【动手学深度学习】第九课 具体的卷积神经网络
目录
一、LeNet
它是最早发布的卷积神经网络之一,在1989年提出,目的是识别图像中的手写数字。
1. 网络架构
主要由两个卷积层和三个全连接层组成。先用卷积层来学习图片的空间信息,再用池化层来降低图片的敏感度,最后用全连接层来转化为类别空间。
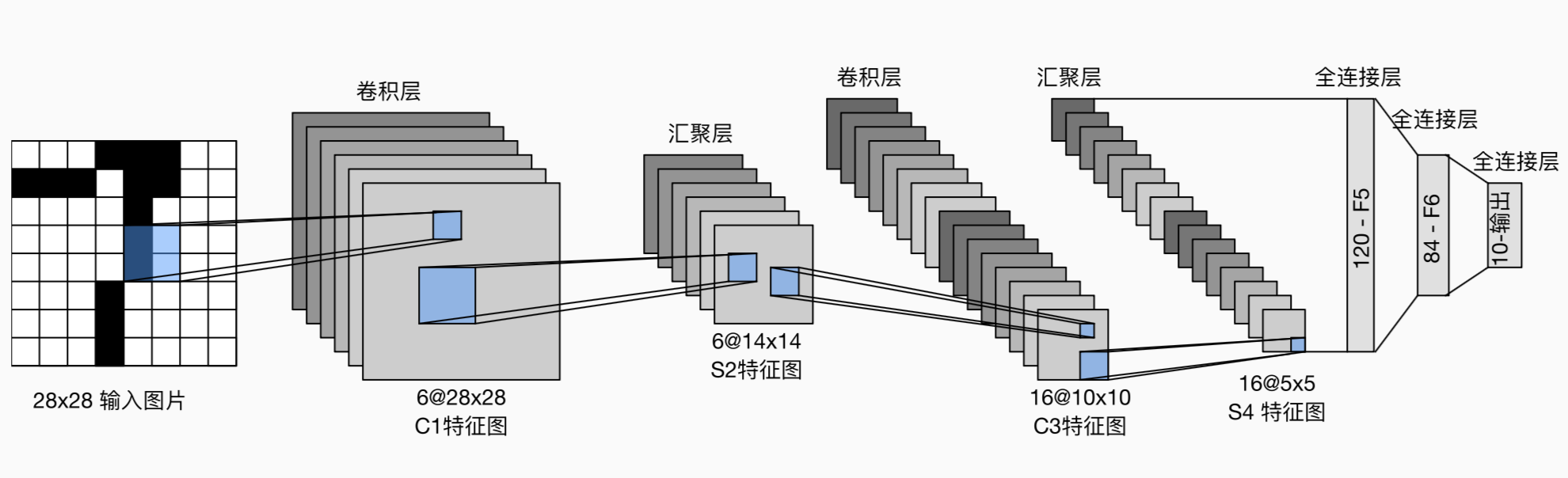
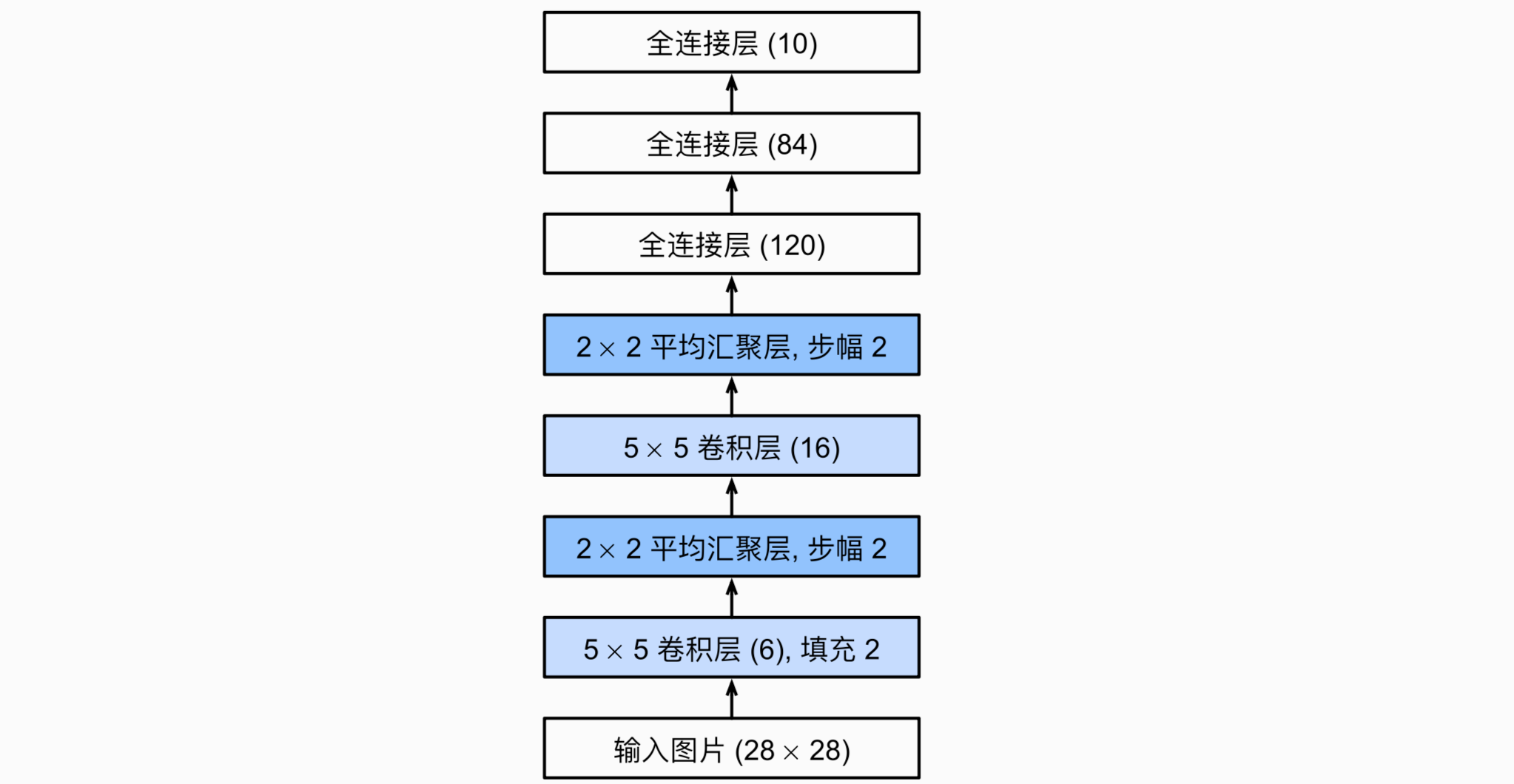
用pytorch框架实现LeNet很简单,只需要实例化一个sequential块并将需要的层连接在一起,下面代码需要看,你会发现其实实现一个框架很简单。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), #展平成向量
#下面就是有两个隐藏层的多层感知机
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))这里注意一下,虽然ReLu和maxpooling更有效,但当时还并未出现,所以用的还是sigmoid和avgpooling。
