自注意力机制
1. 自注意力机制 self-attention
Self-Attention 解决什么?
想象你在读这句话:
"小明把苹果给了小红,她很高兴。"
问:"她" 指的是谁?
你需要回头看句子,找到 "她" 和哪个词最相关
人脑会自动建立这种联系
Self-Attention 就是让模型具备这种"回头看并建立联系"的能力。
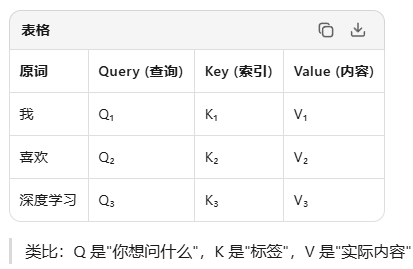
具体举个例子走一遍:
输入句子(已转成向量):
[我] [喜欢] [深度学习]
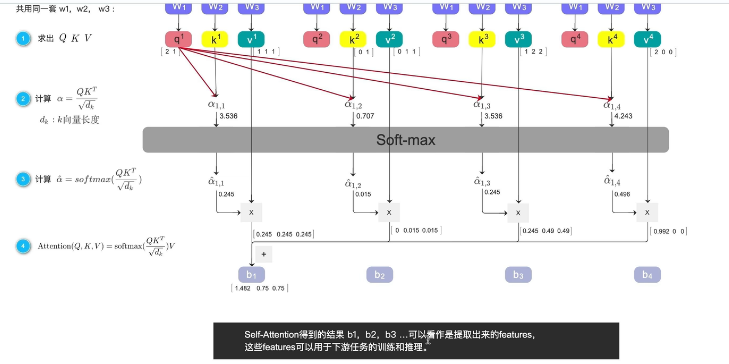
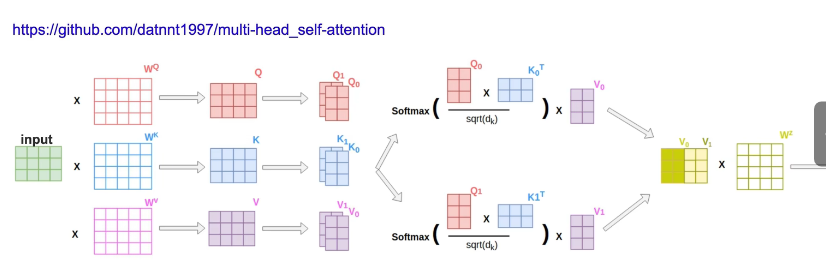
第一步:生成 Q、K、V
每个词都变出 3 个"分身":
第二步:计算"相关性"(注意力分数)
用 点积 计算每对词的相关程度:
第三步:Softmax 归一化
把每行变成概率(每行和为1):
第四步:加权求和,生成新表示
以 "喜欢" 为例,它的新向量 =
结果:"喜欢"这个词,现在携带了"深度学习"的信息!
