大模型推理必看:DP、TP、SP、PP并行策略深度解析,轻松搞定显存与算力瓶颈!
在做大模型推理部署的时候,经常会碰到模型参数量太大,一块GPU的显存装不下,或者单块GPU的算力跟不上推理速度的情况,这时候就需要用并行策略来解决这些问题。
因为计算的流程不一样,推理和训练用到的并行策略在实现上也不一样。
这篇文章就是帮大家快速搞懂常见并行策略的基本原理。推理里主要用到的并行方式有数据并行(DP)、序列并行(SP/CP)、张量并行(TP)、层并行(PP)。
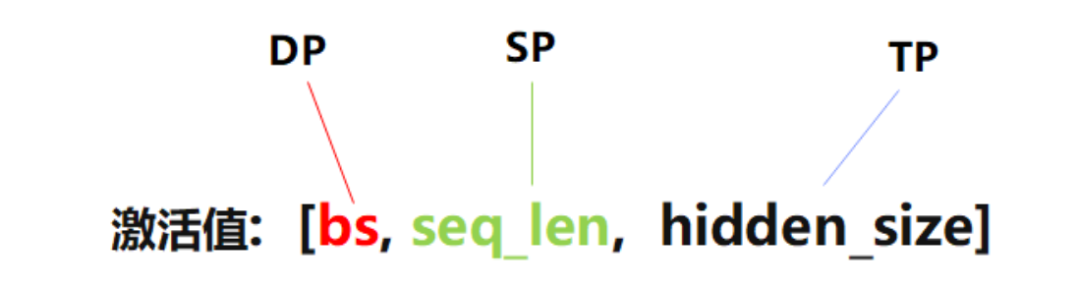
我们可以根据输入激活值的切分维度来区分不同的并行策略,一般来说,切分batch的是数据并行DP,切分序列的是序列并行SP/CP,切分隐藏层尺寸的是张量并行TP。
1 DP策略
1.1 基本原理
DP(Data Parallel)数据并行,是用来应对数据并发量比较大的一种策略。DP的做法是在不同的GPU上跑LLM模型的多个副本,每个模型副本都独立去处理对应的用户请求组。
