【专栏二:深度学习10】-【一张图讲清楚:为什么既要做数据归一化?又要划分 Train / Val / Test?】
文章目录
很多人刚开始训练模型时,会犯两个非常典型的错误:
- 直接把原始数据丢进去训练
- 用同一份数据既训练又评估
结果就是:
- 模型训练不稳定
- 评估结果不可信
但他们往往不知道问题出在哪。
其实原因很简单:模型训练前,有两件必须做的事:数据归一化 + 数据划分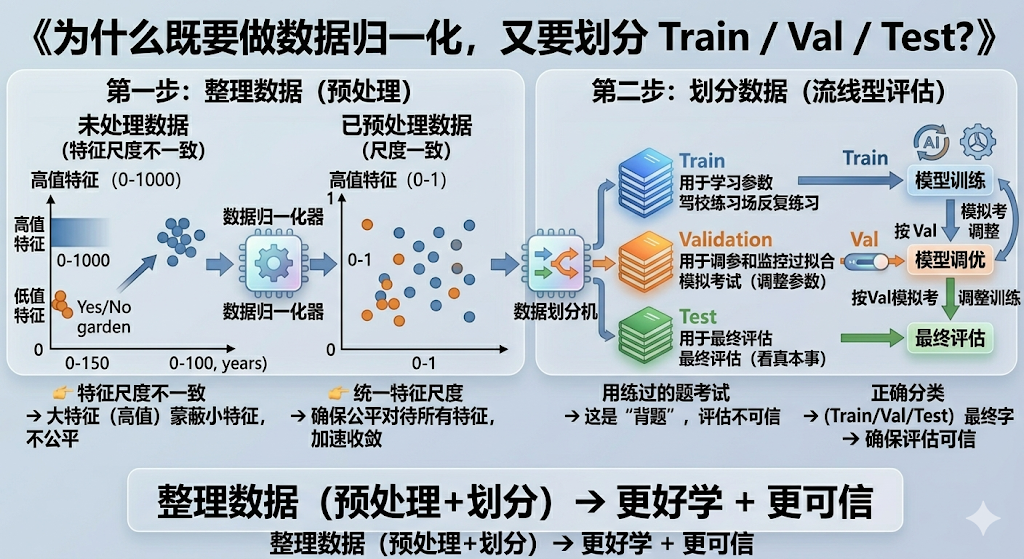
这张图其实在讲一个完整流程:
- 原始数据 → 数据归一化 → 数据划分 → 训练 → 验证 → 测试
你只要顺着这条线看,就能理解:
👉 为什么既要“处理数据”,又要“划分数据”
一、第一步:为什么要做数据归一化(左半部分)
先看图的左侧。
你会发现一个问题:
- 有的特征范围是 0~1000
- 有的特征只有 0~1
👉 这就是:特征尺度不一致
1.会带来什么问题?
模型在训练时,本质是在做加权计算:
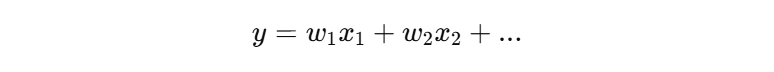
如果:
𝑥1很大(比如 1000)𝑥2很小(比如 0.1)
那么模型更容易被“大数值特征”主导。
👉 结果就是:
- 小特征被忽略
- 学习不公平
- 训练过程不稳定
2.从优化角度看(关键理解)
你可以把训练想象成:
👉 在“山谷”里找最低点(梯度下降)
- 未归一化:山谷又窄又扁 → 走得歪、来回震荡
- 归一化后:山谷更圆 → 更容易找到方向
👉 这就是图左边在表达的核心:
归一化 = 统一尺度,让模型更容易学习
3.怎么做归一化?
最常见的方法是标准化:
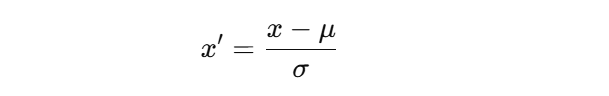
简单理解:
- 减去平均值
- 再除以标准差
👉 让所有特征处于相似范围,左半部分总结一句:
归一化的本质,是让模型“学得更顺”
二、第二步:为什么要划分 Train / Val / Test(右半部分)
再看图右侧。这里在讲另一件完全不同但同样重要的事:如何正确评估模型
为什么不能用同一份数据训练和评估?看图里的类比:“背过的题 vs 真考试”
如果你:
- 用同一份数据训练
- 再用这份数据评估
那就相当于:考前把答案背了一遍,再去做同一张试卷, 结果当然很好,但没有任何意义。
正确做法:三份数据,图中已经帮你拆好了:
1️⃣ Train(训练集)
- 学参数
- 不断优化模型
2️⃣ Validation(验证集)
- 调整模型(学习率、结构等)
- 判断是否过拟合
对应你之前学的:val_loss 上升 = 开始过拟合
3️⃣ Test(测试集)
- 最终评估模型
最关键的一点(必须记住):Test 集只在最后用一次,不参与训练和调参
这一部分的本质
数据划分,是为了让评估“可信”
三、把两件事串起来(这才是这篇的重点)
现在你可以把整张图串起来看:
左边在解决什么?
👉 数据归一化:让模型更容易学(训练问题)
右边在解决什么?
👉 数据划分:让结果更可信(评估问题)
两者本质不同,但缺一不可:
- 只做归一化,不划分数据 → 评估会骗人
- 只划分数据,不归一化 → 模型学得很痛苦
一句话总结整张图:
归一化让模型学得顺,数据划分让结果更可信
四、最容易踩的两个坑(帮你补全认知)
1.坑1:用全部数据做归一化
很多人会这样做:
- 用全部数据算均值和方差
- 再做归一化
这是不对的
正确做法是:只用训练集计算归一化参数,再应用到 Val/Test
否则就会:数据泄露(Data Leakage)
2.坑2:反复用 Test 调模型
如果你:
- 一边看 Test 结果
- 一边调模型
那么:Test 就不再是“真正没见过的数据”,评估就失去意义了
五、最后总结
你只需要记住这三点:
1️⃣ 数据归一化:解决“模型好不好学”
2️⃣ 数据划分:解决“评估准不准”
3️⃣ 两者都是训练前必须做的准备工作
最核心一句:
一个影响训练效率,一个决定评估可信度

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)