Google TurboQuant 技术全解析:3bit 无损 KV 缓存量化,重新定义大模型长上下文的落地边界
在大模型技术飞速迭代的今天,长上下文能力已经成为模型竞争力的核心指标,也是企业级场景落地的刚需。但几乎所有开发者都被同一个核心痛点死死卡住:KV 缓存的显存爆炸问题。
大模型的长上下文对话、长文档解析、代码库全量分析,本质上都在消耗海量的 GPU 显存,而其中 70% 以上的显存占用,都来自 Transformer 架构里的键值缓存(Key-Value Cache)。它会随着输入序列的长度线性增长,上下文越长,显存占用越高,最终让大模型的长上下文能力,只能停留在实验室的高端 GPU 集群里,无法落地到端侧、边缘设备与低成本的生产环境中。
行业的通用解决方案是量化:用更少的比特数(比如 4bit 替代 16bit)来表示 KV 缓存里的数值,以此压缩显存占用。但传统量化方案始终逃不开一个魔咒:压缩必然带来精度损失,低 bit 量化需要额外的校正常数对冲误差,而这些常数本身会吃掉压缩带来的收益—— 当你想要把 KV 缓存压缩到 3-4bit 时,额外的校正常数就会占用 1-2bit 的空间,让低 bit 压缩的价值几乎消失。
而 Google 最新发布的 TurboQuant,彻底打破了这个行业困局。这套无需训练、无需微调的模型压缩技术,能将 Transformer 的 KV 缓存直接量化到 3bit,在标准基准测试中无任何可测量的精度损失,同时还能让注意力计算的运行速度最高提升 8 倍。它不是简单的工程化调优,而是从数学底层重构了 KV 缓存量化的逻辑,为大模型长上下文的规模化落地,打开了全新的边界。
一、长上下文的生死线:为什么 KV 缓存决定了大模型的落地天花板?
想要理解 TurboQuant 的颠覆性,首先要搞懂一个核心问题:KV 缓存到底是什么?为什么它会成为大模型长上下文能力的核心瓶颈?
在 Transformer 的自注意力机制中,模型生成每一个 Token 时,都需要重新计算输入序列中所有 Token 的键(Key)和值(Value)向量,以此计算注意力权重,理解上下文的语义关联。如果每生成一个新 Token 都重新计算全量的 K/V 向量,会导致计算量随序列长度呈平方级增长,推理速度慢到无法使用。
而 KV 缓存,就是为了解决这个问题而生的:它会把之前计算过的所有 Token 的 K/V 向量存储下来,生成新 Token 时,只需要计算新增 Token 的 K/V 向量,直接复用历史缓存的内容,把计算复杂度从 O (n²) 降到了 O (n),让大模型的连续生成成为可能。
但这个设计也带来了一个无法回避的问题:KV 缓存的显存占用,会随着输入序列的长度线性增长。以 Llama-3-70B 模型为例,当上下文长度达到 128K 时,单轮对话的 KV 缓存显存占用就会超过 80GB,哪怕是最高端的 H100 GPU,单卡也无法支撑;即便是 8B 级别的轻量模型,32K 上下文的 KV 缓存也会吃掉大量显存,直接限制了单卡的并发服务能力。
更关键的是,随着大模型向端侧、边缘设备普及,手机、嵌入式设备的显存资源极其有限,KV 缓存的显存占用,直接决定了端侧大模型能否支持长上下文对话、长文档解析等核心功能。可以说,KV 缓存的压缩效率,已经成为了大模型从云端走向端侧、从实验室走向生产环境的核心天花板。
二、传统量化的核心困局:低 bit 压缩的精度诅咒与隐形开销
面对 KV 缓存的显存难题,行业的主流解决方案是量化:用更低的比特宽度来表示 K/V 向量中的数值,比如用 4bit 整数替代原本的 16bit 浮点数,理论上能把 KV 缓存的显存占用直接压缩 75%。但在实际落地中,传统量化方案始终面临两个无法突破的核心瓶颈。
第一个瓶颈,是低 bit 量化的精度损失魔咒。KV 缓存里的数值分布并非均匀的,注意力权重对 K/V 向量的数值变化极其敏感,传统的线性量化会在低 bit 场景下引入大量的量化误差,直接导致注意力计算失准,最终让模型的长上下文理解能力大幅下降,出现回答偏离、事实幻觉、逻辑断裂等问题。绝大多数方案在 4bit 以下量化时,都会出现可测量的精度损失,无法在生产环境中使用。