可视化流程图



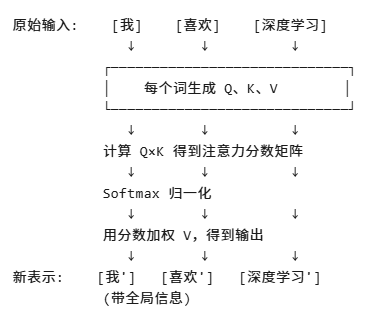
Self-Attention = 让每个词都能"偷看"其他所有词
并根据重要性加权融合信息,从而理解上下文。
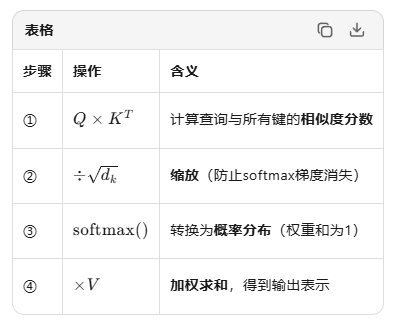
1. Q,K,V 的理解
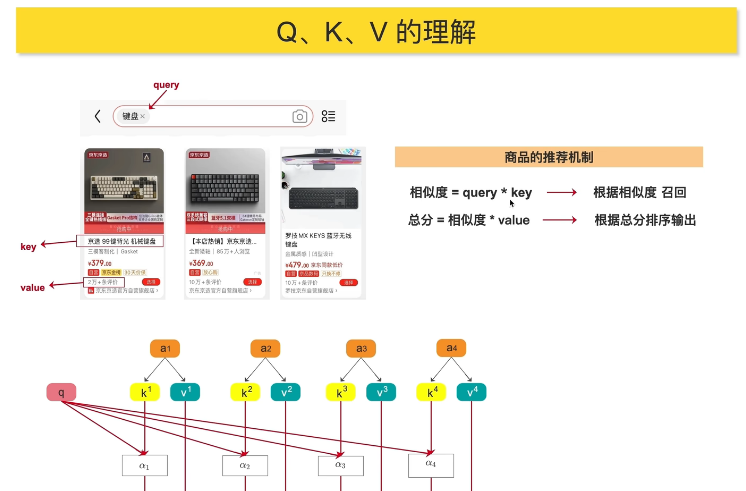
数学定义:

注意力计算步骤:
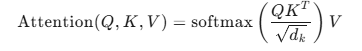
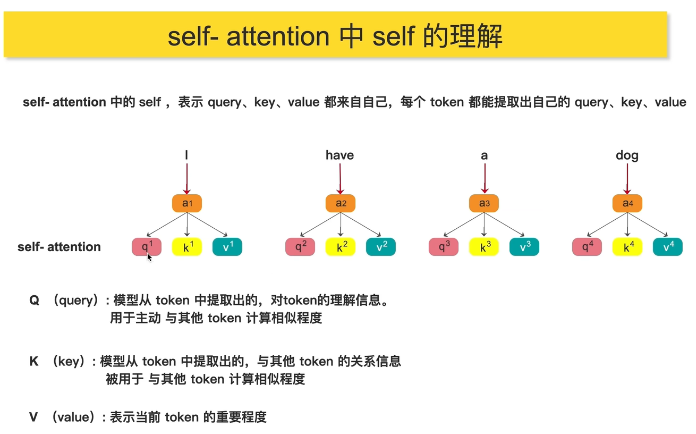
2 self-attention 中self的理解
一个类比:开小组会:
成员A想说:"我觉得方案X不错"
↓
他在心里问(Q):"谁的意见和我相关?"
↓
对比其他三人的专业领域(K):
- 成员B:财务专家 → 相似度 0.3
- 成员C:技术专家 → 相似度 0.8 ✅
- 成员D:市场专家 → 相似度 0.5
↓
最终A的发言 = 融合三人的观点,但重点参考C的技术意见(V)
关键:每个成员都这样做 → 全员建立了内部关联
“self”的精髓,不是从外面去找信息,而是自己人之间互相找关系
传统RNN: A → B → C → D (像传话,越来越远越模糊)
Self-Attention:
A ←→ B ←→ C ←→ D (像开视频会议,所有人互相直接交流)
↓
每个位置都能"看到"所有位置
通过Q去查K,加权融合V,序列内部自发建立全局关联 — 这就是Self-Attention的核心!
