【Jetson + TensorRT 部署实战】YOLOv8 C++ 单图端到端推理
目录
1. 前言
本篇给大家带来 YOLOv8 在 Jetson 平台上的 C++ 部署完整教程。
很多同学跑通 Python 版 Ultralytics 就止步了,但真正工程化、量产、嵌入式落地必须用 C++。
C++ 部署优势:
- 无 Python 环境依赖
- 低延迟、低内存占用、稳定实时
- 适合车载 / 机器人 / 嵌入式平台
- 可编译成独立可执行文件
本篇从 0 到 1 带你实现:
ONNX → TensorRT 引擎 → C++ 预处理 → 推理 → 后处理 NMS → 画框显示类别置信度。
2. 部署环境
2.1 远程平台
远程硬件平台:
- Jetson Orin / Xavier / Nano
远程平台软件环境要求:
- TensorRT 8.x
- OpenCV 4.x
- C++
- CUDA
2.2 本地平台
- 远程开发Ultralytics工程用的是Pycharm。
- 远程开发C++项目用的是VS Code。
这两个开发IDE用着比较顺手,其他相关的也可以。
3. 模型转换:pt→onnx→engine
很多小伙伴一开始直接用 Ultralytics Python 导出的 engine 文件放到 C++ 里用,结果直接报错,这里必须讲清楚三个核心文件的区别,也是部署的核心逻辑:
- .pt 文件:PyTorch 原生模型,包含网络结构 + 权重,仅适用于 Python 环境
- .onnx 文件:通用模型交换格式,相当于 “黄金货币”,不绑定语言、框架、硬件,是跨平台部署的唯一中间件
- .engine 文件:TensorRT 针对当前硬件生成的执行计划,不是网络结构!包含算子融合、内存调度、GPU 计算策略,和硬件 + 运行环境强绑定,Python 导出的 engine 只能 Python 用,C++ 必须重新从 ONNX 生成!
3.1 PyTorch 模型导出 ONNX
首先在 Python 环境(Ultralytics)中导出 ONNX 模型,基于以前的开发习惯,Ultralytics有单独的虚拟环境。关于Ultralytics代码库导出.onnx模型的具体过程及原理,请参考:Ultralytics代码库深度解读【一】:onnx模型导出
第一步:激活虚拟环境:
source /home/jetson/venvs/ultralytics-env/bin/activate
第二步,导出.onnx文件:
yolo export model=yolov8n.pt format=onnx opset=12
命令行输出如下,表示导出成功。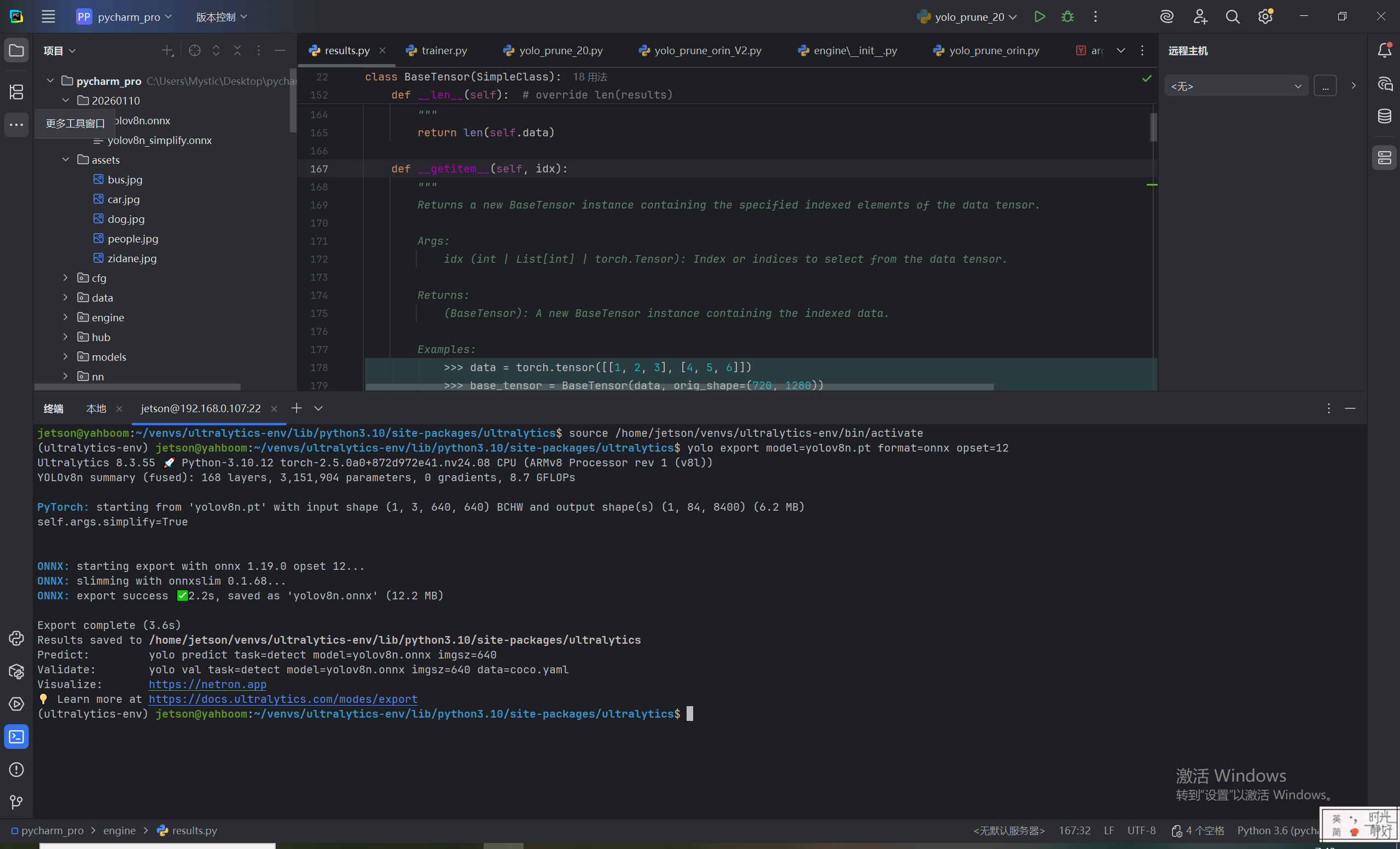
3.2 ONNX 转换 TensorRT 引擎
在部署目标设备(Jetson)上用trtexec执行转换,生成 C++ 专用引擎。
第一步:找到远程设备的trtexec位置:
sudo find /usr -name trtexec
输出如下:
第一个路径就是我们要用到的路径。
第二步:导出onnx引擎
在当前onnx路径下,执行:
/usr/src/tensorrt/bin/trtexec --onnx=yolov8n.onnx --saveEngine=yolov8n_new.engine --fp16
经过漫长的等待,会在当前路径下生成yolov8n_new.engine文件。
4.C++ 工程搭建
在远程jetson设备上任选一个文件位置创建如下的文件夹(把第三章生成的yolov8n_new.engine文件复制到本地即可):
yolov8_trt_inference/
├── CMakeLists.txt # CMake编译配置文件
├── src/
│ └── trt_infer.cpp # 核心推理代码
├── yolov8n_new.engine # 转换好的TensorRT引擎
├── coco.names # COCO数据集80类别名称
└── test.jpg # COCO128数据集测试图(000000000509.jpg)
4.1 COCO 类别名称文件创建
打开创建的 CMakeLists.txt文件,复制以下内容(目标检测框架的80个输出类别):
person
bicycle
car
motorcycle
airplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
handbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
couch
potted plant
bed
dining table
toilet
tv
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
book
clock
vase
scissors
teddy bear
hair drier
toothbrush
4.2 CMakeLists.txt 编译配置
打开创建的 coco.names文件,编写以下程序:
cmake_minimum_required(VERSION 3.10)
project(yolov8_trt_inference)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_BUILD_TYPE Release)
# 查找 OpenCV
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# 查找 CUDA
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
# 系统 TensorRT 路径
include_directories(/usr/include/aarch64-linux-gnu)
link_directories(/usr/lib/aarch64-linux-gnu)