第二个瓶颈,是校正常数的隐形开销。为了对冲低 bit 量化带来的误差,传统方案会为每一个数据块存储额外的校正常数(比如缩放因子、零点偏移量),以此还原量化后的数值。但这些校正常数本身也需要占用显存空间:当你想要把 KV 缓存压缩到 3-4bit 时,校正常数就会额外占用 1-2bit 的空间,让低 bit 压缩的显存收益被大幅抵消。更严重的是,这些常数的存储与读取,还会带来额外的计算开销,导致量化后的模型推理速度不升反降。
这就是行业长期以来的困局:想要极致的压缩比,就要牺牲模型精度;想要保持精度,就无法实现真正的低 bit 压缩。而 Google 的 TurboQuant,通过两大数学创新的结合,彻底跳出了这个困局。
三、TurboQuant 的核心原理:两大数学创新,实现 3bit 无损压缩
TurboQuant 的颠覆性,不在于工程化的调优,而在于从数学底层重构了量化逻辑。它没有在传统的笛卡尔坐标系里做线性量化的优化,而是把两个独立的创新技术 ——PolarQuant 与 QJL,组合成了一套两级压缩体系,最终实现了 3bit 量化无精度损失、无需训练微调、推理速度不降反升的效果。
第一级压缩:PolarQuant,用坐标转换重构量化逻辑
PolarQuant 是 TurboQuant 的第一级压缩核心,它彻底跳出了传统线性量化的框架,通过坐标系统的转换,解决了低 bit 量化的误差问题。
传统量化是在笛卡尔坐标系中,对 K/V 向量的 x/y/z 轴数值分别做线性量化,而 K/V 向量的数值分布往往是不规则的,线性量化很难在低 bit 下精准拟合原始数据,必然会引入大量误差。而 PolarQuant 的核心思路,是把向量从笛卡尔坐标系转换为极坐标系:不再用 x/y/z 的坐标值表示向量,而是用「半径(向量的模长)+ 角度(向量的方向)」来描述。
这个看似简单的坐标转换,带来了一个质的变化:K/V 向量在极坐标系中的数据分布变得高度可预测、高度集中。绝大多数 K/V 向量的方向差异,是注意力权重计算的核心,而模长的分布相对集中。PolarQuant 可以用极少的比特数精准量化向量的角度,用稍多的比特数量化模长,在极低的比特宽度下,就能完整保留向量的核心语义信息,大幅降低量化带来的误差。
作为 TurboQuant 的第一级压缩,PolarQuant 完成了绝大多数的压缩工作,把原本 16bit 的 K/V 向量压缩到极低的比特宽度,同时只留下了极小的残差误差。而这些残差,就交给第二级压缩的 QJL 来处理。
第二级压缩:QJL,1bit 无额外开销的残差校正
QJL(Quantization with Johnson-Lindenstrauss)是 TurboQuant 的第二级核心,也是它能实现无损压缩的关键。传统量化方案的思路,是通过校正常数消除量化残差,而 QJL 的思路完全相反:它不需要消除残差,只需要消除残差的系统偏差,保证它不会持续扭曲注意力分数。
QJL 是一套极致轻量化的 1bit 量化方案,它对每个数值只需要存储一个符号位,不需要任何额外的校正常数、缩放因子,1bit 就是全部的存储开销。它基于严格的数学理论保证,通过约翰逊 - 林登斯特劳斯引理,对 PolarQuant 留下的残差做无偏处理,确保残差不会对注意力权重的计算产生系统性的干扰,哪怕残差本身没有被完全消除,也不会影响模型的最终输出精度。
这个设计完美解决了传统量化的核心痛点:它没有额外的校正常数开销,不会吃掉低 bit 压缩的显存收益,同时从理论上保证了量化不会对模型精度产生可测量的影响。
两级压缩的完美协同:TurboQuant 的无损闭环
TurboQuant 的完整流程,形成了一个完美的无损压缩闭环:
- 第一阶段,通过 PolarQuant 将 K/V 向量从笛卡尔坐标系转换为极坐标系,完成核心的低 bit 量化,实现绝大多数的显存压缩;
- 第二阶段,通过 QJL 对 PolarQuant 留下的残差做 1bit 无偏处理,消除残差对注意力计算的系统性影响,保证量化后的注意力计算结果与原始结果完全一致;
- 整个过程无需任何训练、微调,开箱即用,同时因为比特宽度大幅降低,注意力计算的访存开销显著减少,最终实现了最高 8 倍的推理速度提升。
这就是 TurboQuant 最颠覆性的地方:它没有在传统量化的框架里做边际优化,而是通过数学底层的创新,同时解决了 “压缩比、精度、速度” 三个核心矛盾,打破了低 bit 量化的不可能三角。
四、硬核性能实测:3bit 量化精度持平全精度缓存,推理速度最高提升 8 倍
