机器学习中的混淆矩阵以及PR曲线、ROC曲线
这一次要讲解的是混淆矩阵的概念以及他的衍生物PR曲线和ROC曲线。
首先是混淆矩阵,顾名思义,它确实容易让人混淆,需要时刻复习不然很容易将概念混淆了。我们需要先理解了混淆矩阵里的知识点才能去理解PR曲线和ROC曲线。
混淆矩阵的定义:
混淆矩阵是机器学习中用于评估分类模型性能的一种非常直观且重要的工具。它用于总结模型在测试集上的预测结果与真实标签之间的对比情况。它的表格表示如下: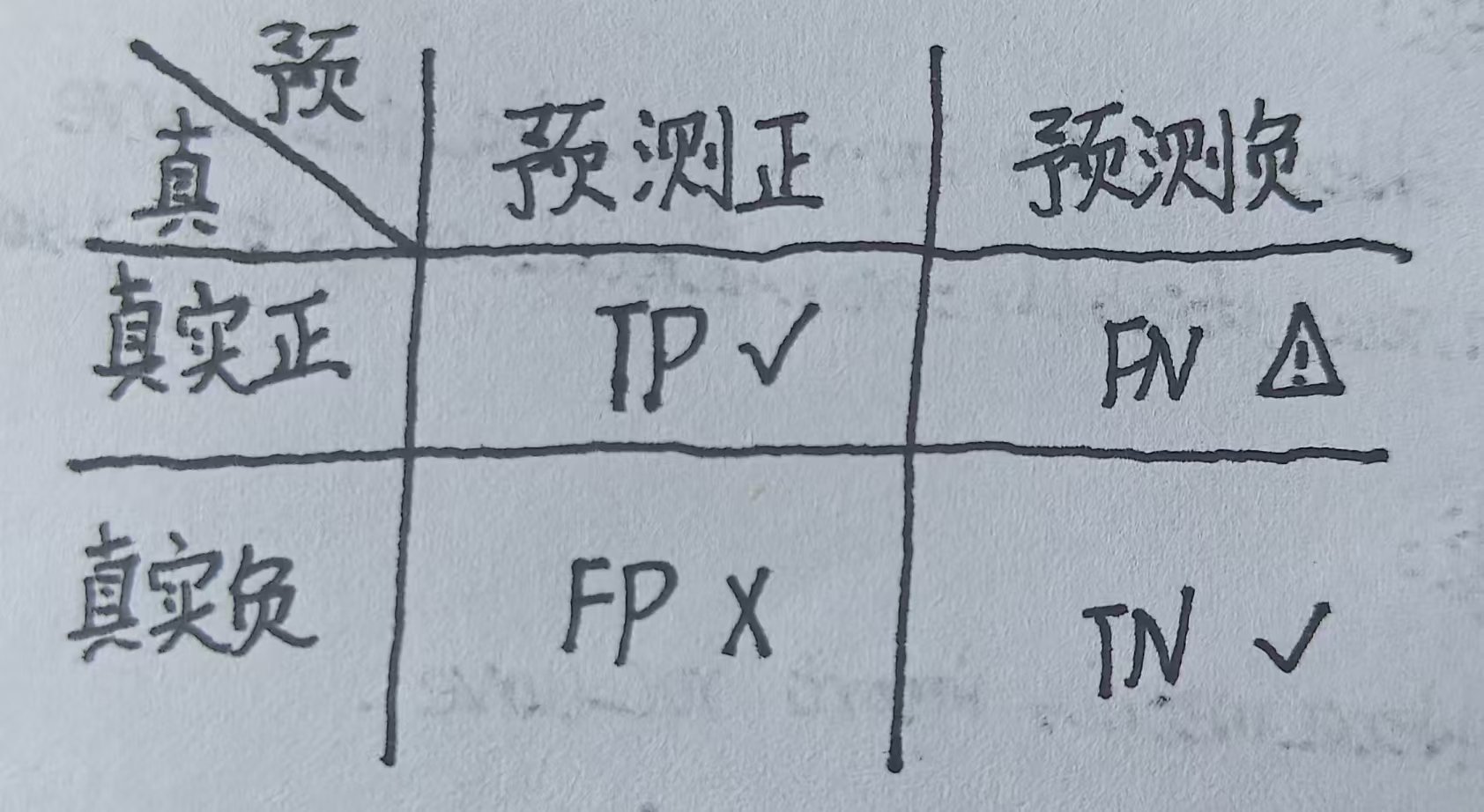

这是最常见的二分类问题混淆矩阵。它只有两个类别一个是正类,另一个是负类。上图中的右图详细解释,先看主对角线预测正确的:
TP(True Positive):模型正确地将正样本预测为正类;
TN(True Negative):模型正确地将负样本预测为负类;
然后是副对角线:
FP(False Positive)[误报]:模型错误地将负样本预测为正类;
FN(False Negative)[漏报]:模型错误地将正样本预测为负类。
本质:
混淆矩阵 = 把“预测 和 真实”地所有情况进行分类统计。
