[AI/GPT] Hugging Face : 开源大模型社区 | 机器学习(ML)和数据科学平台和社区、AI领域的Github
概述:Hugging Face
简介
- Hugging Face(抱抱脸)是一个机器学习(ML)和数据科学平台和社区,帮助用户构建,部署和训练机器学习模型,成立于2016年的人工智能公司。
作为一个流行的自然语言处理 (NLP) 模型库和社区,提供了大量预训练模型、工具和资源,使得 NLP 的开发者和研究人员能够快速高效地构建和应用各种文本相关应用。
抱脸相当于Ai界的GitHub,里面的模型都是开源免费的,非常适合AI开发者使用。
- url
- 专注领域: 开源人工智能库
- Hugging Face提供了在实时应用程序中演示、运行和部署人工智能(AI)的基础设施。用户还可以浏览其他人上传的模型和数据集。
Hugging Face通常被称为机器学习的GitHub,因为它允许开发人员公开分享和测试他们的工作。
开源大模型社区: HuggingFace vs ModelScope(魔搭社区)
- HuggingFace:类似于github,模型比较全,但是需要 ke.xue 上网;
- ModelScope/魔搭:阿里开源的大模型平台,模型相对不是很全,速度比较快;
- HuggingFace的优点:
- 丰富的预训练模型资源:
- 广泛的适用性:Hugging Face 提供了大量的预训练模型,这些模型已经在海量的数据上进行了训练,能够处理各种自然语言处理任务,如文本分类、情感分析、问答、机器翻译等。无论您是从事学术研究、商业应用还是个人项目开发,都可以找到适合的预训练模型,节省大量从头训练模型的时间和资源。
- 高质量与不断更新:其预训练模型经过了专业的训练和优化,具有较高的性能和准确性。而且,Hugging Face 平台不断更新和改进模型,以适应不断变化的自然语言处理需求和技术发展。
- 方便的工具和库:
- Transformers 库:Hugging Face 的 Transformers 库是自然语言处理领域的重要工具,它支持多种预训练模型的加载、使用和微调,如 BERT、GPT、RoBERTa 等。该库提供了简单易用的接口,使得开发者可以轻松地将这些强大的模型集成到自己的项目中,快速实现自然语言处理功能。
- 数据集管理工具:Hugging Face 提供了方便的数据集管理工具,如 Datasets 库,可以帮助用户轻松地下载、处理和管理各种公开的数据集。这使得数据的准备工作变得更加高效,减少了数据处理过程中的繁琐操作。
发展历程
- 2016年,公司成立。 首席执行官&联合创始人为
Clément Delangue。
2016年,法国创业者三名创业者Clément Delangue、Julien Chaumond 和 Thomas Wolf 在纽约成立了Hugging Face。
- 2016-2017:聊天机器人(第一个产品)
- Hugging Face,它的第一个产品是一个聊天机器人。
- 到2017年,Hugging Face聊天机器人拥有了独特的功能,并可以进行高效的对话。
- 团队将其产品定位为为无聊青少年量身打造的个性鲜明的聊天机器人。
- 2018年5月,完成种子融资。通过本轮融资,Hugging Face团队继续专注于以下领域:改进产品;建立一支优秀的工程师团队;深入研发自然语言对话,并撰写了几篇研究论文。
虽然当时产品还没有带来可观的收入,但团队对核心价值和技术共享的强调为Hugging Face创造了一个转折点。
- 2018 年,Hugging Face迎来了关键时刻,
Hugging Face的创始人在网上免费分享该应用的部分代码,其中一个重要的开源框架名为Transformers,目前已被下载超过一百万次。
GitHub项目获得了上万颗星,这表明开源社区认为它很有价值。- 微软、谷歌和 Facebook 的研究人员一直在用它做实验,某些公司甚至在生产中使用了它。
Transformers可用于各种任务,包括文本分类、信息提取、总结、文本生成和对话式人工智能。- 最终,Hugging Face团队迎来了一个转折点,将公司从一家不太赚钱的AI聊天机器人初创公司转变为未来估值十亿美元的AI独角兽。
-
在接下来的几年里,Hugging Face 团队继续专注于产品建设和社区发展,并取得了令人瞩目的成就:
-
2024年1月,Hugging Face宣布与谷歌云(Google Cloud)建立战略合作伙伴关系。
-
2024年10月,Hugging Face更新了月度榜单,智源研究院的BGE模型登顶榜首,这是中国国产AI模型首次成为Hugging Face月榜冠军。BGE在短短一年时间内,总下载量已超数亿次,是目前下载量最多的国产AI系列模型。
-
Hugging Face已成为扩展最快的社区和使用最广泛的机器学习平台!
