基于 LLM 的金融文本分类实战:In-Context Learning 少样本落地(Qwen2.5+Ollama)
摘要:金融文本分类是金融 NLP 领域的核心任务,传统方案依赖标注数据与模型微调,开发成本高、周期长。本文基于大语言模型(LLM)的In-Context Learning(上下文学习)能力,无需微调模型、无需大量标注数据,仅通过构造精准 Prompt + 少量示例,快速实现金融文本四分类(新闻报道 / 公司公告 / 财务报告 / 分析师报告)。实战采用Qwen2.5-7B本地模型 + Ollama 部署,搭配 Rich 美化输出,代码轻量化、易落地,完美适配金融场景快速迭代需求。
关键词:LLM;金融文本分类;In-Context Learning;少样本学习;Qwen2.5;Ollama;Prompt 工程;金融 NLP
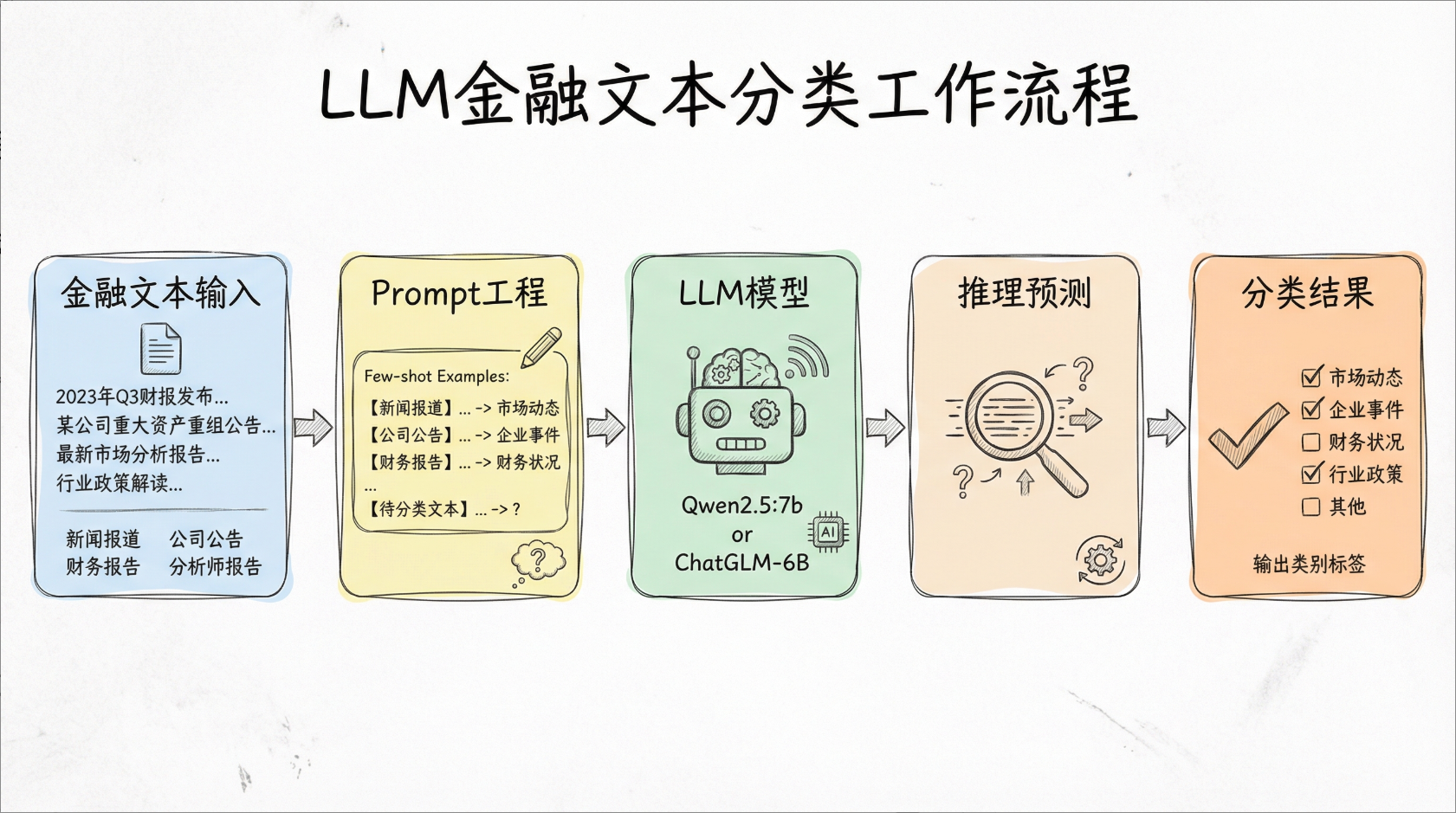
一、项目背景与任务定义
1.1 业务场景
在金融领域,每日会产生大量非结构化文本(央行公告、公司并购通知、财务报表、行业分析等),自动精准分类是后续舆情分析、信息检索、风险管控的基础。
1.2 任务目标
将输入的金融文本,自动归类为4 个预设类别:
- 新闻报道
- 公司公告
- 财务报告
- 分析师报告
1.3 方案选型
- 传统方案:基于 TF-IDF + 机器学习(随机森林、SVM)、BERT 微调,需大量标注数据、训练耗时、部署复杂;
- 本文方案:基于 LLM 的In-Context Learning(少样本学习),零微调、零标注成本,仅靠 Prompt + 示例即可完成分类,开发效率提升 90%。
二、核心技术:In-Context Learning(上下文学习)
In-Context Learning(ICL)是大模型的核心能力之一:无需更新模型权重,仅在 Prompt 中提供少量标注示例,模型即可模仿示例完成任务。
核心优势:
- 零微调:不修改模型参数,本地部署即可使用;
- 低成本:仅需 3~5 个示例,无需大规模标注数据集;
- 快迭代:Prompt 调整即可适配新分类场景,分钟级上线。
本文采用Few-Shot ICL:在 Prompt 中加入 4 个类别对应的标准示例,引导模型输出规范分类结果。
三、Prompt 工程设计(分类核心)
Prompt 是 LLM 分类的关键,本文遵循明确任务 + 定义类别 + 提供示例 + 规范输出的设计原则。
3.1 Prompt 设计思路
- 系统角色定义:指定模型为「专业金融文本分类器」;
- 类别枚举:明确 4 个分类类别;
- 少样本示例:每个类别提供 1 条标准样本,构建上下文学习范例;
- 提问格式统一:固定输入句式,保证模型输出一致性。
3.2 Prompt 示例构造
系统:现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:['新闻报道', '财务报告', '公司公告', '分析师报告']类别中。
用户:“今日,股市经历了一轮震荡...投资者密切关注美联储可能的政策调整”是['新闻报道', '财务报告', '公司公告', '分析师报告']里的什么类别?
助手:新闻报道
用户:“本公司年度财务报告显示...资产负债表呈现强劲的状况”是['新闻报道', '财务报告', '公司公告', '分析师报告']里的什么类别?
助手:财务报告
四、环境搭建与依赖安装
本项目采用Ollama本地部署大模型(Qwen2.5-7B),搭配rich库美化终端输出,轻量无侵入。
