超越语义特征:用于通用AI生成图像检测的像素级映射
超越语义特征:用于通用AI生成图像检测的像素级映射
摘要
生成技术的快速发展使得可靠的 AI 生成图像检测方法变得尤为必要。现有检测器的一个关键局限在于,它们难以泛化到来自未见过的生成模型的图像,因为它们往往过度依赖源模型特定的语义线索,而未能学习通用的生成痕迹。为了解决这一问题,我们提出了一种简单但极为有效的像素级映射预处理方法,通过扰动图像的像素值分布,打破检测器常用的脆弱且非必要的语义模式(通常被检测器作为捷径利用)。这一策略迫使检测器关注图像生成过程中固有的、可泛化的高频痕迹。通过对 GAN 和扩散模型生成图像的全面实验,我们展示了该方法显著提升了现有最先进检测器的跨生成器性能。进一步的分析也验证了我们的假设:破坏语义线索是实现泛化的关键。(现有生成图像检测器为什么无法泛化到未见过的伪影,因为他们学习到了语义线索,就是因为他们学习到了语义线索所以才无法泛化到其他生成模型,他们把语义特征当成了一种捷径就是模型会偷懒相当于短路,作者就提出了一个很有趣的观点,加入我们把像素完全打乱,那么就可以强迫模型学习到通用的伪影特征。)
1.引言
从生成对抗网络(Generative Adversarial Networks, GANs)(Goodfellow 等,2014)到现代扩散模型(Diffusion Models)(Ho, Jain, and Abbeel, 2020),生成模型的快速发展推动了 AI 生成图像在逼真度和多样性方面取得显著提升,以至于这些图像几乎与真实照片无法区分。虽然这些生成技术在创意艺术和工业应用中激发了创新,但它们同时也引发了视觉真实性的危机。AI 生成的伪造图像的泛滥带来了重大社会风险,尤其是在传播虚假信息和削弱关键领域证据可靠性方面。这一新兴威胁格局凸显了在 AI 安全领域中开发稳健检测方法的迫切需求。(开头永远是AI生成技术怎么怎么牛逼,引发了视觉真实性的危机,我们需要迫切开发AI安全领域的稳健检测方法。)
在同分布检测(in-distribution detection)任务中,分类器通常能够取得极高的准确率,但当面对未知生成模型的图像时,其检测性能会显著下降。为应对检测中的泛化挑战,现有方法通常可分为两类:以数据为中心的方法,通过预处理图像以突出取证痕迹;以及以模型为中心的方法,旨在学习更具泛化能力的特征。Wang 等(2020)表明,激进的数据增强可以使卷积分类器实现跨模型的泛化;而 Durall、Keuper 和 Keuper(2020)则通过分析 GAN 生成图像的频域异常,发现由上采样操作产生的高频伪影可用于泛化检测。近期方法利用了大规模预训练模型的强大特征学习能力(Ojha, Li, and Lee, 2023;Tan 等, 2025;Cozzolino 等, 2024;Khan 和 Dang-Nguyen, 2024),假设其在大规模真实图像数据集上的预训练使得模型能够通过特征分布偏差检测合成内容。
