Agent Harness 概念详解
Agent Harness 概念详解
原创 杜睿 · 安如衫 · 2026年3月25日 22:51 · 上海
导读: 大模型上下文哪怕加到 1M,面对复杂长线任务时依然会遗忘和失焦。光靠死磕「提示词」,已经调教不出落地 Agent。要想让大模型 7x24 小时干活不崩溃、不烂尾,我们必须转向「上下文工程」,并为 AI 穿上一套外骨骼——Agent Harness。
- 突破上下文窗口限制有哪 3 种最佳实践?
- 为什么你的 AI 总是眼高手低、自吹自擂?
- 随着模型自身能力的进化,这套 Harness 又该何去何从?
读完本文,你会有新的答案。
01 从 Prompt Engineering 到 Context Engineering
LLM 是非幂等无状态函数,输入提示词,输出下一个 token 概率分布。为减少输入噪声,提示词工程的最佳实践可能是:
System Prompts 应清晰、简单、直接,既不要过度(写硬编码复杂的脆弱 if-else 逻辑,试图精确控制 Agent 行为),也不要提供模糊的形而上学,推荐组织成清晰的 sections(例如 <background_information>、<instructions>、## Tool guidance、## Output description 等),并使用 XML tagging 或 Markdown headers 来分隔这些 sections。最小化不等于最短,先用当前可用的 SOTA 模型测试一个 minimal prompt,看它在你的任务上表现如何,然后根据测试中发现的失败模式添加清晰的指令和示例。
Tools 应该自包含、对错误鲁棒、对其预期用途清晰,输入参数应该具有描述性。工具集切记过于臃肿,覆盖太多功能,或对场景使用哪些工具的带来了模糊和误解,应策划最小可行工具集,遵循 MECE 原则。如果人都无法明确于何场景使用何工具,将心比心,那么就更别指望 Agent 能弄懂。Agent 需能自主循环调用工具,即用什么工具,按何顺序调用工具。
Few-shot prompting,一组多样化、典型的示例,有效描绘 Agent 的预期行为,比冗长的文字描述更有效。
Context = Prompt + Memory
而上下文工程的核心问题是:如何优化进 Context Window 的 token 效用,同时受到 LLM 模型约束,以达到预期结果。
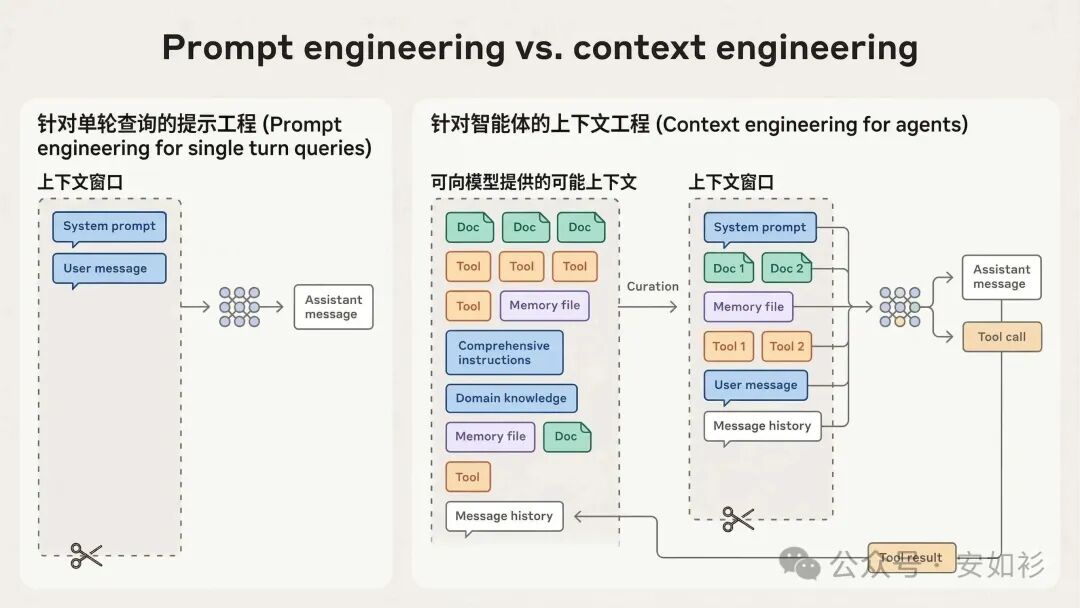
为什么 Context Engineering 重要?
