LangChain教程-2、Langchain基础
·
2.LangChain教程-2、Langchain基础03-26
3.LangChain教程-3、Langchain进阶03-264.LangChain教程-4、构建简易智能 PPT 生成器03-27
收起

LangChain 1.x 实战教程 · 9 个 Demo
基于 demo_basic 实战代码
前置要求:Python 3.10+、uv、API Key(MiniMax 硅基流动)、Ollama 本地服务
官方文档:https://python.langchain.com/docs/
开场:LangChain 的 3W1H
1) Why:为什么需要 LangChain?
直接调用模型 API 只能解决"单次问答",但真实业务要的是"系统能力":提示词管理、记忆、检索(RAG)、工具调用、多步编排和可观测性。LangChain 的价值,是把这些应用层能力标准化、组件化。
2) What:LangChain 是什么?
LangChain 是一个 LLM 应用编排框架,核心是把不同能力拼成可维护的链路:
- 模型层:
ChatOpenAI/ChatOllama负责推理与生成 - 编排层:LCEL 和 Runnable 负责把步骤连起来
- 数据层:Loader / Splitter / Vector Store / Retriever 负责处理知识
- 能力层:Tool / Agent / Memory / Parser 负责扩展应用能力
3) Who:谁适合学?
- 想把模型能力接进业务流程的开发者
- 想把提示词脚本做成可维护系统的人
- 想做 RAG、Agent、工具调用、可观测性的人
4) How:怎么把它落地?
先从最小闭环开始:Prompt -> LLM -> Parser。
再往上叠加:Memory 解决上下文,Retriever 解决知识,Tool 和 Agent 解决外部能力,Callback 解决可观测性。
最后把这些组件组合成真正可维护的应用链路。
补充:这篇文章怎么读
- 基于 demo_basic 真实运行代码
- 使用 MiniMax API(硅基流动)+ Ollama 本地 Embedding
- 每章节对应一个可运行的 demo 文件
LangChain 架构图
[用户输入]
↓
[Prompt / LCEL]
↓
[LLM 推理]
↓
[Output Parser]
↓
[结果输出]
旁路能力:
Memory ──► Prompt
Retriever ──► Prompt
Tool / Agent ◄──► LLM
Callback / Streaming ──► 全链路观测
9 个 Demo 一览
点击下表里的 Demo 名称可直接跳转到对应章节;每个 Demo 标题右侧的
↑可以返回这里。
| Demo | 主题 | 对应文件 |
|---|---|---|
| D01 | LCEL 管道语法 | demo01_lcel_basics.py |
| D02 | Prompt Template | demo02_prompt_template.py |
| D03 | Memory 记忆 | demo03_memory.py |
| D04 | Output Parser | demo04_output_parser.py |
| D05 | RAG 核心链路 | demo05_rag_ingest.py |
| D06 | RAG Chain | demo06_rag_chain.py |
| D07 | Tool + Agent | demo07_tools_agent.py |
| D08 | Callback 可观测性 | demo08_callbacks.py |
| D09 | LCEL 进阶 | demo09_runnable_advanced.py |
Demo 01 · LCEL 语法入门 ↑ 返回目录
学习目标
- ✅ 掌握 LCEL 三件套:
ChatPromptTemplate+llm+StrOutputParser - ✅ 理解管道符
\|原理 - ✅ 掌握
.invoke()/.batch()调用方式
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | ChatPromptTemplate:定义提示词模板,把变量位预留出来;ChatOpenAI:负责把 prompt 送去模型并拿回结果;StrOutputParser:把模型输出转成纯字符串;from_template():创建模板;.partial():预填固定变量;|:串联提示词、模型和解析器。学习目标组件: ChatPromptTemplate、ChatOpenAI、StrOutputParser、 |、.invoke()、.batch()。 |
| 代码对应 | ChatPromptTemplate.from_template(...) 负责定义模板;.partial(profession="技术写作") 负责预填固定变量;prompt | llm | StrOutputParser() 负责串起最小闭环;.invoke() 做单次调用,.batch() 做批量调用。 |
| 对比理解 | format() 只是渲染模板,不会调用模型;.invoke() 才会真正执行整条链;.batch() 适合批量生成;| 表示上游输出自动流入下游输入。 |
| 常见坑 | 常见坑是变量名不一致、批量文本过长、调试时直接看模型输出而不先看渲染结果。建议把模板、模型参数和输出解析拆开配置,便于复用、排查和 A/B 测试。 |
| 真实场景 | 你要做一个最小问答助手,输入一个主题就输出固定风格的介绍。这个 Demo 讲的就是把“提示词 -> 模型 -> 输出”的最小闭环先跑通。 |
完整代码
