AI系统-14特斯拉FSD芯片
 之前的文章讲了特斯拉的AI训练芯片DOJO:AI系统-13特斯拉AI芯片DOJO,那之前特斯拉做的FSD推理芯片相对这就是小儿科了,但是就是这么个推理芯片也是难道国内的一大片厂商,核心就是其NPU和存算一体架构。
之前的文章讲了特斯拉的AI训练芯片DOJO:AI系统-13特斯拉AI芯片DOJO,那之前特斯拉做的FSD推理芯片相对这就是小儿科了,但是就是这么个推理芯片也是难道国内的一大片厂商,核心就是其NPU和存算一体架构。
包括我们之前介绍的TPU,这里其实有一个规律,一般大的科技公司有AI需求,不管是互联网、汽车、机器人等,有钱的时候都会涉及到芯片领域,一般第一款芯片就是从推理芯片做起,比较简单,然后就开始做后端的推理、集群。
AI芯片遍地开花后可能英伟达GPU首先失去的的就是这些大客户,然后就是那些小客户也可能直接用云服务区了,会进一步压缩,这也是一个趋势。
1. FSD发展
-
2013 年,马斯克于推特披露特斯拉正在进行辅助驾驶系统 AP(Autopilot System)的研发, 特斯拉自动驾驶之路开启;
-
2014 年 10 月,特斯拉基于与 Mobileye 的深度合作,推出首款自动驾驶软硬件系统 HW1.0 与 AP1.0;
-
2015 年 4 月, 特斯拉组建软件算法小组 Vision,算法开发由第三方供应转向自研;
-
2016 年 7 月,特斯拉宣布结束与 Mobileye 的合作;
-
2016 年 10 月,特斯拉自动驾驶软硬件系统 HW 2.0 与 AP2.0 发布,计算平台基于英伟达 Drive PX 2;
-
2017 年 8 月,特斯拉将 HW 2.0 更新升级为 HW 2.5,底层算力与冗余能力均有提升。
-
2019年3月,特斯拉推出基于自研芯片FSD 的 HW 3.0, 其为特斯拉发布的首个支持完全自动驾驶 FSD(Full Self-Driving)功能的硬件系统;
-
2020 年 10 月,特斯拉向小批量早期测试者推送 FSD Beta V6.0 版本,FSD 功能首上车;
-
2022 年 11 月,FSD 功能全面向北美用户开放。目前特斯拉在研的最新自动驾驶硬件系统已迭代至 HW 4.0,搭载 FSD 二代芯片。
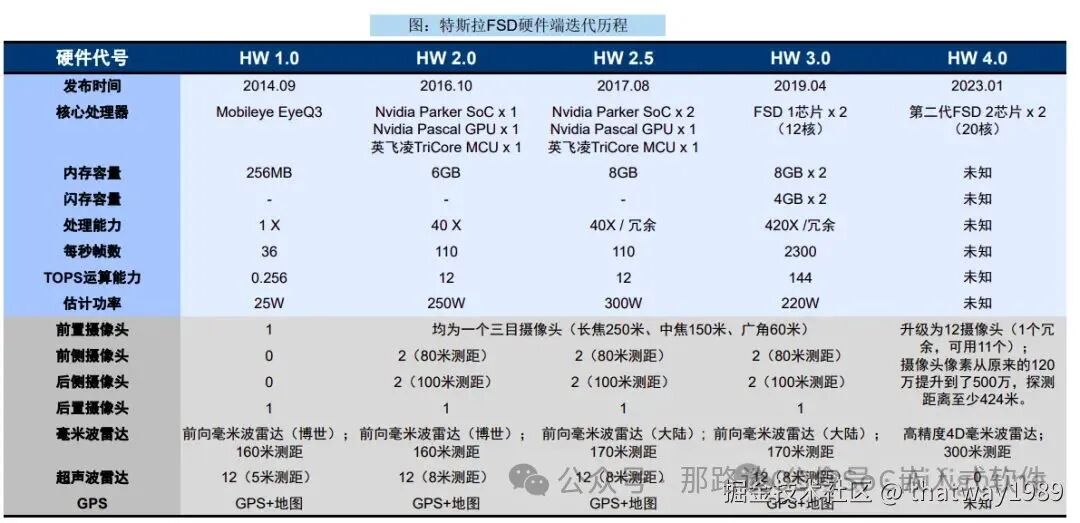
特斯拉 HW1.0 基于与 Mobileye 的深 度合作,其中底层芯片与视觉算法技术均来自于 Mobileye,特斯拉仅负责多传感器融合与应用层软件开发。2014 年-2016 年期间,HW1.0 先后 列装于 Model S 与 Model X 车型。
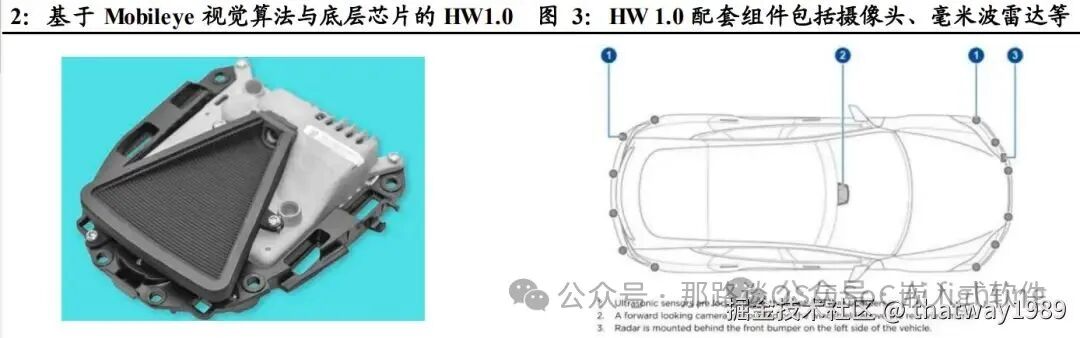
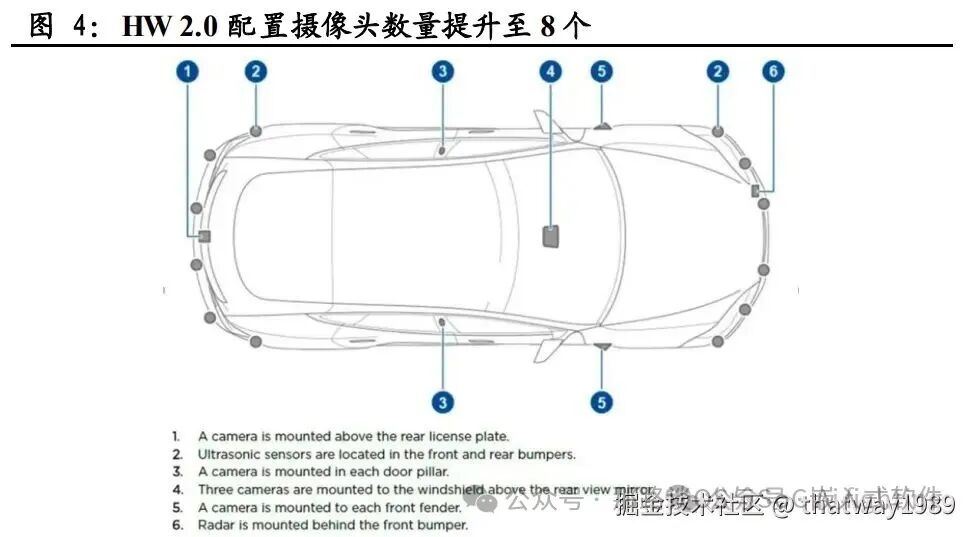
特斯拉第二代自动驾驶硬件系统 HW2.0 基于定制的英伟达 Drive PX 2 计算平台,算力约为 HW1.0 的 40 倍,达到 12TOPS。配套组件方面,HW2.0 搭载 8 个可实现 360 度环视视角的 120 万像素摄像头,包括 1 个前视三目摄像头,2 个后视侧面摄像头,2 个前视侧面摄像头,1 个后视摄像头,供应商为 Aptina。此外,HW2.0 与 HW1.0 一样,同样配置了 1 个博世 77G Hz 毫米波雷达与 12 个超声波传感器(由中程升级为远程)。HW2.0 由特斯拉与英伟达共同开发,其中英伟达提供计算平台与开发工具,特斯拉负责图像识别算法、多传感器融合与应用层软件开发等工作。2016 年 10 月起,特斯拉售出的所有汽车均有配置 HW2.0。