尽管 SOTA LLM 上下文长度已扩展到 1M,但研究者曾使用 Needle-in-a-haystack 测试发现它们和碳基生物一样,在某个临界点之后会失焦或困惑。
Context Rot/上下文溃烂:随着上下文窗口中词元数量增加,大语言模型准确从中召回(回忆)信息的能力随之下降。
这是因为 Transformer 架构的 LLM,每个 token 需要 attend 到所有其他 token,导致了 O(n²) 级复杂度;随着上下文长度增加,模型捕捉这些配对关系的能力被稀释。此外,在训练数据分布上,短序列比长序列更常见。这意味着模型对长上下文处理经验相对不足。虽然 Position Encoding Interpolation 等技术让模型能够处理更长序列,但代价是对 token 位置理解的精度有所下降。

因此,Context 必须被视作有限资源,具有边际收益递减的特性。每次决定向模型传递什么时,都需要一次策划过程,Context Engineering 就是管理这一切的策略集合。当转向构建 Agent,在长工具调用链中运行、更长时间跨度内工作时,我们需要管理整个上下文状态,系统指令、Tools、MCP、Skills、历史消息、Memory 等等。
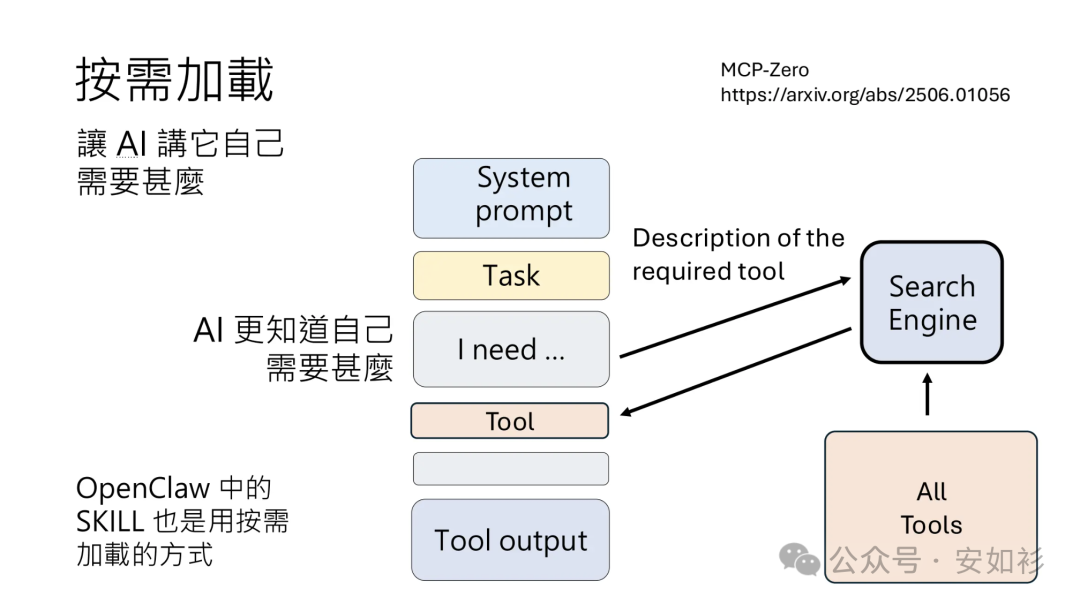
Agentic RAG 融入 Just In Time 法,在运行时使用 Tools 方式动态加载数据。例如,Claude Code 就使用这种方法对大型数据库执行复杂数据分析,可以编写查询命令、存储结果,并使用 head 和 tail 等 Bash Exec 分析数据,而不是将完整数据加载到上下文中。就好像我们人类,也是通过建立外部组织和索引系统(如访达、收件箱、书签)来按需检索相关信息。
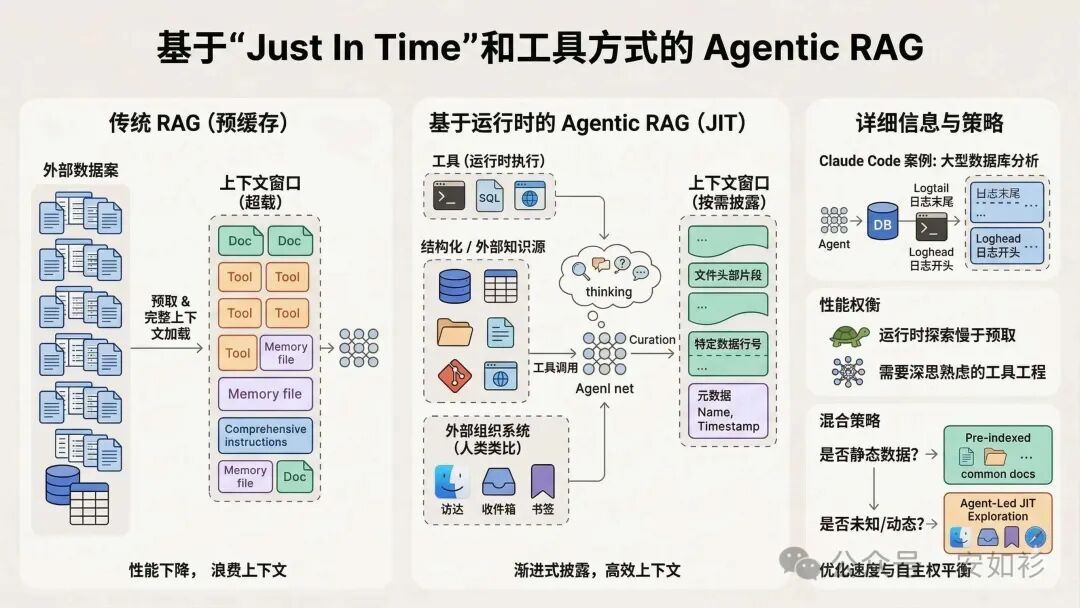
让 Agents 自主导航和检索数据也实现了渐进式披露,允许 Agents 通过探索逐步发现相关上下文。例如,文件大小暗示复杂度,命名规范暗示用途,时间戳可能有相关性暗示。
