从零到1了解Agent Skills
一 概念讲解
| 概念 | 核心定位 | 关键特征 | 类比(以公司为例) | 技术层级 |
|---|---|---|---|---|
| LLM | 大脑(核心引擎) | 知识压缩、推理、生成 | 拥有广博知识的实习生 | 基础设施层 |
| Prompt | 沟通界面(指令) | 意图表达、上下文设定 | 给实习生写的任务清单 | 交互层 |
| Skills | 固化能力(API) | 确定性、工具化、可复用 | 实习生学会使用的办公软件 | 能力层 |
| Agent | 执行主体(数字员工) | 自主规划、决策、执行 | 能自己安排工作的项目经理 | 应用/执行层 |
| AGI | 终极目标(类人智能) | 通用性、自适应、意识 | 全能且可自主学习的超级员工 | 愿景层 |
1.1 LLM(大语言模型):AI系统的"大脑"
- 本质:参数量在百亿级以上的预训练语言模型,核心能力是下一个token预测
- 功能定位:提供基础的语言理解与生成能力,但仅限于文本层面,无法主动执行任务
- 典型代表:GPT-4o、Claude 3.5、Llama 4、Qwen 2.5等
- 关键局限:
- 知识截止到训练日期(存在"幻觉"风险)
- 无法主动调用外部工具
- 上下文窗口有限(即使200k-1M也可能遗忘)
🧠 形象比喻:LLM就像一位知识渊博但行动受限的学者,能回答各种问题,但无法亲自去图书馆查资料或操作实验设备。
1.2. Prompt(提示词):与LLM交互的"指令手册"
- 本质:给LLM的输入文本,是"指令+上下文+示例+约束"的组合
- 功能定位:引导LLM生成特定风格和内容的输出,决定LLM输出质量的80%(模型参数只占20%)
- 关键特点:
- 临时性:单次对话有效,"说完即焚"(除非放入长期记忆)
- 即时性:依赖当前上下文窗口
- 灵活性:可快速测试和调整
📝 典型示例:"你是一位资深Python工程师,请审查以下代码,指出问题并给出重构建议,输出格式用Markdown。"
💡 重要提示:Prompt不是简单的"咒语",而是结构化指令工程,包括零样本、少样本、思维链、角色扮演等多种技术。
1.3. Agent(智能体):具备自主能力的"执行者"
- 本质:能自主规划、调用工具、记忆、迭代完成复杂目标的LLM驱动系统
- 功能定位:将LLM的"大脑"与"手脚"结合,从"回答问题"升级为"完成任务"
- 核心组件:
- Planner:任务分解与路径规划
- Executor:调用工具执行操作
- Memory:短期(对话历史)+ 长期(向量数据库)记忆
- Observer:反思错误与调整策略
🤖 形象比喻:如果LLM是大脑,Agent就是拥有大脑、手脚和记忆的完整生物体,能主动感知环境、制定计划并执行任务。
✅ 关键区别:LLM只能被动回答问题,而Agent能主动拆解任务、调用工具、迭代优化,实现"用户给目标,Agent给结果"的工作模式。
1.4. Skills(技能):领域专长的"方法论资产"
- 本质:可移植的、模块化的领域专长包,让Agent从"通用"变成"专家"
- 功能定位:封装特定任务的领域知识、执行步骤、判断标准、输出格式,使Agent在处理专业任务时有章可循
- 核心特点:
- 持久化:配置一次后可反复调用,解决Prompt"临时性"问题
- 标准化:提供统一的执行规范和输出格式
- 工程化:独立文件管理,支持版本控制和测试验证
🛠️ 典型示例:代码审查Skill包含:
- 审查维度(安全漏洞、逻辑正确性等)
- 风险评级(P0阻塞、P1重要等)
- 输出格式规范
- 边界规则(只审查变更部分)
⚠️ 关键区别:Prompt是"一次性指令",而Skill是可复用、标准化的方法论资产,就像公司SOP手册,确保不同任务结果的一致性和专业性。
1.5. AGI(强人工智能):理论中的"通用智能体"
- 本质:具备与人类相当或超越人类水平的通用认知能力的人工智能系统
- 功能定位:实现对"智能"本质的复现,成为可独立应对复杂、开放、动态世界问题的通用智能体
- 核心特征:
- 跨领域学习:将知识迁移到全新领域
- 自主目标生成:主动设定子目标并制定长期策略
- 元认知能力:监控自身认知过程,识别知识盲区
- 多模态融合:整合视觉、语言、触觉等多源信息
