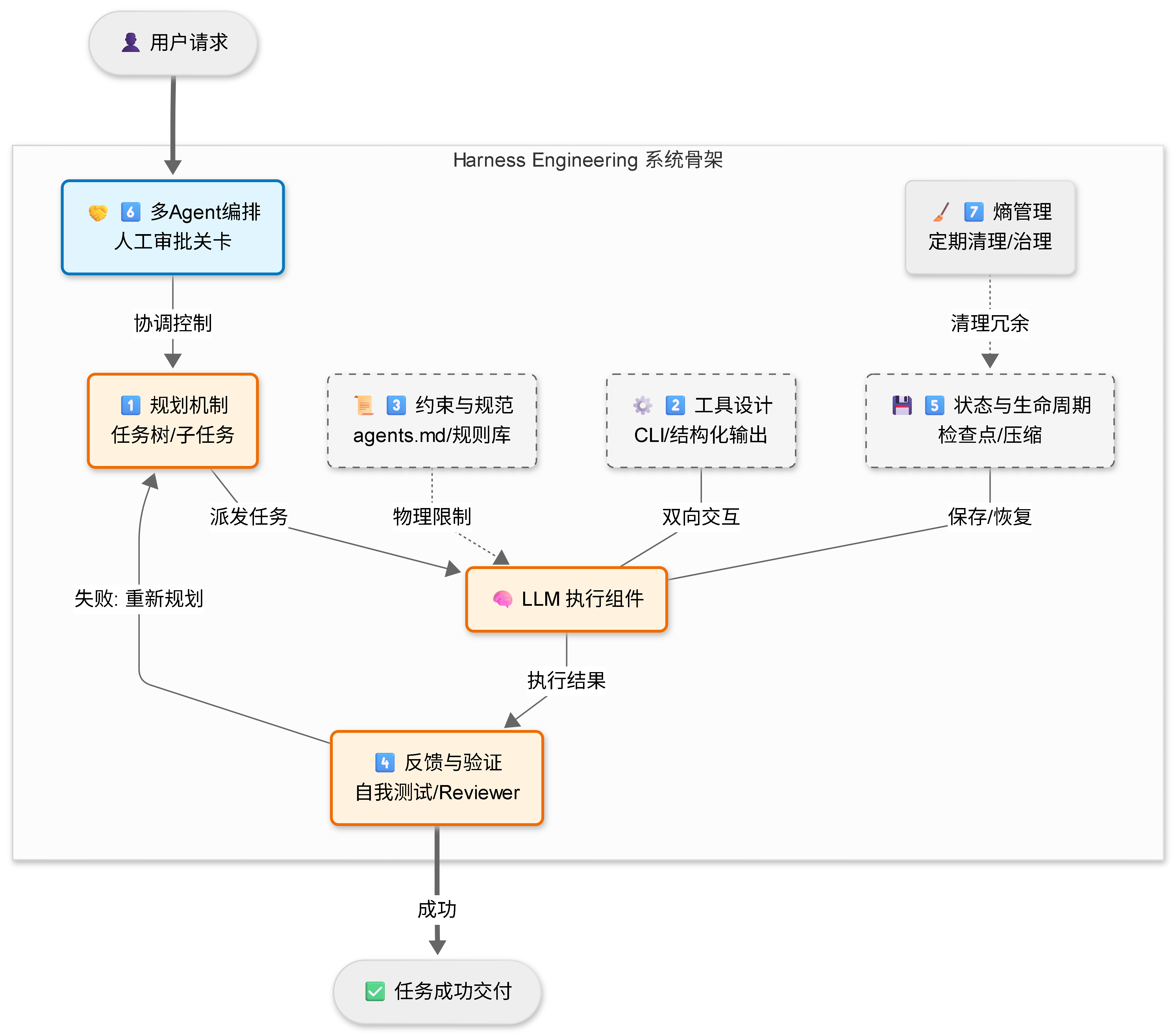
1. 🛠️ 工具设计:越“硬核”越好
给 AI 用的工具,和给人类用的完全不一样。对于 AI 来说,命令行(CLI)远大于图形界面(GUI)。 最关键的一点:报错不仅仅是把 StackTrace 抛出去就完事了。当你丢给它一个报错的 SQL,工具的返回不能只是 Table not found,而应该包含结构化的指引,比如:“表不存在,请先调用 schema 工具查看表结构”。输出必须结构化,Agent 才能解析并自我修正。
2. 🗺️ 规划机制:不撞南墙不回头?得学会绕路
面对复杂任务,系统里必须要有 “任务树” 的概念。 支持子任务拆解,支持并行执行(比如一边用 Java 写后端接口,一边用 Python 跑数据清洗验证)。更重要的是,遇到障碍时要有 重新规划(Re-planning) 的能力,而不是在一个死胡同里疯狂重试把 Token 烧光。
3. 📜 约束与规范:这才是最容易被低估的杀器!