在混淆矩阵中也拓展了多个新概念:
Recall(召回率/查全率):在所有真实为正的样本中被找出来的比例;
公式:TP / TP+FN 直觉是有没有漏掉正类样本。
Precision(查准率):在预测为正的样本中,有多少是真的;
公式:TP / TP+FP 直觉是模型预测对了多少
Specificity(特异度):在所有真实为负的样本中,被正确识别的比例;
公式:TN / TN+FP
Accuracy(准确率):所有预测中正确的比例;
公式:TP+TN / TP+TN+FP+FN
Error Rate(错误率):所有预测中错误的比例。
公式:FP+FN / TP+TN+FP+FN
Recall和Precision对比: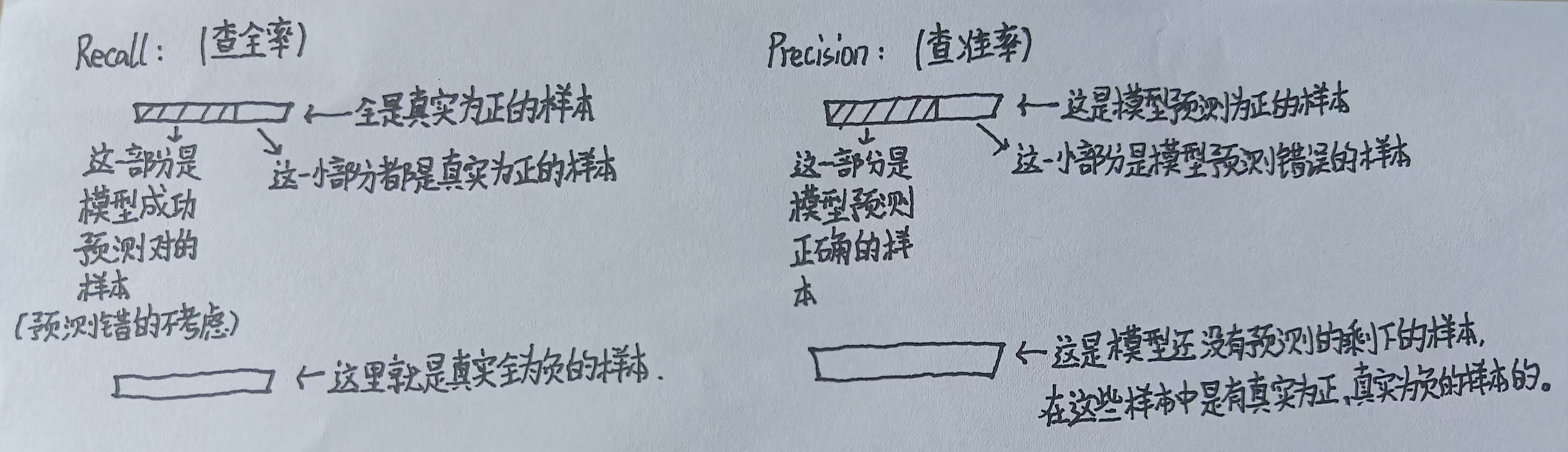
在什么情况下用哪个?
1.如果是关注整体的效果:Accuracy、Error Rate;
2.关注“误报”(FP):Precision; 比如垃圾邮件,不能误杀正常的邮件;
3.关注“漏报”(FN):Recall 比如医疗,不能够漏诊。
那么在此基础上就引入了一个新的概念,F1分数。
为什么需要F1分数?
