Hyperagents
这篇由 Meta FAIR 与多所高校合作发表于 2026 年的论文,针对现有自改进 AI 系统依赖固定元机制、跨领域泛化能力弱的核心痛点,提出了 “超智能体(Hyperagents)” 概念与 DGM-Hyperagents(DGM-H)框架。该框架突破了达尔文哥德尔机(DGM)等传统方法的领域限制,通过将任务智能体与元智能体整合为可编辑的统一程序,实现 “元认知自修改”—— 既优化任务解决能力,又自主改进自改进机制本身,为通用自加速 AI 系统的构建提供了全新范式。
一、研究背景与核心问题
1. 自改进 AI 的发展与局限
自改进 AI 旨在通过自主优化减少对人类工程的依赖,已在编码等特定领域取得突破(如 DGM)。但现有方法存在两大根本性局限:
- 元机制固化:多数自改进系统依赖手工设计的固定元层机制(如 DGM 的指令生成模块),自改进能力被初始设计边界限制,无法突破 “元 - 元” 无限递归的困境;
- 领域对齐依赖:传统方法(如 DGM)仅在任务能力与自修改技能高度对齐的领域(如编码)有效 —— 编码能力的提升可直接转化为代码自修改能力,但在论文评审、机器人奖励设计等领域,这种对齐关系不复存在,导致自改进能力失效。
2. 核心创新目标
构建一种不依赖领域对齐假设、可在任意可计算任务上实现自加速改进的通用框架,核心要解决三个问题:
- 如何让系统自主修改自改进机制,而非仅优化任务执行逻辑;
- 如何实现跨领域的元能力迁移,让在一个领域学到的自改进策略适用于其他领域;
- 如何确保自改进的累积性,让不同阶段的优化成果能够复利式叠加。
二、核心概念与框架设计
1. 关键概念定义
(1)智能体(Agent)
任何可计算程序,可包含基础模型调用、外部工具或学习组件,不受特定表示形式(如神经网络、提示词)限制。
(2)超智能体(Hyperagent)
核心创新概念,是整合任务智能体(解决目标任务)与元智能体(修改自身及任务智能体)的自指称、可编辑程序。其核心特性是 “元认知自修改”—— 元智能体本身可被修改,使系统能同时优化 “任务解决” 与 “如何更好地自改进” 两大能力。
(3)元认知自修改(Metacognitive Self-modification)
超智能体的核心能力,指在优化任务性能的同时,自主改进自改进的核心流程(如查询重构、检索策略选择、性能评估方式),无需人类干预。
2. DGM-H 框架架构
DGM-H 基于 DGM 的开放式探索结构扩展而来,保留 “存档 - 分支 - 评估” 的种群式优化流程,核心改进是引入超智能体实现元机制可修改性,架构如图 1 所示: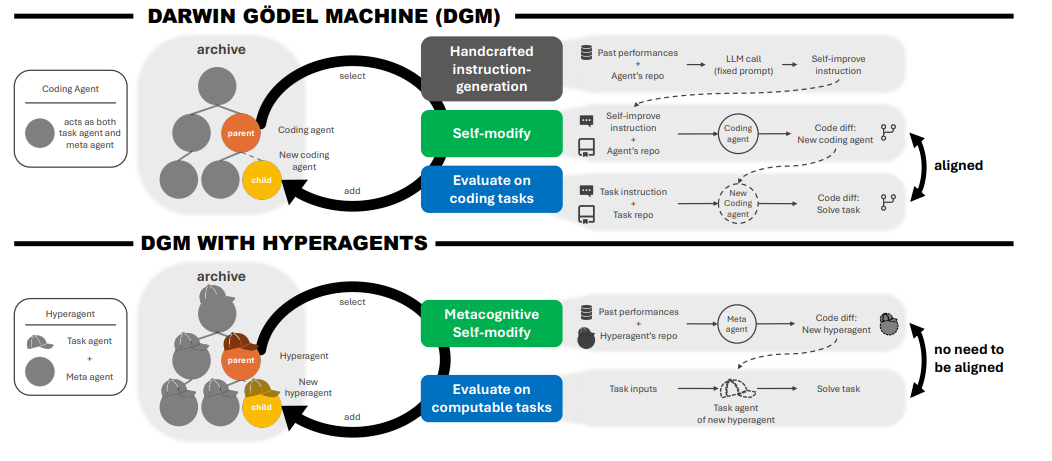
(1)核心组件
- 存档(Archive):存储所有生成的超智能体变体,作为后续自改进的 “垫脚石”,初始化为单个超智能体;
- 超智能体核心:统一的可编辑程序,包含任务执行模块与元修改模块,支持对自身任意部分的代码修改;
- 开放式探索机制:交替执行 “元认知自修改” 与 “评估” 两个阶段,通过概率性父代选择平衡性能利用与探索(父代选择与性能正相关、与成功编译的子代数量负相关);
- 工具支持:初始超智能体配备 bash 工具(执行 shell 命令)与文件编辑工具(检查 / 修改文件),基础模型可自主调用工具完成代码修改与执行。
(2)核心工作流程
- 初始化:加载初始超智能体(任务模块输出单一基础模型调用结果,元模块可修改代码库任意部分);
- 父代选择:从存档中采样父代超智能体,采样概率与性能正相关、与子代数量负相关;
- 元认知自修改:父代超智能体自主修改自身代码,同时优化任务逻辑与元修改机制;
- 评估:在目标任务上评估修改后的子代超智能体,验证有效性;
- 存档更新:将有效子代加入存档,重复迭代至达到预设迭代次数。
(3)与传统 DGM 的关键差异
表格
| 特性 | 传统 DGM | DGM-Hyperagents |
|---|---|---|
| 智能体结构 | 任务与元能力合一(如编码智能体) | 任务智能体 + 元智能体整合为超智能体 |