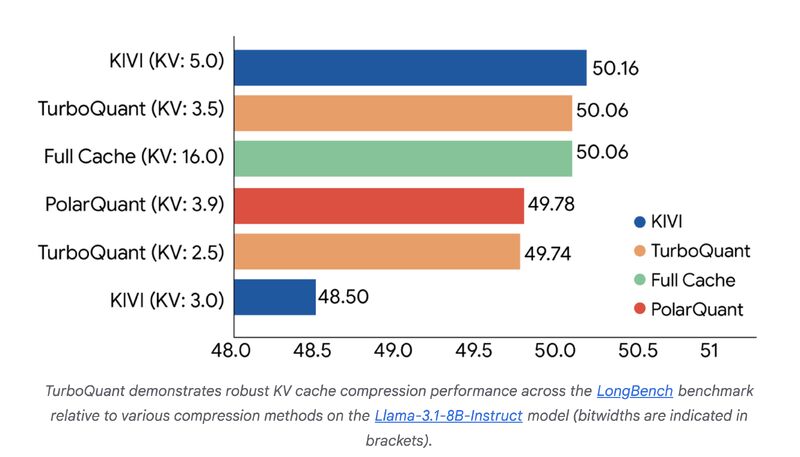
TurboQuant 的实际效果,在 LongBench 长上下文基准测试中得到了完整的验证,测试基于 Llama-3.1-8B-Instruct 模型,对比了行业主流的 KV 缓存压缩方案,结果彻底颠覆了行业对低 bit 量化的认知。
从测试数据中,我们可以清晰看到 TurboQuant 的碾压级优势:
- 3.5bit 量化实现无损精度:TurboQuant 在 KV 缓存 3.5bit 的量化宽度下,LongBench 基准得分达到了 50.06,和 16bit 全精度 Full Cache 的得分完全一致,实现了真正的 “无任何可测量精度损失”。而行业主流的 KIVI 方案,需要 5.0bit 的量化宽度,才能达到 50.16 的接近得分,3.0bit 时得分直接掉到 48.50,出现了显著的精度下降;PolarQuant 单方案在 3.9bit 时,得分仅为 49.78,依然低于 TurboQuant 3.5bit 的表现。
- 2.5bit 量化依然保持极高精度:TurboQuant 在 KV 缓存压缩到 2.5bit 时,LongBench 得分依然达到了 49.74,仅比全精度缓存低 0.32 分,几乎没有可感知的精度损失,完全满足生产环境的使用要求。这个压缩比,是传统量化方案根本无法企及的 —— 同等比特宽度下,传统方案已经出现了严重的精度崩塌。
- 注意力计算最高 8 倍加速:除了显存压缩的核心收益,TurboQuant 还带来了显著的推理速度提升。论文数据显示,得益于极低的比特宽度和无额外校正常数的设计,TurboQuant 能让注意力计算的速度最高提升 8 倍,彻底解决了传统量化 “省显存但降速度” 的通病。对于云端推理场景而言,这意味着单卡能承载的并发数大幅提升,推理成本直接下降 80% 以上。
更重要的是,所有这些效果,都不需要对模型做任何训练、微调,只需要在推理阶段替换掉原有的 KV 缓存逻辑,就能开箱即用。这意味着 TurboQuant 可以无缝集成到现有的大模型推理框架中,几乎零成本落地,这是它相比其他量化方案最具竞争力的优势之一。
五、四大颠覆性突破:TurboQuant 重新定义量化技术的行业标准
TurboQuant 的发布,不是一次简单的量化技术迭代,而是从底层重构了 KV 缓存量化的技术逻辑,带来了四个行业级的颠覆性突破,彻底改写了低 bit 量化的落地规则。
1. 打破低 bit 量化的精度魔咒,3bit 实现无损压缩
在此之前,行业普遍认为 4bit 是 KV 缓存量化的精度红线,低于 4bit 的量化必然会带来显著的精度损失,无法在生产环境使用。而 TurboQuant 通过极坐标量化与无偏残差处理的结合,在 3.5bit 实现了与 16bit 全精度完全一致的效果,2.5bit 依然保持了极高的精度,彻底打破了低 bit 量化的精度魔咒,把 KV 缓存压缩的边界向前推进了一大步。
2. 无需训练微调,开箱即用的零门槛落地
绝大多数先进的量化方案,都需要通过微调、校准数据集来对冲精度损失,落地门槛极高,需要大量的算力与数据支撑。而 TurboQuant 的整个量化过程完全基于数学原理,不需要任何训练、微调,不需要额外的校准数据集,只需要在推理阶段集成即可生效,哪怕是个人开发者,也能零门槛把它用到自己的大模型项目中。
3. 显存压缩与推理加速兼得,打破量化的性能悖论
传统量化方案始终面临一个悖论:压缩了显存,却因为额外的校正、反量化操作,导致推理速度下降,甚至出现 “省了显存,慢了速度” 的尴尬局面。而 TurboQuant 通过极简的量化逻辑,大幅降低了注意力计算的访存开销,在压缩显存的同时,实现了最高 8 倍的推理速度提升,真正做到了 “既要省显存,又要提速度”。
4. 严格的理论保证,而非工程化 Trick
和很多靠工程调优、场景适配的量化方案不同,TurboQuant 的两大核心组件 PolarQuant 和 QJL,都有完整的数学理论支撑与效果保证,不是针对特定模型、特定场景的 Trick。这意味着它可以适配所有基于 Transformer 架构的大语言模型,无论是开源的 Llama、Qwen,还是闭源的商用模型,都能实现稳定的压缩效果与精度保持,具备极强的通用性。
六、行业级影响:TurboQuant 将如何改变大模型的落地格局?