# 编译可执行文件
add_executable(yolov8_trt_inference src/trt_infer.cpp)
target_link_libraries(yolov8_trt_inference
${OpenCV_LIBS}
${CUDA_LIBRARIES}
nvinfer
nvonnxparser
cudart
)
# 设置 rpath 指向系统库路径
set_target_properties(yolov8_trt_inference PROPERTIES
LINK_FLAGS "-Wl,-rpath=/usr/lib/aarch64-linux-gnu"
)
文件的主要内容如下:
- 🍊用 C++17 编译
- 🍊自动找 OpenCV、CUDA
- 🍊手动指定 TensorRT 头文件 / 库路径
- 🍊生成可执行文件 yolov8_trt_inference
- 🍊链接所有依赖库(opencv、cuda、tensorrt)
cmake_minimum_required(VERSION 3.10)
project(yolov8_trt_inference)
要求 CMake 版本至少 3.10,太低会报错。
给项目起名字:yolov8_trt_inference。
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_BUILD_TYPE Release)
编译的时候采用C++17标准。设置build类型为release。如果用过Visual Studio,就会很熟悉这种build类型,如果改成debug类型,比较方便调试,但是编译产生的文件会比较大,release模式会在编译器层面进行优化,适合发布的时候用(比如说用MFC框架开发的应用软件)。
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package:让 CMake 自动找到系统里的 OpenCV
include_directories:把 OpenCV 的头文件路径加到编译器里,后面会自动链接 OpenCV_LIBS。
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
自动找 CUDA(TensorRT 必须依赖 CUDA)
加入 CUDA 头文件路径,后面链接 CUDA_LIBRARIES 和 cudart。
include_directories(/usr/include/aarch64-linux-gnu)
link_directories(/usr/lib/aarch64-linux-gnu)
这是 ARM64 / Jetson 系统的 TensorRT 默认安装路径:
include:头文件(NvInfer.h 等)
lib:库文件(.so 动态库)
add_executable(yolov8_trt_inference src/trt_infer.cpp)
生成可执行文件,最终生成的可执行程序名字:yolov8_trt_inference。
target_link_libraries(yolov8_trt_inference
${OpenCV_LIBS} # OpenCV
${CUDA_LIBRARIES} # CUDA 基础库
nvinfer # TensorRT 核心库
nvonnxparser # TensorRT 解析 ONNX 模型
cudart # CUDA runtime
)
把代码和这些库绑定,运行时才能调用它们的功能。
set_target_properties(yolov8_trt_inference PROPERTIES
LINK_FLAGS "-Wl,-rpath=/usr/lib/aarch64-linux-gnu"
)
让程序运行时能自动找到 TensorRT 动态库。
5. C++ 核心推理代码
打开创建的 trt_infer.cpp文件,编写以下程序:
#include <iostream>
#include <vector>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <NvInfer.h>
#include <cuda_runtime_api.h>
using namespace std;
using namespace cv;
using namespace nvinfer1;
vector<Scalar> class_colors = {
Scalar(0, 255, 0), // person (绿色)
Scalar(255, 0, 0), // bicycle (蓝色)
Scalar(0, 0, 255), // car (红色)
Scalar(255, 255, 0), // motorcycle (青色)
Scalar(128, 0, 128), // airplane (紫色/洋红色)
Scalar(255, 0, 255), // bus(洋红色)
};
// 日志类
class Logger : public ILogger {
void log(Severity severity, const char* msg) noexcept override {
if (severity != Severity::kINFO) {
cout << "[TensorRT] " << msg << endl;
}
}
} gLogger;
// 检测结果结构体
struct Detection {
Rect box;
float conf;
int cls_id;
};
// 加载类别名称
vector<string> load_coco_names(const string& path) {
vector<string> names;
ifstream f(path);
string line;
while (getline(f, line)) {
names.push_back(line);
}
return names;
}
// 加载引擎