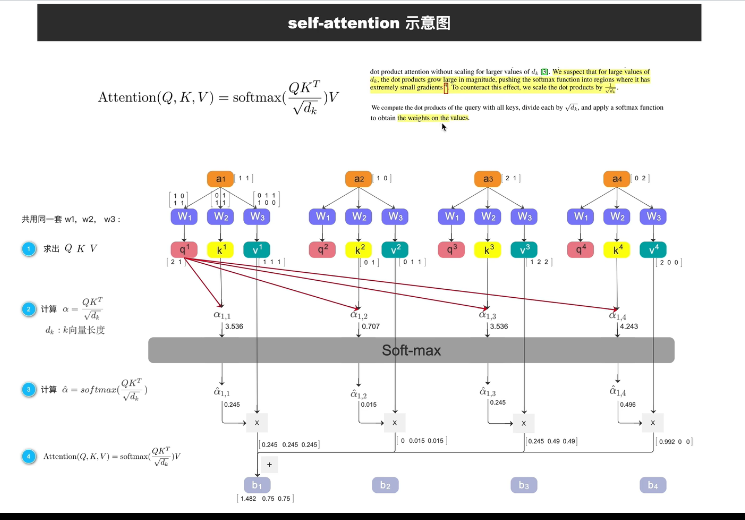
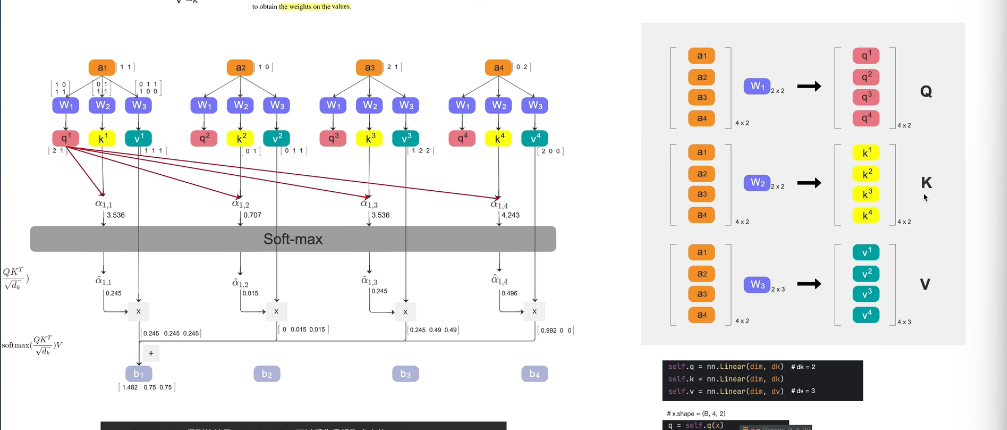
3. softmax的处理
归一化 → 变成"注意力权重"
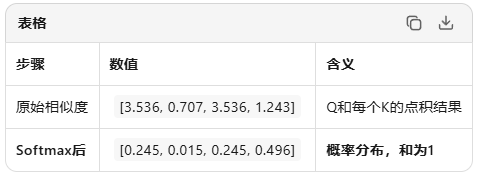
原始分数问题:
- 数值范围不定(可能很大或很小)
- 无法直接作为"权重"使用Softmax解决:
- 压缩到 (0,1) 区间
- 所有权重之和 = 1(像概率分布)
- 大的更大,小的更小(突出重要信息)

Softmax把"相似度分数"变成"注意力概率",让模型决定:我该花多少精力关注每个位置?

4.位置编码 positional encoding
1.为啥需要位置编码?