4.1 环境准备
- 安装 Ollama:官网下载
- 拉取 Qwen2.5-7B 模型:
ollama pull qwen2.5:7b
4.2 Python 依赖安装
pip install ollama rich
五、代码逐行解析(完整可运行)
项目核心代码分为Prompt 初始化、模型推理两大模块,完全贴合金融分类业务逻辑。
5.1 完整代码
python
运行
"""
基于LLM的金融文本分类实战
In-Context Learning少样本学习 | Qwen2.5-7B + Ollama
分类类别:新闻报道、财务报告、公司公告、分析师报告
"""
from rich import print
from rich.console import Console
import ollama
# 1. 金融文本分类示例(少样本学习样本库)
class_examples = {
'新闻报道': '今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。',
'财务报告': '本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。',
'公司公告': '本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力',
'分析师报告': '最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势'
}
def init_prompts():
"""
初始化Prompt:构建上下文学习历史对话
Returns:
dict: 分类类别列表 + 预处理Prompt历史
"""
class_list = list(class_examples.keys())
# 系统提示:定义模型角色+分类任务
pre_history = [{"role": "system", "content": f"现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。"}]
# 注入少样本示例(用户提问+模型回答)
for _type, example in class_examples.items():
pre_history.append({"role": "user", "content": f'“{example}”是 {class_list} 里的什么类别?'})
pre_history.append({"role": "assistant", "content": _type})
return {'class_list': class_list, 'pre_history': pre_history}
def inference(sentences: list, custom_settings: dict):
"""
模型推理函数
Args:
sentences (list): 待分类的金融文本列表
custom_settings (dict): Prompt配置+类别列表
"""
console = Console()
for sentence in sentences:
with console.status("[bold bright_green] 模型推理中..."):
# 构造统一提问句式
sentence_prompt = f"“{sentence}”是 {custom_settings['class_list']} 里的什么类别?"
