RAG还是微调?同事吵了三天没结果,我拿出一张对比表,全员沉默后疯狂点赞!

文章目录
一、前言:AI 界的"买书还是请私教"难题

嗨,小伙伴们!今天咱们来聊一个让无数 AI 开发者深夜辗转反侧的灵魂拷问:
到底是搞 RAG(检索增强生成),还是 Fine-tuning(微调模型)?
这问题就像是在问:“我想学做菜,是该买一堆菜谱书,还是直接请个米其林大厨上门教学?”
答案其实很简单——看你的钱包,也看你的需求 😂
别急,今天我就用最接地气的方式,把这两个技术掰开了、揉碎了讲清楚。看完这篇文章,保证你能在下次技术评审会上侃侃而谈,让老板对你刮目相看!
二、核心概念解析:这不是玄学,是科学
2.1 RAG(检索增强生成):外挂知识库,解决"不知道"的问题

RAG = Retrieval-Augmented Generation,中文翻译过来就是"带小抄的考试"。
专业解释
RAG 是一种将外部知识库与大语言模型相结合的技术架构。当用户提出问题时,系统会:
- 检索(Retrieval):从预设的知识库中搜索相关文档片段
- 增强(Augmented):将检索到的内容作为上下文注入到提示词中
- 生成(Generation)):模型基于这些上下文生成最终答案
大白话解读
想象一下,你是一个学霸,但你的大脑容量有限。考试时老师允许你带一本无限厚的参考书:
- 你遇到了不知道的题目 → 翻书找答案
- 你遇到了见过的题型 → 直接作答
- 翻书 + 脑子= 完美答题
这就是 RAG 的本质:模型本身很聪明,但知识有限,给它外挂一个"知识百宝箱",就能解决"不知道"的问题。
生活案例:RAG 在现实中的影子

场景 1:企业客服机器人
某电商公司的客服 AI 被问到:“你们家最新款的 iPhone 16 Pro Max 什么时候有货?”
- 没有 RAG:AI 一脸懵逼:“我不知道 iPhone 是什么……”
- 有 RAG:AI 快速检索库存数据库:“亲,iPhone 16 Pro Max 将在下周三正式开售,记得定闹钟哦!”
场景 2:医疗咨询助手
用户问:“我有高血压,能吃这个药吗?”
- 没有 RAG:AI:“建议咨询专业医生”(标准但无用的废话)
- 有 RAG:AI 检索权威医疗指南后回答:“根据最新临床指南,高血压患者可以服用此药,但需注意剂量控制,建议……”
RAG 的优缺点速览
| 优点 | 缺点 |
|---|---|
| 成本低:无需训练模型,只需搭建知识库 | 知识时效依赖:如果知识库更新不及时,AI 会"一本正经地胡说八道" |
| 更新快:新文档入库即可,无需重新训练 | 检索精度依赖:检索不准确会影响回答质量 |
| 可解释性强:可以溯源回答来源 | 上下文长度限制:文档太长可能会被截断 |
| 领域适应性强:换个行业知识库即可 | 推理能力有限:仍然是原始模型的推理能力 |
2.2 Fine-tuning(微调模型):内功修炼,解决"学不会"的问题

Fine-tuning = Model Fine-tuning,中文翻译就是"强化训练"。
专业解释
Fine-tuning 是指在一个预训练好的大语言模型基础上,使用特定领域的数据进行进一步训练,使模型掌握特定的:
- 知识格式(如 JSON、XML、代码风格)
- 语气风格(如专业严谨、活泼幽默)
- 指令遵循能力(如多轮对话、复杂任务分解)
- 领域专长(如法律条文、医学诊断)
这个过程就像给一个已经读过万卷书的博士,再进行专业化的岗前培训。
大白话解读
还记得前面"学做菜"的比喻吗?