ICudaEngine* loadEngine(const string& engine_path) {
ifstream file(engine_path, ios::binary);
if (!file.good()) {
cerr << "引擎不存在!" << endl;
return nullptr;
}
file.seekg(0, ios::end);
size_t size = file.tellg();
file.seekg(0, ios::beg);
char* data = new char[size];
file.read(data, size);
file.close();
IRuntime* runtime = createInferRuntime(gLogger);
ICudaEngine* engine = runtime->deserializeCudaEngine(data, size);
delete[] data;
delete runtime;
return engine;
}
// 后处理
vector<Detection> postprocess(float* output, int img_w, int img_h) {
vector<Detection> dets;
for (int i = 0; i < 8400; i++) {
float x = output[0 * 8400 + i];
float y = output[1 * 8400 + i];
float w = output[2 * 8400 + i];
float h = output[3 * 8400 + i];
float max_conf = 0;
int cls_id = 0;
for (int j = 4; j < 84; j++) {
float conf = output[j * 8400 + i];
if (conf > max_conf) {
max_conf = conf;
cls_id = j - 4;
}
}
if (max_conf < 0.45) continue;
int left = (x - w * 0.5f) * img_w / 640;
int top = (y - h * 0.5f) * img_h / 640;
int width = w * img_w / 640;
int height = h * img_h / 640;
left = max(0, left);
top = max(0, top);
dets.push_back({Rect(left, top, width, height), max_conf, cls_id});
}
vector<Rect> boxes;
vector<float> scores;
for (auto& d : dets) {
boxes.push_back(d.box);
scores.push_back(d.conf);
}
vector<int> indices;
dnn::NMSBoxes(boxes, scores, 0.45f, 0.4f, indices);
vector<Detection> final_dets;
for (int idx : indices) {
final_dets.push_back(dets[idx]);
}
return final_dets;
}
int main() {
string engine_path = "/home/jetson/yolov8_cpp_inference/yolov8n_new.engine";
string img_path = "/home/jetson/yolov8_cpp_inference/bus.jpg";
string name_path = "/home/jetson/yolov8_cpp_inference/coco.names";
vector<string> class_names = load_coco_names(name_path);
ICudaEngine* engine = loadEngine(engine_path);
if (!engine) return -1;
IExecutionContext* context = engine->createExecutionContext();
size_t input_size = 3 * 640 * 640 * sizeof(float);
size_t output_size = 84 * 8400 * sizeof(float);
float *d_input, *d_output;
cudaMalloc((void**)&d_input, input_size);
cudaMalloc((void**)&d_output, output_size);
Mat img = imread(img_path);
Mat blob = dnn::blobFromImage(img, 1.0/255.0, Size(640, 640), Scalar(), false);
cudaMemcpy(d_input, blob.ptr<float>(), input_size, cudaMemcpyHostToDevice);
void* bindings[] = {d_input, d_output};
context->executeV2(bindings);
float* h_output = new float[84 * 8400];
cudaMemcpy(h_output, d_output, output_size, cudaMemcpyDeviceToHost);
vector<Detection> dets = postprocess(h_output, img.cols, img.rows);
// 可视化部分
for (auto& det : dets) {
// 取对应类别颜色(如果颜色不够,循环复用)
Scalar color = class_colors[det.cls_id % class_colors.size()];
