分解的潜行动世界模型
26年3月来自德州Austin分校和Sony的论文“Factored Latent Action World Models”。
从无动作视频中学习潜动作已成为扩展可控世界模型学习的有力范式。潜动作为用户提供一个自然的界面,用于迭代地生成和操作视频。然而,大多数现有方法依赖于单一的逆向和正向动力学模型,这些模型学习单个潜动作来控制整个场景,因此在多个实体同时行动的复杂环境中表现不佳。本文提出一种分解潜动作模型(FLAM),这是一种分解动力学框架,它将场景分解为独立的因子,每个因子推断自身的潜动作并预测其下一步的因子值。与单一模型相比,这种分解结构能够更精确地建模复杂的多实体动力学,并在无动作视频场景中提高视频生成质量。基于对模拟和真实世界多实体数据集的实验,FLAM 在预测准确率和表示质量方面优于先前的工作,并促进下游策略学习,证明分解潜动作模型(FLAM)的优势。
将所有视频中的运动压缩成一个单一的潜动作极具挑战性,因为底层动作空间的复杂性会随着可移动实体的数量呈指数级增长(如图所示)。因此,现有方法在这样的场景下难以进行潜动作学习,这严重限制了它们在不同场景中的适用性。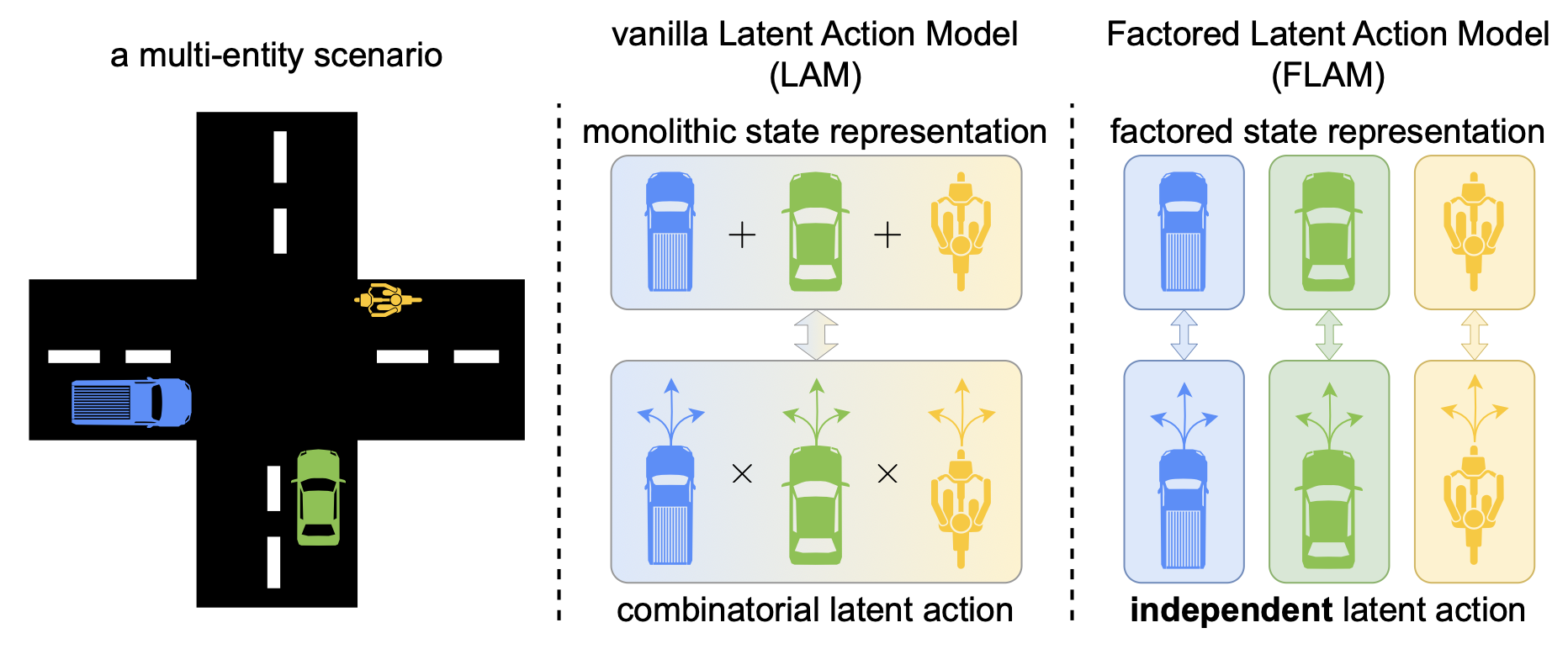
本文提出一种分解潜动作模型(FLAM),其中潜状态被分解为一组因子,每个因子通过共享的分解逆动力学模型(IDM)和正向动力学模型独立地预测其潜动作及其下一步值。与以往必须在单个潜动作空间中捕获所有联合动作组合的工作相比,FLAM 假设所有因子共享一个潜动作空间,从而将学习问题简化为对每个实体在该公共空间中的动作模式进行建模。此外,在前向动力学方面,与大多数先前使用整体场景表示(将所有实体纠缠在一起)的LAM方法不同,FLAM将场景分解为具有共享前向动力学模型的组合实体,从而固有地支持置换不变性并实现更强的泛化能力。以下一帧预测为训练目标,FLAM从无动作视频数据中学习分解后的状态和动作表示,与以往工作相比,能够更准确地建模复杂的多实体动力学,并提高预测质量。
