基于灰狼优化算法优化随机森林算法(GWO - RF)的数据分类预测
基于灰狼优化算法优化随机森林算法(GWO-RF)的数据分类预测 GWO-RF数据分类 利用交叉验证抑制过拟合问题 matlab代码, 注:要求Matlab2018B 版本及以上 注:采用 RF 工具箱(无需安装,可直接运行),仅支持 Windows 64位系统
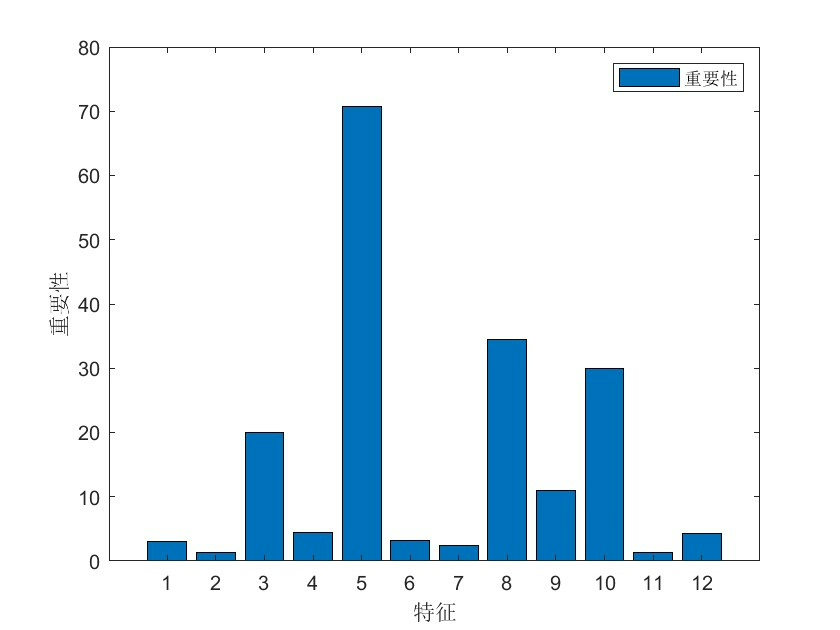
在数据挖掘和机器学习领域,数据分类预测是一项极为重要的任务。随机森林(Random Forest,RF)算法作为一种强大的集成学习方法,在众多分类问题中表现出色。然而,RF 算法的一些参数选择可能影响其性能,这时候就可以借助灰狼优化算法(Grey Wolf Optimizer,GWO)来对其进行优化,从而提升分类预测的准确率。同时,为了避免过拟合问题,我们采用交叉验证的方法。本文将结合 Matlab 代码来详细介绍这一过程。
灰狼优化算法(GWO)简介
灰狼优化算法是一种受灰狼群体捕食行为启发的元启发式优化算法。在 GWO 中,灰狼群体被分为四个等级:α、β、δ 和 ω。α 狼是领导者,负责决策;β 和 δ 狼协助 α 狼进行决策;ω 狼则服从其他等级的狼。在搜索空间中,灰狼们通过互相协作来逼近猎物(最优解)。
随机森林算法(RF)简介
随机森林是由多个决策树组成的集成学习模型。在构建随机森林时,从原始训练数据集中有放回地随机抽取样本构建每棵决策树,并且在每个节点分裂时,随机选择一部分特征来寻找最佳分裂点。最终的预测结果通过对所有决策树的预测结果进行投票(分类问题)或平均(回归问题)得到。它具有较好的泛化能力,对噪声和离群点相对鲁棒。
利用交叉验证抑制过拟合问题