🌌 关键区别:当前所有AI应用(包括LLM、Agent、Skills)都属于弱人工智能(ANI)范畴,而AGI仍是理论探索阶段,尚未有系统被公认为真正实现通用智能。
⚠️ 行业现状:OpenAI CEO奥尔特曼曾表示,"AGI这一术语正逐渐失去其意义",因为概念界定变得越来越困难,不同公司对AGI的定义差异很大。
1.6层级关系图解

- LLM提供基础推理能力,但需要Prompt引导输出方向
- Agent整合LLM、Skills和MCP,实现从"理解需求"到"执行任务"的闭环
- Skills解决"怎么做才专业"的问题,提供领域知识和流程规范
- MCP解决"用什么工具"的问题,提供标准化的工具接入方式
- 三者缺一不可:少了Agent,LLM、Skills、MCP就是孤立的"零件";少了Skills,Agent缺乏专业能力;少了MCP,Agent无法连接外部世界
以"生成销售周报"为例:
- 用户输入:"帮我生成2月销售周报"
- Agent决策:识别任务类型,决定调用"周报生成Skill"
- Skill加载:系统自动加载Skill内部封装的专用Prompt、规则和工具定义
- MCP执行:通过MCP协议连接数据源,获取销售数据
- LLM处理:基于Skill提供的增强版Prompt进行数据处理和分析
- 结果输出:生成结构化周报,通过MCP发送到指定渠道
1.7 行业最新趋势与实践建议
技术演进方向
- 从"Prompt工程"到"Skill工程":行业正从临时性Prompt转向可管理、可复用的Skill资产
- MCP标准化:OpenAI推出的MCP协议正成为行业统一的"工具接入标准",解决Agent生态碎片化问题
- Agent架构分层:现代AI应用架构正形成清晰分层——工作流协调Agent,Agent调用Skills,Skills通过MCP连接外部系统
实践建议
- 对开发者:不要只关注Prompt技巧,应系统化构建Skill库,将业务知识沉淀为可复用的AI能力
- 对产品经理:理解Agent不是单一工具,而是工作模式,需设计支持目标导向的交互流程
- 对业务方:不要追求"AGI"概念,应聚焦解决实际问题的"弱AI应用",当前所有商业化AI都属于ANI范畴
1.8 一句话总结区别
- LLM:提供基础语言能力的"大脑"
- Prompt:引导LLM输出的"指令"
- Agent:整合资源完成任务的"执行者"
- Skills:领域专长的"方法论资产"
- AGI:理论中的"通用智能"(当前尚未实现)
当前AI技术发展的核心逻辑是:通过Skills和MCP扩展LLM的能力边界,使Agent能够从"纸上谈兵"走向"动手做事",最终构建出真正能解决实际问题的AI应用体系。理解这些概念的本质区别与协同关系,是把握AI技术发展趋势和构建有效AI应用的关键基础。
二 skills
1.1 Skill到底是什么
在 AI 应用框架中,Skill 就是一个可以被大语言模型(LLM)调用的函数。
它的本质是把一个特定功能(比如查天气、发邮件、计算数学题)包装成一个标准接口,让 LLM 能够理解这个功能什么时候该用、怎么用,然后自动去调用它。
一个完整的 Skill 通常包含三部分:
名称 – 给 Skill 取一个简短、能表达用途的名字。
描述 – 告诉 LLM 这个 Skill 能做什么、什么时候该用它。
执行逻辑 – 真正的代码,实现具体功能(如调用 API、操作数据库等)。
LLM 本身不执行 Skill,它只是根据用户输入,结合 Skill 的描述,决定是否调用以及填入什么参数,然后由框架去执行对应的函数。
1.2 opencode配置skills
opencode如何安装可以参考:https://blog.csdn.net/josnsense/article/details/159080125?spm=1001.2014.3001.5502
下载skills源码:
https://github.com/anthropics/skills
将下载的代码放到C:\Users\用户名\.config\opencode\skill目录下
在打开opencode, 查询skills
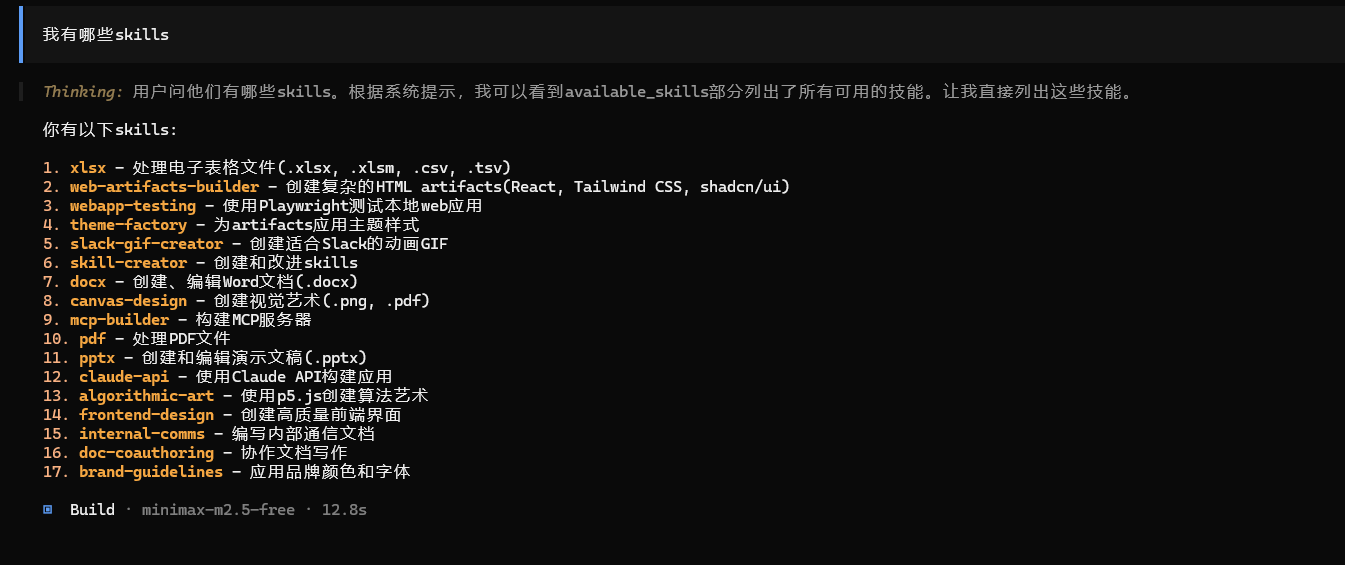 使用skills查询文档内容