// 画框:线宽改成 3(更粗,和 Ultralytics 一致)
rectangle(img, det.box, color, 3);
// 标签文字
string label = class_names[det.cls_id] + " " + to_string(det.conf).substr(0,4);
int baseline = 0;
Size text_size = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.6, 2, &baseline);
// 画文字背景(深蓝色背景,和 Ultralytics 一致)
rectangle(
img,
Point(det.box.x, det.box.y - text_size.height - 5),
Point(det.box.x + text_size.width, det.box.y),
color, // 蓝色背景
FILLED
);
// 画文字(白色文字,更醒目)
putText(
img,
label,
Point(det.box.x, det.box.y - 5),
FONT_HERSHEY_SIMPLEX,
0.6, // 字号稍大
Scalar(255,255,255), // 白色文字
2
);
}
imwrite("result.jpg", img);
cout << "✅ 检测完成!目标数量:" << dets.size() << endl;
// 释放内存
delete[] h_output;
cudaFree(d_input);
cudaFree(d_output);
delete context;
delete engine;
return 0;
}
5.1 main函数
作为整个工程的“入口”,通过main函数,我们可以看到清晰的运行流程。
string engine_path = "/home/jetson/yolov8_cpp_inference/yolov8n_new.engine";
string img_path = "/home/jetson/yolov8_cpp_inference/bus.jpg";
string name_path = "/home/jetson/yolov8_cpp_inference/coco.names";
vector<string> class_names = load_coco_names(name_path);
ICudaEngine* engine = loadEngine(engine_path);
if (!engine) return -1;
IExecutionContext* context = engine->createExecutionContext();
这部分是定义路径和加载引擎,并构建推理上下文。
size_t input_size = 3 * 640 * 640 * sizeof(float);
size_t output_size = 84 * 8400 * sizeof(float);
float *d_input, *d_output;
cudaMalloc((void**)&d_input, input_size);
cudaMalloc((void**)&d_output, output_size);
定义输入输出的数据尺寸,并分配GPU显存。
- 💊3 * 640 * 640 很好理解输入图像的尺寸是640*640,3是RGB三个颜色分量的值,每个值占一个通道。
- 💊84 * 8400是这样的,YOLOv8总共输出有3个stage,分辨率分别是 80×80,40×40,20×20,将其都加起来,就是8400个边界框,84就是80个类别得分外加4个边界框坐标(x, y, w, h)。

Mat img = imread(img_path);
Mat blob = dnn::blobFromImage(img, 1.0/255.0, Size(640, 640), Scalar(), false);
图像预处理,将图像resize到640 * 640,将每个通道的颜色值映射到0~1的区间,并将其维度转化为转为NCHW 格式。
cudaMemcpy(d_input, blob.ptr<float>(), input_size, cudaMemcpyHostToDevice);
将数据拷贝到GPU。
void* bindings[] = {d_input, d_output};
context->executeV2(bindings);
运行GPU推理。这是真正的TensorRT推理。
float* h_output = new float[84 * 8400];
cudaMemcpy(h_output, d_output, output_size, cudaMemcpyDeviceToHost);
vector<Detection> dets = postprocess(h_output, img.cols, img.rows);
将数据拷贝到CPU进行后处理。后处理过程比较详细和复杂,基本上是对预测的诸多边界框通过得分进行筛选,并得出预测。最终的结果,通过一个结构体的vector反馈回main函数中。
// 可视化部分
for (auto& det : dets) {
// 取对应类别颜色(如果颜色不够,循环复用)
Scalar color = class_colors[det.cls_id % class_colors.size()];
// 画框:线宽改成 3(更粗,和 Ultralytics 一致)
rectangle(img, det.box, color, 3);
// 标签文字
string label = class_names[det.cls_id] + " " + to_string(det.conf).substr(0,4);
int baseline = 0;
