NovelClaw-一个为长篇小说创作者而诞生的工具
为什么要做这个工具?
开发者的自述:
其实我在做这个工具的心路历程是很复杂的,从去年12月开始的时候我还在研究多模态视频生成,研究如何把ai生成的视频做长,像老师做的Vimax还是市面上的任何视频工具(像最好的seed2.0),都没法做到生成长视频的问题,主流的工具设定为不超过15秒,vimax也最多一次可以生成一分钟(尽可能保证好效果的前提),但是如果要满足未来的ai生成视频的需要这种问题肯定得需要解决的(像抖音最初爆火的告示牌,还是大只切,还是鸽羽等都是在远远超过这些结果的),那现在大家是如何完成的呢?
只能靠一次次的迭代,靠之前信息提取出关键信息,像人物,像场景,包括现在很多论文的agent框架还是其他模式的框架,都是往这个方向靠近,但是对于一个开始并没有多模态视频基础的我,训练出一个想要的模型肯定是不现实的,于是我又发现了wan2系列的模型,虽然我不会训模型,但是它的思路给的很不错!去利用好动态memory机制,就是让你每次选择出最核心最想要的信息存储下来!当然经过几次不断和老师讨论,最后发现要做好一个好的长视频生成,必须要有一个好的长剧本,但是长剧本怎么来呢?