Transformer模型-模型训练与推理机制
本文是接上文继续写的!!!!!!
三、模型训练与推理机制
Transformer 的训练与推理都基于自回归生成机制(Autoregresive Generation):模型逐步生成目标序列中的每一个词。然而,在实现方式上,训练与推理存在明显区别。
3.1模型训练
训练时,Transformer 将目标序列整体输入解码器,并在每个位置同时进行预测。为防止模型 ”看到 “ 后面的词,破坏因果顺序,解码器在自注意力机子层中引入了 遮盖机制( Mask),限制每个位置只能关注它前面的词。
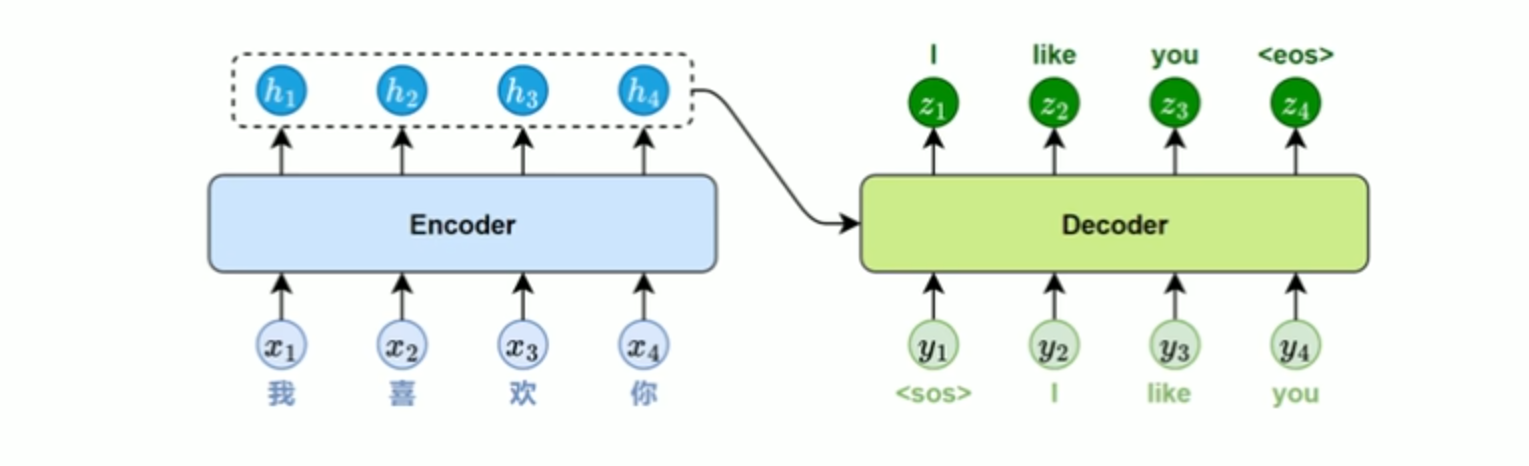
这种机制让模型在结构上模拟逐词生成,但在实际上能充分利用并行计算,大幅提升训练效率。
3.2推理机制
推理时,每一步都要重新输入整个已生成序列,模型需要基于全量前文重新计算注意力分布,决定下一个词的输出。整个过程必须顺序执行,无法并行。
推理阶段,模型每一步都要重新输入当前已生成的全部词,通过自注意力机制建模上下文关系,预测下一个词。
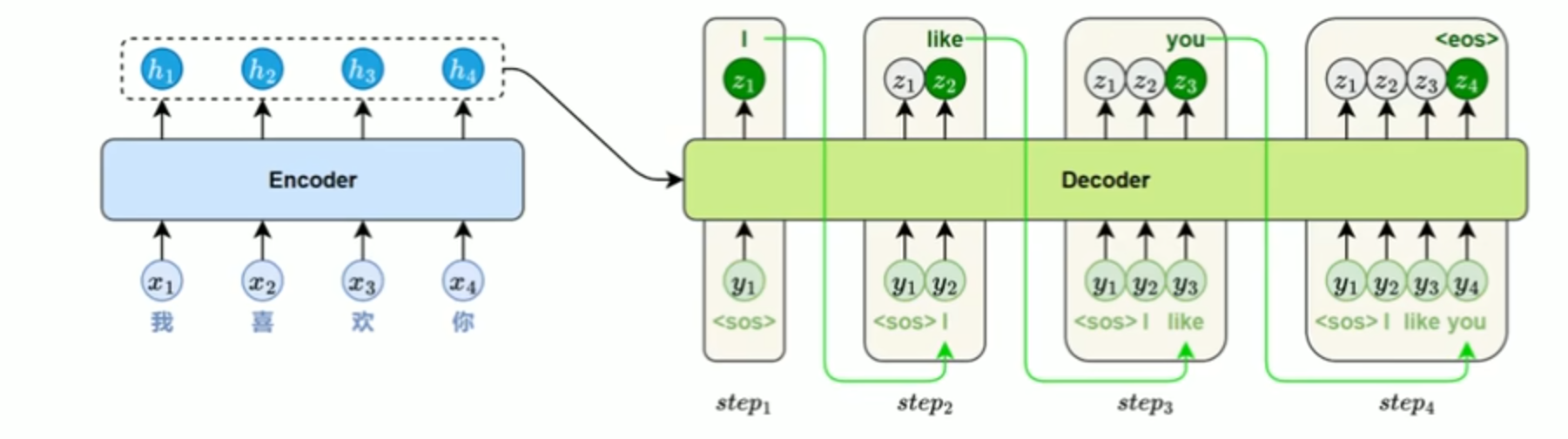
模型会基于完整前文重新计算注意力分布,生成当前步的输出。由于每一步的输入依赖前一步结果,整个过程必须顺序执行,无法并行。
3.3API使用
PyTorch 提供了对Transformer的官方实现,该模块封装了完整的编码器-解码器结构,可直接应用于机器翻译、文本生成等典型的序列建模任务。
PyTorch 中的 Transformer 模块由以下几个核心类构成:
nn.Transformer:
封装了完整的Transformer架构,由编码器和解码器组成。作为顶层接口,适用于需要同时使用编码器和解码器的任务,如机器翻译。支持用户通过参数自定义层数、注意力头数、隐藏维度等模型结构。
nn.TransformerEncoder:
实现了Transformer编码器结构,由多个编码器层的堆叠而成,用于将输入序列编码为上下文相关的表示。