如图所示,逆动力学模型(IDM)和 FDM 都观测到 o_t,但只有 IDM 观测到 o_t+1。因此,为了准确预测 o_t+1,IDM 必须通过潜动作 a_t 提取有用的转换信息。然而,如果没有对 a_t 进行显式的瓶颈限制,模型可能会退化为一个简单的解,即 a_t 简单地复制 o_t+1。为了防止这种捷径,以往的研究通常会限制 a_t 的容量,例如通过矢量量化将其离散化为一组少量的码,或者使用 VAE 式的目标函数将其正则化到某个先验分布(Kingma & Welling, 2013; Van Den Oord et al., 2017)。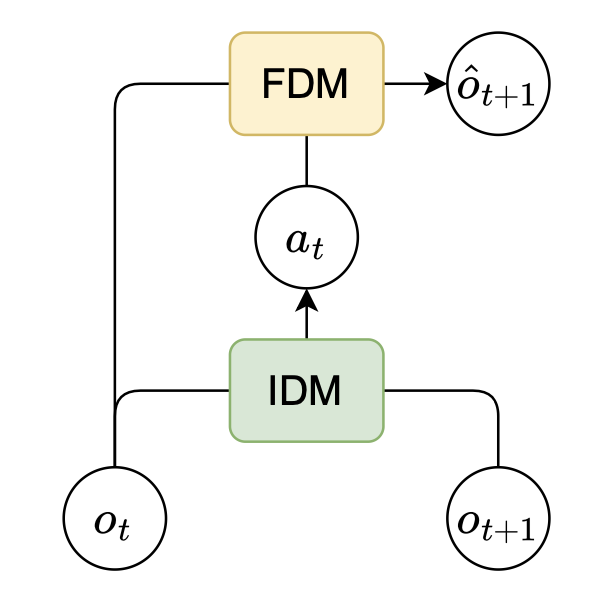
虽然潜动作模型提供一个仅从视频中学习可控世界模型的通用框架,但它们通常使用单个潜动作来表示整个场景的变化,这在多个实体独立行动时会受到限制。例如,在拥挤的十字路口,许多车辆和行人各自独立行动,将所有实体的行动压缩成一个潜行动可能极具挑战性。为了克服这一局限性,FLAM 将状态表示和潜行动都分解为独立的因子,从而能够高效地对多实体动态进行建模。
从宏观角度来看,FLAM 通过在每帧之间推断一组分解的潜动作而非单个潜动作,实现了多实体场景下高效的潜动作模型学习。其学习过程分为两个阶段,如图所示和算法 1 所示: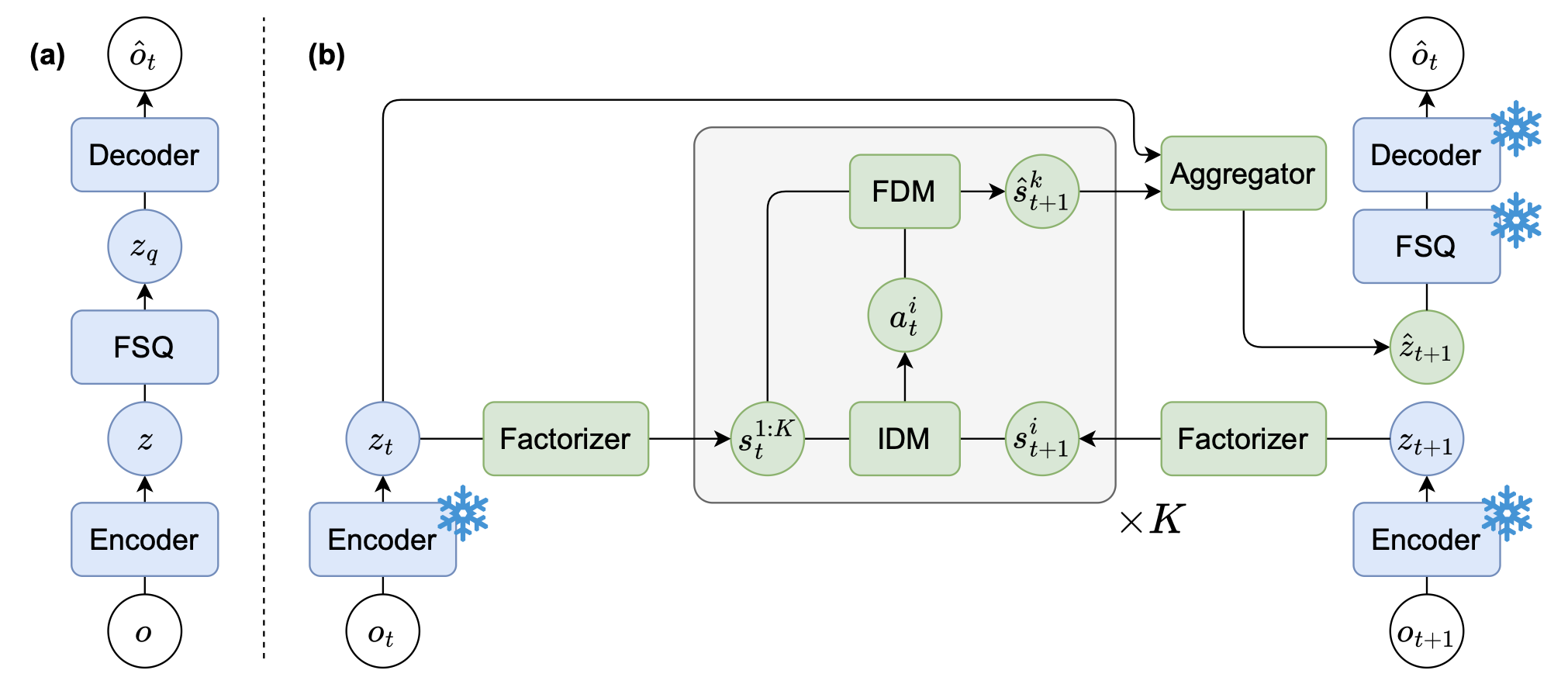

• 编码器学习:FLAM 预训练一个 VQ-VAE 来提取像素的高级特征,从而使潜动作模型能够在特征空间而非像素空间中进行学习,以实现高效学习。
• 潜动作模型 (LAM) 学习:利用提取的特征,FLAM 将场景分解为若干个独立的因子,也称为槽位。对于每个槽位,逆动力学模型根据其当前帧和下一帧的值推断出一个独立的潜动作。然后,基于当前值和相应的潜动作,正向动力学模型独立地预测每个槽位的下一帧值。最后,所有预测的时隙都被映射回特征空间,并解码成下一帧视频。