过拟合是机器学习中常见的问题,它会导致模型在训练集上表现良好,但在测试集上表现不佳。交叉验证是一种有效的抑制过拟合的方法。简单来说,就是将原始数据集分成多个子集,每次用一部分子集作为训练集,另一部分作为验证集,多次训练和验证后取平均结果,以此来评估模型的性能,确保模型具有较好的泛化能力。
Matlab 代码实现
1. 数据准备
% 假设数据存储在一个文件中,格式为特征在前,标签在后
data = readtable('your_data_file.csv');
features = table2array(data(:,1:end - 1));
labels = table2array(data(:,end)); 这里我们使用 readtable 函数读取存储数据的 CSV 文件,然后将特征和标签分别提取出来,为后续建模做准备。
2. 灰狼优化算法实现
% GWO 参数设置
SearchAgents_no = 50; % 灰狼数量
Max_iteration = 100; % 最大迭代次数
dim = length(parameters_to_optimize); % 待优化参数的维度
lb = [1 1 1]; % 待优化参数的下限
ub = [100 10 50]; % 待优化参数的上限
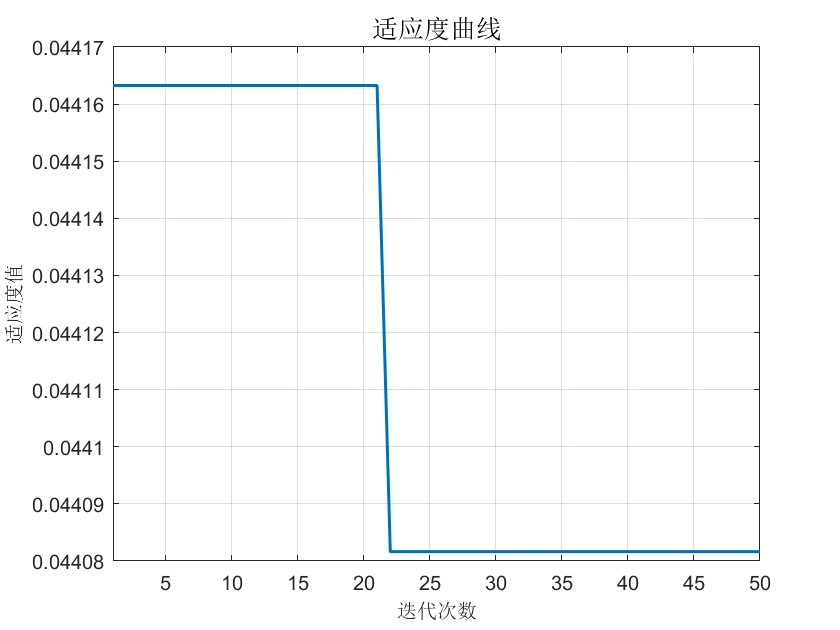
[Best_score,Best_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj);在这段代码中,我们设置了灰狼优化算法的基本参数,包括灰狼的数量、最大迭代次数、待优化参数的维度以及参数的上下限。fobj 是适应度函数,它用于评估每个灰狼位置(即一组随机森林参数)的优劣。
3. 随机森林模型构建与优化
% 利用优化后的参数构建随机森林模型