它的原理跟开多个推理实例并发处理是一样的,区别在于,开DP的时候多个模型副本共用一个推理实例,由这个推理实例里的调度器来把请求分配给不同DP的模型副本。
2 TP策略
2.1 基本原理
Tensor Parallelism,也就是张量并行,简单说就是把模型的每一层拆分开,放到不同的GPU上去跑,用户输入的数据会在这些GPU之间传递处理,每个GPU算出的局部结果最后再拼到一起,形成完整的输出。
张量并行的计算依据是矩阵的分块运算,这种运算方式不会影响最终的计算结果。
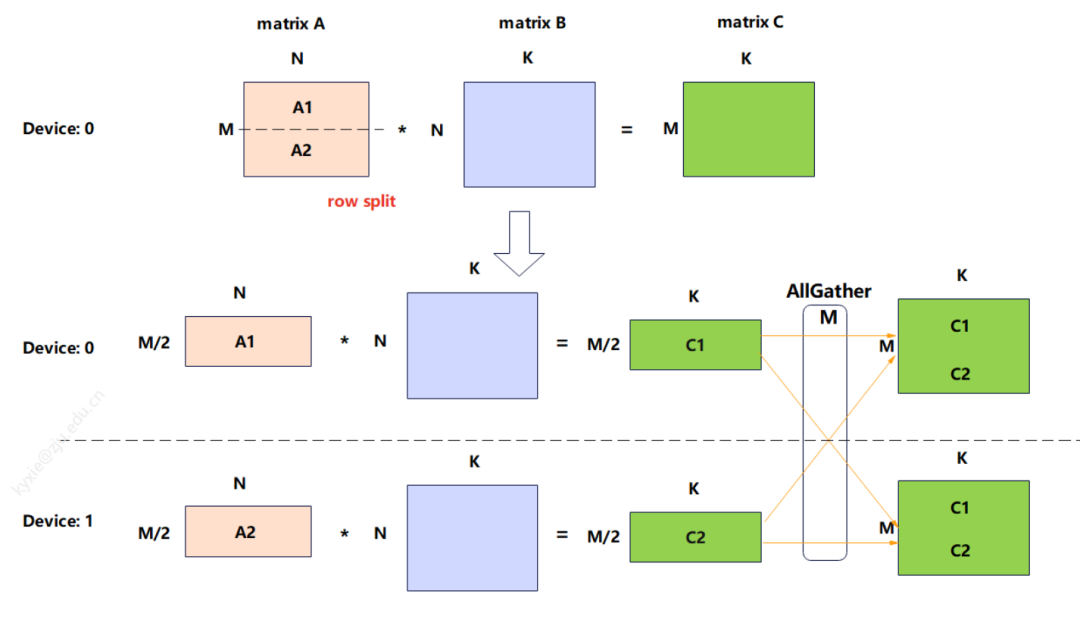
张量并行在大模型推理里用得特别多,主要就是为了减少单张显卡的显存占用,同时也能分担计算压力。
3 SP策略
3.1 基本原理
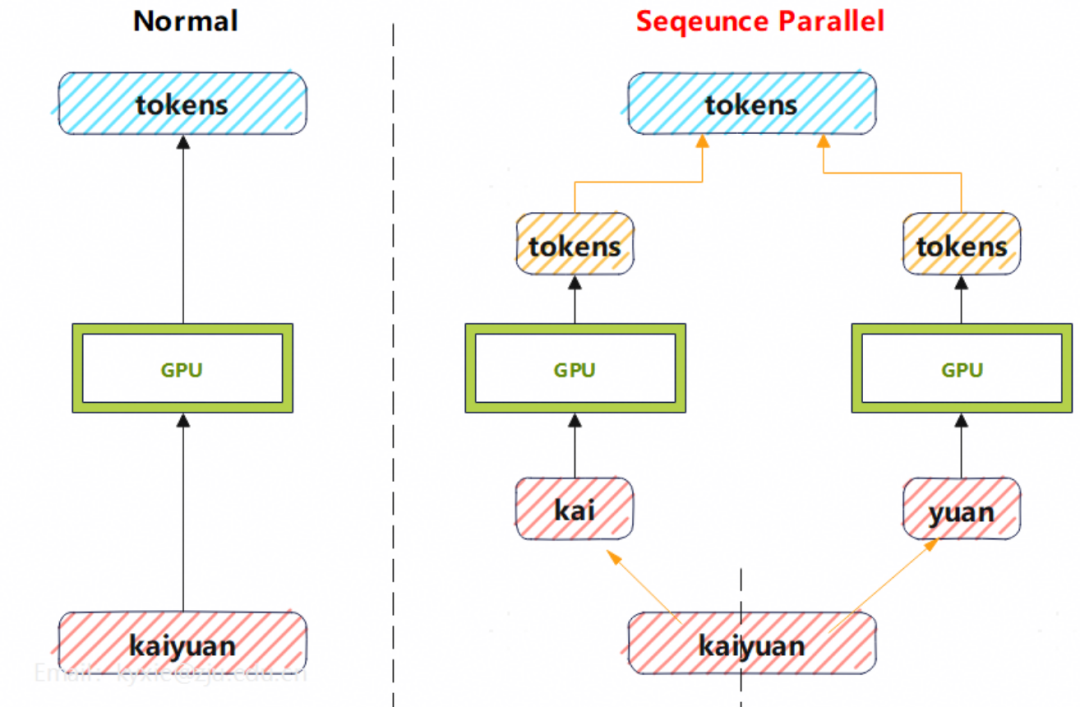
SP(Seqeunce Parallel)序列并行指的是把长序列拆成多个片段,分到不同的GPU设备上同时处理,属于一种模型并行的策略。示意图如下:
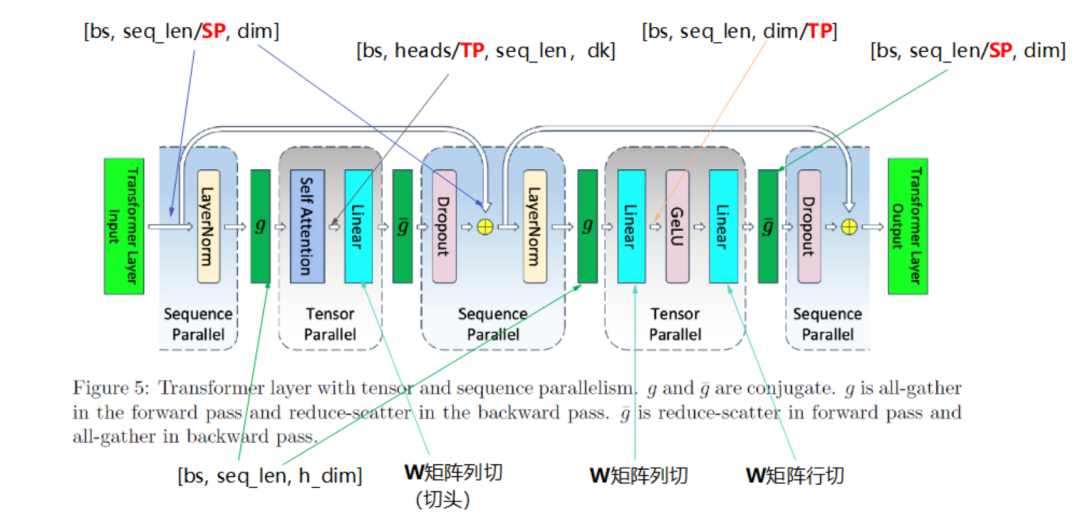
3.2 SP与其它策略结合
Megatron中TP与SP结合的例子:
负载均衡中SP与DP结合案例:
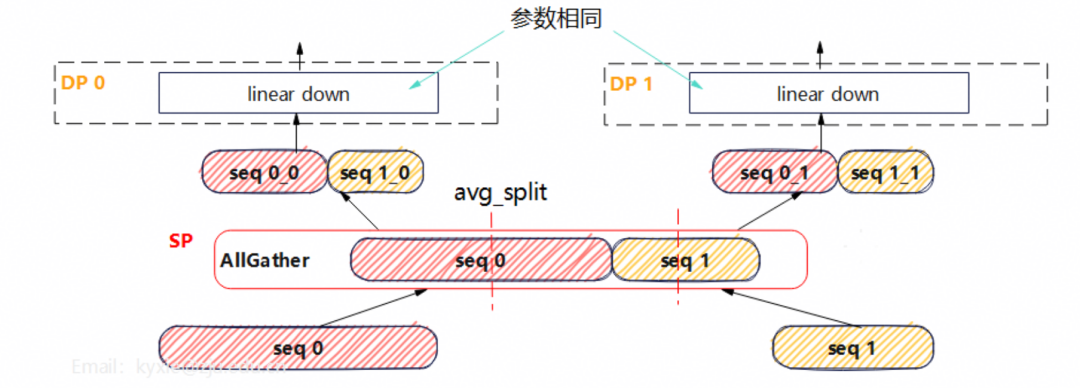
4 PP策略
4.1 基本原理
PP(Pipeline Parallel)流水线并行,是把模型按层拆分到不同设备上,数据像流水线一样在各个设备之间依次流转处理。
这种并行方式最早是在模型训练中得到广泛应用的,相关可以参考Megatron2。
在PP的前向和后向计算过程中,会产生空泡问题,训练时需要想办法把这些空泡消除掉。
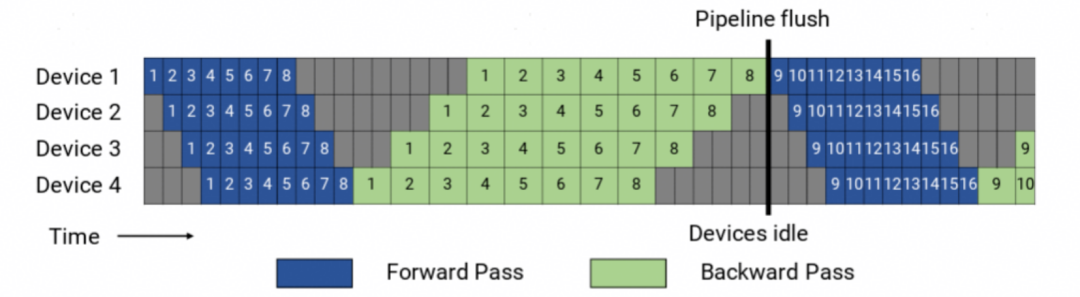
而在推理任务里,流水线并行虽然只需要做前向传播,但实际能用的场景并不多,一般只有在GPU显存实在装不下对应的模型权重时,才会考虑使用。
5 EP策略
5.1 基本原理
EP(Expert Parallel)是MoE模型里用到的一种并行策略,简单说就是把不同的专家网络分到不同的GPU上。