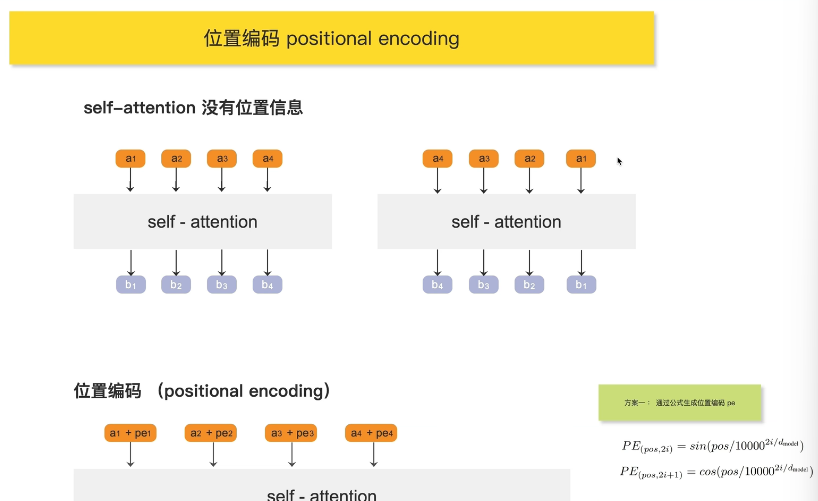
Self-Attention 的致命缺陷:没有位置概念
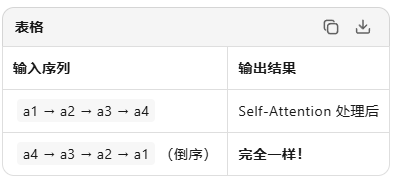
核心问题:Self-Attention 是全连接对称的,每个位置都平等地看到其他所有位置 → 完全不知道谁在左边、谁在右边
就像把一句话的词全部打乱放进袋子,模型无法区分"猫追老鼠"和"老鼠追猫"
2. 位置编码的解决方案:
原始做法(transformer论文):加位置信息
输入 = 词向量(a) + 位置向量(pe)
a1 + pe1 ──┐
a2 + pe2 ──┼──→ Self-Attention → 带位置感知的输出
a3 + pe3 ──┤
a4 + pe4 ──┘
关键:通过正弦/余弦函数生成位置编码,让模型学习"距离"和"相对位置"
3.现在的主流方案
# RoPE (Rotary Position Embedding) - 目前最流行
# 不直接加,而是通过旋转Query和Key来注入位置信息
def apply_rope(q, k, pos):
# 把q,k在复数空间旋转角度pos*θ
# 这样 q·k 自然带有相对位置信息
return rotate(q, pos), rotate(k, pos)
"位置编码不重要" = 那种手工设计的正弦函数不重要了
"位置信息很重要" = 模型必须知道词的顺序,只是现在用更好的方式(如RoPE)来实现
-
以前:纸质地图 + 指南针(正弦PE)
-
现在:GPS实时定位(RoPE)
-
但知道自己在哪这件事永远重要!
-

2. Multi-Head Attention
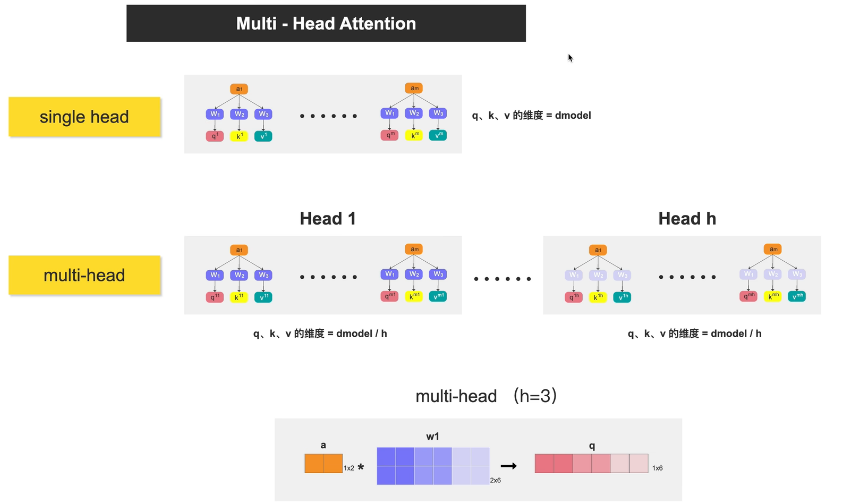
上一小节的selfhead attention可以看作是single head attention。

案件有4个嫌疑人:a1, a2, a3, a4
每个嫌疑人有512个特征(指纹、DNA、证词、监控...)
8个侦探分工:
- 侦探1(Head 1):只看前64个特征(指纹相关)
- 侦探2(Head 2):只看第65-128个特征(DNA相关)
- 侦探3(Head 3):只看第129-192个特征(证词相关)
...
