基于Go + gin+gorm+ rag+千问大模型 + pgvector 构建市场监管智能问答智能体
·
基于Go + 千问大模型 + pgvector构建市场监管智能问答智能体
一、项目背景
随着"放管服"改革的深入推进,市场监管领域政策法规不断更新,企业和公众对政策咨询的需求日益增长。传统的政策咨询模式存在响应慢、效率低、准确性差等问题,已无法满足新时代市场监管的需求。
本文基于Go语言、千问大模型、pgvector向量数据库和RAG技术,构建了一套完整的市场监管智能问答智能体系统,实现法规智能解析、执法文书自动生成、知识库管理等核心功能。

二、技术架构
2.1 技术栈
| 技术组件 | 选型 | 说明 |
|---|---|---|
| 后端框架 | Go Gin | 高性能Web框架,支持SSE流式输出 |
| ORM框架 | GORM | Go语言最流行的ORM库 |
| 数据库 | PostgreSQL + pgvector | 关系数据库 + 向量检索扩展 |
| 大模型 | 千问大模型(Qwen) | 阿里云通义千问,支持流式调用 |
| 前端框架 | Vue 3 + Element Plus | 现代化前端框架,良好的用户体验 |
| 部署容器 | Docker + Docker Compose | 一键部署,环境隔离 |
2.2 系统架构图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 前端Vue │────▶│ Gin服务 │────▶│ PostgreSQL│
│ ElementUI │◀────│ (SSE流式) │◀────│ +pgvector │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌─────────────┐
│ 千问大模型 │
│ (Qwen API) │
└─────────────┘
三、核心功能实现
3.1 数据库设计
知识库主表
CREATE TABLE knowledge_base (
id BIGSERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
category TEXT,
status INTEGER NOT NULL DEFAULT 1,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
知识库分块表(支持向量检索)
CREATE TABLE knowledge_chunks (
id BIGSERIAL PRIMARY KEY,
knowledge_doc_id BIGINT NOT NULL,
chunk_id TEXT NOT NULL,
content TEXT NOT NULL,
ext TEXT,
status INTEGER NOT NULL DEFAULT 1,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
embedding vector(1536) -- 向量字段