# 文件:demo01_lcel_basics.py
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# 使用 MiniMax 模型(硅基流动)
llm = ChatOpenAI(
model="MiniMax-M2.7",
base_url="https://api.minimaxi.com/v1",
api_key=os.getenv("MINIMAX_API_KEY"),
temperature=0.7,
max_tokens=1000,
request_timeout=60,
max_retries=2,
)
# Prompt 模板
prompt = ChatPromptTemplate.from_template(
"你是一位{profession}专家。请用3句话介绍{topic},最后加一个彩蛋笑话。"
).partial(profession="技术写作")
# LCEL 管道
chain = prompt | llm | StrOutputParser()
# 单次调用
result = chain.invoke({"topic": "LangChain 框架"})
print("=== 单次调用 ===")
print(result)
# 渲染后的 Prompt
rendered = prompt.format(topic="Python 装饰器")
print("=== 渲染后的 Prompt ===")
print(rendered)
# 批量调用
results = chain.batch([
{"topic": "量子计算"},
{"topic": "区块链"},
{"topic": "神经网络"},
])
print("=== 批量调用 ===")
for r in results:
print(r)

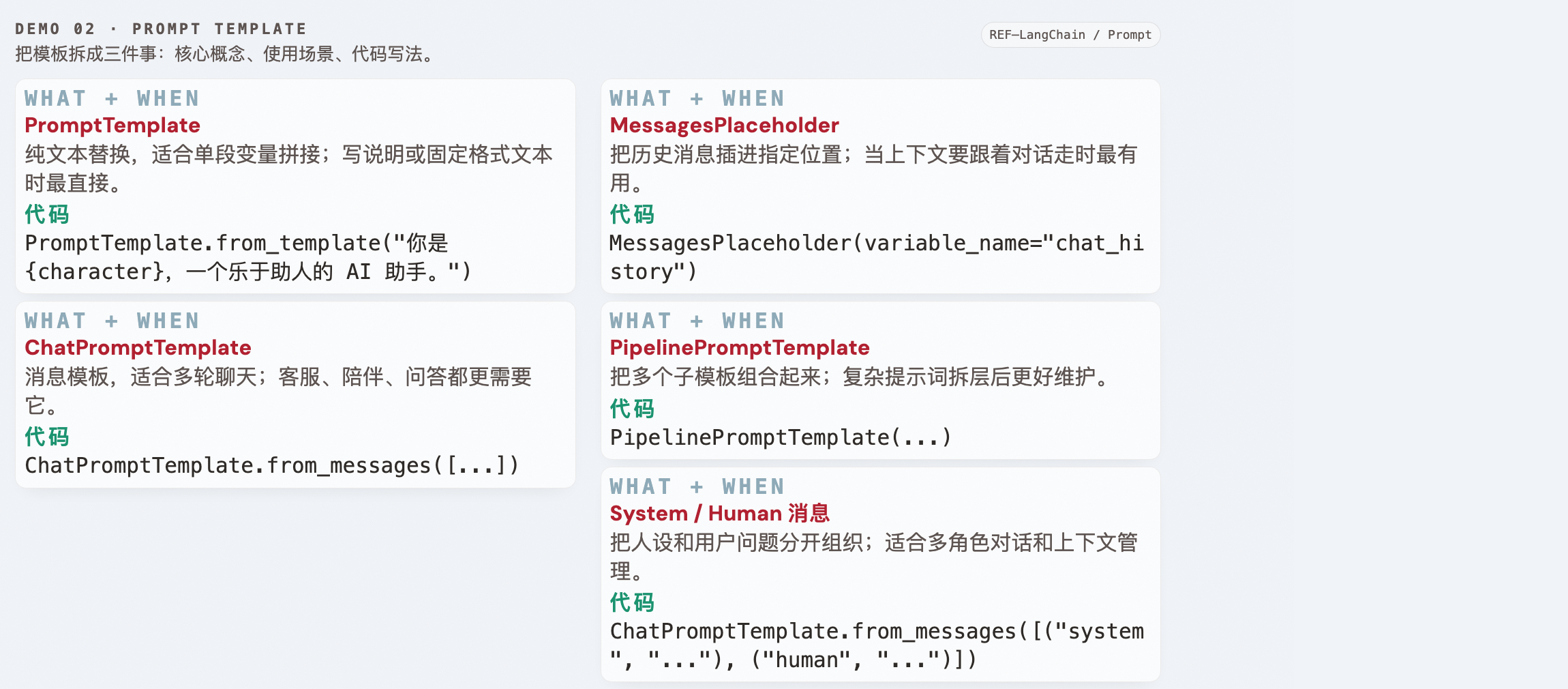
Demo 02 · Prompt Template ↑ 返回目录
学习目标
- ✅ 掌握 PromptTemplate(纯文本)和 ChatPromptTemplate(消息型)
- ✅ 理解 MessagesPlaceholder 的作用
- ✅ 掌握 PipelinePromptTemplate 嵌套模板
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | PromptTemplate:纯文本模板,适合单段变量替换;ChatPromptTemplate:消息模板,适合多角色对话;MessagesPlaceholder:把历史消息插到指定位置;HumanMessagePromptTemplate / SystemMessagePromptTemplate:分别定义用户消息和系统消息;PipelinePromptTemplate:把子模板串起来。 学习目标组件: PromptTemplate、ChatPromptTemplate、MessagesPlaceholder、HumanMessagePromptTemplate、SystemMessagePromptTemplate、PipelinePromptTemplate。 |
| 代码对应 | PromptTemplate.from_template(...) 适合纯文本替换;ChatPromptTemplate.from_messages([...]) 适合多角色对话;MessagesPlaceholder(variable_name="chat_history") 负责插入历史消息;PipelinePromptTemplate(...) 演示模板套模板。 |
| 对比理解 | 纯文本模板适合简单变量替换,消息模板更适合对话场景;MessagesPlaceholder 是消息级插入,不是字符串拼接;模板嵌套适合复杂提示词拆分。 |
| 常见坑 | 常见坑是历史消息传成字符串、嵌套变量漏填、模板层级越写越复杂。建议系统提示词尽量固定,历史消息只保留必要内容,复杂场景再做模板组合。 |
| 真实场景 | 客服、陪伴类、知识问答类应用,都需要把系统人设、历史对话和当前问题拆开管理。这个 Demo 讲的就是提示词模板化。 |
完整代码
# 文件:demo02_prompt_template.py
from langchain_core.prompts import (
ChatPromptTemplate,
PromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate
)
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(
model="MiniMax-M2.7",
base_url="https://api.minimaxi.com/v1",
api_key=os.getenv("MINIMAX_API_KEY"),
temperature=0.7,
max_tokens=1000,
)
# PipelinePrompt 替代方案(更简洁)
introduction = PromptTemplate.from_template("你是 {character},一个乐于助人的 AI 助手。")
main_template = "{introduction}\n\n用户问:{question}\n\n你的回答:"
def create_pipeline_prompt(character, question):
intro = introduction.format(character=character)
return main_template.format(introduction=intro, question=question)
final = create_pipeline_prompt("LangChain 助手", "什么是 RAG?")