特斯拉 HW3.0 又称 FSD Computer,其抛弃了 HW2.5 的英伟达/英飞凌(SOC+MCU)底层芯片组合,转为装载自研 FSD 芯片。与 HW2.5 相比,HW3.0 在性能和成本上都有较大提升,可支持 FSD 功能。根据特斯拉数据,FSD 算力达到 144TOPS,每秒可处理图片2300 张,而 HW 2.5 每秒处理能力仅为 110 张,性能提升21倍;FSD 的成本相对于 HW 2.5 下降了 20%。配套组件方面,HW3.0 与 HW2.5 完全一致,仍采用 8 个可环视摄像头+1 个大陆毫米波雷达+12 个超声波传感器方案。结构布局方面,HW3.0 将驾驶辅助硬件和娱乐系统硬件集成在同一控制器中,但电路设计未实现高度集成,两项功能分别基于独立的电路板。在 HW3.0 研发过程中,特斯拉负责了全套芯片设计、图像识别算法、多传感器融合与应用层软件开发等多项工作,自研比例再次提升。

FSD 芯片采用三星 14nm FinFET CMOS 工艺,在 260mm2 的硅片上集成了约 60 亿个晶体管,组成 2.5 亿个逻辑门电路,芯片封装 尺寸 37.5×37.5mm,底座采用 FCBGA 设计,整体设计符合 AEC-Q100 汽车质量标准。FSD 芯片主要由 CPU、GPU 和 NNA(神经网络加速单 元)三个计算模块,以及各种接口,片上网络等组成,其中 CPU 由三组四核 ARM Cortex-A72 架构组成,主频 2.2GHz,主要用于通用的计算和任务,GPU 支持 16/32 位浮点运算,算力为 600GFlops,主要用于轻量级的后处理任务,NNA 包括 2 个 NPU(神经网络处理器),每个 NPU 都封装了 32MB 的 SRAM。HW3.0 中搭载了两颗 FSD 芯片,在行驶过程中,两颗芯片将分别对传感器收集到的数据进行独立处理,并进行结果平衡、仲裁和验证,自动驾驶功能的可靠性得到提升。
HW4.0
配置将有较大升级。根据外媒拆解报告,HW4.0 采用 FSD 二代芯片,预计算力高于 300TOPS,内部 CPU 的内核从 12 个增加到 20 个,最大频率为 2.35GHz,低功耗频率为 1.37GHz;TRIP 内核数量从 2 个增加到 3 个,最大频率 2.2GHz。配套组件方面,HW4.0 的 主板摄像头接口为 12 个,其中 1 个为备用,即车载摄像头或由原先的 8 个提升至 11 个,前置摄像头像素也有望提升至 500 万。此外,HW4.0 主板增加了 4D 毫米波雷达接口(代号 Phoenix),但未配置超声波雷达。


2. FSD芯片架构
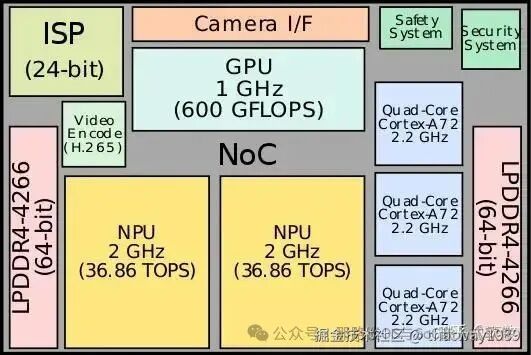
从芯片框图里面可以看到其由:
-
两个NPU
-
ISP图像处理
-
GPU
-
Camera接口
-
3个A72核心簇,一个簇4个核,共有12核
-
VPU核心处理视频编解码
-
FSI功能安全岛
-
信息安全岛处理加解密
-
NoC片内通信
-
LPDDR高速内存
由这10个子系统组成,当然每个子系统都有自己附属的IP,以及一些SRAM。
Camera的图片一般通过MIPI接口把数据给到ISP进行处理(消除噪音等),这时候数据还在DDR中,然后根据CPU的调度把数据放入SRAM里面,这时SRAM里面是存算一体的数据,NPU去拿到数据后进行计算,计算过程中NPU内核心的并行协同需要NoC总线,最后回结果吐到SRAM里面。GPU是为NPU不支持的算子兜底的,最新的架构里面GPU已经被删除了。
对应芯片的位置如下:

2.1 CPU子系统
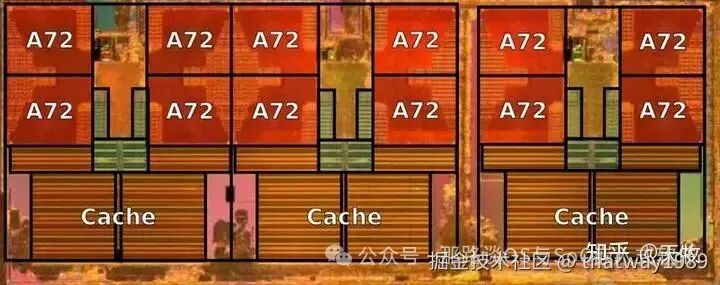
1:拥有12 Cortex-A72 cores
2:频率:2.2 GHz
3:面积为约为~40.2 mm² die size(~1.19 mm² core)