我第一个创新点想到的就是利用好动态memory机制,后来发现挺多人其实尝试去利用这个了,也不算创新点吧hhh,但是就现在如果不去训练一个专门去写作的大模型的话,利用好multiagent模式肯定是解决这些问题的最核心办法。
就此我开始了研究如何去创作出一个好的长文本小说创作工具!并以此作为我的research对象,先不对国外而言,就对中国而言,长创意文本的市场是很大的,各种小说软件层出不穷,但是针对ai写作的问题其实也保持着两个观点,是用?还是不用?但是就我而言,我是去解决这个问题的,所以我当然选择用,但是最后我发现要写出一个好的文章,只能是靠作者本人,ai永远只能成为你的工具,当然就我的研究而言我创作了两种模式,往后我也会不断介绍创新点和我的创作模式,当然前面上述内容只针对于国内场景
怎么做了这个工具?
协同式创作
首先就前面讲的要去写好一个小说,就离不开作者本人,又因为之前刚好听了斯坦福的一位学姐的会议研讨,她之前发表的ICML2025的best paper的思路就可以很好的利用在这里面(感兴趣的可以去搜一下,针对协同式训练的),协同式创作怎么用在这里面的呢?针对idea的创新进行,要让ai给你讲一个好的故事,一个满足作者和读者的故事,作者的idea在里面是必不可少的,那么我们需要去做的是什么,以协同式的形式去完善和帮助作者完成它的idea,通过不断的引导-这个过程在gpt-research模式应该也可以知道,只有有了这个完善且符合作者想法的idea,才能帮助作者更好的去生成论文!
而且我们决定训练一个小模型(huggingface到时候会发布)来帮助我们完成这个任务,这个问题我在之前的博客也说过。下面展示一些我们线上版的版本
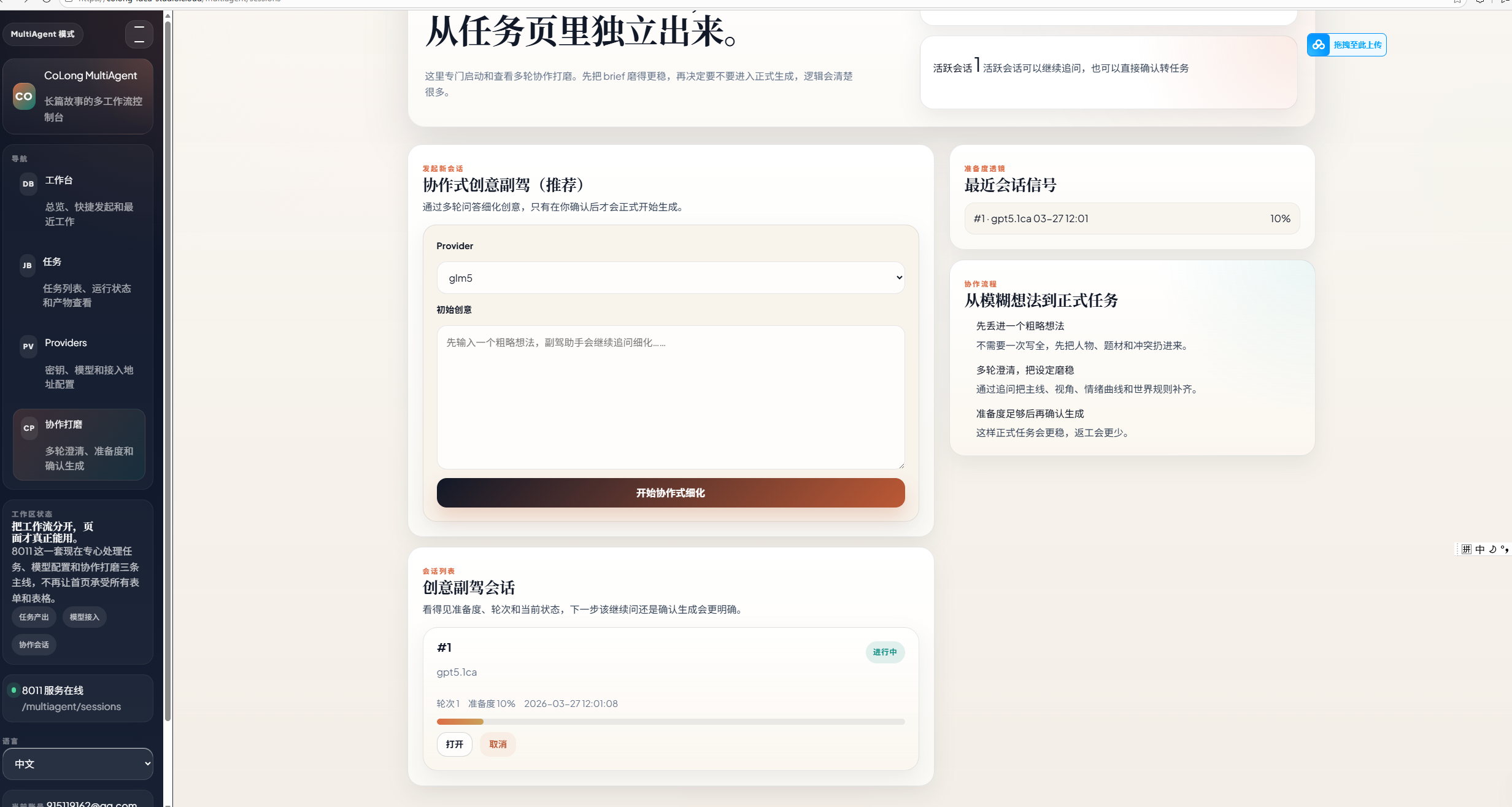
两种模式:一次性idea生成+claw模式
一次性idea生成
这里我取名为multiagent,有部分原因是因为我认为它就是单纯的一个workflow模式,没有什么好去调整的,至于为什么会有这个模式,主要是针对research做的,我们知道创作者想创作肯定要和创作者本人离不开,而且针对每一个章节的创作都是要参与其中的,那么为什么要设计一个一次性生成的模式呢?毫无疑问,benchmark和论文需要,我们实际要解决的问题是什么?当然是针对ai一次性生成长创意文本的问题,那么如何检测呢?