告别无效Agent工程!掌握这3大核心,让你的AI助手效率飙升10倍!
最近 X 上有篇文章很火,叫《How To Be A World-Class Agentic Engineer》,作者是个深度的 Agent 工程实践者。
文章开头是这样描述的:你用着 Claude Code,每天琢磨自己是不是把它的能力榨干了。偶尔看到它干出极其弱智的事情,又实在不理解,为什么别人好像都在用 Agent 造火箭,自己却连垒两块砖都费劲。
读完之后,我觉得作者说到点子上了一件事:大多数人用 Agent 效果差,不是因为工具不够,而是因为方向搞错了。
他的核心判断是:不需要追第三方框架,官方 CLI 就够。因为真正有价值的功能,最终一定会被整合进官方产品——早期社区发现的 Skills、Memory、子智能体方案,现在全是官方标配了。DeepSeek 的推理模式也一样。如果某个东西真的解决了真实问题,大厂不可能让它一直停在第三方。
这个判断我完全认同。 焦虑地追新框架、装新插件,本质上是在追一个会被原生吸收的东西,而且在它被吸收之前,你还要额外承担学习成本和上下文污染的代价。
但我想在他的基础上再补充一点:模型能力本身,才是最大的决定性因素。 用更好的模型,远远胜过在差的模型上堆再好的提示词和配置。同样一个指令,扔给不同能力的模型,结果差距大到不像同一个工具。
所以两件事可以同时成立:不折腾框架,但要用好的模型。
那精力应该放在哪里?放在真正影响 Agent 质量的底层逻辑上。我在之前一篇文章里写过"细颗粒度"的思路——在每一个颗粒度上用你自己的判断收敛 AI 的不确定性。这篇是那个逻辑在 Agent 工程里的延伸和系统化。
在 Agent 工程里,所有真正有效的手段,本质上都是同一件事——用你的确定性,去收敛 Agent 的概率。
这个"收敛",有三个层次可以做,再加上一个贯穿全局的保障机制。
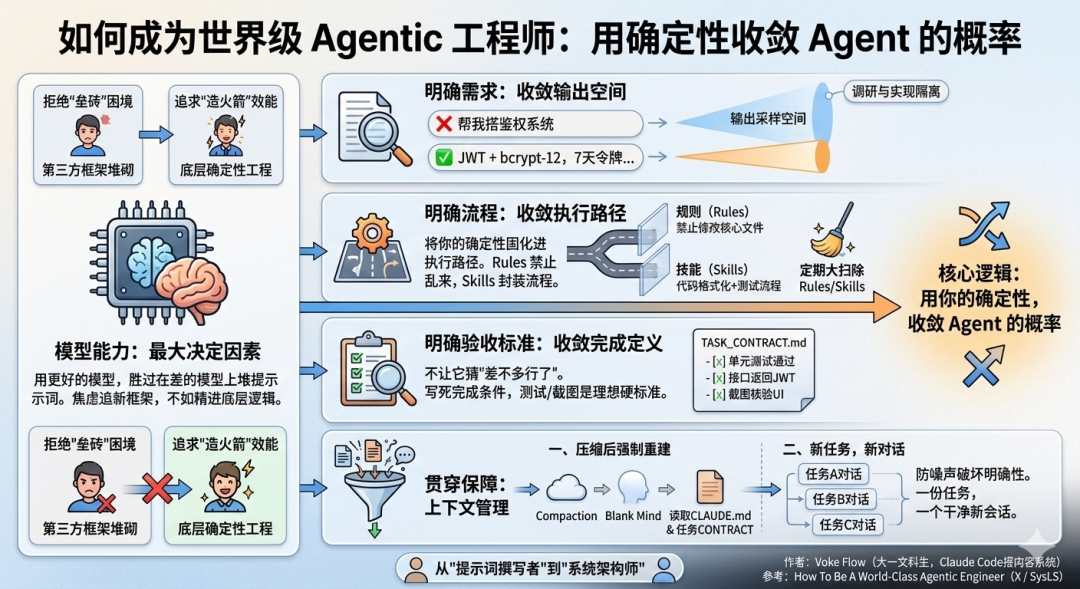
第一层:明确需求,收敛输出空间
Agent 的输出本质上是概率采样。你的需求越模糊,它的采样空间就越大,结果越随机;你的需求越精准,采样空间越窄,结果越可预测。
所以精准描述需求,是在用你已有的确定性知识压缩 Agent 的输出空间。
对比两个写法:
❌ 模糊:“帮我搭一个用户鉴权系统”
✅ 精准:“用 JWT + bcrypt-12 实现用户鉴权,刷新令牌有效期 7 天,token 存储在 httpOnly cookie 里,不需要考虑第三方 OAuth”
第二种写法,Agent 不需要去"研究"还有哪些方案,它的全部上下文用于实现你已经选定的这一种。不只是节省 token,更重要的是:你把自己的经验和判断注入了起点,从一开始就截断了它自由发挥的余地。
但有一个现实:你不可能总是知道要选哪个方案。这时候怎么办?
