NeuPAN:具有端到端基于模型的学习的直接点机器人导航
一、文章概要
1.1 表格总结
|
一、基本信息 |
标题 |
NeuPAN: Direct Point Robot Navigation with End-to-End Model-based Learning |
|
作者 |
Ruihua Han, Shuai Wang, Shuaijun Wang, Zeqing Zhang, Jianjun Chen, Shijie Lin, Chengyang Li, Chengzhong Xu, Yonina C. Eldar, Qi Hao, Jia Pan |
|
|
关键词 |
Direct point robot navigation, model-based learning, optimization based collision avoidance |
|
|
doi |
文本中未涉及相关内容 |
|
|
二、文章概述 |
本文提出NeuPAN,一种实时、高精度、无地图、易于部署且环境不变的机器人运动规划器。它通过紧密耦合的感知-控制框架,直接将原始点云数据映射到潜在距离特征空间以生成无碰撞运动,并从端到端基于模型的学习角度具有可解释性。通过在地面移动机器人、轮腿机器人和自动驾驶车辆上的广泛仿真和现实环境评估,结果表明NeuPAN在准确性、效率、鲁棒性和泛化能力方面优于现有基线。 提出一个名为 NeuPAN 的全新框架,它将原始的点云传感器数据直接、实时地映射为机器人的控制指令,实现了“感知到控制”的紧密耦合,并且整个过程基于可解释的数学模型。 |
|
|
三、研究背景 |
在密集受限环境中,机器人实时导航需精确感知和运动控制以实现实时避障。现有方法存在问题:一是将高维传感器空间压缩到低维动作空间时难以保证可解释性和防止误差传播;二是导航问题计算复杂,需在准确性和复杂性间权衡,导致运动不精确或延迟;三是解决方案需稳定、完整且用户友好,减少手动设计和针对新机器人与环境的再训练。这些系统、算法和工程问题使仅依靠车载计算资源的密集场景导航成为长期挑战。 传统机器人在未知、杂乱环境中导航时,面临三大挑战:1) 误差传播:从感知(如物体检测)到规划(如路径生成)的模块化流程会累积误差,导致导航保守或失败。 2) 黑箱问题:纯粹的端到端学习方法缺乏可解释性,难以保证安全和部署。 3) 精度与效率:精确的传统优化方法计算量巨大,难以实时;而快速的方法又不够精确,无法应对狭窄复杂的场景。 |
|
|
四、研究思路 |
提出研究问题 |
针对现有导航方法在密集未知环境中存在的误差传播、计算复杂、泛化能力差等问题,提出如何实现直接从点云到运动控制的端到端、高精度、实时避障导航。 |
|
构建研究框架 |
设计紧密耦合的感知-控制框架,包括基于深度学习的深度展开神经编码器(DUNE)和神经正则化运动规划器(NRMP),形成端到端数学模型。 |
|
|
选择研究方法 |
采用基于模型的学习方法,通过交替最小化网络(PAN)结合神经元求解带有点级约束的端到端数学模型,将原始点云映射到潜在距离特征空间,融入运动规划作为正则化项。 采用一个包含两大核心模块的迭代循环框架: |
|
|
分析数据 |
在多种机器人平台(地面移动机器人、轮腿机器人、自动驾驶车辆)和不同环境(模拟场景、真实世界的沙箱、办公室、走廊、停车场等)进行实验,评估成功率、导航时间、平均速度等指标。 |
|
|
得出结论 |
通过对比实验验证NeuPAN在准确性、效率、鲁棒性和泛化能力上优于现有方法,能在未知非结构化环境中处理任意形状物体,将不可通行路径转化为可通行路径。 |
|
|
五、研究结果 |
在模拟场景中,处理非凸障碍物时,NeuPAN的成功率比RDA提高19%以上,导航时间减少11.27%,平均速度提升6.0%。 |
|
|
在动态障碍物场景中,NeuPAN-vel(融入点速度)在障碍物速度为3m/s和4m/s时,成功率分别提高10.96%和35.42%,导航时间缩短1.09%和3.47%。 |
||
|
在真实世界结构化测试床中,NeuPAN能通过3厘米间隙,相比TEB精度提升超2倍,且导航时间最短、速度最高。 |
||
|
在非结构化杂乱环境中,人类手动控制失败,而NeuPAN成功导航,通过DoN为0.88的狭窄空间。 |
||
|
在轮腿机器人和自动驾驶车辆实验中,NeuPAN在狭窄空间导航准确性、速度和效率上均优于对比方法,如在DoN=0.89的受限空间中成功通过,而Falco失败。 |
||
|
六、研究结论、不足与展望 |
研究结论 |
NeuPAN通过端到端基于模型的学习方法,实现了直接从点云到机器人动作的映射,避免了感知到控制 pipeline 的误差传播,具有可解释性。在多种机器人平台和环境中,其准确性、效率、鲁棒性和泛化能力均优于现有方法,能在未知非结构化环境中处理任意形状物体,实现高精度实时避障导航。 |
|
研究的创新性 |
1. 直接将原始点云数据映射到潜在距离特征空间生成无碰撞运动,避免误差传播;2. 从端到端基于模型的学习角度具有可解释性,通过 PnP PAN 网络求解带点级约束的数学模型;3. 无缝集成数据和知识引擎,网络参数可通过反向传播微调。 1. 直接映射与误差消除: 2. 端到端的可解释模型学习:
|
|
|
研究的优势 |
高精度(比现有方法精确2倍以上)、实时性、无地图、易部署(对新环境泛化能力强,无需大量重训练)、高鲁棒性和可解释性。 | |
|
研究展望 |
1. 进一步提升在高速动态障碍物环境中的适应性,优化对障碍物速度预测的准确性;2. 探索在更复杂地形(如崎岖地形、水下等)的应用,扩展机器人类型;3. 研究多机器人协同导航场景下的NeuPAN扩展,实现群体避障与路径规划;4. 结合更先进的传感器融合技术(如视觉与激光雷达融合),提升环境感知的全面性和鲁棒性。 |
|
|
研究意义 |
NeuPAN为机器人在密集、未知、非结构化环境中的导航提供了新方法,解决了传统方法的误差传播和计算复杂性问题,推动了端到端模型基学习在机器人导航领域的应用。其高精度和实时性使机器人能在之前认为不可通行的环境中工作,为家庭服务机器人、物流机器人、自动驾驶等领域的实际应用奠定基础。 |
|


1.2 具体实现流程
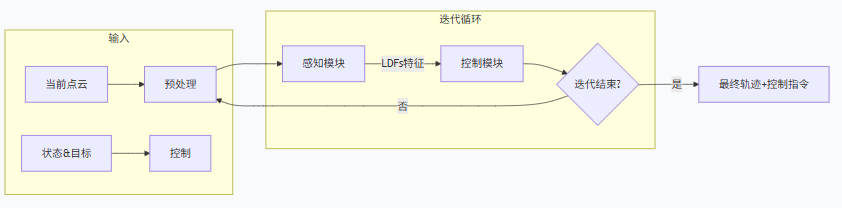
NeuPAN的实现流程是一个紧密耦合的迭代循环,旨在以高频率实时生成最优的控制指令。
1.2.1 输入 (Inputs):
- 实时传感器数据:原始的激光雷达点云数据 (
Pt)。 - 机器人自身状态:当前的位置、姿态、速度等 (
st)。 - 任务指令:目标点的坐标 (
s_goal)和期望的行驶速度 - 机器人物理模型:机器人的几何形状(由矩阵
G, h描述)和运动学模型(如差分驱动、阿克曼转向等)。
1.2.2 核心处理流程 (Core Processing Flow):
整个流程可以看作一个在极短时间内(例如,几十毫秒)迭代数次(例如,K=3次)的优化循环。
第一步:预处理 - 生成点云流 (Point Flow Generation)
逻辑:不仅仅使用当前的静态点云,而是结合上一步规划出的机器人预测运动轨迹 (S[k]),来推算在未来一小段时间内(后退时域 H),每个障碍物点相对于机器人的动态位置。
数据流:将全局坐标系下的点云 Pt 转换到机器人自身的局部坐标系,并根据预测运动生成一个时序点云集合,即点云流 PFt。
第二步:DUNE 模块 - 计算潜在距离特征 (LDF Generation)
逻辑:这是框架的“感知”核心。DUNE网络接收预处理后的点云流,并为每一个障碍物点快速计算出它与机器人车身的精确最小距离。但它输出的不是一个简单的距离值,而是一组被称为**潜在距离特征(LDFs)**的拉格朗日乘子 (M, L)。这组特征非常巧妙,它稀疏地编码了“哪个障碍物点”与“机器人车身的哪条边”即将发生碰撞,以及它们之间的法向量关系。
数据流:点云流 PFt → DUNE网络 → 潜在距离特征 M, L。