2. 训练模型
我们还是使用Fashion-MNIST数据集:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)然后定义测试集精度评估函数。由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]然后,定义训练函数。部分可视化的代码我有改动:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
# 只对线性层和卷积层的权重参数进行初始化,使用Xavier均匀分布。
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
timer, num_batches = d2l.Timer(), len(train_iter)
# ===================== 新增:用于保存曲线的数据 =====================
train_loss_list = []
train_acc_list = []
test_acc_list = []
epoch_list = []
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
print(f"\n=== 正在训练第 [{epoch+1}/{num_epochs}] 轮 ===")
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
test_acc = evaluate_accuracy_gpu(net, test_iter)
# ===================== 新增:每个epoch记录数据 =====================
epoch_list.append(epoch + 1)
train_loss_list.append(train_l)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
最后,训练模型。
lr, num_epochs = 0.9, 20
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())结果如下图所示:
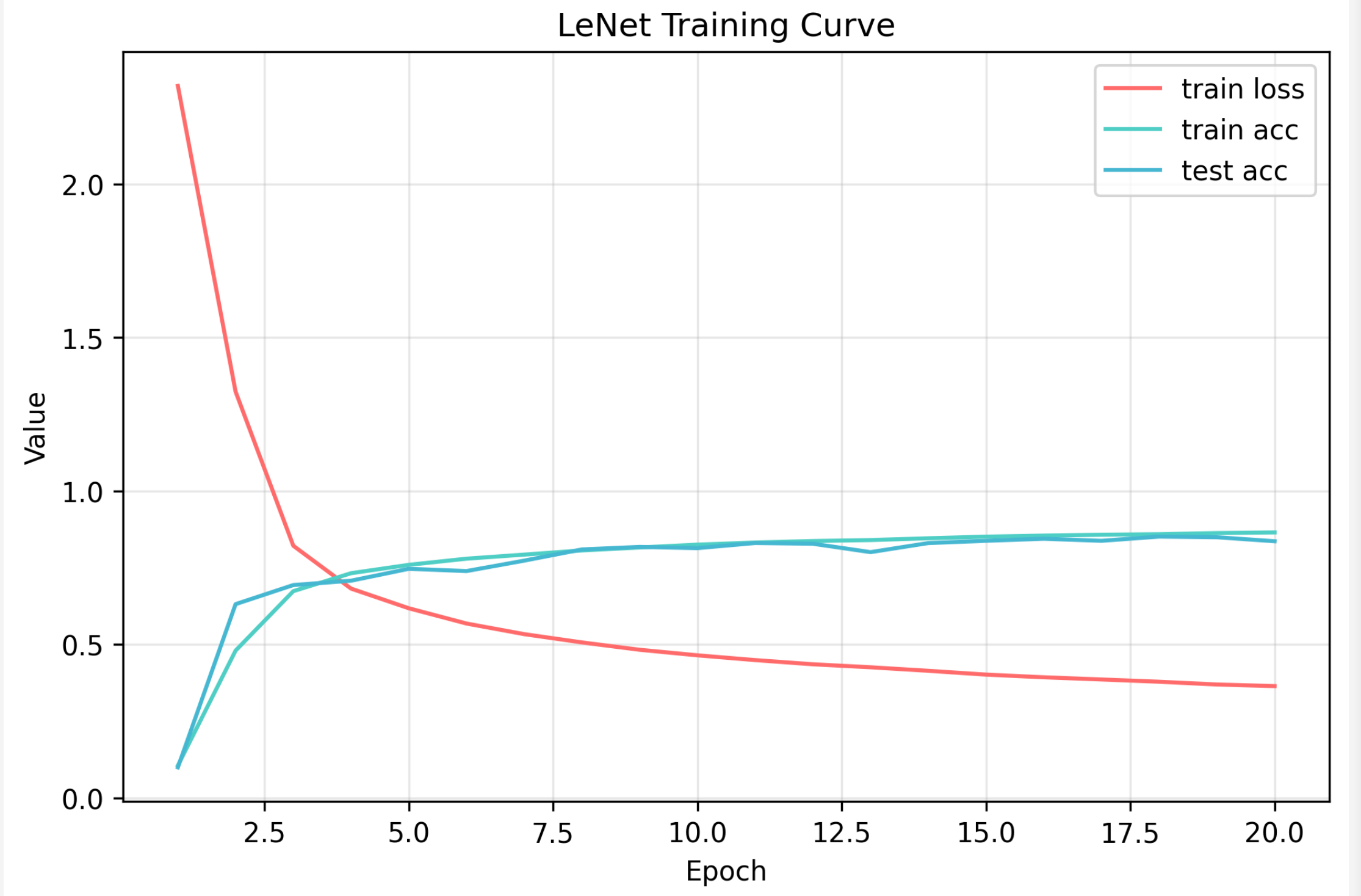
3. 尝试优化
将pooling层换成MaxPooling,激活函数换成ReLU,结果会发现,损失完全不收敛...然后发现应该是学习率的原因,我们的lr设为了0.9,但开始使用的是sigmoid,梯度变化比较平缓,而ReLU的梯度变化比较大,配合大学习率导致梯度爆炸了。于是我们将学习率降为0.05,epoch=50:
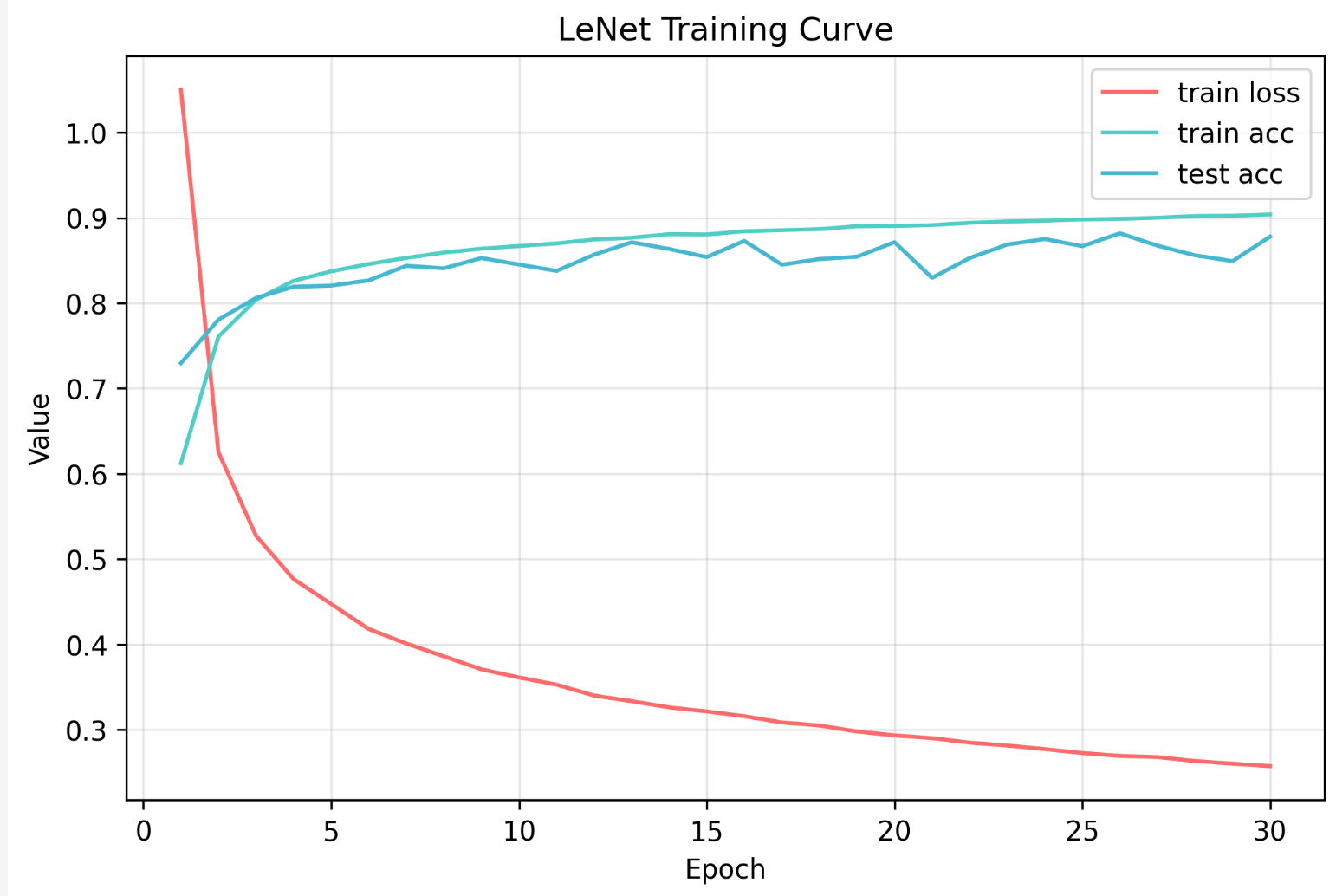
可以看到,损失下降了很多,精度也提升了,不过test acc更加震荡了,也就是说可能有轻微的过拟合。前期0.05的步长可以让模型快速收敛,但后期就需要减小步长进行“精细的微调”。然后我又加了个学习率衰减,每10个 epoch,学习率乘以 0.5,结果如下:
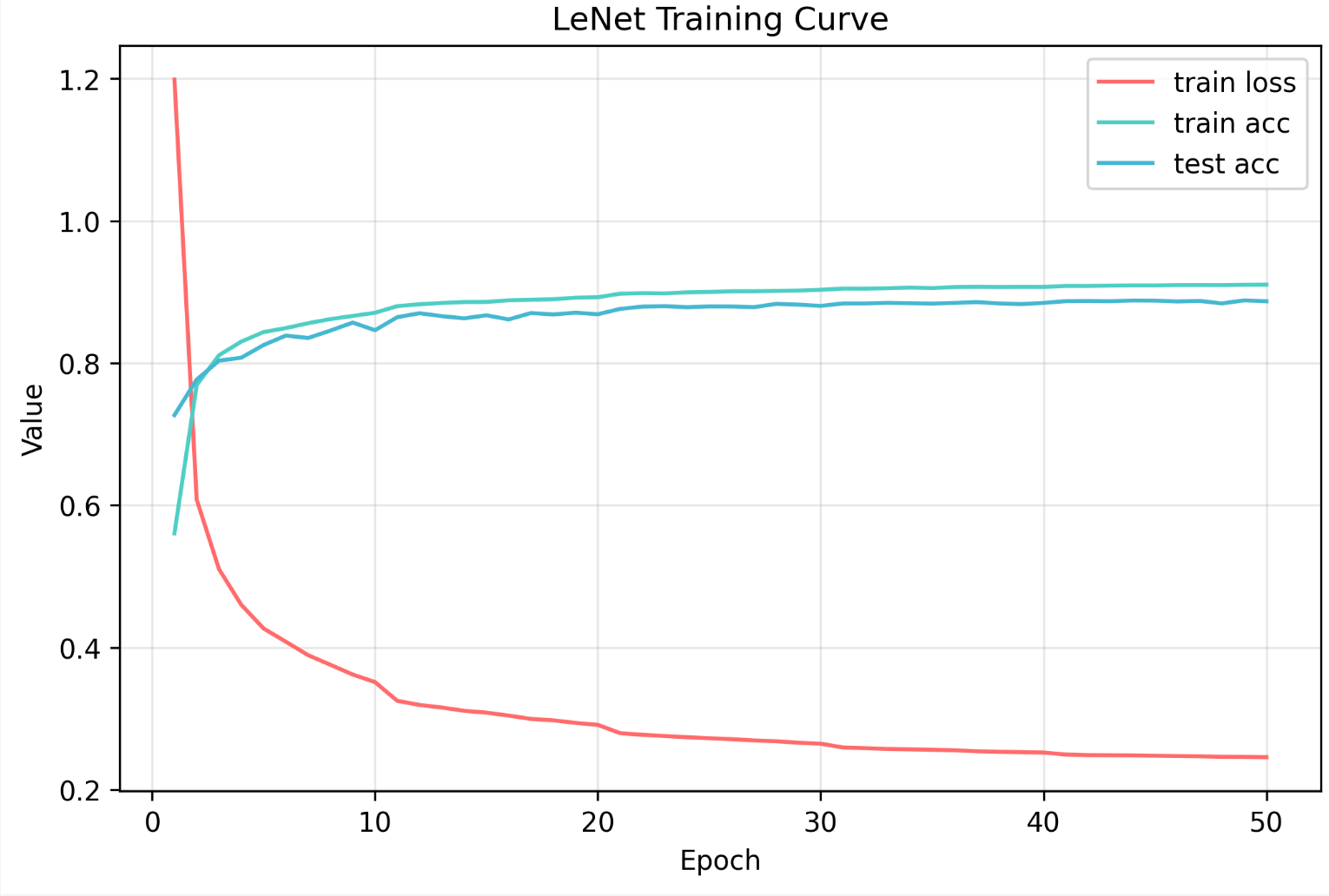