print("PipelinePrompt 结果:", final)
response = llm.invoke(final)
# response 是 AIMessage 对象
answer = response.content
token_usage = response.response_metadata["token_usage"]
model_name = response.response_metadata["model_name"]
finish_reason = response.response_metadata["finish_reason"]
print("AI 回复:", answer)
print("Token用量:", token_usage)
print("模型名称:", model_name)
print("结束原因:", finish_reason)
Demo 03 · Memory 记忆 ↑ 返回目录
学习目标
- ✅ 掌握窗口记忆 WindowedMemory
- ✅ 掌握摘要记忆 SummaryMemory
- ✅ 理解
get_buffer_string的用法
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | WindowedMemory:只保留最近几轮对话;SummaryMemory:把长对话压缩成摘要;get_buffer_string():把消息列表转成可读文本,方便继续喂给模型;MessagesPlaceholder:把历史消息接入提示词;ChatPromptTemplate / StrOutputParser:负责接回推理链。学习目标组件: WindowedMemory、SummaryMemory、 get_buffer_string。 |
| 代码对应 | WindowedMemory(k=2) 保留最近窗口;SummaryMemory(llm, max_history=3) 负责自动摘要;get_buffer_string(...) 把消息列表转成可读上下文;summary_chain 让摘要后的上下文继续参与回答。 |
| 对比理解 | 窗口记忆保留原文但会丢掉更早内容,摘要记忆保信息密度但会损失细节。窗口适合短对话,摘要适合长对话,真实项目里通常要结合使用。 |
| 常见坑 | 常见坑是只保存在内存里、不做持久化;窗口太短会丢上下文,太长又会浪费 token;摘要会失真。建议长对话先摘要,再保留最近几轮原文,并持久化到 Redis 或数据库。 |
| 真实场景 | 用户希望助手“记得我”,但历史又不能无限增长。这个 Demo 讲的是如何把记忆做成一个可控的工程组件。 |
完整代码
# 文件:demo03_memory.py
from langchain_openai import ChatOpenAI
from langchain_core.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
)
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, get_buffer_string
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(
model="MiniMax-M2.7",
base_url="https://api.minimaxi.com/v1",
api_key=os.getenv("MINIMAX_API_KEY"),
temperature=0.7,
max_tokens=1000,
)
class WindowedMemory:
"""只保留最近 k 条消息的窗口记忆"""
def __init__(self, k: int = 6):
self.k = k
self.messages = []
def add_user_message(self, text: str):
self.messages.append(HumanMessage(content=text))
if len(self.messages) > self.k * 2:
self.messages = self.messages[-self.k * 2:]
def add_ai_message(self, text: str):
self.messages.append(AIMessage(content=text))
if len(self.messages) > self.k * 2:
self.messages = self.messages[-self.k * 2:]
def get_messages(self) -> list:
return self.messages[-self.k:]
class SummaryMemory:
"""AI 摘要记忆:对话太长时自动压缩"""
def __init__(self, llm, max_history: int = 20):
self.llm = llm
self.max_history = max_history
self.summary = ""
self.current_messages = []
def add_user_message(self, text: str):
self.current_messages.append(HumanMessage(content=text))
def add_ai_message(self, text: str):
self.current_messages.append(AIMessage(content=text))
def get_context(self) -> str:
recent = get_buffer_string(self.current_messages[-self.max_history:])
if self.summary:
return f"【历史摘要】{self.summary}\n\n【最近对话】\n{recent}"
return recent
def should_summarize(self) -> bool:
return len(self.current_messages) >= self.max_history * 2
def summarize(self):
summary_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="请把以下对话压缩成一段简短摘要,保留关键信息:"),
HumanMessagePromptTemplate.from_template("{messages}"),
])
self.summary = (
summary_prompt | self.llm | StrOutputParser()
).invoke({"messages": get_buffer_string(self.current_messages)})
self.current_messages = []
# 去掉 <think> 标签的辅助函数
def extract_plain_text(summary_with_thinking: str) -> str:
import re
text = re.sub(r'<think>.*?', '', summary_with_thinking, flags=re.DOTALL)
return text.strip()
# 示例
print("\n===== WindowedMemory 示例 =====")
w_memory = WindowedMemory(k=2)
w_memory.add_user_message("你好!")