虽然现有方法在测试分布与训练分布一致时具有良好的泛化能力,但在存在显著语义变化的情况下,其准确率会明显下降。这一问题主要源于生成模型在训练数据上拟合不完全而产生的语义偏差差异(Yan 等, 2025;Guillaro 等, 2025),表现为图像中的模糊和纹理异常等视觉伪影。然而,不同生成模型存在各自特定的语义偏差。随着生成模型在架构和采样技术上的不断改进,这些语义偏差逐渐减弱,从而导致依赖语义偏差的检测器性能下降。因此,在分类器训练过程中降低语义偏差的影响对于实现检测的泛化至关重要。(现有方法在训练和测试时有良好的泛化能力,是意外呢他们粗壮乃显著的语义偏差。所以准确率会下降,现有的模型总是把图片中的一些模糊或者伪影当作伪影,其实那些模糊和纹理异常并不是伪影而是语义信息)
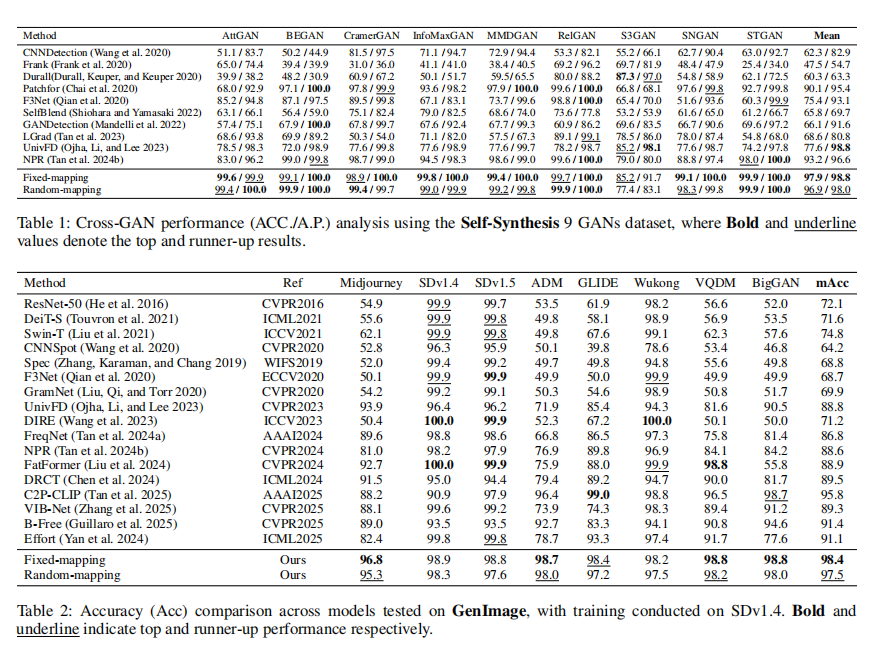
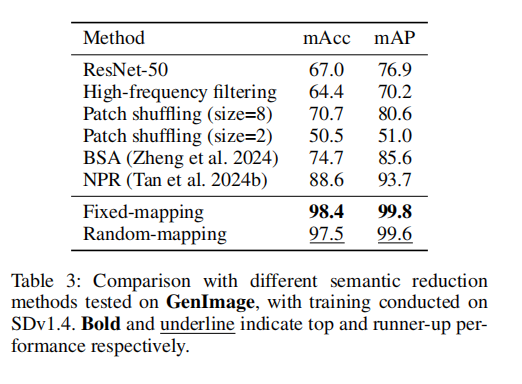
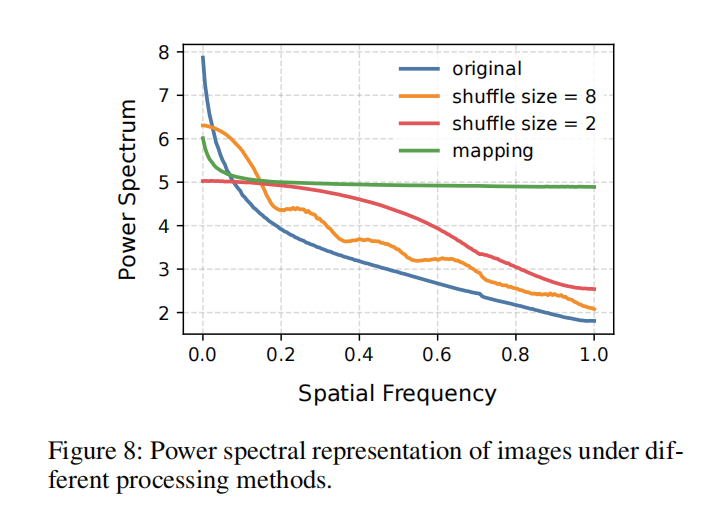
为减轻语义偏差的影响,一些方法利用傅里叶变换将图像转换到频域,在重建图像前通过掩码去除低频成分(Tan 等, 2024b;Bammey, 2023;Chu 等, 2024)。尽管这种频域裁剪可以部分抑制低频信息,但无法完全消除其干扰,并且不可避免地会造成信息损失,从而降低生成痕迹检测的效果。另一类方法采用图像块打乱(patch shuffling)(Fu 等, 2025;Liu 等, 2022;Zheng 等, 2024)来缩小分类器的感受野,从而防止对抽象语义模式的过拟合。然而,如图 2 所示,高通滤波和 NPR(Tan 等, 2024b)方法仍会在图像中保留明显的语义信息。此外,尽管随着块大小减小,打乱方法能够逐步破坏语义,但如图 1 的 ImageNet 分类实验所示,即便在最小块大小为 2 的情况下,模型仍能从打乱后的图像块中提取足够的语义信息,只是收敛速度较慢且验证准确率下降。(我们现在使用的频率方法比如傅里叶变换 变换得到的低频信息就是语义信息 高频信息就是伪影信息,我们做频域变换其实也就是强化伪影信息,进而消除语义信息,同时也有人把图片切成小块打乱来去做去除语义信息,图片约乱他们的准确率就越好)