- 侦探8(Head 8):只看最后64个特征(监控相关)每个侦探都要:
1. 分析4个嫌疑人(全部a)
2. 但只用自己负责的64个特征(部分qkv)
3. 独立判断谁和谁有关联(内部做attention)
4. 最后8个侦探开会,综合所有角度(拼接输出)
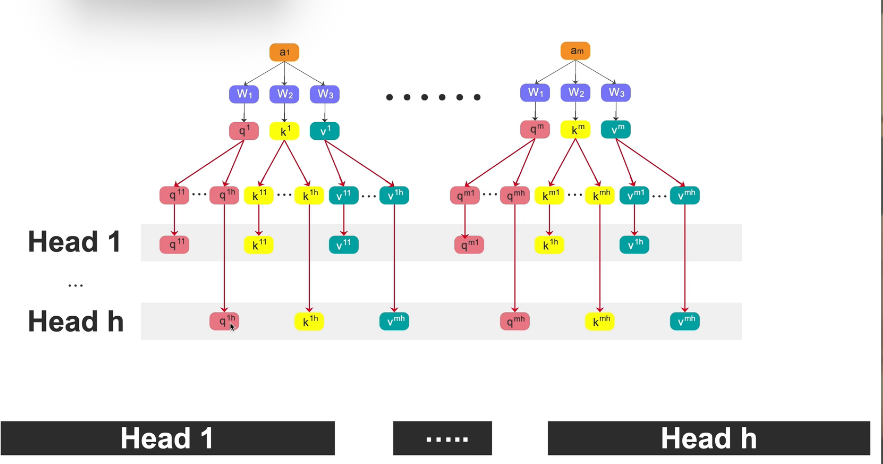
1.第一步骤
输入 → a1, a2, ..., am(m个词)
生成QKV → 每个a乘W1,W2,W3得q,k,v(完整512维)
切分 → 每个q,k,v切成h份,每份64维
分头 → 每个head拿全部m个词的部分qkv
并行计算 → h个头各自做attention
拼接 → 合并所有头的输出
同一个W,不同的a → 不同的qkv → 切开分头 → 并行计算 → 拼回输出
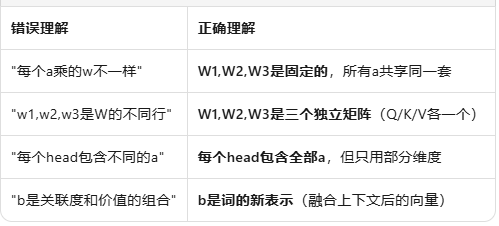
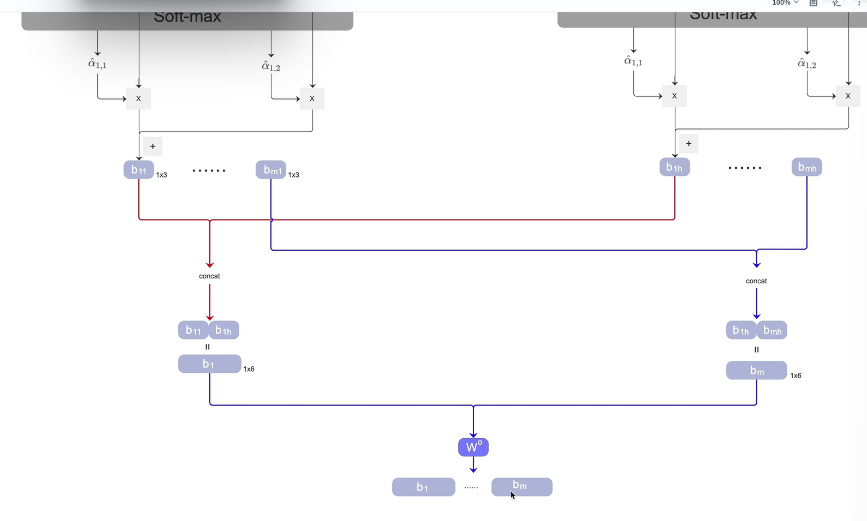
2.第二步骤
之后将b1--bm *w 做一个全连接得到新的b1-bm
每个head内部做attention,得到b,最后把所有head的b融合!