- RAG = 买一堆菜谱书,遇到不会做的菜翻书查
- Fine-tuning = 请大厨手把手教,让你形成肌肉记忆,下次做类似的菜,不用翻书也能信手拈来
Fine-tuning 不是让模型"变聪明"(智商不变),而是让模型"变专业"(技能专精)。
生活案例:Fine-tuning 的实战威力

场景 1:法律文书生成器
某律所开发了一个 AI 助手,需要生成专业的法律文书:
- 原始模型:生成的文书像 AI 写的,缺乏法律专业术语,格式不规范
- Fine-tuning 后:收集了 1000 份真实律师手写文书,训练后的模型生成的文书:
- 格式完美(起诉状的标准结构)
- 用词精准("应当"vs"可以"的法律区别)
- 语气严谨(符合法律文书的严肃性)
场景 2:代码生成助手
- 原始模型:能写代码,但代码风格不统一,变量命名随意
- Fine-tuning 后:训练了企业内部代码规范,模型生成的代码:
- 符合团队代码规范(PEP 8、Google Java Style)
- 变量命名统一(驼峰 vs 下划线)
- 注释风格一致
Fine-tuning 的优缺点速览
| 优点 | 缺点 |
|---|---|
| 风格统一:输出内容符合特定风格要求 | 成本高:需要 GPU 算力、训练数据、技术人员 |
| 格式规范:严格遵守特定格式标准 | 更新慢:新需求需要重新训练 |
| 指令理解强:更好地理解复杂指令 | 知识过时风险:训练数据中的知识会随时间失效 |
| 减少幻觉:在特定领域减少"胡说八道" | 数据隐私风险:训练数据可能包含敏感信息 |
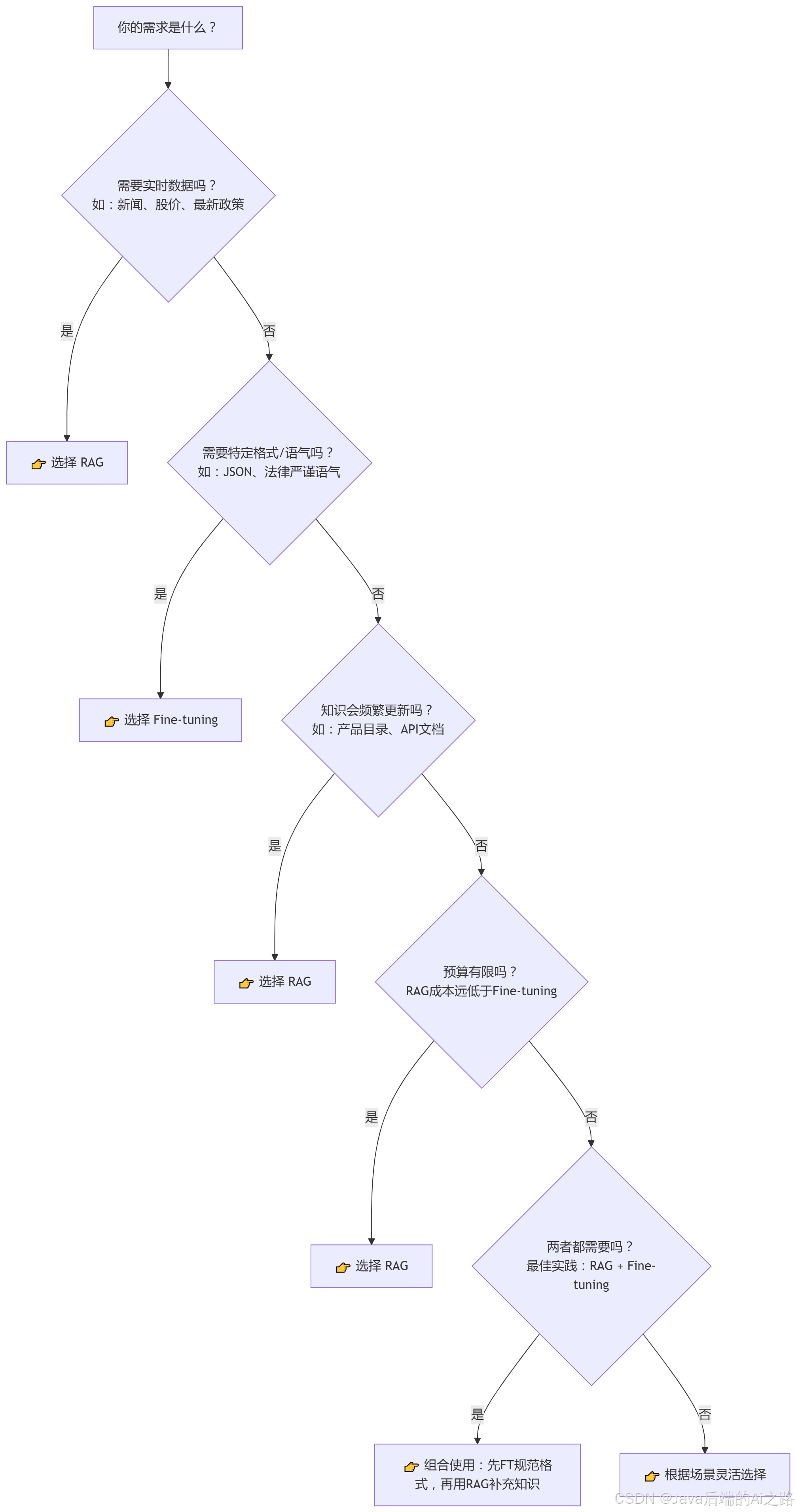
三、RAG vs Fine-tuning:一张决策图看懂何时选哪个
为了让大家能够快速做出决策,我精心制作了一个决策流程图:
四、实战案例:法律文书 Agent 的"组合拳"打法
让我用一个真实的企业项目案例,展示如何巧妙结合 RAG 和 Fine-tuning,达到 1+1>2 的效果。
4.1 项目背景
某顶级律所希望开发一个 AI 法律助手,功能包括:
- 生成法律文书(起诉状、合同、法律意见书)
- 查询最新法律法规(如最新的司法解释)
- 解答法律咨询
4.2 遇到的挑战
团队最初尝试直接使用开源大模型(Qwen-7B),但遇到了两大问题:
问题 1:知识缺口(不知道最新的法律)
用户问:“根据 2024 年最新的《民法典司法解释》,这种情况怎么处理?”