答案是不要在同一个对话里又调研又实现。先开一个 Agent 帮你把方案选项列清楚,你拍板定了之后,再开一个全新的干净 Agent 去实现。调研和实现的上下文完全隔离,互不污染。把需求确定这个动作,从开发过程里剥离出来,单独处理。
第二层:明确流程,收敛执行路径
需求明确了,还有另一层不确定性:Agent 会用什么方式去执行。
你不知道它会不会直接改掉你不想动的文件,会不会跳过你觉得重要的步骤,会不会用一个你完全没预期的方式"解决"了问题。
Rules(规则)和 Skills(技能),是把你的确定性固化进执行路径的手段。
Rules 是你和 Agent 磨合的产物。每次你看到它做了你不认可的操作,就把"禁止这么做"写成一条规则。比如:
- “修改文件前必须先读取文件”
- “禁止在没有用户确认的情况下删除任何文件”
- “测试失败时,必须先读取 coding-test-failing-rules.md,再继续”
Skills 是你把常用工作流程固化下来的地方。如果你每次写完代码都要走一套固定流程——跑格式化、跑测试、生成 commit message——就把这套流程封装成一个 Skill 文件,让 Agent 在对应场景下自动走这条路,而不是每次重新决策。
CLAUDE.md 的最佳形态,是一张极简的导航地图,而不是说明书。 只写 IF-ELSE:遇到什么情况,去读哪个文件。细节全下沉到对应的 Rule 或 Skill 里。CLAUDE.md 越精简,Agent 读它浪费的上下文就越少。
当然,Rules 和 Skills 积累多了之后,它们自己也会开始打架,出现矛盾,Agent 重新变得迟钝。这时候要做的是定期让 Agent 做一次"大扫除"——过一遍所有的规则和技能,合并重复,删掉废话,消除矛盾。做完之后,那种"手感回来了"的感觉非常明显。
第三层:明确验收标准,收敛完成定义
这一层是最容易被忽视的,也是我踩坑最多的地方。
Agent 知道怎么开始一个任务,但不太知道什么叫"做完了"。如果你不明确定义,它可能给你写几个空函数,然后告诉你"完成了"。或者它自己认为逻辑通了,但从来没跑过测试。
解法:写一个 TASK_CONTRACT.md。
在这个文件里列出本次任务所有必须满足的完成条件,然后在 CLAUDE.md 里写死:除非 CONTRACT 里的所有条目全部满足,否则禁止结束任务,必须继续迭代。
一个例子:`## 任务完成标准
- 所有单元测试通过(禁止修改测试文件)
- /api/auth/login 接口返回正确的 JWT token
- 刷新令牌过期后能正确触发登出
- 截图验证登录页面 UI 符合设计稿`
测试是最理想的验收标准,因为它是确定性的——要么通过,要么没通过,没有灰色地带。截图验证也已经可用,可以让 Agent 自己截图、自己核验 UI 是否符合预期。
这一层的本质,和前两层一样:把你对"完成"的确定性定义,从你的脑子里搬出来,变成 Agent 能直接执行的硬性标准。 不让它自己猜,不让它自己判断"差不多行了"。
贯穿三层的保障机制:上下文管理
以上三层都有一个共同的敌人:噪声信息。
噪声会污染你精心构建的每一层确定性。你的需求还在,但 Agent 的上下文里多了一堆无关的信息,它开始混淆;你的 Rules 还在,但它在处理完七个不同任务之后已经"忘了"最重要的那条;你的验收标准还在,但它在上下文压缩之后重新理解了一遍,理解歪了。
上下文管理的核心目的,不是"节省 token",是防止噪声破坏你已经建立的明确性。
有两个最重要的实践:
一、上下文压缩后强制重建。 Claude Code 在对话进行一段时间后会触发上下文压缩(Compaction)。压缩发生后,Agent 对你的项目的认知会出现空白,它开始靠概率填补——猜文件结构,猜技术选型,猜你的偏好。解法是在 CLAUDE.md 里写一条硬性规则:每次读取 CLAUDE.md 之后,必须重新读取项目核心文件和当前任务的 CONTRACT。强制重建,不给它猜的机会。
二、新任务,新对话。 把多个任务堆进同一个超长会话,等于把不同任务的上下文全混在一起。Agent 处理后面任务的时候,脑子里还残留着前面任务的细节。更好的方式是:一份任务,对应一个干净的新会话,带着当前任务必需的最少上下文去工作。
这就是"编排层(Orchestration Layer)"的思路:由一个调度机制负责创建 CONTRACT、启动新会话、传入必要上下文,让每个 Agent 只专注于眼前的那一件事。
还有一个真实的坑:Agent 天生想讨好你
把这个放在最后,因为它稍微独立于"确定性收敛"这个框架,但同样重要。
Agent 是被训练成取悦用户的。这意味着如果你问它"这里有没有问题",它很可能会找出一个问题——哪怕是脑补出来的,因为它知道你在期待一个正面回答。
解法一:中立提问。 不要用带有预设方向的问题。把"找一下这里的 Bug"改成"把这段代码的逻辑过一遍,把你的所有发现汇报给我"。不引导方向,让它自己汇报。
解法二:多 Agent 对抗验证。 这是多智能体系统里的经典三智能体结构:一个 Agent 生成结果,一个 Agent 专门批判和证伪,一个 Agent 裁定最终判断。三者之间天然博弈,反而逼近了客观真相。这套结构的精妙之处恰好是利用了 Agent"想取悦对方"的本性——让两边互相对抗,而不是都在取悦同一个人。
总结
回到最开始的那句话:所有真正有效的 Agent 工程手段,本质上都是用你的确定性,去收敛 Agent 的概率。
- 明确需求:用你的经验和判断,压缩它的输出空间
- 明确流程:用 Rules 和 Skills,固化你认可的执行路径
- 明确验收标准:用 CONTRACT,定义什么叫真正做完
- 上下文管理:保护这三层明确性不被噪声污染
这个逻辑和我上篇写的"细颗粒度"是同一条线——把每一个环节拆细,在每一个颗粒度上注入你的判断。不同的是,上篇在说人和 AI 的协作,这篇在说 Agent 工程的系统设计。
最终,你对 Agent 的贡献越来越不是"写提示词",而是做一个架构师——设计它的信息获取方式,定义它的任务边界,建立它的评估标准。
把你的确定性编码进系统,然后让 Agent 全速跑。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)