numTrees = Best_pos(1); % 优化后的树的数量
minLeaf = Best_pos(2); % 优化后的最小叶子节点样本数
maxDepth = Best_pos(3); % 优化后的最大深度
rfModel = TreeBagger(numTrees,features,labels,'Method','classification','MinLeaf',minLeaf,'MaxDepth',maxDepth);这里我们根据灰狼优化算法得到的最优参数来构建随机森林模型。TreeBagger 是 Matlab 中随机森林的实现函数,通过传入优化后的参数,我们可以得到一个性能较好的随机森林模型。
4. 交叉验证
cv = cvpartition(labels,'KFold',5); % 5折交叉验证
accuracy = zeros(cv.NumTestSets,1);
for i = 1:cv.NumTestSets
training = cv.training(i);
test = cv.test(i);
trainFeatures = features(training,:);
trainLabels = labels(training);
testFeatures = features(test,:);
testLabels = labels(test);
numTrees = Best_pos(1);
minLeaf = Best_pos(2);
maxDepth = Best_pos(3);
rfModel = TreeBagger(numTrees,trainFeatures,trainLabels,'Method','classification','MinLeaf',minLeaf,'MaxDepth',maxDepth);
predictions = predict(rfModel,testFeatures);
accuracy(i) = sum(predictions == testLabels)/length(testLabels);
end
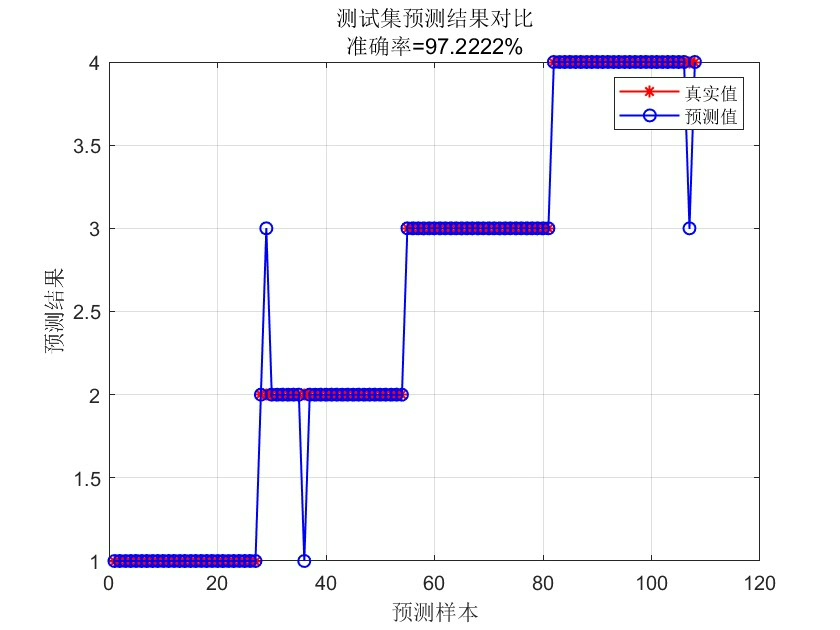
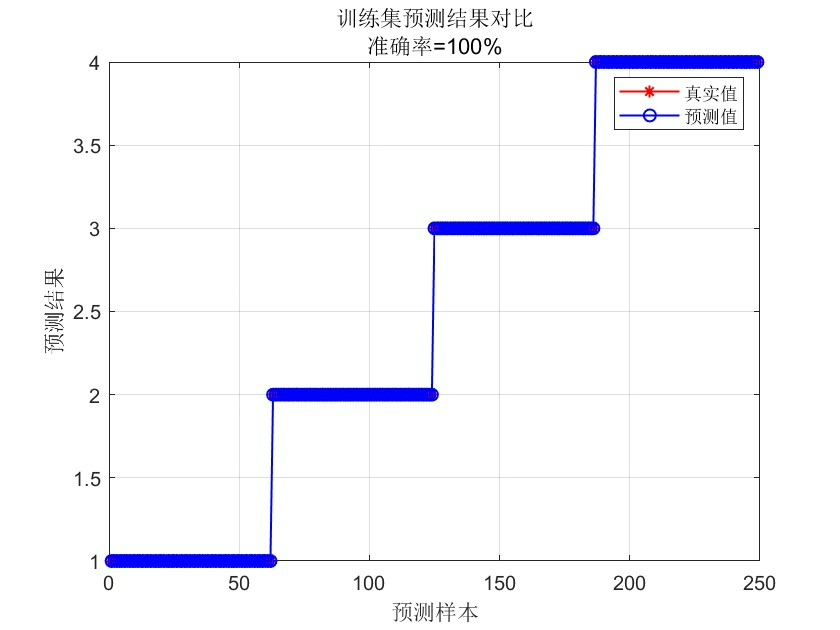
avg_accuracy = mean(accuracy);这段代码实现了 5 折交叉验证。我们将数据集分成 5 份,每次使用其中 4 份作为训练集,1 份作为测试集。在每次循环中,根据优化后的参数构建随机森林模型,并对测试集进行预测,计算预测准确率。最后,取所有测试集准确率的平均值作为模型的最终性能指标。
基于灰狼优化算法优化随机森林算法(GWO-RF)的数据分类预测 GWO-RF数据分类 利用交叉验证抑制过拟合问题 matlab代码, 注:要求Matlab2018B 版本及以上 注:采用 RF 工具箱(无需安装,可直接运行),仅支持 Windows 64位系统
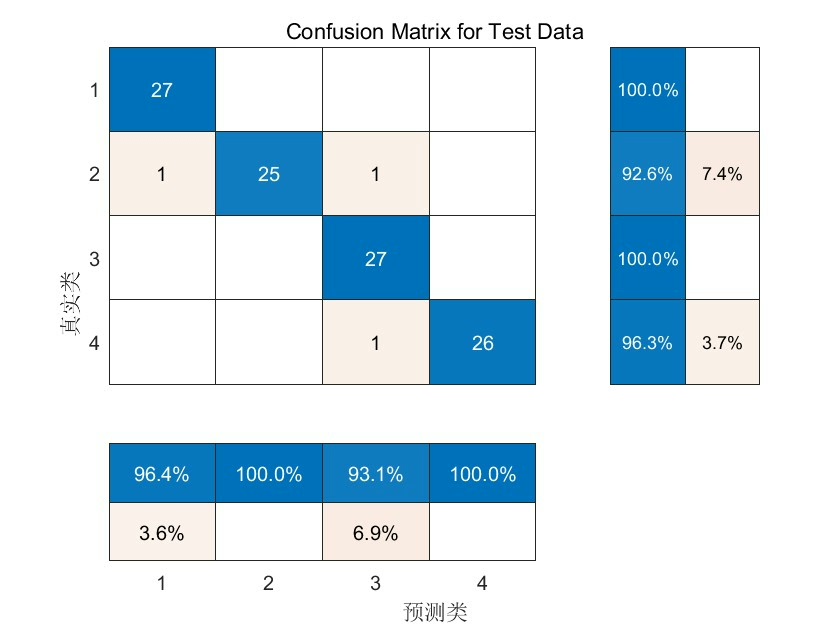
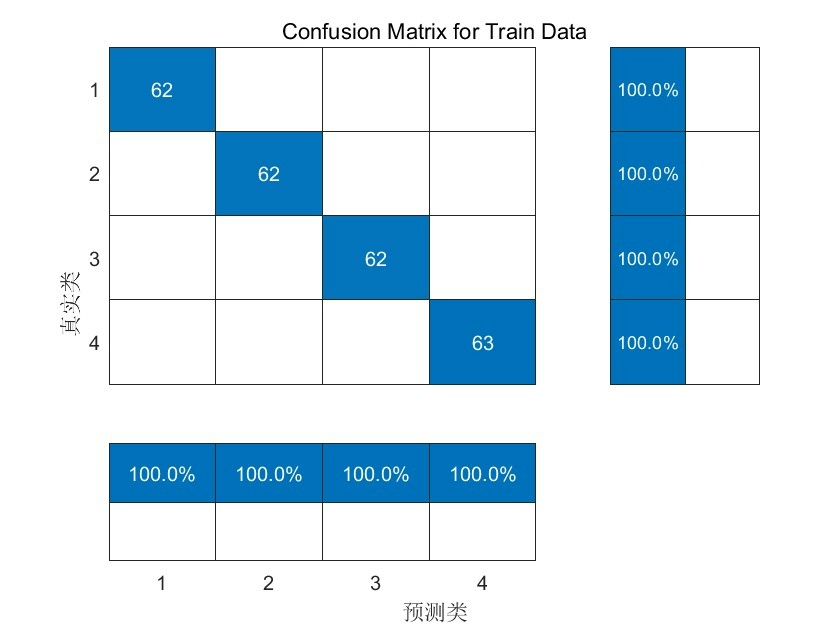
需要注意的是,本文的代码基于 Matlab 2018B 版本及以上,采用 RF 工具箱(无需安装,可直接运行),并且仅支持 Windows 64 位系统。通过上述步骤,我们实现了基于灰狼优化算法优化随机森林算法的数据分类预测,并利用交叉验证抑制了过拟合问题,希望能为你的相关研究或项目提供一些参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)