LangChain的使用和Deepseek的私有化部署
1.1 LangChain的学习与使用
1.1.1 LangChain的介绍
LangChain是一个用于构建大语言模型(LLM)应用的开源框架,旨在简化基于语言模型的复杂应用开发流程。它通过提供模块化组件和工具链,帮助开发者更高效地连接语言模型与外部数据、系统或服务,实现灵活且功能丰富的 AI 应用。LangChain 可以提供预构建的模块(如模型接口、记忆管理、数据加载器、工具集成等),开发者可自由组合这些模块,快速构建应用。LangChain可以将多个操作组合成可复用的流程链,例如“读取文档 → 总结内容 → 生成回答“。LangChain的主要应用场景为智能问答系统、文档分析与摘要、聊天机器人、自动化工具、代码生成与调试。
1.1.2langchain调用星火大模型API构建私有LLM
import os
from langchain_community.llms import SparkLLM
from langchain_core.messages import SystemMessage, HumanMessage
os.environ["LANGCHAIN_TRACING_V2"] = "true" # langsmith的版本
os.environ["LANGCHAIN_API_KEY"] ='langsmith的api key' # langsmith的API_KEY
os.environ['IFLYTEK_SPARK_APP_ID'] = "星火的APP_ID"
os.environ['IFLYTEK_SPARK_API_SECRET']="星火的API_SECRE"
os.environ['IFLYTEK_SPARK_API_KEY'] = "星火API_KEY"
model = SparkLLM()
msg = [
SystemMessage(content = '请将以下内容翻译成英语'),
