强化学习理论2 基于价值的强化学习
动态规划估计
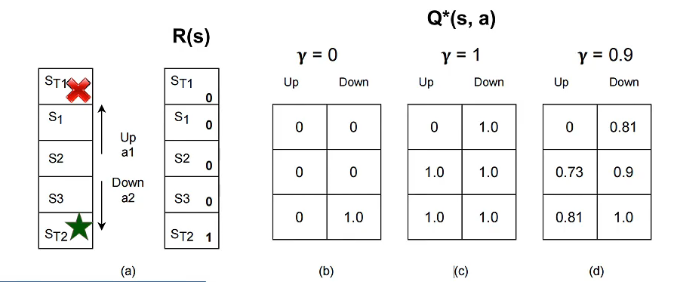
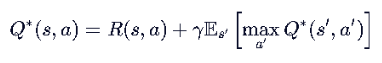
在这个例子中,根据更新公式,不同的奖励·折扣会极大影响收敛。
上面这个例子实际上是一个DP问题,因为其状态转移是肯定的,但在真实环境中,往往这种转移是有概率发生的,因此需要“蒙特卡洛估计”
(对V/对Q都可以更新)蒙特卡洛估计
-
2.2 动态规划(DP):
- 假设你知道整个 MDP 模型 → 知道 p(s′∣s,a)和 R(s,a)
- 可以直接用贝尔曼方程迭代求解 → “理论推导型”
-
2.3 蒙特卡洛(MC):
- 不知道模型! 只能跟环境交互 → 做个动作,得到下一个状态和奖励 (s′,r)
- 必须靠“实际跑轨迹”收集数据 → “实验统计型”
- 正如图中强调:“这个假设对后面思路很重要,我们只能是做个动作,然后得到环境的反馈”
📌 这正是强化学习最核心的设定:Model-Free(无模型) —— 不依赖环境内部机制,只靠交互学习。

📐 蒙特卡洛怎么估计 V(s)?【试到终点求均值 更新迭代】
回顾定义:
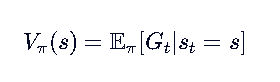
![]()
Gt是从当前这一步到终止状态的所有奖励!
意思是:从状态 s 开始,按策略 π 行动,未来总回报 G_t 的期望值。
但既然我们不知道期望是多少,那就:
- 初始化一个随机的 V(s) (比如全设为0)
- 让智能体按照当前策略 π 去玩很多轮游戏(episode)
- 在每一轮游戏中,每当访问到状态 s,就记录下从那一刻起直到 episode 结束所获得的实际总回报 G_t
- 把所有这些 G_t 加起来求平均 → 就是 V(s) 的估计值!
或者更工程化一点,用增量更新公式(图中给出):
🔄 同样适用于 Q(s, a)
Q 函数的定义是:
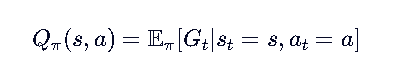
所以做法完全一样:
- 记录所有在状态 s 执行动作 a 后,后续得到的实际总回报 G_t
- 对这些 G_t 取平均 → 得到 Q(s, a)
- 也可以用增量更新:
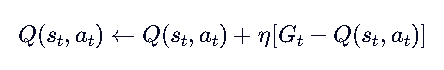
🧭 有了 Q,就能改进策略!
图中最后一行:
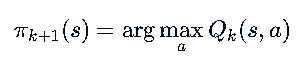
意思是:
我们用当前的 Q 估计值,在每个状态下选那个看起来最好的动作 → 得到新策略 π_{k+1}
这其实是一个策略迭代的过程:
- 用当前策略 π_k 去采样,估计 Q_k
- 用 Q_k 贪心地更新策略 → π_{k+1}
- 再用 π_{k+1} 去采样,重新估计 Q_{k+1}
- 重复… 直到收敛到最优策略!