TurboQuant 的出现,绝不仅仅是一次量化技术的升级,它会从底层改变大模型的落地格局,推动整个行业进入长上下文规模化落地的新阶段。
1. 端侧大模型迎来长上下文革命
端侧部署是大模型未来的核心赛道,但手机、嵌入式设备的显存资源极其有限,此前端侧大模型只能支持几千 Token 的短上下文对话,长文档解析、多轮长对话根本无法实现。TurboQuant 能把 KV 缓存压缩到原本的 1/5 甚至更低,让 8B 级别的端侧模型,在手机上就能稳定支持 32K 甚至更长的上下文,彻底打开端侧大模型的应用边界,让真正的离线长上下文 AI 助手成为可能。
2. 云端推理成本迎来指数级下降
对于云厂商、AI 企业而言,大模型推理的核心成本就是 GPU 算力与显存开销。KV 缓存是推理阶段显存占用的核心大头,TurboQuant 的 3bit 无损压缩,能让单张 GPU 的并发服务能力提升 4-5 倍,同时 8 倍的注意力计算加速,能进一步提升推理吞吐量。这意味着大模型的推理成本会直接下降 70% 以上,大幅降低 AI 应用的落地门槛,让更多中小企业能用上低成本、长上下文的大模型服务。
3. 超长上下文场景实现规模化落地
百万级上下文的大模型早已出现,但始终无法规模化落地,核心瓶颈就是 KV 缓存的显存开销。TurboQuant 的出现,让 128K、256K 甚至百万级上下文的大模型,能在普通的 GPU 上稳定运行,长文档合同审查、代码库全量分析、完整书籍解读、多轮超长对话等场景,终于可以从 demo 演示走向规模化生产落地,彻底释放大模型长上下文能力的商业价值。
4. 开源模型的竞争力迎来质的飞跃
此前,闭源商用大模型在长上下文能力上,一直通过工程优化、推理框架保持着领先优势。而 TurboQuant 是完全开源的技术方案,开源模型可以无缝集成这套量化技术,在不损失精度的前提下,大幅提升长上下文支持能力与推理速度,快速缩小与闭源模型的差距,推动整个开源大模型生态的快速发展。
七、开发者学习路径:从基础组件到完整方案
TurboQuant 是 PolarQuant 与 QJL 两大技术的结合体,对于想要深入理解、落地这套方案的开发者,Google 给出了清晰的学习顺序:
- 先学习 QJL:作为 1bit 无偏量化的基础理论,它是 TurboQuant 残差处理的核心,理解了 QJL 的数学原理,就能明白无损量化的底层逻辑;
- 再学习 PolarQuant:掌握极坐标量化的坐标转换逻辑与量化方法,理解它如何在低 bit 下保留向量的核心语义信息;
- 最后学习 TurboQuant:搞懂两级压缩的协同逻辑,以及工程落地的完整流程。
目前,QJL、PolarQuant、TurboQuant 的三篇论文都已公开,开发者可以通过论文完整学习技术细节,同时基于开源实现快速集成到自己的推理框架中。
结语
TurboQuant 的发布,让我们看到了大模型技术发展的一个核心趋势:当模型架构的创新逐渐放缓,工程化与底层数学原理的优化,正在成为突破大模型落地瓶颈的核心驱动力。
它用一套优雅的数学方案,解决了困扰行业多年的 KV 缓存量化难题,让 3bit 无损量化从不可能变成了现实。更重要的是,它零门槛、开箱即用的特性,让这项技术可以快速普及到整个行业,彻底打破了长上下文大模型的落地壁垒。
未来,TurboQuant 必然会成为大模型推理框架的标配技术,它不仅会改变大模型的量化标准,更会推动大模型从云端的高端算力集群,走向每一台手机、每一个边缘设备,真正让长上下文 AI 能力,成为普惠的基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)