AI 大模型落地系列|Eino 编排篇:既然有了 Chain、Graph,为何还需要 Workflow
声明:本文数据源于官方文档与官方示例,重点参考 Workflow 编排框架、Chain/Graph 编排介绍 与 eino-examples/compose/workflow。
既然有了 Chain、Graph,为何还需要 Workflow
很多人学完 Eino的 Chain / Graph 之后,会产生一个很自然的判断:
流程都能连起来了,为什么还要再学一个 Workflow 这种编排方式?
1. 为什么 Chain/Graph 讲完了,还要单独学 Workflow
之前博客中说过 Chain / Graph 的区别:
Chain更像“把固定步骤按顺序串起来”Graph更像“流程在不同节点之间怎么分支、跳转、汇合”
这两句话对大多数编排问题都成立。
但当你继续往工程里走,会遇到一类更细的麻烦:
- 节点 A 和节点 B 的输入输出类型根本不对齐
- 节点 D 的执行顺序受 B、C 控制,但它还想读 A 的一个字段
- 节点 E 只需要等 D 执行完成,却完全不关心 D 的输出
这类问题,Graph 不是不能做。
只是你往往要在下面几种方案里二选一:
- 把多个节点都改成同一种输入输出结构
- 中间塞
map[string]any - 借
OutputKey / InputKey / state兜一层
这些办法能解决问题,但表达不够直接。所以需要引入 workflow。
我觉得官方给的解释,就非常恰当。
官方是这样说的: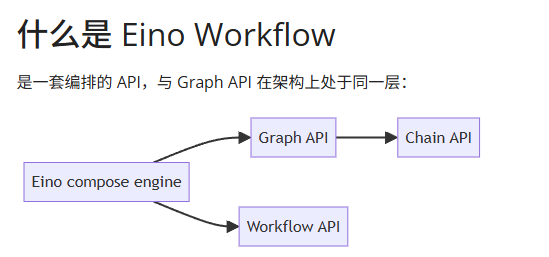
本质特点是:
- 与 Graph API 具有同等级别的能力,都是编排“围绕大模型的信息流”的合适框架工具。
- 在节点类型、流处理、callback、option、state、interrupt & checkpoint 等方面保持一致。
- 实现 AnyGraph 接口,可以在 AddGraphNode 时作为子图加入上级 Graph/Chain/Workflow。
- 也可以把其他 Graph/Chain/Workflow 添加为自己的子图。
- 字段级别映射能力:节点的输入可以由任意前驱节点的任意输出字段组合而成。
- 原生支持 struct,map 以及任意嵌套层级的 struct 和 map 之间的相互映射。
- 控制流与数据流分离:Graph 的 Edge 是既决定执行顺序,又决定数据传递。Workflow 中可以一起传递,也可以分开传递。
- 不支持环(即类似 react agent 的 chatmodel->toolsNode->chatmodel 的环路)。NodeTriggerMode 固定为 AllPredecessor。
所以别把它理解成“Graph 的语法糖”。
Graph 主要解决节点关系建模,Workflow 主要解决字段级编排建模。
这两者不是高低关系,是表达重点不同。
2. Workflow 真正解决的 2 个工程问题
2.1 现有业务函数的输入输出,不必为了编排而改形状
假设你已经有两个业务函数:
f1(ctx, OrderInput) -> RiskMaterialf2(ctx, AuditContext) -> AuditResult
现在你只想把 f1 的 UserTags、OrderAmount 这两个字段,映射给 f2 的 Tags、Amount。
(想要理解 workflow 的重点之一,就是明白映射的含义)
如果你只用 Graph,通常有两条路:
- 把两个函数都改成吃同一个 common struct
- 统一退化成
map[string]any
前者侵入业务函数签名,后者牺牲强类型边界。
Workflow 的思路不一样:
- 节点签名继续服从业务
- 编排层只声明“从谁的哪个字段,映射到谁的哪个字段”
这不是语法糖,而是边界表达。
它让业务函数继续保持自己的输入输出语义,而不是为了拼装执行图去迁就编排框架。
2.2 控制流和数据流,可以拆开表达
再看另一个常见场景。
假设有一条链路:
START提供用户原始请求Retriever负责查知识库Ranker决定是否需要补充召回PromptBuilder最终组装 promptLogger只负责记录“组装已完成”
这里很容易出现两种关系:
PromptBuilder的执行顺序受Ranker控制,但它同时还想读取START.prompt和Retriever.contextLogger必须在PromptBuilder之后执行,但它并不消费PromptBuilder的输出
如果把这两类关系都压成同一种边,你能写出来,但图的语义会越来越绕。
Workflow 则把这件事拆开了:
- 有些边同时承担控制和数据
- 有些边只承担数据
- 有些边只承担控制
你可能还不理解,请看demo:
3. 先看最小闭环,再看为什么它不只是 Graph 套壳
