蓝迪哥玩转Ai(6)---FPGA本地算力研究:当GPU不擅长“生成”,FPGA不擅长“理解”:如何把大模型推理拆给最合适的硬件?
当GPU不擅长“生成”,FPGA不擅长“理解”:如何把大模型推理拆给最合适的硬件?
学习本地AI推理算力:
大模型推理这件事,表面上看是“同一件工作”——输入一段提示词,输出一段回答。但从硬件视角看,它其实由两种完全不同的计算组成:
一段是Prefill(预填充),负责“读懂提示词”;
另一段是Decode(自回归生成),负责“一个 token 一个 token 地写答案”。
问题在于,这两段工作对硬件的偏好几乎相反。
GPU擅长 Prefill,却不擅长小批量 Decode;FPGA擅长 Decode,却不擅长长上下文 Prefill。
于是,一个很自然但又非常有工程价值的问题出现了:
能不能别让一种硬件干完整条链路,而是让 GPU 和 FPGA 各做自己最擅长的那一半?
一、这篇到底要解决什么问题?
抓住了 LLM 推理里一个常被忽略、但对系统设计极其关键的事实:
• Prefill 阶段处理整段输入,主要是大规模矩阵-矩阵乘法,计算密度很高,属于算力瓶颈。
• Decode 阶段每次只生成一个 token,主要退化为矩阵-向量乘法,数据复用很差,更像是带宽瓶颈。
这意味着:
GPU 在 Prefill 阶段能够把张量核心和并行算力吃得很满;
但到了 Decode 阶段,小 batch、单 token 的模式会让 GPU 的高算力几乎无处施展。给出的一个非常醒目的数字是:在 A100 上,Decode 阶段的计算单元利用率只有 0.19%。
反过来,HBM FPGA 在 Decode 阶段往往非常有竞争力,因为它更容易围绕带宽去做定制;但它在 Prefill 阶段受限于 DSP 数量和频率,首 token 延迟(TTFT)会非常难看。举例:对 LLaMA2-7B、1536 token 的 Prefill,U280 FPGA 需要大约 5 秒,是 A100 的 28.44 倍。
所以作者的核心判断很直接:
不要试图让单一硬件同时把 Prefill 和 Decode 都做到最好,而应该做异构协同。
GPU-FPGA协同的LLM推理系统架构
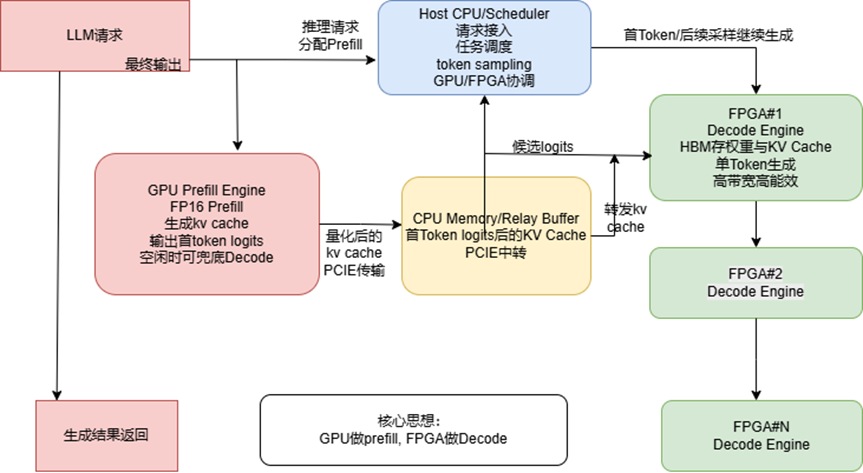
二、核心思路:GPU管“理解”,FPGA管“生成”
其实一句话就能概括:
让 GPU 负责 Prefill,让 FPGA 负责 Decode。
系统由三部分组成:
• Host CPU:做调度;
