BLIP前瞻:解析多模态对齐基石模型ALBEF
深度对齐:ALBEF (Align Before Fuse)
论文标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
作者:Salesforce Research (2021)
核心思想:在多模态融合之前,先通过对比学习对齐单模态特征,并引入动量蒸馏解决图文噪声问题。
1. 诞生背景
在 ALBEF 出现之前,VLP(Vision-Language Pre-training)主要面临两个瓶颈:
-
特征空间不一致 (The Modality Gap):图像特征(通常由预训练的检测器提取)和文本特征(BERT 提取)处于完全不同的分布。直接进行深层融合(Heavy Fusion),模型很难在杂乱的特征中找到对应关系。
-
目标检测器的束缚:当时主流模型依赖 Faster R-CNN 提取 Region Features。这导致:
-
计算昂贵:检测器非常慢。
-
视野受限:检测器只能看到预定义的类别,会丢失背景等有用信息。
-
-
图文数据噪声:互联网爬取的图文对(如 Conceptual Captions)极其“脏”。文本往往并不是严谨的描述,这种弱相关性会误导传统的硬分类目标函数(One-hot labels)。
2. ALBEF 模型架构:三段式设计
ALBEF 采用了对称+非对称混合结构:
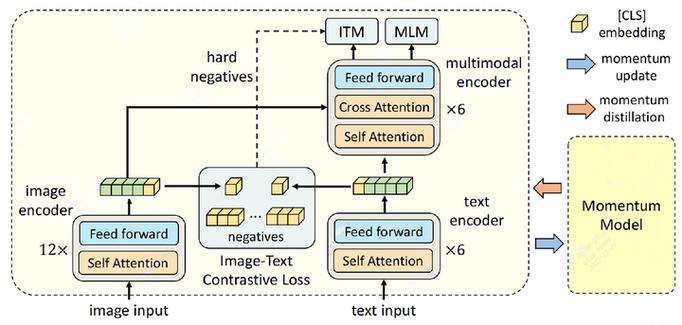
2.1 图像编码器 (ViT)
不再使用传统的检测器,而是直接采用 ViT-B/16(12层的transformer)。并用ImageNet-1k上预训练的权重初始化它。将图像切成 的 Patch,通过 Transformer 提取全局特征。
2.2 文本编码器 (Text Encoder)
使用 BERT 的前 6 层 。它独立地处理文本,提取初步的语言语义。
2.3 多模态融合编码器 (Multimodal Encoder)
使用 BERT 的后 6 层 。这里引入了关键的 Cross-Attention 层。每一层都会将图像编码器的输出作为 Key 和 Value,文本特征作为 Query,实现视觉信息对文本语义的注入。
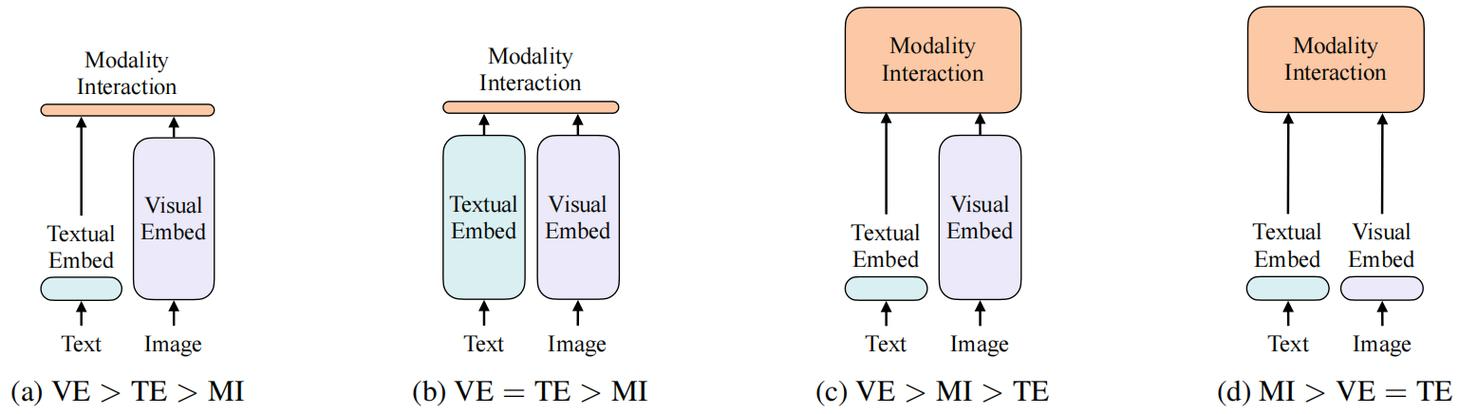
ALBEF之所以采用图像编码器12层Transformer、文本编码器6层Transformer、多模态编码器6层Transformer的架构配置,核心原因可结合VILT论文对多模态模型结构的分类总结来解释:VILT已归纳出多模态模型的几类典型架构,并指出性能更优的模型普遍遵循“图像编码器足够深、多模态编码器足够强,而文本编码器无需过深”的设计原则,这类C类架构在效果上具备显著优势。ALBEF的整体结构与C类架构高度契合,正是基于这一规律进行的架构选型。
3. 三大核心训练任务(损失函数)
ALBEF 的强大在于其层层递进的训练目标:
3.1 图像-文本对比学习 (Image-Text Contrastive Learning:ITC)
目的:在融合前实现粗粒度对齐。
这一任务正是ALBEF 论文命名的核心依据。其中,ITC(Image-Text Contrastive)任务在多模态融合阶段之前执行,仅依赖图像编码器与文本编码器,不参与多模态编码器的计算。ITC 的核心目标是解决论文研究动机中的第一个关键问题:将图像编码器与文本编码器的特征向量空间进行显式对齐。