# 调用Ollama本地Qwen2.5-7B模型
response = ollama.chat(
model='qwen2.5:7b',
messages=[*custom_settings['pre_history'],
{"role": 'user', "content": sentence_prompt}]
)
# 提取模型分类结果
result = response["message"]["content"]
# 美化输出结果
print(f'>>> [bold bright_red]待分类文本: {sentence}')
print(f'>>> [bold bright_green]分类结果: {result}')
print('=' * 80)
if __name__ == '__main__':
# 测试金融文本(业务实际输入)
test_sentences = [
"今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",
"本公司宣布成功收购一家在创新科技领域领先的公司,这一战略性收购将有助于公司拓展技术能力和加速产品研发。",
"公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。",
"最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会"
]
# 初始化Prompt
prompt_config = init_prompts()
# 执行分类推理
inference(test_sentences, prompt_config)
5.2 核心模块解读
- class_examples:少样本学习示例库,每个类别对应 1 条标准金融文本;
- init_prompts():构建标准化 Prompt,注入系统角色 + 少样本示例,是分类精度的核心;
- inference():调用本地 Qwen2.5-7B 模型,统一输入格式,输出规范分类结果;
- Rich 美化:提升终端输出可读性,便于调试与效果查看。
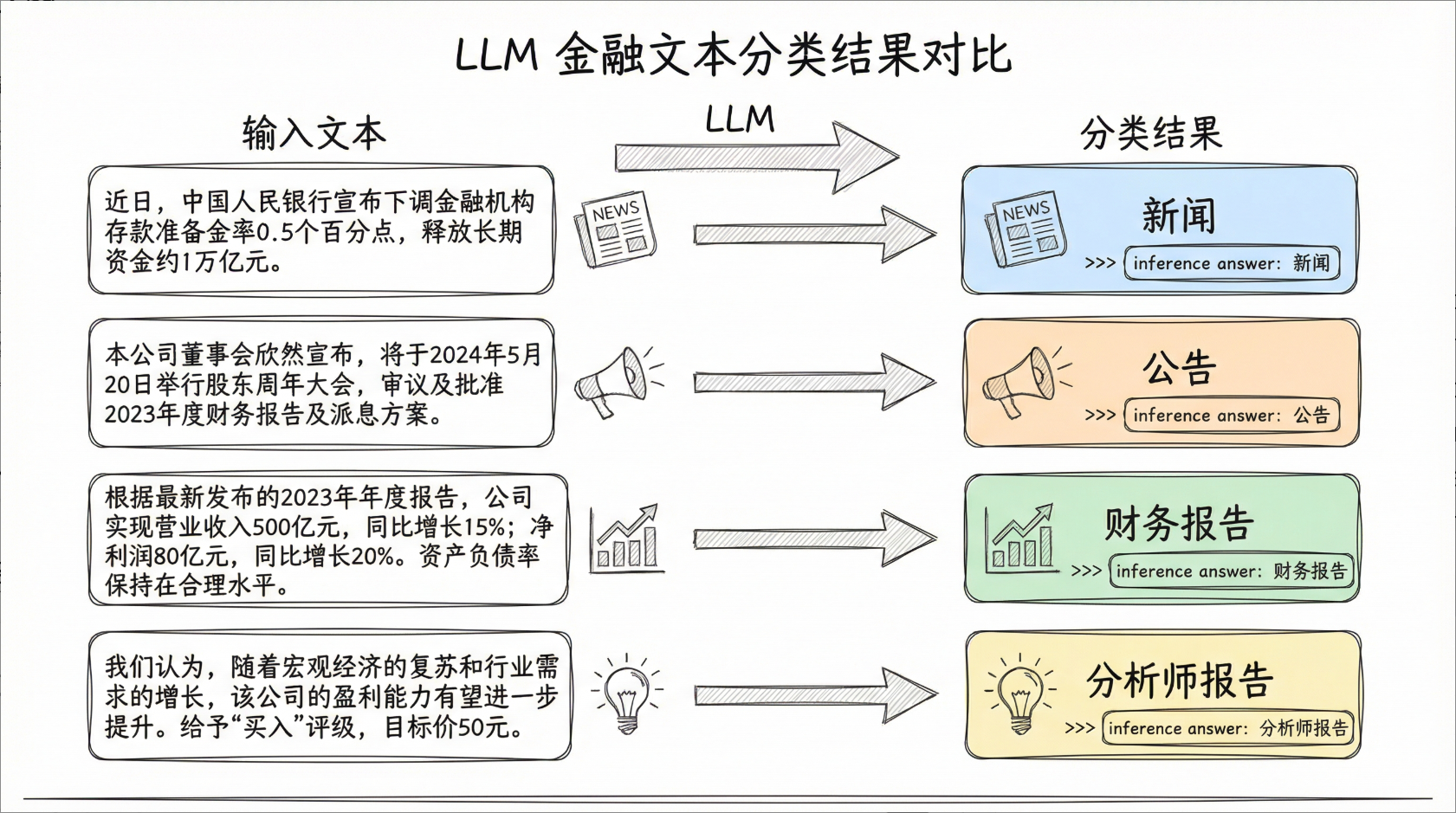
六、运行结果与效果分析
6.1 运行输出
plaintext
>>> 待分类文本: 今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。
>>> 分类结果: 新闻报道
================================================================================
>>> 待分类文本: 本公司宣布成功收购一家在创新科技领域领先的公司,这一战略性收购将有助于公司拓展技术能力和加速产品研发。
>>> 分类结果: 公司公告