二、AlexNet
2012年提出,在深度学习领域掀起了热潮。
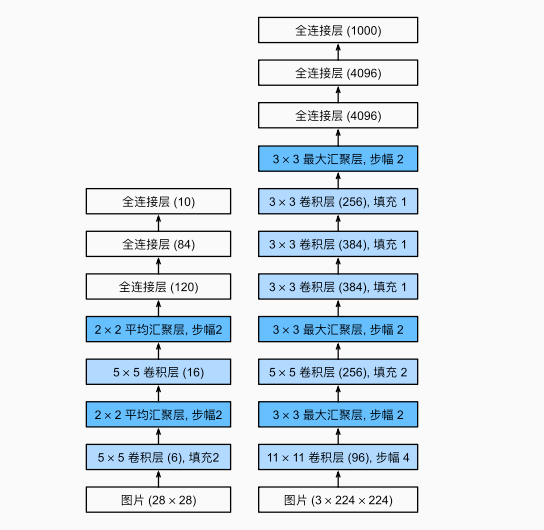
它与LeNet很相似,由5个卷积层和3个全连接层组成。但也存在显著差异:
- AlexNet更深
- AlexNet激活函数用的是ReLU,而LeNet用的是Sigmoid
- AlexNet池化层使用maxpooling,LeNet使用avgpooling(熟悉吗)
- 用的数据集不同,AlexNet使用ImageNet数据集,大多数图像的宽和高比MNIST图像的多10倍以上,因此最开始的卷积窗口变大,通道数目也大得多,最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。
1. 激活函数
(1) ReLU激活函数的计算更简单,而不像sigmoid激活函数那般复杂的求幂运算。
(2)sigmoid函数只在原点附近有比较大的梯度变化,在两端梯度变化很小,参数难以更新。相反,ReLU激活函数在正区间的梯度总是1。
具体细节可以看第六课的激活函数部分。