先看一个最简单的 Workflow:
// 创建一个 Workflow:输入类型是 int,输出类型是 string
wf := compose.NewWorkflow[int, string]()
// 添加一个 Lambda 节点:接收 int,转成 string
wf.AddLambdaNode("lambda", compose.InvokableLambda(
func(ctx context.Context, in int) (string, error) {
return strconv.Itoa(in), nil
}),
// 声明该节点的输入来自流程起点 START
).AddInput(compose.START)
// 声明流程终点 END 的输入来自 lambda 节点
wf.End().AddInput("lambda")
// 编译 Workflow,生成可执行的 runner
runner, err := wf.Compile(context.Background())
if err != nil {
panic(err)
}
// 执行流程:传入 1,得到字符串结果
out, err := runner.Invoke(context.Background(), 1)
if err != nil {
panic(err)
}
// 输出结果:1
fmt.Println(out)
这个例子看起来确实很像 Graph。
因为这里的映射是“整体到整体”:
START的全部输出,给lambda的全部输入lambda的全部输出,给END的全部输入
所以它在效果上接近一条普通边。
但这段代码里,已经有几个对后面很关键的点:
1. NewWorkflow[I, O] 先把整体边界定死。
这和 Graph 一样,入口和出口的类型在图创建时就确定了。
2. AddXXXNode 返回的是 *WorkflowNode。
这意味着你不是“先加节点,再单独配置关系”。
而是可以直接对节点做方法链式配置,比如:
AddInputAddInputWithOptionsSetStaticValue
3. Workflow 把很多错误延迟到 Compile。
Graph 的 AddXXXNode 往往更早暴露错误。Workflow 则倾向于把字段映射、依赖关系、类型对齐等问题统一放到 Compile 里检查。
4. 如果你觉得他跟 Graph 没两样
那请看下方这个demo,你就会明白了。
4. 字段映射为什么是 Workflow 的主角
Workflow 最核心的能力,不是多了几个方法名。
而是它把编排粒度从“节点到节点”推进到了“字段到字段”。
看一个很典型的例子:
- 整体输入是
message message.Message.Content给计数器c1message.Message.ReasoningContent给计数器c2- 两个计数结果最后汇总到
END
代码可以写成这样:
type counter struct {
FullStr string // 被统计的大字符串
SubStr string // 要查找的子串
}
type message struct {
*schema.Message // 原始消息,里面有 Content 和 ReasoningContent
SubStr string // 要统计的目标子串
}
// 统计子串在指定字符串中出现的次数
wordCounter := func(ctx context.Context, c counter) (int, error) {
return strings.Count(c.FullStr, c.SubStr), nil
}
// Workflow: 输入 message,输出统计结果 map
wf := compose.NewWorkflow[message, map[string]any]()
// c1:统计 SubStr 在 Message.Content 中出现的次数
wf.AddLambdaNode("c1", compose.InvokableLambda(wordCounter)).
AddInput(
compose.START,
compose.MapFields("SubStr", "SubStr"), // message.SubStr -> counter.SubStr
compose.MapFieldPaths([]string{"Message", "Content"}, []string{"FullStr"}),
// message.Message.Content -> counter.FullStr
)
// c2:统计 SubStr 在 Message.ReasoningContent 中出现的次数
wf.AddLambdaNode("c2", compose.InvokableLambda(wordCounter)).