⚠️ 注意:这里有个隐含前提 —— 要保证探索(exploration),否则可能陷入局部最优。比如可以用 ε-greedy 策略。
一言蔽之
这是一个交叉更新的过程,一开始VQ都是0,然后让模型随机探索地图,每次到达st开始记录从这里到结束的实际值Gt,然后用Gt-Qt乘以更新步长η去更新在st的估计值Qt。
更新到完全收敛,会得到每个状态下最优的动作a,这就是更新后的策略,接下来,按照这个新策略重新更新Qt,再更新Π,交替执行。
| 特性 | 动态规划 (DP) | 蒙特卡洛 (MC) |
|---|---|---|
| 是否需要模型 | ✅ 需要 | ❌ 不需要 |
| 更新时机 | 每一步都可更新(bootstrapping) | 必须等 episode 结束才更新 |
| 方差 | 低 | 高(因为依赖完整轨迹) |
| 偏差 | 无偏(如果模型准确) | 无偏(只要采样足够多) |
| 适用场景 | 小规模、已知模型 | 大规模、未知模型、真实环境 |
(对V更新)时序差分法
从上表看出,蒙特卡洛是基于随机采样更新策略的,这样的方差很大,也很耗时间。
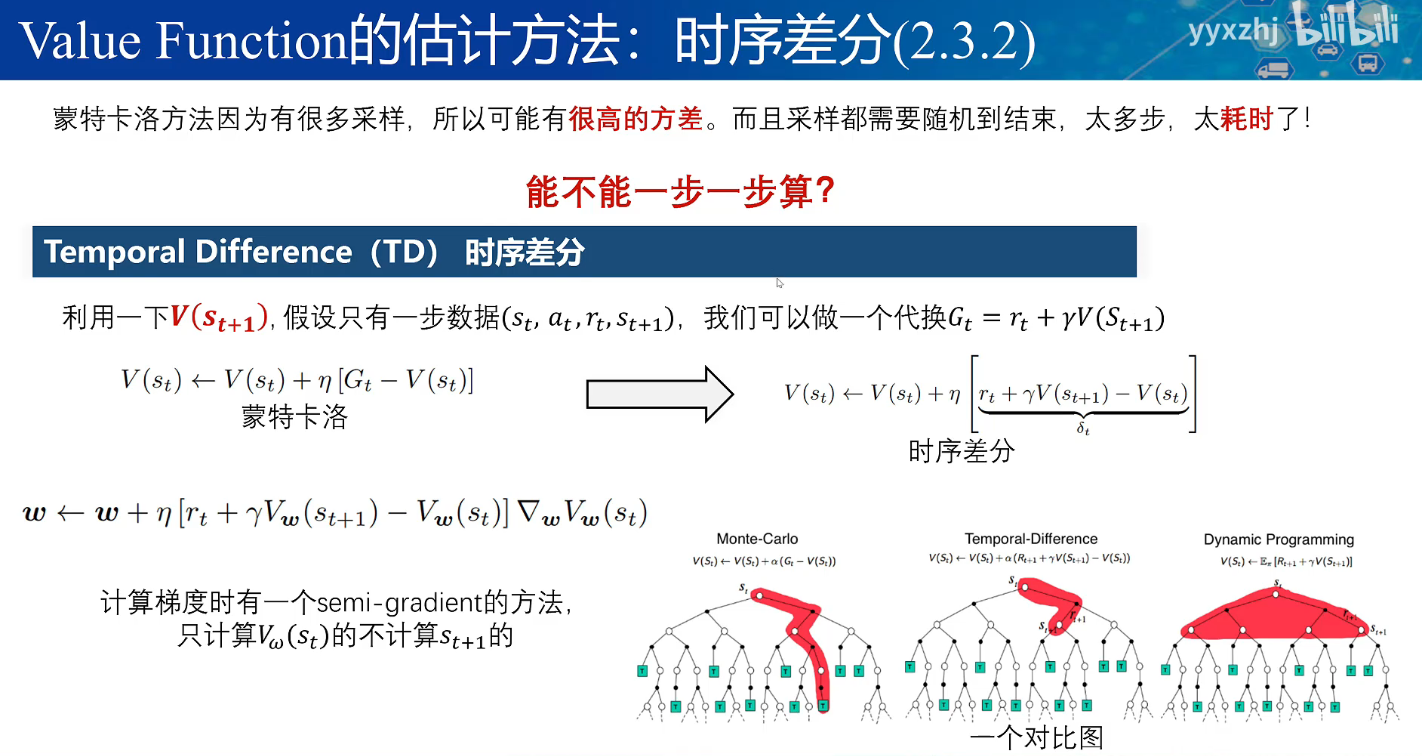
为此,我们可以将Gt截止到下一步就更新,这样的更新就更加稳定,也更快。
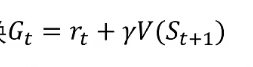
这是一个交叉更新的过程,一开始VQ都是0,然后让模型随机探索地图,每次到达st开始记录从这里到结束的实际值Gt,然后用Gt-Qt乘以更新步长η去更新在st的估计值Qt。
更新一段时间后,会得到每个状态下较优的动作a(不用等收敛,否则太久了),这就是更新后的策略,接下来,按照这个新策略重新更新Qt,再更新Π,交替执行。
总结一下,
对于蒙特卡洛,是要走到终点才更新策略,时序差分是走一步就更新策略,而动态规划需要遍历所有的状态,得知准确的状态转移情况才能执行。
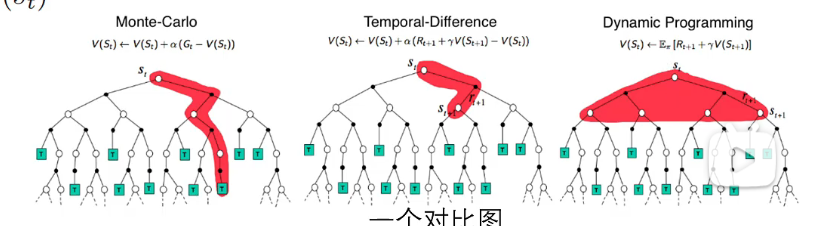
更普遍的,可以选择前n步使用蒙特卡洛(真实估计),后面到终止状态使用时序差分,每次更新一步。
| 项 | 含义 | 来源 |
|---|---|---|
rt,rt+1,...,rt+n−1 |
从 t 到 t+n-1 的实际获得的奖励 | 👉 蒙特卡洛风格 —— 依赖真实环境反馈 |