# 步骤1: DUNE 输出拉格朗日乘子
M, L = DUNE(points) # M 和 L 编码了碰撞信息
# 步骤2: 从 LDFs 中提取 mu(避障权重)
mu = extract_mu(M, L) # mu_i = 拉格朗日乘子,表示第 i 个半平面的重要性
# 步骤3: 计算全局避障力
lam = -R @ G.T @ mu
# 这个 lam 直接告诉机器人:往哪个方向移动以避开障碍物
# 告诉路径规划"往哪个方向走能最快离开机器人边界"障碍物点 p → DUNE模型 → 预测 mu 和 λ
↓
计算 distance
↓
按距离排序 → 优先规划近处障碍物(按距离排序后,只保留最近的 max_num 个点进行精确规划,其余作为稀疏背景或填充。)
↓
路径规划器生成安全轨迹
第三步:NRMP 模块 - 规划运动轨迹 (Motion Planning)
逻辑:这是框架的“控制”核心。NRMP是一个模型预测控制器(MPC),它需要在一个优化问题中找到最优的动作序列。其巧妙之处在于,它不把成千上万个点级碰撞约束当作“硬约束”(这会使计算量爆炸),而是将从DUNE模块得到的LDFs作为一个**“神经正则化项”**(Neural Regularizer)加入到优化目标的成本函数中。
数据流:潜在距离特征 M, L + 机器人当前状态 st + 目标 s_goal → NRMP优化器 → 优化的未来状态和动作序列 {S̃, Ũ}。
PS:
1、神经正则化项:神经正则化项是通过在损失函数中添加惩罚项(如L1/L2、Dropout、标签平滑等),约束模型复杂度或引导学习特定结构,从而提升泛化能力、防止过拟合的关键技术。
通常神经网络训练时:总损失 = 任务损失(如轨迹跟踪误差) + λ·R(θ)
本文的创新点将 LDFs 替换传统的 R(θ),变成:总损失 = 轨迹跟踪误差 + λ·LDFs(轨迹点)
具体操作:
-
神经网络输出一条候选轨迹
-
用DUNE模块计算轨迹上每个点的LDF值
-
将LDF值作为惩罚项加入损失函数
-
反向传播时,梯度会“告诉”网络:避免进入LDF值低的区域
关键区别:传统正则化作用在模型参数上,这里作用在模型输出(轨迹)的几何性质上,是一种输出空间的正则化。
2、第二步与第三步的整体流程如下:

3、正则化
正则化是在原始目标函数(比如让轨迹到达目标)的基础上,加上一个额外的惩罚项。
-
原始目标:只关心结果(比如“到达目标点”)。这可能导致模型走极端(比如“穿墙而过”)。
-
正则化项:关心过程或代价(比如“路径必须平滑”或“远离障碍物”)。
-
总目标:在“到达目标”和“满足约束”之间找到平衡点。
在优化目标里加了一条“看不见的手”,用来惩罚你不希望出现的行为(如碰撞、过拟合),从而引导模型/系统找出更合理、更通用的解。
第四步:反馈与迭代 (Feedback & Iteration)
逻辑:NRMP规划出的新运动轨迹比之前的预测更优。因此,这个新的轨迹被反馈回第一步,用于生成更精确的点云流。
数据流:新运动轨迹{S̃, Ũ} → 更新为 {S[k+1], U[k+1]} → 返回第一步。
这个 预处理 -> DUNE -> NRMP -> 反馈 的循环会快速执行几次,每一次迭代都会让最终的动作决策更精确。
1.2.3 输出 (Outputs):
1.控制指令 (Control Command):在循环结束后,系统取出最终规划的动作序列 {S*, U*} 中的第一个动作 u*,并发送给机器人的底层控制器执行(例如,设定车轮速度和转向角)。
2.规划轨迹 (Planned Trajectory):完整的规划路径 {S*, U*} 可以用于可视化或调试。
1.2.4 sum up
上述内容流程如下图所示:

1.3 该算法与传统的区别
我觉得最大的区别在于传统的算法无法精准识别每个障碍物点与小车之间的距离,以及各个模块之间的误差累计,会导致一系列的决策失误以及延迟与实时性问题以及无法经过复杂狭窄等场景;导致最终的驾驶决策非常保守和笨拙。
而该算法是采用了点级约束,同时采用了神经网络加速计算,明确了小车与每个障碍物点之间的距离以及排斥,进而可以实现满足实时性的同时快速进行复杂狭窄环境的规划与避碰,进而完成整体的导航任务。
二、文章分析
——该部分参考链接:https://blog.csdn.net/u013010473/article/details/148555198
摘要
——在杂乱、未知的环境中导航非完整机器人需要精确的感知和精确的运动控制,以实现实时碰撞规避。本文提出NeuPAN:一个实时、高精度、无地图、易于部署且环境不变的机器人运动规划器。NeuPAN利用一个紧密耦合的感知-控制框架,与现有方法相比具有两个关键创新:1) 它将原始点云数据直接映射到一个潜在距离特征空间,用于生成无碰撞运动,避免了从感知到控制流程中的误差传播;2) 从端到端基于模型的学习角度来看,它是可解释的。NeuPAN的核心是使用一个即插即用(PnP)近端交替最小化网络(PAN)解决一个包含大量点级约束(点级约束 = 对“每一个点云中的点”都单独建立一个避碰约束)的端到端数学模型(点 → 高维几何信息 → 低维特征(LDF)),该网络在循环中加入了神经元(“神经元” = DUNE神经网络网络输出的结构化特征(LDFs),即一组可微、可学习的拉格朗日乘子(M, L))。这使得NeuPAN能够生成实时的、物理可解释的运动。它无缝集成了数据和知识引擎,其网络参数可以通过反向传播进行微调。我们在地面移动机器人、轮腿机器人和自动驾驶 汽车上,在广泛的模拟和真实世界环境中评估了NeuPAN。结果表明,NeuPAN在准确性、效率、鲁棒性和泛化能力方面,在包括杂乱沙箱、办公室、走廊和停车场在内的各种环境中均优于现有基准。我们展示了NeuPAN在未知和非结构化环境中对任意形状的物体同样有效,能将不可通行的路径转化为可通行路径。
关键字——直接点云机器人导航,基于模型的学习,基于优化的碰撞规避。
2.1 引言
在密集受限环境中进行实时机器人导航对于包括家庭机器人、物流和自动驾驶在内的广泛应用至关重要。与广阔开放的环境相比,前述的杂乱场景要求机器人的感知(即提供关于环境的必要信息)和运动(即计算连接当前和目标状态的一系列可行动作)在运动学约束下非常精确;否则,效率或安全性可能会受到极大影响。如果导航系统还需要在先前未见过的环境中正常工作,情况会变得更加复杂。
现有方法未能解决该问题的原因如下:1) 将高维传感器空间(例如,每秒海量点云)压缩到低维动作空间(例如,油门和转向)同时保证可解释性并防止误差传播是相当困难的[1], [2];2) 导航问题是PSPACE-hard问题,现有解决方案[3]–[5]必须在准确性和复杂性之间进行权衡,导致运动不精确,从而采取保守策略,或导致运动延迟,增加碰撞风险;3) 解决方案应稳定、完整且用户友好,仅需少量手工工程和对新机器人、新环境的再训练[6], [7]。上述系统、算法和工程问题使得仅利用板载计算资源在密集场景中导航成为一个长期存在的挑战。
为了解决这些问题,本文提出了NeuPAN,一种直接点云、端到端、基于模型的学习方法,旨在实现实时、高精度(例如,与最先进方法相比提升超过2倍)、无地图、易于部署且环境不变的碰撞规避。具体而言,我们的解决方案利用激光雷达(lidar)传感器提供障碍物点,因为它们能够提供直接、主动和精确的环境深度测量,并且对光照变化和运动模糊不敏感。基于激光雷达扫描的这些固有特性,并通过NeuPAN的赋能,一个轮腿机器人可以在没有先验地图的情况下穿越狭窄的间隙,同时避开任意形状的动态物体,如图1所示。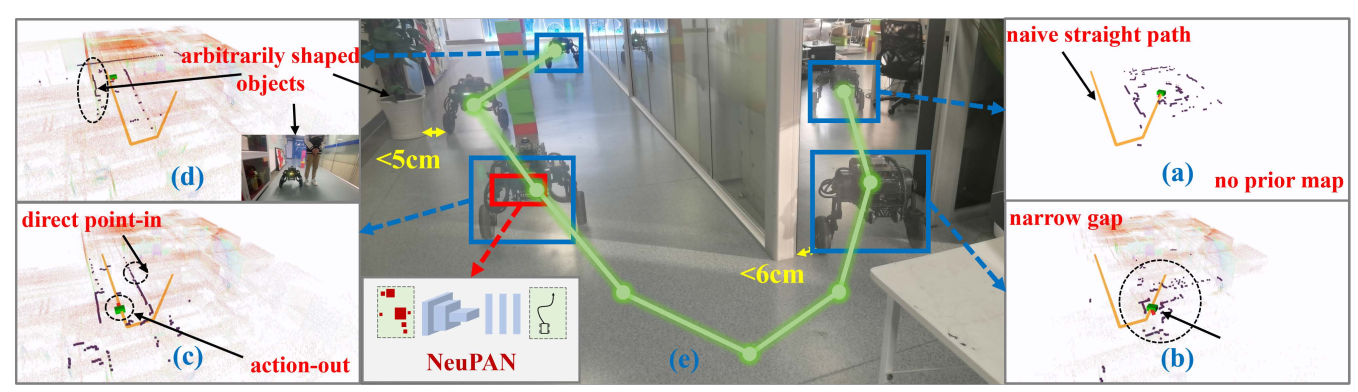
图1:由NeuPAN赋能的轮腿机器人在办公室中的无地图导航:(a) 机器人在没有先验地图的情况下沿朴素直线路径导航;(b) 机器人通过狭窄间隙(< 6 cm);© NeuPAN以高频方式采用“直接点云输入-动作输出”模式;(d) NeuPAN可以处理任意形状的(移动)物体。(e) 机器人轨迹。
我们系统的卓越性能主要归功于以下关键贡献:1) 与现有方法将点云转换为凸集或占用栅格图并采用非精确最小距离不同,NeuPAN直接处理海量原始点云,并基于预测的自身运动计算点流。然后,利用一个神经编码器 将点流映射到相应的潜在距离特征空间,该空间表示在后退时域内自身机器人到障碍物点的精确距离。2) 潜在距离特征作为范数正则化项无缝地融入运动规划器,添加到损失函数中,代表了远离障碍物的奖励。运动规划器生成的预测状态和动作被反馈回前端,用于重新计算点流。这在感知和控制之间形成了一个紧密耦合的循环。3) 为了更深入地理解NeuPAN,我们构建了一个带有逐点约束的端到端数学规划。我们证明了NeuPAN等效于使用即插即用(PnP)近端交替最小化(PAN)算法来解决此问题。据我们所知,这是首次从基于模型的学习角度来解释导航算法,从而将数据驱动系统与严谨的数学模型无缝集成。4) 我们进行了各种实验来评估所开发的NeuPAN系统的有效性。在各种模拟场景中的详尽基准比较表明,NeuPAN在成功率上始终更高,导航时间更短,优于最先进的机器人导航系统。最后,我们展示了NeuPAN在真实世界的动态、杂乱和非结构化环境(包括沙箱、办公室、走廊和停车场)中,在地面移动机器人、轮腿机器人和乘用自动驾驶汽车上的有效性。实验视频和更多细节可以在我们的项目页面上找到:https://hanruihua.github.io/neupan_project/。
本文的其余部分组织如下。第二部分回顾了相关工作。第三部分陈述了问题。第四部分描述了系统架构。随后,第五部分介绍了神经编码器网络和神经正则化运动规划器。第六部分展示了模拟和真实世界的实验。最后,第七部分总结了本文。
2.2 相关工作
A. 模块化 vs. 端到端
模块化方法将导航分为不同的模块(例如,在最简单的情况下是一个物体检测器和一个运动规划器),由于其可靠性和易于调试的特性,是目前被最广泛采用的框架[8]–[10]。然而,这些方法会遭受从感知到控制模块的误差传播:1) 在前端感知层,即使是最好的检测器生成的检测对象表示(例如边界框)也可能与真实情况存在偏差,这需要在运动规划器中加入更大的安全距离以保证最坏情况下的碰撞规避;2) 在中间表示层,边界框或凸集无法精确匹配可能具有任意非凸形状的真实世界物体;这些在各个层级中的误差会累积到导航流程中,使得模块化方法在杂乱环境中容易陷入困境。
为了减轻模块化方法固有的误差传播,最近的机器人导航正经历着向端到端方法的范式转变,该方法直接将传感器输入映射到运动输出[7], [11], [12]。早期的端到端解决方案专注于使用单个黑箱深度神经网络(DNN)来学习映射,但后来发现其难以训练且不具备对未见场景的泛化能力。新兴的端到端方法采用多个模块,但在三个方面与模块化方法不同:1) 它交换的是特征(例如编码器输出),而不是显式表示(例如边界框);2) 模块间的交互是双向的,而不是单向的;3) 整个系统可以以端到端的方式进行训练。这种广义的端到端方法在基于视觉的自动驾驶和基于编码器的机器人操纵中已显示出有效性。例如,统一自动驾驶(UniAD)框架由骨干、感知、预测和规划模块组成,任务查询作为连接每个节点的接口[13]。
大多数行业实践已将端到端方法应用于自动驾驶任务,利用视觉Transformer生成鸟瞰图(BEV)[14]进行占用地图绘制[15],直接用于后续规划。类似的见解也已在机器人操纵中获得,这可以通过一个由神经编码器和运动规划器组成的运动规划网络(MPNet)来完成[16]。这些纯数据驱动技术的局限性在于其缺乏可解释性。这使得为新的机器人平台调整网络参数变得困难。当泛化到新环境时,它们通常需要大量的手工工程和长时间的训练,并且通常需要配合其他保守策略来保证安全。这些方法也需要大量的数据收集和标注工作。