咱们假设一个情况,当下有Precision(查准率)和Recall(查全率)。
问题:
模型A:Precision高,但是漏掉很多(Recall低);模型B:Recall高,但是误报很多(Precision高),那这两个模型哪个好???这就用到了我们的F1分数。
什么是F1分数?
F1分数就是综合了Precision和Recall的一个指标。它不是普通的平均,而是调和平均(Harmonic Mean)。
为什么要用调和平均?
因为调和平均有一个特性,只要有一个很低,整体就很低。
举个栗子:Precision=1、Recall=0,那么F1=0;
Precision=0.9,Recall=0.9,那么F1≈0.9。
结论:F1就是强制两个指标都要好。
从混淆矩阵角度理解:当前我们知道Precision=TP / TP+FP,Recall=TP / TP+FN,F1的本质就是同时惩罚FP和FN。
什么情况下用到F1?
类别不平衡,同时关心误报和漏报。
总结:F1分数是查准率和查全率的调和平均,用于在类别不平衡或需要关注误报和漏报时,综合评估分类模型性能的指标。
那么他们在sklearn中是怎么表示的?
from sklearn.metrics import(
confusion_matrix, #混淆矩阵
accuracy_score, #准确率
precision_score, #查准率
recall_score, #查全率
f1_score #F1分数
)那么混淆矩阵里面的概念就全部解释完了,接下来就是PR曲线和ROC曲线了。
首先是PR曲线:
PR曲线(Precision--Recall Curve,精确率-召回率曲线):
