[JBHI 2025]AIPNet: Action-Instance Progressive Learning Network for Instrument-Tissue Interaction De

目录
2.3.1. Identifying Instrument-Tissue Interaction
2.3.2. End-to-End Object Detector
2.3.3. Human-Object Interaction Detection
2.4.1. Feature Extraction and Proposal Generation
2.4.4. Action Class Refinement
2.5.4. Comparison With State-of-The-Arts
2.5.5. Comparison Experiments on Model Structure
2.5.6. Ablation Study on Key Components of the Model
2.5.7. Ablation Study on Dynamic Proposal Generator
1. 心得
(1)总是不太能get到CNN视觉这边的各种捏形状
(2)可能我不是专门做这个的,感觉图都有点难以理解(可能做目标检测的可以一眼懂?
(3)这个写作手法...不是很亲民
(4)好难的一个任务,普遍精度好低啊
(5)不知道作者的方法到底新颖不新颖,我也没有看过相关工作列举的经典的那些,DETR啥的。虽然这篇论文也有很多槽点,但作者的出发点还是很新颖的,也可以说很神奇?
2. 论文逐段精读
2.1. Abstract
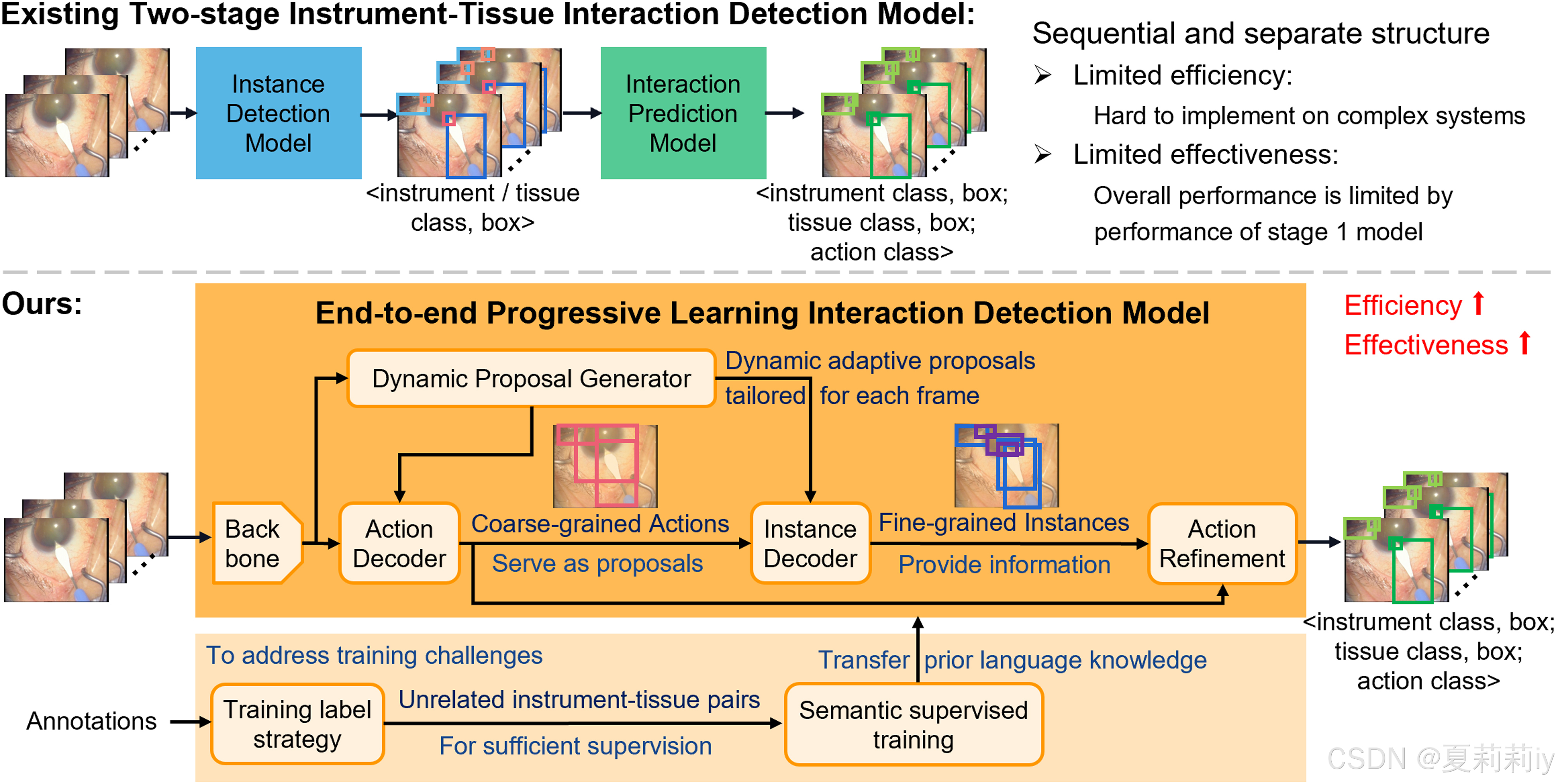
①器械-组织交互现在一般有两个阶段:实例检测和交互预测
②作者提出end-to-end Action-Instance Progressive Learning Network (AIPNet),包含动作检测,实例检测和动作类细化
③图形摘要:
2.2. Introduction
①器械-组织交互需要检测:器械类型,器械框,组织类别,组织框,动作类型
②现有的器械-组织交互模型是两阶段的,第一阶段是检测实例,第二阶段才能预测关系。如此图的(a):
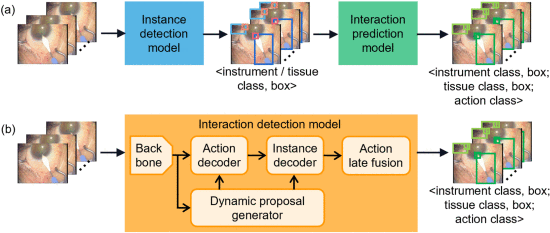
双阶段模型通常缺陷是明显的,第二阶段的预测会过于依赖第一阶段准确率;其次就是模型复杂耗时高
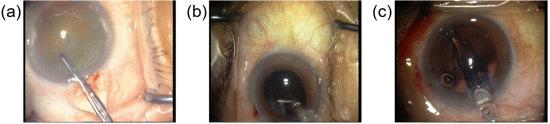
③PhacoQ数据集示例,器械和组织交互非常不明显:
quintuple adj./det.五倍的;由五部分(或人、群体)构成的;五方面的 v.(使)成为五倍 n.五倍量;〈罕〉五个一套
intraocular adj.眼内的
cholecystectomy n.胆囊切除术
2.3. Related Works
