逻辑回归(Logistic Regression)
逻辑回归(Logistic Regression)
概叙
- 逻辑回归是一种用于解决分类问题的统计学习方法,尤其适用于二分类(Binary Classification),也可扩展到多分类(Multinomial Logistic Regression)。
- 尽管名字中有“回归”,但它实际上是一种分类算法。
- 输出是样本属于某一类别的概率(0 到 1 之间)。
核心思想
逻辑回归通过线性组合输入特征,再通过Sigmoid 函数将其映射到 [0, 1] 区间,表示属于正类的概率。
线性部分:
z=wTx+b=w1x1+w2x2+⋯+wnxn+b z = \mathbf{w}^T \mathbf{x} + b = w_1 x_1 + w_2 x_2 + \dots + w_n x_n + b z=wTx+b=w1x1+w2x2+⋯+wnxn+b
Sigmoid 函数(Logistic 函数):
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
预测概率:
P(y=1∣x)=σ(wTx+b) P(y=1|\mathbf{x}) = \sigma(\mathbf{w}^T \mathbf{x} + b) P(y=1∣x)=σ(wTx+b)
P(y=0∣x)=1−P(y=1∣x) P(y=0|\mathbf{x}) = 1 - P(y=1|\mathbf{x}) P(y=0∣x)=1−P(y=1∣x)
决策规则(通常阈值为 0.5):
y^={1,if P(y=1∣x)≥0.50,otherwise \hat{y} = \begin{cases} 1, & \text{if } P(y=1|\mathbf{x}) \geq 0.5 \\ 0, & \text{otherwise} \end{cases} y^={1,0,if P(y=1∣x)≥0.5otherwise
损失函数(Loss Function)
逻辑回归使用对数损失(Log Loss / Cross-Entropy Loss)作为目标函数:
对于单个样本:
L(y,p^)=−[ylog(p^)+(1−y)log(1−p^)] \mathcal{L}(y, \hat{p}) = -\left[ y \log(\hat{p}) + (1 - y) \log(1 - \hat{p}) \right] L(y,p^)=−[ylog(p^)+(1−y)log(1−p^)]
其中 p^=σ(wTx+b)\hat{p} = \sigma(\mathbf{w}^T \mathbf{x} + b)p^=σ(wTx+b)
所以 p^\hat{p}p^是一个概率估计值。
💡直观解释
- 当 y=1y = 1y=1:损失为 −log(p^)-\log(\hat{p})−log(p^),希望 p^→1\hat{p} \to 1p^→1
- 当 y=0y = 0y=0:损失为 −log(1−p^)-\log(1 - \hat{p})−log(1−p^),希望 p^→0\hat{p} \to 0p^→0
模型越“自信”但预测错误,损失越大!
| 真实标签 | 预测概率p^\hat{p}p^ | 损失值 |
|---|---|---|
| y=1y=1y=1 | p^=0.9\hat{p}=0.9p^=0.9 | 很小(~0.1) |
| y=1y=1y=1 | p^=0.1\hat{p}=0.1p^=0.1 | 很大(~2.3) |
| y=0y=0y=0 | p^=0.1\hat{p}=0.1p^=0.1 | 很小(~0.1) |
| y=0y=0y=0 | p^=0.9\hat{p}=0.9p^=0.9 | 很大(~2.3) |
这个损失函数 惩罚错误预测非常严厉,尤其是当模型很自信但错了时(如 y=1y=1y=1 但 p^=0.1\hat{p}=0.1p^=0.1),损失会急剧上升。
对于整个训练集(m 个样本):