• GPU:执行 Prefill,也能在必要时兜底做 Decode;
• 多个 FPGA:主要负责 Decode。
具体流程如下:
- CPU 收到一个 LLM 推理请求后,把 Prefill 分给 GPU。
- GPU 用 FP16 完成 Prefill,算出每层的 K/V cache 和首 token 的 logits。
- GPU 把 Prefill 产生的 KV cache 先保存在显存里,然后量化后通过 PCIe 传给 CPU,再由 CPU 转发到指定 FPGA 的 HBM 中。
- CPU 根据首 token logits 采样出第一个 token,把这个 token 发送给对应 FPGA。
- FPGA 从此接管 Decode,每轮生成 logits,回传给 CPU 采样下一个 token,再继续下一轮。
这个设计有两个很重要的工程点。
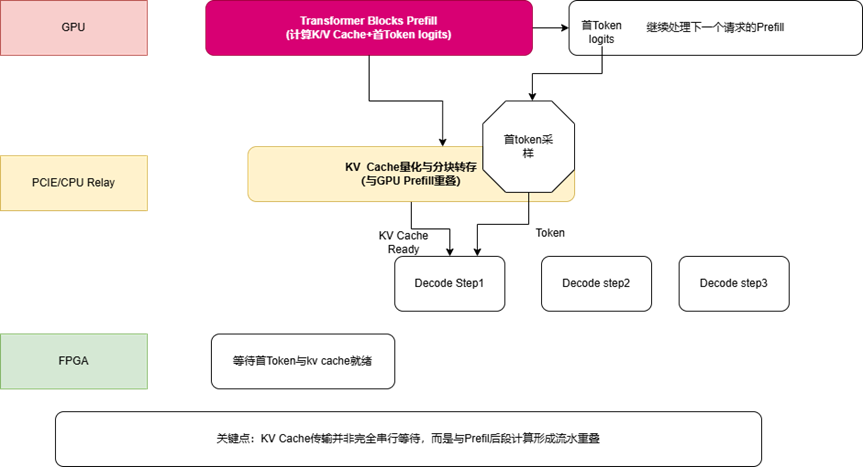
1)KV cache 传输延迟大多可以被掩盖
直觉上,大家可能会担心:
“GPU 刚算完 Prefill,就要把大量 KV cache 搬到 FPGA,这不就把异构系统的收益全吃掉了吗?”
答案是:大多数情况下不会。
原因是 Prefill 的复杂度随序列长度近似二次增长,而 KV cache 传输量主要随序列长度线性增长;再加上作者把多个 Transformer block 的计算与 KV cache 传输做了流水重叠,因此在较长输入下,数据传输延迟往往低于 GPU 自己的 Prefill 时延。
这其实是 GLITCHES 能成立的前提之一:
异构不是简单拼盘,而是必须把“传输”嵌到“计算”里。
2)GPU 不必闲着,还可以“客串” Decode
作者没有把 GPU 固定死为只做 Prefill。
当所有 FPGA 都忙时,如果 GPU 暂时没有新的 Prefill 任务,它也可以临时作为 Decode 设备参与生成。与此同时,Host 侧调度器采用先来先服务策略,把 Decode 请求分配给空闲 FPGA;如果显存不足,则任务进入队列等待。
这说明不是只在“单请求静态映射”层面讲故事,而是已经开始考虑多请求调度和单节点资源利用率。
三、最有意思的点:它不只“分工”,还继续榨干 FPGA 的带宽
如果说“GPU 做 Prefill、FPGA 做 Decode”是系统级思路,那么第二个贡献则更偏硬件实现:
作者发现,即便已经用上了 HBM,FPGA 在 Decode 阶段的带宽利用率依然没有被吃满。
为什么?