B. 基于模型 vs. 基于学习
算法决定了模块化或端到端框架中每个模块的推理映射。现有算法可分为基于模型和基于学习两类。
基于模型的算法利用代表底层物理、先验信息和领域知识的数学或统计公式。经典的基于模型的算法包括基于图搜索、基于采样和基于优化的方法。基于图搜索的技术,如A*,将配置空间近似为离散的网格空间,以搜索成本最小的路径[17]。基于采样的技术,如快速探索随机树(RRT)或RRT*,使用采样策略探测配置空间[18]。快速似然碰撞规避方法(Falco)[19]通过最大化达到目标的似然性来确定下一个导航动作。基于优化的技术通过在动力学和运动学约束下最小化成本函数来生成轨迹[1], [9]。
在密集场景导航的背景下,基于优化的技术,如模型预测控制(MPC),因其能够计算当前最优输入以在未来产生最佳行为而更具吸引力,从而产生高性能的轨迹。基于优化的技术的一个主要缺点是其计算成本高,这限制了它们的实时应用。特别地,碰撞规避约束的数量与障碍物的数量(空间上)和后退时域的长度(时间上)成正比。在杂乱的环境中,如果还考虑障碍物的形状,计算时间将进一步乘以每个障碍物的表面数量。为了克服非凸碰撞规避约束,文献[1]中为全形状控制对象开发了基于优化的碰撞规避(OBCA)算法,该算法采用对偶性来重新表述基于精确距离的碰撞规避约束。此外,全形状机器人导航通过时空分解算法在[20]中得到进一步加速。然而,当处理数十个物体时,这些算法的频率并不令人满意。另一方面,大多数现有工作放弃了精确距离,而采用非精确的距离,如中心点距离、近似符号距离或时空走廊[21], [22]。此外,可以将硬约束转换为软正则化项以加速,如EGO规划器所示,它通过增加惩罚项来移除碰撞规避约束[23]。虽然非精确算法实现了高频率(例如,高达100 Hz),但它们不适用于密集场景导航,如第一部分所述。
与基于模型的方法相比,学习算法通过从数据中提取特征而无需分析模型。这在分析模型未知的复杂系统中尤其有用。因此,学习算法对于端到端导航任务很有前景。在这个方向上,强化学习(RL)是一个主要范式[26]。RL的思想是通过与环境交互并最大化累积动作奖励来学习一个神经网络策略[27]。特别地,RL已广泛用于动态碰撞规避(所谓的CARL-based方法),其中障碍物的运动信息直接映射到机器人动作,例如CADRL [28], LSTM-RL [29], SARL [6], RGL [30], 和AEMCARL [24]。然而,RL-based方法的性能受训练数据集分布的影响。因此,这些方法在模拟中很有前景,但在真实世界设置中实现通常具有挑战性。此外,为密集场景导航找到一个合适的奖励函数通常很困难。
如第II-A节所述,基于学习的算法缺乏可解释性。因此,一个新兴的范式涉及基于模型和基于学习算法的交叉融合。这导致了机器人导航中各种基于模型的学习方法。具体来说,一种直接的方法是使用学习算法来模仿复杂的动力学或数值程序,通过将迭代计算转换为前馈过程。这是通过使用DNN从求解器的演示中学习来实现的。例子包括[31]中的神经PID和[32]中的神经MPC。另一方面,基于学习的算法被用来生成候选轨迹,减少后续基于模型算法的解空间,例如,MPNet [16], MPC-MPNet [25], NFMPC [33], 和MPPI [34]。注意,轨迹生成通常是从经典采样方法中学到的。最后,学习算法可以用于调整基于模型算法中涉及的超参数。例如,MPC的成本和动力学项可以通过对策略函数关于优化问题进行参数微分来学习[35], [36]。
我们的框架NeuPAN也属于基于模型的学习方法。然而,与上述部分可解释的工作相比,NeuPAN从感知到控制是端到端可解释的。这是通过使用PnP PAN解决一个具有大量点级约束的端到端优化问题来实现的。这使得NeuPAN适用于具有非完整机器人的密集场景碰撞规避,而现有结果[7], [22], [23]通常考虑完整无人机或在开放场景中的非完整机器人。与[35], [36]类似,NeuPAN中的成本和约束参数可以通过函数微分以端到端的方式进行训练。因此,NeuPAN具有易于部署和环境不变的特性。
C. 与现有解决方案的全面比较
[TABLE CONTENT: A table comparing NeuPAN with other navigation approaches like TEB, OBCA, RDA, etc., across various characteristics.]
表 I:NeuPAN与现有导航方法的特性比较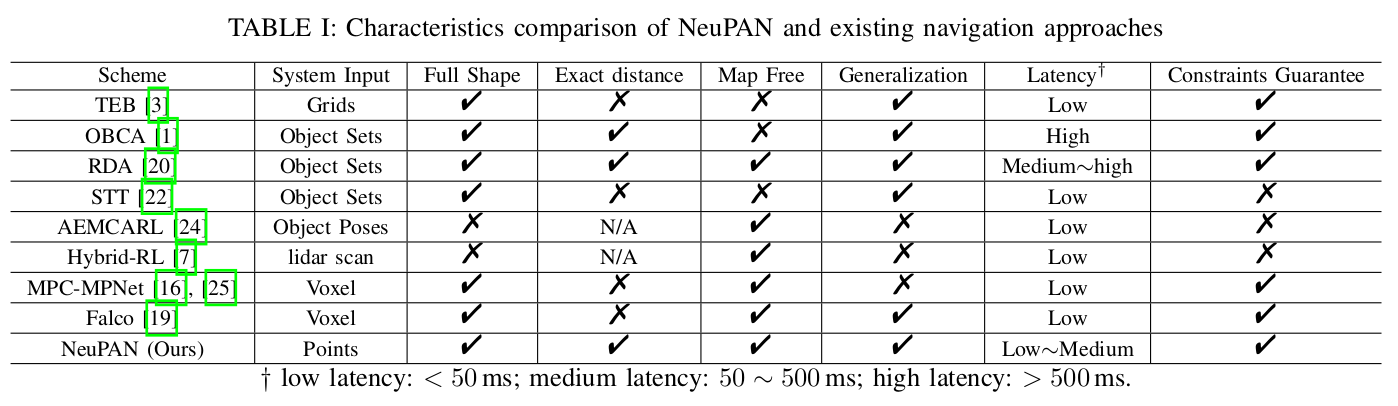
表 I 提供了与著名导航方法的全面比较。特别地,TEB [3], OBCA [1], RDA [20], STT [22], AEMCARL [24], 和Falco [19]是模块化方法。它们的输入是栅格、姿态、边界框或集合,这些都是由预先建立的栅格地图或前端物体检测器生成的。所有这些方法都涉及误差传播。与将自身机器人视为一个点(或球)的AEMCARL不同,TEB, OBCA, RDA, STT和Falco考虑了自身机器人和障碍物的形状。然而,TEB, STT和Falco在计算距离时涉及近似。OBCA和RDA是最精确的方法,但需要高计算延迟,例如,高达秒级(即小于1Hz)。另一方面,Hybrid-RL [7], MPC-MPNet [25], 和NeuPAN(我们的方法)是端到端方法。通过将原始激光雷达点作为输入,这些方法没有误差传播。Hybrid-RL采用单个网络进行点输入和动作输出。尽管其集成度高,Hybrid-RL的泛化能力较差。MPC-MPNet和NeuPAN采用两个网络,一个用于编码,另一个用于规划:MPC-MPNet使用神经编码器将点映射到体素特征;NeuPAN使用神经编码器将点和预测的自身运动映射到潜在距离特征。它们都考虑物体的形状;然而,由于从点到体素的离散化,MPC-MPNet无法计算两个形状之间的精确距离。它们也缺乏泛化性,因为轨迹生成器是场景依赖的,需要为新机器人重新训练。我们的NeuPAN克服了这些缺点,代价是计算负载略高。
NeuPAN是第一个构建端到端数学模型(即点云输入和动作输出)并使用基于模型的学习来解决它的方法。因此,NeuPAN是完全可解释的。由于这一新特性,NeuPAN能实时生成非常精确、端到端、物理可解释的运动。这使得自主系统能够在密集的非结构化环境中工作,这些环境以前被认为是不可通行的,不适合自主操作,从而催生了新的应用,如杂乱房间的管家和有限空间的停车。与现有的端到端方法[7], [11]–[16]相比,NeuPAN提供了数学保证,并导致更低的不确定性和更高的泛化能力。与现有的基于模型的运动规划方法[1], [16], [20], [22]相比,NeuPAN更精确,因为传统的运动规划属于模块化方法,并涉及误差传播。也存在其他用于机器人导航的基于模型的学习方法[16], [31]–[34]。然而,这些方法不是端到端的,例如,[31], [32]考虑状态输入动作输出,[16], [33], [34]考虑点云输入轨迹输出。文献[25]通过将[16]与后端控制器桥接来考虑点云输入动作输出。然而,这样的桥接失去了数学保证,不再解决固有的端到端模型。方法[16], [25]也利用像Transformer这样的神经编码器来压缩传感器数据,而这种神经编码器没有可解释性。
2.3 问题陈述
我们考虑一种基于模型预测控制(MPC)框架,针对全维度机器人,采用点云输入、动作输出的端到端导航方法。为了通过一个控制序列达到目标状态,在每个时间步t,都会迭代地解决一个在后退时域H = t , . . . , t + H 上的感知-控制优化问题。
1) 机器人运动学: 给定控制向量ut,当前状态st和后续状态st+1应遵循离散时间运动学模型:

2) 机器人模型: 自身机器人在坐标系原点所占用的空间可以用一个紧凸集C来表示。基于锥不等式表示[37],C由下式给出:




2.4 NEUPAN系统架构
为了保留关于环境最准确、完整和密集的信息,我们建议直接处理Pt,从而实现一种用于非结构化和未知环境的端到端感知-控制方法。系统架构如图2所示。下面,我们首先介绍NeuPAN背后的数学解释。然后我们提供系统的详细描述。



注:Q1与Q2交替求解,即Q1更新M/L到Q2,Q2更新状态S/U到Q1;
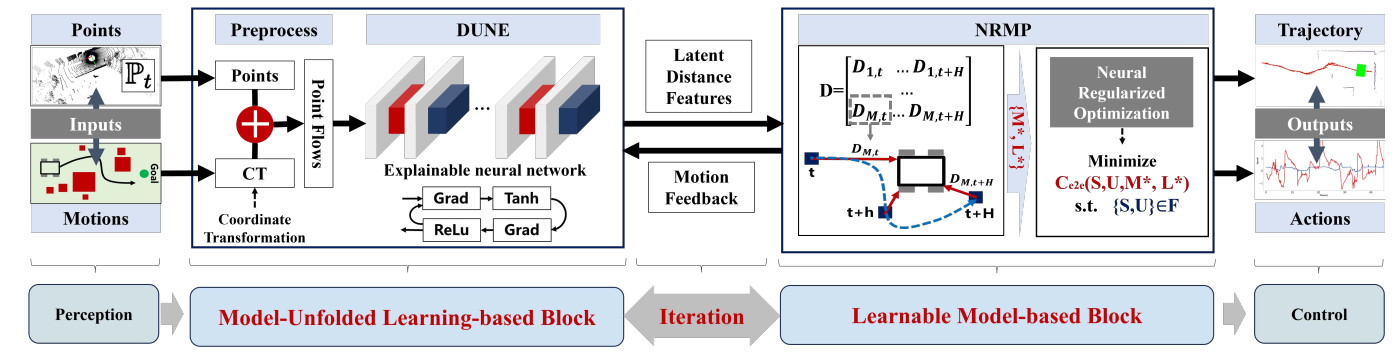

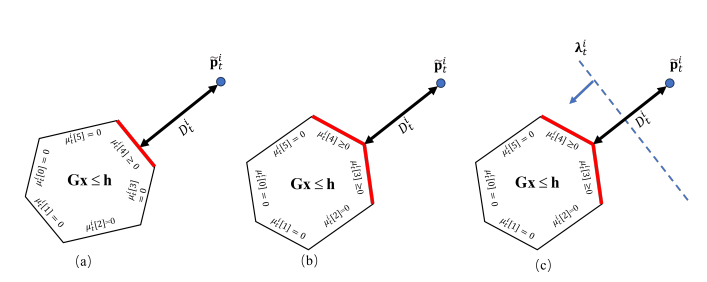
图3:LDFs M和L的几何解释。红边表示离障碍物点最近的机器人边。λ表示分离超平面的法向量。μᵢ中值为正的元素表示与碰撞相关的红边。
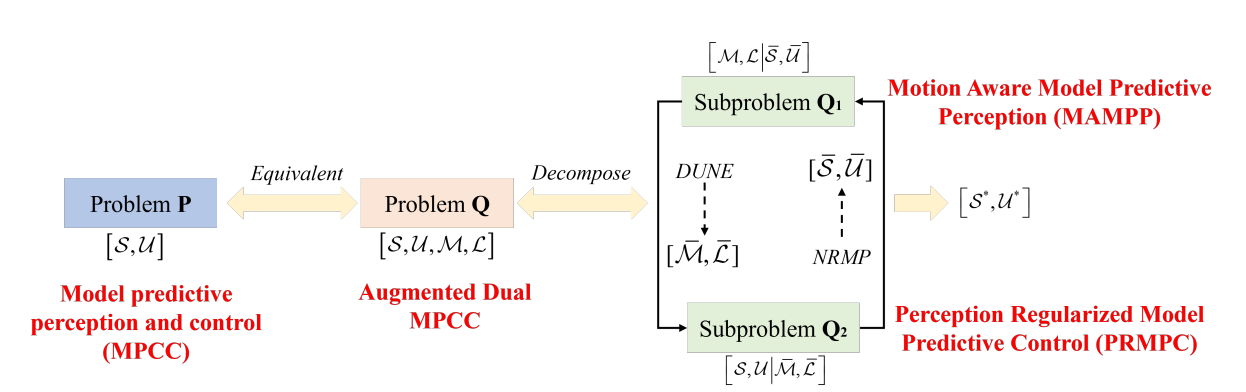
图4:问题P, Q, Q1和Q2之间的关系。

Pt与Vt:在全局坐标系下估计障碍物真实速度,在局部坐标系下使用相对位置与相对速度进行控制决策。
“后退时域”就是 MPC 中那个不断向前滚动、每次只规划未来一段时间的有限长窗口。