模型:“我不知道 2024 年的司法解释,我的训练数据截止到 2023 年……”
原因:模型的训练数据有截止时间,无法获取实时更新的法律知识。
问题 2:风格不对味(AI 味太浓)
生成的法律文书虽然逻辑正确,但明显缺乏专业感:
“根据相关法律条文,您应该……”(太随意)
正确写法:“应当根据《民法典》第 XXX 条之规定……”(严谨规范)
4.3 解决方案:RAG First + Fine-tuning 组合策略
团队采取了"RAG 优先,微调补充"的组合策略:

Step 1:搭建 RAG 系统,解决"不知道"的问题
# RAG系统核心代码示例
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 1. 加载法律知识库(最新的司法解释、判例等)
legal_docs = load_documents("./legal_knowledge_base/")
# 2. 文档切分(chunk处理)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(legal_docs)
# 3. 构建向量索引
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever()
# 4. 检索相关法律条文
def query_legal_knowledge(question):
docs = retriever.get_relevant_documents(question)
return "\n\n".join([doc.page_content for doc in docs])
# 测试查询
question = "2024年最新的《民法典司法解释》中,关于合同解除的规定是什么?"
relevant_law = query_legal_knowledge(question)
print(f"检索到的相关法律条文:\n{relevant_law}")
Step 2:使用 Fine-tuning,解决"学不会"的问题
团队收集了 1000 份高质量律师手写文书,对 Qwen-7B 进行指令微调(SFT):
# Fine-tuning数据准备示例
training_data = [
{
"instruction": "请根据以下案件事实,生成一份标准的民事起诉状",
"input": "案件事实:原告张三于2023年5月1日与被告李四签订房屋买卖合同...",
"output": """民事起诉状
原告:张三,男,汉族,1980年1月1日出生,住北京市朝阳区...
被告:李四,男,汉族,1985年5月20日出生,住北京市海淀区...
诉讼请求:
一、判令被告继续履行《房屋买卖合同》,将位于北京市朝阳区XX小区XX号房屋交付给原告;
...
事实与理由:
根据《民法典》第五百零九条之规定,**当事人应当按照约定全面履行自己的义务**...
此致
北京市朝阳区人民法院
具状人:张三
2023年8月15日"""
},
# ... 1000份类似样本
]
# 使用LoRA进行高效微调
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(model_name)
# 配置LoRA参数
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA
model = get_peft_model(base_model, lora_config)
# 开始训练(伪代码,实际需使用trainer)
# trainer = Trainer(...)
# trainer.train()
# model.save_pretrained("./fine_tuned_qwen_lawyer")
Step 3:组合使用,效果炸裂
微调后的模型负责格式和语气,RAG 系统负责知识补充:
# 组合使用示例
def generate_legal_document(question, use_rag=True):
# 1. 如果需要,检索相关知识
context = ""
if use_rag:
context = query_legal_knowledge(question)
context = f"\n【相关法律依据】:\n{context}\n"
# 2. 使用微调后的模型生成文书
prompt = f"""请根据以下要求生成法律文书:
【用户需求】:
{question}
{context}
【文书要求】:
1. 格式符合法律文书规范
2. 用词严谨,使用"应当"而非"可以"
3. 引用法律条文需准确
4. 整体风格符合律师专业水准
【文书】:
"""
# 调用微调后的模型生成
response = fine_tuned_model.generate(prompt)
return response
# 测试
result = generate_legal_document(
"请根据张三与李四的房屋买卖合同纠纷,生成起诉状"
)
print(result)
4.4 最终效果
| 维度 | 单用 RAG | 单用 Fine-tuning | RAG + Fine-tuning |
|---|---|---|---|
| 知识准确性 | ✅ 实时更新 | ❌ 可能过时 | ✅ 实时且准确 |
| 格式规范性 | ❌ 需要提示词约束 | ✅ 内化规范 | ✅ 完美规范 |
| 语气专业度 | ⚠️ 需要反复调试 | ✅ 专业严谨 | ✅ 专业严谨 |
| 开发成本 | ✅ 较低 | ❌ 较高 | ⚠️ 中等 |
| 维护成本 | ✅ 易更新 | ❌ 需重新训练 | ⚠️ 中等 |
结论:RAG 补全知识,Fine-tuning 规范格式和语气,两者结合效果最好!