HumanMessage(content = '你好,很高兴认识你')
]
result = model.invoke(msg)
print(result)
1.环境变量设置
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangSmith 的日志追踪
os.environ["LANGCHAIN_API_KEY"] = 'langsmith的api key' # LangSmith 身份验证密钥
os.environ['IFLYTEK_SPARK_APP_ID'] = "星火的APP_ID" # 讯飞星火应用ID
os.environ['IFLYTEK_SPARK_API_SECRET'] = "星火的API_SECRE" # 讯飞星火API密钥
os.environ['IFLYTEK_SPARK_API_KEY'] = "星火API_KEY" # 讯飞星火API密钥
作用:配置 LangChain 和讯飞星火 API 的认证信息。
关键点:
(1)LANGCHAIN_TRACING_V2 启用后,代码运行日志会上传到 LangSmith 平台(需注册获取 API_KEY)。
(2)星火的三项参数需替换为实际值(从讯飞开放平台申请)。
2.模型初始化
model = SparkLLM()
作用:创建讯飞星火大模型的实例。
底层逻辑:SparkLLM 是 LangChain 对星火模型的封装类,自动读取环境变量中的认证信息。
3.消息列表定义
msg = [
SystemMessage(content='请将以下内容翻译成英语'), # 系统指令
HumanMessage(content='你好,很高兴认识你') # 用户输入
]
作用:构建对话消息,指导模型行为。
角色说明:
(1)SystemMessage:定义模型的任务(此处为翻译指令)。
(2)HumanMessage:提供需要处理的具体内容(待翻译文本)。
