AI Infra Baseline 的构想

很多 AI 系统一开始都能跑,跑着跑着就容易变乱。
经常出现请求入口混乱、Agent 被滥用、状态乱放、推理层职责混乱、GPU 资源利用低等问题。
轻则响应慢,影响客户体验。
重则成本失控,系统崩溃。
设计这个基线,核心目标是在可控前提下,收敛复杂度,实现可复用。

常见问题
1、请求入口混乱
有人直接调模型,有人自己接工具,有人另外起一套 Agent 流程。
如果整个平台没有统一管控,限流、优先级、资源分配这些东西也很难真正生效。
同样一批请求,有些走平台,有些绕过去直接打 GPU,整套系统越来越难控。
2、Agent 被滥用
很多任务其实普通推理就够了。
有时候为了炫技,什么都往 Agent 里塞。
这样做下来,延迟高了,成本上去了,链路也更复杂。
一个本来一句话就能答完的问题,被拉成长流程,多走好几步,没必要。
3、状态乱放
会话信息、中间结果、任务进度,如果都放在某个服务实例自己的内存里,机器一重启,或者服务一扩容,前面的上下文就接不上了。
比如用户的任务做到一半,实例挂了,后面只能从头再来,这种体验会很差。
4、推理层职责混乱
如果把业务判断、工具调用、状态管理都塞进模型服务,短时间看起来省事,后面基本会变成一个谁都不敢动的大黑盒。
想换推理引擎,发现里面绑了很多业务逻辑,根本换不动。
想做性能优化,甚至只是想查个问题,都会很吃力。
5、GPU 资源利用低
请求如果不先统一调度,很难做好排队、合批和负载分配。
结果一些卡很忙,另外一些很闲,整体吞吐并不好。
GPU 利用率低的情况下,很难再向公司申请买新卡。
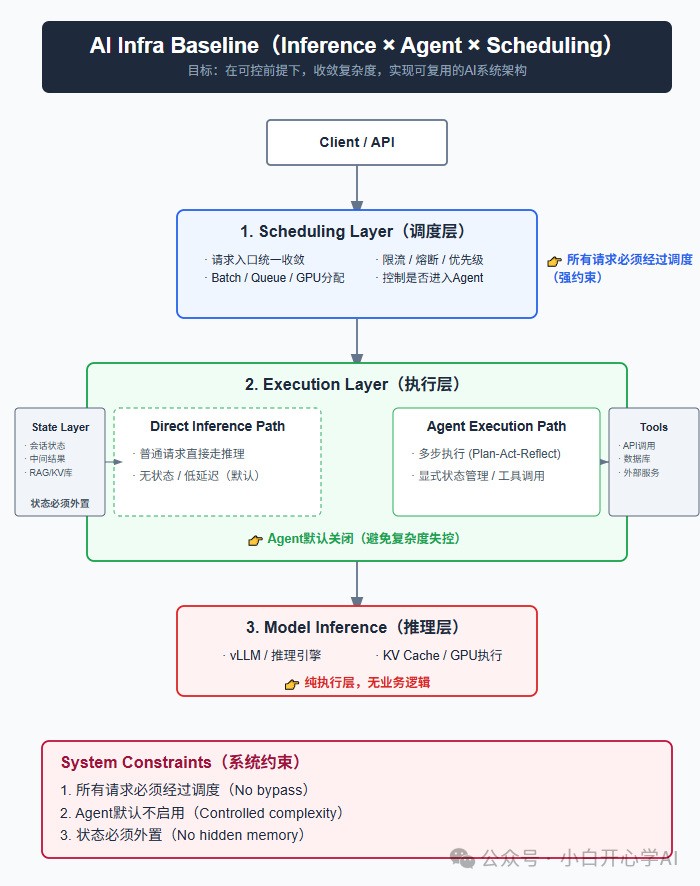
AI Infra Baseline
为了解决上述问题,我构思了一套面向 AI 系统的基础架构基线。
这是一套 GPU 友好的架构。
调度、执行、推理 ,三层分开。
Agent、状态、工具,放在受控的位置。
既能迭代,又不至于失控。
系统分成三层:
第一层、Scheduling Layer(调度层)
负责请求的分配和治理。
统一接收请求。
做 Batch / Queue / GPU 分配。
限流、熔断、优先级控制。
并决定是否进入 Agent。
第二层、Execution Layer(执行层)
负责请求该走哪条执行路径。
分成两条路:
-
Direct Inference Path:普通请求直接推理,无状态、低延迟、默认走这条
-
Agent Execution Path:多步执行、状态管理、工具调用
第三层、Model Inference(推理层)
负责模型怎么真正跑起来。
放的是 vLLM / 推理引擎、KV Cache / GPU执行 这类纯推理能力。
只负责执行,不放业务逻辑。
旁边有 2 类外部依赖:
-
State Layer:会话状态、中间结果、RAG/KV 库
-
Tools:API、数据库、外部服务
底部是 3 条系统约束:
-
所有请求必须经过调度
-
Agent 默认不启用
-
状态必须外置

