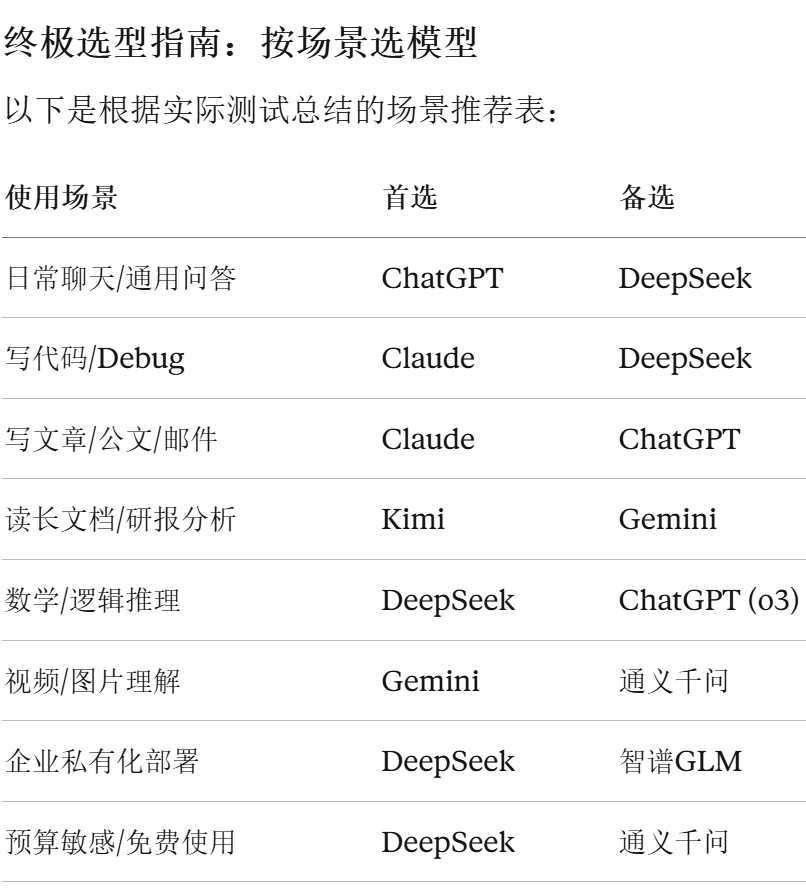
2026年主流AI大模型横评:谁是你的最佳搭档?
8款主流大模型实测对比,从写作、编程、长文本到中文理解,帮你找到最适合自己的AI助手。
2026年的AI大模型赛道,用"神仙打架"来形容毫不夸张。
一边是ChatGPT、Claude、Gemini这些海外老牌选手持续迭代,一边是DeepSeek、通义千问、Kimi等国产模型强势崛起。作为一个每天和AI打交道的科技从业者,我花了两周时间系统测试了目前最主流的8款大模型,从日常写作、代码生成、长文档处理到中文语境理解,给大家做一个尽量客观的横向对比。
先说结论: 没有"最好"的模型,只有"最适合你"的模型。不同使用场景下,各家表现差异巨大。
第一梯队:海外三巨头
1. ChatGPT(OpenAI)—— 全能型选手,生态最强
最新版本: GPT-5.2 / GPT-4.1
ChatGPT到2026年已经不只是一个聊天工具了。OpenAI拥有超过9亿周活跃用户,是目前全球认知度最高的AI产品。GPT-5.2在多步推理方面取得了明显突破,而GPT-4.1则提供了100万token的超长上下文窗口,实用性大幅提升。
最大优势: 插件生态无敌,GPTs商店覆盖画图、数据分析、联网搜索等各类场景;实时语音对话的流畅度仍然是独一档的存在。
明显短板: 中文细节偶有偏差;模型版本太多(光GPT系列就有6个以上变体),选择成本高;付费门槛不低,Plus 20美元/月,Pro 200美元/月。
适合人群: 需要"一站式AI平台"的全能型用户、英文办公为主的用户。
2. Claude(Anthropic)—— 编程之王,写作最像人
最新版本: Claude Opus 4.6 / Claude Sonnet 4.6
如果说ChatGPT是"什么都会一点"的全才,Claude就是"编程和写作两个点拉满"的偏科生。Claude Opus 4.6在SWE-bench代码评测中达到了72.5%的修复成功率,是目前编程能力的天花板。它的上下文窗口也达到了100万token,可以一次性读完几本书。
但Claude最让人印象深刻的其实是它的写作风格——逻辑通顺、文笔自然,几乎没有"AI味"。如果你需要写一篇读起来像人写的文章,Claude是目前最好的选择。
最大优势: 代码能力全球领先;写作质量高,几乎无AI痕迹;Artifacts功能让它成为优秀的交互式开发环境。
明显短板: 创意类脑暴略逊于ChatGPT;国内直接访问需要特殊网络条件。
适合人群: 程序员、技术写作者、需要高质量中英文写作的用户。
3. Gemini(Google)—— 多模态标杆,谷歌生态核心
最新版本: Gemini 3.0 Pro / Gemini 2.5 Flash
Google在AI领域的底蕴确实深厚。Gemini是第一个"从训练阶段就原生支持多模态"的模型,理解视频、图片、音频的能力领先同行。上下文窗口更是达到了惊人的200万token,长文档处理方面几乎没有对手。
更关键的是Gemini与Google Workspace的深度打通——如果你日常重度使用Gmail、Google Docs、Google Drive,Gemini基本可以无缝嵌入你的工作流。
最大优势: 多模态理解能力最强;200万token超长上下文;深度集成谷歌全家桶。
明显短板: 国内访问不太稳定;插件生态不如OpenAI完善。
适合人群: 谷歌全家桶重度用户、需要分析长视频/长文档的用户。
第二梯队:国产新锐
4. DeepSeek —— 性价比之王,开源界扛把子
最新版本: DeepSeek-V3.2
DeepSeek可能是2025-2026年全球AI界最大的黑马。这家来自中国的公司,用MoE混合专家架构把训练成本打到了GPT级模型的1/10,直接引发了全球大模型降价潮。DeepSeek在GitHub上已经获得超过10万Star,是目前开源模型的绝对王者。
更让人惊讶的是,DeepSeek-V3.2在多语言软件工程评测中达到了70.2%,甚至超过了GPT-5的55.3%。它的中文理解能力也是全球断层领先的水平。
最大优势: 完全免费(网页/APP版);API价格约为GPT的1/10;代码和数学推理能力极强;开源可私有化部署。
明显短板: 创意类内容风格偏单一;偶尔服务稳定性波动。
适合人群: 预算敏感的开发者、理工科学生、企业私有化部署需求。