五、企业级最佳实践:如何设计你的 AI 系统架构
基于大量实战经验,我总结了一套企业级 AI 系统的分层架构设计原则:
5.1 架构分层图

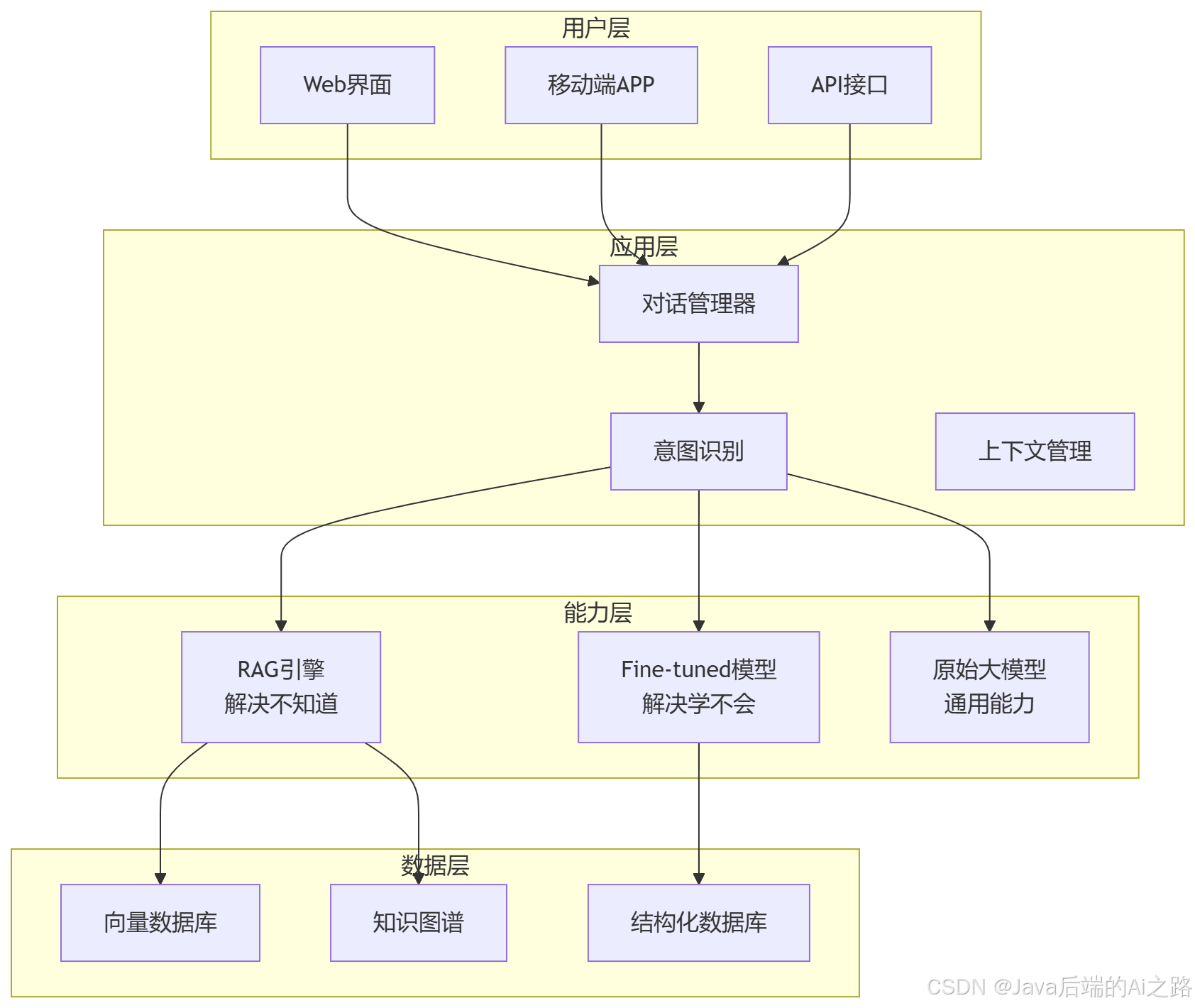
5.2 核心设计原则
原则 1:RAG First(RAG 优先)
在大多数企业场景中,优先考虑 RAG,原因如下:
- 知识更新频繁:企业的产品信息、政策文档、API 文档会持续更新
- 成本可控:RAG 的维护成本远低于 Fine-tuning
- 可解释性强:可以追溯回答来源,满足合规要求
原则 2:按需 Fine-tuning
仅在以下场景考虑 Fine-tuning:
- 需要特定格式输出:如 JSON、XML、代码、法律文书
- 需要特定语气风格:如专业严谨、活泼幽默、客服礼貌
- 指令理解能力不足:原始模型无法理解复杂指令
- 减少幻觉需求:在医疗、法律等高风险领域
原则 3:数据质量决定一切
无论是 RAG 还是 Fine-tuning,数据质量都是成败关键:
- RAG 数据:确保知识库的准确性、时效性、结构化程度
- Fine-tuning 数据:确保训练样本的专业性、多样性、标注准确性
5.3 企业级代码框架
以下是一个生产级别的 AI 系统框架,结合了 RAG 和 Fine-tuning:
# enterprise_ai_system.py
from typing import Optional, List, Dict
from dataclasses import dataclass
from enum import Enum
class ModelType(Enum):
"""模型类型枚举"""
BASE = "base" # 原始模型
FINE_TUNED = "fine_tuned" # 微调模型
class KnowledgeSource(Enum):
"""知识来源枚举"""
VECTOR_DB = "vector_db" # 向量数据库
KNOWLEDGE_GRAPH = "kg" # 知识图谱
STRUCTURED_DB = "sql" # 结构化数据库
@dataclass
class AIRequest:
"""AI请求对象"""
user_id: str
question: str
use_rag: bool = True
model_type: ModelType = ModelType.FINE_TUNED
knowledge_sources: List[KnowledgeSource] = None
@dataclass
class AIResponse:
"""AI响应对象"""
answer: str
sources: List[str] # 回答来源(用于溯源)
confidence: float # 置信度
model_used: ModelType
class EnterpriseAISystem:
"""企业级AI系统"""
def __init__(self):
# 初始化RAG引擎
self.rag_engine = RAGEngine()
# 初始化模型加载器
self.model_loader = ModelLoader()
# 初始化知识库管理器
self.knowledge_manager = KnowledgeManager()
def process(self, request: AIRequest) -> AIResponse:
"""处理用户请求"""
# Step 1: 意图识别(判断是否需要RAG)
intent = self._detect_intent(request.question)
# Step 2: 加载合适的模型
model = self.model_loader.load_model(request.model_type)
# Step 3: 如果需要RAG,检索相关知识
context = ""
sources = []
if request.use_rag:
context, sources = self.rag_engine.retrieve(
question=request.question,