);
3.2 RAG检索增强生成
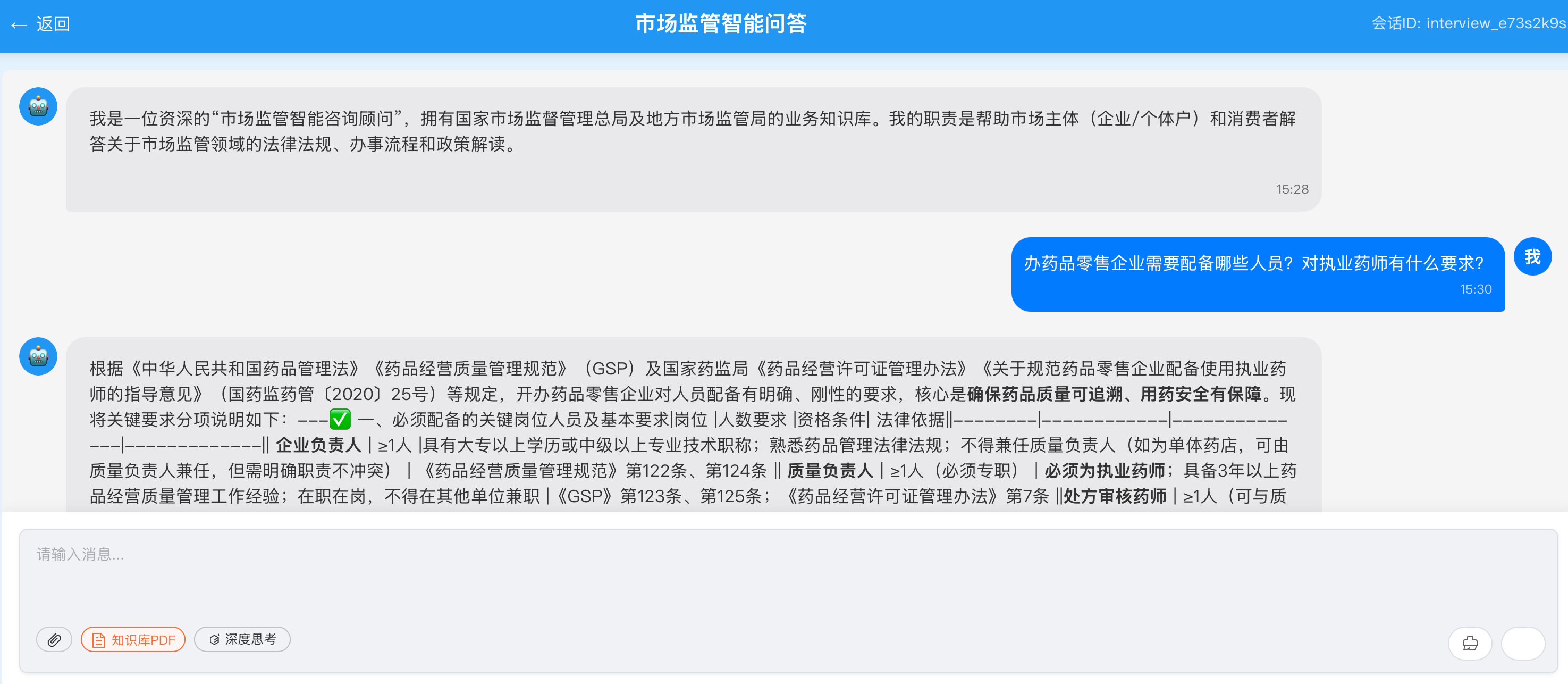
RAG的核心思想是在大模型生成答案前,先从知识库中检索相关文档,作为上下文输入给大模型,从而提升回答的准确性和专业性。
// RAG服务核心代码
func (r *RAGService) AnswerStream(ctx context.Context, query string, sendEvent func(string)) error {
// 1. 向量检索相关文档
docs, err := r.Retrieve(ctx, query, r.TopK)
if err != nil {
return err
}
// 2. 构建System Prompt
systemPrompt := buildQAPrompt(query, docs)
// 3. 流式调用大模型
return CallLLMStream(systemPrompt, query, func(chunk string) {
sendEvent(chunk) // 实时推送
})
}
3.3 向量检索优化
func (r *RAGService) Retrieve(ctx context.Context, query string, topK int) ([]models.LawDocument, error) {
// 生成查询向量(带缓存)
emb, err := r.getOrGenerateEmbedding(query)
if err != nil {
return nil, err
}
var docs []models.LawDocument
// 使用pgvector的余弦距离排序,并过滤低相似度结果
err = r.DB.WithContext(ctx).
Model(&models.LawDocument{}).
Select("id, title, content, source").
Where("embedding <=> ? < ?", pgvector.NewVector(emb), r.SimilarityThreshold).
Order("embedding <=> ?", pgvector.NewVector(emb)).
Limit(topK).
Find(&docs).Error
return docs, err
}
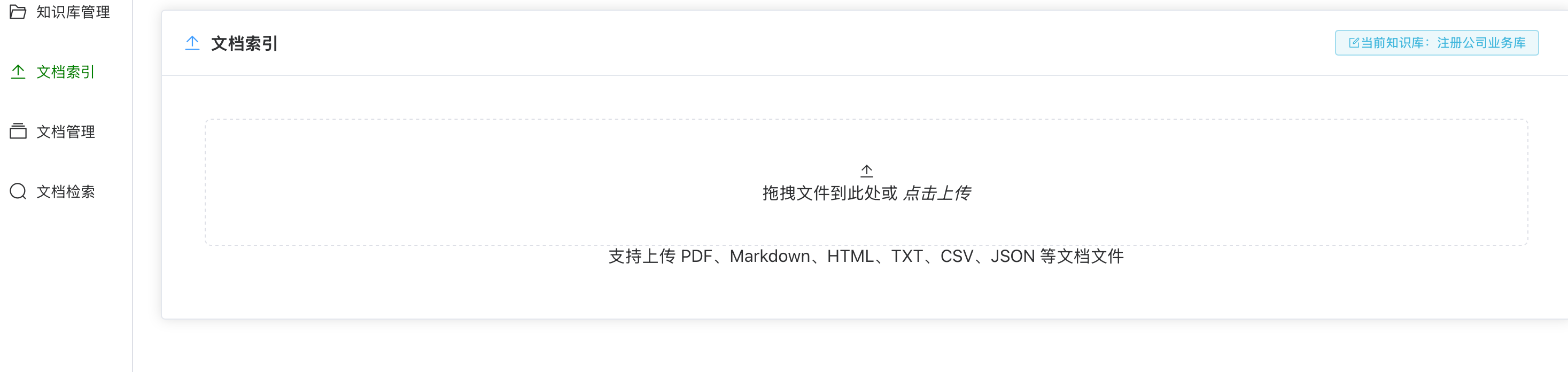
3.4 PDF知识库构建
系统支持上传PDF文档,自动解析、分块、向量化后存入知识库:
func (s *PDFUploadService) UploadPDFWithKnowledgeBase(
ctx context.Context,
knowledgeBaseID uint,
fileName string,
fileData []byte,
) (int, error) {
// 1. 提取PDF文本
text, err := ExtractTextFromPDF(fileData)