5. 通义千问 Qwen(阿里)—— 最全面的国产选手
最新版本: Qwen3-Max
通义千问是国产模型中综合能力最均衡的选手。阿里在开源社区(HuggingFace)的影响力巨大,Qwen3系列支持"思考/非思考"双模式切换,适应不同场景需求。相比只专注模型性能的DeepSeek,通义千问更贴近应用层面,功能更全面。
它的视觉识别能力在国产模型中数一数二,能看懂复杂图表,甚至还能帮你自动点餐——阿里生态的联动确实方便。
最大优势: 中文理解扎实;开源生态丰富;图片理解能力强;与阿里系产品联动顺畅。
明显短板: 海外场景适配较弱;跨语言流畅度有提升空间。
适合人群: 国内企业用户、需要处理中文商务文档的人群。
6. Kimi(月之暗面)—— 长文档阅读专家
最新版本: Kimi K2.5
Kimi曾经是国内长文档阅读的开创者,虽然进入2025年后声势相比其他国产模型有所减弱,但在"吃透长文档"这个细分场景上依然有独到优势。你可以直接扔50份PDF给它,它能快速总结核心观点,搜索引用链接也很规范,减少了胡编乱造的概率。
Kimi K2.5还推出了Agent Swarm功能,可以编排100个并行子Agent协同工作,这在复杂任务编排方面走在了前沿。
最大优势: 长文档总结精准;搜索引用规范;界面清爽好用。
明显短板: 通用对话能力不如第一梯队;生态丰富度有限。
适合人群: 金融从业者、学生党、日常需要大量阅读研报/论文的用户。
7. 智谱 GLM(清华系)—— Agent原生,国产芯片适配最强
最新版本: GLM-5 / GLM-5-Turbo
智谱作为清华系AI公司,走了一条与众不同的路——深度适配国产GPU芯片,支持GPU/CPU混合部署。对于算力供应链安全有要求的国内企业来说,这是一个不可忽视的优势。GLM-5采用MIT开源协议,商业友好度极高。
今年3月新发布的GLM-5-Turbo专门强化了Agent能力,在工具调用、指令遵循方面做了深度优化。
最大优势: 国产芯片适配最强;商业开源协议友好;Agent能力突出。
明显短板: 表现稳定性有波动,时好时差;整体知名度不如DeepSeek和Qwen。
适合人群: 对国产算力有需求的企业、Agent开发者。
8. 文心一言 ERNIE(百度)—— 中文知识图谱优势
最新版本: ERNIE 4.0 Turbo
百度文心一言的核心壁垒在于知识图谱与大模型的融合。在中文权威榜单C-Eval和CMMLU上,ERNIE 4.0 Turbo多次表现出色,中文语义理解确实扎实。依托百度搜索的海量中文数据,它在回答中文事实性问题时的准确率较高。
最大优势: 中文知识图谱深厚;与百度生态联动;事实性问答准确。
明显短板: 创造性输出相对保守;整体产品体验不如竞品流畅。
适合人群: 重度百度生态用户、中文知识问答场景。
我的实际使用搭配
分享一下我个人的日常组合,供参考:
主力组合:DeepSeek + Claude
日常快速问答和代码生成用DeepSeek(免费且快),需要高质量写作或复杂编程任务时切换到Claude。两者互补效果非常好——DeepSeek做初步筛选和快速验证,Claude处理需要深度思考的任务。
辅助工具: Kimi用来读长文档和研报,通义千问处理中文图表识别。
这种"主力+辅助"的搭配方式,既控制了成本,又覆盖了绝大多数使用场景。
2026年大模型趋势观察
最后聊几个值得关注的趋势:
推理能力成为标配。 从OpenAI的o系列开创"深度思考"范式以来,几乎所有厂商都推出了推理模型。到2026年,"会思考"已经像2024年的"会联网搜索"一样,成为大模型的基本功能。
Agent是下一个战场。 各家都在从"调用API"转向"编排Agent网络"。Claude的MCP协议、Kimi的Agent Swarm、智谱的Agent原生架构,都在抢占这个方向的制高点。
价格还会继续降。 DeepSeek把价格打到了GPT的1/10,Gemini Flash的定价也极其激进。对普通用户来说,AI的使用门槛会越来越低。
你日常使用的是哪款AI大模型?欢迎在评论区分享你的使用体验和心得!
本文内容基于2026年3月的产品状态撰写,AI模型迭代速度极快,建议以各平台最新版本为准。
作者是一名科技行业从业者,长期关注AI工具和效率提升方向。关注我,持续分享科技干货。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)