2.3.1. Identifying Instrument-Tissue Interaction
①简要介绍器械组织交互,和之前一样就是双阶段
2.3.2. End-to-End Object Detector
①作者使用轻量高效的Sparse R-CNN作为解码器
2.3.3. Human-Object Interaction Detection
①人与物的交互(HOI)从两阶段发展到端到端,但还没有面向手术视频的
2.4. Method
①AIPNet示意图:
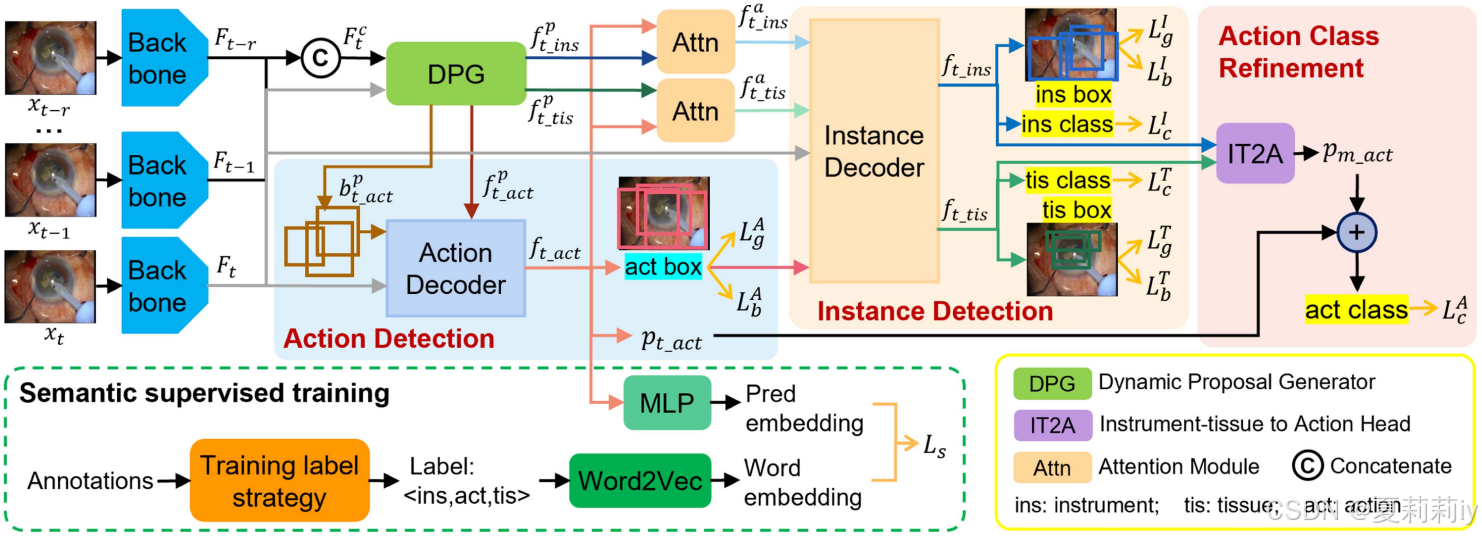
它包含三个主要步骤:动作检测、实例检测和动作类细化
②为每个视频帧提出一个动态提议生成器(DPG)
③生成无关的器械-组织相互作用训练标签
2.4.1. Feature Extraction and Proposal Generation
①对于一个有帧的视频
,将当前帧视为帧
。当前帧的前
帧是
②把放进由CNN和FPN组成的主干网络,得到特征图
,其中
是特征图的通道
③作者提出动态提议生成(Dynamic Proposal Generator,DPG),把基础提议框加上帧的权重。并且为动作、器械和组织分别设置提议生成器、
和
④受动态卷积启发,提出的DPG包括个基础特征和
个基础框,
为可学习参数。因为
需要时间信息,所以它是多个视觉特征图的拼接(就是
的所有特征图)。
会依次经过全局平均池化,GRU和残差连接:
然后把得到的放进全连接层,出Softmax之后,会被捏成
的形状。然后就要看右边的图(绿框内右边白色部分):
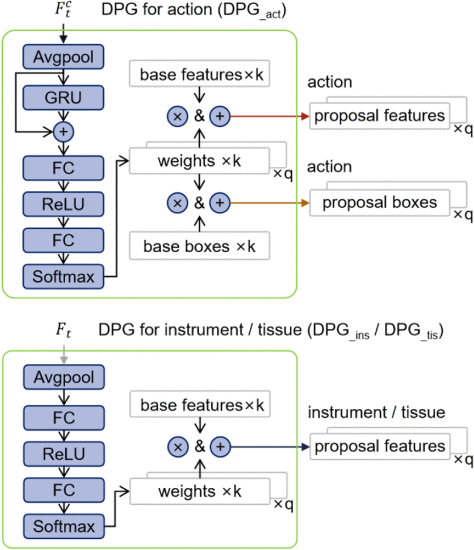
得到的特征会遇到基础特征(一开始随机初始化)和提议框
(一开始也随机初始化),加权求和(矩阵乘法,就是图中的×&+)之后得到
和
。对于静态当前帧的器械和组织特征,不需要GRU时间建模,也不需要提议框。
2.4.2. Action Detection
①动作解码器和实例解码器示意图:
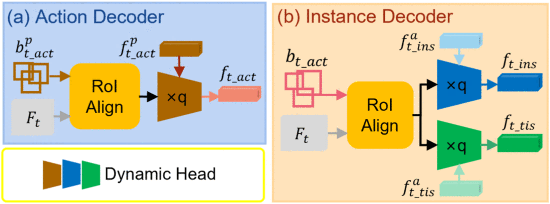
先用框获取特征图的特征,这个不是乘法操作应该,可能就是
个提议(可能是
个动态头吧)。通过动态头之后得到
②经过两个前馈网络(FFN)生成
(
是动作类别个数),然后退化成动作框
2.4.3. Instance Detection
①使用注意力增强提议特征(对这是个注意力):
其中角标
②然后将特征送入实例解码器
2.4.4. Action Class Refinement
①把器械特征、组织特征、仪器-组织对的空间编码分别通过全连通层、归一化函数和 ReLU 激活函数,然后拼接在一起通过全连接层,得到最终的映射动作对数
2.4.5. Training and Inference
①因为数据集只给了存在的交互集合,不是很够用,所以作者不全了其他的单独集合,如
进行训练
②利用预训练的 Word2Vec 模型将“器械-动作-组织”三元组转换为词嵌入作为监督信号,使用 L1 和 InfoNCE 作为损失