Size text_size = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.6, 2, &baseline);
// 画文字背景(深蓝色背景,和 Ultralytics 一致)
rectangle(
img,
Point(det.box.x, det.box.y - text_size.height - 5),
Point(det.box.x + text_size.width, det.box.y),
color, // 蓝色背景
FILLED
);
// 画文字(白色文字,更醒目)
putText(
img,
label,
Point(det.box.x, det.box.y - 5),
FONT_HERSHEY_SIMPLEX,
0.6, // 字号稍大
Scalar(255,255,255), // 白色文字
2
);
}
然后就是绘制最终的检测结果。通过遍历vector中的结构体,可以将检测到的object一个个绘制出来。单个边界框的绘制步骤分别是取色→画框→提取类别文字内容和配置部分属性→画类别文字背景→绘制文字
imwrite("result.jpg", img);
cout << "✅ 检测完成!目标数量:" << dets.size() << endl;
// 释放内存
delete[] h_output;
cudaFree(d_input);
cudaFree(d_output);
delete context;
delete engine;
return 0;
最后就是保存预测结果,打印完成信息,释放内存啦!运行后,可以在build文件夹路径下找到目标检测结果。
5.2 后处理函数
后处理就是在YOLOv8网络的诸多预测框中(8400个),选出最优的几个框,作为最终的预测结果。
📈先看看神经网络的输出信息:
输出维度:1 × 84 × 8400
8400 个框
每个框 84 个值:
0: x
1: y
2: w
3: h
4~83: 80个类别置信度
再看看软件实现过程:
for (int i = 0; i < 8400; i++) {
float x = output[0 * 8400 + i];
float y = output[1 * 8400 + i];
float w = output[2 * 8400 + i];
float h = output[3 * 8400 + i];
float max_conf = 0;
int cls_id = 0;
for (int j = 4; j < 84; j++) {
float conf = output[j * 8400 + i];
if (conf > max_conf) {
max_conf = conf;
cls_id = j - 4;
}
}
if (max_conf < 0.45) continue;
依次遍历预测框,从中取出尺寸和坐标。然后取出当前框在80个类别中的置信度,得到置信度最大的类别得分max_conf,以及具体类别cls_id,如果最大的都小于0.45,则直接丢弃当前预测结果。预测框无效。
int left = (x - w * 0.5f) * img_w / 640;
int top = (y - h * 0.5f) * img_h / 640;
int width = w * img_w / 640;
int height = h * img_h / 640;
left = max(0, left);
top = max(0, top);
dets.push_back({Rect(left, top, width, height), max_conf, cls_id});
再通过坐标转换,将x,y,w,h坐标转换为left,top,width,height,为防止出现负坐标,还进行了边界检查。然后就将计算结果push到局部变量dets中。
vector<Rect> boxes;
vector<float> scores;
for (auto& d : dets) {
boxes.push_back(d.box);
scores.push_back(d.conf);
}
vector<int> indices;
dnn::NMSBoxes(boxes, scores, 0.45f, 0.4f, indices);
vector<Detection> final_dets;
for (int idx : indices) {
final_dets.push_back(dets[idx]);
}
return final_dets;
定义两个局部的vector:boxes和scores,分别将dets的边界框和得分保存到两个变量中。
再定义一个vector:indices,NMS处理完,边界框的索引会保存到indices中。
然后再遍历indices,根据具体的索引取出最终预测结果并返回。
💥 总体来说,后处理分两步骤,先根据仅仅所有框的置信度得分“粗筛”一波,再用NMS算法进行“精筛”,从而得到最终结果。
但重点是,NMS算法的细节我们好像并不知道只是调用了一个底层的接口,虽然不知道底层的细节,但是基本的原理还是知道的。
先来看看我们传入的参数都是什么含义:
dnn::NMSBoxes(boxes, scores, 0.45f, 0.4f, indices);
boxes和scores很明显,就是经过初筛的边界框坐标及其得分。0.45f是我们刚才筛选边界框时候的判定阈值,0.4f是交并比阈值,将来用来精筛的,最终的结果会保存在变量indices中。
NMS的原理大致是这样的(当然第一步稍显多余):
- 再按置信度过滤一遍(第二次粗筛)
只保留 score ≥ 0.45 的框 - 按置信度从高到低排序
置信度越高,优先级越高,越容易被保留 - 遍历每一个框,计算 IoU(重叠度)
拿置信度最高的框当基准
计算它和其他所有框的重叠度
如果重叠度 IoU > 0.4
→ 判定为同一个目标
→ 直接删掉! - 输出最后保留的框编号 → indices。
这就是整个后处理的逻辑!