- 平台上有 10 万个预训练模型和 1 万个数据集,涵盖 NLP、语音、时间序列、强化学习、计算机视觉、生物、化学等领域。
- Hugging Face Hub 已发展成为机器学习构建者开发、协作和部署尖端模型的家园。
- 目前有10000 多家公司使用 Hugging Face来构建机器学习技术,Hugging Face 帮助这些机器学习工程师和数据科学家团队节省了大量时间,加快了机器学习项目的进度。
Hugging Face还领导着BigScience,一个专注于研究和构建大语言模型的合作研讨会。这项计划汇集了来自不同领域和背景的1000多名研究人员,BigScience致力于训练世界上最大的开源多语言模型。
Hugging Face为什么能成功?
-
赶上
Transformer相继在AI的细分领域NLP、泛AI领域爆火; -
军阀混战,谷歌TensorFlow Bert, FaceBook PyTorch,跑一下模型需要各种环境;
-
人家是一个舞台/平台,不是一个工具,那后来的人,也只能在这上面玩。
Models / Spaces / Datasets
Hugging Face是一个旨在推动自然语言处理(NLP)技术和工具发展的开源社区和公司。
平台有海量的开源模型,以及数据集,致力于提供各种NLP任务中的最新技术、模型和工具,为开发者提供便捷的方式来使用、微调和部署这些技术。
https://pic2.zhimg.com/v2-c656c728e5c1f378972e7d3bcc5d20eb_1440w.jpg
模型Model
https://pic2.zhimg.com/v2-9691c0bbe5ac744be87468198bc7adb5_1440w.jpg
- 自然语言处理:文本分类、文本生成,文本转语音、文本填空、文本摘要等;
- 计算机视觉:图片分类、物体识别、文本转图片、题、图片转文本、图片特征提取等;
- 音频:文本转语音、语音转文本、语音识别、语音分类等;
- 多模态:Image-Text-to-Text、Video-Text-to_text
数据集/DataSet
https://pic4.zhimg.com/v2-682e9023c1951264abb6ad74e3781e0d_1440w.jpg
- 互联网开源的一些最标准的语料库,可以用来训练或者微调你的模型,其特点为:
- 包含丰富的数据集:IMDB, CoNLL-2003和GLUE等;
- 简化数据集的下载、预处理操作;
- 提供数据集分割、采样和迭代器的功能;
应用/Spaces
https://pic4.zhimg.com/v2-b7fe3f9d7c2147d40bc38925e80cfe61_1440w.jpg
2 应用指南
安装篇 for Hugging Face
安装 Hugging Face
-
在命令行中输入 pip install transformers 就可以安装 Hugging Face 的 transformers 库。
-
两大模块的对比 : transformers vs. huggingface-hub
| 特性 | transformers |
huggingface-hub |
|---|---|---|
| 核心目的 | 运行和训练模型 | 管理和传输模型文件 |
| 是否包含模型架构 | 是 (BERT, GPT, ViT 等代码) | 否 (只管文件,不管内容) |
| 能否直接推理 | 能 (pipeline, model.generate) |
不能 (只能下载文件) |
| 能否上传模型 | 能 (通过内置的 push_to_hub 方法,底层调用 hub 库) |
能 (原生支持上传功能) |
| 安装包大小 | 较大 (包含大量模型代码) | 较小 (轻量级工具) |
| 依赖关系 | 包含 huggingface-hub |
不包含 transformers |
| 典型用户 | 算法工程师、数据科学家、应用开发者 | MLOps 工程师、需要自定义下载逻辑的开发者 |
前置环境安装
