Transformer-GRU模型:多变量回归预测新方案
Transformer-GRU基于Transformer结合门控循环单元的数据多变量回归预测 Matlab语言 程序已调试好,无需更改代码直接替换Excel运行你先用,你就是创新 多变量单输出回归,回归预测也可以加好友换成分类或时间序列单列预测(售前选一种),回归效果如图1所示~ 网络结构图如图2所示评价指标包括R2、MAE、RMSE、MAPE 可售前加好友增加各类优化算法进行参数自动化寻优(如冠豪猪CPO、霜冰RIME等等),也可改进任意算法 Matlab版本要求在2023b及以上,没有的可附赠安装包 注: 1.附赠测试数据,数据格式如图3所示~ 2.注释清晰,适合新手小白运行main文件一键出图~ 3.商品仅包含Matlab代码,后可保证原始程序运行 4.模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果~
今天,我将带大家了解一个结合Transformer和GRU的创新模型,用于多变量回归预测的问题。这个模型在Matlab中已经调试完成,可以直接替换Excel数据运行,方便又高效。接下来,我会详细分析模型结构,解读其工作原理,并指导大家如何快速上手使用。
为什么选择Transformer和GRU?
在数据科学领域,处理时序数据是个经典问题。传统的循环神经网络(RNN)及其变体,如LSTM和GRU,非常适合捕捉时间依赖性,但由于其串行处理的特性,在处理长距离依赖和多维数据时表现有限。另一方面,Transformer通过自注意力机制,能够高效捕捉全局依赖关系,但在处理时序数据时,可能遗漏局部时间模式。于是,我将两者结合,试图发挥二者的优势,形成一种更强大的模型。
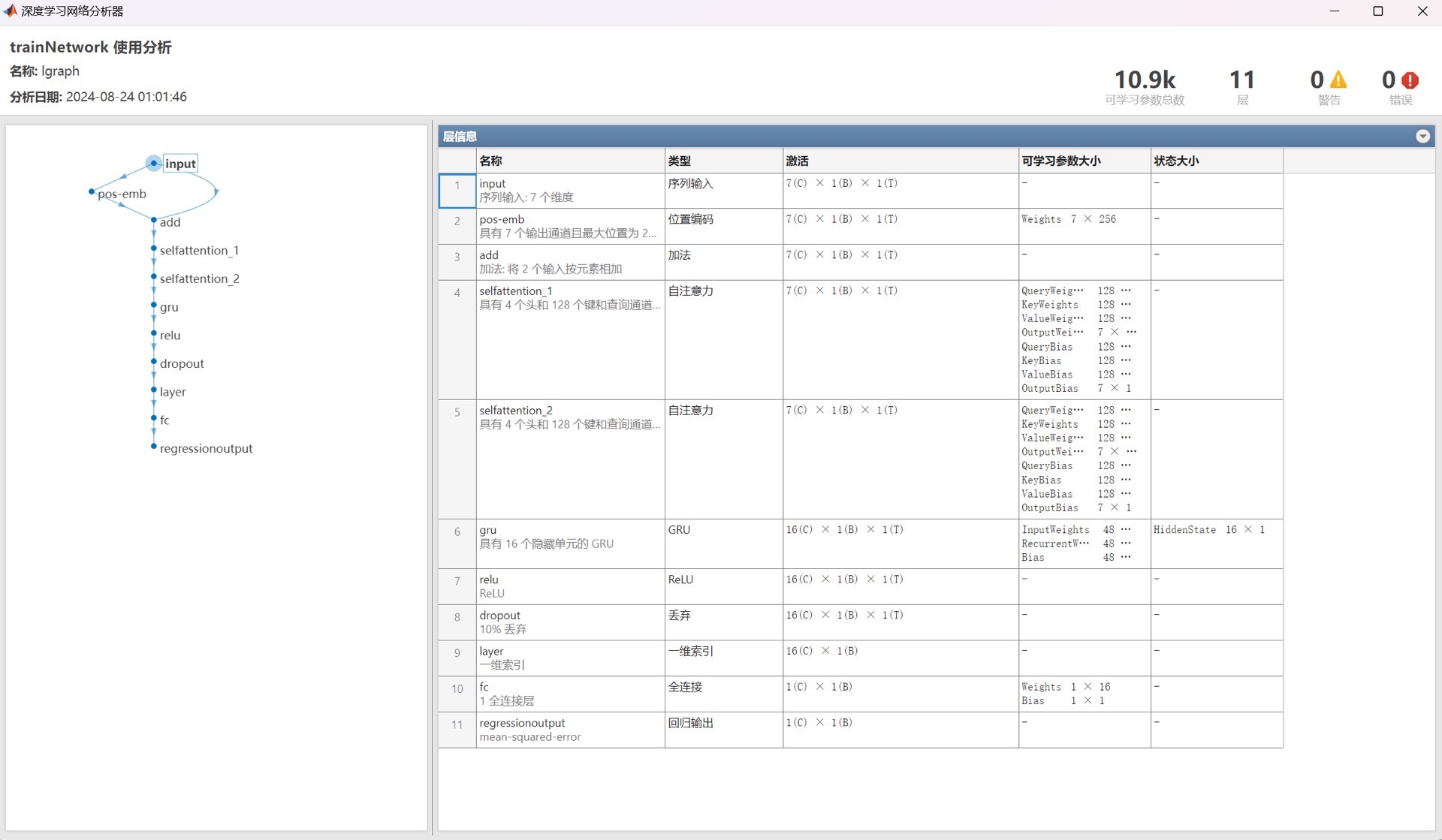
模型结构概述
让我们看看模型结构:
- 嵌入层(Embedding Layer):将输入数据映射到高维空间,为后续处理提供更丰富的特征。
- 多头自注意力机制(Multi-Head Self-Attention):捕捉输入数据中的全局依赖关系,帮助模型理解各变量间的复杂关系。
- GRU层(GRU Layer):处理经过Transformer编码后的序列,捕捉时间上的局部依赖模式。
- 全连接层(Fully Connected Layer):将GRU的输出映射到目标回归值,完成预测。