6. 编译运行
如果已经定位到当前项目路径了,首先需要将当前路径CD到build路径下:
cd build
然后运行我们写好的Cmake文件:
cmake ..
运行完,就会在build路径下生成相关的make文件。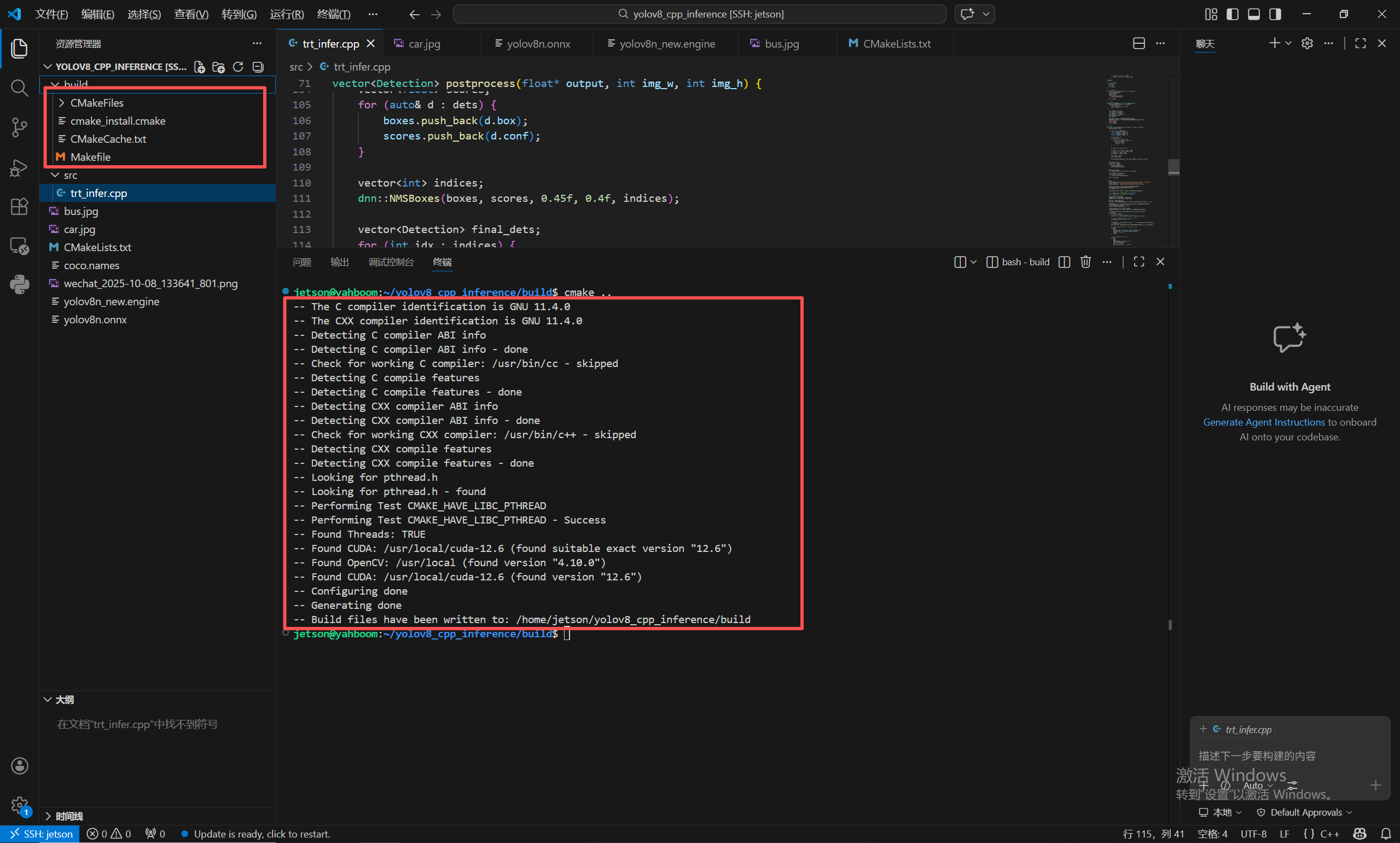
执行编译:
make
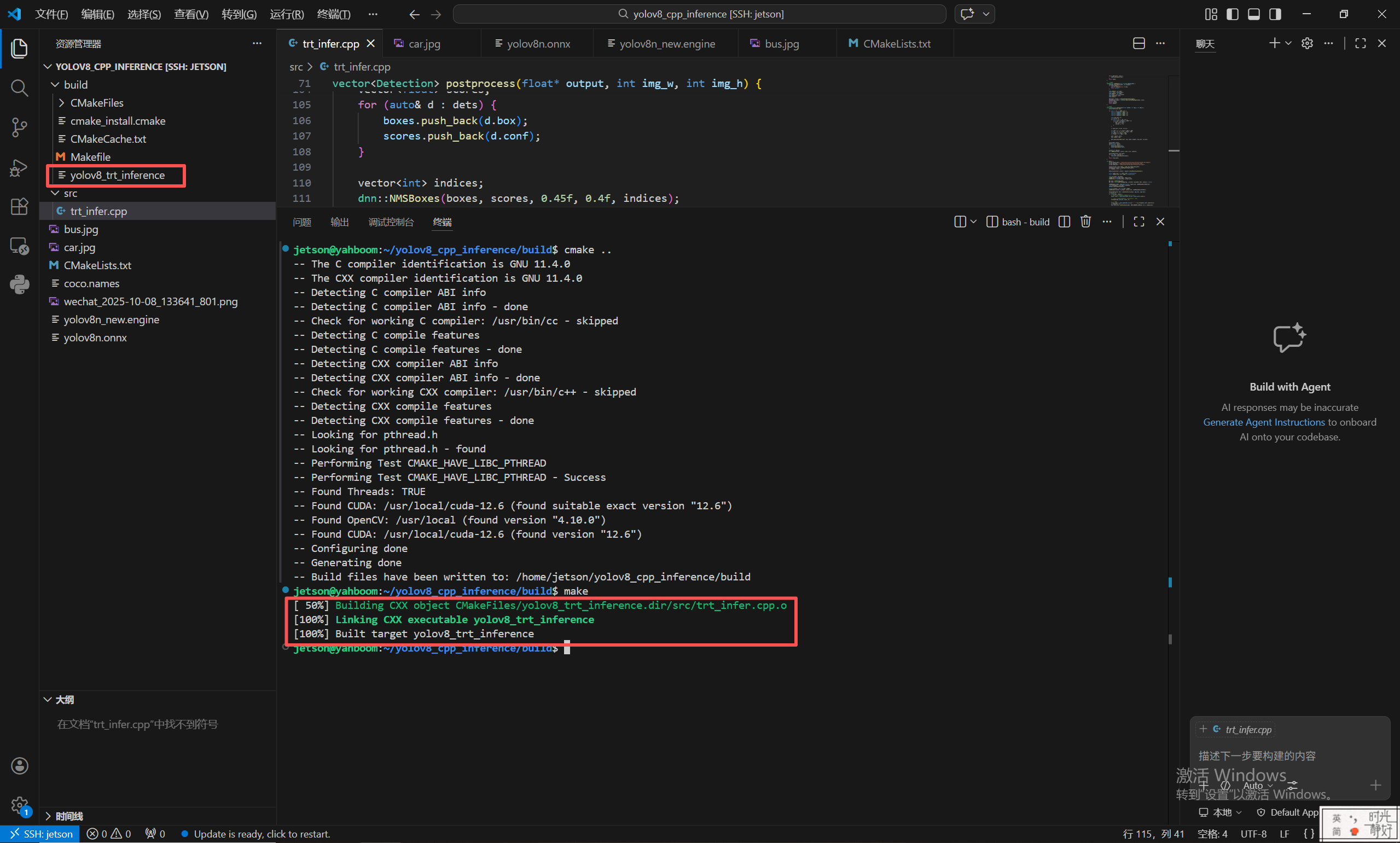
最终在build文件夹下生成可执行文件yolov8_trt_inference。