FLAM 从无动作视频中学习建模世界之后,其推断出的潜动作可用于可控视频生成或策略学习,从而解决下游任务。
预训练编码器
如图 (a) 所示,FLAM 学习一个 VQ-VAE(Van Den Oord,2017)从原始像素中提取特征,从而实现快速 LAM 学习。对于每一帧 o,CNN 编码器首先提取 N 个块级特征 z。然后,使用有限标量量化 FSQ(Mentzer,2023)将这些特征从连续的编码器输出量化到离散码本 z_q 中最近的条目,FSQ 将特征强制转换为一组有限的学习嵌入。最后,解码器根据量化后的特征重建帧。
分解潜动作模型 (FLAM)
如图 (b) 所示,潜动作模型包含四个关键组件:1) 一个因子分解器,用于将场景 z 分解为一组独立的槽位(slots) s;2) 一个共享的逆动力学模型,用于为每个槽位推断一个独立的潜动作 ai;3) 一个共享的前向动力学模型,用于根据当前槽位值和潜动作预测每个槽位的下一帧值;以及 4) 一个聚合器,用于将预测的槽位映射回特征空间。这四个组件联合训练,以最小化下一帧的预测误差。
学习的潜动作利用
FLAM学习的潜动作隐式地捕捉环境中各个实体的可控动态,为操控视频生成提供一个自然的接口。具体来说,用户可以通过从先验分布中采样或选择值来指定潜动作,并在生成过程中将其用作控制变量,从而生成多样化的未来轨迹。
除了生成之外,学习的潜动作还编码丰富的智体行为信息,并支持直接从视频中高效学习策略。用一个带有动作标签的小型演示数据集,首先通过监督学习训练一个动作解码器f,将潜动作a映射到真实动作。对于仅包含没有动作标注的视频的大型数据集,用FLAM提取潜动作,并应用学习的解码器为真实动作生成伪标签。然后,这些推断出的动作标签被用于训练行为克隆策略。
数据集。用 4 个仿真数据集和 1 个真实世界数据集进行实验。仿真数据集来自 MultiGrid 环境(Oguntola,2023)和 Procgen 基准测试集(Cobbe,2019)。在 Procgen 中,用 3 个环境:Bigfish、Leaper 和 Starpilot。对于真实世界数据集,用 nuPlan(Karnchanachari,2024),这是一个自动驾驶数据集。用这些数据集是因为它们包含多个独立的实体,例如智体、敌人和车辆。