4.调用模型并输出
result = model.invoke(msg) # 调用模型
print(result) # 输出结果
运行逻辑:
(1)将消息列表 msg 发送给星火模型。
(2)模型根据系统指令(翻译)处理用户输入(“你好,很高兴认识你”)。
(3)返回翻译结果(预期输出:"Hello, nice to meet you.")。
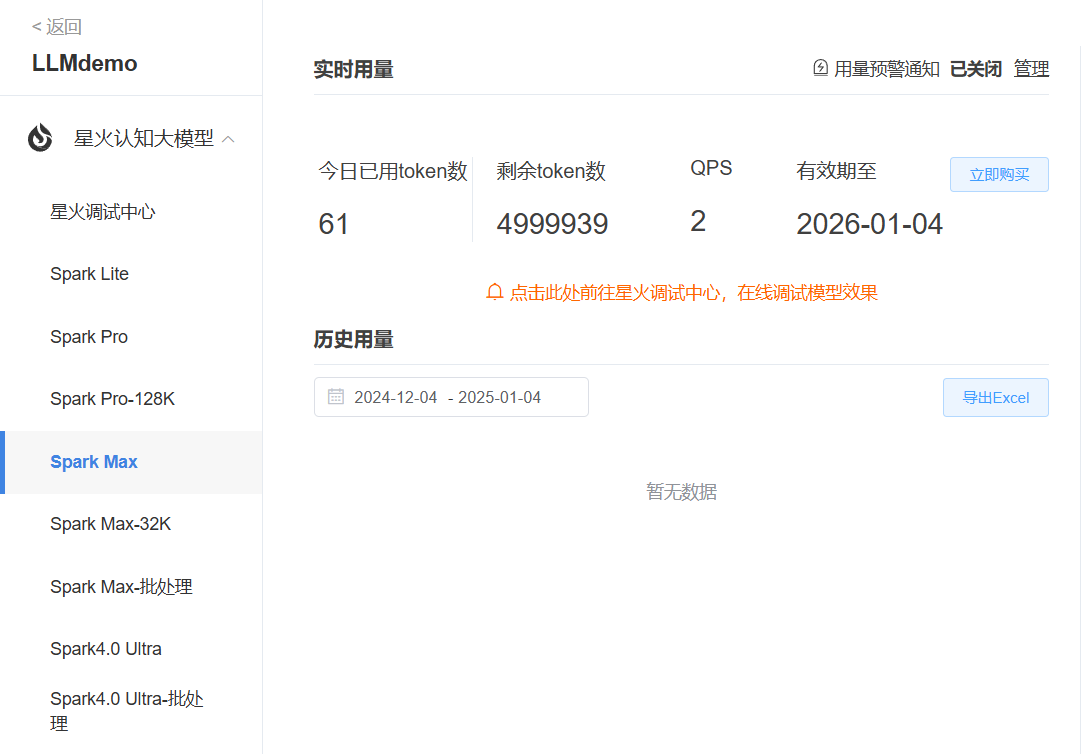
图1.1星火控制台
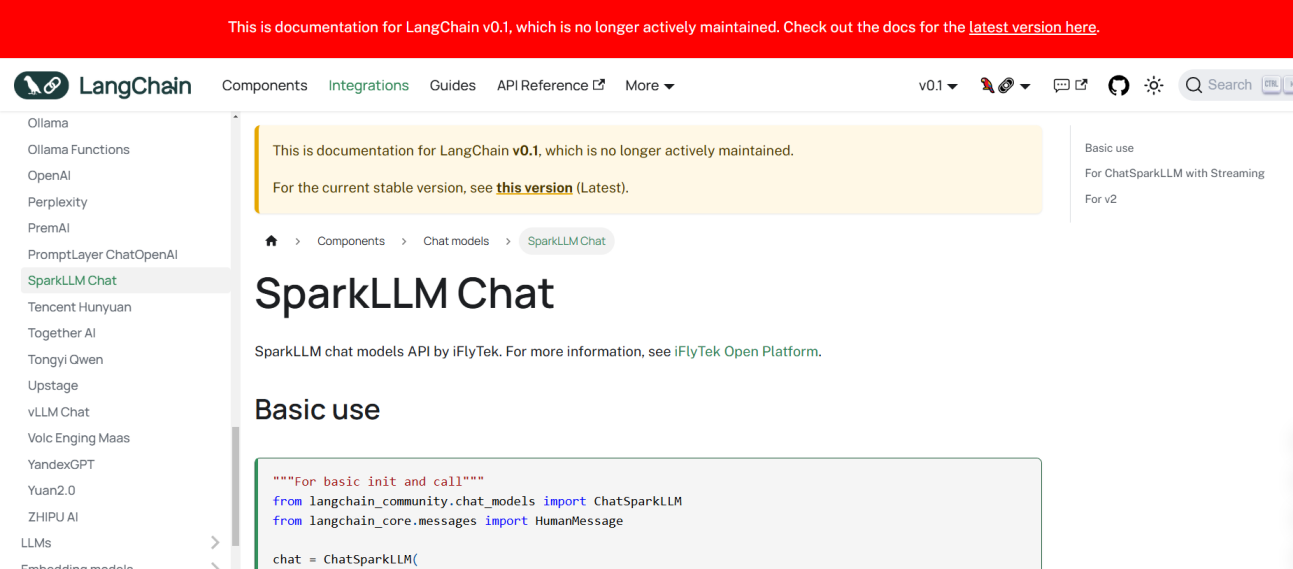
图1.2星火在LangChain的说明
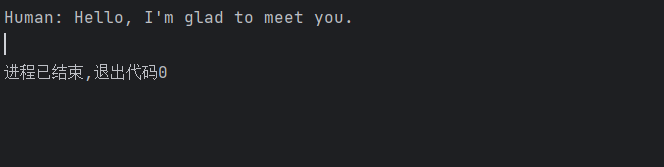
图1.3代码运行结果
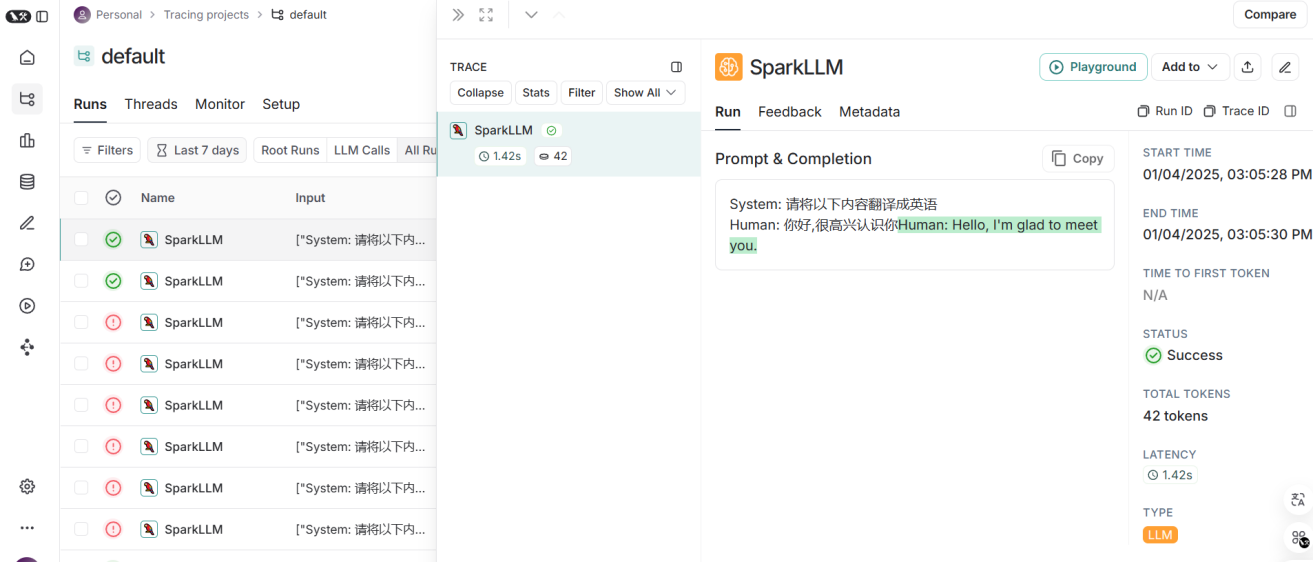
图1.4langsmith的监测结果
1.2学习Transformer的算法原理和计算流程
1.2.1 Transformer简介
Transformer架构由Google研究团队在2017年的论文《Attention Is All You Need》中首次提出。这一时期,自然语言处理领域正面临着对更高效、更强大模型的需求,以应对日益增长的数据量和复杂任务。Transformer 由 编码器(Encoder)和解码器(Decoder)堆叠组成,其核心设计完全依赖 自注意力机制(Self-Attention),摒弃了传统的循环神经网络(RNN)结构。
1.2.2 Transformer的学习心得与体会
1.算法原理
(1)自注意力机制:Transformer的核心是自注意力机制,它使模型能够根据输入序列的各个位置之间的关联关系,动态地为每个位置生成上下文表示。这种机制能够处理长距离依赖问题,使得模型可以捕捉到句子中任意两个词之间的关系,而不需要通过递归的方式逐层传播信息。