每个head独立算attention得b → 所有head的b拼接 → 融合成最终输出
最后得到的b是啥?
b = 每个词的新表示(融合了上下文信息)
具体的解释(举例):
b₁ = 0.245×v¹ + 0.015×v² + 0.245×v³ + 0.496×v⁴
↑ ↑ ↑ ↑
"我"的value "喜欢"的value "深度"的value "学习"的value
×0.245 ×0.015 ×0.245 ×0.496
↑ ↑ ↑ ↑
注意力权重 注意力权重 注意力权重 注意力权重(最高)一句话总结
b = 每个词"读完整个句子后"的新理解
不是"关联度+价值",而是:
关联度(注意力权重) 决定怎么混合
价值(v) 是被混合的原料
b 是混合后的最终产品(新的词向量)
看到"我"时,你会自动联系后面的"学习"
b₁ 就是"我"这个词在你大脑里的新印象(带上下文的那种)
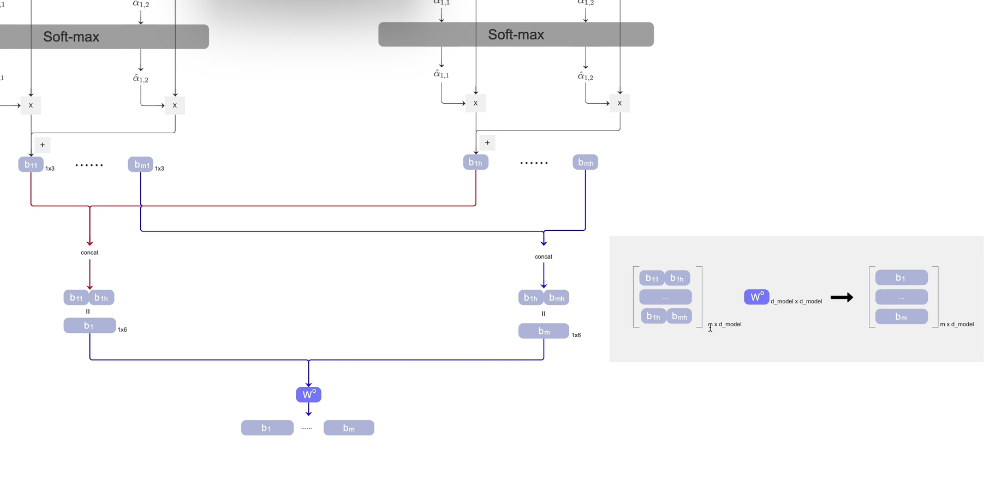
3. 第三步骤 concat拼接
Head 1 输出:[b₁₁, b₂₁, b₃₁, b₄₁] → 形状 [4, 64]
Head 2 输出:[b₁₂, b₂₂, b₃₂, b₄₂] → 形状 [4, 64]
...
Head 8 输出:[b₁₈, b₂₈, b₃₈, b₄₈] → 形状 [4, 64]拼接方式:横着拼(特征维度拼接)
[b₁₁ | b₁₂ | b₁₃ | ... | b₁₈] → b₁ 的新向量,512维
[b₂₁ | b₂₂ | b₂₃ | ... | b₂₈] → b₂ 的新向量,512维
[b₃₁ | b₃₂ | b₃₃ | ... | b₃₈] → b₃ 的新向量,512维
[b₄₁ | b₄₂ | b₄₃ | ... | b₄₈] → b₄ 的新向量,512维结果:[4, 64×8] = [4, 512]
为啥要这样拼接:
横着拼(特征维度)→ 保留所有head的信息
→ 再投影让模型学习组合 → 得到更丰富的表示
8个专家写报告 → 把8份报告订在一起 → 领导看全部再综合决策 📚


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)