在 ITC 任务中,分别提取图像编码器的[CLS] token 作为全局图像特征,文本编码器的[CLS] token 作为全局文本特征,通过计算二者相似度构建对比学习目标:训练过程中不断拉大匹配图文对的相似度,缩小不匹配图文对的相似度,从而完成跨模态特征对齐。
受 MoCo 论文启发,ALBEF 在 ITC 中引入动量蒸馏(Momentum Distillation)机制,用以解决研究动机中的第三个问题 ——大规模网络图文数据存在噪声标注的问题。具体做法为:在预训练阶段,通过滑动平均(moving-average)维护两套动量编码器作为当前编码器的副本;利用动量编码器为当前图像 / 文本检索最相似的文本 / 图像,生成伪标签(pseudo-labels),并将其作为额外监督信号融入损失函数。

实验结果表明,动量蒸馏生成的 ITC 伪标签在一定程度上比原始 Ground Truth 更为可靠。借助该机制,模型可有效缓解数据集噪声问题,实现更鲁棒的预训练。
在单模态编码器输出端,计算图像特征 和文本特征
的余弦相似度。通过对比学习,拉近匹配对(Positive),推开不匹配对(Negative)。
直觉:让模型在进融合层之前,先在对比空间认出谁是谁的对象。
3.2 图像-文本匹配 (Image-Text Matching: ITM)
目的:执行细粒度的深层二分类任务,建立模态间的“强关联”。
如果说 ITC(对比学习)是让模型合照中模糊地认出对方,那么 ITM 就是让模型坐下来,通过多模态融合编码器(Multimodal Encoder)的 Cross-Attention 机制,仔细比对图像细节与文字描述是否完全吻合。
3.2.1 任务机制
在 ITM 阶段,模型将图像特征序列和文本特征序列同时输入融合编码器。取融合后输出序列的 [CLS] token,该 token 已经通过多层 Cross-Attention 充分吸收了双模态的信息。随后将其接入一个线性投影层和 Softmax,预测一个二分类概率:(匹配或不匹配)。
3.2.2 核心痛点:难样本挖掘 (Hard Negative Mining)
简单的随机负采样(Random Negative Sampling)对模型来说太容易了。比如:一张“狗”的图片配上“波音747”的文字,模型闭着眼都能分出来。为了让模型学到更本质的特征,ALBEF 引入了难样本挖掘策略:
-
策略来源:利用同一 Batch 内 ITC 任务计算出的相似度矩阵。
-
做法:对于每一张图像,我们不随机选文本作为负样本,而是去选那些在 ITC 空间里相似度最高、但实际不匹配的文本(Top-K Hard Negatives)。
-
直觉:这些文本在语义上可能与图像非常接近(例如图像是“黑色的猫”,负样本文字是“黑色的狗”)。强迫模型在这种“极度相似”的干扰下做出正确判断,极大地提升了模型对细微差异的敏感度。
3.3 遮蔽语言模型 (Masked Language Modeling: MLM)
目的:通过视觉线索补偿缺失语义,实现像素级与词级(Token-level)的细粒度对齐。
ALBEF 的 MLM 任务与纯文本 BERT 的 MLM 有本质区别:它是一个多模态驱动的填空题。
3.3.1 任务流程
-
遮蔽(Masking):随机遮盖输入文本中 15% 的 Token,用
[MASK]代替。 -
线索来源:模型必须结合剩余的上下文文本以及图像编码器提供的视觉特征。
-
预测:多模态编码器输出被遮蔽位置的特征,通过一个分类器预测原词。
3.3.2 为什么在 ALBEF 中 MLM 很强大?