为什么所有请求必须经过调度?
与互联网相比,AI 系统单次请求成本更高,差异更大。
请求长短不一、到达时间随机。
有的是简单问答,有的需要复杂推理。
而 GPU 天生不适合处理大量、零碎的小任务。
更适应稳定连续的任务流、尽量少的切换和抖动、大批量并行和可预测的显存占用。
如果没有调度,各式各样的请求会直接把 GPU 干得稀碎。
所以,调度层的本质是把随机、零散、差异很大的请求,整理成 GPU 更擅长处理的稳定并行任务流。
从而提高利用率、降低浪费、保护关键业务。
为什么 Agent 默认不启用?
基于 Transformer 的大模型是一个概率机器,天生有幻觉、输出不稳定的问题。
Agent 步骤多,出错的概率会随着链路的延长而变大。
而且,多次调用,代价也高。
系统会更慢、更贵。
很多简单请求,其实直接推理就够了,没必要一上来就走 Agent。
所以默认不启用,是为了把复杂能力收住。
只有在确实需要多步执行时再打开。
这样系统会更稳,成本也更容易控制。
为什么状态必须外置?
系统每走一步,都依赖当前状态和新输入,然后产出新状态和输出结果。
状态外置,就是把这个当前状态从进程内部拿出来,变成一个可存储、可读取、可恢复的显式变量。
如果状态放在服务自己的内存里,服务一重启、扩容或者切机器,状态就可能丢掉,流程也容易断。
把状态外置后,会话信息、中间结果、任务进度都能被保存下来,系统更容易恢复、扩展和排查问题。
这样多步任务也能接着跑,不会因为实例变化就全丢了。
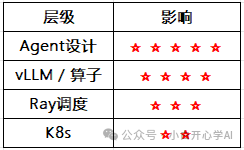
为什么把系统治理能力放在入口?
对于软硬一体的 AI 系统,Agent 设计是提高整体性能、GPU 使用率最有效的地方。
在入口对所有请求进行调度,是 Agent 设计中效率最高的做法。
限流、熔断、优先级、排队、资源分配这些能力,本质上都属于平台治理能力。
如果请求绕过调度层,就会出现资源争抢、延迟抖动、线上不稳定、问题难定位等问题。

Batch / Queue / GPU 分配为什么放在调度层?
Batch :打包
把多个请求凑在一起处理。
作用是提高吞吐。
GPU 更擅长一次处理一批任务。
很多小请求拼在一起,通常比一个个单独跑更省算力。
Queue :排队
让请求先排队,按顺序或优先级等待。
作用是稳住系统。
请求多的时候,先排队,系统才不会一下子被打爆。
也方便控制优先级、限流和等待顺序。
GPU 分配 :派活
决定这个请求该交给哪张 GPU、哪个推理实例去跑。
避免有的卡很忙,有的很闲,让整体利用率更高。
这三件事本质上都属于统一分配和统一治理。
放在调度层之后,系统才能从全局看请求和资源。

限流、熔断、优先级控制为什么要放在调度层?
限流
限制请求进来的速度或数量,避免系统一下子被撑爆。
作用是保护系统稳定。
熔断
当某个服务已经很慢、很多错误,或者快撑不住时。
先暂时拒绝或跳过这部分请求,别让问题继续扩大。
作用是防止故障扩散。
优先级控制
先处理重要请求,一般请求后处理。
作用是保证关键业务先拿到资源。
这三件事本质上都是入口治理。
请求一旦深入到推理服务,再去做这些事就晚了。

为什么推理层是纯执行层?
推理层的职责就是把模型跑起来。
完成计算,把输入变成输出。
推理层是纯执行层。
从数学上看,就是把它看成一个相对纯粹的映射函数。
有以下好处:
-
职责清楚,边界明确
-
更容易围绕 GPU 和推理引擎做性能优化
-
更容易替换模型或推理框架
-
出问题时更容易定位是哪一层的问题
如果把业务判断、流程控制、状态管理、工具调用这些东西也塞进推理层。
这一层就会越来越乱。
后面很难优化、排查和替换。

算力有限,所以调度优先。
成本敏感, 所以路径分流。
稳定优先,所以显式状态。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)