在ARM架构的CPU子系统中,组件设计旨在高效地整合了多种功能模块,以支持处理器核心的运行、内存管理、中断处理、数据交换以及与外部设备的交互等。以下是ARM CPU子系统中的一些关键组件:
-
CPU Cores (处理器核心): 包括多个处理单元,如高性能的Cortex-A系列核心或高效能效核心,负责执行指令。
-
GIC (Generic Interrupt Controller): 管理中断请求,确保系统对事件做出快速响应,支持多级中断处理和虚拟化。
-
DSU (DynamIQ Shared Unit): 在具备DynamIQ技术的SoC中,DSU管理共享资源,如L3缓存,优化多核通信和数据一致性。
-
Cache System: 包括L1 Cache(靠近核心的高速缓存,分指令和数据缓存),L2 Cache(更大,有时是多核共享)。
-
Memory Controller: 控制内存访问,如DDR控制器,管理与主存交互。
-
AMBA总线: 如AMBA总线架构,提供系统内部组件间的通信,包括常见的AXI(Advanced eXtensible Interface)协议。
-
System Control Block: 负理系统复位、时钟、电源管理等初始化配置。
-
Security Features: 如TrustZone、加密引擎,确保系统安全。
-
Debugging and Trace: CoreSight、JTAGC等,方便调试和性能分析。
-
Connectivity and Peripherals: 包括USB、Ethernet控制器、显示接口、I2C、SPI等,以支持与外设别交互。
2.2 NPU子系统
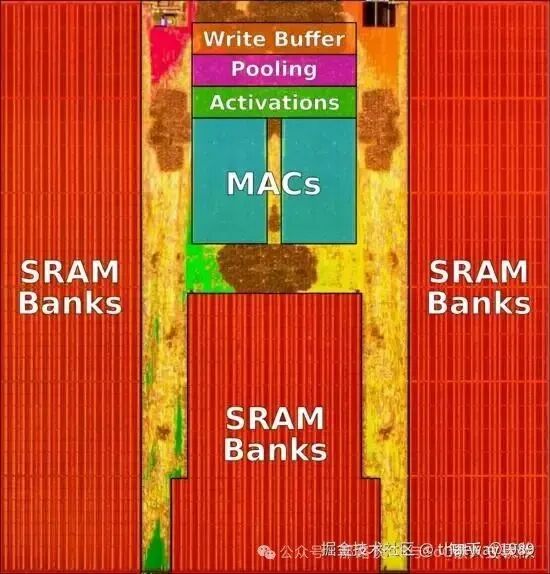
可以看到周围都是SRAM,除了核心的寄存器外,SRAM是速度最快的存储了,直接给大量配上了。
尽管芯片上的大多数逻辑都使用经过行业验证的IP块来降低风险并加快开发周期,但Tesla FSD芯片上的神经网络加速器(NPU)是由Tesla硬件团队完全定制设计的。它们也是FSD芯片上最大的组件,也是最重要的逻辑部分。
为什么是两个NPU,不是一个更大的NPU?特斯拉指出,每个NPU的大小都是物理设计(时序,面积,布线)的最佳选择。
3. NPU分析
下面将详细介绍下这个NPU,也就是NNA(NEURAL NETWORK ACCELERATOR)。
NNA整体架构
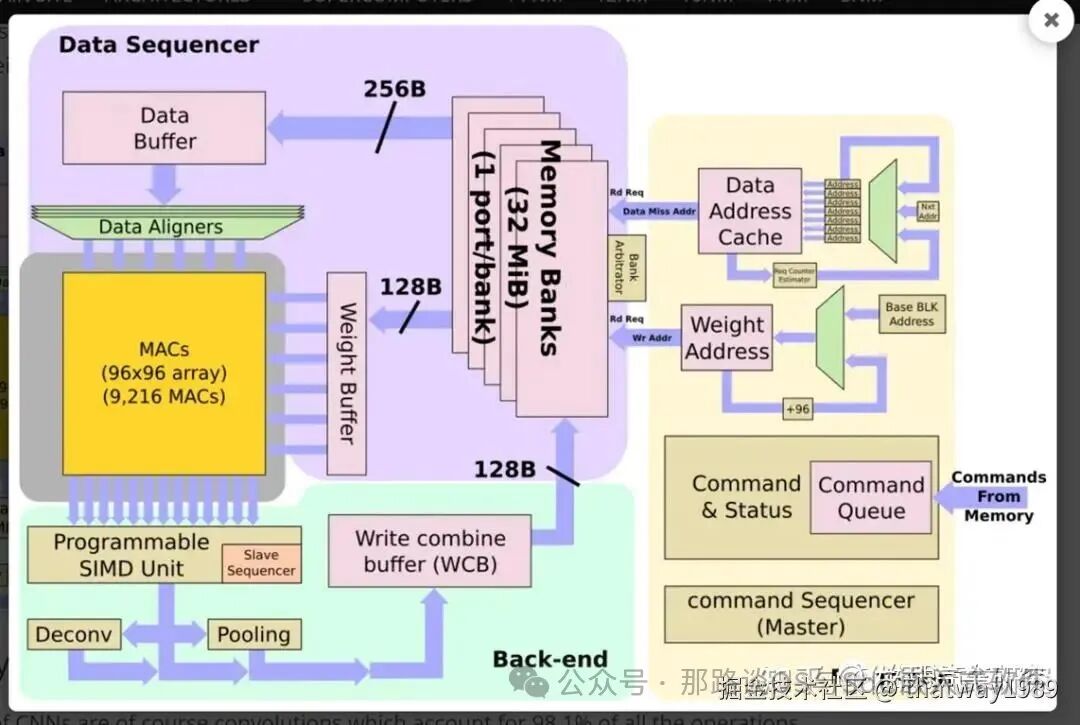
每个NNA有32mb SRAM和96 \96 MAC阵列。在2 GHz下,每个NNA提供36个TOPs,总共为FSD芯片增加了72个TOPs。
-
MAC(矩阵乘加运算)相乘的两个矩阵就是Data x Weight
-
SIMD:单指令多数据运算
-
Decone和Pooling:卷积和池化运算
-
WCB写回SRAM
-
Command队列和序列控制器
MAC阵列
CNN的主要操作当然是卷积,占特斯拉软件在NPU上执行的所有操作的98.1%,而反卷积又占1.6%。在优化MAC上花费了大量的精力。
MAC阵列中的数据重用很重要,否则,即使每秒1 TB的带宽也无法满足要求。在某些设计中,为了提高性能,可以一次处理多个图像。但是,由于出于安全原因,延迟是其设计的关键属性,因此它们必须尽快处理单个图像。特斯拉在这里做了许多其他优化。NPU通过合并输出通道中X和Y维度上的输出像素,在多个输出通道上并行运行。这样一来,他们可以并行处理工作,并同时处理96个像素。换句话说,当它们作用于通道中的所有像素时,所有输入权重将被共享。此外,它们还交换输出通道和输入通道循环(请参见下图的代码段)。这使它们能够依次处理所有输出通道,共享所有输入激活,而无需进一步的数据移动。这是带宽需求的另一个很好的降低。