w_memory.add_ai_message("你好,有什么可以帮你的?")
w_memory.add_user_message("我想了解 LangChain")
w_memory.add_ai_message("LangChain 是一个构建 LLM 应用的框架。")
print("只保留最近 2 条:", w_memory.get_messages())
print("\n===== SummaryMemory 示例 =====")
s_memory = SummaryMemory(llm, max_history=3)
s_memory.add_user_message("我想计划下个月去日本东京旅游")
s_memory.add_ai_message("东京旅游很棒!必去景点包括:浅草寺、东京塔...")
s_memory.add_user_message("签证怎么办理?")
s_memory.add_ai_message("日本旅游签证需要通过旅行社代办...")
s_memory.add_user_message("机票和酒店有推荐吗?")
s_memory.add_ai_message("机票建议提前2个月订,东京往返含税约2500-4500元...")
print(f"消息数: {len(s_memory.current_messages)}, 需摘要: {s_memory.should_summarize()}")
s_memory.summarize()
plain_summary = extract_plain_text(s_memory.summary)
print(f"压缩后摘要: {plain_summary}")

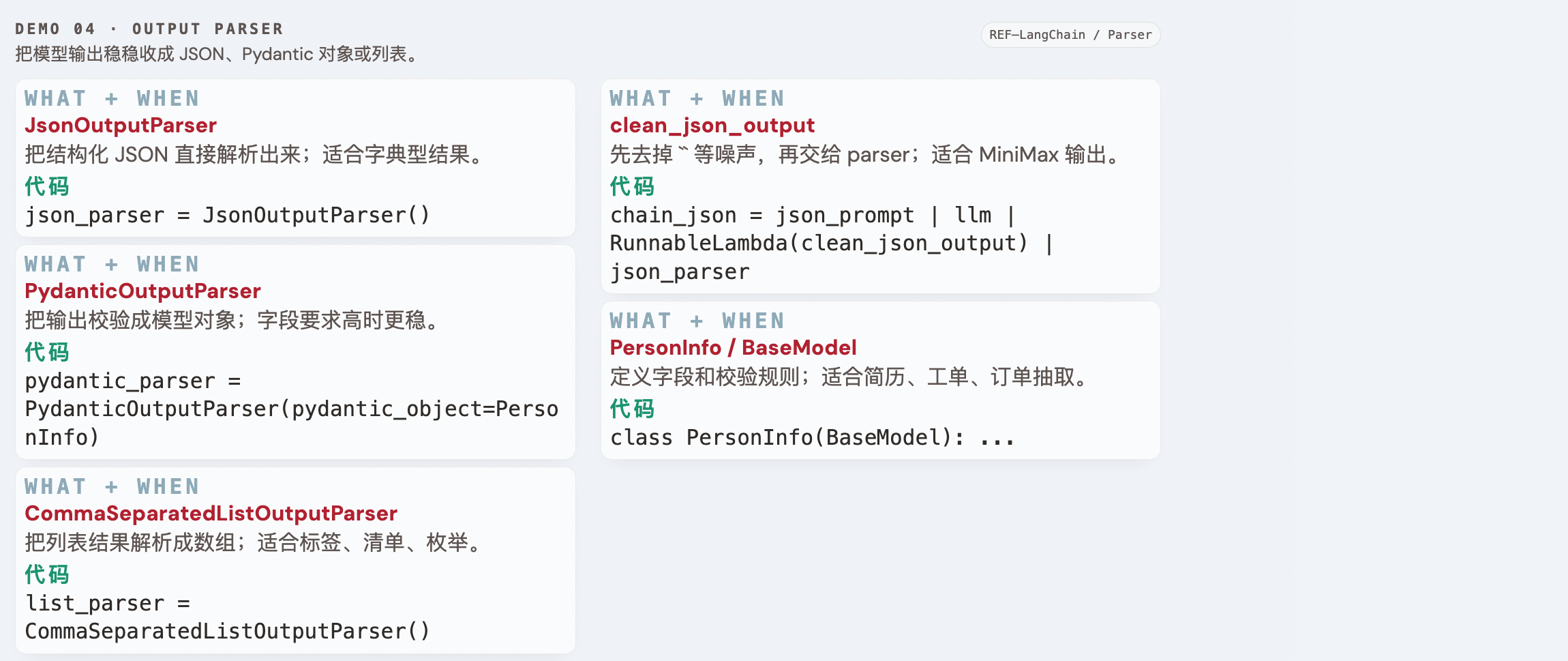
Demo 04 · Output Parser ↑ 返回目录
学习目标
- ✅ 掌握 JsonOutputParser
- ✅ 掌握 PydanticOutputParser + BaseModel
- ✅ 学会处理 MiniMax 输出的
<think>标签
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | JsonOutputParser:解析 JSON 字典;PydanticOutputParser:把输出校验成模型对象;CommaSeparatedListOutputParser:解析逗号列表;RunnableLambda:在 parser 前做清洗;clean_json_output() / clean_list_output():去掉 <think> 和中文标点噪声;PersonInfo / field_validator:定义字段和校验规则。学习目标组件: JsonOutputParser、PydanticOutputParser、BaseModel、 clean_json_output、RunnableLambda、CommaSeparatedListOutputParser。 |
| 代码对应 | build_llm() 把温度调到 0.0 降低漂移;chain_json = ... | RunnableLambda(clean_json_output) | json_parser 先清噪音再解析 JSON;PersonInfo 负责 schema 和字段校验;list_chain 负责把输出归一成逗号列表。 |
| 对比理解 | JSON 解析更灵活,Pydantic 解析更严格,列表解析更轻量;parser 负责“解析”,不负责“纠错”。结构越关键,校验就越要严格。 |
| 常见坑 | 常见坑是模型看起来像 JSON 但其实不是合法 JSON,中文标点会影响列表解析,只靠提示词也不够稳。建议关键字段做 schema 验证、重试和人工兜底。 |
| 真实场景 | 当你需要从简历、工单、合同或订单备注里抽字段时,最怕模型胡说八道。这个 Demo 讲的就是结构化输出。 |
完整代码
# 文件:demo04_output_parser.py
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.messages import SystemMessage
from langchain_core.output_parsers import (
JsonOutputParser,
PydanticOutputParser,
CommaSeparatedListOutputParser,
)
from langchain_core.runnables import RunnableLambda
from pydantic import BaseModel, Field, field_validator
import re
from dotenv import load_dotenv
import os
load_dotenv()
def build_llm() -> ChatOpenAI:
return ChatOpenAI(
model="MiniMax-M2.7",
base_url="https://api.minimaxi.com/v1",
api_key=os.getenv("MINIMAX_API_KEY"),
temperature=0.0,
max_tokens=1000,
timeout=60,
max_retries=2,
)