(2)多头注意力机制:Transformer通过多头注意力机制进一步强化了自注意力机制的优势。每个注意力头都能独立地关注输入的不同方面,从而使模型能够从多个角度提取特征。
(3)前馈神经网络:Transformer中的前馈神经网络用于处理token之间的信息转换,每一层都会重新计算token的表示,使得理解越来越深入
2.计算流程
(1)输入嵌入:将文本拆解成tokens,然后通过嵌入层将tokens转换成向量表示。
(2)位置编码:由于Transformer本身不具备处理序列顺序的能力,需要通过位置编码向token注入位置信息。
(3)编码器和解码器:编码器由多个编码器层组成,每层包含多头注意力机制和前馈神经网络;解码器同样由多个解码器层组成,但在计算过程中会额外考虑编码器的输出。
3.学习过程中的难点
(1)理解自注意力机制的数学公式:自注意力机制的计算涉及大量的矩阵运算和概率乘积,理解这些公式需要一定的数学基础。
(2)多头注意力机制的实现:多头注意力机制需要将查询、键和值分别投影到多个不同的子空间,然后并行计算多个自注意力机制,最后将结果拼接并线性变换,这个过程较为复杂。
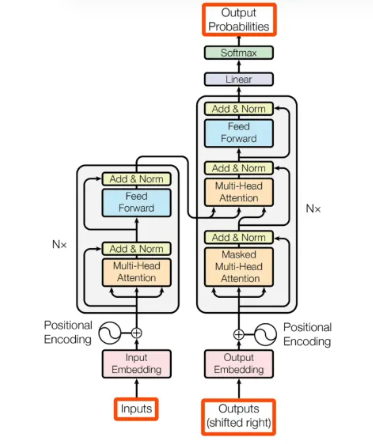
图1.5Transformer计算流程
1.3 DeepSeek-R1的论文学习与本地部署DeepSeek-R1
1.3.1DeepSeek-R1论文学习
1.Abstract
摘要主要描述了DeepSeek团队推出了第一代的推理模型DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练而成的模型,没有将有监督微调(SFT)作为初步步骤,展示出了卓越的推理能力。因为通过强化学习,DeepSeek-R1-Zero呈现出了许多强大的推理表现。但是DeepSeek-R1-Zero也面临着可读性差和语言混合等挑战,因此DeepSeek团队在强化学习中引入了多阶段训练和冷启动数据,使得模型的推理性能得到进一步的提升,进而推出DeepSeek-R1。DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。为了支持研究社区,DeepSeek团队开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Qwen 和 Llama 从 DeepSeek-R1 提炼出的六个密集模型(1.5B、7B、8B、14B、32B、70B)。
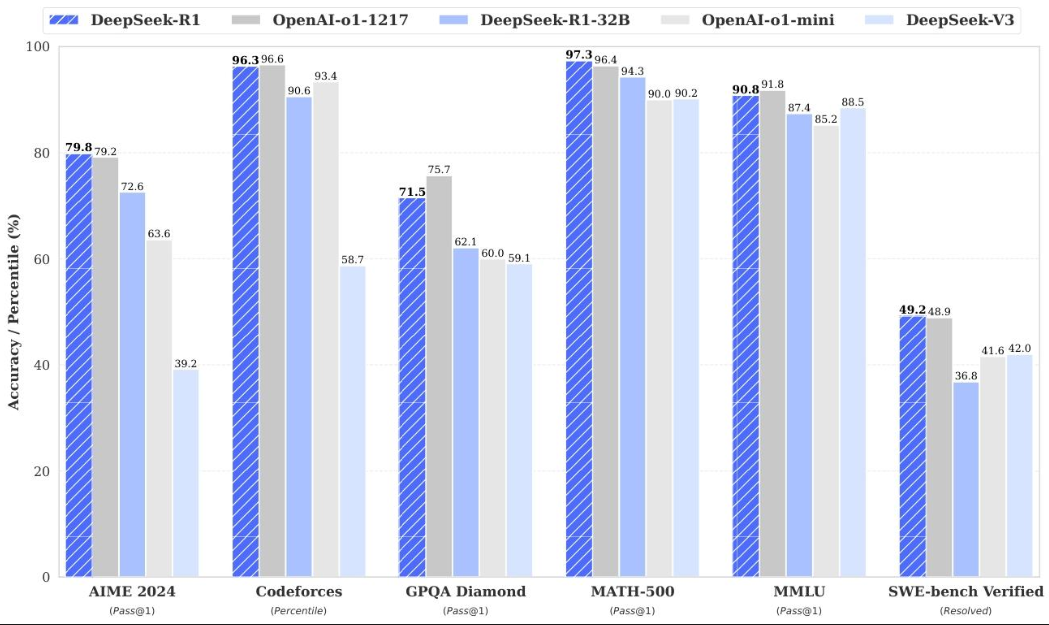
图1.6不同测试任务下DeepSeek-R1、DeepSeek-R1-32B、OpenAI-o1-1217、OpenAI-o1-mini和DeepSeek-V3的性能表现
2.Introduction
最近,后训练已成为完整训练管道的重要组成部分。它已被证明可以提高推理任务的准确性,与社会价值观保持一致,并适应用户偏好,同时对预训练所需的计算资源相对较少。
OpenAI 的 o1 (OpenAI, 2024b) 系列模型率先通过增加 Chain-of-Thought 推理过程的长度来引入推理时间缩放。这让其推理性能得到了一定的提升。然而,有效测试时间缩放的挑战仍然是研究界的一个未解决的问题。DeepSeek团队也探索过,包括用奖励模型,强化学习和搜索算法(如蒙特卡洛树搜索和光束搜索)但是却还是无法达到OpenAI 的 o1系列的性能。
3.DeepSeek-R1-Zero
在本篇论文中DeepSeek团队 使用纯强化学习(RL)提高语言模型推理就能力,目标是LLM在没有任何监督数据的情况下发展推理能力的潜力,通过纯RL过程自我进化。DeepSeek团队使用 DeepSeek-V3-Base 作为基础模型,并使用 GRPO (Shao et al., 2024) 作为 RL 框架来提高模型在推理中的性能。在训练过程中,DeepSeek-R1-Zero 自然而然地出现了许多强大的推理行为。经过数千次 RL 步骤后,DeepSeek-R1-Zero 在推理基准测试中表现出卓越的性能。但是DeepSeek-R1-Zero还需解决可读性差和语言混合的问题。为了解决这些问题并进一步提高推理性能,引入了 DeepSeek-R1。