2.5 NEUPAN编码器和规划器设计

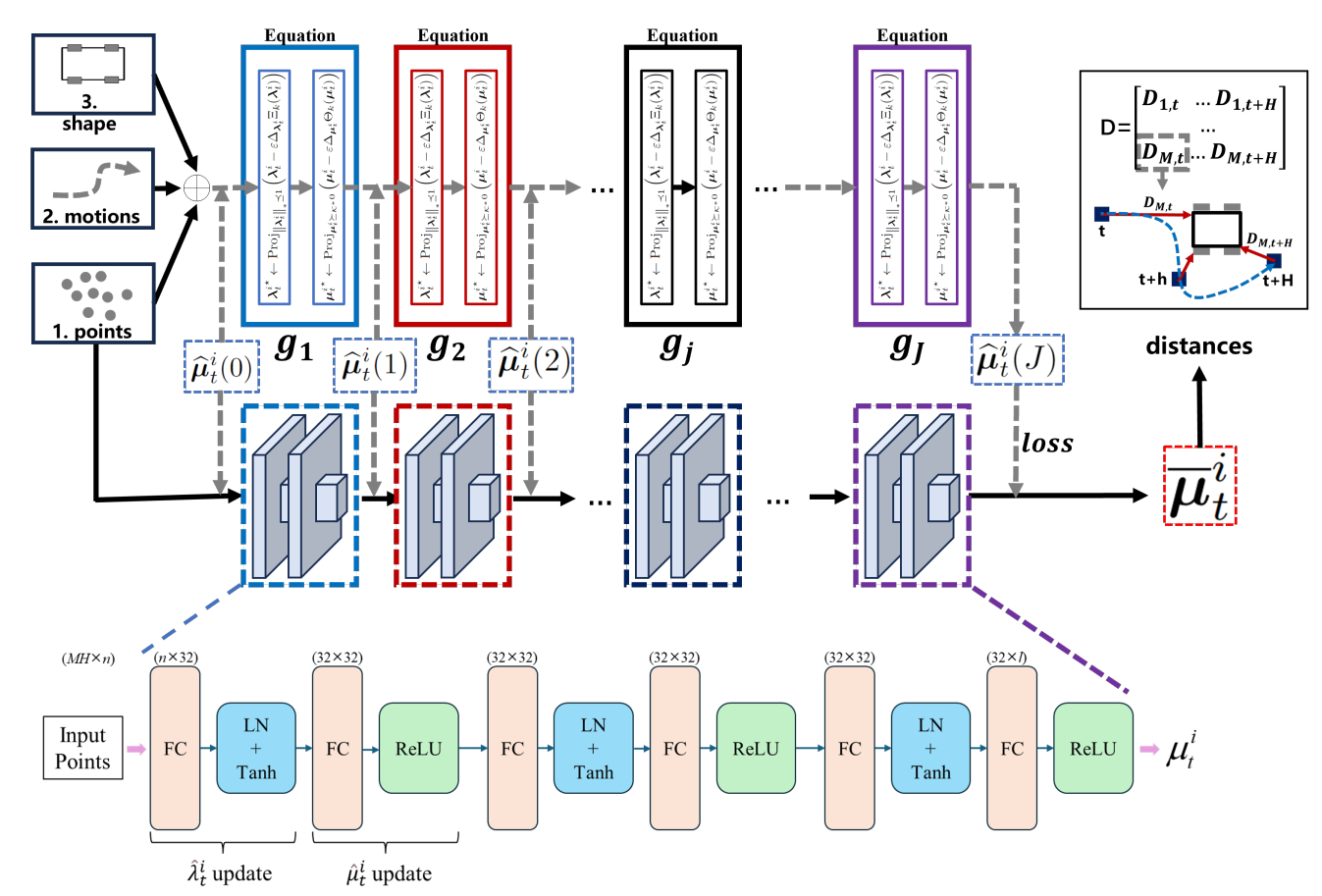
图5:DUNE的结构,它展开了PIBCD算法。DUNE是可解释、简单且训练快速的,并且可以在各种场景中部署而无需重新训练,只要机器人的形状保持不变。





即构建基于优化求解生成的监督数据集,通过神经网络学习空间状态与最优控制参数之间的映射关系,从而实现优化过程的快速近似推理。
PIBCD 是一种求解凸优化问题的经典迭代算法,NeuPAN 将其核心迭代步骤“展开”成可解释的神经网络 DUNE;



M 和 L 不是 NRMP 的硬约束,而是通过正则化项 Cr(S,M,L)软性地引导优化解避开障碍物。








2.6 实验
三、算法项目分析
1 项目概述
NeuPAN (Neural Proximal Alternating-minimization Network) 是一个端到端、实时、无需预建图且易于部署的基于模型预测控制(MPC)的机器人运动规划器。该项目由香港大学 Ruihua Han 团队开发,相关论文已发表在 IEEE Transactions on Robotics (T-RO) 2025。
1.1 核心创新
NeuPAN 通过融合学习-based 和优化-based 技术,将障碍物点云数据直接映射为控制指令,实现了在杂乱和未知环境中的高效安全导航。
1.2 项目特点
特性 说明
端到端 无需中间模块设计,避免误差传播
实时性 CPU 环境下可达到 15Hz 以上的控制频率
无需地图 直接处理障碍物点云,无需预建图
易部署 训练一次即可应用于各种环境
安全保证 通过数学优化约束保证碰撞避免
2 项目结构分析
NeuPAN/
├── neupan/ 核心算法库
│ ├── __init__.py
│ ├── neupan.py 主类,用户接口
│ ├── blocks/ 核心算法模块
│ │ ├── pan.py PAN(近端交替最小化网络)
│ │ ├── nrmp.py NRMP(神经正则化运动规划器)
│ │ ├── dune.py DUNE(深度展开神经编码器)
│ │ ├── dune_train.py DUNE 模型训练
│ │ ├── obs_point_net.py 观测点网络
│ │ └── initial_path.py 初始路径生成
│ ├── robot/ 机器人模型
│ │ └── robot.py 运动学模型和约束
│ ├── configuration/ 配置模块
│ └── util/ 工具函数
├── example/ 示例和实验(单纯基于ir-sim仿真环境来测试不同场景下的neupan效果)
│ ├── run_exp.py 统一实验入口
│ ├── corridor/ 走廊环境
│ ├── dyna_obs/ 动态障碍物
│ ├── convex_obs/ 凸障碍物
│ ├── dune_train/ 模型训练
│ └── model/ 预训练模型
├── pyproject.toml 项目配置
└── README.md 项目文档
3 核心模块详解
3.1 算法架构
NeuPAN 的核心算法由 PAN (Proximal Alternating-minimization Network) 实现,包含两个主要组件:
PAN
├── DUNE (Deep Unfolded Neural Encoder)
│ └── ObsPointNet (神经网络)
│
└── NRMP (Neural Regularized Motion Planner)
└── CVXPY (凸优化求解器)
3.2 主类 (neupan.py)
主类 neupan 是整个库的入口点,封装了 PAN 算法并提供用户友好的接口:
核心功能:
- 从 YAML 配置文件初始化规划器
- 处理激光雷达等传感器数据
- 执行路径规划并返回控制命令
- 支持多种运动学模型的机器人
关键参数:
neupan(
receding=10, # MPC 预测视界步数
step_time=0.1, 时间步长
ref_speed=4.0, 参考速度
device='cpu', 计算设备
robot_kwargs={}, 机器人参数
ipath_kwargs={}, 初始路径参数
pan_kwargs={}, PAN 算法参数
adjust_kwargs={}, 调整参数
)
3.3 机器人模型 (robot.py)
robot 类定义了机器人的运动学模型,是规划算法的基础。
支持的运动学模型:
模型 说明 控制输出
diff 差分驱动 [v, ω] 线速度、角速度
acker 阿克曼转向 [v, δ] 线速度、转向前角
omni 全向移动 [vx, vy] X/Y 方向速度
核心功能:
- 定义状态转移矩阵(A, B, C)
- 生成运动约束(速度、加速度限制)
- 计算机器人碰撞几何(顶点、半平面表示)
3.4 PAN 算法 (pan.py)
PAN 是核心规划算法,通过迭代交替最小化解决优化问题:
for i in range(iter_num):
# 1. DUNE 层:处理障碍物点云
point_flow_list, R_list, obs_points_list = generate_point_flow(...)
mu_list, lam_list, sort_point_list = dune_layer(...)
# 2. NRMP 层:求解优化问题
nom_s, nom_u, nom_distance = nrmp_layer(...)
# 3. 收敛检查
if stop_criteria(...):
break收敛判断条件:

3.5 DUNE 模块 (dune.py)
DUNE (Deep Unfolded Neural Encoder) 负责将障碍物点云映射到潜在距离空间:
核心网络结构(ObsPointNet):
输入: point_flow (N, 2) - 机器人坐标系下的点云
↓
MLP: Linear(2, 64) → ReLU → Linear(64, 128) → ReLU → Linear(128, edge_dim)
↓
输出: mu (edge_dim, N) - 潜在距离特征关键概念:
- G, h: 机器人半平面表示 (Gx ≤ h)
- mu: 学习的潜在距离权重
- lam = -R @ G.T @ mu : (公式)转换到全局坐标系
NeuPAN 中的 DUNE 网络将“每个障碍物点到机器人形状的最小距离计算”这一复杂的凸优化问题,通过深度展开技术转化为一个轻量级的前馈神经网络。该网络直接以原始点云坐标作为输入,每一层模拟 PIBCD 优化算法中的一步梯度下降与投影操作:第一类全连接层配合 Tanh 更新拉格朗日乘子 λ(即分离超平面的法向量),第二类全连接层配合 ReLU 更新拉格朗日乘子 μ(即标识机器人最近边的激活向量)。经过固定次数(如 3 次)的交替迭代后,网络并行输出所有点对应的 (μ, λ) 对,即潜在距离特征 (M, L)。由此,成千上万个点的几何约束被高效地编码为这些拉格朗日乘子的数值,为后续的运动规划提供了精确且稀疏的避障信息。