2. 网络架构
整体定义与Lenet相似,不过这里AlexNet使用dropout(暂退法,随机失活神经元)来控制全连接层的模型复杂度,因为后面的全连接层参数非常多、输出数量也是LeNet的好几倍,所以使用dropout减轻过拟合。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))3. 训练模型
# 这里为了有效使用AlexNet架构,将图像的分辨率调高(因为我们没有下载ImageNet数据集)
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
#训练
lr, num_epochs = 0.01, 20
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())在训练过程中,明显感觉到一个epoch所花费的时间变长了很多,这是我们的网络变复杂并且将图片像素提高了的原因。训练结果如下:
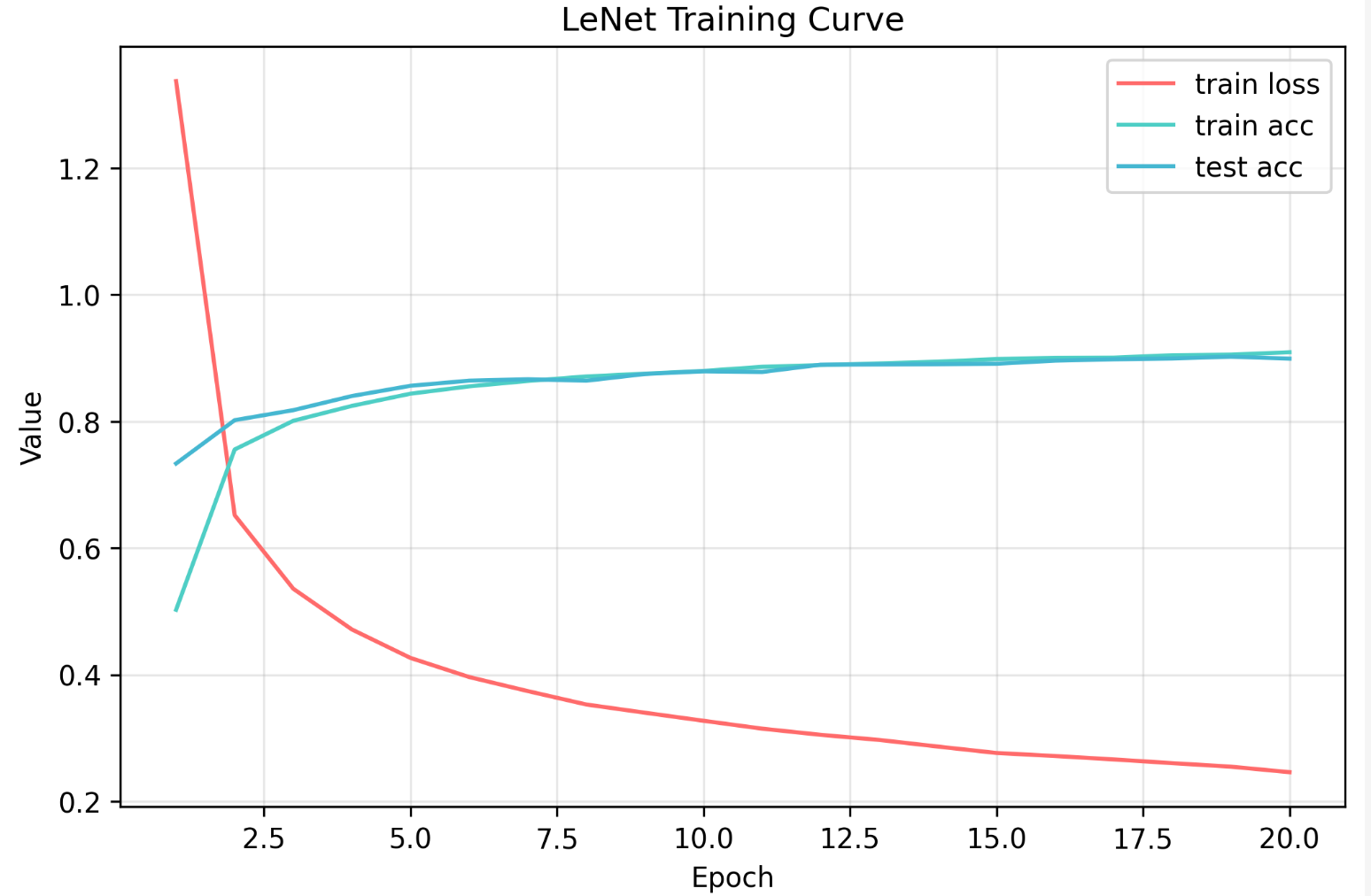