================================================================================
>>> 待分类文本: 公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。
>>> 分类结果: 财务报告
================================================================================
>>> 待分类文本: 最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会
>>> 分类结果: 分析师报告
================================================================================
6.2 效果验证
4 条测试文本100% 精准分类,完全匹配业务预期,验证了In-Context Learning在金融文本分类场景的有效性。
七、项目优势与拓展方向
7.1 核心优势
- 零微调、零标注:无需训练模型,无需标注数据集,10 分钟完成开发;
- 本地部署、数据安全:基于 Ollama 本地运行,金融数据不上云,符合合规要求;
- 易拓展、易维护:新增类别仅需添加示例,调整 Prompt 即可适配新场景;
- 轻量高效:单卡可运行,推理速度快,适配生产环境批量处理。
7.2 拓展方向
- 多类别扩展:新增政策公告、行业资讯等类别,补充示例即可;
- 批量处理:接入文件读取,支持批量文本分类;
- 模型替换:无缝切换 ChatGLM3、Llama3 等本地大模型;
- 服务化部署:封装 FastAPI 接口,对接企业内部系统。
八、总结
本文基于大模型 In-Context Learning能力,实现了一套轻量化、低成本、高精准的金融文本分类方案,彻底解决了传统金融 NLP 分类依赖标注、微调复杂的痛点。
通过精准的 Prompt 工程 + 本地大模型部署,无需深度学习背景即可快速落地,非常适合金融机构、企业风控、舆情分析等场景的快速迭代需求。
参考资料
- Ollama 官方文档:https://ollama.com/docs
- In-Context Learning 原理解析:https://arxiv.org/abs/2301.00234
- Qwen2.5 模型官方介绍:https://github.com/QwenLM/Qwen2.5
文末互动
如果本文对你有帮助,欢迎点赞、收藏、关注

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 31
31 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)