针对现有语义抑制方法的局限性,本文提出了一种像素级映射方法(pixel-level mapping),通过像素值变换来降低语义偏差。由于语义偏差主要集中在图像的低频成分,我们的方法通过放大像素间差异来抑制低频模式,同时保留可检测的高频生成痕迹。如图 1 和图 2 所示,该映射方法相比基线方法和打乱方法在语义抑制上更为有效,同时验证准确率更低,验证了语义信息确实被有效削弱。通过转换低频信息,语义偏差对分类器的影响显著降低,从而在训练过程中增强了高频生成痕迹的作用。在操作像素值的同时,该方法保留了像素的局部相关性,相比现有的偏差缓解策略具有两个明显优势 图像处理过程中信息损失最小;分类器训练时对高频取证特征的关注得到增强。 在多种数据集和生成模型(GAN 与扩散模型)上的全面实验表明,该方法能够持续提升检测泛化性能。(目前还没有人对像素级做映射来去做生成图像检测的,于是作者提出通过像素值变换来降低语义偏差,由于语义偏差主要集中在图像的低频成分,我们的方法通过放大像素间差异来抑制低频模式,同时保留可检测的高频生成痕迹。
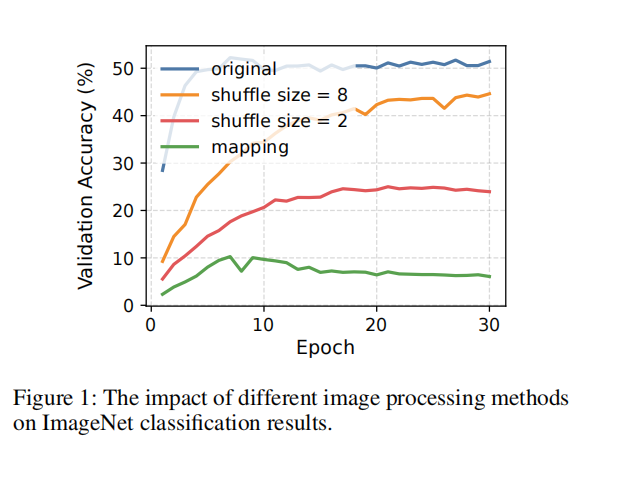
(作者做了一个图像分类任务就是使用Imagenet去做图像分类,原始图像 网络能够凭借语义信息达到百分之50的准确率,而作者使用自己方法后,模型分不出来了,准确率剩下10%,这说明作者的方法完美把语义信息去破坏掉了)

本文的主要贡献
我们通过实验证明,简单的高通滤波和图像块打乱方法无法有效消除语义信息,因此不足以减轻语义偏差对检测泛化的影响。我们的研究结果揭示了现有方法的关键局限性,并强调了开发更精细语义抑制方法的必要性。
我们提出了一种新颖的像素级映射方法,在分类器训练过程中能够显著削弱语义偏差。通过在增强高频生成痕迹的同时转换低频信息,该方法显著降低了分类器对偏置语义特征的依赖,从而解决了合成图像检测中的核心泛化问题。对多个基准数据集的广泛验证进一步证明了该方法的有效性。实验结果显示,在检测来自未见生成架构的图像时,本方法持续提升性能,充分体现了其泛化能力。
2.相关工作
2.1生成模型
生成模型与传统自编码器(Masci et al. 2011;Vincent et al. 2008;Salah et al. 2011)在本质上的区别在于,前者能够采样生成符合已有数据分布的新样本。GAN 最初主导了合成图像生成领域,其关键变体分别针对特定限制进行了改进:ProGAN(Karras et al. 2017)用于渐进式训练,StyleGAN(Karras, Laine, and Aila 2019)用于学习解耦表征,BigGAN(Brock, Donahue, and Simonyan 2018)用于大规模图像合成,而 StarGAN(Choi et al. 2018)则用于多域图像到图像转换。尽管 GAN 具有推理速度快、模块扩展性强等优势,但由于生成质量受限,往往会产生较为明显的语义伪影。随后,扩散模型(Ho, Jain, and Abbeel 2020;Song, Meng, and Ermon 2020;Song et al. 2020)作为一种具有良好数学基础的生成框架出现,不仅克服了 GAN 训练不稳定的问题,同时也保证了更好的样本多样性。