当然,Agentic RAG 可能比传统 RAG 取数据慢,而且需要上下文工程确保 LLM 有正确 Tools 有效导航信息环境。如果没有指导,Agent 可能浪费上下文(滥用 Tools、钻牛角尖或未能识别关键信息)。
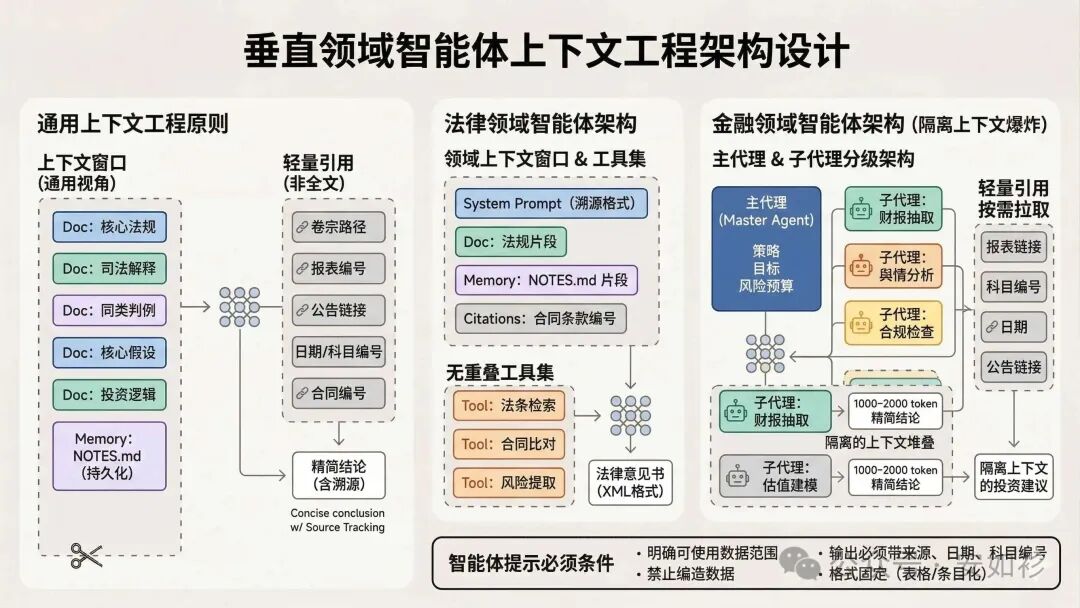
在某些场景下可能采用混合 RAG 策略:预先加载以提高速度(包括 CLAUDE.md),同时保留按需即时检索以保证精确。在动态内容较少的领域(如法律或金融工作),相对更适合 Hybrid 混合检索 + 强结构化上下文。
02 24/7 Long-horizon Tasks
长时任务(例如数小时或 24/7 不间断运行)要求智能体在跨越几百个会话的操作连贯性。在大型代码库迁移或科研项目场景下,输入输出词元数必然会超过 LLM 的上下文窗口限制,这就需要专门技术来驾驭 LLM,克服上下文窗口大小限制。
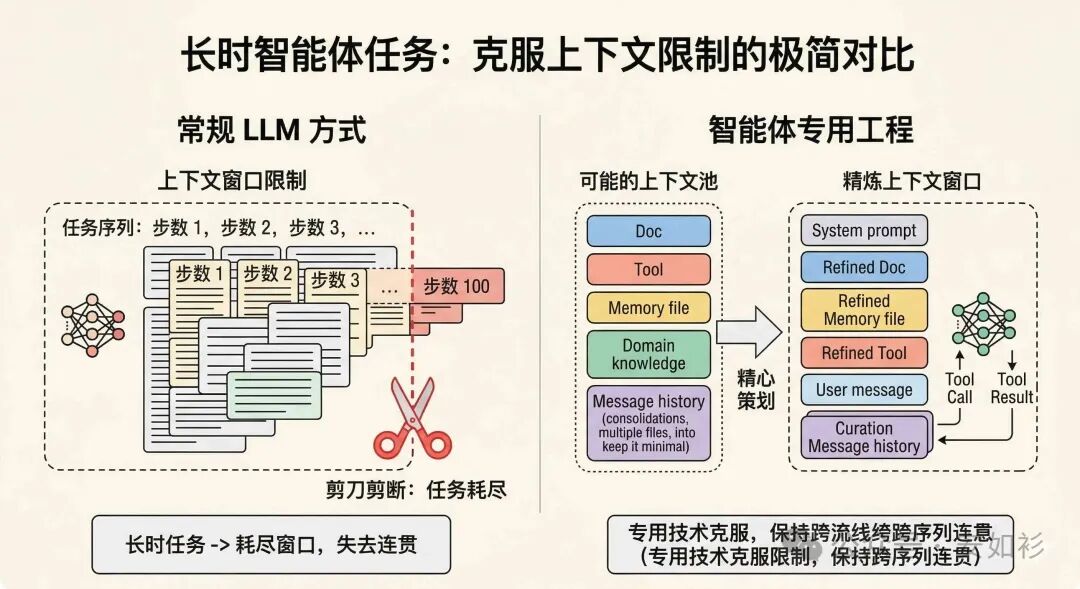
虽然模型的上下文窗口一定会扩展,但这不能解决「上下文污染」和「信息相关性」问题。为了使 Agents 有效地跨延长的时间跨度工作,有以下几种基础技术。
| 技术 | 场景 |
|---|---|
| Compaction | 需要大量对话来回的连续性任务 |
| Structured Note-taking | 有清晰里程碑的迭代开发 |
| Sub-agent Architectures | 需要并行探索的复杂研究和分析 |
第一个技术是压缩,即在接近上下文窗口限制的对话进行总结,用总结内容开启新会话。压缩的关键在于选择保留什么和丢弃什么。
对于压缩模块,工程师应在 traces 上反复调优提示词:首先最大化召回,确保你压缩提示词从 trace 中捕获每一个相关信息,迭代提高精度,消除多余内容。
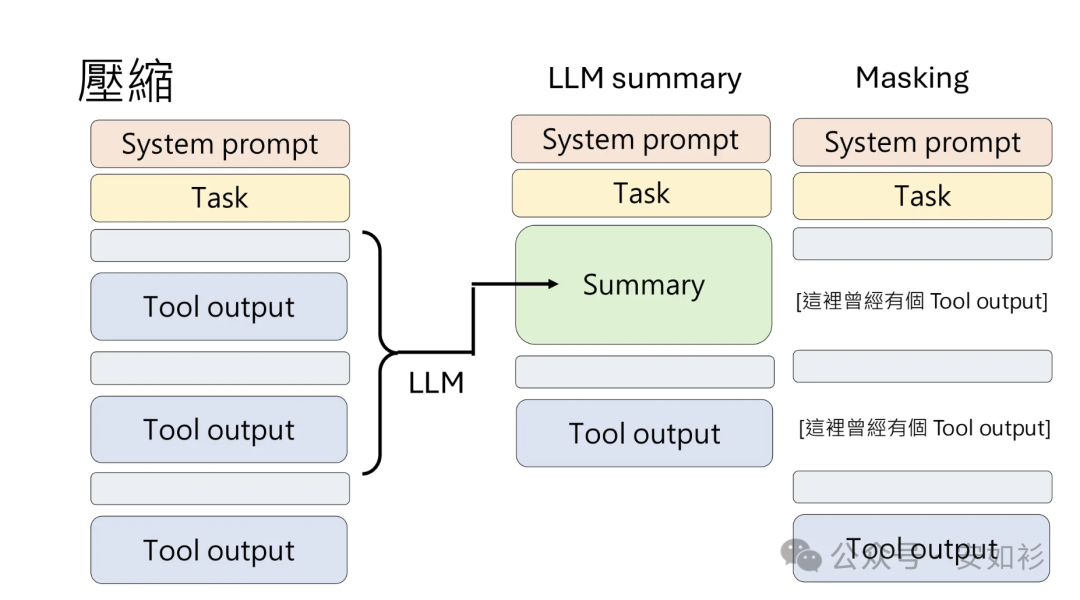
惯常实践是保留未解决的 bugs,丢弃冗余的 tool results。符合直觉的思考时,为什么智能体需要再次看到原始结果,需要自己查日志不就好了?