J(w,b)=−1m∑i=1m[y(i)log(p^(i))+(1−y(i))log(1−p^(i))] J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(\hat{p}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{p}^{(i)}) \right] J(w,b)=−m1i=1∑m[y(i)log(p^(i))+(1−y(i))log(1−p^(i))]
- m :训练样本总数
- y(i)∈0,1y^{(i)}∈{0,1}y(i)∈0,1 :第 iii 个样本的真实标签
- p^(i)=σ(wTx(i)+b)\hat{p}^{(i)}=σ(w^Tx^{(i)}+b)p^(i)=σ(wTx(i)+b) :第 iii 个样本的预测概率
- 整体目标是 最小化所有样本的平均对数损失
注意:该损失函数是凸函数,因此可通过梯度下降等优化方法找到全局最优解。
为什么用这个损失函数?(关键原因)
1. 基于最大似然估计(MLE)推导而来
逻辑回归的本质是 最大似然估计
假设:
- P(y=1∣x)=p^P(y=1∣x)=\hat{p}P(y=1∣x)=p^
- P(y=0∣x)=1−p^P(y=0∣x)=1-\hat{p}P(y=0∣x)=1−p^
则联合概率为:
P(y∣x)=p^y(1−p^)(1−y)P(y∣x)=\hat{p}^y(1-\hat{p})^{(1-y)}P(y∣x)=p^y(1−p^)(1−y)
对所有样本取对数似然:
logL=∑i=1m[y(i)log(p^(i))+(1−y(i))log(1−p^(i))] \log L = \sum_{i=1}^{m} \left[ y^{(i)} \log(\hat{p}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{p}^{(i)}) \right] logL=i=1∑m[y(i)log(p^(i))+(1−y(i))log(1−p^(i))]
最大化对数似然 ⇨ 最小化负对数似然 ⇨ 得到上面的损失函数!
所以这个损失函数是 统计上最优的选择。
2.它是凸函数!
💡 注意:该损失函数是关于参数 w,bw,bw,b 的 凸函数(在二分类中)。
这意味着:
- 使用梯度下降法可以找到 全局最优解
- 不会出现局部极小值陷阱
- 收敛稳定
❌ 如果我们用 MSE(均方误差)作为逻辑回归的损失函数,会导致非凸问题,难以优化。
参数优化
使用梯度下降法更新参数:
梯度计算(对权重 wjw_jwj):
∂J∂wj=1m∑i=1m(p^(i)−y(i))xj(i) \frac{\partial J}{\partial w_j} = \frac{1}{m} \sum_{i=1}^{m} (\hat{p}^{(i)} - y^{(i)}) x_j^{(i)} ∂wj∂J=m1i=1∑m(p^(i)−y(i))xj(i)
更新规则:
wj:=wj−α⋅∂J∂wj w_j := w_j - \alpha \cdot \frac{\partial J}{\partial w_j} wj:=wj−α⋅∂wj∂J
b:=b−α⋅1m∑i=1m(p^(i)−y(i)) b := b - \alpha \cdot \frac{1}{m} \sum_{i=1}^{m} (\hat{p}^{(i)} - y^{(i)}) b:=b−α⋅m1i=1∑m(p^(i)−y(i))
其中 α\alphaα 是学习率。
逻辑回归API
sklearn.linear_model.LogisticRegression
基本导入
from sklearn.linear_model import LogisticRegression
核心参数
| 参数 | 说明 |
|---|---|
penalty='l2' |
正则化类型:'l1', 'l2', 'elasticnet', 'none' |
C=1.0 |
正则化强度的倒数(越小正则越强) |
solver='lbfgs' |
优化算法:'liblinear', 'lbfgs', 'sag', 'saga' 等 |
max_iter=100 |
最大迭代次数(若不收敛可增大) |
multi_class='auto' |
多分类策略:'ovr'(一对多)或 'multinomial' |
random_state=None |
随机种子(用于可复现性) |