实现数据共享的技术就是NoC通信,NoC将所有的PE运算节点分配的SRAM都链接起来,这样某个PE的运算需要的输入就直接去读,避免了数据拷贝移动。
通过上述优化,可以简化MAC阵列操作。每个阵列包括9,216个MAC,并排列在96 x 96的独立单周期MAC反馈环路的单元中(请注意,这不是脉动阵列,单元间没有数据移位)。为了简化其设计并降低功耗,它们的MAC由8x8位整数乘法和32位整数加法组成。特斯拉自己的模型在发送给客户时都经过了预先量化,因此芯片只将所有数据和权重存储为8位整数。
在每个周期中,将在整个MAC阵列中广播输入数据的底行和权重的最右列。每个单元独立执行适当的乘法累加运算。在下一个循环中,将输入数据向下推一行,而将权重网格向右推一行。在整个数组中广播输入数据的最底行和权重的最右列,重复此过程。单元继续独立执行其操作。全点积卷积结束时,MAC阵列一次向下移动一行96个元素,这也是SIMD单元的吞吐量。
NPU本身实际上可以在2 GHz以上的频率上运行,尽管特斯拉根据2 GHz时钟引用了所有数字,所以大概是生产时钟。在2 GHz的频率下,每个NPU可获得36.86 teraOPS(Int8)的最高计算性能。NPU的总功耗为7.5 W,约占FSD功耗预算的21%。这使它们的性能功率效率约为4.9 TOPs / W,这是我们迄今为止在出货芯片中看到的最高功率效率之一–与英特尔最近宣布的NNP-I(Spring Hill)推理加速器配合使用。尽管特斯拉NPU在实际中的通用性有点疑问。请注意,每个芯片上有两个NPU,它们消耗的总功率预算略超过40%。
SIMD单元
从MAC阵列,将一行压入SIMD单元。SIMD单元是可编程执行单元,旨在为Tesla提供一些额外的灵活性。为此,SIMD单元为诸如sigmoid, tanh, argmax和其他各种功能提供支持。它带有自己丰富的指令集,这些指令由从机指令定序器执行。从指令定序器从前面描述的指令的扩展槽中获取操作。特斯拉表示,它支持在普通CPU中可以找到的大多数典型指令。除此之外,SIMD单元还配备了可执行归一化,缩放和饱和的点状量化单元。
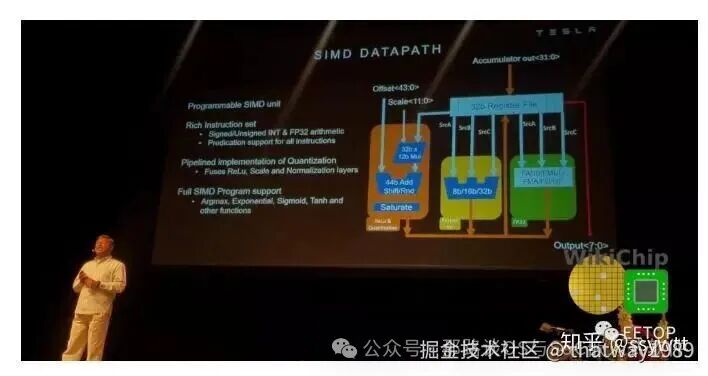
将结果从SIMD单元转发到合并单元,或直接转发到写组合,在其中以128B /周期的速度将其有机会写回到SRAM。该单元进行2×2和3×3合并,在conv单元中进行更高阶的处理。它可以进行max pooling 和 average pooling。对于average pooling,使用基于2×2/3×3的常量的定点乘法单元替换除法。由于特斯拉最初对MAC阵列的输出通道进行了交错处理,因此它们会首先进行适当的重新对齐以进行校正。
详细的优化算法信息参考论文《Compute Solution for Tesla’s Full Self-Driving Computer》,可以在sci-hub里面免费下载。下面内容来自此论文。
NNA神经网络加速器上运行的算法:

自定义NNA用于以极高的帧速率和适中的功率预算检测一组预定义的对象,包括但不限于车道线、行人、不同类型的车辆,如平台目标中所述。
图3显示了一个典型的初始卷积神经网络。1,2该网络有许多层,连接指示计算数据流或激活。通过这个网络的每一次传递都涉及到一个图像的进入,以及各种各样的特征或激活,然后被构建每一层都按顺序。在最终层之后检测到一个对象。
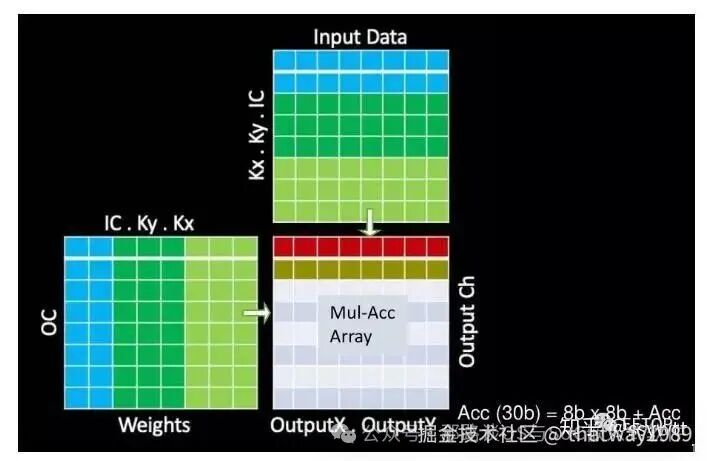
如图3所示,超过98%的运算属于卷积。卷积算法由一个七层嵌套循环组成,如图3所示。最内层循环中的计算是乘法累加(MAC)操作。因此,我们设计的主要目标是尽可能快地执行大量MAC运算,而不增加功耗预算。