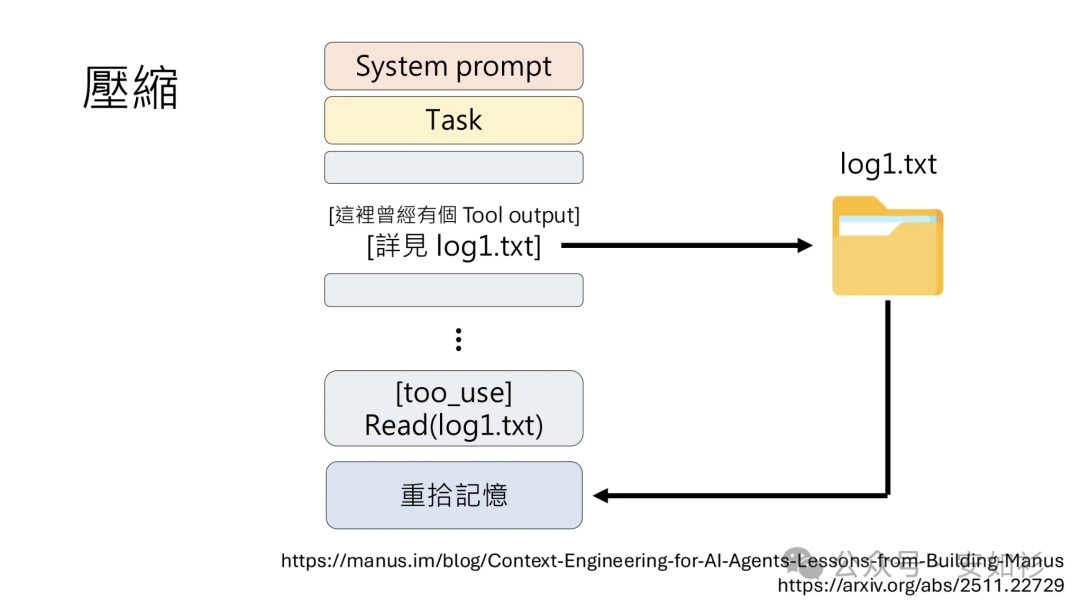
第二个技术是结构化笔记,即 Agentic Memory。好记性不如烂笔头,Agent 定期将笔记写入持久化内存(在上下文窗口外的上下文)的技术,并自主查看修改(需防范遍历攻击)。这种跨压缩步骤的连贯性使得长期策略成为可能,这是单独依靠上下文窗口维护所有信息时不可能做到的。
第三个技术是子代理。与其让一个 Agent 试图管理整个项目维护状态,不如让专门的 sub-agents 处理聚焦的任务,每个 sub-agent 都有干净的 context window。主 Agent 协调高层计划,而 sub-agents 执行深度技术工作或使用 Tools 查找相关信息。
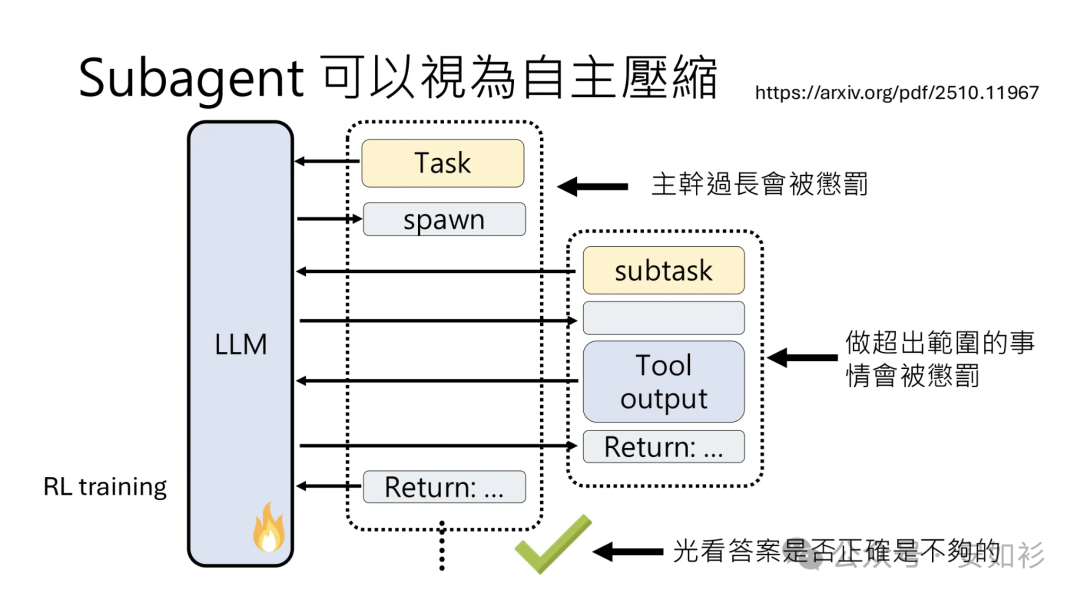
每个 sub-agent 可能探索数万甚至更多 token,但只返回浓缩摘要(通常 2000 字)。
03 Agent Harness
理论上,拥有一个可靠的 Agent Harness,Agent 就能够持续进行 Brownfield 领域任意长时间的有效工作。
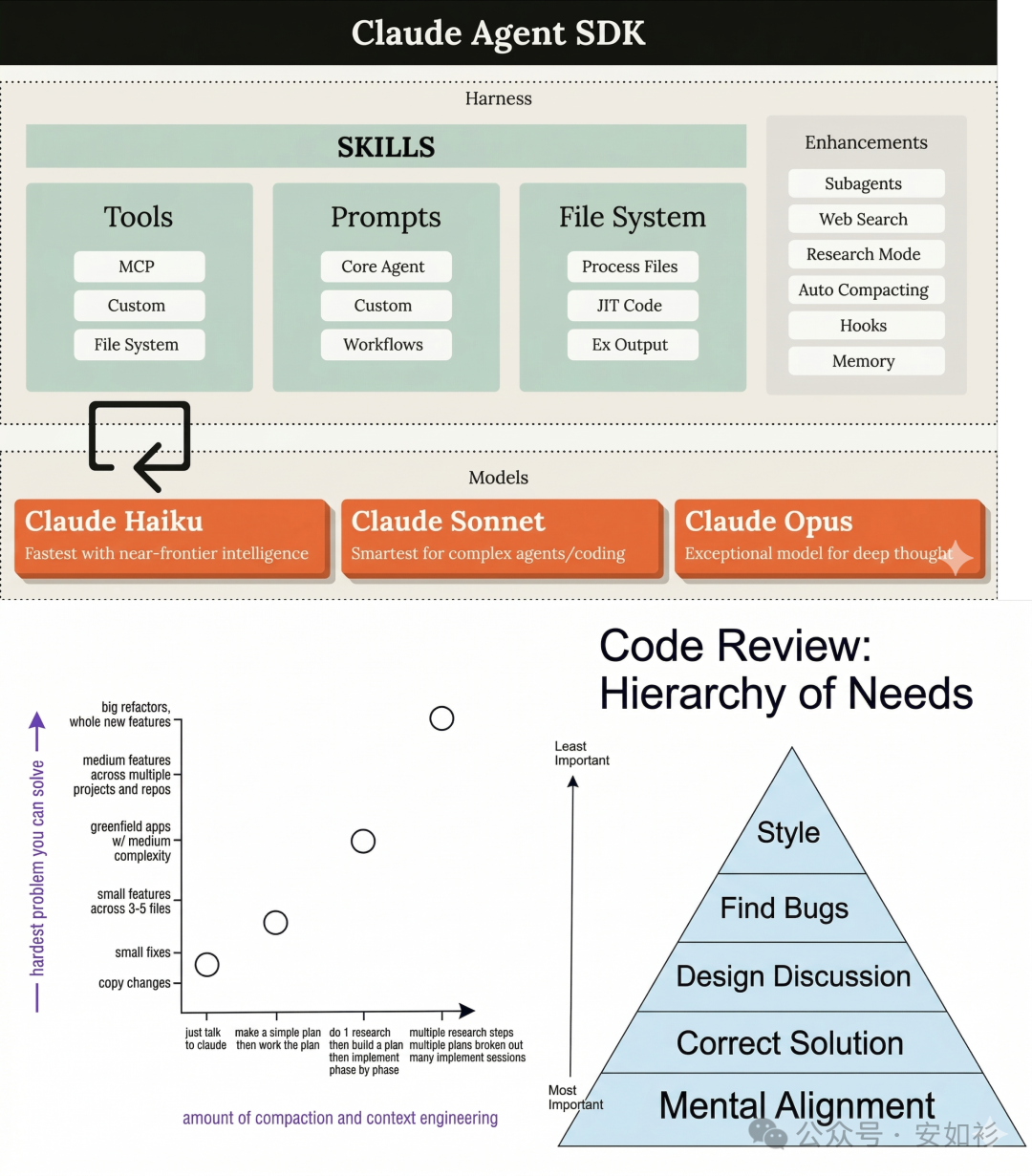
以 Claude Agent SDK 为例,这个 Agent Harness 具有压缩等上下文管理能力。然而,只靠「压缩」远远不足以自动化构建生产质量的 Web 应用。
失败模式一:一次性完成太多。模型倾向于 one-shot 整个应用,漫无目的,脚踩西瓜皮,最终耗尽上下文还留一个半实现、未记录的功能。然而,等到下个会话,Agent 处于失忆状态,又得猜测之前发生了什么,并花费大量时间让基本应用重新工作。这即使在有 compaction 的情况下也会发生,因为 compaction 并不总是完美地将指令传递给下一个 Agent。
失败模式二:过早宣布完成。在项目后期,一些功能已经构建之后,看到已经取得了进展,就草草收场,不会批评与自我批评。结果等到你亲自验收,发现并不达预期,Agent 才假模假样地意识到问题「You are absolutely right」。