③训练损失:
其中是边界框L1损失,
是IoU损失,
是focal损失,
是语义损失
2.5. Experiments
2.5.1. Dataset
①白内障手术视频数据集PhacoQ,包含20个帧率为1 fps的手术视频。每帧的注释包括仪器和组织的位置,以及仪器、组织和动作的类型。注释包含12种仪器、12种组织和15种作用类型,总共产生32种交互方式。PhacoQ数据集随机分为包含12个视频的训练集、包含4个视频的验证数据集和包含4个视频的测试集。
②内窥镜图像CholecQ数据集由CholecT50和CholecSeg8k两个公开数据集构建,标记了两种仪器、五种组织和五种作用,形成了17种相互作用类型。它包含181个视频片段,包含17种仪器-组织相互作用注释,每个视频片段包含80个图像帧。手术视频数据集分为训练集(含145个视频剪辑)和测试集(含36个视频剪辑)。同一视频中的剪辑也被归入同一套。
2.5.2. Evaluation Metrics
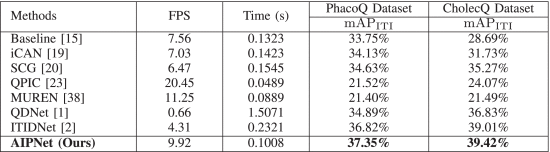
①看比较表
2.5.3. Implementation Details
①特征和框个数
②提议:
③特征通道
④数据增强:随机水平翻转、随机垂直翻转、随机明亮和随机对比
⑤损失系数:全是1
⑥学习:AdamW优化器训练20个纪元,初始学习率设为0.0001,第15个纪元衰减0.1