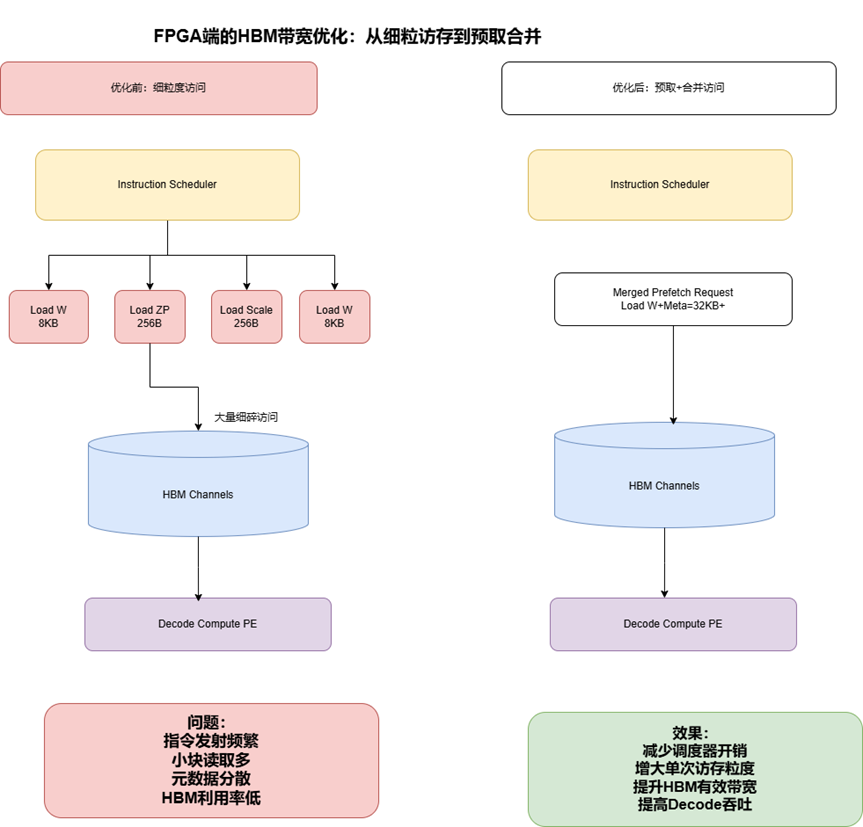
因为作者基于 FlightLLM 这类指令驱动的 FPGA LLM 加速器观察到:
FPGA 访问 HBM 不是“想读就读”,而是通过 LD/ST 指令发给 datamover。于是,性能不只取决于 HBM 本身,还取决于指令调度器的解码与发射开销。如果读取的数据块太小,虽然 HBM 理论带宽很高,但实际会被大量细粒度指令拖慢。
更麻烦的是,量化模型虽然减少了权重体积,却引入了更多量化元数据(如 zero point、scale)。这些元数据和权重常常放在不同缓冲区中,导致需要大量细粒度 load 指令。结果是:
HBM 带宽利用率只有约 40%。
6. 作者的优化:数据预取 + 访问合并
做法是:
• 预先把后续多个矩阵-向量计算所需的权重和量化元数据一并取回来;
• 把原本很多细粒度内存访问请求合并成更粗粒度的大访问;
• 从而减少指令调度开销,提高 HBM 有效利用率。
作者还专门做了一个 profiler,证明小块访问在带有 instruction scheduler 的情况下性能明显更差,而把单次访问量提高到 32KB 以上会显著改善带宽利用。
实验里,最佳预取比为 4。在这个设置下:
• q_proj 层单次权重访问从 8KB 提高到 32KB;
• 量化元数据单次访问从 256B 提高到 1KB;
• 端到端 Decode 性能在序列长度 128 和 1024 时分别提升 1.20× 和 1.16×。
这部分很值得做系统的人细品:
硬件瓶颈很多时候不是“HBM 不够快”,而是“你喂 HBM 的方式太碎了”。
四、最关键的实验数字
实验对象是:
• GPU:NVIDIA A100、V100S
• FPGA:Xilinx Alveo U280(带 HBM)
• 模型:LLaMA2-7B
• GPU 端使用 HuggingFace FP16 实现;
• FPGA 端基于接近 FlightLLM 的量化实现,约为 W4A8。
U280加速卡价格:
学习成本不是一般高,加油,努力赚钱。
1)单设备层面的观察
给出的例子中,针对 Prefill 1536 tokens + Decode 512 tokens:
• A100 Prefill 延迟为 175.85 ms,Decode 每 token 平均 24.26 ms;
• V100S Prefill 延迟为 398.80 ms,Decode 每 token平均 29.52 ms;
• U280 FPGA Prefill 延迟约 5001.20 ms,但 Decode 每 token平均 21.50 ms。
这个结果很能说明问题:
FPGA 在 Prefill 上惨败,但在 Decode 上并不差,甚至优于 V100S。
更进一步看能效和成本效率,在 Decode 阶段:
• A100 的能效为 2.46E-01 token/s/W
• V100S 为 1.52E-01 token/s/W
• U280 FPGA 则达到 1.01E+00 token/s/W。
也就是说,FPGA 更像是“省电生成器”,GPU 更像是“高速理解器”。
2)系统级对比:异构系统是否真的值?