- conda
- python 3.10
- cuda 安装(可选)
安装 Hugging Face 底层交互工具库 : hf_hub_download
- 安装 Hugging Face 底层交互工具库
安装的是底层交互工具库。它主要用于与 Hugging Face Hub(模型托管平台)进行交互,比如下载文件、上传模型、管理仓库、登录账号等。它不包含运行模型所需的神经网络架构代码。
- 主要功能:提供了一个 Python 客户端,用于与 https://huggingface.co 网站进行文件级交互。它不关心模型内部是怎么运行的,只关心文件的下载、上传和管理。
- 核心功能:
- hf_hub_download: 下载特定的文件(不仅仅是模型权重,也可以是数据集、配置文件等)。
- upload_folder: 将本地文件夹上传到 Hub 仓库。
- login / logout: 管理访问令牌。
- 创建仓库、删除文件等管理操作。
# 代码示例 |
|
from huggingface_hub import hf_hub_download |
|
# 仅下载文件到本地缓存,返回文件路径 |
|
file_path = hf_hub_download( |
|
repo_id="bert-base-uncased", |
|
filename="pytorch_model.bin" |
|
) |
|
print(f"文件已下载到: {file_path}") |
|
# 注意:这里你还无法直接运行模型,因为没有加载逻辑 |
- 使用场景:
你想下载一个大模型的权重文件,但不想立即加载它,或者想手动管理缓存。
你训练好了自己的模型,想要上传到 Hugging Face Hub 分享给社区。
你在编写一个轻量级工具,只需要下载资源而不需要完整的 transformers 重型依赖。
- 依赖关系:非常轻量,主要依赖 requests, filelock, fsspec 等。它不会安装 transformers 或 torch。
#pip install huggingface-hub |
|
#pip install --upgrade huggingface-hub |
|
pip install -U huggingface_hub |
安装 Hugging Face 核心模型库 : transformers
- 安装 Hugging Face 核心模型库
安装的是核心模型库。如果你想要加载、运行或微调具体的 AI 模型(如 BERT, GPT, Llama 等),你需要这个。它通常会自动把
huggingface-hub作为依赖项一起安装。
- 主要功能:提供了数千种预训练模型(用于文本、图像、音频等)的架构实现和推理/训练代码。
- 核心类:AutoModel, AutoTokenizer, Pipeline 等。
- 使用场景:
- 加载一个模型进行推理(例如:情感分析、文本生成)。
- 微调(Fine-tuning)一个预训练模型。
- 使用
pipeline快速调用任务。
例如:
from transformers import pipeline |
|
# 直接加载并运行模型 |
|
classifier = pipeline("sentiment-analysis") |
|
print(classifier("I love using Hugging Face!")) |
- 依赖关系:安装 transformers 时,pip 自动会安装 huggingface-hub、torch (PyTorch) 或 tensorflow、numpy 等必要的依赖库。
pip install transformers |
安装 Hugging Face : datasets / tokenizers
pip install datasets tokenizers |
查验版本
#(ai-env) PS D:\xxxx\> huggingface-cli version |
|