按数量级加速卷积将导致不太频繁的操作,如量化或池化,如果它们的性能大大降低,将成为整体性能的瓶颈。这些操作还通过专用硬件进行了优化,以提高整体性能。
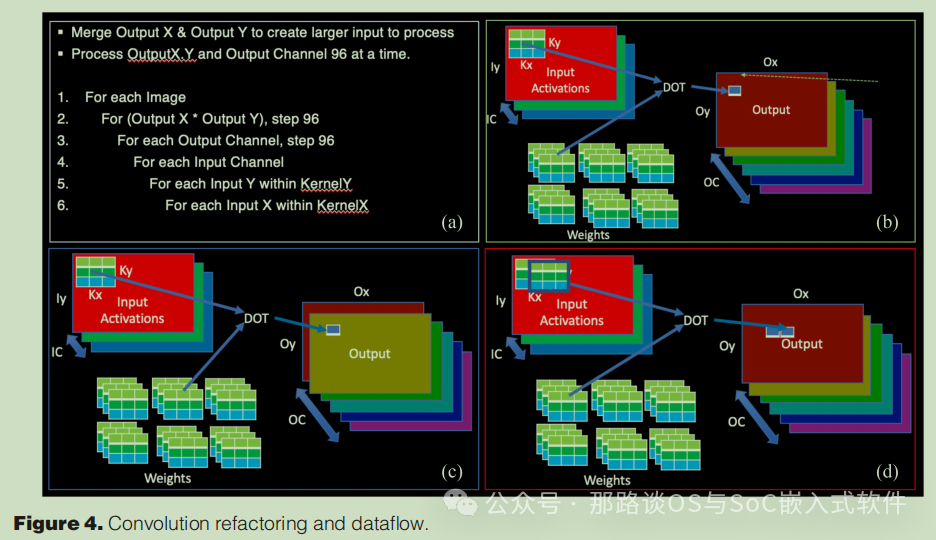
图4(a)显示了经过一些重构的卷积循环。进一步的研究表明,这是一个令人尴尬的并行问题,有很多机会并行处理MAC操作。在卷积循环中,决定每个点积长度的三个最内层循环内的MAC运算的执行在很大程度上是连续的。然而,三个外环内的计算,即对于每个图像、每个输出通道、每个输出通道内的所有像素的计算,是可并行化的。但这仍然是一个难题,因为支持如此大规模的并行计算需要很大的内存带宽和显著增加的功耗。
我们将跨多个输出通道和每个输出通道内的多个输出像素并行化计算。
图4(a)显示重构的卷积环路,优化数据重用以降低功耗并提高实现的计算带宽。我们将每个输出通道的两个维度合并,并以行为主的形式将其简化为一个维度,如图4(a)的步骤(2)所示。这提供了许多并行处理的输出像素,而不会丢失所需输入数据的局部连续性。
我们还将用于迭代输出通道的循环与用于迭代每个输出通道内的像素的循环互换,如图4(a)的步骤(2)和(3)所示。对于固定的一组输出像素,我们首先迭代输出通道的子集,然后再移动到下一组输出像素进行下一步。在输出通道的子集内组合一组输出像素的一个这样的过程可以作为并行计算来执行。我们继续这一过程,直到耗尽第一个输出通道子集内的所有像素。一旦所有像素耗尽,我们移动到输出通道的下一个子集并重复该过程。这使我们能够最大限度地共享数据,因为对所有输出通道内的同一组像素的计算使用相同的输入数据。
图4(b)–(d)还显示了卷积层的上述重构的数据流。通过共享输入激活来计算连续输出通道的相同输出像素,并且通过共享输入权重来计算相同输出通道内的连续输出像素。这种用于点积计算的数据和权重共享有助于利用大的计算带宽,同时通过最小化移动数据的负载数量来降低功耗。
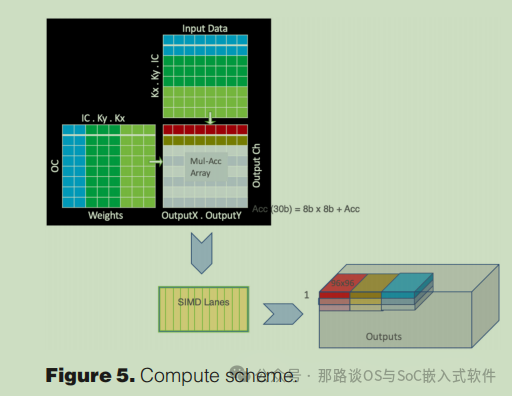
上一节描述的重构卷积算法适用于数据流如图5所示的计算方案。为了空间的简洁,中间示出了物理96¢96 MAC阵列的缩小版本,其中每个单元由利用单周期反馈环路实现MAC操作的单元组成。顶部和左侧的矩形网格是虚拟的,表示数据流。顶部的网格,这里称为数据网格,显示了每行96个数据元素的缩小版本,而左侧的网格,这里称为权重网格,显示了每列96个权重的缩小版本。的高度和宽度数据和权重网格等于点积的长度。
计算过程如下:数据网格的第一行和权重网格的第一列分别在MAC阵列的所有96行和96列中以流水线方式在几个周期内传播。每个小区利用广播数据和本地权重来计算MAC运算。在下一个周期中,以流水线方式广播数据网格的第二行和权重网格的第二列,并且类似地执行每个单元中的MAC计算。这个计算过程一直持续到数据和权重网格的所有行和列都被广播,并且所有MAC操作都已完成。因此,每个MAC单元在本地计算点积,MAC阵列内没有数据移动,这与许多其它处理器中实现的脉动阵列计算不同。3,4这导致比脉动阵列实现更低的功率和更小的单元面积。
当所有的MAC操作完成时,累加器值准备好被下推到SIMD单元进行后处理。这就产生了第一个96?96输出限幅,如图5所示。通常涉及量化操作的后处理是在96-宽度SIMD单元中进行的。96宽SIMD单元的带宽与每个输出通道的96元素累加器输出相匹配。MAC阵列中的累加器行以每个周期一行的速率向下移位到SIMD单元。物理上,累加器行每八个周期仅移位一次八人小组。这降低了显著移动累加器数据的功耗。
MAC引擎的另一个重要特征是MAC和SIMD操作的重叠。当累加器值被下推到SIMD单元进行后处理时,卷积的下一步在MAC阵列中立即开始。这种重叠计算增加了计算带宽的整体利用率,避免了死循环。