这样的结构既保持了Transformer的全局视角,又利用了GRU的顺序处理能力,非常适合多变量时序数据的回归问题。
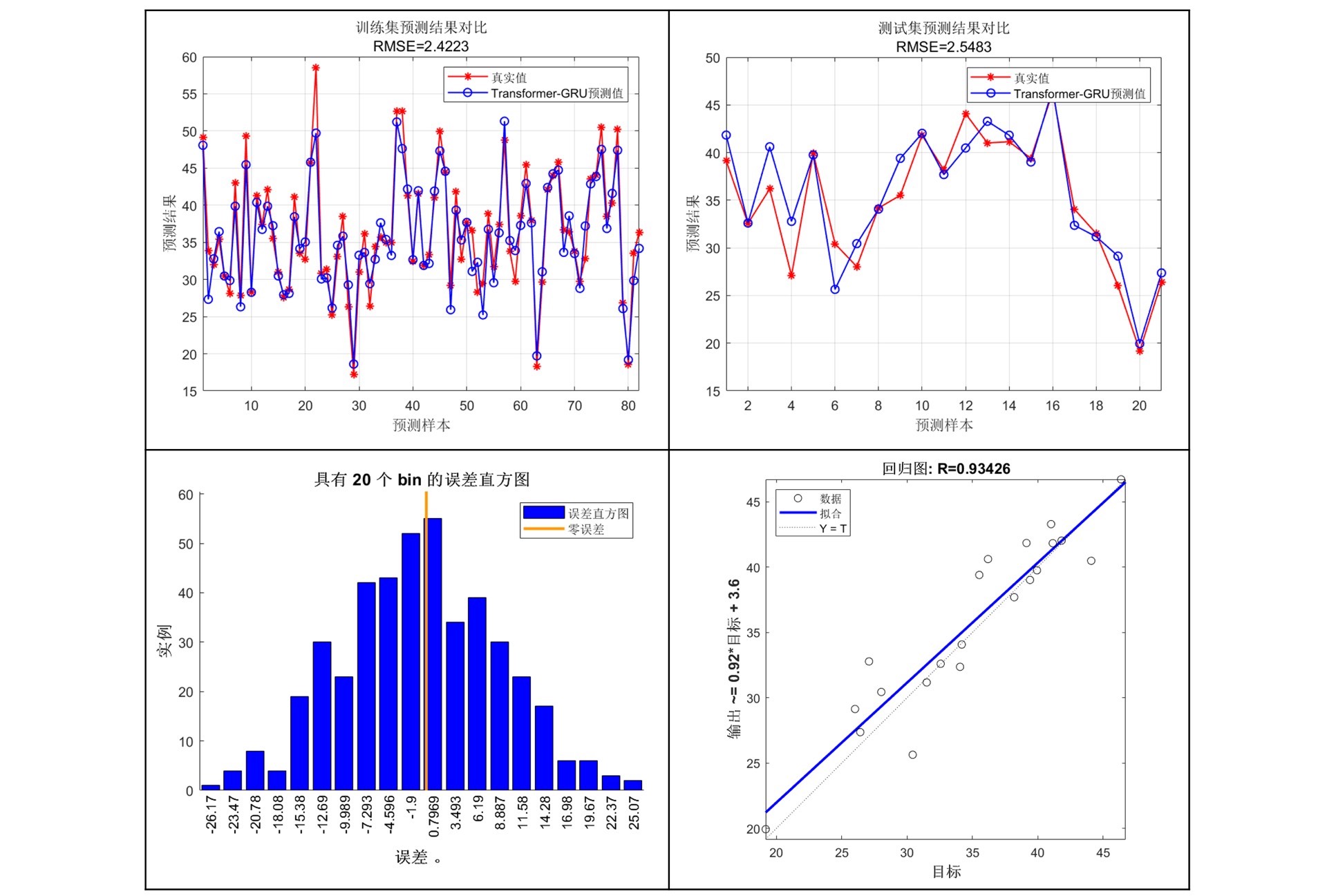
效果展示
图1展示了模型在某个多变量回归问题中的预测结果。可以看到,模型能够较好拟合真实值,尤其在捕捉数据波动方面表现优异。
评价指标
我们采用四个指标来评估模型性能:
- R²(决定系数):衡量模型解释数据的比例,值越靠近1,模型越好。
- MAE(平均绝对误差):预测值与真实值绝对差的平均值,数值越小越好。
- RMSE(均方根误差):与MAE类似,但平方处理放大了误差的影响,数值越小越好。
- MAPE(平均绝对百分比误差):以百分比形式衡量误差,适合数据量级变化大的情况。
优化算法升级
对于有需求的用户,可以添加优化算法进行参数自动化寻优。比如:
- 冠豪猪CPO(Coprimes Optimizer):基于数学理论,寻优速度快。
- 霜冰RIME(Responsive Inverse Migration Evolution):模拟冰川运动,全局搜索能力强。
这些算法可显著提高模型的训练效率和预测精度,适合对性能有更高要求的场景。
Matlab环境要求
本模型在Matlab 2023b及以上版本运行,如旧版本用户可联系获取安装包。
数据格式要求
图3展示了测试数据的格式,通常为CSV文件,包括多个输入变量和一个目标变量。
使用步骤
- 加载数据:使用Matlab加载CSV文件。
- 预处理:标准化数据,防止因量纲差异影响模型效果。
- 模型定义:构建Transformer-GRU网络结构。
- 训练模型:配置训练参数,启动训练循环。
- 预测与评估:使用测试集评估模型表现。
代码示例
以下是一些关键代码片段,帮助读者快速上手:
Transformer-GRU基于Transformer结合门控循环单元的数据多变量回归预测 Matlab语言 程序已调试好,无需更改代码直接替换Excel运行你先用,你就是创新 多变量单输出回归,回归预测也可以加好友换成分类或时间序列单列预测(售前选一种),回归效果如图1所示~ 网络结构图如图2所示评价指标包括R2、MAE、RMSE、MAPE 可售前加好友增加各类优化算法进行参数自动化寻优(如冠豪猪CPO、霜冰RIME等等),也可改进任意算法 Matlab版本要求在2023b及以上,没有的可附赠安装包 注: 1.附赠测试数据,数据格式如图3所示~ 2.注释清晰,适合新手小白运行main文件一键出图~ 3.商品仅包含Matlab代码,后可保证原始程序运行 4.模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果~