当然是靠你一次性生成的结果,而不是人类参与其中,我们就为什么ai没法生成长创意文本进行讨论一下,首先是幻觉问题!ai在有限的token下没办法接收好那么多的信息,肯定会产生幻觉,要么是情节要么是人物等,这也是主流问题,我们只能找到最优的抑制办法,没办法完全消灭这个幻觉问题,另一个是情感方面的问题,如何解决好ai在生成小说的情感问题也是很重要的,ai在生成生成着往往会情感差异很大,或者不合理,总而言之,都是token和训练集造成的,但是我们却没办法完全解决!
那么我们用什么办法来抑制这个呢?后续我会指出我目前使用且用在论文里的两种方案!这里我先展示一下线上的一次性idea生成的模式
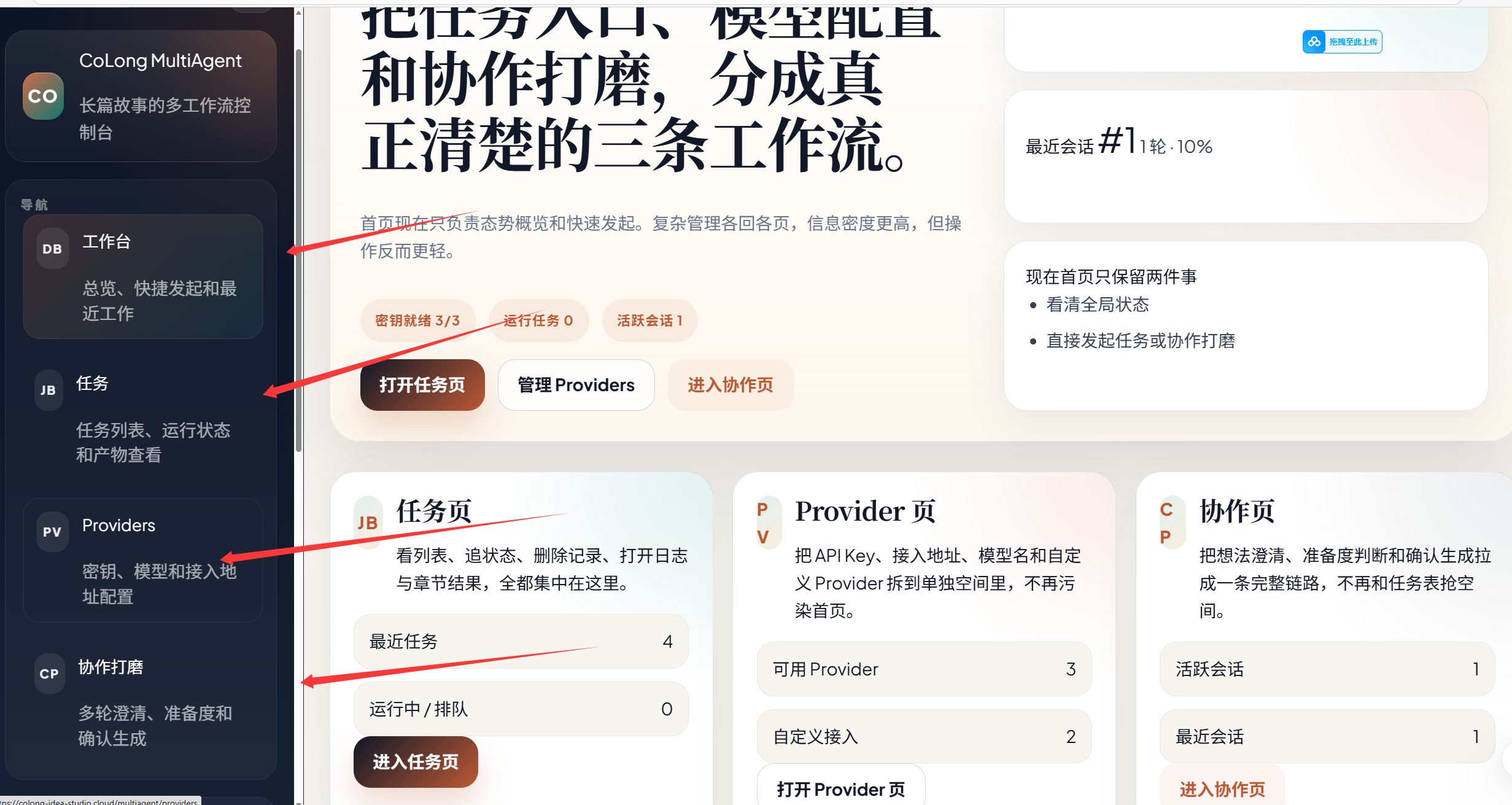
首先是两种模式,一种是有协同式打磨的,一种是直接生成的,这个也其实是之前为设计消融实验设计的!然后是看每次任何和放api-key的位置
可以自己取消和放在那里让它持续工作,线上是测试所以可能没法融入很多人
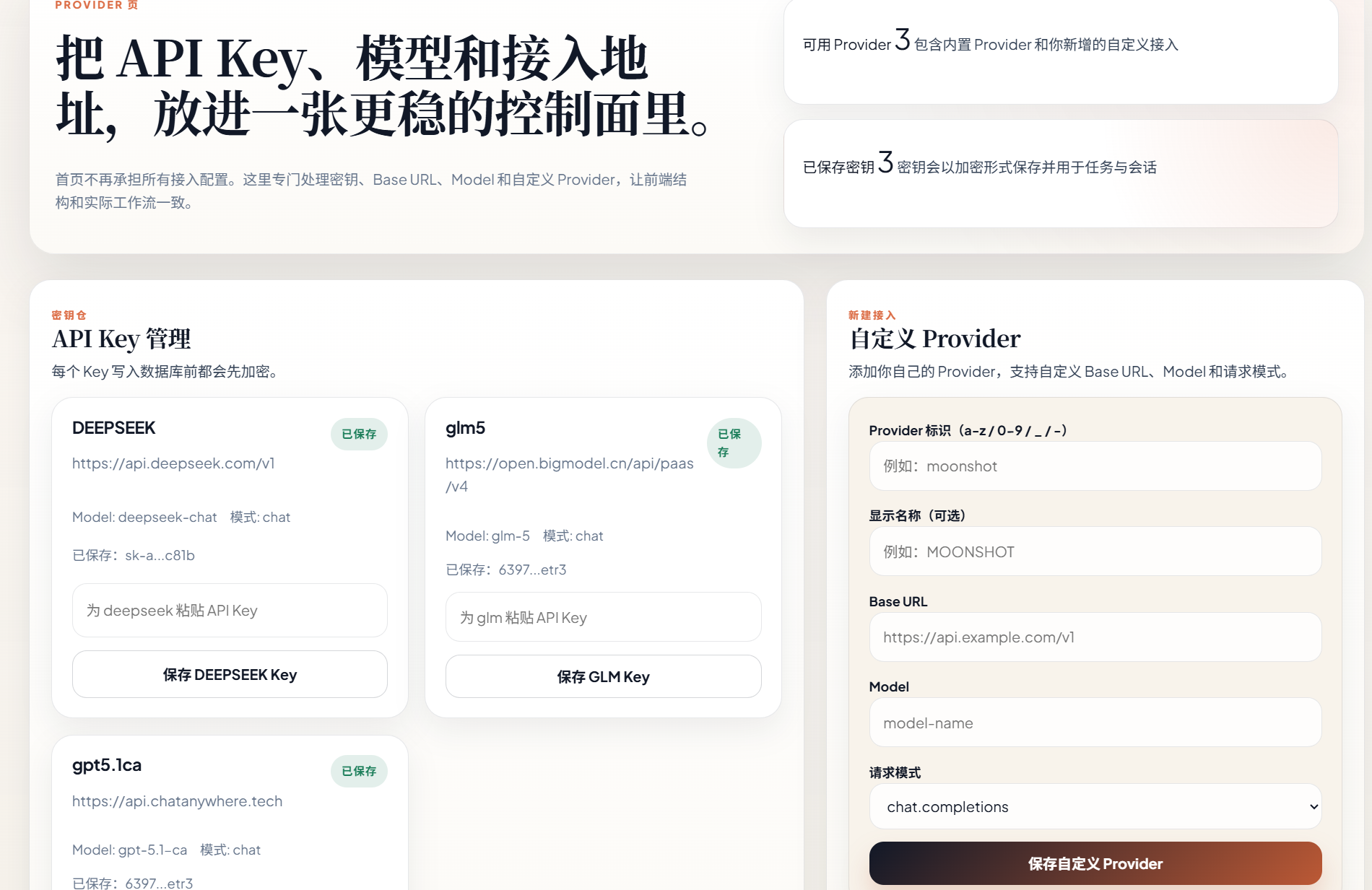
api-key基本上所有都使用直接填即可
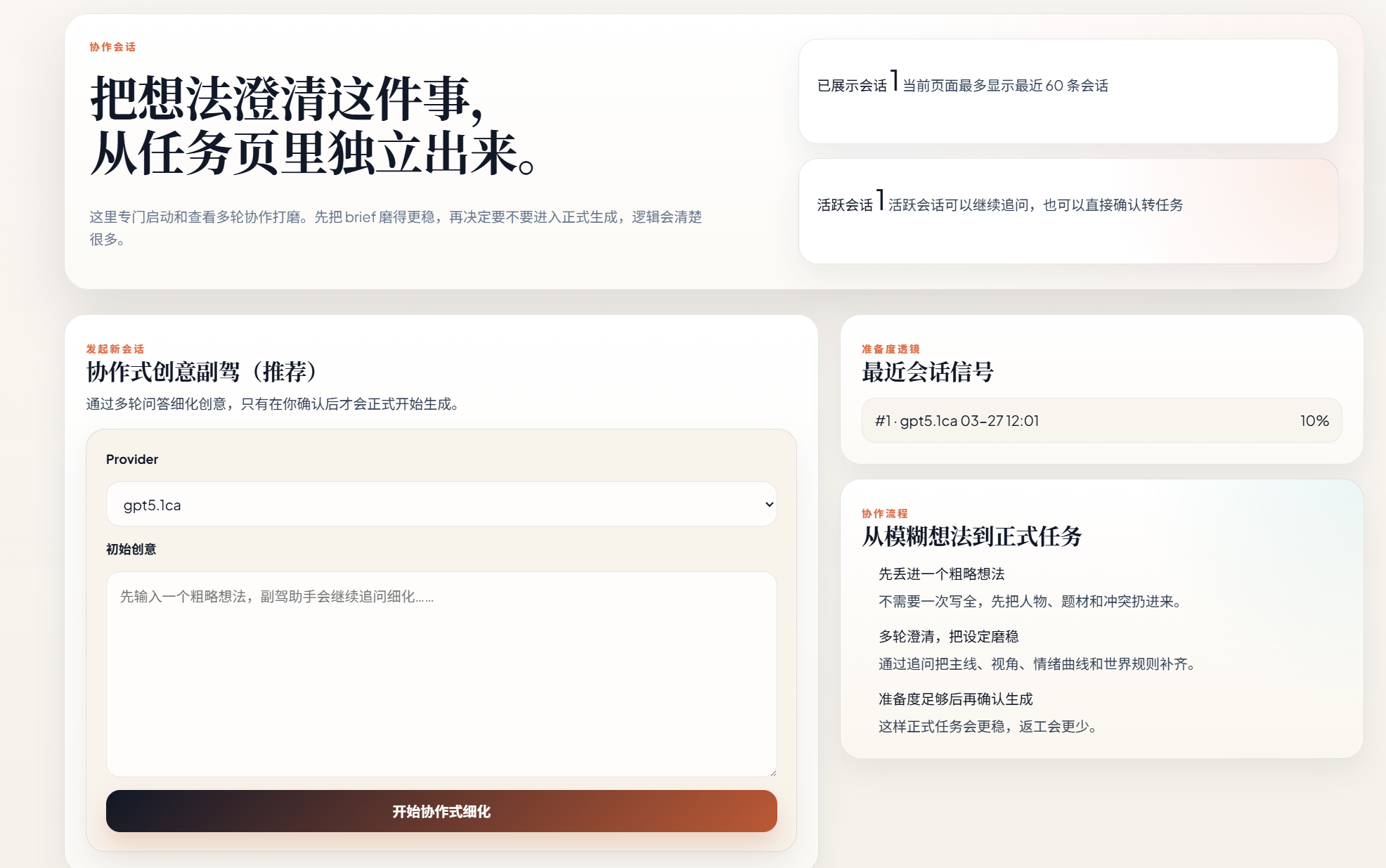
协同式和一次性生成本质区别并不大,好的至此我的一次性idea生成的展示就结束了,然后我们到claw模式