在 Prompt 里写“请注意代码规范”那叫建议,AI 随时可能假装没看见。 真正的约束是物理规则!比如在项目中建立 agents.md 或 .cursorrules 文件。这是 Harness 最核心的运营逻辑:用错误来“喂养”规则库。AI 只要犯了错,就把这个坑变成永久写入系统的规则。系统在使用中完成自我进化。
4. 🔁 反馈与验证:别总让人类来擦屁股
让 Agent 自己跑测试、查日志、甚至截图核查。发现失败了?强制打断循环,重新规划。必要的时候,再拉一个专门的 “Reviewer Agent” 来做代码审查。极大地减少对人工 Review 的依赖,形成闭环。
5. ⏳ 状态与生命周期:AI 也会“内存溢出”
一个任务如果跑了几百步,上下文窗口早就撑爆了,AI 连自己姓什么都忘了。 这就需要 动态的上下文压缩机制。而且,如果一个跑了半小时的任务中间网络断了,必须能从 检查点(Checkpoint) 恢复,绝对不能每次都从头再来。
6. 🤝 多 Agent 编排:打群架的艺术
把一个庞大的任务,拆给多个子 Agent 并行处理,主 Agent 负责统筹协调。这里的关键是 自主性的平衡——自主性不是全有或全无。在修改生产库数据、合并核心代码等“高风险决策点”,Harness 必须强制留出人工审批的关卡(Human-in-the-loop)。
7. 🧹 熵管理:赛博空间的垃圾回收(GC)