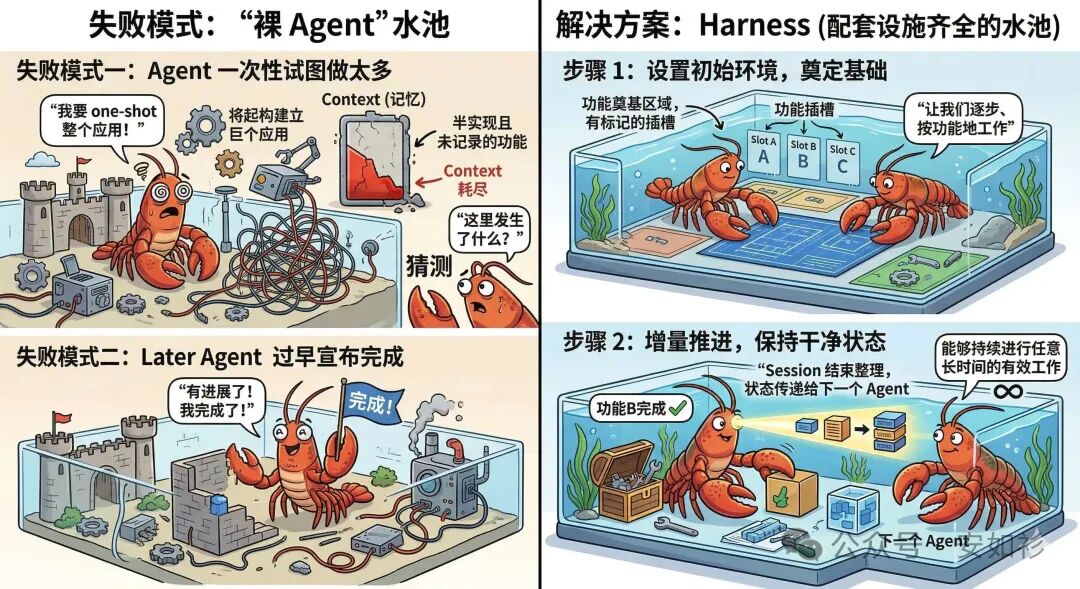
因此,我们需要:1. 一个初始环境,为给定任务/目标所需所有功能奠定基础,并让 Agent 能逐步工作;2. 提示每个 Agent 增量地向其目标推进,不达目标誓不罢休(Ralph Wiggum Loop)。
因此,一个朴素的 Agent Harness 有两个 Agent:Initializer 和 Coder。
Initializer 负责初始化:
init.sh:用于启动开发服务器progress.txt:记录 Agents 的 TO-DO Listgit:用版本控制工具管理文件夹
在开始新的会话时,Agent 就可以快速上手,理解项目进度,这通过 progress.txt 和 git history 实现。
此外,Initializer 应编写一份全面的需求说明书,并设置一个结构化 JSON 文件,包含端到端功能描述列表,每个功能最初标记为「失败/未实现」,以便接手的 Coder Agent 清楚了解完整功能点,看清方向。
Coder SOP:
pwd查看工作目录- git logs 和 progress files 了解最近的工作
readfeatures list file,选择未完成的最高优先级功能./init.sh启动开发服务器,然后运行基本端到端测试以确保基本功能仍然工作- 开始处理新功能
- 先使用单元测试或 curl 命令对开发服务器进行测试,然后使用浏览器自动化工具进行 UI 测试,识别、修复仅从代码中检查不到的明显的 bugs。
在实验中发现,使用 JSON 格式效果最好,因为与 Markdown 文件相比,模型不太可能不当更改或覆盖 JSON 文件。
{
"category": "functional",
"description": "New chat button creates a fresh conversation",
"steps": [
"Navigate to main interface",
"Click the 'New Chat' button",