数据加载与预处理:
% 加载数据
data = readtable('your_data.csv');
X = data(:, 1:end-1); % 多个输入变量
y = data(:, end); % 目标变量
% 数据标准化
[X_normalized, mu, sigma] = zscore(X, 0, 2);
y_normalized = (y - mean(y)) / std(y);模型定义:
function [model] = define_model(input_dim)
layers = [
sequenceInputLayer(input_dim, 'Name', 'input')
transformerEncoderLayer(input_dim, 8, 'Name', 'transformer')
gruLayer(128, 'Name', 'gru')
fullyConnectedLayer(1, 'Name', 'dense')
];
model = model;
end模型训练与预测:
% 设置训练选项
options = trainingOptions('adam', ...
'MaxEpochs', 100, ...
'InitialLearnRate', 0.001, ...
'MiniBatchSize', 32, ...
'Shuffle', 'every-epoch', ...
'Plots', 'training-progress');
% 训练模型
net = trainNetwork(X_normalized, y_normalized, layers, options);
% 预测
y_pred = predict(net, X_normalized);总结与展望
Transformer-GRU模型在多变量回归预测中表现优异,尤其适用于需要捕捉全局和局部依赖关系的场景。通过合理的参数调优和优化算法,模型性能还能进一步提升。虽然代码已调试完成,但数据特性和任务需求仍需具体分析。如果你对模型感兴趣,或有优化需求,欢迎随时交流!
希望这篇博文能为你的项目提供灵感和帮助,让我们一起探索数据科学的无限可能!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)