每张GPU只存一部分专家参数,一张卡上可以放一个或者多个专家。
输入的数据会通过路由机制,分到对应的专家所在的GPU上做计算,最后再把计算结果汇总到一起。
这样做能明显扩大模型的总参数量,同时还能控制好单个GPU的内存占用,很适合用来训练超大的稀疏模型。
现在比较常见的做法是把EP和DP结合起来用,一般Attention部分用DP,FFN部分用EP。
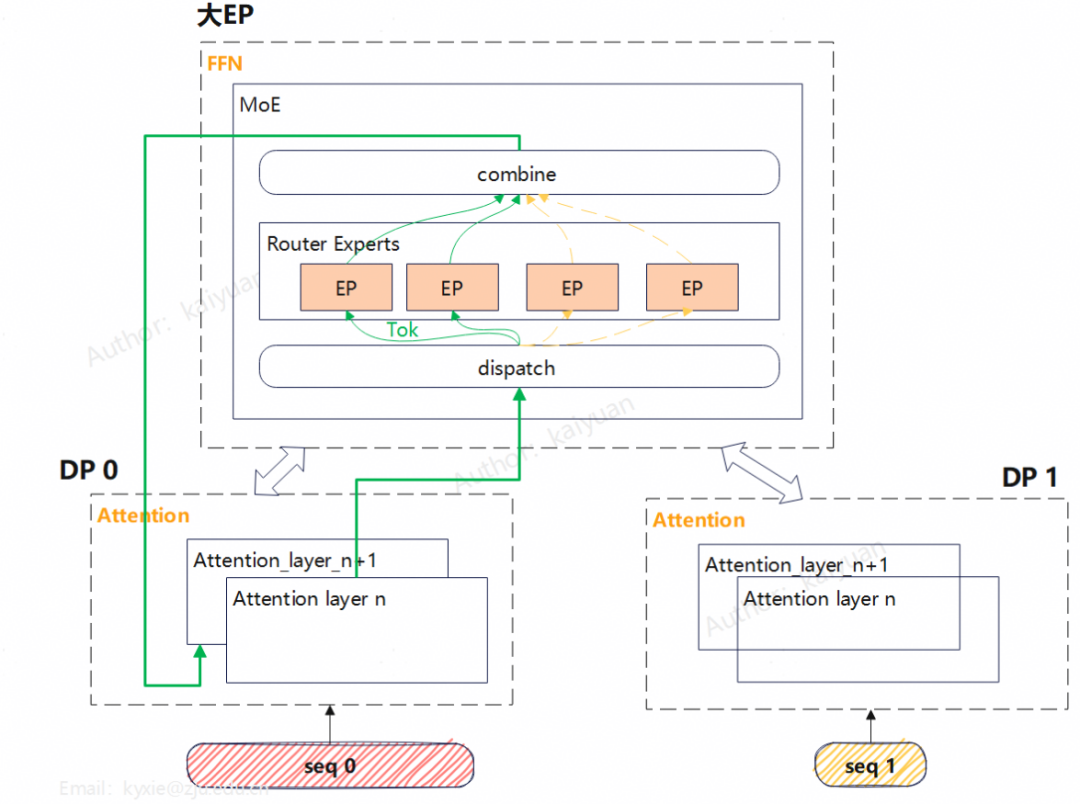
不过用EP做切分的时候,容易出现负载不均衡的情况,这个问题可以通过EPLB来解决。
6 其它策略
6.1 CP策略
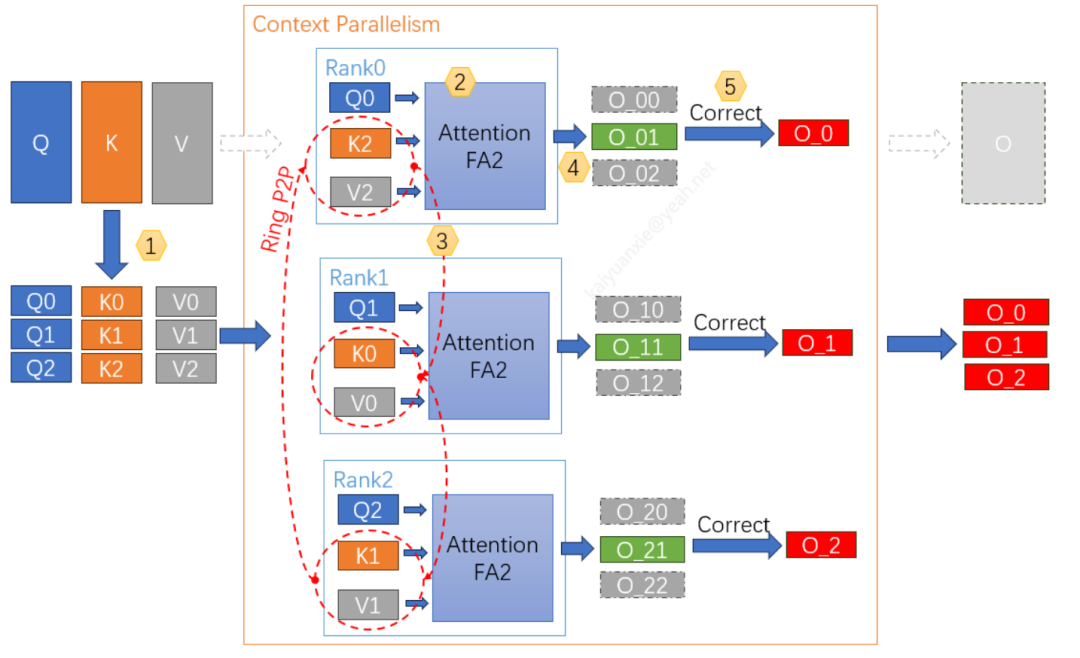
CP(Context Parallel)上下文并行和序列并行SP,都是从序列维度来做划分的并行策略,而且这两种方式最早都是在训练并行的场景里被提出来的。
它们的发展过程是这样的:最先出现的是SP策略,主要用来处理模型前向和反向传播过程里,除了Attention计算之外,因为序列切分产生的内存和计算消耗问题。