"Verify a new conversation is created",
"Check that chat area shows welcome state",
"Verify conversation appears in sidebar"
],
"passes": false
}
在这个朴素 Harness 设计中,每个会话 Coder Agent 一次只聚焦处理一个新功能,并且 commit 到 git,写 commit messages 提交到 git,并在 progress 文件中写入总结。
实践表明,增量法对于解决 Agent 试图同时做太多事的毛病缓解至关重要,而且允许模型使用 git 撤销更改,恢复工作状态。
04 GAN-Inspired Multi-Agents Harness
Opus 4.5 如何设计高质量前端网页?
Anthropic 研究员 Prithvi 创建了一个 Agent Team:
| 角色 | 职责 | 策略 | 约束与交付物 |
|---|---|---|---|
| Planner | 需求规划:将 1-4 句原始提示扩展为详尽的产品 Spec。 | 保持野心:专注产品 Context 与高层设计,避开过度详细的技术实现以防止错误级联。 | 交付物:功能规格说明书 (Spec)。要求:必须在 Spec 中寻找机会织入 AI 功能。 |
| Coder | 功能构建:负责按 Sprint 粒度将 Spec 转化为代码实现。 | 采用 One-feature-at-a-time 方法;每个 Sprint 结束前进行 Self-evaluate。 | 技术栈:React, Vite, FastAPI, PostgreSQL。要求:使用 Git 进行版本控制。 |
| Evaluator | 质量评估者:作为"守门员",对运行中的应用进行动态黑盒测试。 | 使用 Playwright 模拟用户点击 UI、校验 API 响应及数据库状态。 | 根据硬性阈值(视觉、代码、功能)评分,未达标则强制打回重修。 |
为什么需要 Evaluator?