sources=request.knowledge_sources or [KnowledgeSource.VECTOR_DB]
)
# Step 4: 构建提示词
prompt = self._build_prompt(
question=request.question,
context=context,
model_type=request.model_type
)
# Step 5: 模型推理
answer = model.generate(prompt)
# Step 6: 后处理(格式化、安全性检查等)
answer = self._post_process(answer)
return AIResponse(
answer=answer,
sources=sources,
confidence=self._calculate_confidence(answer, context),
model_used=request.model_type
)
def _detect_intent(self, question: str) -> str:
"""检测用户意图"""
# 使用规则或分类模型判断意图
if "最新" in question or "当前" in question:
return "need_realtime_data"
elif "生成" in question or "写" in question:
return "need_generation"
else:
return "general_query"
def _build_prompt(self, question: str, context: str, model_type: ModelType) -> str:
"""构建提示词"""
if model_type == ModelType.FINE_TUNED:
# 微调模型不需要复杂的提示词
prompt = f"{context}\n\n【用户问题】:{question}\n\n【回答】:"
else:
# 原始模型需要详细的提示词
prompt = f"""你是一个专业的AI助手。请根据以下信息回答用户问题。
【相关信息】:
{context}
【用户问题】:
{question}
【回答要求】:
1. 基于提供的信息回答,不要编造
2. 如果信息不足,请明确说明
3. 回答要清晰、准确、有逻辑
【回答】:"""
return prompt
def _post_process(self, answer: str) -> str:
"""后处理"""
# 1. 格式化
answer = answer.strip()
# 2. 安全性检查
# if self._contains_sensitive_content(answer):
# return "抱歉,我无法回答这个问题。"
# 3. 其他后处理逻辑
return answer
def _calculate_confidence(self, answer: str, context: str) -> float:
"""计算置信度"""
# 这里可以实现更复杂的置信度计算逻辑
if context:
return 0.85 # 有RAG支持,置信度较高
else:
return 0.70 # 依赖模型自身知识,置信度中等
class RAGEngine:
"""RAG引擎"""
def __init__(self):
self.vector_store = self._init_vector_store()
self.knowledge_graph = self._init_knowledge_graph()
self.sql_db = self._init_sql_db()
def retrieve(self, question: str, sources: List[KnowledgeSource]) -> tuple[str, List[str]]:
"""检索相关知识"""
contexts = []
source_refs = []
for source in sources:
if source == KnowledgeSource.VECTOR_DB:
context, refs = self._search_vector_db(question)