// 2. 文本分块(每块500字符,重叠50字符)
chunks := ChunkText(text, 500, 50)
// 3. 生成向量并批量入库
for _, chunk := range chunks {
embedding, _ := GenerateEmbedding(chunk.Content)
chunkModel := models.KnowledgeChunk{
Content: chunk.Content,
Embedding: embedding,
}
chunkModels = append(chunkModels, chunkModel)
}
// 4. 批量插入数据库
return s.DB.CreateInBatches(chunkModels, 100).Error
}
3.5 SSE流式输出
为了提升用户体验,系统采用SSE(Server-Sent Events)实现大模型答案的实时流式输出:
func (qc *QAController) Ask(c *gin.Context) {
// 设置SSE响应头
c.Writer.Header().Set("Content-Type", "text/event-stream")
c.Writer.Header().Set("Cache-Control", "no-cache")
c.Writer.Header().Set("Connection", "keep-alive")
sendEvent := func(data string) {
c.Writer.Write([]byte(fmt.Sprintf("data: %s\n\n", data)))
c.Writer.Flush()
}
// 调用流式问答
qc.RAG.AnswerStream(c.Request.Context(), req.Question, sendEvent)
}
四、项目部署
4.1 Docker Compose一键部署
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: yourpassword
POSTGRES_DB: market_intel
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
app:
build: .
ports:
- "8080:8080"
depends_on:
- postgres
environment:
DB_HOST: postgres
QIANWEN_API_KEY: ${QIANWEN_API_KEY}
4.2 启动命令
# 设置环境变量
export QIANWEN_API_KEY=sk-xxx
# 一键启动
docker-compose up -d
# 查看日志
docker-compose logs -f app
五、核心优化策略
5.1 向量缓存机制
对于相同或相似的问题,缓存查询向量,减少API调用:
var embeddingCache = cache.New(5*time.Minute, 10*time.Minute)