3.6 NRMP 模块 (nrmp.py)
NRMP (Neural Regularized Motion Planner) 解决凸优化问题:
- fa = lam.T
- fb = (lam.T @ point) + (mu.T @ h)fa 和 fb 是 NRMP 模块中用于构建障碍物安全距离约束的系数;
优化目标:
min ||q_s * state - q_s * ref_state||² 状态跟踪成本
+ ||p_u * control - p_u * ref_speed||² 控制跟踪成本
+ η * Σ distance 安全距离成本
+ 0.5 * bk * ||state - nom_state||² 近端成本约束条件:
- 动力学约束:x_{t+1} = A_t x_t + B_t u_t + C_t
- 速度约束:|u| ≤ u_max
- 加速度约束:|u_t - u_{t-1}| ≤ a_max
- 安全距离约束:d_min ≤ distance ≤ d_max

4 example项目分析
4.1 example目录结构
example/
├── run_exp.py 统一入口
├── corridor/ 走廊避障
│ ├── diff/, acker/, omni/
│ ├── env.yaml 环境配置
│ └── planner.yaml 规划器配置
├── dyna_obs/ 动态障碍物
├── convex_obs/ 凸形状障碍物
├── non_obs/ 无障碍物
├── pf/ 路径跟踪
├── polygon_robot/ 多边形机器人
├── reverse/ 倒车场景
├── dune_train/ DUNE 训练(单纯)
└── model/ 预训练模型
├── diff_robot_default/
├── acker_robot_default/
└── polygon_robot/
4.2 配置文件格式
环境配置 (env.yaml):
world:
height: 42
width: 42
step_time: 0.1
collision_mode: 'stop'robot:
- kinematics: {name: 'diff'}
shape: {name: 'rectangle', length: 1.6, width: 2.0}
state: [10, 42, 1.57]
goal: [40, 40, 0]
sensors:
- type: 'lidar2d'
range_max: 10
angle_range: 3.1415926
number: 100
规划器配置 (planner.yaml):# MPC 基础配置
receding: 10
step_time: 0.1
ref_speed: 4
device: 'cpu'# PAN 算法配置
pan:
iter_num: 2
dune_max_num: 100
nrmp_max_num: 10
dune_checkpoint: 'example/model/diff_robot_default/model_5000.pth'# 调整参数
adjust:
q_s: 1.0
p_u: 1.0
eta: 15.0
d_max: 1.0
d_min: 0.1
4.3 运行示例
# 基本运行
python run_exp.py -e corridor -d diff# 带动画保存
python run_exp.py -e dyna_obs -d omni -a# 动态障碍物场景
python run_exp.py -e dyna_obs -d diff -v -m 500
实验类型对比:
实验类型 障碍物类型 动态 主要测试
corridor 静态矩形 否 狭窄通道避障
convex_obs 圆形/多边形 否 凸形状障碍物
dyna_obs 圆形 是 移动障碍物避让
non_obs 无 否 纯路径跟踪
pf 无 否 路径跟踪精度
polygon_robot 多种 可选 自定义形状
5 技术栈与依赖
5.1 核心依赖
依赖库 版本 用途
torch ≥2.1.0 深度学习框架
cvxpylayers - CVXPY 与 PyTorch 接口
cvxpy - 凸优化建模
ecos - 优化求解器
numpy - 数值计算
pyyaml - 配置文件解析
ir-sim ≥2.4.0 仿真环境(可选)
5.2 项目配置 (pyproject.toml)
[project]
name = 'neupan'
version = "1.3"
requires-python = ">= 3.10"
dependencies = [
'cvxpylayers',
'numpy',
'scipy<=1.13.0',
'torch>=2.1.0',
'ecos',
'pyyaml',
][project.optional-dependencies]
irsim = ['ir-sim>=2.4.0']
6 工作流程
6.1 规划器初始化
from neupan import neupan
# 方式1:从代码初始化
planner = neupan(
receding=10,
step_time=0.1,
robot_kwargs={'kinematics': 'diff', 'length': 1.6, 'width': 2.0}
)
# 方式2:从 YAML 初始化
planner = neupan.init_from_yaml('planner.yaml')
6.2 主循环
for i in range(max_steps):
# 1. 获取传感器数据
robot_state = env.get_robot_state()
lidar_scan = env.get_lidar_scan()
# 2. 转换激光雷达数据为点云
points = planner.scan_to_point(robot_state, lidar_scan)
# 3. 执行规划
action, info = planner(robot_state, points)
# 4. 可视化(可选)
env.draw_points(planner.dune_points, s=25, c="g")
env.draw_trajectory(planner.opt_trajectory, "r")
# 5. 执行控制
env.step(action)
7 与其他方案的对比
方面 传统模块化规划器 (TEB/DWA) 端到端学习 (RL/IL) NeuPAN
架构 多模块流水线 端到端策略网络 端到端,无中间模块
环境处理 受限于地图表示 依赖训练环境 直接处理障碍物点云
训练数据 无(规则驱动) 大量数据 少量数据(随机点云)
训练时间 无 数小时到数天 1-2 小时(CPU)
泛化能力 无需训练 常需重训练 一次训练,多场景应用
安全性 依赖精确感知 无正式保证 数学优化约束
部署 复杂集成 黑盒,难调试 易于部署
8 整体运行步骤
8.1 NeuPAN(非py38)的ir-sim例子运行步骤
1、下载miniconda3
2、
创建 neupan 环境
conda create -n neupan python=3.10 -y激活并使用
conda activate neupan# Install NeuPAN
git clone https://github.com/hanruihua/NeuPAN
cd ~/NeuPAN
pip install .或者pip install -e .3、
# Install IR-SIM for running examples
pip install ir-sim4、
# Run your first example(仿真例子)
cd example
python3 run_exp.py -e corridor -d diff
5、可根据机器人尺寸重新修改(差速/阿克曼)
/home/shaoyu/NeuPAN/example/dune_train/dune_train_diff.yaml进行python3 /home/shaoyu/NeuPAN/example/dune_train/dune_train_diff.py进行DUNE模型的训练
8.2 NeuPAN的ros版本运行步骤
1、安装依赖包以及编译
{- rvo_ros - 用于生成动态障碍物
- limo_ros - LIMO机器人模型
- neupan -neupan规划器
}
cd ~/neupan_ws/src/
sh gazebo_example_setup.sh
git clone https://github.com/hanruihua/NeuPAN3.8.git(py3.8版本,不需要conda虚拟环境)
cd ~/NeuPANpy38
pip install .或者pip install -e .cd ~/neupan_ws && catkin_make
2、配置环境变量
cd ~/neupan_ws/src/neupan_ros
sh source_setup.sh
3、启动
3.1 一键启动
cd ~/neupan_ws/src/neupan_ros/example/gazebo_limo
./run_neupan_gazebo_exp.sh
3.2 分布启动
# 终端1:启动Gazebo仿真环境和动态障碍物
roslaunch neupan_ros gazebo_limo_env_complex_20.launch
# 终端2:启动NeuPAN控制器
roslaunch neupan_ros neupan_gazebo_limo.launch
4、离线路径方式
1)发布到 /initial_path 话题,写一个path.py脚本发布
启动时设置 refresh_initial_path: true ,然后通过话题动态发布你的路径。
2)使用 /neupan_waypoints 话题,写一个path.py脚本发布
3)使用 /neupan_goal 话题,直接用rviz的2D nav goal
neupan_planner_limo.yaml 文件中的loop设置成false ,就不能使用rviz的2D goal去设置终点,因为此时设置为false相当于走完初始路径就到达终点了,如果你重新设置goal,就会导致gazebo的模型崩溃。
9 总结
NeuPAN 代表了机器人路径规划领域的前沿技术,通过创新性地结合深度学习和优化方法,实现了高效、鲁棒、安全的实时路径规划。其模块化设计和配置文件机制使其易于使用和定制,为自主机器人的导航能力提供了有力支持。
相关链接:
- 项目主页:https://hanruihua.github.io/NeuPAN/
- 论文链接:https://arxiv.org/pdf/2403.06828.pdf
- ROS 封装:https://github.com/hanruihua/neupan_ros
四、训练与部署
参考链接:
1、概述
- NeuPAN 的 DUNE(Deep Unfolded Neural Encoder)模块将障碍点映射到潜在距离特征(latent distance feature,mu),供后端 NRMP 优化层(基于 cvxpy)使用。
- DUNE 训练是“纯离线”的数学训练过程,不依赖物理仿真或传感器数据;训练标签通过求解凸优化问题自动生成。
- LON(Learning to Optimize NeuPAN)是可选的仿真驱动参数调优流程,用于在特定场景中自动调优 adjust 参数以提升导航效果。LON 依赖仿真(例如 ir-sim)。
2、训练方法
2.1 DUNE 模型训练(纯离线)
-
核心目标:学习从单点坐标 p -> 对应的 mu,以及与之对应的 distance,使得神经网络输出的 mu 在后续优化中产生正确的避障约束/代价。
-
训练流程(步骤化):
- 准备机器人几何:配置机器人凸形几何(
vertices或length,width,wheelbase),由此生成不等式矩阵 G、h(Gx <= h)。几何必须为凸多边形,非凸需用凸包近似。- 配置训练超参数:在
train配置段设置data_size,data_range,batch_size,epoch,lr等。- 数据生成(完全离线):
- 在指定的二维范围
data_range内随机采样点 p(2D)。- 对每个 p,使用 cvxpy 求解凸优化问题得到最优 mu 和 distance(标签由数学求解得到,不依赖仿真)。
- 代码参考:
DUNETrain.generate_data_set()(neupan/blocks/dune_train.py 中,大约在 109-132 行)。- 网络训练:
- 模型:
ObsPointNet(MLP,hidden_dim=32),见neupan/blocks/obs_point_net.py。- 优化器:Adam(默认 lr=5e-5 等,详见 train 配置)。
- 损失项:mu MSE、distance MSE、fa(lam 相关)与 fb(muTh + lam^Tp 相关)四项综合损失,保障几何一致性。
- 训练入口:DUNETrain.start()(在
dune_train.py中)。- 保存模型:训练期间按
save_freq保存.pth模型文件,并记录训练日志(results.txt)、loss(loss.pkl)等。
- 训练命令
根据机器人尺寸重新修改(差速/阿克曼)
~/NeuPAN/example/dune_train/dune_train_diff.yaml首先进行neupan的编译:
cd ~/catkin_neupan/src/neupan_ros/src/NeuPAN-py38
首先修改一下pyproject.toml文件,将 Python 版本要求从 >=3.10 改为 >=3.8 。
pip install -e .
python3 ~/NeuPAN/example/dune_train/dune_train_diff.py
-
特点与优势:
- 完全数学驱动,标签来源清晰可复现;
- 一次训练针对机器人几何生效,环境变化(障碍分布)通常不需要重训;
- 训练不依赖传感器噪声或光照等现实因素(因其学习的是几何约束)。
2.2 LON 参数调优(可选)
- 目的:在具体仿真场景中使用在线/仿真数据来自动调优 NRMP 的 adjust 参数(如 q_s、p_u、eta、d_max、d_min),以提升规划在该场景下的性能(轨迹误差、速度误差、碰撞约束代价等)。
- 依赖:需要仿真环境(例如 ir-sim)来采集场景执行结果作为优化目标。通常 LON 运行时间短(示例 10–30 分钟,视场景与设置而定)。
- 输出:优化后的配置文件(YAML),例如
planner_0.1.yaml、planner_0.2.yaml等,包含新的 adjust 参数。可将其复制或合并到生产配置中使用。 - 说明:LON 是可选手段,不是运行 NeuPAN 的前置需求。若默认参数表现良好,完全可以跳过 LON。
LON训练步骤
LON(Learning to Optimize NeuPAN)训练通过ir-sim仿真环境自动调优NeuPAN的adjust参数。
快速开始
# 进入LON训练目录
cd example/LON
# 运行LON训练
python3 LON_corridor_02.py
详细训练流程
1. 准备工作
确保已安装ir-sim并存在预训练的DUNE模型:
# planner.yaml中指定DUNE模型路径
pan:
dune_checkpoint: 'example/model/diff_robot_default/model_5000.pth'planner.yaml:29-35
2. 初始化环境和规划器
env = irsim.make(display=True)
neupan_planner = neupan.init_from_yaml('planner_0.2.yaml')LON_corridor_02.py:6-7
3. 选择要优化的参数
从adjust参数中选择需要优化的参数(通常优化p_u、eta、d_max):
q_s_tune = neupan_planner.adjust_parameters[0]
p_u_tune = neupan_planner.adjust_parameters[1]
eta = neupan_planner.adjust_parameters[2]
d_max = neupan_planner.adjust_parameters[3]
d_min = neupan_planner.adjust_parameters[4]
opt = torch.optim.Adam([p_u_tune, eta, d_max], lr=5e-3)LON_corridor_02.py:116-122
4. 训练循环
运行多个epoch的仿真训练:
for epoch in range(epoch_num):
total_loss, arrive = train_one_epoch(max_steps=600, render=True)
print(f'Epoch: {epoch:02d} Total Loss: {total_loss:.3f}')
if total_loss < 0.1 and arrive:
breakLON_corridor_02.py:129-137
5. 损失计算
每个仿真步骤计算损失并反向传播:
def cal_distance_loss(distance, min_distance, collision_threshold, stuck):
if min_distance < collision_threshold + 0.1:
distance_loss = 50 - torch.sum(distance)
elif stuck:
distance_loss = 50 + torch.sum(distance)
else:
distance_loss = torch.tensor(0.0, requires_grad=True)
return distance_lossLON_corridor_02.py:10-19
训练结果
训练完成后,优化后的参数会保存在新的YAML文件中:
原始参数(planner.yaml):
adjust:
p_u: 2.0
eta: 10
d_max: 0.2planner.yaml:37-45
优化后参数(planner_0.1.yaml):
adjust:
p_u: 1.774
eta: 10.236
d_max: 0.415planner_0.1.yaml:37-44
训变体
LON提供三个训练脚本变体:
-
LON_corridor.py- 基础版本 -
LON_corridor_01.py- 增加噪声处理 -
LON_corridor_02.py- 调整碰撞阈值和损失策略
Notes
-
训练时间:约10-30分钟
-
需要ir-sim仿真环境
-
DUNE模型在训练中保持冻结状态
-
优化参数针对特定场景,其他场景可能需要重新训练
3、DUNE 训练解释(代码位置与运行方式)
-
关键源码文件与类:
- 训练类(数据生成、标签、训练主流程):
neupan/blocks/dune_train.py(类DUNETrain,关键方法:construct_problem、prob_solve、generate_data_set、start、train_one_epoch)。
- 注:标签求解(cvxpy)关键步位于
prob_solve(),并被generate_data_set()用于每个随机点。- DUNE 层封装(加载/触发训练):
neupan/blocks/dune.py(类DUNE,当 checkpoint 缺失时可调用train_dune());DUNE.train_dune()内部会创建DUNETrain(self.model, self.G, self.h, checkpoint_path)并调用start(**train_kwargs)。- 网络结构:
neupan/blocks/obs_point_net.py(类ObsPointNet,MLP)。
-
示例训练脚本目录(示例):
example/dune_train/- 典型运行命令(以仓库示例脚本名为准):
bash
或cd example/dune_train python3 dune_train_diff.py --config config.yamlbash
cd example/dune_train python3 train_dune.py --config config.yaml - 说明:示例脚本调用最终会构造
DUNETrain并运行start(),完成离线数据生成与训练保存.pth。
- 典型运行命令(以仓库示例脚本名为准):
-
关键代码行(位置参考):
- DUNETrain 数据生成:
dune_train.py中generate_data_set()(大约 109-132 行) - DUNETrain 标签生成(cvxpy 求解):
prob_solve()(大约 101-107 行) - 训练执行主体:
start()(dune_train.py,训练循环与保存逻辑)
- DUNETrain 数据生成:
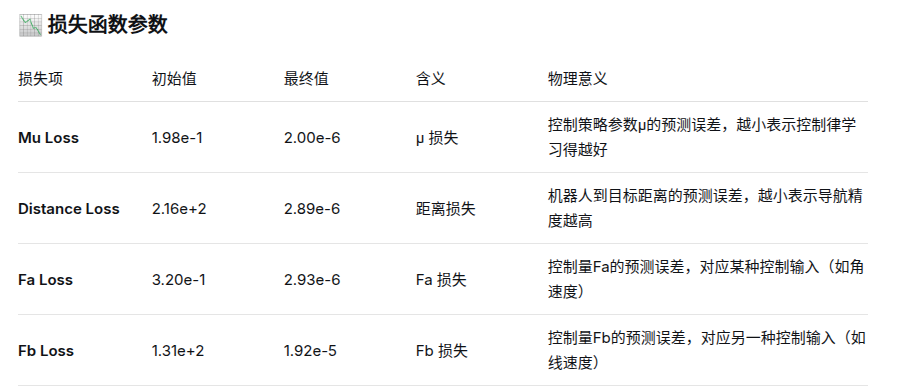
- 训练结果分析pth文件