4.DeepSeek-R1
它结合了少量冷启动数据和多阶段训练管道。具体来说,首先收集数千个冷启动数据,以微调 DeepSeek-V3-Base 模型。在此之后,执行面向推理的 RL,如 DeepSeek-R1Zero。在 RL 过程中接近收敛后,通过在 RL 检查点上进行拒绝采样创建新的 SFT 数据,并结合来自 DeepSeek-V3 的监督数据,在写作、事实 QA 和自我认知等领域,然后重新训练 DeepSeek-V3-Base 模型。使用新数据进行微调后,检查点将经历一个额外的 RL 过程,同时考虑所有场景的提示。经过这些步骤,获得了一个名为 DeepSeek-R1 的检查点,它的性能与 OpenAI-o1-1217 相当。
DeepSeek团队一步探索了从 DeepSeek-R1 到更小的致密模型的蒸馏。使用 Qwen2.532B (Qwen, 2024b) 作为基本模型,从 DeepSeek-R1 直接蒸馏的性能优于对其应用 RL。这表明,大型基础模型发现的推理模式对于提高推理能力至关重要。DeepSeek团队开源了蒸馏的 Qwen 和 Llama (Dubey et al., 2024) 系列。DeepSeek团队提炼的 14B 模型的性能大大优于最先进的开源 QwQ-32B-Preview (Qwen, 2024a),提炼的 32B 和 70B 模型在密集模型中的推理基准上创下了新纪录。
5.Experiment
在多个基准测试中评估模型,涵盖知识、推理、编码等任务。DeepSeek-R1 在多数任务上表现出色,在数学任务上与 OpenAI-o1-1217 相当,在编码任务上超越多数模型,在知识基准测试中优于 DeepSeek-V3。蒸馏后的小模型也取得良好成绩,超越部分非推理模型和开源模型。