# 关键:处理 MiniMax 输出的 <think> 标签
def clean_json_output(input_str: str) -> str:
if hasattr(input_str, "content"):
input_str = input_str.content
# 去掉 <think>...
pattern = r"<think>.*?"
text = re.sub(pattern, "", str(input_str), flags=re.DOTALL)
return text.strip()
def clean_list_output(input_str: str) -> str:
text = clean_json_output(input_str)
return text.replace(",", ",").replace("、", ",")
def run_json_demo(llm: ChatOpenAI) -> None:
json_parser = JsonOutputParser()
json_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你是一个数据提取助手。只返回合法 JSON,不要解释。"),
HumanMessagePromptTemplate.from_template(
"从以下文本中提取信息,以 JSON 格式返回:\n{text}\n\n格式要求:\n{format}"
),
])
chain_json = json_prompt | llm | RunnableLambda(clean_json_output) | json_parser
result = chain_json.invoke({
"text": "布鲁斯,37岁,来自深圳,是一名技术合伙人,擅长 Python 和 Java。",
"format": json_parser.get_format_instructions(),
})
print("JSON 结果:", result)
# Pydantic 模型
class PersonInfo(BaseModel):
name: str = Field(description="人物姓名")
age: int = Field(description="人物年龄(必须是整数)")
city: str = Field(description="所在城市")
skills: list[str] = Field(default_factory=list, description="掌握的技能列表")
@field_validator("age")
@classmethod
def age_must_be_positive(cls, v: int) -> int:
if v <= 0 or v > 150:
raise ValueError(f"年龄 {v} 不合理!")
return v
def run_pydantic_demo(llm: ChatOpenAI) -> None:
pydantic_parser = PydanticOutputParser(pydantic_object=PersonInfo)
pydantic_prompt = (
ChatPromptTemplate.from_messages([
SystemMessage(content="你是一个数据提取助手。只返回符合格式要求的 JSON 本身。"),
HumanMessagePromptTemplate.from_template("从以下文本中提取信息:\n{text}\n\n{format}"),
])
.partial(format=pydantic_parser.get_format_instructions())
)
chain_pydantic = pydantic_prompt | llm | RunnableLambda(clean_json_output) | pydantic_parser
person: PersonInfo = chain_pydantic.invoke({
"text": "布鲁斯,37岁,深圳技术合伙人,擅长Node Python、Java、Go。"
})
print(f"姓名:{person.name},年龄:{person.age},城市:{person.city},技能:{person.skills}")
def run_list_demo(llm: ChatOpenAI) -> None:
list_parser = CommaSeparatedListOutputParser()
list_prompt = (
ChatPromptTemplate.from_messages([
SystemMessage(content="你是一个只输出逗号分隔列表的助手。使用英文逗号。"),
HumanMessagePromptTemplate.from_template("列出 {subject} 的 {n} 个优点。\n\n{format}"),
])
.partial(format=list_parser.get_format_instructions())
)
list_chain = list_prompt | llm | RunnableLambda(clean_list_output) | list_parser
result = list_chain.invoke({"subject": "Python", "n": 5})