AddInput(
compose.START,
compose.MapFields("SubStr", "SubStr"), // message.SubStr -> counter.SubStr
compose.MapFieldPaths([]string{"Message", "ReasoningContent"}, []string{"FullStr"}), // message.Message.ReasoningContent -> counter.FullStr
)
// 汇总两个节点结果到输出 map
wf.End().
AddInput("c1", compose.ToField("content_count")).
AddInput("c2", compose.ToField("reasoning_content_count"))
这段代码最该注意的不是“数了几个字符”。
而是它把 3 件事一次性说清楚了:
- 一个节点可以从同一个前驱拿多个字段
- 一个节点也可以从多个前驱拿字段
- 字段映射和节点签名是分开的
这就带来了 Workflow 最重要的设计收益:
让节点签名服从业务,而不是服从编排。
4.1 常用 FieldMapping helper 应该怎么理解
这些 helper 不难记,但更重要的是记住它们解决的是什么映射关系:
(可以关注一下to与from出现时,上下游转换的方式。)
compose.MapFields("A", "B")- 顶层字段到顶层字段
compose.MapFieldPaths([]string{"req", "body"}, []string{"payload"})- 嵌套路径到路径
compose.ToField("result")- 把上游整体输出塞进下游某个字段
compose.FromField("payload")- 把上游某个字段当成下游整体输入
compose.ToFieldPath([]string{"result", "payload"})- 把上游整体输出塞进下游嵌套路径
compose.FromFieldPath([]string{"req", "body"})- 把上游嵌套字段当成下游整体输入
比如下面这个片段,就把这几个 helper 放在了一起:
wf.AddLambdaNode("validate", compose.InvokableLambda(validateBody)).
AddInput(compose.START, compose.FromFieldPath([]string{"req", "body"}))
wf.End().
AddInput("validate", compose.ToFieldPath([]string{"result", "payload"}))
第一句的意思是:
START.req.body这段嵌套字段,作为validate节点的完整输入
第二句的意思是:
validate的整体输出,塞到END.result.payload
这类表达,在 Graph 里往往就得借助中间结构、state 或额外节点了。
4.2 映射不是自由拼装,Workflow 有几条硬规则
字段映射很灵活,但不是没有约束。
第一,merge 只能往不同字段合。
下面这种是允许的:
c1 -> END.content_countc2 -> END.reasoning_content_count
但如果多个映射都往同一个字段写,Compile 会报冲突。
第二,整体映射和字段映射不能混着往同一个输入上塞。
比如你一边 AddInput("x"),一边又 AddInput("y", compose.ToField("k")),只要两者指向同一个目标输入,就会形成冲突。
第三,struct 参与映射时,字段必须导出。
因为内部要走反射。
如果字段没导出,映射本身就不成立。
// 首字母大小写的原因
type Req struct {
Body string // 导出字段
body string // 未导出字段
}
第四,类型校验有些发生在 Compile,有些只能推迟到运行时。
比如:
- 上游
int,下游string,这种在Compile阶段就能判死刑 - 上游
any,下游int,只有真正跑起来,拿到值的实际类型后才能判断
所以别把 Compile 理解成形式化步骤。
它其实在替你提前挡掉一大批字段级错误。
5. 真正把 Workflow 和 Graph 拉开差距的,是控制流与数据流解耦
如果字段映射解决的是“谁给谁什么数据”,
那控制流与数据流拆开,解决的就是“谁决定谁执行”和“谁给谁数据”不一定是同一件事。
5.1 只有数据流,没有控制流
看一个简单例子:
adder先把一组整数求和mul再把求和结果和START.Multiply相乘
其中 mul 的执行顺序受 adder 控制,
但 mul.B 这个字段的数据来自 START,不是来自 adder。
代码如下:
type calculator struct {
Add []int // 需要先做加法的一组数字
Multiply int // 再用于乘法的数字
}
type mul struct {
A int // 第一个乘数
B int // 第二个乘数
}
// 创建 Workflow:输入 calculator,最终输出 int
wf := compose.NewWorkflow[calculator, int]()
// adder 节点:只取输入里的 Add 字段,交给 adder 计算
wf.AddLambdaNode("adder", compose.InvokableLambda(adder)).