contexts.append(context)
source_refs.extend(refs)
elif source == KnowledgeSource.KNOWLEDGE_GRAPH:
context, refs = self._search_kg(question)
contexts.append(context)
source_refs.extend(refs)
elif source == KnowledgeSource.STRUCTURED_DB:
context, refs = self._search_sql(question)
contexts.append(context)
source_refs.extend(refs)
return "\n\n".join(contexts), source_refs
def _search_vector_db(self, question: str) -> tuple[str, List[str]]:
"""搜索向量数据库"""
# 实际实现使用FAISS/Milvus等
docs = self.vector_store.similarity_search(question, k=3)
context = "\n\n".join([doc.page_content for doc in docs])
sources = [doc.metadata.get("source", "unknown") for doc in docs]
return context, sources
def _search_kg(self, question: str) -> tuple[str, List[str]]:
"""搜索知识图谱"""
# 实际实现使用Neo4j等
return "KG搜索结果(示例)", ["KG:法律条文-合同法"]
def _search_sql(self, question: str) -> tuple[str, List[str]]:
"""搜索结构化数据库"""
# 实际实现使用Text-to-SQL
return "SQL查询结果(示例)", ["DB:产品表"]
class ModelLoader:
"""模型加载器"""
def __init__(self):
self.models = {}
def load_model(self, model_type: ModelType):
"""加载模型"""
if model_type not in self.models:
if model_type == ModelType.BASE:
self.models[model_type] = self._load_base_model()
elif model_type == ModelType.FINE_TUNED:
self.models[model_type] = self._load_fine_tuned_model()
return self.models[model_type]
def _load_base_model(self):
"""加载基础模型"""
# 实际实现使用HuggingFace Transformers
return BaseModelWrapper("Qwen/Qwen-7B")
def _load_fine_tuned_model(self):
"""加载微调模型"""
# 实际实现加载微调后的模型
return FineTunedModelWrapper("./models/qwen-7b-lawyer")
class KnowledgeManager:
"""知识库管理器"""
def add_document(self, doc_path: str, doc_type: str):
"""添加文档到知识库"""
# 实现文档解析、向量化、存储逻辑
pass
def update_document(self, doc_id: str, new_content: str):
"""更新文档"""
# 实现文档更新逻辑
pass
def delete_document(self, doc_id: str):
"""删除文档"""