4、训练要求
4.1 硬件(CPU / GPU)
- DUNE 训练:
- 可在 CPU 上完成(项目文档建议优先 CPU,因为 cvxpy 不支持 GPU)。
- 如果仅想加速神经网络前后向,可在训练脚本中将模型移动到 GPU,但注意标签生成(cvxpy 求解)仍在 CPU。
- 训练时间(参考):在强性能 CPU(例如桌面 i7)上,训练大约需要 1–2 小时(取决于 data_size、epoch 等)。
- 推理(导航)阶段:
- 必须使用 CPU(cvxpy 求解器通常在 CPU 上运行),因此部署平台 CPU 性能直接决定在线规划频率与实时性。
- 开发板算力建议(参照 Intel Core i7 第 9 代):
- 参考目标:Intel Core i7 第 9 代(例如 i7-9700/9700K)—— 多核(6–8 核)与较高主频(基频约 3.0–3.6 GHz,涡轮更高)。
- 建议:若希望在部署平台实现 ≥10–15 Hz 的规划频率,开发板的综合 CPU 性能(单线程与多线程)应尽量接近或不远低于该档次。低算力平台需要通过减少 NRMP 复杂度(降低 obs 点数、下采样、减小 receding T 等)来换取帧率。
- 备注:具体频率受问题规模(T、max_num、obs 点数)和求解器选择影响。
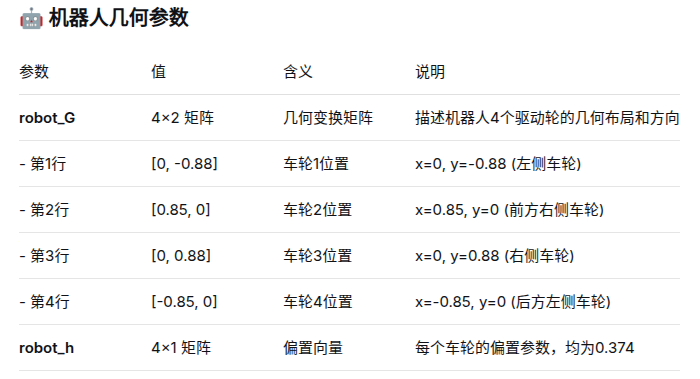
4.2 机器人参数
训练 DUNE 时必须提供机器人几何以及动力学约束信息,典型字段:
kinematics:运动学类型(支持diff、acker、omni)。vertices(首选):凸多边形顶点(2 x N),或length,width,wheelbase(矩形机器人可用此三项构建顶点)。max_speed:最大速度约束(线速度、角速度或转向角)。max_acce:最大加速度。wheelbase:对 Ackermann(acker)车型必需。
约束说明:
- 几何必须为凸多边形(gen_inequal_from_vertex 将在内部计算 G、h)。
- 若几何非凸,请先做凸包近似再训练。
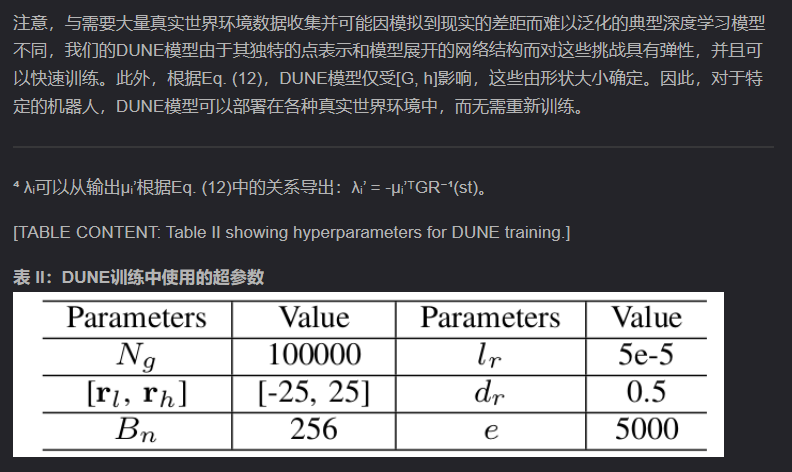
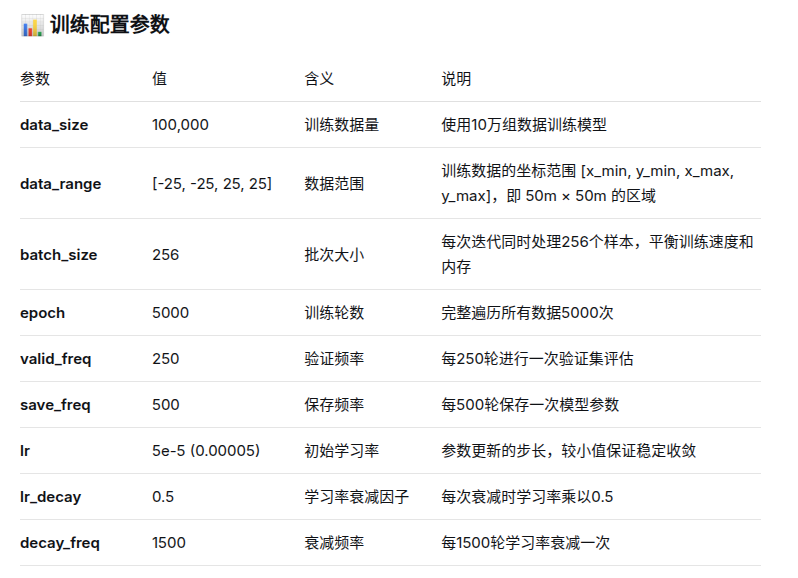
4.3 训练数据与超参数建议
- 数据来源(DUNE):完全随机生成的 2D 点(在
data_range内),并通过 cvxpy 基于 G、h 求标签。 - 建议超参数(工程起点/默认值):
- data_size: 100000
- data_range: [-25, -25, 25, 25]
- batch_size: 256
- epoch: 5000
- lr: 5e-5
- lr_decay: 0.5
- decay_freq: 1500
- save_freq: 500
- 调整建议:
- 若机器人尺寸更大或工作区域更广,增大
data_size与data_range; - 训练不稳定时适当减小学习率并增加
epoch; - 使用
save_loss=True保存 loss 曲线以便分析。
- 若机器人尺寸更大或工作区域更广,增大
5、训练输出与文件对比(DUNE vs LON)
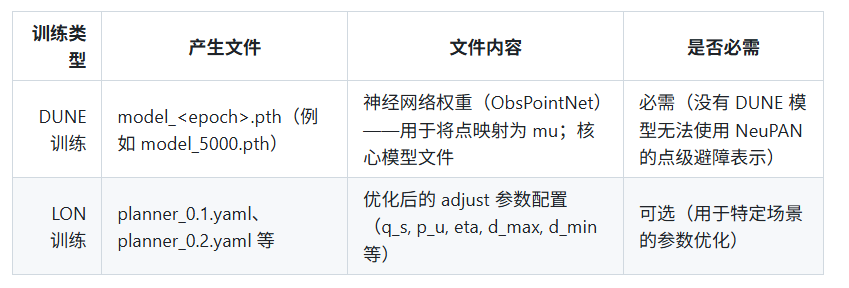
- 区别要点:
- DUNE 产生的
.pth是功能性强依赖几何的核心模型,必须训练(针对新几何)。 - LON 的 YAML 只是参数 tuning 的结果,属于性能调优可选项;若默认参数能满足需求,无需 LON。
- DUNE 产生的
6、使用建议与注意事项
- 新用户建议流程:
- 先使用仓库自带的默认
planner.yaml/train配置进行快速运行(或示例训练),观察结果; - 若机器人几何发生变化(尺寸、形状),必须重新训练 DUNE;
- 若单纯希望改善特定场景(走廊、室内窄通道等),可考虑运行 LON 调优。
- 先使用仓库自带的默认
- DUNE 训练不依赖仿真或传感器数据,属离线数学训练;因此训练数据覆盖部署场景尺度很重要(调整 data_range)。
- LON 训练需要仿真环境(ir-sim),训练后参数针对该场景,跨场景直接迁移可能不理想。
- 若部署平台 CPU 性能不足,建议:
- 减少 dune_max_num 与 nrmp_max_num;
- 对观测点进行更粗的下采样(downsample);
- 减小 receding horizon T;
- 或采用更强的边缘设备。
- 遇到模型加载缺失时:
DUNE类在加载 checkpoint 找不到时,会询问是否开始训练(或可在代码中以direct_train参数自动触发),也可以直接使用DUNE.train_dune(train_kwargs)。
7、运行检查表(快速启动)
- 环境准备:
- Python 环境安装依赖(见 requirements.txt,注意 cvxpy、cvxpylayers、ecos 等)。
- 若运行 LON,准备 ir-sim。
- 训练 DUNE(示例):
- 编辑 robot 配置(vertices 或 length/width/wheelbase)。
- 编辑
example/dune_train/config.yaml(或脚本参数)设置 train 超参数。 - 运行:
(或cd example/dune_train python3 dune_train_diff.py --config config.yamlpython3 train_dune.py --config config.yaml,以示例脚本名为准)
- 训练输出检查:
- 检查 checkpoint 目录下是否生成
model_<epoch>.pth(例如 model_5000.pth)。 - 检查
results.txt(训练日志)与loss.pkl(如有)是否生成并合理。
- 检查 checkpoint 目录下是否生成
- 验证:
- 在仿真或单元测试中加载
.pth并运行DUNE.forward()或完整neupan前向,检查 mu、distance 是否合理。
- 在仿真或单元测试中加载
- 可选:运行 LON(仅在需调优参数时):
- 在仿真场景(示例走廊)运行 LON 脚本(示例
LON_corridor.py),输出planner_0.1.yaml等。
- 在仿真场景(示例走廊)运行 LON 脚本(示例
8、参考源码位置(关键文件与类/函数)
- DUNE 训练与网络:
- neupan/blocks/dune_train.py — DUNETrain(数据生成、标签、训练主逻辑)
- neupan/blocks/obs_point_net.py — ObsPointNet(MLP 网络结构)
- neupan/blocks/dune.py — DUNE(加载模型、触发训练、cal_distance、train_dune)
- PAN 与 NRMP:
- neupan/blocks/pan.py — PAN(迭代交替最小化流程)
- neupan/blocks/nrmp.py — NRMP(NRMP 层、cvxpylayer 封装)
- 辅助配置与工具:
- neupan/configuration/init.py — np_to_tensor / to_device 等
- neupan/util/init.py — file_check / gen_inequal_from_vertex / downsample 等
- neupan/robot/robot.py — robot 类(生成 G、h 与动力学相关方法)
- 示例训练目录(仓库):
- example/dune_train/(训练脚本及配置示例)
五、参考链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)