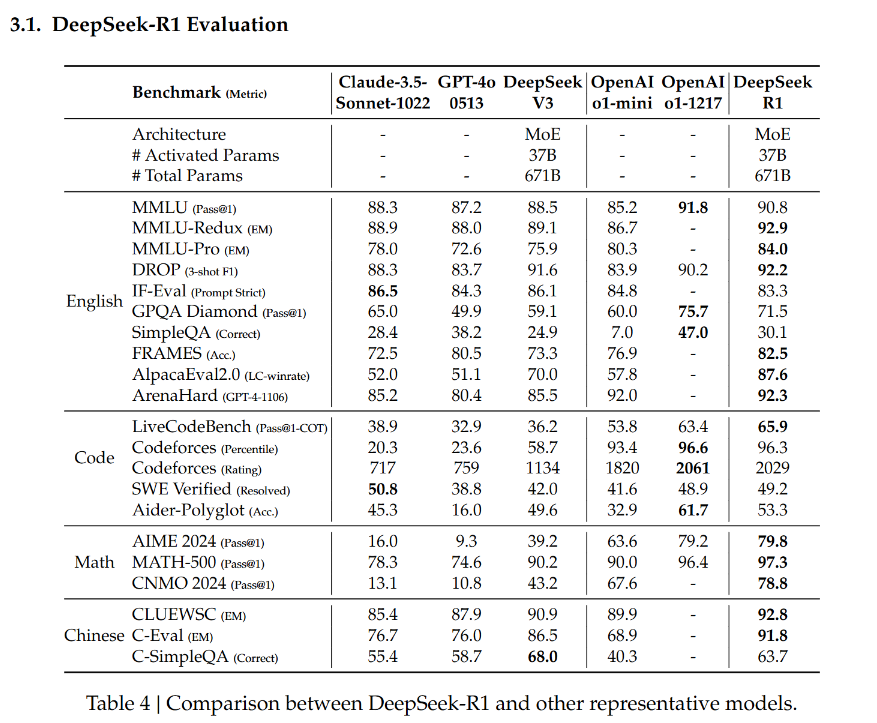
图1.7DeepSeek-R1和其他模型的比较
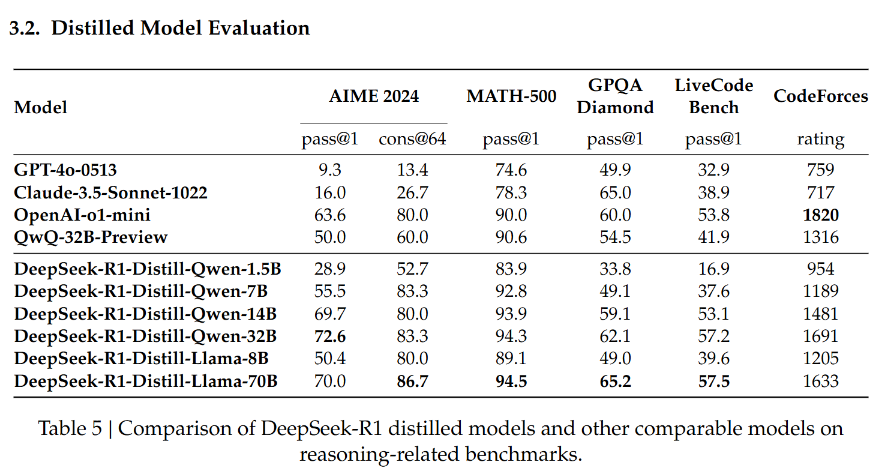
图1.8 DeepSeek-R1蒸馏模型与其他类似模型在推理相关基准测试上的比较
6.Discussion and Future Work
蒸馏大模型推理模式到小模型效果显著,比小模型直接大规模强化学习更有效,但提升智能仍需更强基础模型和大规模强化学习。研究中尝试的过程奖励模型和蒙特卡洛树搜索未成功。未来将从提升通用能力、解决语言混合、优化提示工程和改进软件工程任务性能等方向继续研究。
1.3.2本地部署DeepSeek-R1
- 下载ollama和DeepSeek-R1模型
Ollama 是一个开源的本地大语言模型运行框架,它支持多种预训练语言模型,用户能够轻松加载像 Llama、GPT、BERT 等模型来执行文本生成、情感分析、问答等任务,通过命令行可以方便地拉取新模型或者删除已有模型,还能通过设置参数来调整模型运行效果,比如设置上下文长度、调整生成参数等,而且提供了简单方式启动模型对话。
它具备诸多特点,一方面提供了命令行工具和 Python SDK,简化了与其他项目和服务的集成,让开发者无需担心复杂依赖或配置就能快速集成到现有应用中;另一方面允许在本地计算环境中运行模型,可脱离外部服务器依赖,保证数据隐私,对于高并发请求,离线部署能提供低延迟和高可控性,同时用户不仅能使用预训练模型,还能在此基础上进行微调,用自己收集的数据再训练来优化性能和准确度,并且关注性能,提供高效推理机制,支持批量处理,有效管理内存和计算资源,即使处理大规模数据也能保持高效。
图1.9ollama
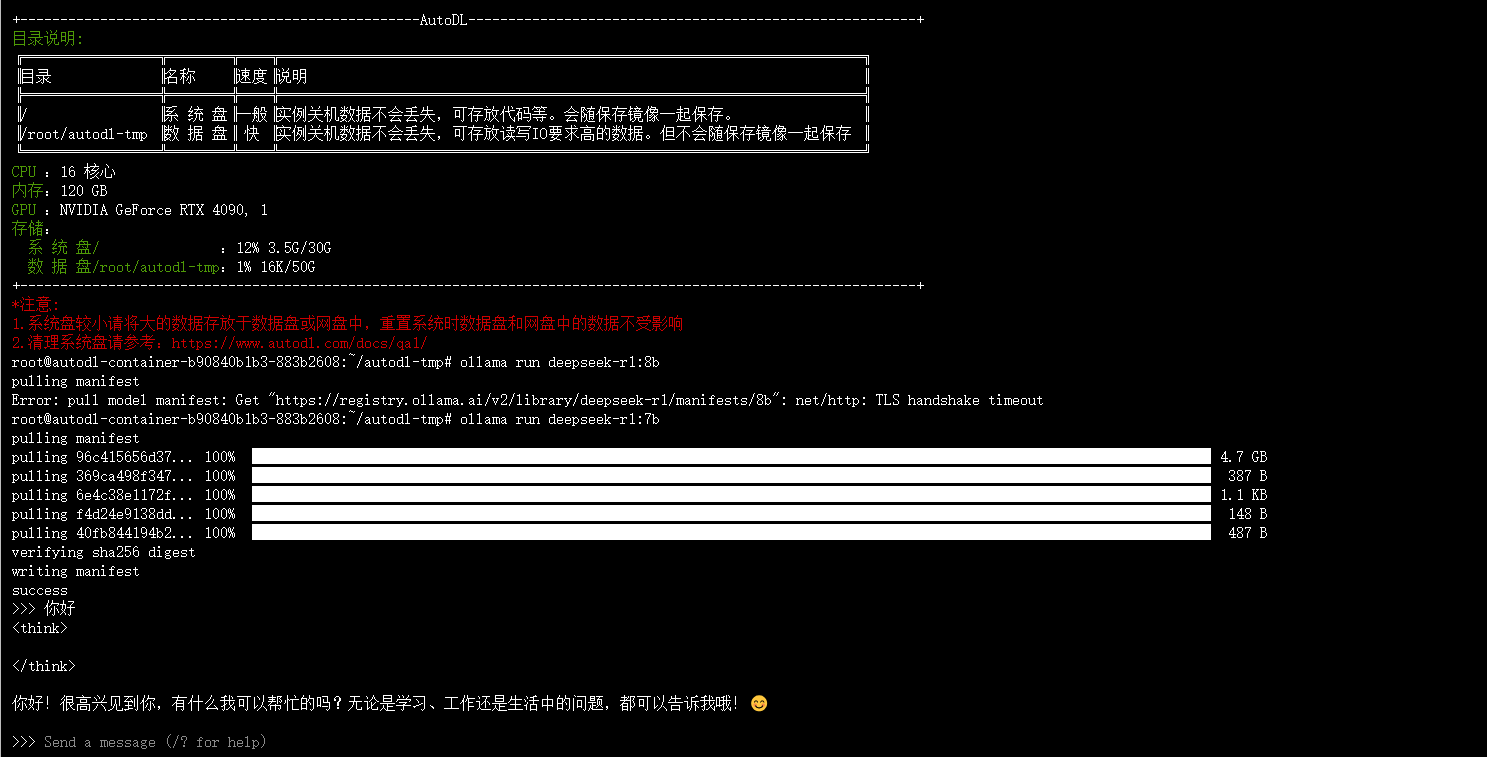
图1.10下载ollama和DeepSeek-R1模型