使用skills查询文档内容
1.3 编写一个 简单的skills实例
pip install langchain langchain-community langchain-core langchain-openaifrom langgraph.graph import StateGraph, END, MessagesState
from langgraph.prebuilt import ToolNode
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
dp_api_key = "xxxxxxx"
open_api_key = "xxxxxx"
# 1. 定义工具
@tool
def multiply(a: int, b: int) -> int:
"""将两个数字相乘。"""
return a * b
tools = [multiply]
tool_node = ToolNode(tools)
# 2. 初始化模型
# model = ChatOpenAI(model="deepseek-reasoner", temperature=0, api_key=open_api_key).bind_tools(tools)
model = ChatDeepSeek(model="deepseek-reasoner", temperature=0, api_key=dp_api_key).bind_tools(tools)
# 3. 定义模型调用节点
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": [response]}
# 4. 构建状态图
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
# 决定下一步去哪里:如果有工具调用就去 tools 节点,否则结束
lambda state: "tools" if state["messages"][-1].tool_calls else END,
)
workflow.add_edge("tools", "agent") # 执行工具后返回 agent 节点
# 5. 编译并运行
app = workflow.compile()
result = app.invoke({"messages": [HumanMessage(content="3 乘以 5 等于多少?")]})
print(result["messages"][-1].content)1.4 Skill 的调用机制:Function Calling
现代 LLM(如 GPT-4、Claude 3)原生支持 Function Calling。它的流程是:
开发者定义好一系列函数(包括名称、描述、参数 Schema)。
把这些定义随用户消息一起发给模型。
模型如果判断需要调用某个函数,会返回一个结构化的 JSON,里面包含函数名和参数。
开发者解析这个 JSON,执行对应函数,把结果再发给模型。
模型基于结果生成最终回答。
LangChain、Semantic Kernel 等框架把这一过程封装好了,我们只需要定义 Skill,框架会自动处理与模型的交互。
1.5 组合多个 Skill:让 Agent 自动编排
一个 Agent 可以拥有多个 Skill。例如一个旅行助手 Agent 可以同时有:
get_weather(查天气)
search_attractions(搜索景点)
book_hotel(订酒店)
当用户说:“我想下周去杭州玩三天,帮我看看天气,推荐几个景点,再推荐一家离西湖近的酒店。”
Agent 可能会:
先调用
get_weather(city="杭州", date="下周")再调用
search_attractions(city="杭州", limit=3)最后调用
book_hotel(city="杭州", location="西湖", nights=3)
它会自动决定调用顺序,并把前一个步骤的结果(比如天气状况)作为上下文,影响后续决策。这就是多步推理(Reasoning + Acting)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)