nn.TransformerDecoder:
实现了Transformer解码器结构,由多个解码器层堆叠而成,用于基于编码结果逐步生成目标序列。
nn.TransformerEncoderLayer:
实现了单个编码器层结构,包含一个多头自注意力子层和一个前馈神经网络子层,两者均带有残差连接和LayerNorm。
nn.TransformerDecoderLaver:
实现了单个解码器层结构,包含自注意力、编码器-解码器注意力、前馈子层,同样配有残差连接和 LayerNorm。
Transformer 本身不关心词的顺序,因为它是一次性看所有词的。
但语言里“我打你”和“你打我”意思完全不同,所以必须把位置强行告诉模型。
怎么做:
在把每个词变成数字向量(词向量)之后,马上加上一个位置向量。
-
词向量负责表达“这个词是什么”(苹果、吃、我)
-
位置向量负责表达“这个词在第几个位置”(第1位、第2位、第3位)
👉 最终输入 = 词向量 + 位置向量
关键点:位置向量不是随机的,是用三角函数(或可学习的方式)预先算好的。
(三角函数位置编码 = 用 sin 和 cos 给每个位置生成一个独一无二、且有“距离相似性”的向量)
公式(你不需要背,看懂规律即可):
当 ii 是偶数时:
用 sin( pos / 10000^(i/d) )当 ii 是奇数时:
用 cos( pos / 10000^(i/d) )其中 dd 是总维度
关键1:为什么用 sin / cos?——为了“相对位置可被捕捉”
这是最漂亮的地方。
对任意两个位置 pospos 和 pos+kpos+k
它们的编码向量之间,存在一个固定的线性变换关系翻译成人话:
位置 5 的编码 和 位置 6 的编码
位置 100 的编码 和 位置 101 的编码
👉 它们之间的“差值模式”是一样的
✅ 模型不需要死记硬背每个位置
✅ 模型可以自动学到:“偏移1”是一种关系,“偏移5”是另一种关系
✅ 关键2:为什么有 10000^(i/d)?