⚠️ Warning: 'huggingface-cli version' is deprecated. Use 'hf version' instead. |
|
huggingface_hub version: 0.36.2 |
|
#(ai-env) PS D:\xxxx\> hf version |
|
huggingface_hub version: 0.36.2 |
模型管理
使用场景
浏览 Hugging Face 的模型库
- 找到适合你项目需求的模型。
- 可以通过搜索或筛选来缩小范围。
- 点击模型名称进入模型主页,可以查看模型的详细信息、用法示例、源代码等。
下载并使用模型
- 使用
from transformers import MODEL_NAME导入模型。 - 实例化模型:
model = MODEL_NAME.from_pretrained('MODEL_NAME')。其中 MODEL_NAME 是模型的名称或路径。 - 准备输入数据,转换为模型支持的格式。(如 tokenizer 后的文本、图像等)
- 调用模型并获得输出:
outputs = model(inputs)。其中 inputs 是模型的输入数据。
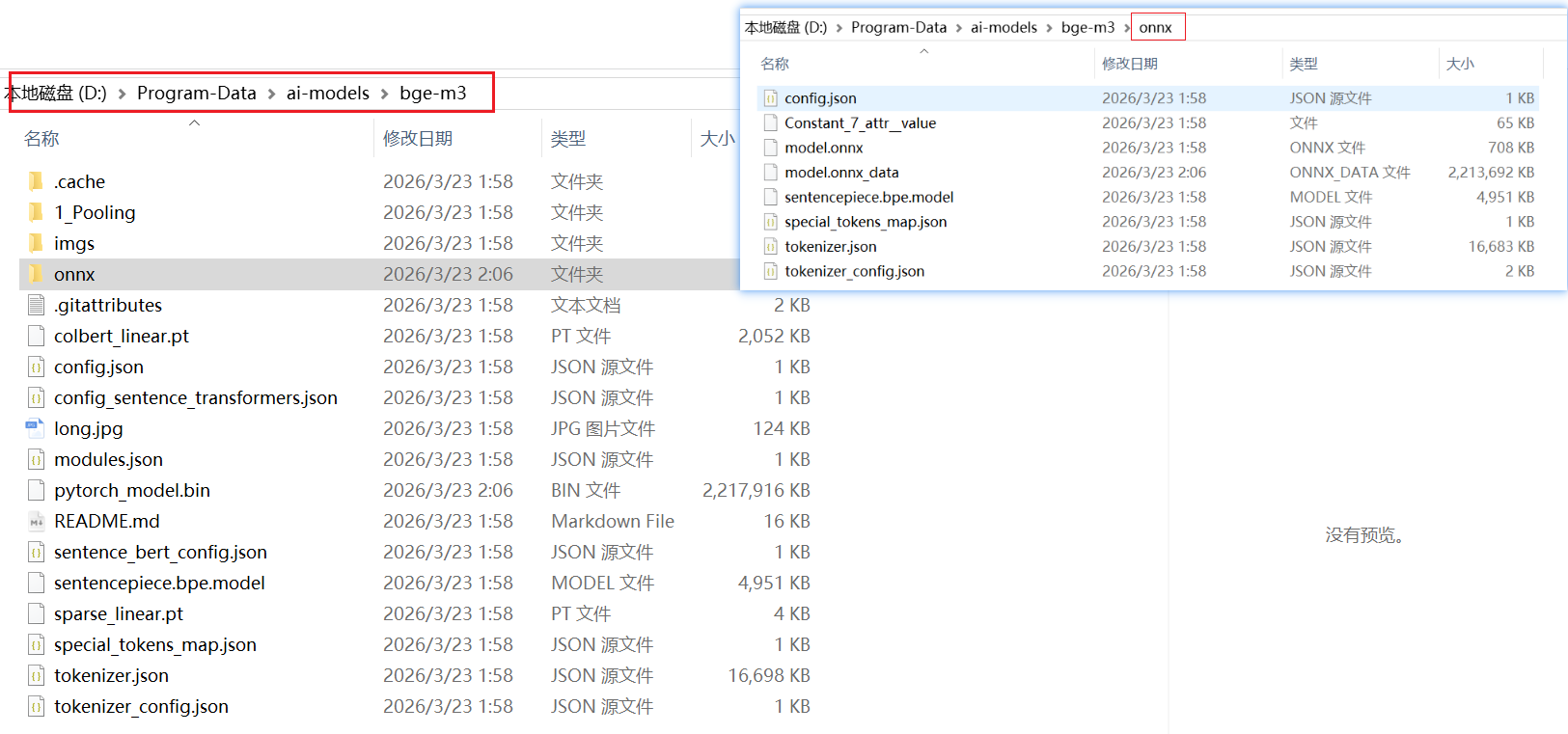
- 手动下载模型
huggingface-cli --resume-download BAAI/bge-m3 --local-dir D:/Program-Data/ai-models/bge-m3 |
|
或 |
|
huggingface-cli --endpoint=https://hf-mirror.com download --resume-download BAAI/bge-m3 --local-dir D:/Program-Data/ai-models/bge-m3 |
保存和加载模型
- 使用
model.save_pretrained('PATH')将模型保存到指定路径。 - 使用
MODEL_NAME.from_pretrained('PATH')来加载模型。
效果展示-文本分类
from transformers import pipeline, AutoTokenizer |
|
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") |
|
model = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english") |
|
text = "This movie is really good!" |
|
inputs = tokenizer(text, return_tensors="pt") |
|
outputs = model(**inputs) |
|
print(f"Input text: {text}") |
|
print(f"Predicted label: {outputs[0]['label']}, score: {outputs[0]['score']:.2f}") |
out:
Input text: This movie is really good! |
|
Predicted label: POSITIVE, score: 0.99 |
效果展示-命名实体识别
from transformers import pipeline, AutoTokenizer |
|
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") |
|
model = pipeline("ner", model="dslim/bert-base-NER") |
|
text = "Hugging Face is a startup based in New York City" |
|
inputs = tokenizer(text, return_tensors="pt") |
|
outputs = model(**inputs) |