最后运行可执行文件:
./yolov8_trt_inference
输出最终的预测结果,命令行输出:共检测到5个目标。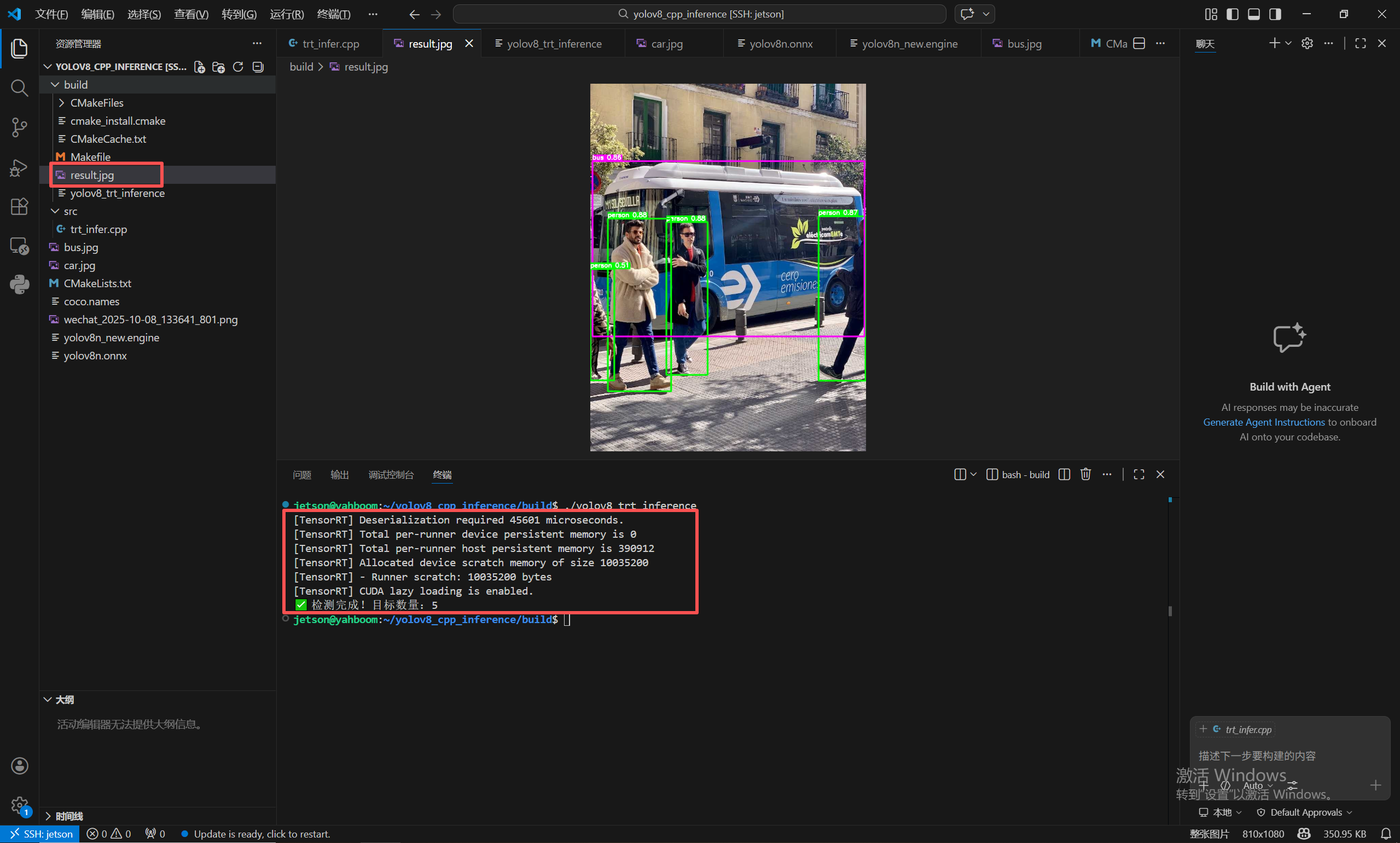
7 总结
本篇完整实现了 YOLOv8 在 Jetson 平台上的 C++ + TensorRT 端到端单图检测流程,从模型转换(pt→onnx→engine)、工程搭建、核心推理代码编写,到后处理与可视化,全程可复现、可落地。
通过本次实战,我们清晰理解了:
- TensorRT engine 是硬件绑定的执行计划,而非网络结构,必须重新生成才能在 C++ 环境中使用;
- 后处理的核心逻辑:先通过置信度过滤粗筛,再通过 NMS 细筛,最终得到干净的检测结果;
本篇只涉及单个图片的实时推理,关于数据集和视频数据的实时推理,后续文章会继续更新,敬请期待!💪💪💪

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)