print("列表结果:", result)
def main() -> None:
llm = build_llm()
# run_json_demo(llm)
# run_pydantic_demo(llm)
run_list_demo(llm)
if __name__ == "__main__":
main()
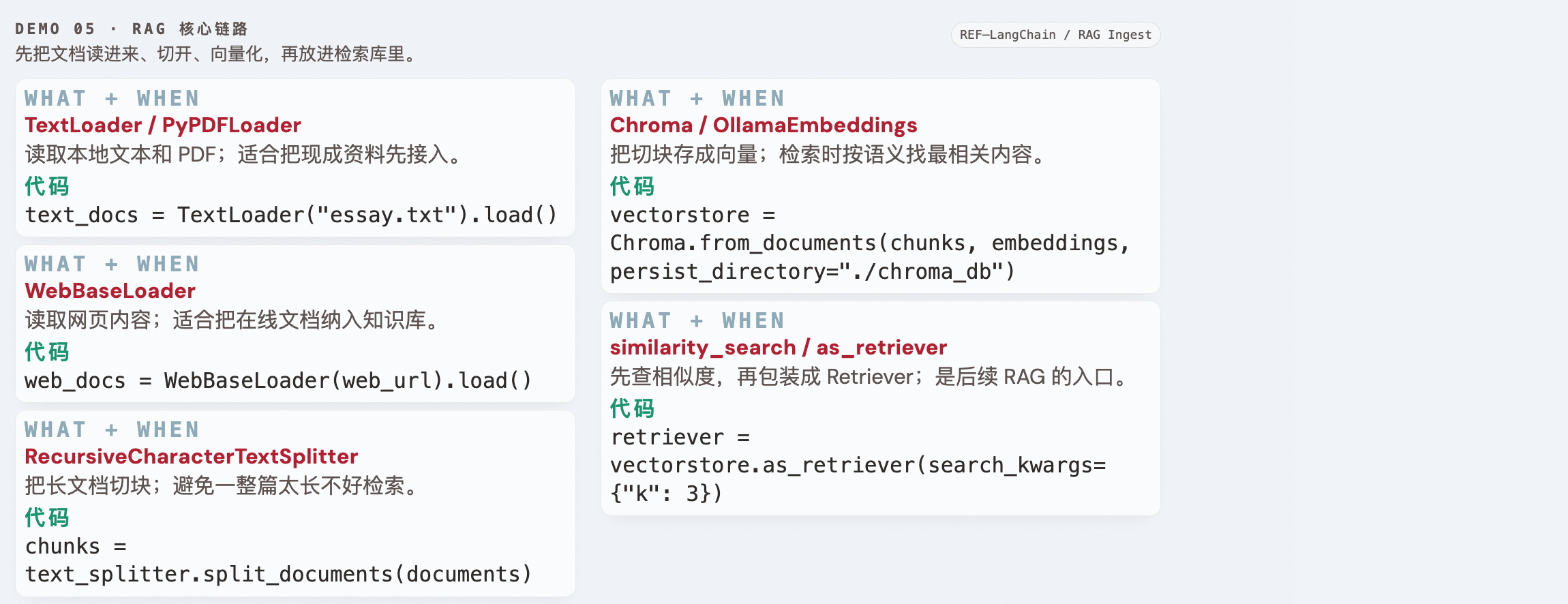
Demo 05 · RAG 核心链路 ↑ 返回目录
学习目标
- ✅ 掌握 TextLoader / PyPDFLoader / WebBaseLoader
- ✅ 掌握 RecursiveCharacterTextSplitter
- ✅ 掌握 Chroma 向量库 + Ollama Embedding
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | TextLoader:读本地文本;PyPDFLoader:读 PDF;WebBaseLoader:读网页;RecursiveCharacterTextSplitter:把长文切块;Chroma:存向量并检索;OllamaEmbeddings:把文本转成向量;requests:做 Ollama 健康检查;Document:统一承载内容和 metadata。学习目标组件: TextLoader、PyPDFLoader、WebBaseLoader、RecursiveCharacterTextSplitter、Chroma、OllamaEmbeddings。 |
| 代码对应 | build_embeddings() 先做 Ollama 健康检查;load_documents() 把文本、PDF、网页统一成 Document;split_documents() 切块;build_vectorstore() 写入 Chroma;run_queries() 验证检索效果。 |
| 对比理解 | 文档加载和文档切块是两件事;similarity_search() 只看结果,similarity_search_with_score() 还能看分数;不同来源最终都要统一成 Document 列表。 |
| 常见坑 | 常见坑是文档来源不统一、切块过大或过小、网页加载受网络影响。建议入库前做清洗、去重、metadata 标注,文档更新后做重建或增量同步。 |
| 真实场景 | 企业知识库、FAQ 搜索、产品文档问答,都需要先把文本处理成向量库。这个 Demo 讲的是“入库”阶段。 |
完整代码
# 文件:demo05_rag_ingest.py
from pathlib import Path
import os
import requests
from dotenv import load_dotenv
from langchain_community.document_loaders import TextLoader, PyPDFLoader, WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
load_dotenv()
def build_embeddings() -> OllamaEmbeddings:
"""使用本地 Ollama embedding 模型"""
model = os.getenv("OLLAMA_EMBED_MODEL", "qwen3-embedding:0.6b")
base_url = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434")
# 检查 Ollama 服务
health_url = f"{base_url.rstrip('/')}/api/tags"
try:
requests.get(health_url, timeout=3)
except requests.RequestException as exc:
raise RuntimeError(f"Ollama 服务不可用,请先启动 ollama") from exc
return OllamaEmbeddings(model=model, base_url=base_url)
def load_documents() -> list[Document]:
"""读取本地文本 / PDF / 网页"""
# 文本
text_path = Path("essay.txt")
if text_path.exists():
text_docs = TextLoader(str(text_path), encoding="utf-8").load()
else:
text_docs = [Document(
page_content="LangChain 是一个用于构建 LLM 应用的框架。",
metadata={"source": "inline:essay.txt"},
)]
print("essay.txt 不存在,已使用内置示例文本代替。")
# PDF
pdf_path = Path("paper.pdf")
if pdf_path.exists():
pdf_docs = PyPDFLoader(str(pdf_path)).load()
else:
pdf_docs = []
print("paper.pdf 不存在,已跳过 PDF 读取。")
# 网页
web_url = "https://python.langchain.com/docs/introduction"