作者模拟了单节点 8 卡系统,比较三种方案:
• 全 GPU;
• 全 FPGA;
• 1 张 GPU + 7 张 FPGA 的 异构系统。
结论是:
• 使用 A100 + 7×U280 时, 相比 8×A100 的纯 GPU 系统,平均系统吞吐提升 1.28×,成本效率提升 2.38×;相比 8×U280 纯 FPGA 系统,平均吞吐提升 1.23×,成本效率提升 1.08×。
• 使用 V100S + 7×U280 时,相比 8×V100S 的纯 GPU 系统,平均系统吞吐提升 1.34×,成本效率提升 1.90×;相比纯 FPGA 系统,吞吐提升 1.21×,成本效率提升 1.14×。
换句话说,这个的价值不是“某个 kernel 更快”,而是:
它把一条本来在单一架构上利用率很差的推理链路,重组成了一条更平衡的系统流水线。
五、最值得关注的,不只是结果,而是方法论
最值得记住的,不是“1.28× 吞吐提升”这种数字本身,而是它体现出的三层方法论。
第一层:按阶段分解 LLM 推理,而不是按模型整体看硬件
很多人讨论“大模型部署在哪种硬件更好”,默认前提还是“整模型在一种硬件上跑”。
说明,LLM 推理天然就该分阶段看。Prefill 和 Decode 的算子形态、访存模式、瓶颈来源都不同,把它们强行绑定在同一种硬件上,本身就是一种资源浪费。
第二层:异构系统的关键不是“连接起来”,而是“流水化”
GPU 和 FPGA 之间当然可以互连,但真正决定收益的,是不是能把 Prefill 计算、KV cache 传输、Decode 启动 做成重叠流水。GLITCHES 之所以成立,正是因为作者验证了数据传输通常可以被 Prefill 计算掩盖。
第三层:系统优化不能停留在“高层分工”,还得回到“底层带宽喂养”
没有满足于“系统结构已经对了”,而是继续追问:
FPGA 的 HBM 为什么还没吃满?
这才引出了 instruction scheduler 开销、细粒度访存、量化元数据分离、数据预取合并这些真正影响端到端性能的细节。
这类工作最难的地方恰恰在这里:
它既要懂模型,也要懂系统,还要懂硬件微架构。
六、这篇的局限也很明显
当然,这不是“终极答案”。
首先,它主要基于 LLaMA2-7B 和单节点 8 卡系统评估,更多是验证思路的可行性,而不是直接给出大规模生产级方案。
其次,系统里仍然存在一些现实约束:
• GPU 与 FPGA 都要各自保存模型权重副本;
• KV cache 仍要经过 GPU→CPU→FPGA 的路径;
• 调度器目前相对简单,复杂多租户环境下的最优调度仍未解决;
• 多节点扩展只做了方向性讨论,尚未展开完整实验。
再进一步说,思路更适合延迟敏感、batch 较小的场景。
如果进入超大 batch、高吞吐离线服务,系统的最优点未必还是这种划分。
七、我的看法:代表了一种很重要的趋势
如果把时间拉长看,这代表的不是“GPU+FPGA 组合拳”这么简单,而是:
LLM 推理系统正在从“单芯片优化”走向“跨设备阶段解耦”。
未来的部署系统,很可能不是:
• 一整条链路塞进 GPU,也不是:
• 一整条链路塞进 FPGA,而是变成:
• GPU 集群负责高吞吐 Prefill;
• FPGA / ASIC / 近存设备负责高能效 Decode;
• KV cache、调度、网络传输成为系统设计中心。
从这个意义上说,价值在于它把一个以前“好像能想象,但不太敢认真做”的方案,变成了有实验、有数据、有工程逻辑的异构系统原型。
一句话总结
这个方案最精彩的地方,不是证明 GPU 或 FPGA 谁更强,而是证明:在 LLM 推理里,“让最合适的硬件干最合适的阶段”,比争论谁是万能硬件更重要。
总得来说:AI就是贵。没有办法,努力搞钱吧,大家好好工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)