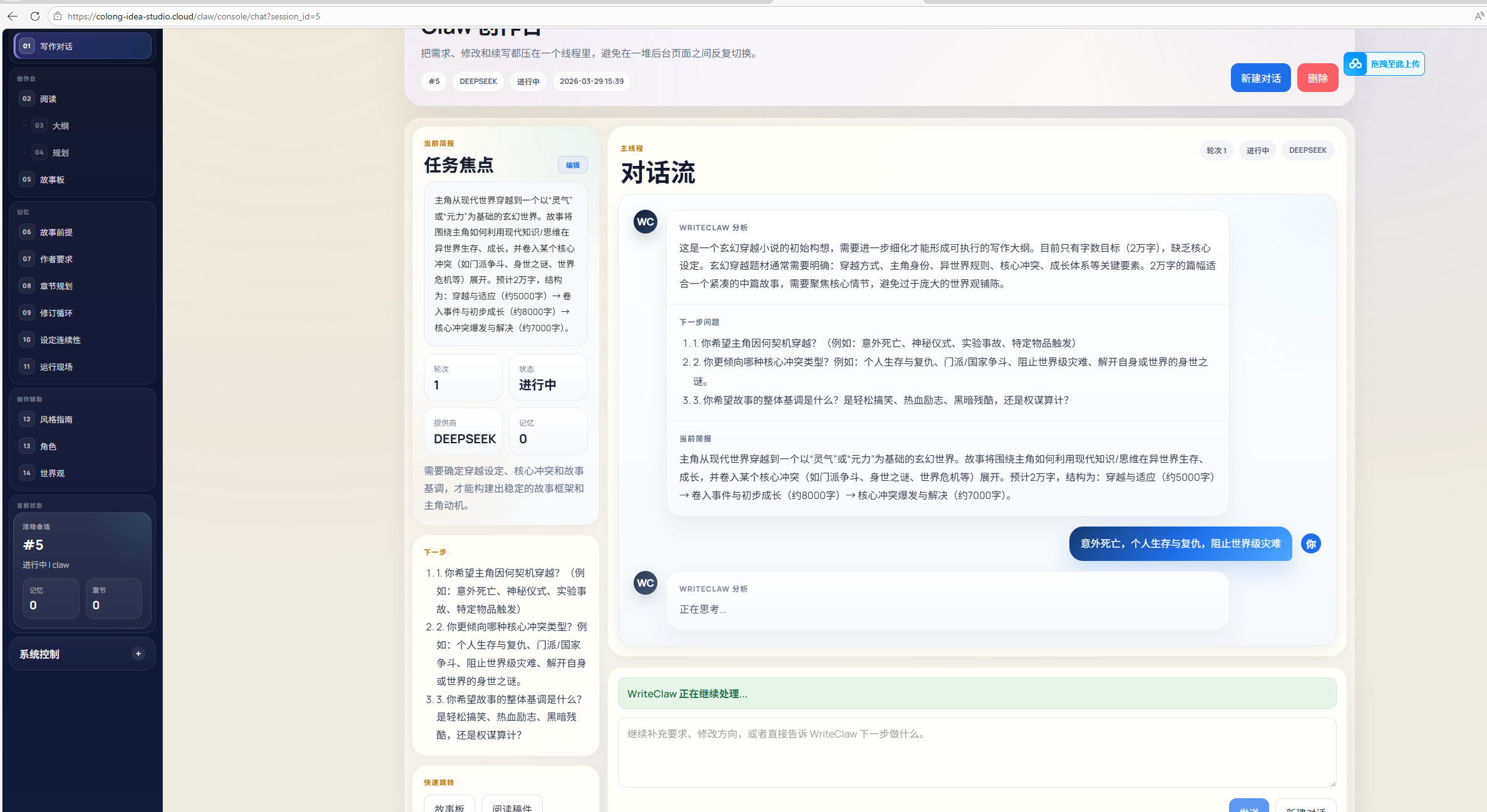
claw模式
有的人可能要说,你这个就是在蹭open claw的热度,如果你说完全没有蹭,我不认为,毕竟没有open claw我也不会取这个名,但是我用它里面的想法并不是完全因为它是open claw,怎么说呢?我这里用到了什么所以可以叫它claw?很显然:我们可以先看我的线上版
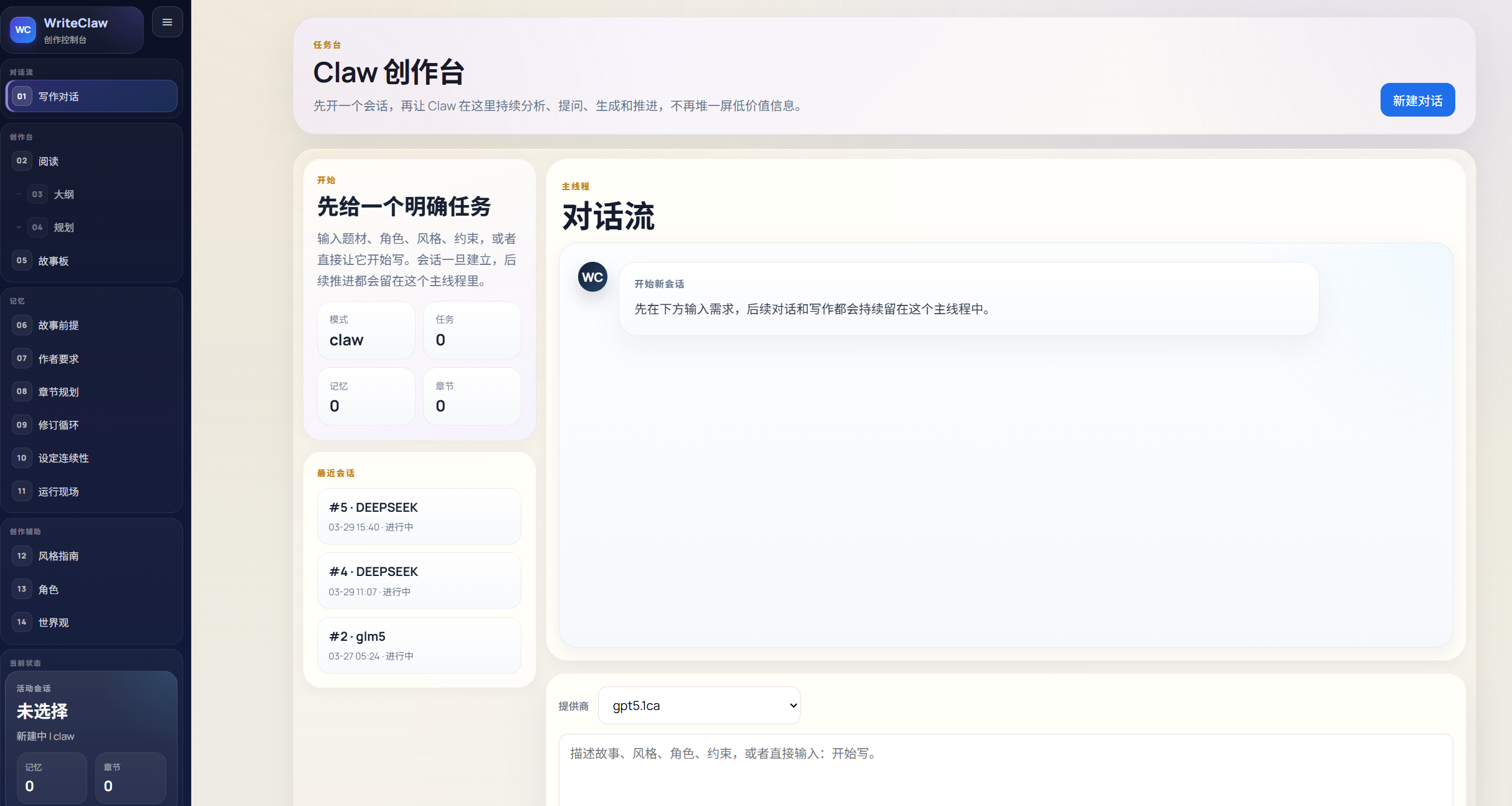
一个对话流?当然,为了保证能和用户很好的交互,对话流是必不可少的,但是用的它的最核心想法是什么?agent loop,open claw提出的这个loop实际上在其他领域以及使用过很多了,像具身智能等等,大家更喜欢叫它子任务,很多很多论文其实都提到了,就是让agent不断细分任务,然后不断解决好,agent loop其实也大差不差,就是让一个核心agent不断去调用其他的东西来循环完成这件复杂的事情,把这件复杂的事情拆分成很多小事情,当然中国的小说市场是最适合的,为什么呢?