# 实现文档删除逻辑
pass
# 模型包装类(伪代码)
class BaseModelWrapper:
def __init__(self, model_name):
self.model_name = model_name
# 加载模型
def generate(self, prompt: str) -> str:
# 生成逻辑
return f"Base模型回答:{prompt}"
class FineTunedModelWrapper:
def __init__(self, model_path):
self.model_path = model_path
# 加载微调后的模型
def generate(self, prompt: str) -> str:
# 生成逻辑
return f"Fine-tuned模型专业回答:{prompt}"
# 使用示例
if __name__ == "__main__":
# 初始化系统
ai_system = EnterpriseAISystem()
# 处理用户请求
request = AIRequest(
user_id="user_123",
question="请生成一份房屋买卖合同的起诉状,根据最新的民法典司法解释",
use_rag=True,
model_type=ModelType.FINE_TUNED
)
response = ai_system.process(request)
print(f"回答:{response.answer}")
print(f"来源:{response.sources}")
print(f"置信度:{response.confidence}")
print(f"使用模型:{response.model_used}")
六、成本对比与选型建议
6.1 成本详细对比
| 成本项 | RAG | Fine-tuning |
|---|---|---|
| 初始开发成本 | 中等(需搭建检索系统) | 高(需训练数据、算力) |
| 数据准备成本 | 中等(文档收集、清洗) | 高(需高质量标注数据) |
| 算力成本 | 低(仅推理) | 高(训练 + 推理) |
| 维护成本 | 低(文档更新即可) | 高(需重新训练) |
| 人力成本 | 中等(需知识库管理) | 高(需 ML 工程师) |
| 总成本(首年) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 总成本(次年) | ⭐⭐ | ⭐⭐⭐⭐ |
6.2 选型决策矩阵
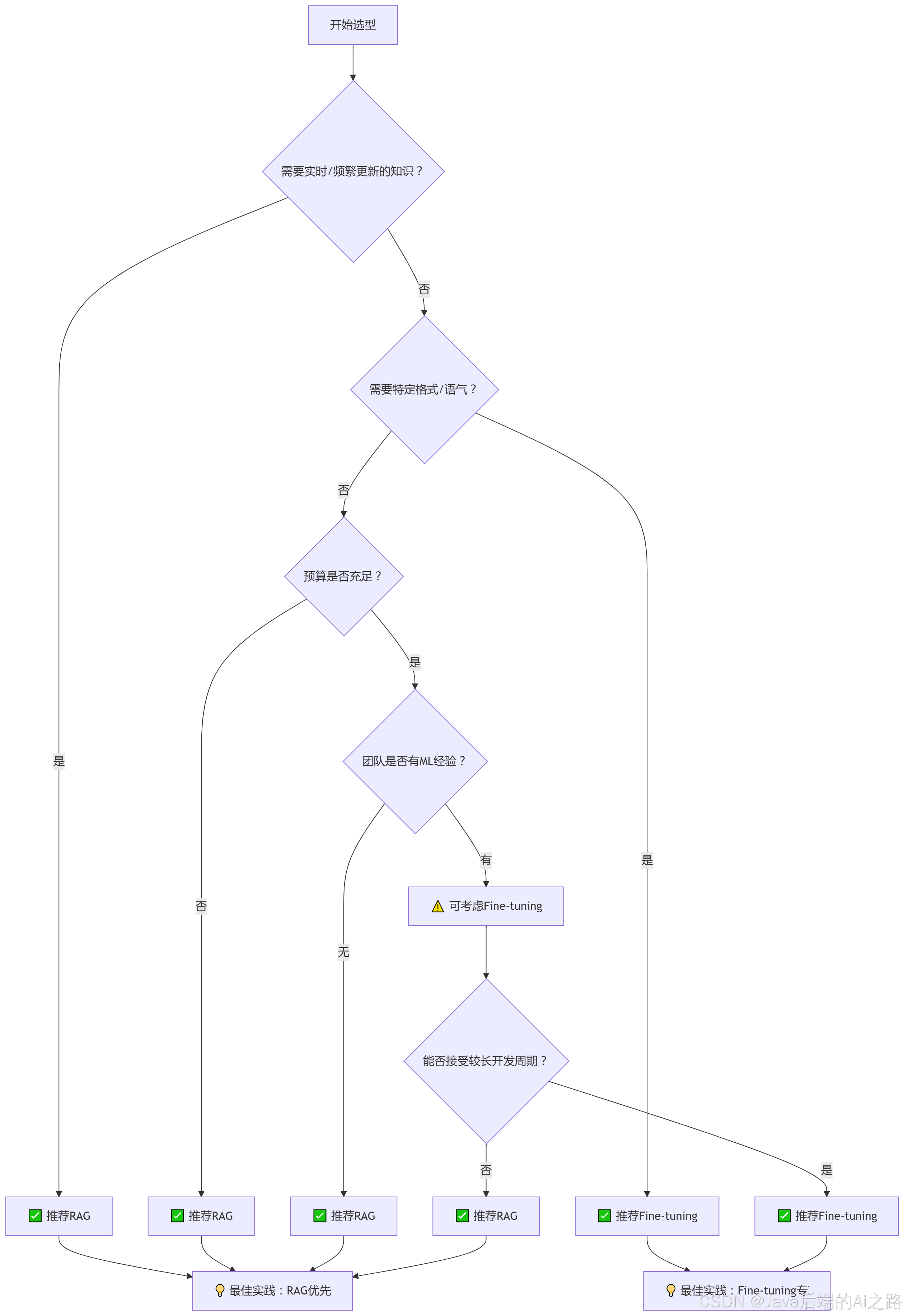
6.3 我的建议:80% 场景用 RAG,20% 用 Fine-tuning
根据我的经验,80% 的企业 AI 场景用 RAG 就足够了,只有以下 20% 的场景才需要 Fine-tuning:

适合 RAG 的场景(80%):
- ✅ 客服问答系统
- ✅ 企业知识库搜索
- ✅ 产品文档智能问答
- ✅ 政策法规查询
- ✅ 技术文档辅助
- ✅ 内部培训助手
适合 Fine-tuning 的场景(20%):
- ✅ 需要特定格式的文书生成(法律、医疗)
- ✅ 需要特定语气的品牌助手
- ✅ 复杂任务分解与执行(Agent)
- ✅ 领域专用模型(金融、医疗)
- ✅ 降低幻觉需求的严肃场景
两者都需要的场景(黄金组合):
- 🌟 法律文书生成(案例展示过)
- 🌟 医疗诊断助手
- 🌟 代码生成与优化
- 🌟 高级客服系统
七、常见问题解答(FAQ)
Q1:RAG 和 Fine-tuning 能同时用吗?
答:当然可以!而且这是最佳实践。正如法律文书 Agent 的案例所示:
- RAG 负责补充实时知识
- Fine-tuning 负责规范格式和语气
- 两者结合,效果最好!
Q2:RAG 会替代 Fine-tuning 吗?
答:不会。RAG 和 Fine-tuning 解决的是不同维度的问题:
- RAG 解决"不知道"(知识缺失)
- Fine-tuning 解决"学不会"(能力缺失)
就像"买书"和"请私教"不冲突一样,它们各有各的用武之地。
Q3:Fine-tuning 后还需要 RAG 吗?