💡对于二分类,默认即可;多分类时注意
solver和multi_class的兼容性。
案例
二分类任务
场景:预测肿瘤是良性(0)还是恶性(1)
# 导包
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
# 1. 生成模拟数据(或替换为真实数据,如 sklearn.datasets.load_breast_cancer)
X, y = make_classification(
n_samples=1000,
n_features=4,
n_informative=3,
n_redundant=1,
n_clusters_per_class=1,
random_state=42
)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 3. 创建并训练模型
model = LogisticRegression(
penalty='l2',
C=1.0,
solver='lbfgs',
max_iter=200,
random_state=42
)
model.fit(X_train, y_train)
# 4. 预测
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)[:, 1] # 正类概率
# 5. 评估
print("准确率:", accuracy_score(y_test, y_pred))
print("\n分类报告:\n", classification_report(y_test, y_pred))
print("\n混淆矩阵:\n", confusion_matrix(y_test, y_pred))
# 6. 查看模型参数
print("\n权重 (w):", model.coef_)
print("偏置 (b):", model.intercept_)
多分类示例
鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target # 3 类:setosa, versicolor, virginica
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 自动处理多分类
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
model.fit(X_train, y_train)
print("多分类准确率:", model.score(X_test, y_test))
分类问题评估
混淆矩阵(Confusion Matrix)
展示真实标签 vs 预测标签的计数表。
| 预测为正类 (1) | 预测为负类 (0) | |
|---|---|---|
| 真实为正类 (1) | True Positive (TP) | False Negative (FN) |
| 真实为负类 (0) | False Positive (FP) | True Negative (TN) |
- TP(真正例):正确识别的正例(如:癌症患者被正确诊断)
- FN(伪反例):漏报(危险!如:患者被误判为健康)
- FP(伪正例):误报(如:健康人被误判为患者)
- TN(真反例):正确识别的负例
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 0, 0, 1, 1]
cm = confusion_matrix(y_true, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted'); plt.ylabel('Actual')
plt.show()
精确率(Precision)
“预测为正类的样本中,有多少是真的正类?”
Precision=TPTP+FP \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP
- 关注 预测质量:避免过多误报(FP)
- 适用于:垃圾邮件检测(不希望把正常邮件判为垃圾)
from sklearn.metrics import precision_score