在前一个朴素 Harness 中,当要求 Coder Agent 评估他们自己的交付物时,它们倾向于自吹自擂,尤其是主观型任务。

因此,需要一个客观、独立、第三方的挑剔的 Evaluator,一旦这个外部反馈 Agent 存在,Coder 就有具体反馈可以迭代,而不是沉浸在对自己的美好幻想。
拿前端设计为例,人类只需要定义高质量评分标准和权重策略:
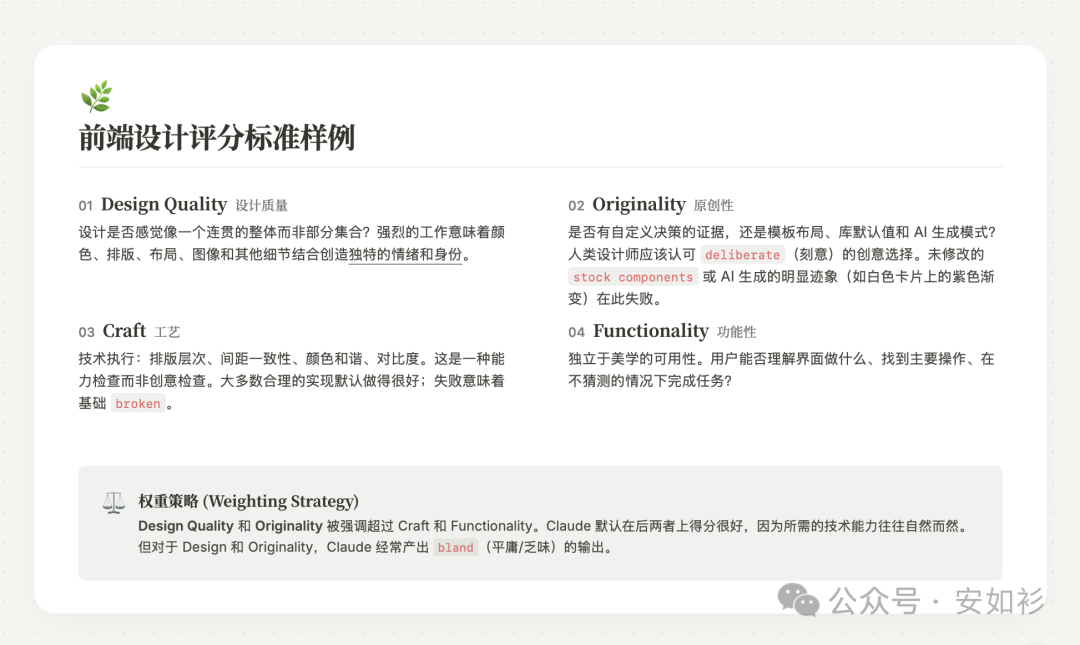
在 Prithvi 看来,比起功能性应该强调原创性,因为他非常不希望 Claude 生成的网页平庸、安全、毫无特色。这就是权重策略。你的发心。
除了给出评分标准外,还可以用 few-shot 提示词给出例子对应的评价分数 breakdown。这一步是在强化 mental alignment(使用 CC 时,审阅调研&计划也是对齐上下文),校准 Evaluator,确保 Agent 的判断与人类偏好一致,减少跨迭代的分数漂移。
Browser-Use
然后,Evaluator 应被赋予 browser-use 工具(例如 Playwright MCP),它可以复现错误、验证修复,推理 UI 的行为。
Playwright MCP 的核心能力包括:
- 页面导航:
navigate、open、tabs、focus、close - 页面内容:
snapshot(AI ref / aria 无障碍树)、screenshot、pdf、resize - 元素交互:
click、hover、type、fill、select、drag、press、scrollintoview、upload - 网络相关:
requests、responsebody - 页面状态:
console、errors、cookies、storage - 对话框与下载:
dialog、wait、waitfordownload、download - 浏览器配置:
profiles、create-profile、delete-profile、reset-profile、set - 调试:
evaluate、trace、highlight
这也就意味着 Evaluator 能自主进行 UI 测试,产生评估,并将反馈流向 Coder 作为下一次迭代的输入。如果分数趋势良好,优化当前方向;如果方法不 work,pivot 到不同的美学。
Prithvi 表示他 prompt 模型为荷兰艺术博物馆创建一个网站,直到第九次自动迭代,它都是产生了一个干净、深色主题的落地页,但在预期范围内,平平无奇:

结果是,在第十次自动迭代,Coder 完全放弃了方法,重新想象为空间体验:用 CSS perspective 渲染棋盘格地板的 3D 房间,艺术品以自由形式位置挂在墙上,用门口式导航在画廊房间之间切换(而非滚动或点击)。
这是 Prithvi 从未见过的创意飞跃。
Sprint Contract
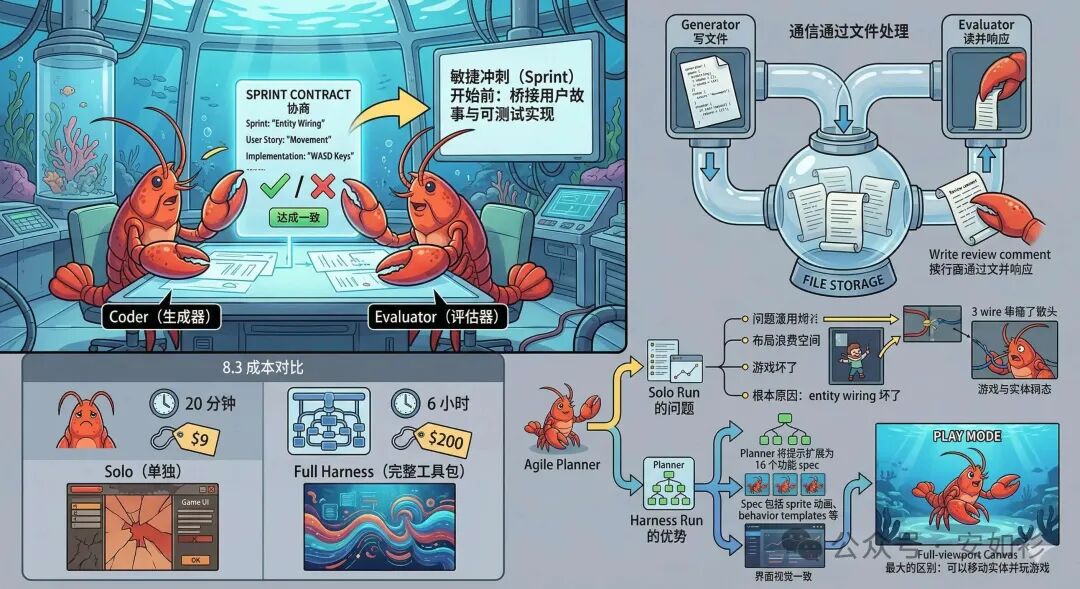
此外,还可以在 Harness 设计一个讨论协商机制。例如,每个 Sprint(敏捷开发中迭代冲刺一个开发的小阶段)之前,Coder 和 Evaluator 先协商 Sprint Contract:在写任何代码之前商定该工作块的样子。
因为产品 spec 是故意高层次的,需要一个步骤来桥接 user stories 和可测试实现。Coder 提议将要构建的内容以及如何验证成功,Evaluator 审查该提议以确保 Coder 正在构建正确的东西。两者迭代直到达成一致。还有一种方式是本地文件通信:一个 Agent 写文件,另一个 Agent 读取并响应。Coder 然后根据协商的 Contract 构建,然后再交给 Evaluator 做质量评估。这保持了工作忠实于 spec,而不过早过度指定实现。
| Harness 类型 | 持续时间 | 成本 | 效果 |
|---|---|---|---|
| 朴素单智能体 | 20 分钟 | $9 | 差 |
| Planner/Coder/Evaluator | 6 小时 | $200 | 中等 |
Evaluator 如何设计?
