RAG检索秒变神级!揭秘重排序技术如何让你的AI效果起飞!
本文深入探讨了在RAG检索流程中应用重排序技术的必要性及其核心优势。文章首先阐述了重排序技术如何通过优化检索结果、增强上下文相关性及应对复杂查询来提升整体检索效果。接着,详细介绍了重排序模型的工作原理,包括粗排与精排的概念,以及重排序模型如何计算相关性分数并重新排序文档。此外,文章还列举了市面上可用的重排序模型,并分析了其在生产环境中可能面临的资源和效率问题。最后,通过实战案例展示了如何使用BGE的bge-reranker-v2-m3模型进行重排序,提供了具体的代码实现和操作步骤。
@ 目录
- 一、为什么要使用重排序技术
- 二、重排序技术的几个优势
- 三、重排序模型 (Reranking Model)
- 四、重排序技术实战
一、为什么要使用重排序技术
- 在 RAG 检索流程中,重排序技术(Reranking)通过对初始检索结果进行重新排序,改善检索结果的相关性,为生成模型提供更优质的上下文,从而提升整体 RAG 系统的效果。
- 尽管向量检索技术能够为每个文档块生成初步的相关性分数,但引入重排序模型仍然至关重要。向量检索主要依赖于全局语义相似性,通过将查询和文档映射到高维语义空间中进行匹配。然而,这种方法往往忽略了查询与文档具体内容之间的细粒度交互。
- 重排序模型大多是基于双塔或交叉编码架构的模型,在此基础上进一步计算更精确的相关性分数,能够捕捉查询词与文档块之间更细致的相关性,从而在细节层面上提高检索精度。因此,尽管向量检索提供了有效的初步筛选,重排序模型则通过更深入的分析和排序,确保最终结果在语义和内容层面上更紧密地契合查询意图,实现了检索质量的提升。
二、重排序技术的几个优势
-
优化检索结果
在 RAG 系统中,初始的检索结果通常来自于向量搜索或基于关键词的检索方法。然而,这些初始检索结果可能包含大量的冗余信息或与查询不完全相关的文档。通过重排序技术,我们可以对这些初步检索到的文档进行进一步的筛选和排序,将最相关、最重要的文档置于前列。
-
增强上下文相关性
RAG 系统依赖于检索到的文档作为生成模型的上下文。因此,上下文的质量直接影响生成的结果。重排序技术通过重新评估文档与查询的相关性,确保生成模型优先使用那些与查询最相关的文档,从而提高了生成内容的准确性和连贯性。
-
应对复杂查询
对于复杂的查询,初始检索可能会返回一些表面上相关但实际上不太匹配的文档。重排序技术可以根据查询的复杂性和具体需求,对这些结果进行更细致的分析和排序,优先展示那些能够提供深入见解或关键信息的文档。
三、重排序模型 (Reranking Model)
-
RAG 流程有两个概念,粗排和精排。
-
粗排检索效率较快,但是召回的内容并不一定强相关。
-
精排效率较低,因此适合在粗排的基础上进行进一步优化。精排的代表就是重排序(Reranking)。
-
重排序模型(Reranking Model)查询与每个文档块计算对应的相关性分数,并根据这些分数对文档进行重新排序,确保文档按照从最相关到最不相关的顺序排列,并返回前 top-k 个结果。
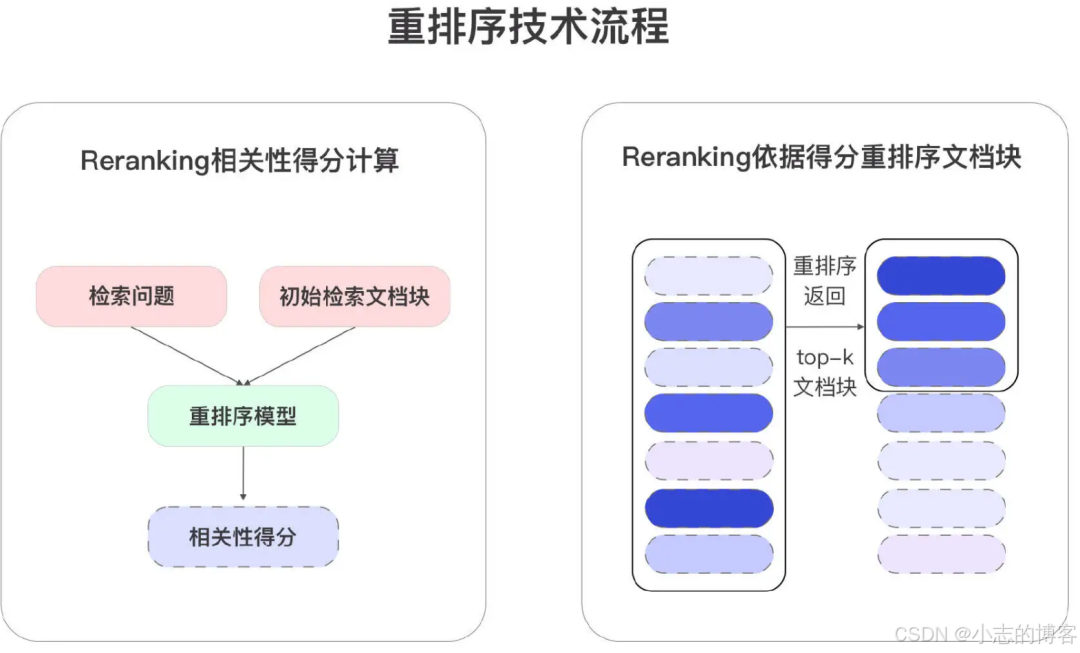
-
与嵌入模型不同,重排序模型将用户的查询(Query)和文档块作为输入,直接输出相似度评分,而非生成嵌入向量。目前,市面上可用的重排序模型并不多,商用的有 Cohere,开源的有 BGE、Sentence、Mixedbread、T5-Reranker 等,甚至可以使用指令(Prompt)让大模型(GPT、Claude、通义千问、文心一言等)进行重排,大模型指令参考如下:
-
以下是与查询 {问题} 相关的文档块:
[1] {文档块1}[2] {文档块2}(更多文档块) -
请根据这些文档块与查询的相关性进行排序,以 “1,2,3,4”(文档块数字及逗号隔开的形式),输出排序结果。
-
在生产环境中使用重排序模型会面临资源和效率问题,包括计算资源消耗高、推理速度慢以及模型参数量大等问题。这些问题主要源于重排序模型在对候选项进行精细排序时,因其较大参数量而导致的高计算需求和复杂耗时的推理过程,从而对 RAG 系统的响应时间和整体效率产生负面影响。因此,在实际应用中,需要根据实际资源情况,在精度与效率之间进行平衡。
四、重排序技术实战
-