它是机器学习中用于评估二分类模型性能的重要可视化工具,尤其是在正负样本不平衡的情况下效果很好。
定义:横轴为Recall(查全率),纵轴为Precision(查准率)绘制的一条曲线。
本质:在不同阈值下,Precision和Recall的权衡关系。
阈值变化:当阈值低时,Recall高,但Precision低;当阈值高时,Precision高,但Recall低。
怎么去看PR曲线???
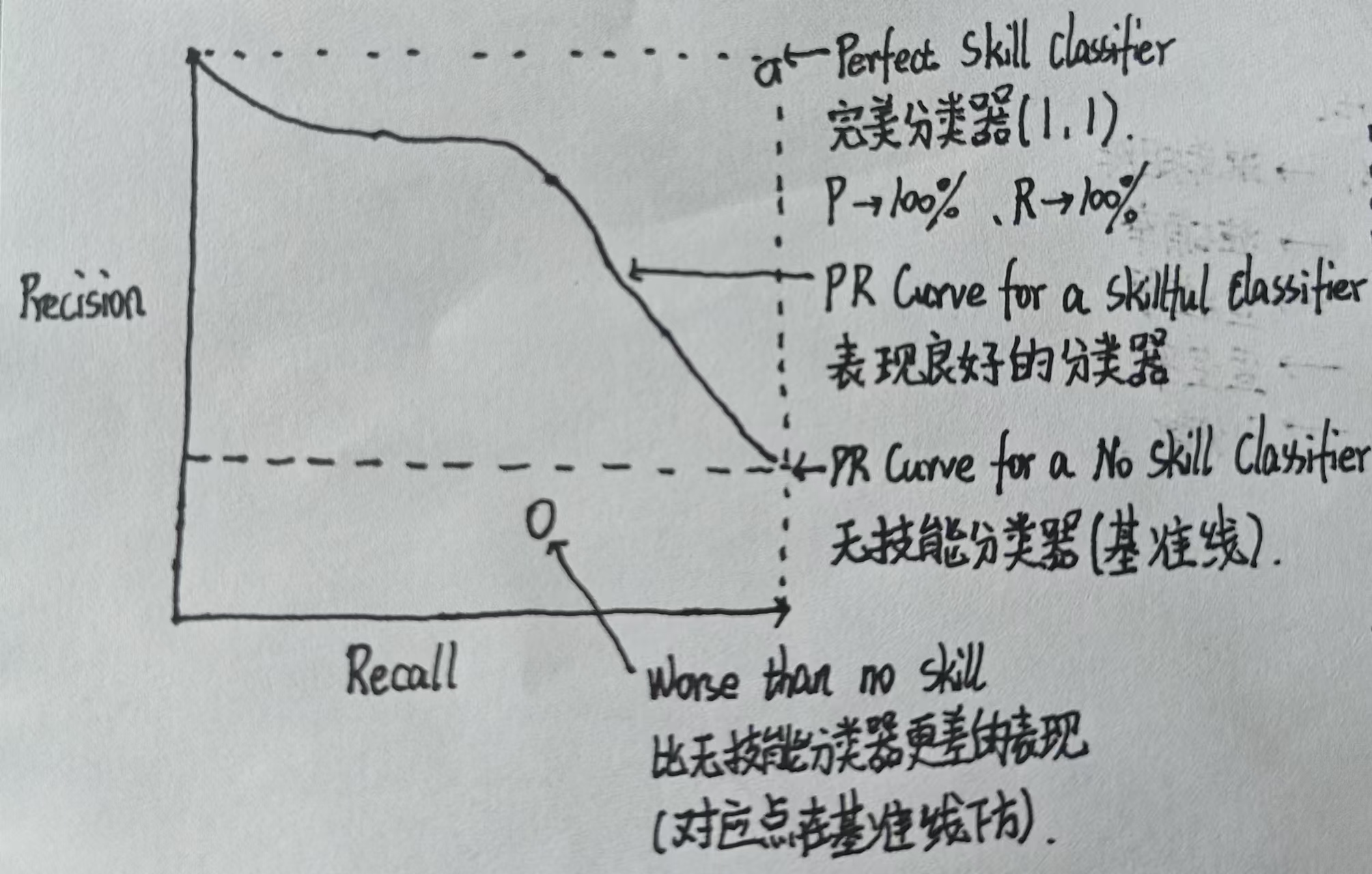
由图我们可以看出,我们的模型越接近右上角模型越完美,越倾向于右上角模型越好,最差的情况就是在基准线下方。
接下来是ROC曲线。
ROC曲线(Receiver Operating Characteristic Curve):是机器学习中用来评估二分类模型性能的最经典、可视化工具之一。
定义:横轴为假正率(False Positive Rate, FPR),纵轴为真正率(True Positive Rate, TPR)绘制的一条曲线。
假正率和真正率:
假正率(FPR) = FP / FP+TN,也就是1-Specificity(特异度);
真正率(TPR),其实就是我们的Recall(查准率) = TP / TP+FN。
本质:模型区分“正类 和 负类”的能力。比如:有一条线,如果是副对角线(线性),那么他就是随机模型;如果这条线越向左上角弯曲,那么它的模型越好。
那么这里还有一个概念,AUC,AUC是什么?就是ROC曲线下的面积。它的含义是,随机抽一个正样本比负样本得分高的概率。
怎么看ROC曲线???
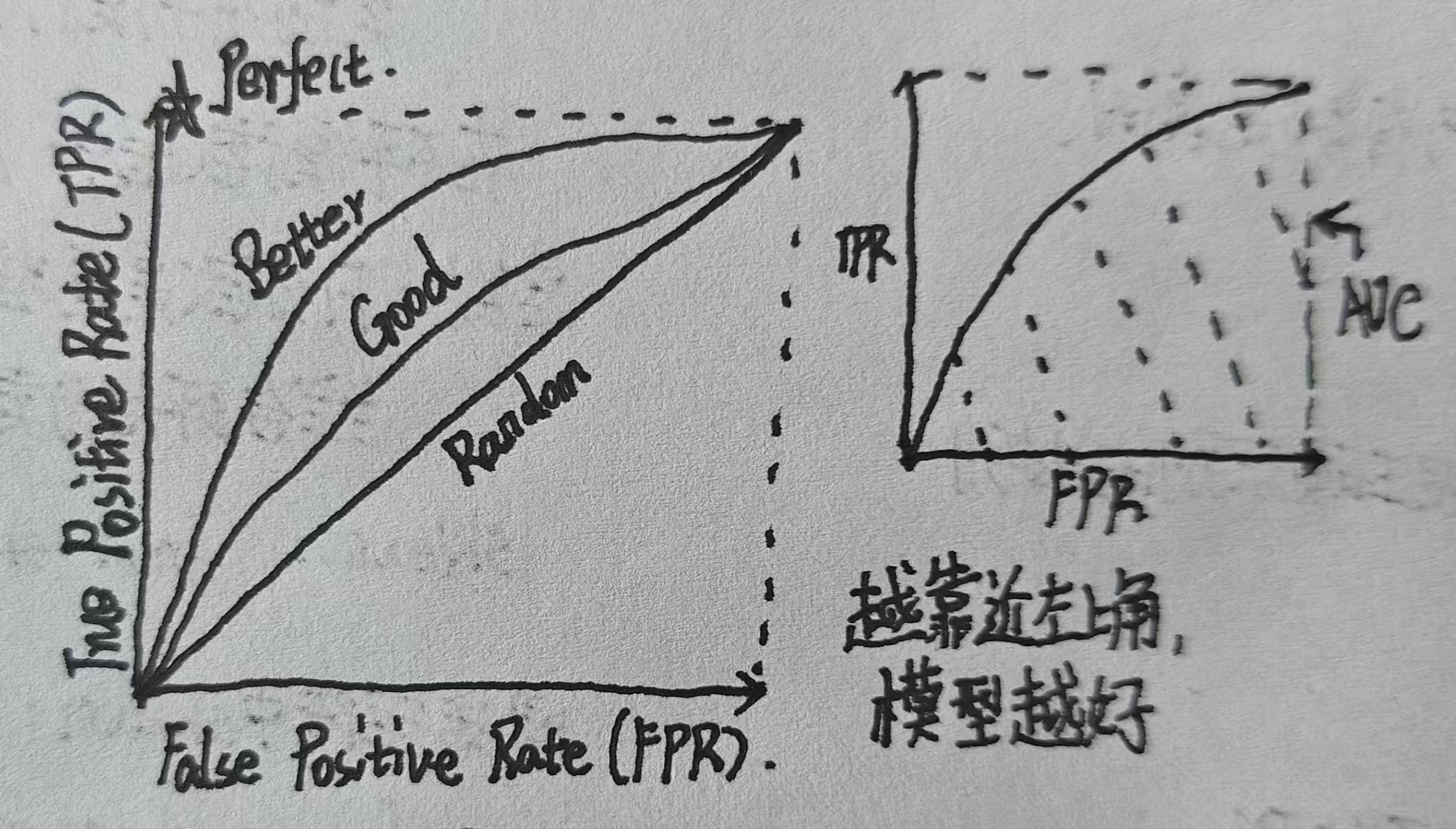
由图可以看出,我们的模型越接近左上角模型越完美,越倾向于左上角模型越好,如果变成了一条线,那很差了。而AUC就是我们曲线下方的面积。