近期的大规模实现方法(Rombach et al. 2022;Ramesh et al. 2022;Saharia et al. 2022)在海量数据集上进行训练,从而实现了逼真、高分辨率的图像生成。这些在生成质量和多样性上的快速进步显著减少了语义伪影,因此削弱了那些依赖语义特征进行检测的方法的有效性。(作者从GAN模型和扩散模型的发展历程讲了一下生成模型的相关工作,在这里强调了一下 ,目前扩散模型的生成质量以及越来越高了,其实语义伪影以及显著减少了,这削弱了那些以来语义特征进行检测的方法的有效性)。
2.2 AI生成图像检测
合成图像检测中的泛化挑战最早由 Wang et al.(2020)提出,他们表明,强数据增强能够实现跨 GAN 检测。随后,Durall、Keuper 和 Keuper(2020)揭示了 GAN 上采样过程会引入明显的高频伪影,这些伪影可以通过频谱分析进行检测。然而,这类基于 GAN 的观察限制了分类器的泛化能力。扩散模型的出现进一步加剧了这一挑战,因为更高的图像保真度消除了许多可检测的伪影。因此,后续方法(Ojha, Li, and Lee 2023;Cozzolino et al. 2024;Tan et al. 2025)开始利用大规模预训练模型,通过捕捉合成图像相对于自然图像分布的偏离来进行检测。然而,这些模型主要依赖语义特征,而忽略了与生成伪影相关的高频痕迹。当测试数据偏离微调分布时,它们的检测性能会显著下降,并在不同域之间表现出不稳定性。
为减轻分类器对语义偏差的过度依赖,现有方法通常通过频域操作或图像块打乱来破坏全局语义。一些研究(Tan et al. 2024b;Bammey 2023;Chu et al. 2024)通过残差操作或频率滤波提取高频成分,以减弱语义干扰。然而,去除特定频带并不能完全消除语义影响,而且由于生成伪影与语义内容之间存在固有耦合,直接进行频域抑制会带来附带损伤。另一方面,图像块打乱策略(Fu et al. 2025;Liu et al. 2022;Zheng et al. 2024)旨在通过随机置换图像块来限制分类器的感受野。这类语义抑制技术的目标,是迫使分类器优先关注能够更好跨生成架构泛化的取证痕迹。然而,我们的实验表明,分类器仍然可以凭借强大的拟合能力,从打乱后的图像块中捕获语义信息。与此同时,打乱操作还可能破坏生成伪影的全局结构模式。
(在这里作者聊了一些AI生成图像检测的方法,说传统方法依赖语义信息,频域方法是为了破坏语义信息,还有图像块打乱什么的这些都是和语义信息相关的,作者这里是紧贴着语义信息走的,和作者的主题是一致的)
3.方法
2.1 预备知识

2.2 用于降低语义偏差的像素级映射