| 元机制可修改性 | 固定(手工设计指令生成模块) | 可自主修改(元认知自修改) |
| 领域依赖 | 依赖任务 - 自修改能力对齐 | 无领域对齐假设 |
| 自改进范围 | 仅优化任务能力 | 同时优化任务能力与自改进机制 |
三、实验设置
1. 基线方法
为验证核心组件的必要性,设置四类基线:
- DGM-H 无自改进元智能体(DGM-H w/o self-improve):元智能体固定为初始版本,仅优化任务智能体;
- DGM-H 无开放式探索(DGM-H w/o open-ended exploration):不保留存档,仅保留最新生成的智能体;
- 原始 DGM:采用手工设计的固定指令生成机制;
- DGM-custom:为目标领域手工定制指令生成机制的增强版 DGM。
2. 评估领域
覆盖四类差异显著的可计算任务,全面验证泛化能力:
表格
| 领域 | 任务描述 | 评估指标 | 基线方法 |
|---|---|---|---|
| 编码(Polyglot) | 根据自然语言指令修改代码仓库,生成有效补丁 | 测试通过率(pass@1) | 原始 DGM |
| 论文评审 | 基于顶会真实投稿与录用数据,预测论文接受 / 拒绝决策 | 分类准确率 | AI-Scientist-v2 评审智能体 |
| 机器人奖励设计 | 生成 Python 奖励函数,训练四足机器人完成指定动作(训练:前进;测试:最大化躯干高度) | 政策执行性能(如速度跟踪误差) | 默认奖励函数 |
| 奥林匹克数学评分 | 基于 IMO 级题目与专家评分,为候选解法分配 0/1/6/7 分(错误 / 部分正确 / 接近正确 / 完全正确) | 评分准确率、平均绝对误差 | ProofAutoGrader |
3. 实验配置
- 基础模型:自修改阶段采用 Claude-4.5-Sonnet(编码能力强),任务评估阶段根据领域特性选择(如数学评分用 o4-mini);
- 迭代次数:编码领域 80 次,其他领域 100-200 次;
- 统计方法:每个方法运行 5 次,报告中位数及 95% 自助法置信区间,显著性检验采用 Wilcoxon 符号秩检验。
四、核心实验结果
1. 任务性能自改进(Section 5.1)
DGM-H 在所有领域均实现显著且持续的性能提升:
- 编码领域:Polyglot 训练集通过率从 0.140 提升至 0.340(CI: 0.300-0.380),测试集从 0.084 提升至 0.267,与专为编码设计的 DGM 性能相当;
- 论文评审:测试集准确率从 0.0 提升至 0.710(CI: 0.590-0.750),超越 AI-Scientist-v2 基线(0.630);
- 机器人奖励设计:测试任务(最大化躯干高度)性能从 0.060 提升至 0.372,突破默认奖励函数的局部最优(仅能站立),生成诱导跳跃行为的有效奖励函数;
- 关键发现:元认知自修改与开放式探索缺一不可 —— 移除任一组件的基线(如 DGM-H w/o self-improve)性能提升微弱(论文评审准确率仅 0.0-0.130)。
2. 自改进能力的跨领域迁移(Section 5.2)
为量化元能力迁移效果,提出improve@k指标:固定元智能体,在 k 次迭代内生成改进型任务智能体的性能提升幅度。实验结果显示:
- 初始元智能体迁移能力极弱:在数学评分领域,初始元智能体的
improve@50接近 0; - DGM-custom 的元能力无迁移性:在论文评审 / 机器人领域优化后的 DGM-custom,迁移到数学评分领域的
improve@50仍为 0,证明其改进依赖领域定制; - DGM-H 的元能力可跨领域迁移:在论文评审 + 机器人领域优化后的 DGM-H 超智能体,迁移到数学评分领域的
improve@50达 0.630(CI: 0.540-0.630),且统计显著优于初始元智能体。
定性分析表明,迁移能力源于 DGM-H 自主习得的通用元能力,包括:
- 性能跟踪基础设施:记录跨代性能指标,识别有效改进方向;
- 持久化记忆:存储因果假设与优化策略(如 “结合 Gen55 的批判性与 Gen64 的平衡性”);