因为本身就是一件分章节的事情,我们需要把一个大的小说去分成很多章节,然后让agent来完善这个章节,所以其实设计一个这个agent loop模式去解决好这个问题其实也是我的一个创新出发点,注意agent loop和workflow有什么区别?workflow是死的,而agent loop是unfixed,它会变,会根据不断的调整,像skill的选择,或者这章它认为更需要什么,它是会变的!毫无疑问这种模式更适合小说创作者。
好的这个模式我们说完了,那还有什么呢?你可能会很好奇左侧这边为什么有这么多!
当然你可以看到左侧更偏向于一堆适合创作者的技能,右侧更偏向claw的利用
左侧是什么呢?
这里不得不提到另一个地方了:我们如何设计的我们动态memory呢?
首先你得知道不是什么东西都有资格加入我们的动态memory的,至于别人问你为什么不用rag,不是?真有人觉得在小说创作里面rag真的可以起很大用吗?到时候那么多的信息,如何检索,如何保证相似性问题,而且是联网的,如果单纯让rag真的风格利用肯定是没有必要的,那么怎么办,至于知识图谱不过是改了下形式的json文件,那么我们这里只能用自己的设计好的动态memory权重模式
首先我们要知道什么信息是要的:
大纲+章节大纲+风格+人物+情节+场景....
还挺多,那你token怎么够?有人可能会这么问,确实一个ai大模型的token取决于它的基模,这个我们没发改,那么只能让我们能利用更好更有用的信息