这是最容易被忽视的一条!AI 的生产力越强,系统混乱度(熵)增长得就越快。 Agent 批量生成的中间文件、冗余代码、不一致的配置,时间一长能把仓库堆满。必须有专项的后台清理机制,定期扫描、定期治理。这不是可选项,这是与 AI 生产力配套的必要成本。
💡 蜂蜜的总结时刻
最后给大家梳理一下这套完整的进阶框架:
⏳ 总结时刻: 技术的跃迁往往是因为遇到了旧工具无法跨越的“交付墙”。从追求“说得好”到“做得对”,这正是我们作为 AI 工程师在未来两年的进阶之路。
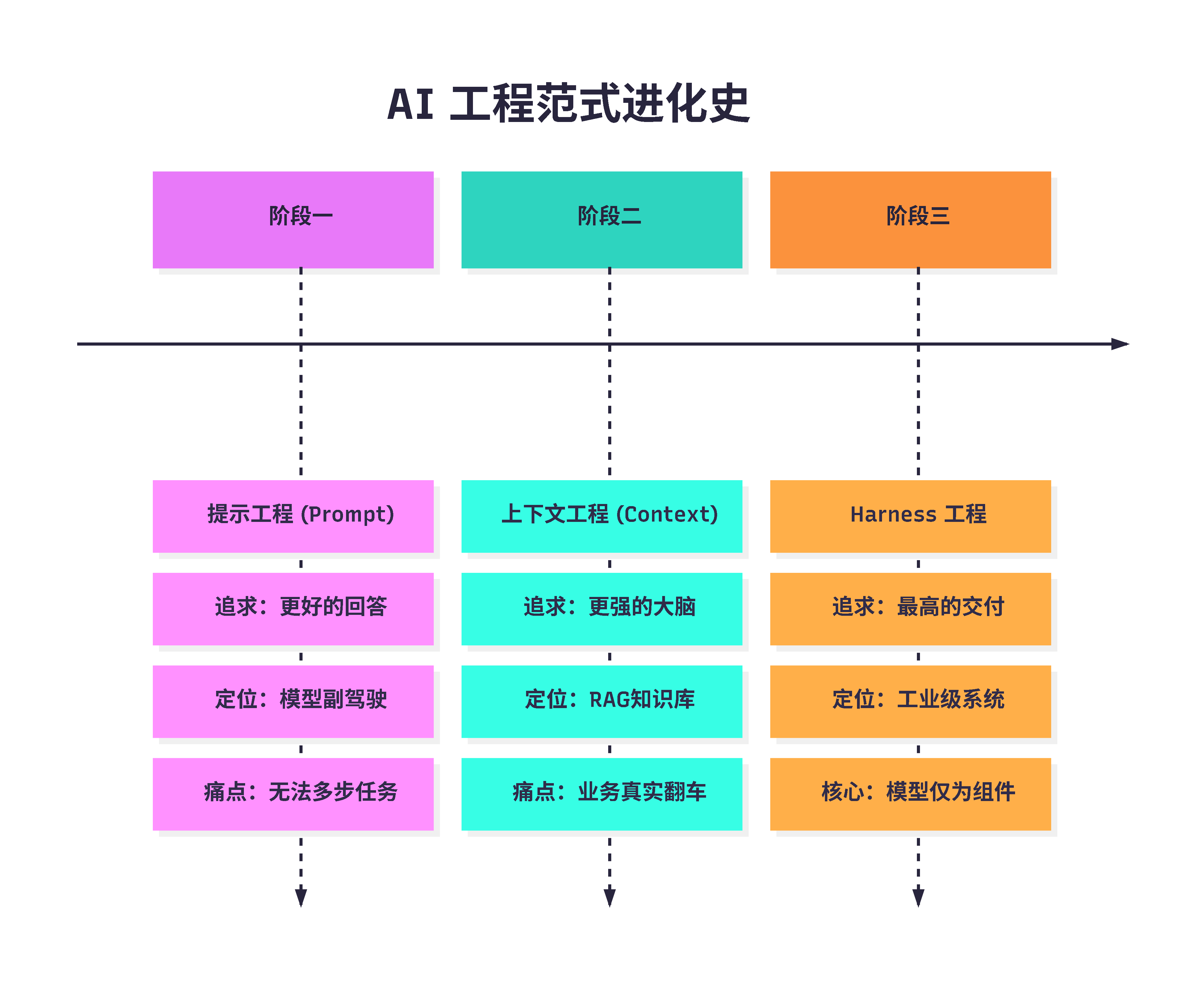
- 🎯 提示工程(Prompt):追求更好的回答。
- 🧠 上下文工程(Context):追求更强的大脑。
- 🏗️ 马具工程(Harness):追求更高的交付质量。
每一层的升级,都是因为上一层的目标实现了,却发现还有更大的工程难题没有解决。
所以各位同行们,不要再盲目焦虑模型又更新了哪几代。真正的 AI 工程能力,不在于你会用多聪明、多昂贵的模型,而在于你能不能把这个模型,稳稳当当地包在一套可靠的系统(Harness)里,交付到真实的业务场景中稳定运转。
这,才是接下来两年,真正值钱的硬核工程能力!
聊到这里,你目前在开发 Agent 的时候,在哪一层遇到的“坑”最多?是 Prompt 调不准,还是 RAG 上下文太乱,又或者是苦于没有一套好的 Harness 机制?需要在评论区和我一起探讨一下你目前的架构痛点吗? 欢迎随时留言交流!👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)