|
for entity in outputs: |
|
print(f"Entity: {entity['word']}, Type: {entity['entity']}, Score: {entity['score']:.2f}") |
out:
Entity: New, Type: B-LOC, Score: 0.24 |
|
Entity: York, Type: I-LOC, Score: 0.28 |
|
Entity: City, Type: I-LOC, Score: 0.25 |
高阶玩法
Fine-tuning 模型
- 在 Hugging Face 中,我们可以使用预训练模型进行 fine-tuning,以适应特定任务或领域的需求。以下是一个简单的示例:
from transformers import Trainer, TrainingArguments |
|
training_args = TrainingArguments( |
|
output_dir='./results', |
|
num_train_epochs=1, |
|
per_device_train_batch_size=16, |
|
per_device_eval_batch_size=64, |
|
warmup_steps=500, |
|
weight_decay=0.01, |
|
logging_dir='./logs', |
|
) |
|
trainer = Trainer( |
|
model=model, |
|
args=training_args, |
|
train_dataset=train_dataset, |
|
eval_dataset=eval_dataset, |
|
) |
|
trainer.train() |
- 自定义模型和 Tokenizer: 如果 Hugging Face 提供的现成模型无法满足需求,我们可以通过继承 PreTrainedModel 和 PreTrainedTokenizer 类来创建自己的模型和 Tokenizer。
- 使用Hugging Face Hub: Hugging Face Hub 是一个在线平台,可以轻松共享、发现和使用各种 NLP 模型。我们可以使用 upload() 函数将自己的模型上传到 Hub 上,并使用 from_pretrained() 函数来加载其他人分享的模型。
J 最佳实践
CASE bge-m3嵌入模型的下载示例
- 假设需将模型下载至本地路径:
D:\Program-Data\ai-models\bge-m3
model_download.py
# @install-command pip install -U huggingface_hub |
|
from huggingface_hub import snapshot_download |
|
# 下载完整模型到指定目录 |
|
model_local_dir=r"D:\Program-Data\ai-models\bge-m3" |
|
snapshot_download( |
|
endpoint="https://hf-mirror.com", # 可选配置项 |
|
repo_id="BAAI/bge-m3", |
|
local_dir=model_local_dir, # 使用 r"" 处理 Windows 路径 |
|
local_dir_use_symlinks=False, # Windows 建议禁用符号链接 (deprecated 配置项) |
|
resume_download=True, # 支持断点续传 (deprecated 配置项) |
|
ignore_patterns=[".DS_Store", "**/.DS_Store"], # 关键:忽略指定的 .DS_Store 等无关紧要但又阻塞下载使用的文件 (可选配置项) |
|
max_workers=4 # 可选配置项 |
|
) |
CASE bge-m3嵌入模型的使用示例