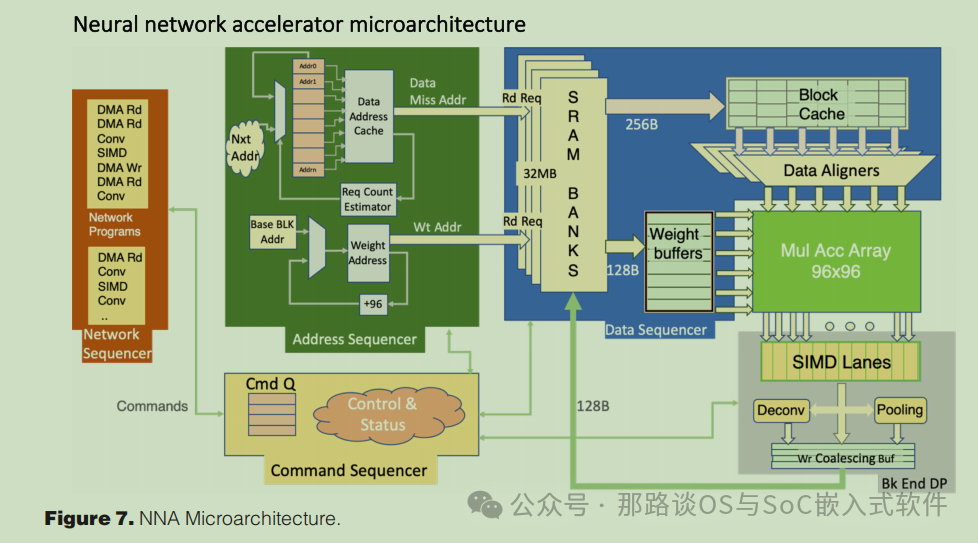
如图7所示,NNA是围绕两条主要的数据路径(点积引擎和SIMD单元)和状态机组织的,状态机解释程序,生成内存请求流,并控制数据进出数据路径。
点积引擎
如“计算方案”一节所述,点积引擎是一个96 \96的MAC单元阵列。每个单元接受两个8位整数输入(有符号或无符号)并将它们相乘,将结果添加到30位宽的本地累加器寄存器中。有许多处理器使用单精度或半精度浮点(FP)数据和权重来部署浮点运算进行推理。我们的整数MAC计算具有足够的范围和精度,能够以所需的精度执行所有Tesla工作负载,并且功耗比采用FP算法的低一个数量级。9
在每个周期中,阵列接收两个向量,每个向量有96个元素,并将第一个向量的每个元素与第二个向量的每个元素相乘。结果就地累积,直到点积序列结束,然后卸载到SIMD引擎进行进一步处理。
每个累加器单元围绕两个30位寄存器构建:一个累加器和一个移位寄存器。计算序列完成后,点积结果被复制到移位寄存器中,累加器清零。这允许结果通过SIMD引擎移出,而下一个计算阶段在点积引擎中开始。
SIMD单位
SIMD单元是一个96宽的数据路径,可以执行一整套算术指令。它一次从点积引擎(一个累加器行)读取96个值,并作为一系列指令执行后处理操作(SIMD程序)。SIMD程序不能直接访问SRAM,并且不支持流控制指令(分支)。对从MAC数组中卸载的每组96个值执行相同的程序。
SIMD单元可通过丰富的指令集进行编程,包括各种数据类型、8位、16位和32位整数以及单精度浮点(FP32)。指令集还为控制流提供了条件执行。输入数据始终为30位宽(转换为int32),最终输出始终为8位宽(有符号或无符号int8),但中间数据格式可能与输入或输出不同。
由于大多数常见的SIMD程序可以用一条指令来表示,称为Fuse- dReLu(融合量化,缩放,ReLu),指令格式允许融合任何算术运算与移位和输出操作。FusedReLu指令完全流水线化,允许在96个周期内卸载整个96 \u 96点积引擎。更复杂的后处理序列需要额外的指令,增加了点积引擎的卸载时间。一些复杂的序列是由FP32指令和条件执行构建的。在这种SIMD程序开始时,30位累加器值被转换成FP32操作数,在SIMD程序结束时,FP32结果被转换回8位整数输出。
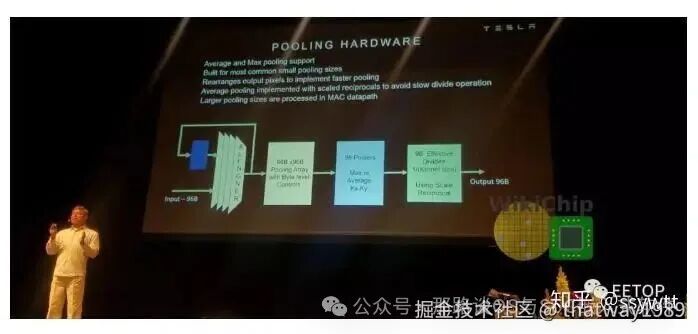
共享支持
在SIMD单元中进行后处理之后,输出数据也可以有条件地通过汇集单元进行路由。这允许最频繁的小内核池操作(2¢2和3¢3)在SIMD执行的阴影下执行,与产生数据的早期层并行。汇集硬件实现了对齐器,以将被后置以优化卷积的输出像素对齐回原始格式。池单元有三个96字节的池数组,具有字节级控制。频率较低的大型内核池操作在点积引擎中作为卷积层执行。
存储器组织
NNA使用32mb本地SRAM来存储权重和激活。为了同时实现高带宽和高密度,SRAM使用许多相对较慢的单端口存储体来实现。每个周期可以访问多个这样的存储体,但是为了保持高单元密度,不能在连续的周期中访问一个存储体。
在每个周期,SRAM可以通过两个独立的读取端口(256字节和128字节宽)提供高达384字节的数据。仲裁器对来自多个来源(权重、激活、程序指令、DMA输出等)的请求进行优先级排序。)并通过两个端口订购它们。来自媒体资源的请求无法处理重新排序,但是可以对来自不同来源的请求进行优先排序,以最大限度地减少银行冲突。
在推理过程中,权重张量始终是静态的,可以在SRAM中布局,以确保有效的读取模式。对于激活,这并不总是可能的,因此加速器将最近读取的数据存储在1kb的缓存中。这有助于通过消除对相同数据的连续读取来最大限度地减少SRAM存储体的冲突。为了进一步减少银行冲突,加速器可以使用网络程序提示的不同模式填充输入和/或输出数据。