⑦显卡:GeForce RTX 3060
2.5.4. Comparison With State-of-The-Arts
①结果:
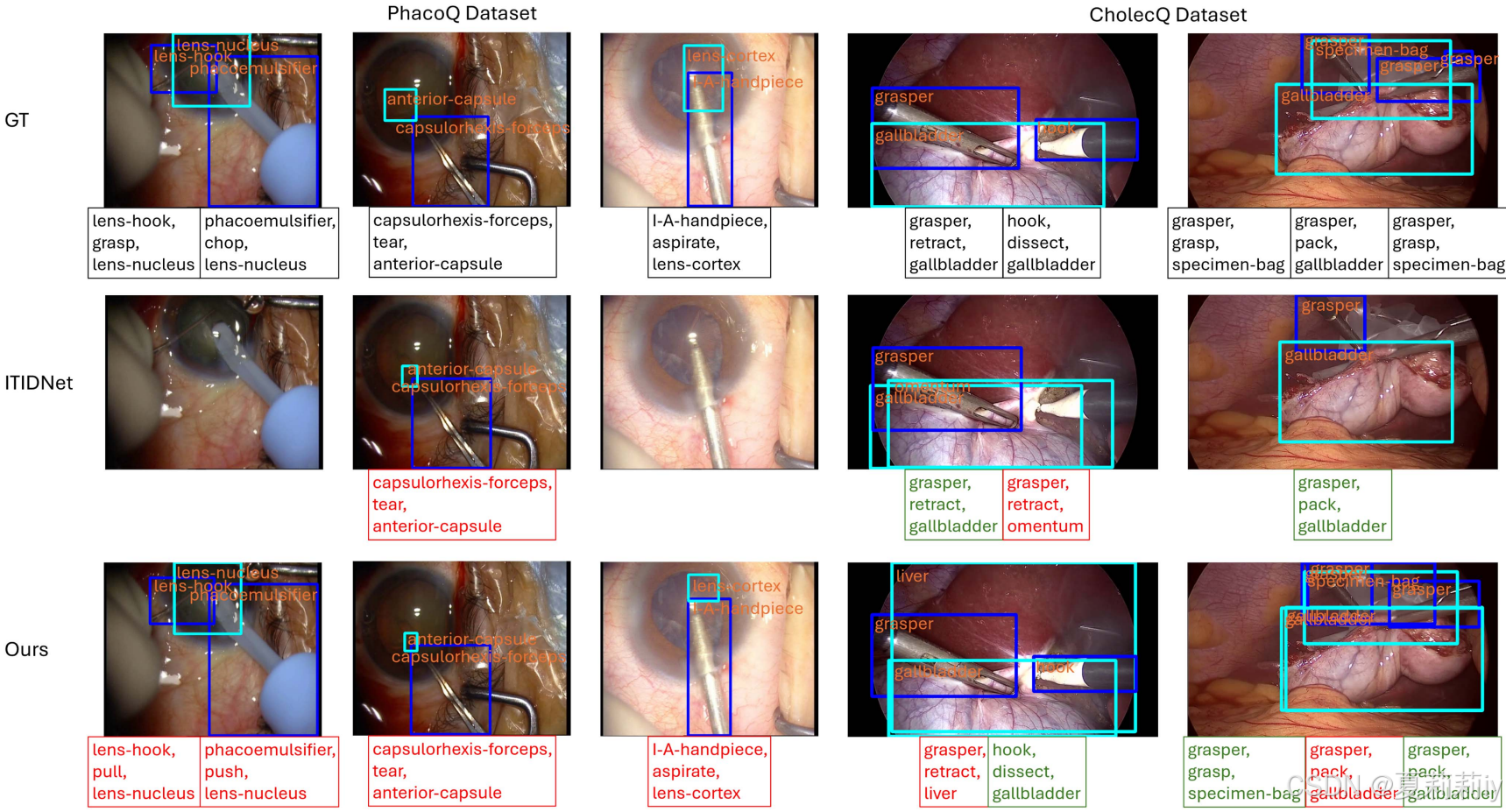
②PhacoQ和Cholec数据集的可视化:
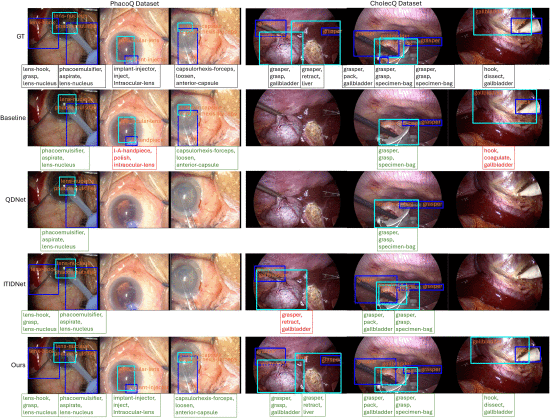
③因为动作差异不大所以动作预测很容易错;动作非常连续所以可能错;组织边界不明确;多个仪器可能导致判断失误;遮挡。根据这些挑战,作者给出了错误案例:
2.5.5. Comparison Experiments on Model Structure
①不同模型结构的对比(重组自己模型):
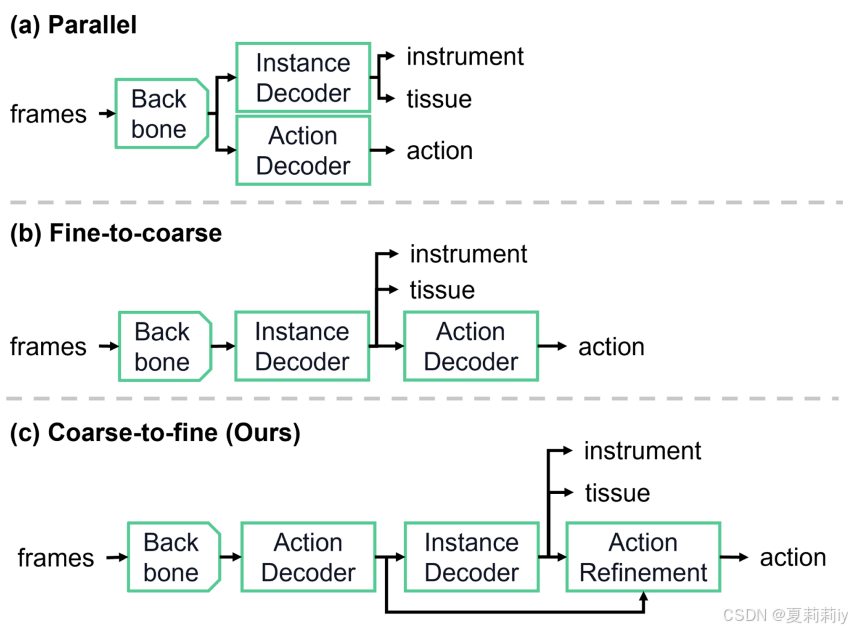
②不同结构的结果:

2.5.6. Ablation Study on Key Components of the Model
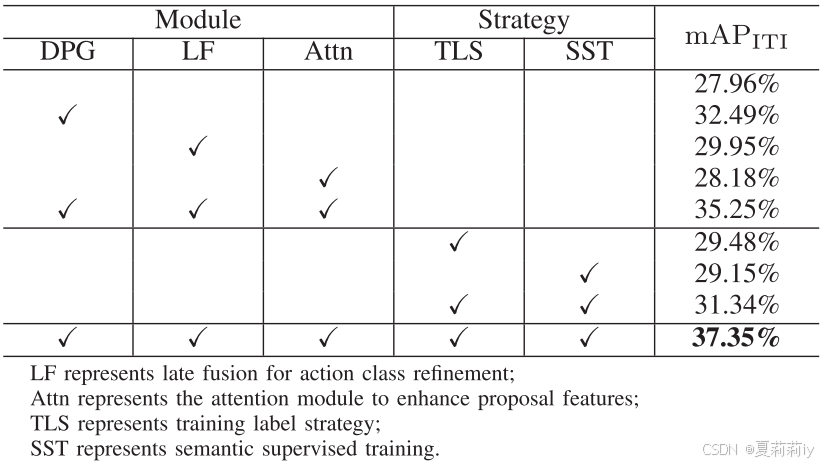
①模块消融:
2.5.7. Ablation Study on Dynamic Proposal Generator
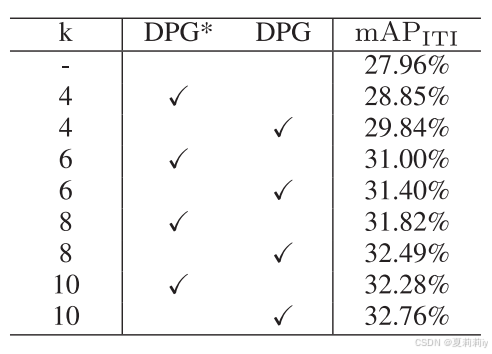
①参数消融:
2.6. Conclusion
~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)