在纯文本任务中,如果句子是“一只[MASK]在草地上跑”,模型可能猜“狗”或“猫”。但在 ALBEF 中,多模态编码器的 Cross-Attention 会让 [MASK] 位置的 Query 去图像中“寻找”对应的区域。
-
如果图像中出现了一个橘色的猫,Cross-Attention 会赋予相关像素极高的权重。
-
这种机制强迫模型建立起词汇(如 "Cat")与图像局部区域(Patch)之间的强映射关系。

3.3.3 动量蒸馏在 MLM 中的应用 (Momentum Distillation for MLM)
与 ITC 类似,MLM 同样受到噪声影响。互联网上的标注往往不全,当某个词被遮盖时,可能存在多个合理的候选词。
-
ALBEF 使用动量模型(Momentum Model)作为“老师”,生成一个预测词的概率分布。
-
在线模型(Base Model)的目标是减小自身预测分布与动量模型生成的“软标签”之间的 KL 散度。
-
意义:这允许模型学习到一种语义上的平滑性(例如,即使没猜对准确的词,猜到一个近义词也会得到部分奖励),从而在处理不准确的网页数据时表现得更加鲁棒。
4. 动量蒸馏 (Momentum Distillation) 的深度拆解
4.1 核心痛点:互联数据的“弱相关性”
在理想的学术数据集(如 COCO)中,图文是一一对应的。但在现实(如 Conceptual Captions 4M)中:
-
文本缺失:图片里有猫、狗、草地,但文字只写了“草地”。
-
语义重叠:Batch 内的两张图片可能都包含“狗”,如果强行互为负样本,会迫使模型学习错误的区分特征。
-
硬标签的局限:传统的 Cross-Entropy 配合 One-hot 标签(非黑即白)会强制模型抑制那些虽然没有被标注、但客观存在的语义关联。
4.2 动量模型(Momentum Model)的构建
ALBEF 维护了两个模型:
-
Base Model (在线模型
):正在学习、不断梯度更新的模型。
-
Momentum Model (动量模型
):结构与 Base 完全一致,但不通过反向传播更新。
参数更新公式:
-
其中
通常是一个接近 1 的超参数。
-
直觉理解:动量模型是 Base 模型的一个“时间平滑版”或者是“更稳重的老师”。它反应较慢,但因为它融合了过去多个版本的知识,其输出的特征表示(Embedding)在空间中更加稳定。
4.3 伪标签(Pseudo-targets)的生成流程
在训练的每一轮,我们会同时将数据输入这两个模型。
4.3.1 计算动量相似度 (For ITC)
动量模型会对 Batch 内的图文对计算余弦相似度。由于动量模型很稳,它能敏锐地察觉到:“虽然这张图和这段话不是原配,但它们的特征向量靠得很近”。
它会生成一个概率分布 和
,这个分布不是 0 或 1,而是类似于:
4.3.2 计算动量预测 (For MLM)
在遮蔽语言模型任务中,动量模型(基于未遮蔽的图像和文字)预测被遮盖词的概率分布 。这个分布捕捉到了词语之间的语义相近性(例如,预测“猫”和“小猫”都有较高的概率)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)