首先在我们用于idea之后,我们的claw就会自己去调用我们的skill和agent这些东西应该也能使用在真正的openclaw上,当然我设计的模式还是让我们的claw先根据idea生成自己的大纲,然后会个根据风格和场景以及世界观生成每个章节的规划,为什么要这么设计?!当然是保证整个小说是不会因为后期出现幻觉而跑题,当然作者认为不好也是可以修改的!
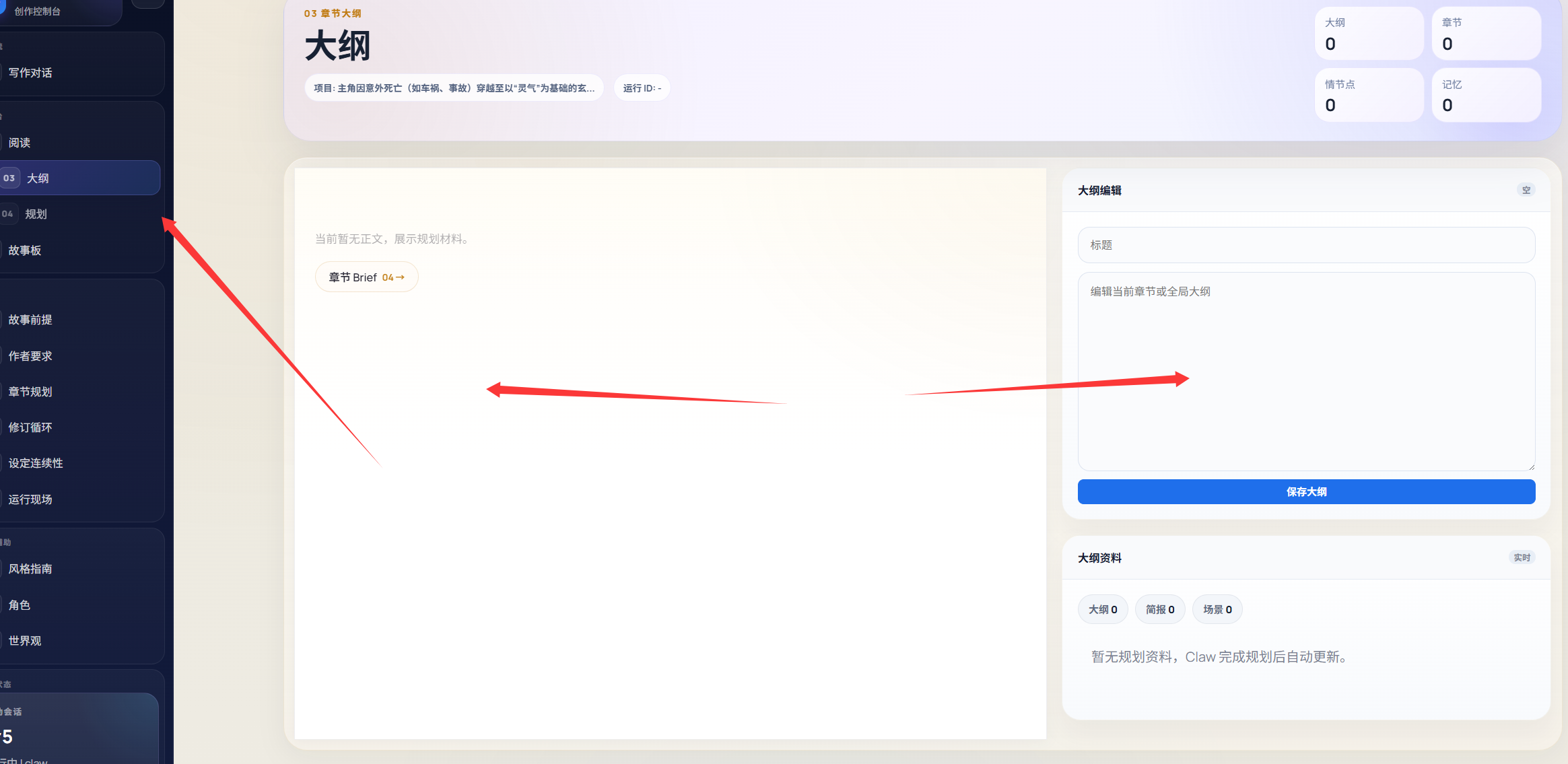 当然我这里可能没有很好的可以展示出来
当然我这里可能没有很好的可以展示出来
然后每一章会根据这些来设定情节,章节大纲和总的大纲它们的权重是最大的,当然总的大纲是动态也是可以改变的!
然后每章会产生人物,人物毫无疑问也是可以存储的,而且人物出现幻觉是很严重的,针对人物的性格,情节等等装备什么的?都需要存储,而且这个也是得知道的,当然这个的权重会根据这个章节是否有这个人物作调整!如果有当然是要出现这个人物的,而且会不断的更新!

当然还有很多其他可能需要的记忆:像每章产生的核心章节,这章末尾场景和对话,还有情感转折伏笔,这些都会被记录下来来保证整体的连惯性
