从流程到落地:手把手解析一个完整的BERT文本分类项目
你是否曾经拿到一个开源项目却不知从何入手?本文将带你从流程视角,拆解一个基于BERT的中文文本分类项目的完整架构,涵盖数据准备、模型定义、训练、预测到服务化的全流程。
一、项目背景
在NLP领域,文本分类是最基础也最广泛的任务之一。借助预训练模型(如BERT)和迁移学习,我们可以在少量标注数据上快速构建高精度分类器。本文将解析一个典型的BERT文本分类项目,其目录结构清晰,将模型、训练、预测、API服务分离,非常适合作为学习范本。
二、项目目录结构
text
04-bert/
├── bert-base-chinese/ # 本地预训练模型
├── save_models/
│ └── bertclassifier_model_20251017/
│ └── bertclassifier_model.pt # 训练好的模型权重
└── src/
├── api.py # API服务接口
├── api_test.py # API测试脚本
├── app.py # 服务启动入口
├── bert_classifier_model.py # 模型定义
├── config.py # 配置文件
├── predict_fun.py # 预测函数封装
├── train.py # 训练脚本
├── utils.py # 工具函数(数据加载等)
└── utils_old.py # 旧版工具(备份)
三、核心流程解析
整个项目遵循“数据准备 → 模型定义 → 训练 → 预测 → 服务化”的经典流程,各文件职责明确,环环相扣。
1. 数据准备阶段
主要文件:utils.py、config.py
-
config.py:集中管理所有超参数和路径,例如:python
class Config: model_name = "bert-base-chinese" hidden_size = 768 num_classes = 2 batch_size = 32 learning_rate = 2e-5 epochs = 3 train_data_path = "data/train.csv" save_dir = "save_models/" -
utils.py:负责数据加载与预处理-
读取CSV文件,提取文本和标签
-
使用
BertTokenizer将文本转换为input_ids、attention_mask -
构建
Dataset和DataLoader供训练使用
-
2. 模型定义阶段
主要文件:bert_classifier_model.py、config.py
python
class BertClassifier(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained(Config.model_name)
self.fc = nn.Linear(Config.hidden_size, Config.num_classes)
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(input_ids, attention_mask, return_dict=False)
logits = self.fc(pooled_output)
return logits
-
模型封装了预训练BERT和一个线性分类头
-
pooled_output是BERT对[CLS]的池化表示,适合作为句子特征
3. 训练阶段
主要文件:train.py、config.py、utils.py、bert_classifier_model.py
训练脚本的主要步骤:
python
# 加载配置、数据和模型
config = Config()
train_loader, valid_loader = load_data(config)
model = BertClassifier().to(device)
optimizer = AdamW(model.parameters(), lr=config.learning_rate)
criterion = nn.CrossEntropyLoss()
# 训练循环
for epoch in range(config.epochs):
for batch in train_loader:
input_ids, attention_mask, labels = batch
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 保存模型
torch.save(model.state_dict(), f"{config.save_dir}/bertclassifier_model.pt")
4. 预测阶段
主要文件:predict_fun.py、config.py、bert_classifier_model.py
将模型封装成独立的预测函数:
python
def predict(text):
# 加载模型(单例模式或全局变量)
model = load_model()
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
logits = model(**inputs)
pred = torch.argmax(logits, dim=-1).item()
return {"label": pred, "prob": torch.softmax(logits, dim=-1).tolist()}
5. 服务化阶段
主要文件:api.py、app.py、api_test.py
-
api.py:使用Flask定义REST接口python
@app.route('/predict', methods=['POST']) def predict_route(): data = request.get_json() text = data['text'] result = predict_fun.predict(text) return jsonify(result) -
app.py:启动服务入口python
from api import app if __name__ == '__main__': app.run(host='0.0.0.0', port=5000) -
api_test.py:发送测试请求python
import requests response = requests.post('http://localhost:5000/predict', json={'text': '这家餐厅很棒'}) print(response.json())
四、完整流程图
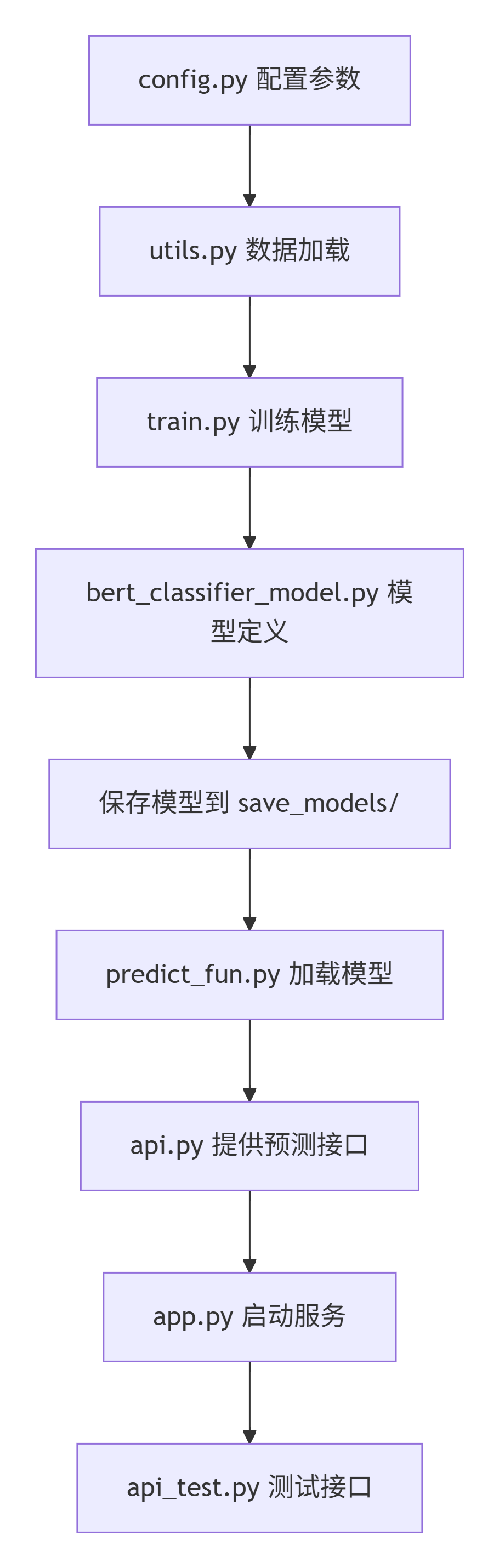
五、关键设计亮点
-
模块分离:配置、模型、训练、预测、服务各司其职,便于维护和扩展。
-
本地模型:
bert-base-chinese本地存放,避免每次从Hugging Face下载。 -
模型版本管理:以日期命名文件夹,方便回溯。
-
工程化意识:提供API服务,使模型可以快速集成到生产环境。
六、总结
通过这个项目,你可以完整学习到如何将BERT模型应用到文本分类任务,并封装成可服务化的API。无论你是初学者还是想规范工程实践的开发者,这套结构都值得参考。下一步,你可以尝试在config.py中修改超参数,或替换为其他预训练模型(如RoBERTa、ALBERT),观察效果变化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)