loss 0.246, train acc 0.909, test acc 0.899
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。但它的结构不够清晰,我们并不知道它相比LeNet的变大变深的规律是什么,于是我们迎来了接下来的VGG。
三、VGG
刚刚提到,怎么让网络更深更大?
- 更多的全连接层(很贵,很占内存)
- 更多的卷积层(如何添加呢?直接复制吗?)
- 将卷积层组合成块
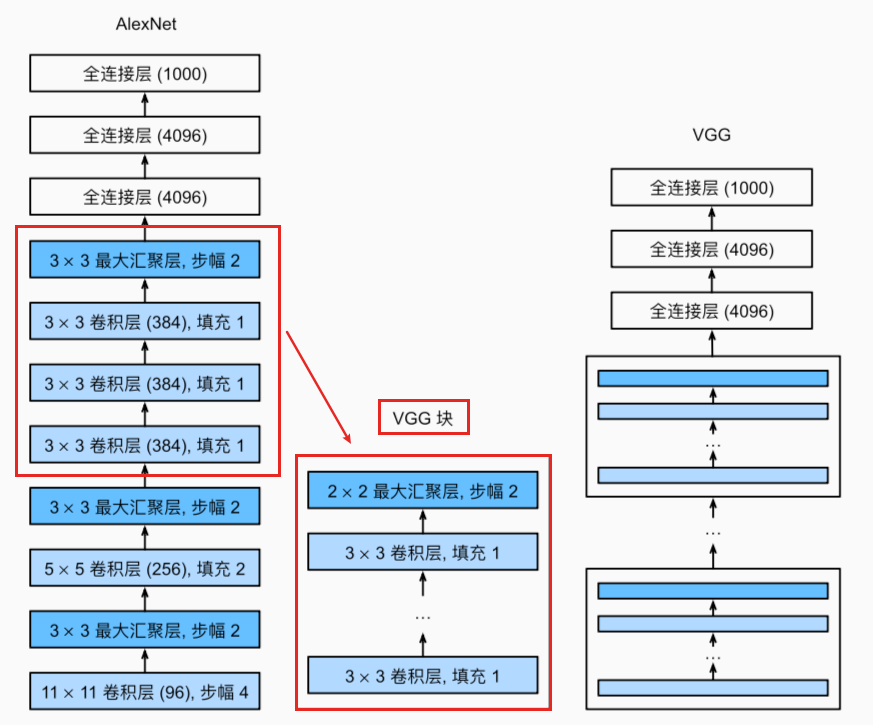
所以这里提出了vgg块,它其实是alexnet思路的一个拓展。
1. vgg块
由一系列卷积层组成,最后再加上用于空间下采样的最大汇聚层。
最初的vgg论文作者使用了3*3卷积核、padding=1的卷积层,以及2*2、stride=2的maxpooling层。
那为什么不使用5*5的卷积层呢?其实,更多的3*3的卷积层要比更少的5*5的效果好,也就是神经网络深但窄的效果更好。
我们定义了一个名为vgg_block的函数来实现一个VGG块。