实现。编码器在潜动作模型学习期间进行预训练并冻结。没有训练一个适用于所有数据集的通用特征提取器,而是为每个数据集训练一个单独的编码器,因为工作重点是展示因子分解对世界模型的优势,而不是开发一个通用的世界模型。针对特定数据集的编码器学习确保表征学习不会成为性能瓶颈,从而能够对不同方法进行有意义的比较。
基线模型。将 FLAM 与以下基线模型进行比较:
• Genie (Bruce,2024) 和 AdaWorld (Gao,2025) 是基础的潜动作模型,它们推断单个场景级潜动作。Genie 通过矢量量化来约束潜动作容量,而 AdaWorld 采用 VAE 式正则化。由于 Genie 与 LAPO 的实现类似,因此在比较中省略 LAPO。
• World 模型使用真实动作而非推断的潜动作,并且仅学习前向动力学模型。它仅在具有动作标签的模拟数据集上进行评估。
• PlaySlot(Villar-Corrales & Behnke,2025)首先使用 SAVi(Kipf,2021)学习以对象为中心的表示,然后在冻结的表示之上训练潜动作模型。
• SlotFormer(Wu,2022)类似地使用 SAVi 学习以对象为中心的表示,但它训练的是基于槽位的预测模型,该模型仅以当前槽位为条件(即,不包含潜动作)。
为了公平比较,所有方法均使用相同的预训练编码器进行特征提取,并在适用的情况下,使用相同的因子分解器、IDM 和 FDM 架构。此外,为了使各方法的潜动作容量相匹配,Genie 和 AdaWorld 使用单个维度为 d 的潜动作,而 FLAM 和 PlaySlot 则分别使用 K 个维度为 d/K 的因子级潜动作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)