AddInput(compose.START, compose.FromField("Add"))
// mul 节点:调用 multiplier,入参类型应为 mul
wf.AddLambdaNode("mul", compose.InvokableLambda(multiplier)).
// 把 adder 的输出结果作为 mul.A
AddInput("adder", compose.ToField("A")).
AddInputWithOptions(
compose.START,
[]*compose.FieldMapping{
// 把输入里的 Multiply 字段映射到 mul.B
compose.MapFields("Multiply", "B"),
},
// 这里只做字段取值,不把 START 视为 mul 的直接依赖边
compose.WithNoDirectDependency(),
)
// 结束节点:直接接收 mul 的输出,作为 Workflow 最终结果
wf.End().AddInput("mul")
这里最关键的是:
AddInput("adder", compose.ToField("A"))建立了正常的控制 + 数据依赖AddInputWithOptions(..., compose.WithNoDirectDependency())只负责把START.Multiply这个数据注入给mul.B
也就是说,START 不直接决定 mul 何时执行。
它只是提供 mul 要消费的一块数据。
这不是“跨节点随便取值”,而是“在已有控制路径上补一条纯数据依赖”。
这一点非常重要。
纯数据依赖仍然要求存在可达控制路径。
如果控制上根本到不了,你也不能靠 Workflow 硬把字段从图外抠过来。
5.2 只有控制流,没有数据流
再看另一个更像真实业务的场景:
b1先报价announcer只负责记录“报价 1 已完成”- 分支判断报价是否足够高
- 不够高就轮到
b2
这里 announcer 必须在 b1 之后执行,但它不应该吃到 b1 的报价数据。
这时就该用 AddDependency:
// 创建一个 Workflow:输入是一个 float64,输出是 map[string]float64
wf := compose.NewWorkflow[float64, map[string]float64]()
// 节点 b1:直接接收 START 的输入,调用 bidder1
wf.AddLambdaNode("b1", compose.InvokableLambda(bidder1)).
AddInput(compose.START)
// 节点 announcer:不消费数据,只声明执行上依赖 b1
// 也就是 b1 执行完后,announcer 才能执行
wf.AddLambdaNode("announcer", compose.InvokableLambda(announcer)).
AddDependency("b1")
// 给 b1 添加分支:根据 b1 的输出结果决定下一步去哪
wf.AddBranch("b1", compose.NewGraphBranch(
func(ctx context.Context, in float64) (string, error) {
// 如果 b1 的结果大于 5,流程直接结束,不再走 b2
if in > 5.0 {
return compose.END, nil
}
// 否则继续走 b2
return "b2", nil
},
map[string]bool{
compose.END: true, // 合法分支目标:END
"b2": true, // 合法分支目标:b2
},
))
// 节点 b2:也使用原始输入 START,调用 bidder2
// WithNoDirectDependency 表示这里主要是取 START 的值,不额外强调一条显式依赖边
wf.AddLambdaNode("b2", compose.InvokableLambda(bidder2)).
AddInputWithOptions(compose.START, nil, compose.WithNoDirectDependency())
// 结束节点:汇总结果
// b1 的输出放到最终结果的 bidder1 字段
// b2 的输出放到最终结果的 bidder2 字段
wf.End().
AddInput("b1", compose.ToField("bidder1")).
AddInput("b2", compose.ToField("bidder2"))
这里的语义很清楚:
AddDependency("b1")只建立控制依赖announcer不消费b1输出b2是否执行由branch决定b2自己的输入则通过别的映射关系单独声明
这就是 Workflow 和 Graph 在 branch 语义上的一个关键差别:
Graph 里的 branch 更像“控制和数据一起往下走”,Workflow 里的 branch 默认只管控制,数据怎么给要你自己说清楚。
6. Branch、Static Value、Stream,决定它是不是工程级编排
如果 Workflow 只有字段映射,它还只是“更细粒度的图”。
真正让它进入工程态的,是它没有脱离 Eino 的统一运行时(runtime)。
6.1 SetStaticValue 解决的是配置注入,不是拿 state 顶锅
还是拿竞拍场景举例。
假设 b1 和 b2 都要吃 Price 和 Budget,
其中 Price 来自流程输入,Budget 是节点自己的静态配置。
这时比起把预算塞进 state,更直接的做法是:
type bidInput struct {
Price float64 // 当前价格:来自流程输入
Budget float64 // 当前节点自己的预算:通过静态配置注入
}
// b1 节点:执行 bidder 逻辑
wf.AddLambdaNode("b1", compose.InvokableLambda(bidder)).