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)2. vgg网络
如上面架构图所示,VGG神经网络连接了几个VGG块,其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。下面代码实现了vgg11:
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)3. 训练模型
由于我们用的数据集比较简单,这里轻量化一下vgg,减少通道数。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())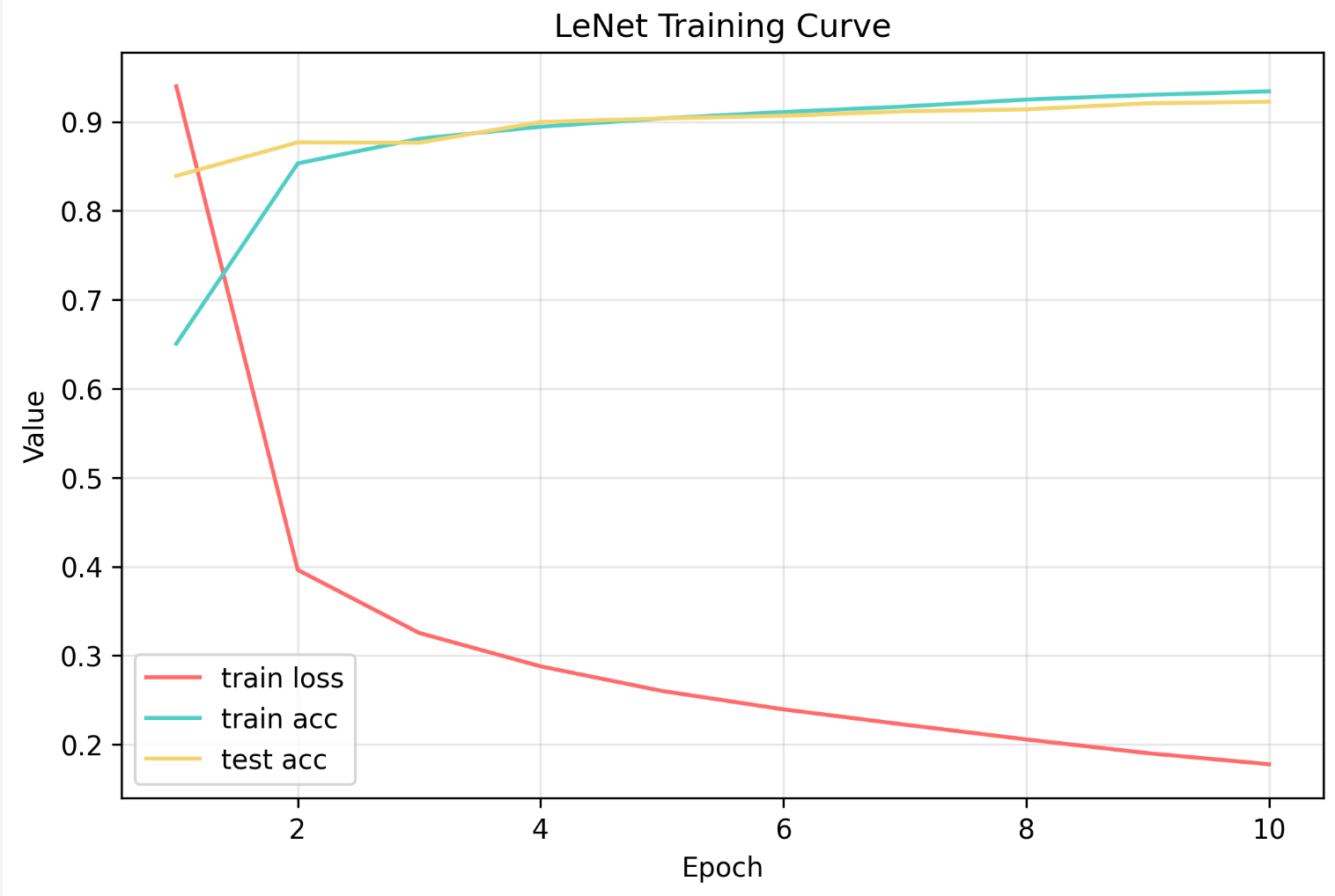
loss 0.178, train acc 0.934, test acc 0.923
后面的几个卷积神经网络,下个月有时间再进行补充。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)