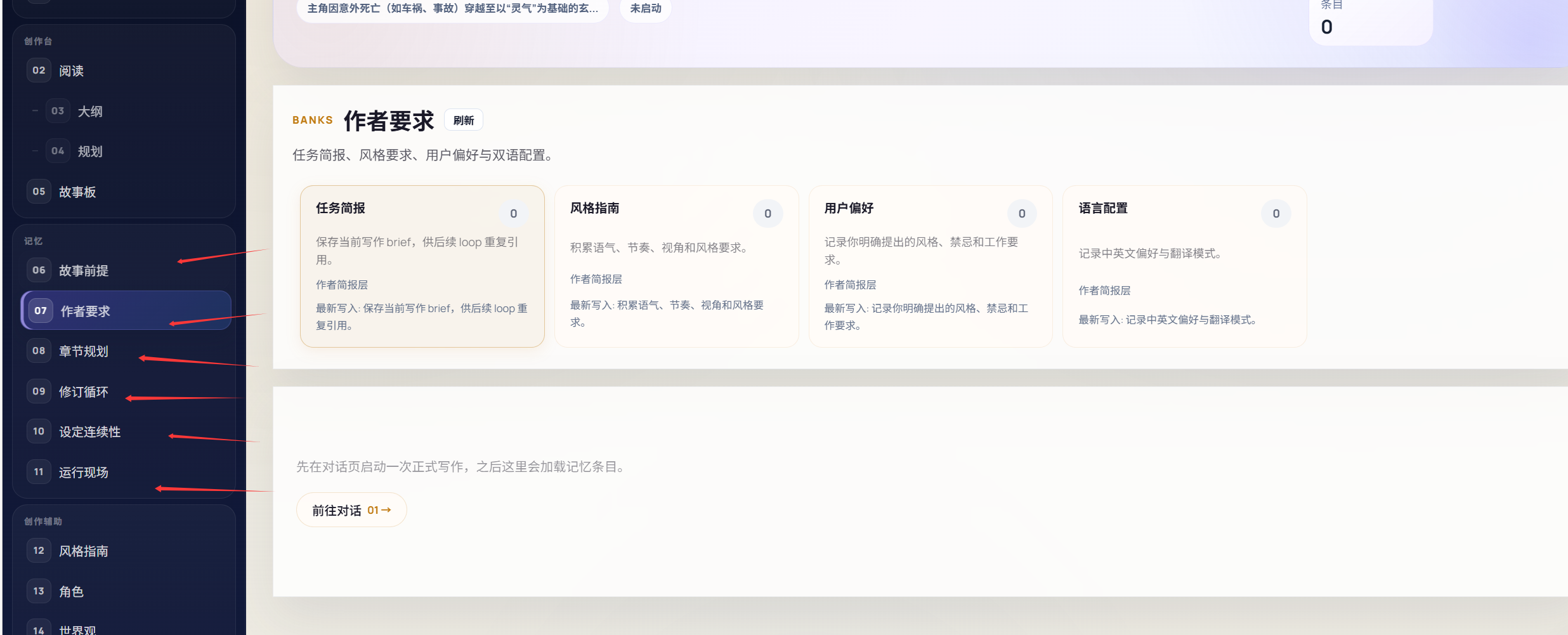
当然一次的成功可能不太行,还会针对上述的全部信息,在生成一次后给予它做一致性检验,来保证效果的有用性!至此,大概也功能也讲得差不多,希望可以自己使用一下感受一下
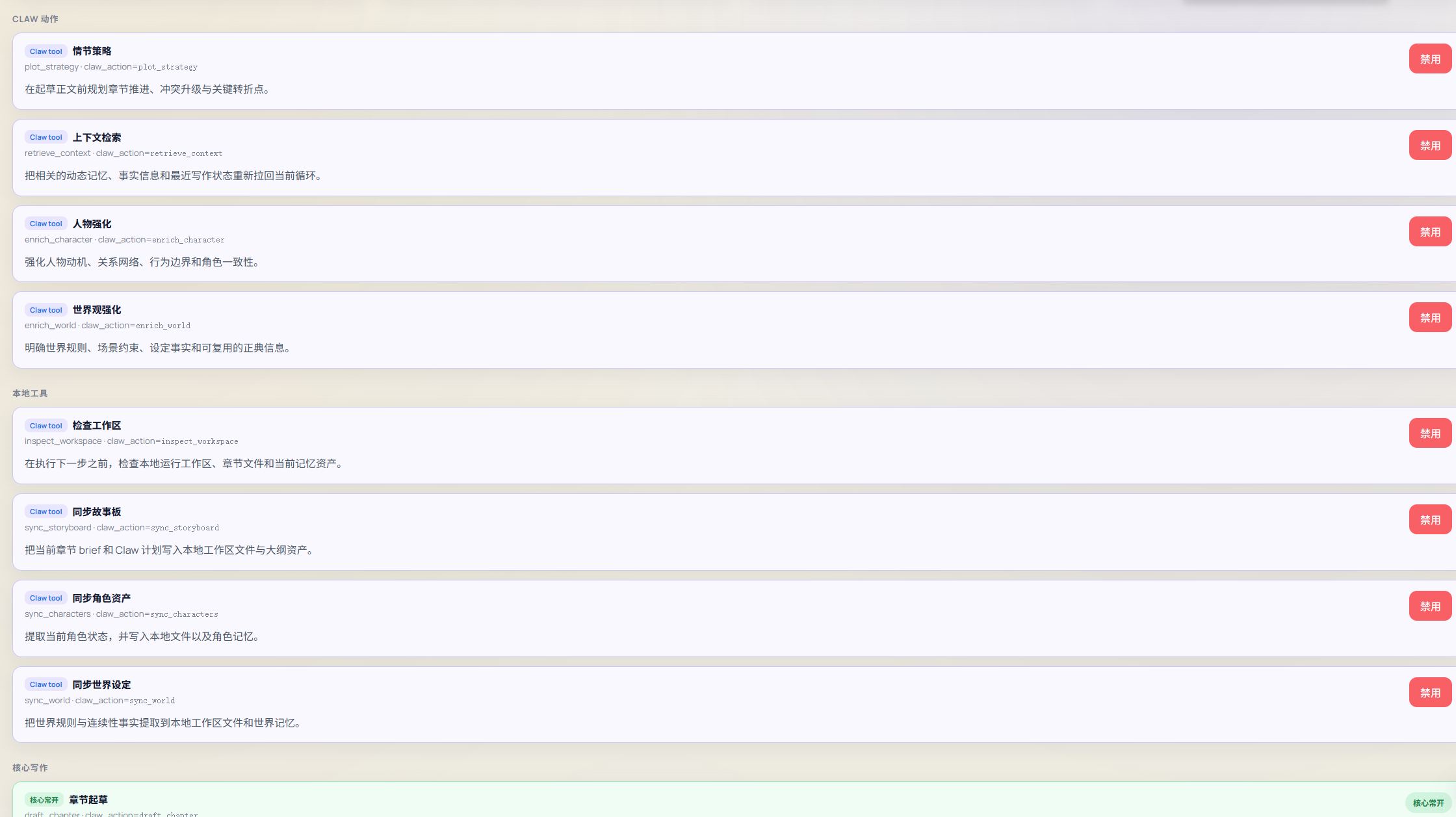 至于skill等等,都应该可以复用进open claw什么的,还有需要设置自己的claw模式,不然给你疯狂掉去了
至于skill等等,都应该可以复用进open claw什么的,还有需要设置自己的claw模式,不然给你疯狂掉去了
好的两种模式我讲得差不多了,动态memory也不去细讲了
至于动态记忆库想看的也可以去看一下我的从静态检索到动态记忆:面向长篇 AI 写作的一种 Memory-First 架构思路 | re的编程之旅
也非常欢迎大家的使用和感谢star
至于还有什么技术层面的复杂利用吗?确实还有:针对prompt向量化检验,当然这个论文里面再体现了,最后再一次感谢大家!--下一个工作可能是往evo方向的也欢迎一起talk!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)