控制逻辑
如图7所示,控制逻辑分为几个不同的状态机:命令序列器、网络序列器、地址和数据序列器以及SIMD单元。
每个NNA可以将多个网络程序排队并按顺序执行。命令定序器维护这种程序的队列及其相应的状态寄存器。一旦网络运行完成,加速器就会触发主机系统的中断。在其中一个CPU上运行的软件可以检查完成状态,并重新启用网络来处理新的输入帧。
网络定序器解释程序指令。如前所述,指令是长数据包,它编码了足够的信息来初始化执行状态机。网络定序器对该信息进行解码,并将其引导至适当的消费者,加强依赖性并同步机器,以避免生产者层和消费者层之间潜在的竞争情况。
一旦计算指令被解码并被引导至其执行状态机,地址序列发生器就产生SRAM地址流和用于下游计算的命令。它将输出空间划分为多达96¢96个元素的部分,并且对于每个这样的部分,它对相应点积的所有项进行排序。
权重包在SRAM中预先排序以匹配执行,因此状态机简单地以96个连续字节为一组对其进行流式处理。然而,激活并不总是来自连续的地址,它们经常必须来自连续的地址
从多达96个不同的SRAM位置收集。在这种情况下,地址序列器必须为每个包产生多个加载地址。为了简化实现并允许高时钟频率,96个元素的分组被分成12个片段,每个片段8个元素。每个片由单个加载操作提供服务,因此其第一个和最后一个元素之间的最大距离必须小于256字节。因此,可以通过发出1到12个独立的加载操作来形成96个激活的包。
加载数据与控制信息一起被转发到数据序列发生器。权重在预取缓冲器中被捕获,并在需要时发布给执行。激活存储在数据缓存中,从那里收集96个元素并发送到MAC阵列。到数据通路的命令也是从数据定序器来的,控制执行使能、累加器移位、SIMD程序开始、存储地址等。
SIMD处理器对从MAC阵列中卸载的每组96个累加器结果执行相同的程序。它由地址序列发生器中产生的控制信息同步,它可以解码、发布和执行SIMD算术指令流。虽然SIMD单元有自己的寄存器文件,并控制数据路径中的数据移动,但它不控制存储结果的目的地址。当地址序列器选择要处理的96-96输出片时,它产生存储地址和任何池控制。
架构决策和结果
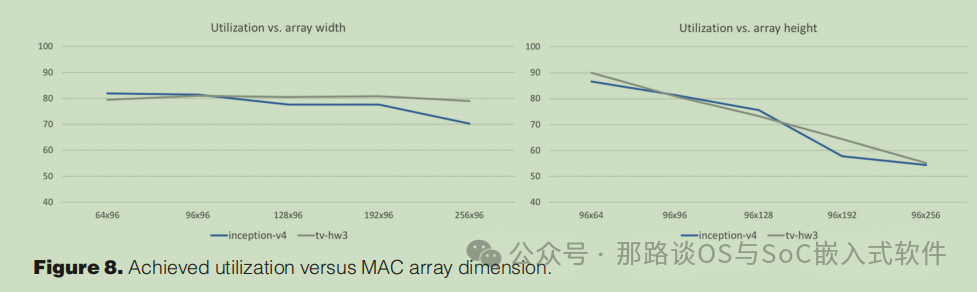
当实现像我们的MACarrayandSIMDprocessor这样非常宽的机器时主要问题总是与其工作时钟频率有关。高时钟频率更容易实现目标性能,但通常需要一些逻辑简化,这反过来会影响特定算法的利用。
我们决定为具有大量输入和输出通道的深度卷积神经网络优化这种设计。SRAM每个周期提供给MAC阵列的192字节的数据和权重只能被跨距为1或2的层充分利用,跨距较大的层往往利用率较低。
根据MAC阵列的大小和形状,加速器的利用率可能会有很大差异,如图8所示。inception-v4和Tesla Vision网络都显示出对MAC阵列高度的显著敏感性。虽然同时处理更多的输出通道会损害整体利用率,但这种能力相对便宜,因为它们都共享相同的输入数据。增加阵列的宽度不会对利用率造成太大影响,但它需要大量的硬件资源。在我们选择的设计点(96¢96 MAC阵列),这些网络的平均利用率刚刚超过80%。
我们必须评估的另一个权衡是SRAM的大小。神经网络的规模越来越大,因此添加尽可能多的SRAM可能是一种面向未来的设计方法。然而,大得多的SRAM会增加流水线深度和芯片总面积,从而增加功耗和系统总成本。另一方面,太大而不适合SRAM的卷积层总是可以分解成多个更小的组件,这可能会因向溢出和填充数据而付出一些代价RAM。基于我们当前网络的需求和我们的中期扩展预测,我们为每个加速器选择了32 MB的SRAM。
4. ISA指令集