答:通常仍然需要。原因有二:
- 知识会过时:Fine-tuning 模型的知识停留在训练数据的时间点
- 知识范围有限:Fine-tuning 无法覆盖所有可能的用户问题
最佳实践:先用 Fine-tuning 打好"内功",再用 RAG 外挂"知识库"。
Q4:RAG 的检索质量如何保证?
答:这是 RAG 系统的核心挑战,可以从以下方面优化:
- 提升文档质量:确保知识库文档的准确性、结构化
- 优化切分策略:合理的 chunk size 和 overlap
- 使用高级检索:混合检索(关键词 + 语义)、重排序(Re-rank)
- 使用知识图谱:增强语义理解能力
Q5:Fine-tuning 需要多少数据?
答:这取决于任务复杂度:
| 任务类型 | 建议数据量 | 示例 |
|---|---|---|
| 简单格式调整 | 100-500 条 | JSON 格式化 |
| 中等复杂度任务 | 500-2000 条 | 代码风格统一 |
| 复杂任务学习 | 2000-10000 条 | 法律文书生成 |
注意:质量远比数量重要!1000 条高质量数据 > 10000 条垃圾数据。
八、未来展望:RAG 和 Fine-tuning 的演进趋势
8.1 RAG 的发展方向
- 多模态 RAG:不仅检索文本,还能检索图片、视频、音频
- 实时 RAG:与实时数据源(新闻、股价)无缝集成
- 个性化 RAG:根据用户画像动态调整检索策略
- 分布式 RAG:跨多个知识库的联邦检索
8.2 Fine-tuning 的发展方向
- 参数高效微调:LoRA、QLoRA 等技术降低训练成本
- 持续学习:模型在不遗忘旧知识的情况下学习新知识
- 联邦微调:在保护隐私的前提下进行分布式微调
- 自动化微调:AutoML 技术自动化微调流程
8.3 技术融合趋势
未来,RAG 和 Fine-tuning 的边界会越来越模糊,可能出现:
- Fine-tuned RAG:微调过的检索增强模型
- RAG-aware Fine-tuning:在微调时考虑检索上下文
- 一体化架构:RAG 和 Fine-tuning 统一在一个框架中
九、总结:记住这个核心原则
经过这么多分析和案例,让我们回到最初的核心问题:
什么时候用 RAG,什么时候用 Fine-tuning?
答案其实非常简单,记住这个黄金法则:
解决"不知道"的问题 → 用RAG(外挂知识库)
解决"学不会"的问题 → 用Fine-tuning(内功修炼)
最佳实践:RAG First,按需Fine-tuning
两者结合,效果最好!
最后送给大家一句话:
RAG 是"站在巨人的肩膀上",Fine-tuning 是"把自己变成巨人"。
聪明的做法是:先站在巨人肩膀上(RAG),再努力把自己变成巨人(Fine-tuning)。
十、互动时间
好啦,今天的内容就到这里!相信大家对 RAG 和 Fine-tuning 已经有了清晰的认识。
🎯 思考题
- 你的项目中遇到过"不知道"还是"学不会"的问题?你是怎么解决的?
- 你觉得你的场景适合用 RAG、Fine-tuning,还是两者结合?
- 你有没有遇到过 RAG 检索质量不佳的情况?你是怎么优化的?
欢迎在评论区分享你的经验和见解!我会认真回复每一条评论哦~ 👀
📚 延伸阅读
如果你想深入了解这两个技术,推荐以下资源:
- RAG 相关:
- LangChain 官方文档:https://python.langchain.com/
- FAISS 向量数据库:https://github.com/facebookresearch/faiss
- RAG 技术综述论文:《Retrieval-Augmented Generation for Large Language Models: A Survey》
- Fine-tuning 相关:
- HuggingFace PEFT 库:https://github.com/huggingface/peft
- LoRA 论文:《LoRA: Low-Rank Adaptation of Large Language Models》
- Qwen 模型库:https://github.com/QwenLM/Qwen
📝 转载声明
本文为原创内容,版权归作者所有。
🔗 参考链接
- LangChain 官方文档:https://python.langchain.com/
- FAISS 向量数据库:https://github.com/facebookresearch/faiss
- Qwen 开源模型:https://github.com/QwenLM/Qwen
- PEFT 参数高效微调库:https://github.com/huggingface/peft
- RAG 技术综述:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
- LoRA 论文:《LoRA: Low-Rank Adaptation of Large Language Models》
- 混合检索技术:《Dense Passage Retrieval for Open-Domain Question Answering》
感谢阅读!如果这篇文章对你有帮助,别忘了点赞、收藏、关注哦~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)