// 把流程入口 START 的值映射到 bidInput.Price
AddInput(compose.START, compose.ToField("Price")).
// 给 bidInput.Budget 直接注入一个固定值 3.0
// 说明这个值不是上游传来的,而是当前节点自己的配置
SetStaticValue([]string{"Budget"}, 3.0)
// b2 节点:同样执行 bidder 逻辑
wf.AddLambdaNode("b2", compose.InvokableLambda(bidder)).
// 控制依赖:b2 要等 b1 执行完之后才会运行
AddDependency("b1").
AddInputWithOptions(
compose.START,
// 仍然从流程入口 START 取值,并映射到 bidInput.Price
[]*compose.FieldMapping{compose.ToField("Price")},
// 不把 START -> b2 视为直接控制依赖
// 这里只是补一条“数据来源”,不是说 b2 由 START 直接触发
compose.WithNoDirectDependency(),
).
// 给 b2 单独注入自己的预算 4.0
// 也就是说:b1 和 b2 吃的是同一个 Price,但 Budget 各不相同
SetStaticValue([]string{"Budget"}, 4.0)
SetStaticValue 的价值很朴素:
- 这是节点输入的一部分
- 但它不来自任何前驱节点
- 所以不该为了塞一个常量,把
state搞成杂物间
静态值是输入装配问题,不是状态管理问题。
6.2 Workflow 不是只能跑单次调用,它仍然是完整的 Eino runtime
Workflow 的另一个容易被低估的点,是它没有脱离 Runnable。
也就是说,Compile 之后你拿到的仍然是统一的运行体:
- 可以
Invoke - 可以
Transform - 也能进入更大的编排图
看一个流式例子。
这里输入不再是单条消息,而是一条 *schema.Message 流:
type counter struct {
FullStr string // 当前收到的正文片段
SubStr string // 要统计的目标子串,比如 "o"
}
wordCounter := func(ctx context.Context, in *schema.StreamReader[counter]) (
*schema.StreamReader[int], error,
) {
var subStr, cached string
// subStr: 已经拿到的目标子串
// cached: 当目标子串还没到时,先暂存正文内容
// 一个回调函数
return schema.StreamReaderWithConvert(in, func(chunk counter) (int, error) {
// 如果当前 chunk 带来了 SubStr,说明现在才拿到“统计目标”
if chunk.SubStr != "" {
subStr = chunk.SubStr
// 把之前缓存的正文和当前正文拼起来一起统计
full := cached + chunk.FullStr
cached = ""
return strings.Count(full, subStr), nil
}
// 如果 SubStr 还没到,就先缓存正文,暂时不能产出结果
if subStr == "" {
cached += chunk.FullStr
return 0, schema.ErrNoValue
}
// 如果已经拿到 SubStr,后续正文片段就可以直接统计
return strings.Count(chunk.FullStr, subStr), nil
}), nil
}
然后 Workflow 这边这么接:
wf := compose.NewWorkflow[*schema.Message, map[string]int]()
// 创建一个 Workflow:
// 输入是 *schema.Message 的流
// 输出是 map[string]int,最后把多个节点的统计结果汇总成一个 map
wf.AddLambdaNode("c1", compose.TransformableLambda(wordCounter)).
// c1 节点处理 Message.Content
// 把输入消息里的 Content 字段映射到 counter.FullStr
AddInput(compose.START, compose.MapFields("Content", "FullStr")).
// 给 counter.SubStr 注入静态值 "o"
// 表示 c1 专门统计 Content 中 "o" 出现的次数
SetStaticValue([]string{"SubStr"}, "o")
wf.AddLambdaNode("c2", compose.TransformableLambda(wordCounter)).