实际上,开箱即用的 Claude Code 是一个糟糕的 Evaluator,研究员表示早期测试中,Evaluator 明明观察到它识别合法问题,结果居然说服自己这不是什么大不了的事,它也倾向于表面测试,而非探测边界情况。

研究人员的调优循环是:
阅读 Evaluator 的日志 → 找到 Evaluator 判断与人类不符的例子 → 迭代更新 prompt 继续观测能否解决这些问题。
需要多轮调优循环才能让 Evaluator 以合理的方式评分。即使如此,harness 输出显示了模型 QA 能力的极限:小的布局问题、感觉不直观的地方,以及在更深层嵌套功能中未被发现的 bugs。但与朴素的单智能体相比,提升是明显的。
05 模型对 Harness 的影响?
上一个 harness 结果令人鼓舞,但笨重、慢且昂贵。
如无必要,勿增实体。
如何不降低性能,找到简化 harness 的方法呢?研究员 Prithvi 采用了一种朴素的剔除法(边际效应),即自动化一次移除一个组件/工具,测试对最终结果的影响。
实际上,Harness 中的每个组件映射了关于模型不能独立做什么的假设。这些假设值得压力测试,因为它们不仅可能不正确,而且会随着模型改进而迅速过时。
每当新模型发布,工程团队就有了进一步减少复杂性的动机。
例如,Opus 4.6 计划更仔细,在更长的 agentic 任务上持续更长时间,可以更可靠地处理更大的代码库,并有更好的代码审查和调试技能来捕捉自己的错误,并在长期上下文检索方面显著改进。
因此,研究员做了一个测试——移除了 Sprint Construct。Sprint 结构帮助将工作分解以便模型连贯地工作,但鉴于 Opus 4.6 的改进,有充分理由相信模型可以本地处理工作而无需这种分解。也由于模型原始能力增强,边界向外移动。对于仍处于模型能力边缘的部分,Evaluator 还在提供价值。但对于某些范围内的任务,Evaluator 反而成为不必要的开销。
随着模型不断改进,大致可以预期它们能够工作更长时间,处理更复杂的任务。
在某些情况下,这意味着围绕模型的 Harness 设计随着时间推移会逐渐变得不那么重要。说不定到下一个模型,某些问题就能自行解决,尤其是模型在特定 Harness 中训练时,尽管这可能引入过拟合问题。
另一方面,模型越好,就有越多空间开发能够实现超出模型基准能力的更复杂任务的 Harness。这意味着 Harness 空间不会随着模型改进而缩小,而在移动。
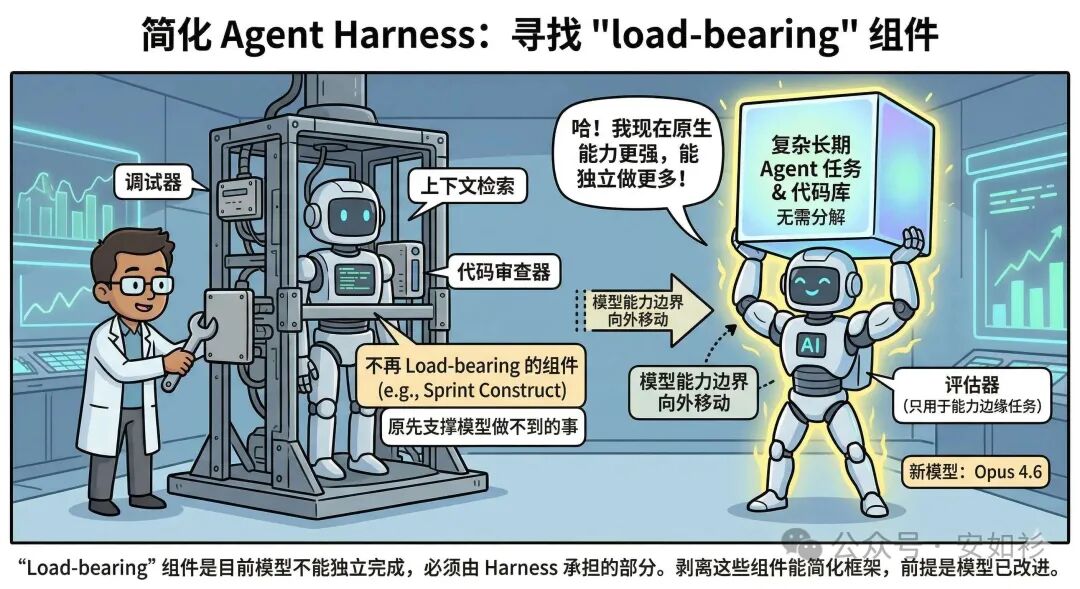
Agent 工程师需要不断寻找下一个新颖的 Harness 组合,这需要依靠:
- 实验:阅读其在现实问题上的 Logs、Metrics 和 Traces,并根据需要调优性能以达到预期结果。Harness 来自科学的实验迭代。
- 拆解:在处理更复杂的任务时,有时有空间通过分解任务并将专门的 agents 应用于问题的每个方面来获得提升。
- 变革:当新模型出现时,重新审视 Harness,剥离不再对性能 load-bearing(承重)组件,添加新组件以实现以前的不可能。
参考资料
- https://www.anthropic.com/engineering/harness-design-long-running-apps
- https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)