- 假设已将模型下载至本地路径:
D:\Program-Data\ai-models\bge-m3
model_use.py
model_use.py
import torch |
|
from transformers import AutoModel, AutoTokenizer |
|
# @install-command : pip install transformers -U |
|
# 设置模型本地路径 |
|
MODEL_PATH = r"D:\Program-Data\ai-models\bge-m3" |
|
def load_bge_m3_model(model_path): |
|
""" |
|
加载本地的 BGE-M3 模型和分词器 |
|
""" |
|
# 加载(本地模型目录下的)分词器 |
|
tokenizer = AutoTokenizer.from_pretrained( |
|
model_path, |
|
trust_remote_code=True # 信任远程代码(本地模型也建议开启) |
|
) |
|
print(f"分词器(`{model_path}`)加载成功, 词汇表大小: {len(tokenizer)}") |
|
# 加载(本地模型目录下的)模型 |
|
model = AutoModel.from_pretrained( |
|
model_path, |
|
trust_remote_code=True, |
|
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32 # 根据GPU情况选择精度 |
|
) |
|
model = AutoModel.from_pretrained(model_path) |
|
print(f"模型加载成功!model_path:{model_path}") |
|
# 如果有GPU则使用GPU |
|
if torch.cuda.is_available(): |
|
model = model.cuda() |
|
model.eval() # 设置为评估模式 |
|
return tokenizer, model |
|
def text_to_vector(text, tokenizer, model, max_length=512): |
|
""" |
|
将文本转换为词向量 |
|
:param text: 输入文本 |
|
:param tokenizer: 分词器 |
|
:param model: BGE-M3 模型 |
|
:param max_length: 最大序列长度 |
|
:return: 归一化后的词向量 |
|
""" |
|
# 文本预处理(BGE-M3 建议添加指令以提升效果) |
|
if isinstance(text, str): |
|
text = [text] |
|
# 为文本添加指令(BGE-M3 推荐的做法) |
|
texts = [f"为句子生成表示以用于检索:{t}" for t in text] |
|
# 分词处理 |
|
inputs = tokenizer( |
|
texts, |
|
padding=True, |
|
truncation=True, |
|
max_length=max_length, |
|
return_tensors="pt" |
|
) |
|
# 如果有GPU则将数据移到GPU |
|
if torch.cuda.is_available(): |
|
inputs = {k: v.cuda() for k, v in inputs.items()} |
|
# 模型推理(不计算梯度以提升速度) |
|
with torch.no_grad(): |
|
outputs = model(**inputs) |
|
# 获取 cls token 的输出作为句子向量 |
|
embeddings = outputs.last_hidden_state[:, 0] |