func (r *RAGService) getOrGenerateEmbedding(text string) ([]float64, error) {
if cached, found := embeddingCache.Get(text); found {
return cached.([]float64), nil
}
emb, err := GenerateEmbedding(text)
if err == nil {
embeddingCache.Set(text, emb, cache.DefaultExpiration)
}
return emb, err
}
5.2 相似度阈值过滤
只返回余弦距离低于阈值的文档,避免低质量结果影响回答质量:
Where("embedding <=> ? < ?", pgvector.NewVector(emb), 0.8)
5.3 PDF文本清理
处理PDF提取中的编码问题,确保文本有效的UTF-8:
func sanitizeUTF8(s string) string {
if !utf8.ValidString(s) {
s = strings.ToValidUTF8(s, "�")
}
var result strings.Builder
for _, r := range s {
if r == utf8.RuneError {
continue
}
result.WriteRune(r)
}
return result.String()
}
六、性能测试结果
| 测试场景 | 响应时间 | 说明 |
|---|---|---|
| 向量检索 | <50ms | 使用pgvector HNSW索引 |
| 大模型首字 | <2s | 千问大模型首Token延迟 |
| PDF上传(10MB) | <15s | 含解析、分块、向量化 |
| 并发问答(10) | <3s | 平均响应时间 |
七、项目亮点
- 智能问答:基于RAG技术,打破传统关键词检索局限,实现"即问即答"
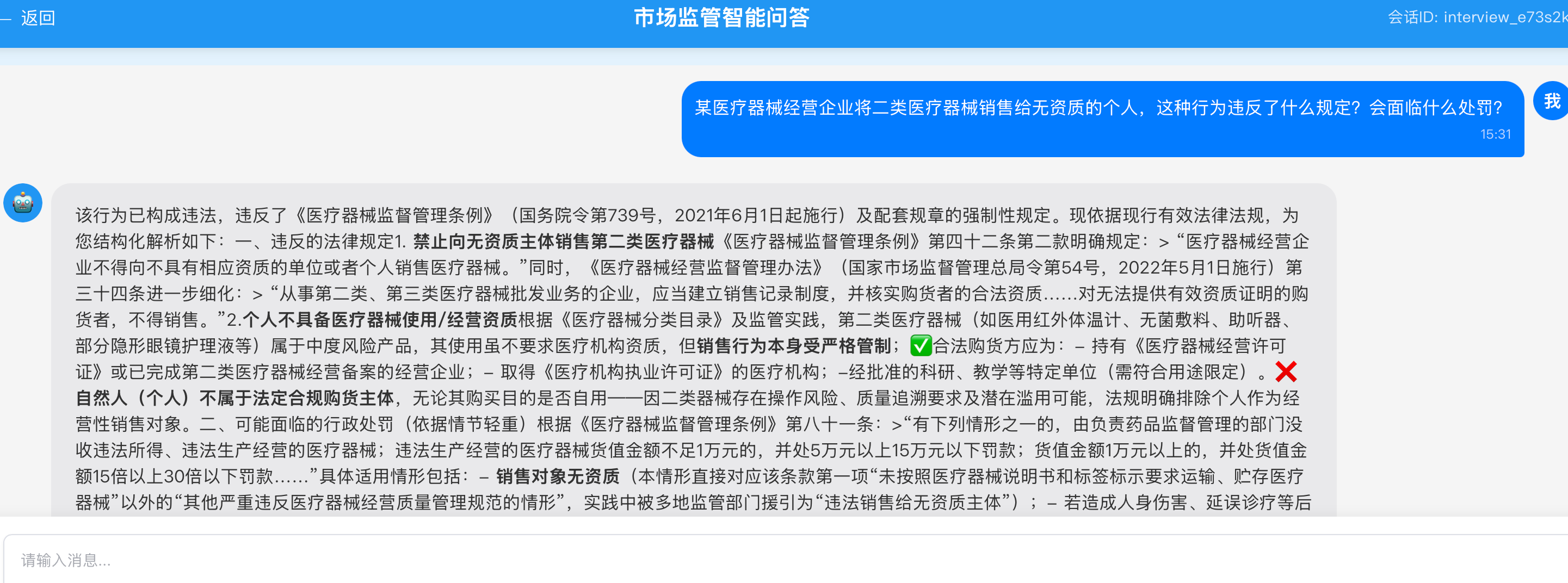
- 执法辅助:自动识别违法行为,生成《检查记录表》《责令整改通知书》等执法文书
- 语音驱动:支持语音输入,实现"一语即中的"的监管新模式
- 知识库持续优化:通过用户反馈机制,不断优化提示词和知识库质量
- 流式输出:SSE技术实现实时响应,用户体验流畅
八、总结
本文基于Go语言和千问大模型,结合RAG技术,构建了一套完整的市场监管智能问答系统。系统实现了法规智能解析、执法文书自动生成、知识库管理、语音输入等核心功能,有效提升了市场监管咨询服务的响应效率和准确度。
未来将持续优化:
- 引入更多大模型适配(如GPT、Claude)
- 增加多轮对话能力
- 优化向量检索算法(HNSW索引)
- 实现用户行为分析和个性化推荐
作者简介:资深后端开发工程师,专注于Go语言、大模型应用和云原生技术。欢迎技术交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)