那么什么情况下使用PR曲线,什么情况下使用ROC呢?
首先是PR曲线:
PR曲线关注的是正类(Precision + Recall),它只关心正类预测的怎么样。
情况一:类别严重不平衡。
比如:欺诈检测,有一万个数据,9990个是正常数据,10个是欺诈数据。如果是ROC曲线的话,模型可能很好,但是模型其实根本没抓住正类。因为FPR = FP / FP+TN,TN巨大导致FPR很小,因此ROC被“稀释”。所以应该使用PR曲线,PR曲线能够更真实地反应模型能力。
情况二:只关心“正类”。
比如:在癌症筛查、稀有疾病检测、异常检测等人物中,我们主要关注模型对正类(患病、异常)地识别能力,而对负类(健康、正常)地误判容忍度较高。
其次是ROC曲线:
ROC曲线关注的是整体(TPR + FPR),同时考虑正类 + 负类。
情况一:类别比较均衡。
比如:有猫和狗的数据各一半,这个时候ROC更稳定。
情况二:关心整体排序能力。
比如:在推荐系统、信用评分、搜索引擎结果排序等场景中,我们最关心模型对样本的排序质量(将正样本尽量排在负样本前面),而不是在某一个固定阈值下Precision和Recall的具体数值。此时的ROC曲线和AUC指标的优势非常明显,他不依赖具体分类阈值,能全面反映模型的整体区分能力。AUC越高,说明模型的排序性能越好。
总结:PR曲线适用于类别不平衡或更关注正类预测性能的场景,因为他直接反映查准率和查全率的权衡;而ROC曲线适用于类别相对均衡或需要评估模型整体区分能力的场景,通过真正率和假正率衡量模型性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)