在实战中,我们使用来自北京人工智能研究院 BGE 的 bge-reranker-v2-m3 作为 RAG 项目的重排序模型,这是一种轻量级的开源和多语言的重排序模型。更多模型相关信息参考,可访问 bge-reranker-v2-m3 官方介绍站点 https://huggingface.co/BAAI/bge-reranker-v2-m3。
-
对应的代码在 Gitee https://gitee.com/techleadcy/rag_app.git上托管项目。此文章的代码文件为 rag_app_lesson6_2.py。
-
拉取最新代码:
git clone https://gitee.com/techleadcy/rag_app.git -
创建并激活虚拟环境,若已创建则无需重复执行:
python3 -m venv rag_env -
命令行中拉取仓库的最新代码,执行依赖库安装命令,本课时对应的是 FlagEmbedding 向量操作库和 Peft 大语言模型操作库:
source rag_env/bin/activatepip install -U pip FlagEmbedding Peft jieba rank_bm25 chromadb langchain langchain_community sentence-transformers dashscope unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple -
代码中设置大模型 qwen_model,qwen_api_key 参数,访问阿里云百炼大模型服务平台 https://www.aliyun.com/product/bailian 。
-
执行课程代码:
python rag_app/rag_app_lesson6_2.py -
此章节涉及的代码改动均已在 rag_app_lesson6_2.py 文件中添加详细注释,主要包括以下内容:
-
引入依赖库:
from FlagEmbedding import FlagReranker # 用于对嵌入结果进行重新排序的工具类 -
增加 reranking 方法:
def reranking(query, chunks, top_k=3): # 初始化重排序模型,使用BAAI/bge-reranker-v2-m3 reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True) # 构造输入对,每个 query 与 chunk 形成一对 input_pairs = [[query, chunk] for chunk in chunks] # 计算每个 chunk 与 query 的语义相似性得分 scores = reranker.compute_score(input_pairs, normalize=True) print("文档块重排序得分:", scores) # 对得分进行排序并获取排名前 top_k 的 chunks sorted_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True) reranking_chunks = [chunks[i] for i in sorted_indices[:top_k]] # 打印前三个 score 对应的文档块 for i in range(top_k): print(f"重排序文档块{i+1}: 相似度得分:{scores[sorted_indices[i]]},文档块信息:{reranking_chunks[i]}\n") return reranking_chunksretrieval_process方法: # 使用重排序模型对检索结果进行重新排序,输出重排序后的前top_k文档块 reranking_chunks = reranking(query,vector_chunks + bm25_chunks, top_k) print("检索过程完成.") print("********************************************************") # 返回重排序后的前top_k个文档块 return reranking_chunks
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)