|
# 对向量进行归一化(重要:BGE-M3 推荐归一化后再使用) |
|
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1) |
|
# 转换为 numpy 数组(方便后续使用) |
|
return embeddings.cpu().numpy() |
|
# 主程序 |
|
if __name__ == "__main__": |
|
# 1. 加载模型 |
|
print("正在加载 BGE-M3 模型...") |
|
tokenizer, model = load_bge_m3_model(MODEL_PATH) |
|
print("模型加载完成!") |
|
# 2. 待向量化的文本 |
|
test_texts = [ |
|
"人工智能的发展前景", |
|
"自然语言处理技术应用", |
|
"深度学习模型的优化方法" |
|
] |
|
# 3. 转换为词向量 |
|
print("\n正在将文本转换为词向量...") |
|
vectors = text_to_vector(test_texts, tokenizer, model) |
|
# 4. 输出结果 |
|
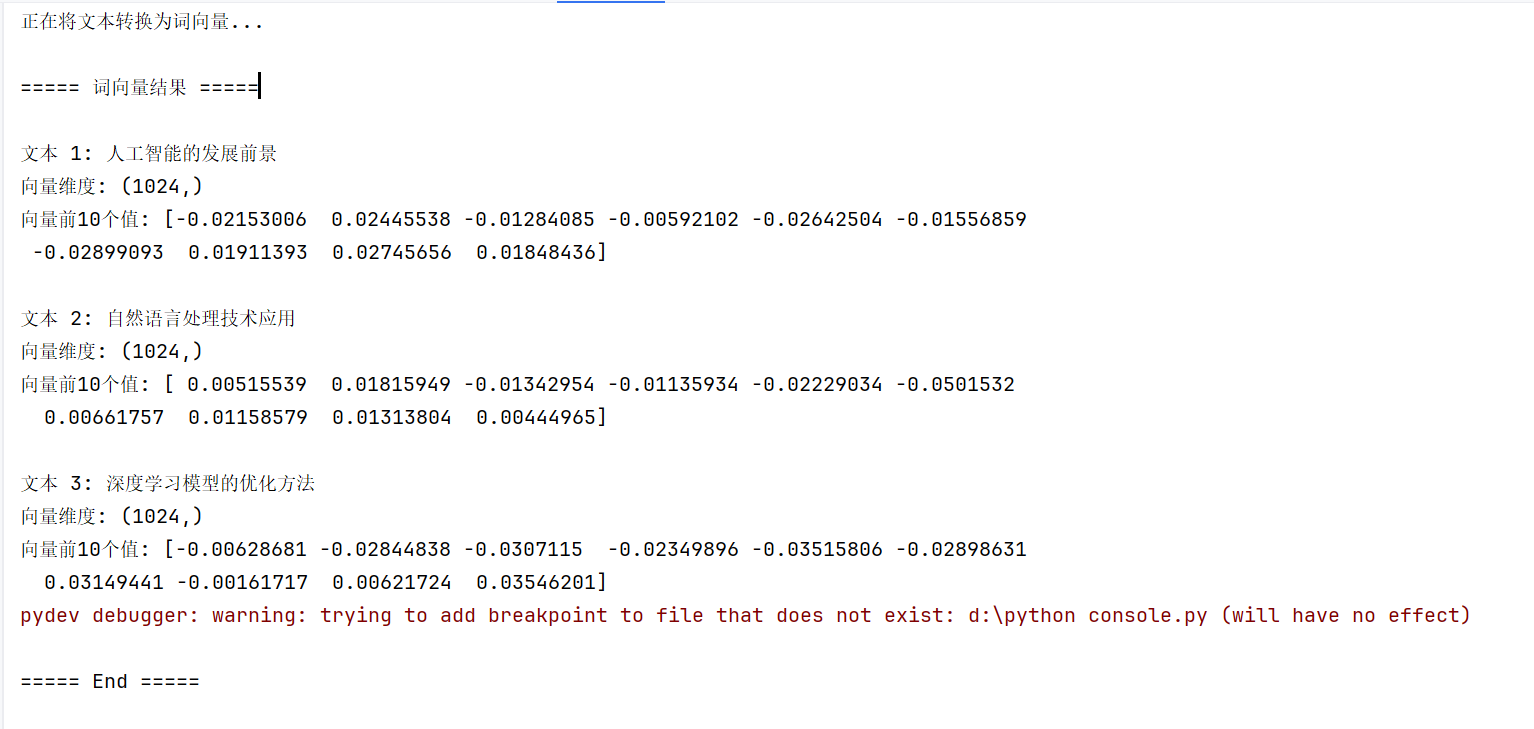
print("\n===== 词向量结果 =====") |
|
for i, (text, vector) in enumerate(zip(test_texts, vectors)): |
|
print(f"\n文本 {i + 1}: {text}") |
|
print(f"向量维度: {vector.shape}") |
|
print(f"向量前10个值: {vector[:10]}") |
|
print("\n===== End =====") |
output
正在加载 BGE-M3 模型... |
|
`torch_dtype` is deprecated! Use `dtype` instead! |
|
Loading weights: 100%|██████████| 391/391 [00:00<00:00, 5099.31it/s] |
|
模型加载完成! |
|
正在将文本转换为词向量... |
|
===== 词向量结果 ===== |
|
文本 1: 人工智能的发展前景 |
|
向量维度: (1024,) |
|
向量前10个值: [-0.02153006 0.02445538 -0.01284085 -0.00592102 -0.02642504 -0.01556859 |
|
-0.02899093 0.01911393 0.02745656 0.01848436] |
|
文本 2: 自然语言处理技术应用 |
|
向量维度: (1024,) |
|
向量前10个值: [ 0.00515539 0.01815949 -0.01342954 -0.01135934 -0.02229034 -0.0501532 |
|
0.00661757 0.01158579 0.01313804 0.00444965] |
|
文本 3: 深度学习模型的优化方法 |
|
向量维度: (1024,) |
|
向量前10个值: [-0.00628681 -0.02844838 -0.0307115 -0.02349896 -0.03515806 -0.02898631 |
|
0.03149441 -0.00161717 0.00621724 0.03546201] |
|
pydev debugger: warning: trying to add breakpoint to file that does not exist: d:\python console.py (will have no effect) |
|
===== End ===== |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)