之后为了进一步解决Attention模块本身的序列并行难题,Megatron框架就引入了CP策略。这两种策略的原理比较接近,只是针对的计算阶段不一样。
6.2 Ulysses并行
Ulysses的全称是DeepSpeed‑Ulysses,它的核心逻辑是这样的:打开序列并行之后,在多头Attention运算开始之前,多个GPU设备之间会先做数据交换,这样单个GPU就能拿到完整的序列。
等Attention计算结束之后,再通过集合通信把序列恢复成原来被切分的样子。
总结
在做大模型推理的时候,现在主流的推理框架基本都支持好几种并行策略。这些策略各有各的优势和不足,主要是为了解决不同层面上的性能和资源问题。
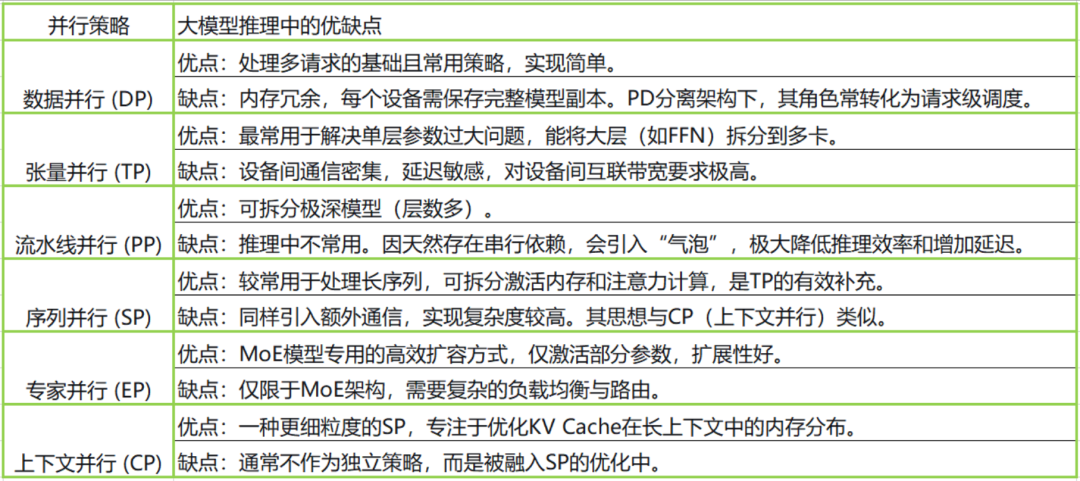
实际挑选用哪种的时候,要结合具体场景来综合判断,比如模型参数量、PD/AF分离的需求、硬件拓扑的特点这些因素都要考虑进去。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)