| γnV(st+n) | 对未来从 t+n 开始的回报的估计值 | 👉 TD 风格 —— 用当前学到的 V 函数“猜”剩下的部分 |

(对Q更新)SARSA法
前面对V的更新方法很优秀,但是
🅰️ 如果你只更新 V(s) :【只存储了状态】
- 你知道什么:你知道站在某个位置 s 大概能得多少分。
- 你不知道什么:你不知道具体往哪个方向走能拿到这个分。
- 例如:你知道站在“悬崖边”分值很低(危险),但你不知道是“向左跳”安全还是“向右跳”安全,除非你有环境模型。
- 如何决策(选动作):
- 必须依赖模型:你需要知道 p(s′∣s,a) 和 R(s,a) ,然后做一个一步前瞻计算:
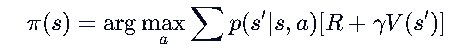
🅱️ 如果你更新 Q(s,a) :【Q是状态-动作价值,存储了当前状态对应的最优动作,可以直接得到】
- 你知道什么:你直接知道在状态 s 下,做动作 a1,a2,a3... 分别能得多少分。
- 如何决策(选动作):
- 不需要模型! 直接查表取最大值:
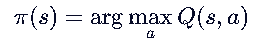
在Q领域,对应时序差分的方法是SARSA

⚠️ 注意:这里有个隐含前提 —— 要保证探索(exploration),否则可能陷入局部最优。比如可以用 ε-greedy 策略。
举个例子:

假设你用的是 ε-greedy 策略(这是最常用的):
- 以概率 1−ϵ :选择当前 Q 值最大的动作 → 即 “上”
- 以概率 ϵ :随机选择一个动作(左、右、上、下等概率)
| 情况 | 概率 | ||
|---|---|---|---|
| 贪婪选择 | 1−ϵ | 上 | 2.3 |
| 随机探索 | ϵ/4 | 左 | 0.5 |
| 随机探索 | ϵ/4 | 右 | -1.0 |
| 随机探索 | ϵ/4 | 下 | 0.1 |
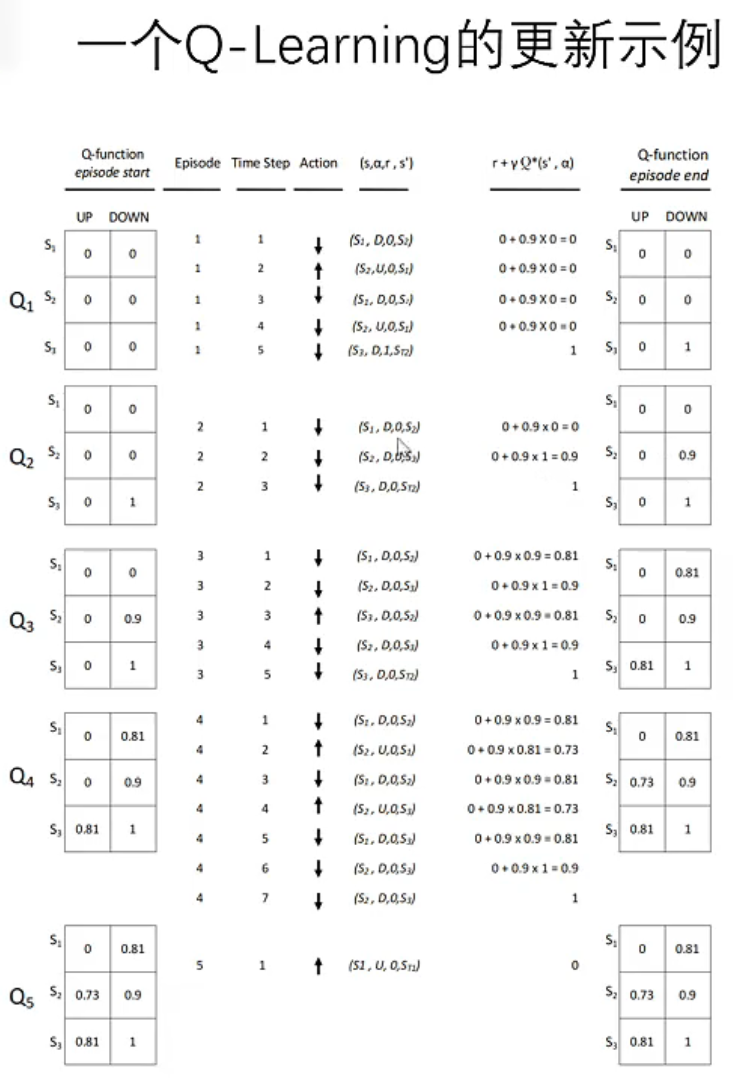
(对Q更新)Q-LEARNING法 贪婪
SARSA有个弊端,就是每次选择动作时,只能选当前策略下的Q,不能用以前的Q。这就导致了可能以前的Q比现在的价值高,但受限于策略,不能使用。这时候就需要Q-LEARNING了,这个策略的更新公式是:
![]()
![]()
用上一题的例子:

你不需要“知道”未来的最优动作 Q 是多少。
你只需要:
- 查当前的 Q 表。
- 取最大值。
- 假设那就是最优的。
- 更新。
- 重复无数次。
| 维度 | 蒙特卡洛 (MC) | 时序差分 (TD) -> SARSA | 时序差分 (TD) -> Q-Learning |
|---|---|---|---|
| 更新对象 | V 或 Q | 专门用于 Q (也有 V 的变体但少见) | 专门用于 Q |
| 目标值构成 | 真实全程回报 Gt |
r+γQ(s′,实际动作) | r+γmaxaQ(s′,a) |
| 策略类型 | On-Policy (通常) | On-Policy (评估的就是当前行为策略) | Off-Policy (评估的是最优策略,行为可以是随机的) |
| 对待探索 | 包含在采样中 | 谨慎:知道你会乱动,所以避开风险 | 乐观:假设你以后不乱动了,直取最优 |
| 典型场景 | 棋盘游戏(局短) | 机器人控制(需安全) | 游戏 AI(追求高分,可重试) |
总结:【策略】-【问题】-【新策略】
首先介绍了强化学习的基本概念,智能体的 当前状态、动作、策略、状态转移函数,以及强化学习的目的。
接着介绍了奖励函数Gt的设定和折扣因子
然后开始讲 状态价值函数V(当前状态价值) 状态行动价值Q(做了这个动作后的价值) 最优函数 贝尔曼迭代方程(最优QV迭代)
【DP】开始讲MDP马尔可夫决策过程,如何基于已知的环境迭代出最优的策略
【MC】但对于环境未知且会变化的情况,就需要蒙特卡洛采样法了,这是一种【从st试到重点求Gt的方案】,每次到终点了更新一次策略
【TD】但到每次到终点太久了,因此考虑每走一步迭代一次,这就是时序差分方法
【MIX】还有一种混合算法,前n步使用蒙特卡洛,后续Gt使用时序差分
【SARSA】上面都是基于V的优化,V的参数不含动作,因此无法得到当前状态下应该如何做,这就需要SARSA了,一种基于Q的更新方式,他的更新逻辑和时序差分一致,但是需要ε-贪心策略保证一定的随机性,我们举了个例子。
【QLEARNING】但sarsa只能选择当前策略下的动作Q,而不是直接找最大预估值Q,这就需要QLEARNING算法了,尽管这个Q是预估的,不准确的,但是会在更新后趋于稳定。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)