print(precision_score(y_test, y_pred))
召回率(Recall / Sensitivity / True Positive Rate, TPR)
“所有真实的正类中,有多少被找出来了?”
Recall=TPTP+FN \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP
- 关注 查全能力:避免漏报(FN)
- 适用于:疾病筛查、欺诈检测(宁可误报,不可漏报)
from sklearn.metrics import recall_score
print(recall_score(y_test, y_pred))
F1-Score(F1-Measure)
精确率和召回率的调和平均(Harmonic Mean)
F1=2⋅Precision⋅RecallPrecision+Recall F_1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} F1=2⋅Precision+RecallPrecision⋅Recall
- 当 Precision 和 Recall 冲突时,F1 提供平衡指标
- 范围:0 ~ 1,越大越好
💡 为什么用调和平均?
算术平均会掩盖极端值(如 P=1, R=0 → avg=0.5),但 F1=0,更合理。
from sklearn.metrics import f1_score
print(f1_score(y_test, y_pred))
ROC 曲线 与 AUC
ROC 曲线(Receiver Operating Characteristic Curve)
-
横轴:
“所有真实负例中,被错误预测为正例的比例”
FPR(False Positive Rate)= FPFP+TN\frac{FP}{FP + TN}FP+TNFP
-
纵轴:
“所有真实正例中,被正确预测的比例”
TPR(True Positive Rate) = Recall = TPTP+FN\frac{TP}{TP + FN}TP+FNTP
-
通过改变分类阈值(如从 0.1 到 0.9)得到一系列 (FPR, TPR) 点,连成曲线
准确率、精确率等指标依赖于固定的分类阈值(如 0.5)
| 指标 | 公式 | 含义 |
|---|---|---|
| TPR ↑ | 更多正例被找出 | 好(查全能力强) |
| FPR ↓ | 更少负例被误判 | 好(误报少) |
图像
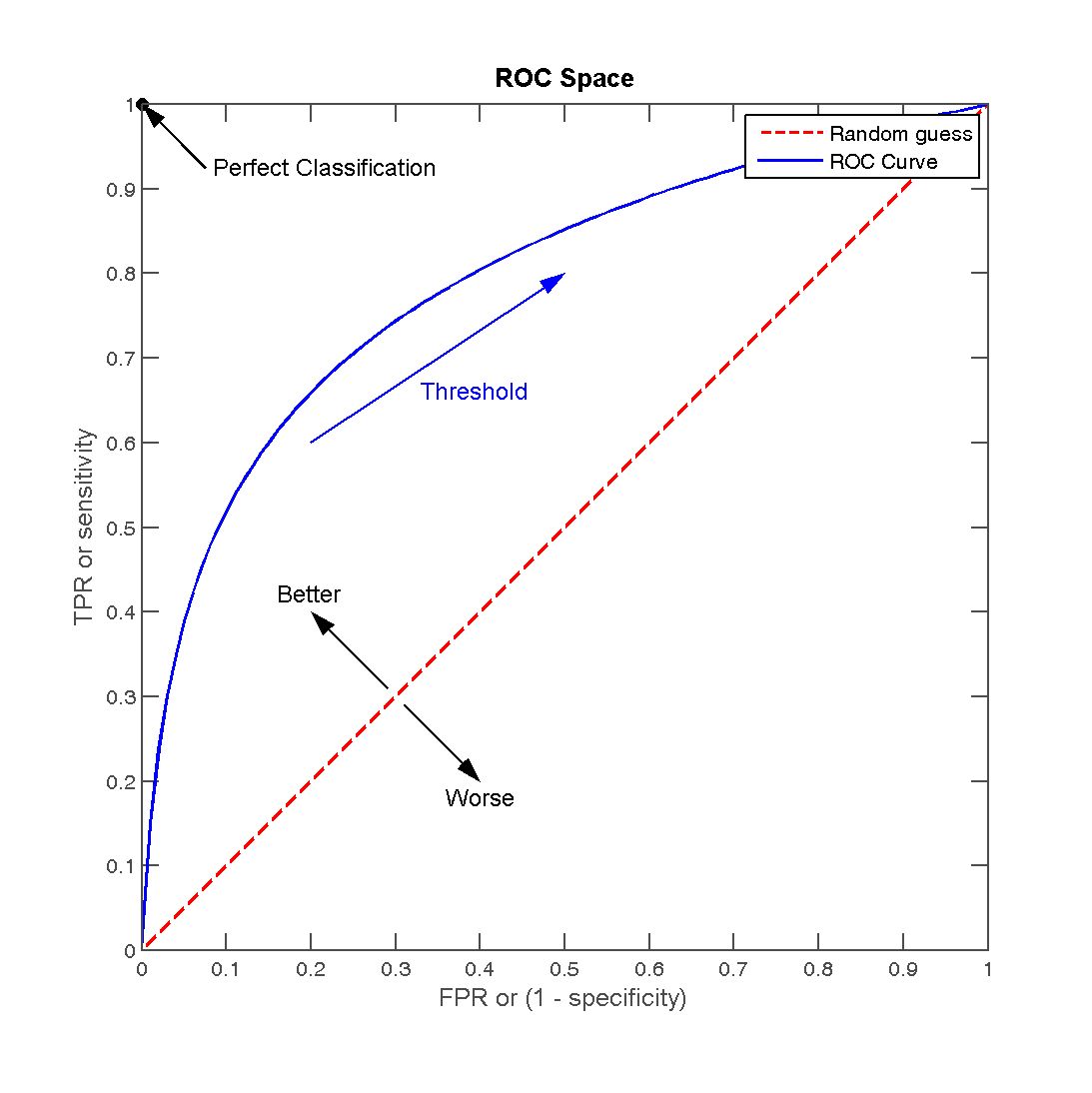
- 模型对每个样本输出一个预测概率(如 0.83, 0.21, …)
- 遍历所有可能的分类阈值(从 0 到 1):
- 阈值 = 0 → 所有样本预测为正类 → TPR=1, FPR=1
- 阈值 = 1 → 所有样本预测为负类 → TPR=0, FPR=0
- 中间阈值 → 得到不同的 (FPR, TPR) 点
- 将所有 (FPR, TPR) 点连成曲线 → ROC 曲线
✅ 理想模型:ROC 曲线经过左上角 (0,1)
❌ 随机猜测:ROC 曲线为对角线 y = x
AUC(Area Under Curve)
- ROC 曲线下面积,衡量模型整体判别能力
- AUC ∈ [0.5, 1.0]:
- AUC = 0.5:随机猜测
- AUC = 1.0:完美分类器
- AUC > 0.7:通常可接受;> 0.8 较好;> 0.9 优秀
✅ 优点:AUC 对类别不平衡不敏感,适合评估概率输出质量。
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# 获取预测概率(必须是正类概率)
y_proba = model.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 随机线
plt.xlabel('False Positive Rate'); plt.ylabel('True Positive Rate')
plt.legend(); plt.title('ROC Curve')
plt.show()
准确率(Accuracy)
准确率 = 所有预测正确的样本数 / 总样本数