合成图像中的生成痕迹与语义内容之间存在紧密耦合,其中对语义的扰动往往不可避免地会改变伪影分布。现有研究通常认为,语义偏差主要与图像平滑区域中的低频成分相关,而生成痕迹则与高频细节有关(Tan et al. 2024a;Bammey 2023)。卷积分类器对低频特征的归纳偏置(Tang et al. 2022)进一步加剧了训练过程中语义信息的主导地位。因此,削弱低频语义偏差并增强高频痕迹,是提升检测泛化能力的一条有前景的途径。(为什么卷积神经网络会对语义特别在意,因为卷积神经网络会对于语义有偏执,加剧了语义信息的主导地位,因为再卷积神经网络中,语义是主导地位 所以模型才回去学习语义特征而不是伪影特征。)
为此,我们提出了一种像素级映射方法,将按单调顺序排列的像素值(0–255)转换为一组新的像素值,从而改变相邻像素之间原本紧密的空间排列关系。该变换在保留像素相关性的同时,将图像中的低频信息转化为高频信息。整体过程如图 3(a) 所示。输入图像在送入分类头之前,首先通过一个像素级映射模块完成语义变换。为了通过放大像素值之间的差异,有效地将低频信息转化为高频成分,我们在图 3(b) 所示的像素级映射模块中提出了一种计算高效的固定映射方法。(作者就是提出了像素级因施工和方法,将按单调顺序排列的像素值(0–255)转换为一组新的像素值,从而改变相邻像素之间原本紧密的空间排列关系。我们在图 3(b) 所示的像素级映射模块中提出了一种计算高效的固定映射方法。)。
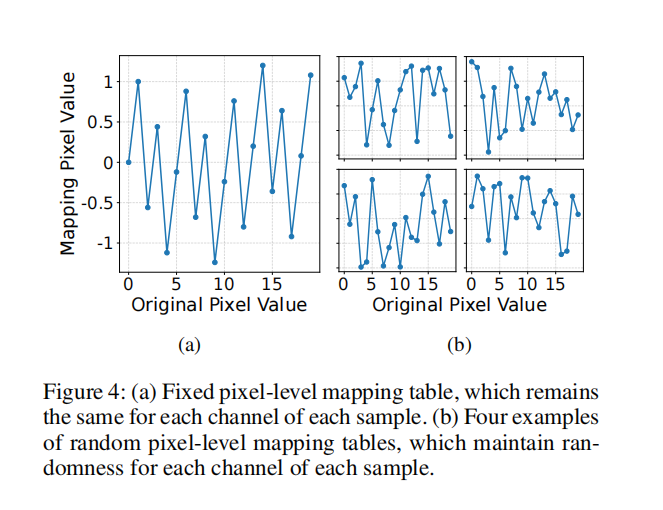
我们进一步的大量实验结果揭示了一个重要现象:具体采用何种像素映射关系本身并不是关键因素。真正关键的是打乱原始单调的像素排列关系。即使采用如图 3(c) 所示、针对每个样本变化的完全随机映射关系,检测精度在统计意义上仍与确定性映射相当。因此,本文提出的固定映射实际上可以看作这一更广义映射范式的一种具体实现。所提出的像素级映射模块具体实现如下:
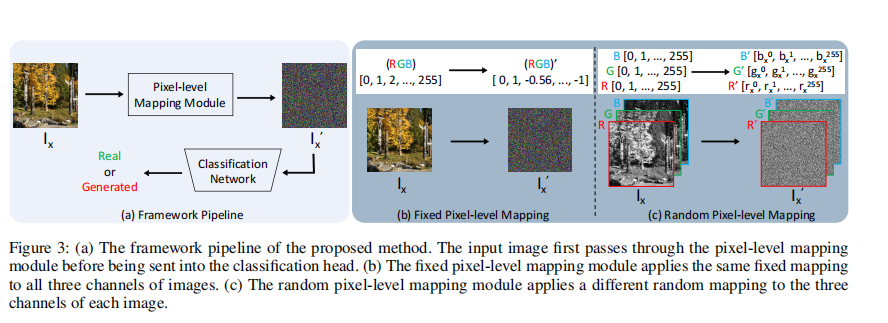
2.2.1 固定像素映射模块


2.2.2 随机像素映射模块

(作者换了一个映射公式,一个公式一个通道一个映射表格,然后发现效果仍然很好)
4.实验





5.结论
本文提出了一种像素级映射方法,通过抑制低频特征并增强高频伪影,缓解了分类器对语义偏差的依赖,从而显著提升了跨模型和跨分布检测的泛化能力。该方法作为一种计算高效的预处理步骤,在分类之前对像素值进行变换,以放大像素间差异并破坏低频偏差。在多个基准数据集上的大量实验表明,所提出的方法在泛化场景下取得了优异性能,为合成图像检测中的语义偏差抑制提供了新的思路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)