这是一个波长控制参数。
低维度(小 i):变化非常快 → 适合区分相邻位置
高维度(大 i):变化非常慢 → 适合区分远处位置
类比:
低维度像秒针(看得清细微移动)
高维度像时针(只看大致范围)最终效果:
同一个位置编码中,同时包含了“局部精确信息”和“全局大致信息”好处是:模型既能知道“苹果”在第2位,也能根据这个位置去和其他词计算关系。
三角函数位置编码 = 用不同频率的 sin/cos 给每个位置打一个“波动的标签”
低频 → 看全局
高频 → 看局部
相对位置的相似性天然存在
✅ 结果:模型依然可以并行处理所有词,但每个词的“位置身份”被牢牢焊死在它的表示里。
API构造函数:
import torch
import torch.nn as nn
# ==================== 超参数设置 ====================
batch_size = 32 # 批量大小:一次处理32个句子对
src_len, tgt_len = 10, 20 # 源序列长度10,目标序列长度20
d_model, nhead = 512, 8 # 特征维度512,注意力头数8(512/8=64维/头)
num_encoder_layers, num_decoder_layers = 6, 6 # 编码器和解码器各堆叠6层
# ==================== 创建Transformer模型 ====================
model = nn.Transformer(
d_model=d_model, # 输入/输出的特征维度(整个模型统一)
nhead=nhead, # 多头注意力机制的头数,必须能整除d_model
num_encoder_layers=num_encoder_layers, # 编码器层数(6个Encoder堆叠)
num_decoder_layers=num_decoder_layers, # 解码器层数(6个Decoder堆叠)
batch_first=True, # 输入形状为(batch, seq_len, feature)而非(seq_len, batch, feature)
dropout=0.1 # Dropout比率,防止过拟合
)
# ==================== 准备输入数据 ====================
# 随机生成源序列输入(模拟经过词嵌入后的向量)
# 形状: (batch_size, src_len, d_model) = (32, 10, 512)
src = torch.rand(batch_size, src_len, d_model)
# 随机生成目标序列输入(模拟经过词嵌入后的向量)
# 注意:训练时tgt是正确序列(通常右移一位并加上起始符)
# 形状: (batch_size, tgt_len, d_model) = (32, 20, 512)
tgt = torch.rand(batch_size, tgt_len, d_model)
# ==================== 生成因果掩码(Causal Mask) ====================
# 作用:防止解码器在预测第i个位置时"偷看"第i+1及之后的位置
# 生成一个下三角矩阵(上三角部分为-inf,下三角部分为0)
# 形状: (tgt_len, tgt_len) = (20, 20)
tgt_mask = model.generate_square_subsequent_mask(tgt_len)
# 掩码矩阵示例(简化版):
# 位置: 0 1 2 3
# 0 [0, -∞, -∞, -∞] # 位置0只能看到自己
# 1 [0, 0, -∞, -∞] # 位置1能看到位置0和1
# 2 [0, 0, 0, -∞] # 位置2能看到位置0,1,2
# 3 [0, 0, 0, 0] # 位置3能看到所有位置
# ==================== 前向传播 ====================
# 执行Transformer计算:
# 1. 编码器:处理src,输出记忆特征
# 2. 解码器:结合记忆特征和tgt,逐步生成输出
# 3. 掩码:确保解码器的自注意力不会看到未来信息
output = model(
src, # 源序列(编码器输入)
tgt, # 目标序列(解码器输入)
tgt_mask=tgt_mask # 因果掩码(防止解码时看到未来)
)
# ==================== 输出结果 ====================
# 输出形状: (batch_size, tgt_len, d_model) = (32, 20, 512)
# 含义:每个目标位置的隐藏表示(通常再接线性层+softmax得到词概率)
print(f"输入src形状: {src.shape}") # torch.Size([32, 10, 512])
print(f"输入tgt形状: {tgt.shape}") # torch.Size([32, 20, 512])
print(f"输出形状: {output.shape}") # torch.Size([32, 20, 512])
# ==================== 补充:完整的使用流程 ====================
"""
# 1. 词嵌入层:将整数token ID转换为向量
src_embedding = nn.Embedding(vocab_size, d_model)
tgt_embedding = nn.Embedding(vocab_size, d_model)
# 2. 位置编码:为序列添加位置信息
# (PyTorch的Transformer不内置位置编码,需要手动添加)
src = src_embedding(src_tokens) + positional_encoding(src_len)
tgt = tgt_embedding(tgt_tokens) + positional_encoding(tgt_len)
# 3. 输出层:将d_model维度映射回词表大小
output_proj = nn.Linear(d_model, vocab_size)
logits = output_proj(output) # (32, 20, vocab_size)
# 4. 计算损失(忽略padding位置)
loss = nn.CrossEntropyLoss(ignore_index=pad_idx)
loss(logits.view(-1, vocab_size), tgt_tokens.view(-1))
"""
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)