try:
web_docs = WebBaseLoader(web_url).load()
except Exception as exc:
web_docs = []
print(f"网页读取失败,已跳过:{exc}")
return text_docs + pdf_docs + web_docs
def split_documents(documents: list[Document]) -> list[Document]:
"""切块"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=len,
add_start_index=True,
)
chunks = text_splitter.split_documents(documents)
print(f"切块数: {len(chunks)}")
return chunks
def build_vectorstore(chunks: list[Document], embeddings: OllamaEmbeddings) -> Chroma:
"""构建向量库"""
return Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db",
)
def run_queries(vectorstore: Chroma) -> None:
"""检索测试"""
# 相似度检索
query = "LangChain 的核心概念是什么?"
docs = vectorstore.similarity_search(query=query, k=3)
for i, doc in enumerate(docs, 1):
print(f"[{i}] {doc.page_content[:150]}")
# 带分数的检索
docs_with_scores = vectorstore.similarity_search_with_score(query=query, k=3)
for doc, score in docs_with_scores:
print(f" [分数:{score:.4f}] {doc.page_content[:100]}")
# Retriever
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
retrieved_docs = retriever.invoke("LangChain 是什么?")
print(f"Retriever 返回 {len(retrieved_docs)} 个文档块")
def main() -> None:
embeddings = build_embeddings()
documents = load_documents()
for doc in documents:
print(doc.metadata)
chunks = split_documents(documents)
for i, chunk in enumerate(chunks, 1):
print(f"Chunk {i}: 长度={chunk.page_content.__len__()}, 元数据={chunk.metadata}")
vectorstore = build_vectorstore(chunks, embeddings)
run_queries(vectorstore)
if __name__ == "__main__":
main()
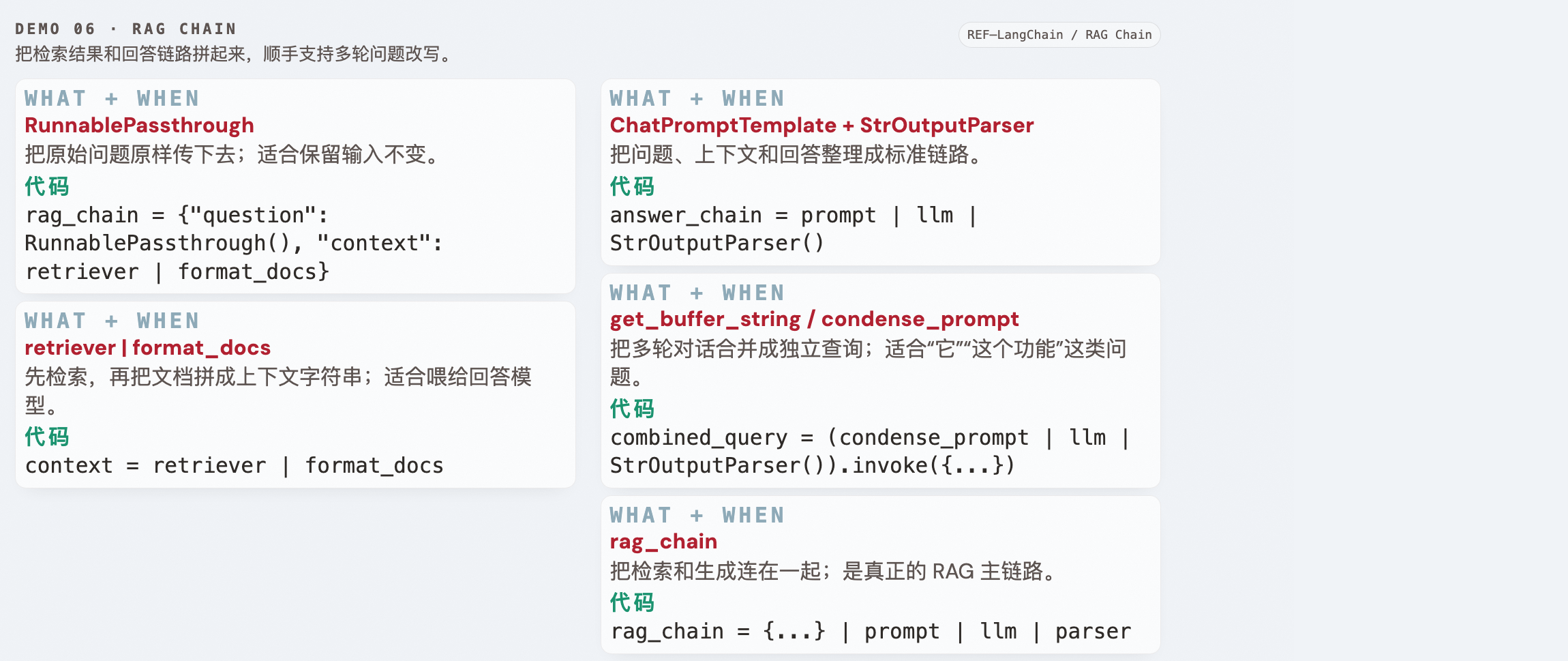
Demo 06 · RAG Chain ↑ 返回目录
学习目标
- ✅ 掌握 RAG Chain 的 LCEL 组装
- ✅ 理解 RunnablePassthrough 透传
- ✅ 掌握多轮 RAG(condense query)
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | RunnablePassthrough:原样透传问题;retriever:负责检索;format_docs():把检索结果拼成字符串上下文;ChatPromptTemplate:组织回答提示词;StrOutputParser:输出字符串;get_buffer_string():把历史对话转成文本;ChatOpenAI / OllamaEmbeddings / Chroma:分别负责生成、向量化和向量库。学习目标组件: RunnablePassthrough、retriever、 format_docs、ChatPromptTemplate、StrOutputParser、get_buffer_string。 |
| 代码对应 | rag_chain = {"question": RunnablePassthrough(), "context": retriever | format_docs} | prompt | llm | parser 负责检索+回答;condense_prompt 负责把多轮问题改写成独立查询;final_chain 负责把检索到的文档内容转成最终答案。 |
| 对比理解 | 主流程负责检索和回答,改写流程负责把“它”“这个功能”这类多轮问题转成独立查询;在这条链里 context 是字符串,不是消息列表。 |