NPU是具有乱序内存子系统的有序计算机。总体设计有点像是一种状态机。指令集比较简单,只有8条指令:DMA Read,DMA Write,Convolution,Deconvolution,Inner-product,Scale,Eltwidth,Stop。NPU只是运行这些命令,直到碰到停止命令为止。还有一个额外的参数slots ,可以更改指令的属性(例如,卷积运算的不同变体)。有一个标志slots ,用于数据依赖性处理。还有另一个扩展slots 。该slots 存储了整个微程序命令序列,每当有一些复杂的后处理时,这些序列就会发送到SIMD单元。因为这,指令从32字节一直到非常长的256字节不等。稍后将更详细地讨论SIMD单元。

5. 存算一体
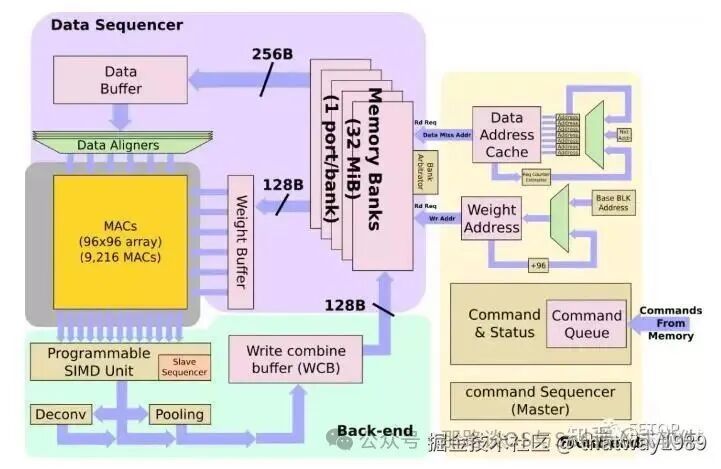
NPU的程序最初驻留在内存中,跟数据在一块。它们被带入NPU,并存储在命令队列中。NPU本身是一个非常花哨的状态机,旨在显着减少控制开销。来自命令队列的命令连同需要从中获取数据的一组地址一起解码为原始操作-包括权重和数据。例如,如果传感器是新拍摄的图像传感器照片,则输入缓冲区地址将指向该位置。一切都存储在NPU内部的超大缓存中,不需要与DRAM交换数据。
高速缓存的容量为32 MB,有一个完善的bank仲裁程序,与一些编译器提示一起,用于减少bank冲突。每个周期中,最多可以将256个字节的数据读取到数据缓冲区中,并且最多可以将128个字节的权重读取到权重缓冲区中。根据步幅,NPU可能在操作开始之前将多条线路带入数据缓冲区,以实现更好的数据重用。每个NPU的组合读取带宽为384B/周期,其本地缓存的峰值读取带宽为786GB/s。特斯拉表示,这使他们能够非常接近维持其MAC所需的理论峰值带宽,通常利用率至少为80%,而很多时候则要达到更高的利用率。
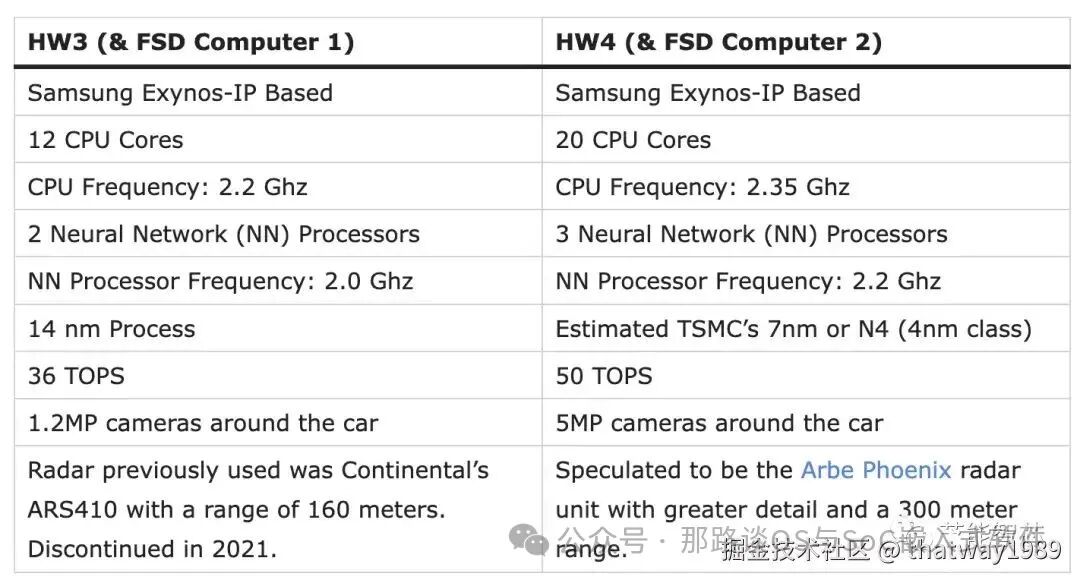
6. HW4 的芯片进化
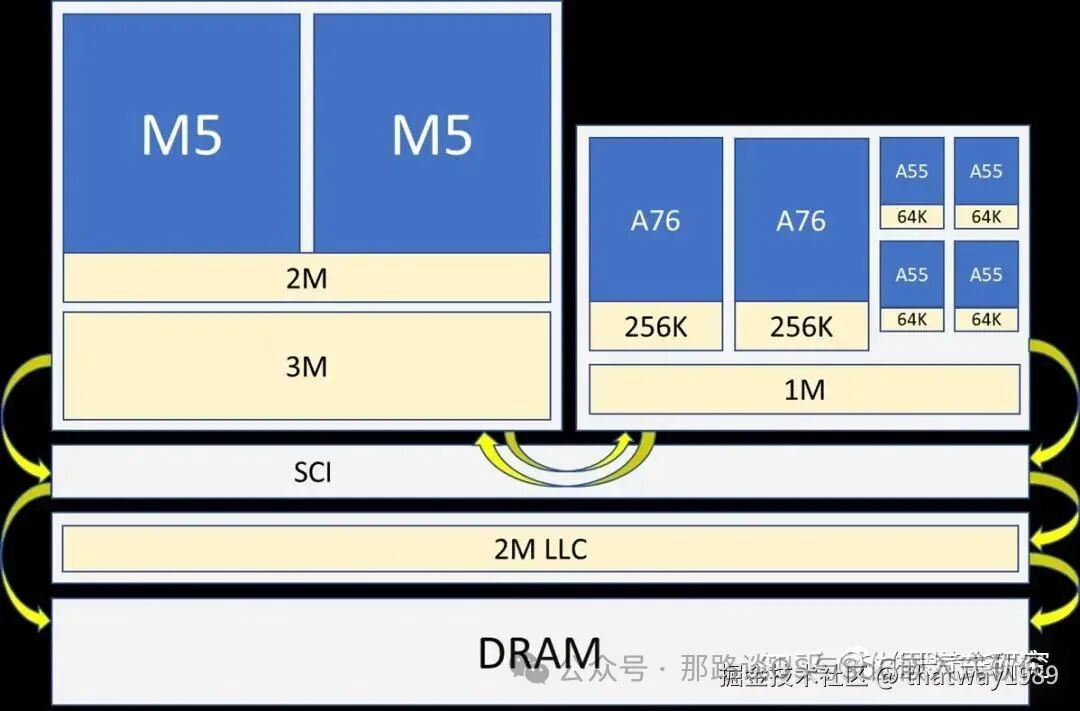
HW4 的 SOC 芯片在 HW3 上进行迭代:
计算核心 (CPU) :三星 Exynos IP,CPU 频率 2.35GHz、 5 个 CPU 集群 (20 个 CPU 核心)
NN 的 AI 加速器 :3 个神经网络 (NN) 处理器、NN 处理器频率 2.2 Ghz,估 50 TOPS 的算力;
应该基本框架已经定了,后续就是堆核和工艺,以及软件编译器等的优化,还有硬件新算子的支持等。
还有就是作为汽车上使用的产品,FSD只是智能驾驶域,车控和座舱的软硬件也会集成进去,大一统也是一个趋势,就需要更多的异构核心和Hypersior的支持。这里其实定制SoC里面的异构核,RISC-V就有优势了,因为其开源,目前像Inter、英飞凌等不会卖IP,甚至都不公开IP,只卖成品芯片捞钱,做SoC想集成那只能拿开源不要钱的RISC-V来搞了,这就是开源的魅力。
参考:
1. https://zhuanlan.zhihu.com/p/1889707818090725982
2. https://zhuanlan.zhihu.com/p/83701837
3. https://zhuanlan.zhihu.com/p/644458995
4. https://zhuanlan.zhihu.com/p/715815282
“啥都懂一点,啥都不精通,
干啥都能干,干啥啥不是,
专业入门劝退,堪称程序员杂家”。
欢迎各位有自己公众号的留言:申请转载!
纯干货持续更新,欢迎分享给朋友、点赞、收藏、在看、划线和评论交流!
公众号:“那路谈OS与SoC嵌入式软件”,欢迎关注!
个人文章汇总:https://thatway1989.github.io

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)