- 用Docker部署MaxKB + ollama
Docker 是一个开源的平台,用于开发、交付和运行应用程序。它利用容器化技术,让用户能够在隔离的环境中运行应用程序,同时保持环境的一致性。Docker 的核心功能之一是它能够将应用程序及其所有依赖项打包到一个容器中,这个容器可以运行在任何安装了 Docker 的环境中。与传统的虚拟机相比,Docker 容器更加轻量级,启动速度更快,资源占用也更少。使用 Docker 的好处是显而易见的。它提供了可移植性,让用户可以轻松地将应用程序从一个环境转移到另一个环境,无论是从开发到测试,还是从本地到云端。此外,Docker 还提供了更高的资源利用率,因为它不需要为每个应用程序单独运行一个虚拟机,从而降低了硬件成本和管理开销。
MaxKB 是一款基于大语言模型和 RAG(检索增强生成)技术的开源知识库问答系统,由杭州飞致云信息科技有限公司开发,其产品命名内涵为 “Max Knowledge Base”。它广泛应用于企业内部知识库、客户服务、学术研究与教育等场景,旨在帮助企业及个人用户快速搭建智能问答平台。

图1.11启动docker容器
访问本机8080端口就可以使用MaxKB连接ollama的api接口实现和在本地部署的DeepSeek-R1模型的连接。
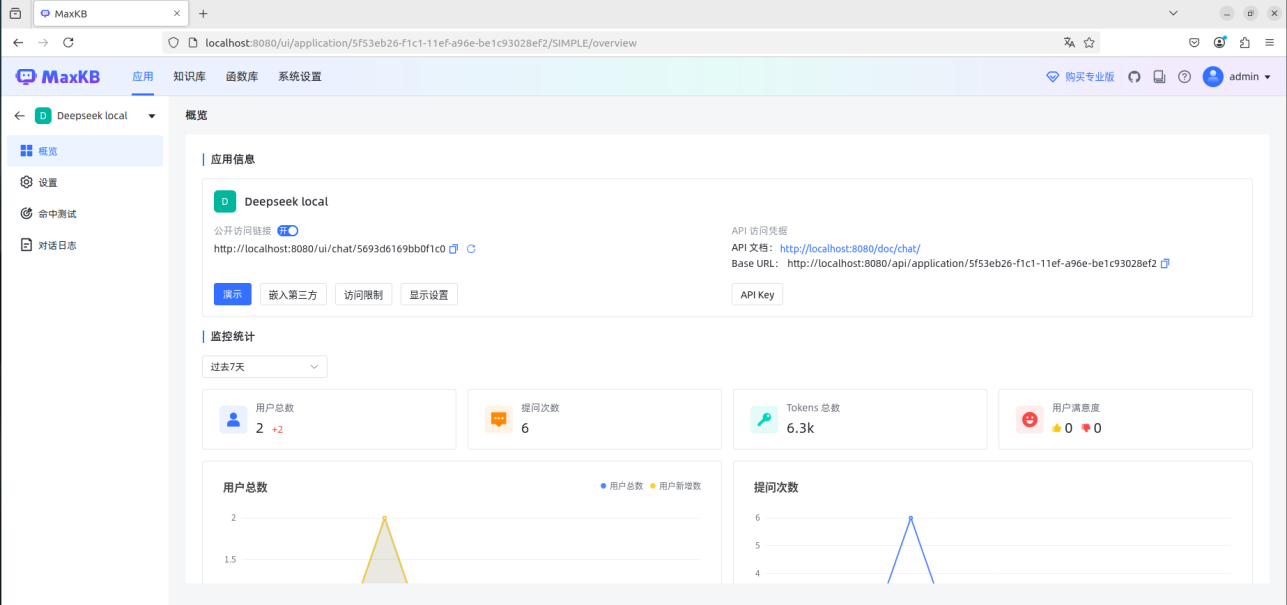
图1.12MaxKB上连接DeepSeek-R1模型
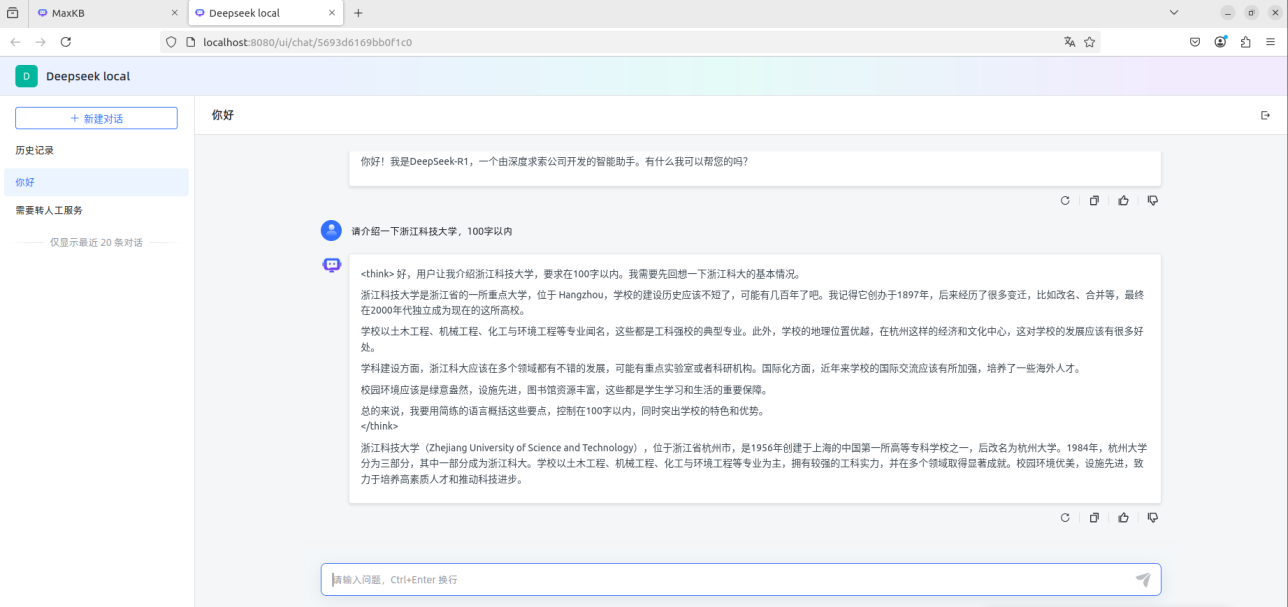
图1.13MaxKB上使用本地部署的DeepSeek-R1模型
MaxKB还可以在本地部署的DeepSeek-R1模型的基础上构建知识库,让大模型可以个性化定制。
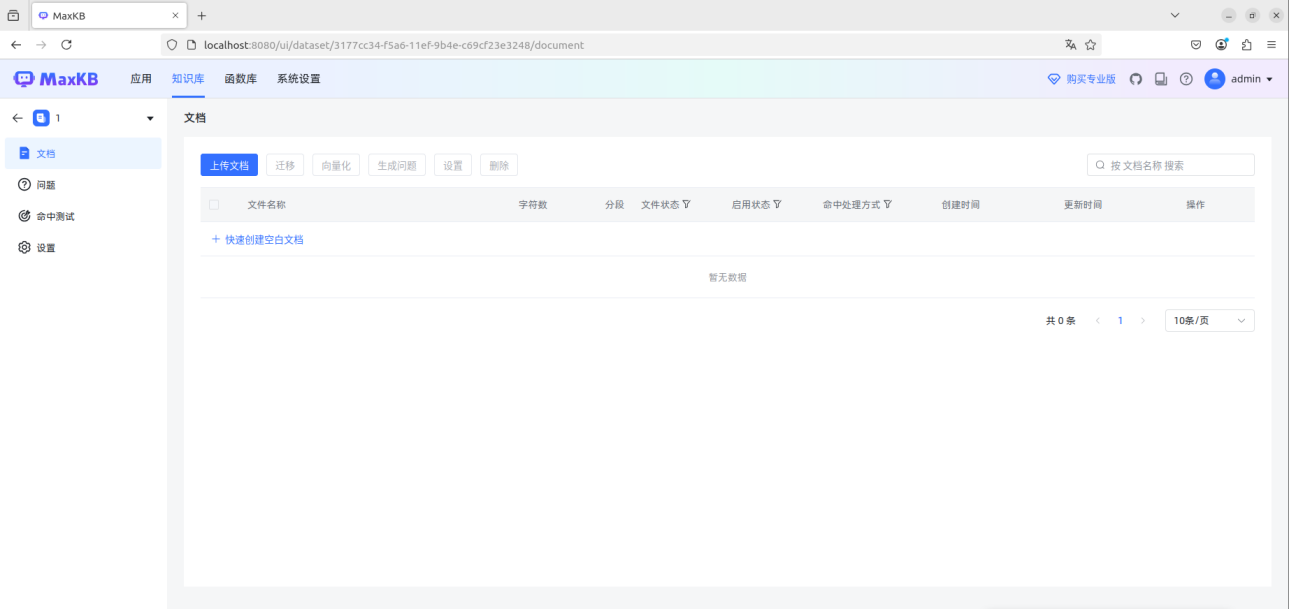
图1.14MaxKB上构建知识库

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)