| 常见坑 | 常见坑是检索结果没有来源、问题改写偏题、上下文过长导致超窗。建议加来源标签,先 rewrite 再 retrieval,回答里加“未找到”兜底。 |
| 真实场景 | 用户常常会说“这个功能”“它”“上一条那个问题”,而不是完整句子。这个 Demo 讲的是知识检索和多轮上下文怎么接起来。 |
完整代码
# 文件:demo06_rag_chain.py
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.messages import SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.messages import HumanMessage, AIMessage, get_buffer_string
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# 使用 MiniMax 作为 LLM
llm = ChatOpenAI(
model="MiniMax-M2.7",
base_url="https://api.minimaxi.com/v1",
api_key=os.getenv("MINIMAX_API_KEY"),
temperature=0.7,
max_tokens=1000,
timeout=60,
max_retries=2,
)
# 使用 Ollama 作为 Embedding
embeddings = OllamaEmbeddings(
model="qwen3-embedding:0.6b",
base_url="http://localhost:11434",
)
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
def format_docs(docs):
return "\n\n".join(f"[来源{i+1}] {d.page_content}" for i, d in enumerate(docs))
# RAG Chain
rag_chain = (
{"question": RunnablePassthrough(), "context": retriever | format_docs}
| ChatPromptTemplate.from_messages([
SystemMessage(content=(
"你是知识渊博的助手,基于文档片段回答。"
"如果文档中没有答案,说「没有找到相关信息」,不要编造。"
)),
HumanMessagePromptTemplate.from_template("文档内容:\n{context}\n\n问题:{question}"),
])
| llm
| StrOutputParser()
)
result = rag_chain.invoke("LangChain 是什么?有哪些核心概念?")
print("RAG 结果:", result[:200])
# 多轮 RAG(合并历史问题)
chat_history = [
HumanMessage(content="LangChain 支持哪些模型?"),
AIMessage(content="LangChain 支持 OpenAI、Anthropic、Google Gemini、HuggingFace 等主流 LLM。"),
]
condense_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="把对话历史和最新问题合并成一个独立的问题。"),
HumanMessagePromptTemplate.from_template("历史:{chat_history}\n\n最新问题:{question}"),
])
combined_query = (
condense_prompt | llm | StrOutputParser()
).invoke({
"chat_history": get_buffer_string(chat_history),
"question": "那 embedding 模型呢?",
})
print("合并检索词:", combined_query)
docs = retriever.invoke(combined_query)
final_chain = (
ChatPromptTemplate.from_messages([
SystemMessage(content="基于文档回答问题。"),
HumanMessagePromptTemplate.from_template("文档:\n{context}\n\n问题:{question}"),
])
| llm
| StrOutputParser()
)
answer = final_chain.invoke({"context": format_docs(docs), "question": combined_query})
print("最终答案:", answer)
Demo 07 · Tool + Agent ↑ 返回目录
学习目标
- ✅ 掌握 @tool 装饰器定义工具
- ✅ 掌握 create_agent 的用法
重点知识强化
| 知识模块 | 内容 |
|---|---|
| 组件说明 | @tool:把普通函数注册成工具;create_agent:创建会自己选工具的 Agent; |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)