它衡量的是模型在全部样本中预测正确的比例。
Accuracy=TP+TNTP+TN+FP+FN \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
from sklearn.metrics import accuracy_score
y_true = [0, 1, 1, 0, 1, 0]
y_pred = [0, 1, 0, 0, 1, 1]
acc = accuracy_score(y_true, y_pred)
print(f"准确率: {acc:.4f}") # 输出: 准确率: 0.6667
⚠️ 准确率的致命缺陷:对类别不平衡敏感
❌ 反例:癌症筛查
- 数据集:99% 健康人(负类),1% 癌症患者(正类)
- 模型:永远预测“健康”
- 结果:
- Accuracy = 99%
- 但 Recall = 0%(所有患者都被漏诊!)
这时高准确率具有严重误导性!
对比
| 指标 | 关注点 | 对不平衡数据敏感? |
|---|---|---|
| Accuracy | 整体正确率 | ✅ 非常敏感 |
| Precision | 预测为正的可靠性 | 中等 |
| Recall | 正类被找出的比例 | 较不敏感 |
| F1-score | Precision 与 Recall 的平衡 | 较不敏感 |
| AUC-ROC | 概率排序能力 | ❌ 不敏感 |
多分类场景下的指标
- 宏平均(Macro-average):对每个类单独计算指标,再取算术平均(平等对待每个类)
- 微平均(Micro-average):先汇总 TP/FP/FN,再计算全局指标(等价于 Accuracy)
- 加权平均(Weighted-average):按每个类的样本数加权平均
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
输出示例:
precision recall f1-score support
0 0.92 0.95 0.93 50
1 0.94 0.91 0.92 50
accuracy 0.93 100
macro avg 0.93 0.93 0.93 100
weighted avg 0.93 0.93 0.93 100
总结
如何选择:
| 场景 | 推荐指标 |
|---|---|
| 类别平衡,关注整体性能 | Accuracy, F1 |
| 正类更重要(如疾病) | Recall(高查全) |
| 误报代价高(如垃圾邮件) | Precision(低误报) |
| 需要综合 Precision & Recall | F1-score |
| 比较不同模型的概率排序能力 | AUC-ROC |
| 多分类问题 | Macro-F1 或 Weighted-F1 |
黄金法则:没有“最好”的指标,只有“最合适”业务目标的指标。
案例
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
# 生成模拟数据
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LogisticRegression(penalty='l2', C=1.0) # C 越小,正则化越强
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
prob = model.predict_proba(X_test)[:, 1] # 正类概率
print("Accuracy:", accuracy_score(y_test, y_pred))
优缺点
优点:
- 简单、高效、可解释性强(系数反映特征重要性)。
- 输出具有概率意义。
- 训练速度快,适合大规模数据。
- 不易过拟合(尤其加正则化后)。
缺点:
- 假设特征与 log-odds 线性相关(线性决策边界)。
- 对非线性关系建模能力弱。
- 对异常值敏感(可通过正则化缓解)。
应用场景
- 信用评分(是否违约)
- 医疗诊断(是否患病)
- 垃圾邮件检测
- 用户点击预测(CTR)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)