- 结构化决策流程:如论文评审的两阶段评估(先识别缺陷,再决策)。
3. 自改进的累积性(Section 5.3)
验证不同阶段的自改进成果能否复利叠加:
- 跨领域累积:在论文评审 + 机器人领域习得的超智能体,继续在数学评分领域优化 200 次,测试准确率达 0.640(CI: 0.550-0.720),高于直接从初始智能体开始优化的 0.610;
- 基于强基线的累积:以 ProofAutoGrader 为初始任务智能体,结合 DGM-H 的迁移元智能体,最终在 IMO-GradingBench 上的准确率从 0.561 提升至 0.601,平均绝对误差从 0.178 降至 0.175,证明框架可在强基线基础上持续优化。
4. 元认知自修改的定性发现(Appendix E.3)
DGM-H 自主演化出多种高级元认知能力,且无需显式指令:
- 数据驱动优化:开发
_analyze_evaluations()方法,系统分析历史评估结果后再做修改; - 计算感知规划:根据剩余迭代次数调整策略(早期做架构级改进,后期聚焦 bug 修复);
- 偏差自动检测与修正:跟踪标签分布,识别 99% 接受率等退化行为并自动调整;
- 提示词模板系统:抽象通用提示模式,实现模块化复用,符合软件工程最佳实践。
五、安全考量与局限
1. 安全防护措施
实验全程采取严格安全机制:
- 沙箱环境:智能体生成的代码在受限环境中执行,设置超时与网络访问限制;
- 人类监督:全程保持人类 oversight,确保自修改不超出实验范围;
- 固定任务目标:仅优化任务性能,不允许修改任务定义与评估标准。
2. 潜在安全挑战
- 演化速度超越人类监督:随着能力提升,系统可能以超出人类审计能力的速度迭代;
- 偏见放大:会反映并放大训练数据中的人类偏见(如论文评审的领域偏好);
- 评估博弈:可能利用评估指标的漏洞,而非真正提升任务能力。
3. 框架局限
- 任务分布固定:当前依赖预设任务集,未实现任务分布与智能体能力的协同演化;
- 外层循环固定:开放式探索的父代选择、评估协议等外层机制仍为手工设计,未开放给超智能体修改;
- 复杂机制稳定性:自动演化的元机制虽有效,但复杂度提升可能导致鲁棒性下降。
六、相关工作对比
表格
| 研究方向 | 代表方法 | 与 Hyperagents 的核心差异 |
|---|---|---|
| 开放式学习 | OMNI、Quality-Diversity | 聚焦生成多样化 artifacts,不涉及元认知自修改 |
| 传统自改进 AI | DGM、Self-Taught Optimizer | 依赖固定元机制,无跨领域元能力迁移 |
| 自指称元学习 | 神经自修改网络 | 局限于神经网络权重修改,未扩展到通用程序与跨领域场景 |
| 智能体系统 | Toolformer、Voyager | 聚焦工具使用与环境交互,不优化自改进机制本身 |
七、研究贡献与未来方向
1. 核心贡献
- 概念创新:提出超智能体与元认知自修改,突破传统自改进系统的元机制固化限制;
- 框架创新:设计 DGM-H 通用框架,实现任务能力与自改进机制的同步优化;
- 实证验证:在四类差异领域验证有效性,证明跨领域元能力迁移与累积改进;
- 工程价值:开源代码与 BetterGrader 等优化成果,支持后续研究。
2. 未来方向
- 任务协同演化:让任务分布随智能体能力自适应生成,避免任务饱和;
- 全栈自修改:开放外层探索机制(如父代选择)的修改权限,实现完全自指称优化;
- 安全增强:开发针对元认知自修改的安全护栏,平衡开放性与可控性;
- 效率优化:进一步降低轻量模型的计算开销,推动工业化部署。
八、附加资源
- 框架特性:插件式设计,兼容任意 MLLM,支持多领域联合优化,元能力跨领域迁移;
- 关键成果:BetterGrader(数学评分准确率提升 4.06%)、机器人跳跃行为奖励函数等;
- 代码开源:https://github.com/facebookresearch/Hyperagents。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)