// c2 节点处理 Message.ReasoningContent
// 把输入消息里的 ReasoningContent 映射到 counter.FullStr
AddInput(compose.START, compose.MapFields("ReasoningContent", "FullStr")).
// 同样统计 "o" 的出现次数
SetStaticValue([]string{"SubStr"}, "o")
wf.End().
// 把 c1 的输出放到结果 map 的 content_count 字段
AddInput("c1", compose.ToField("content_count")).
// 把 c2 的输出放到结果 map 的 reasoning_content_count 字段
AddInput("c2", compose.ToField("reasoning_content_count"))
runner, err := wf.Compile(context.Background())
if err != nil {
panic(err)
}
// 编译 Workflow,得到可运行的 runner
result, err := runner.Transform(
context.Background(),
schema.StreamReaderFromArray([]*schema.Message{
// 第一段消息只有 ReasoningContent
{ReasoningContent: "I need to say something meaningful"},
// 第二段消息只有 Content
{Content: "Hello world!"},
}),
)
// 以流式方式执行:
// c1 统计 Content 里 "o" 的数量
// c2 统计 ReasoningContent 里 "o" 的数量
if err != nil {
panic(err)
}
这个例子至少说明了三件事:
- 字段映射到了流式场景,不需要换另一套写法
- 静态值在流式场景仍然成立
- 但静态值不保证是你收到的第一个 chunk,所以节点实现不能想当然
这就是为什么上面的 wordCounter 要先缓存字符串。
很多人第一次写 Workflow 流式逻辑,最容易犯的错就是默认“静态值先到、正文后到”。
真实运行时没有这个保证。
6.3 这些运行边界,最好在动手前就知道
Workflow 很灵活,但边界也写得很明确:
- 不支持环,所以你别拿它去硬凑 ReAct 那种
chatmodel -> tools -> chatmodel的回路 NodeTriggerMode固定为AllPredecessor- 因为没有环,
WithMaxRunSteps这类控制也没有意义 WithNodeTriggerMode不支持自定义
这几条限制不是缺点。
它们反而是在告诉你:
Workflow 适合复杂但可静态展开的编排,不适合靠回路驱动的 agent 结构。
7. Workflow 中,需要注意的五点
7.1 只把它当“字段映射器”
如果你只记住了 MapFields 和 ToField,
很容易把 Workflow 用成一个“更好使的字段搬运工具”。
但它真正的价值不只在字段映射,
还在于控制流和数据流拆开以后,图的表达会清楚很多。
7.2 明明 Chain / Graph 已经够用,还是一上来就上 Workflow
不是所有流程都值得用 Workflow。
如果你的主路径高度线性,节点间输入输出本来就对齐,
那 Chain 或普通 Graph 更省脑子。
工具不该为了“高级”而用。
该用的时候用,不该用时别硬上。
7.3 把 AddDependency 和 WithNoDirectDependency 混着写,却没想清控制路径
这是最容易把图写乱的地方。
AddDependency只建控制关系WithNoDirectDependency只是在已有控制路径上补一条纯数据依赖
如果你自己都说不清某个节点到底是谁控制执行、谁提供数据,
那十有八九这条图还没想明白。
7.4 多路 merge 往同一字段写
Workflow 支持多路汇聚,不等于支持无脑覆盖。
多个映射往同一个字段写,或者一边整体映射一边字段映射,
都属于冲突。
这类问题最好在设计阶段就避免,
不要等 Compile 报错再回头找。
7.5 流式场景默认认为静态值一定先到
这个坑很隐蔽。
很多人本地 demo 跑通后,会下意识把流式输入理解成“配置先来,正文后到”。
但 Workflow 不承诺这个顺序。
所以一旦你的节点既要吃流,又要吃静态值,
最好自己考虑缓存、拼接和 ErrNoValue 这类处理逻辑。
8. 总结
Workflow 解决的是“数据怎么精确喂到字段里”,Graph 解决的是“图怎么更通用地跑起来”;前者更细,后者边界更大。却又因为 Workflow 是无环 DAG,所以它不适合直接承载 ReAct 这种靠回路推进的主流程。
DAG :Directed Acyclic Graph
(有向无环图)
参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)